Embed Size (px)
Citation preview

ACADGILDACADGILD
In simple words, Kafka is a distributed, partitioned, replicated commit log service. With a uniquedesign It provides the functionality of a messaging system.
What does all that mean?
First, let's look at some of the basic messaging terminologies:
• Kafka maintains all the feeds of messages in categories called topics.
•The processes that publish messages to a Kafka topic are known as producers.
•The processes that subscribe to topics and process the feed of published messages are
known as consumers.
•Kafka runs in a cluster containing one or more servers, each of which is called a broker.
At a high level, the network producers send messages to the Kafka cluster, which in turn serves
them up to consumers.
Apache Kafka has the following benefits:
• Fast: A single Kafka broker can serve thousands of clients by handling megabytes of reads and
writes per second.
• Scalable: Data are partitioned and streamlined over a cluster of machines to enable larger data.
• Durable: Messages are persistent and are replicated within the cluster to prevent data loss.
• Distributed by Design: Kafka provides fault tolerance, guarantees and durability.
https://acadgild.com/blog/wp-admin/post.php?post=5395&action=edithttps://acadgild.com/blog/wp-admin/post.php?post=5395&action=edit

ACADGILDACADGILD
Kafka Architecture:
Before we proceed, let’s look at the basic concepts of Kafka. Its architecture consists of the following components:
•A stream of messages of a particular type is defined as a topic. A Message is defined as a
payload of bytes and a Topic is a category or feed name to which messages are published.
•A Producer can be anyone who can publish messages to a Topic.
•The published messages are then stored at a set of servers called Brokers or Kafka Cluster.
•A Consumer can subscribe to one or more Topics and consume the published Messages by
pulling data from the Brokers.
Figure 1: Kafka Producer, Consumer and Broker environment
Producer can choose their favorite serialization method to encode the message content.
For efficiency, the producer can send a set of messages in a single publish request. The
following code examples shows how to create a Producer to send messages.s
What is a Zookeeper in Kafka and is it possible to use Kafka without Zookeeper?
Zookeeper is an open-source, high-performance coordination service used for distributed
applications adapted by Kafka.
No, it is not possible to bye-pass Zookeeper and connect straight to the Kafka broker. Once
the Zookeeper is down, it cannot serve the client request.
• Zookeeper is used to communicate between different nodes in a cluster.
• In Kafka, it is used to commit offset. So if the node fails in any case, it can be retrieved
from the previously committed offset.
https://acadgild.com/blog/wp-admin/post.php?post=5395&action=edithttps://acadgild.com/blog/wp-admin/post.php?post=5395&action=edit

ACADGILDACADGILD
• Apart from this, it also does other activities like leader detection, distributed
synchronization, configuration management, identifies when a new node leaves or joins,
the cluster, node status in real time, etc.
Step-by-Step Installation of Kafka in Single Node Hadoop Cluster:
Step 1: Check if Hadoop and Zookeeper are installed and running.
Step 2: Download the Kafka tar file from below link and extract the file.
https://drive.google.com/open?id=0B1QaXx7tpw3SYjhvZWZBRFRNTkU
https://acadgild.com/blog/wp-admin/post.php?post=5395&action=edithttps://acadgild.com/blog/wp-admin/post.php?post=5395&action=edit

ACADGILDACADGILD
Step 3: To get recognized by the system, open bashrc and add the home and path for the
Kafka.
Step 4: Execute the source command for the changes made in bashrc file to get affected. Also,
make a directory named logs where Kafka will be writing all its logs process.
You can refer to the below screenshot and find a file named server.properties.
https://acadgild.com/blog/wp-admin/post.php?post=5395&action=edithttps://acadgild.com/blog/wp-admin/post.php?post=5395&action=edit

ACADGILDACADGILD
Step 5: Edit the property in server.property file, inside conf directory in the extracted folder of
Kafka and save the file.
Step 6: In the terminal, run the command for starting Kafka, using the below syntax:
Nohup <path to kafka-server-start.sh file> <path to server.properties>
https://acadgild.com/blog/wp-admin/post.php?post=5395&action=edithttps://acadgild.com/blog/wp-admin/post.php?post=5395&action=edit

ACADGILDACADGILD
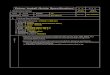
Step 7: Use the jps command to check if the Kafka daemon has started.
Hope this post has been helpful in understanding the steps to install Kafka. In case of any queries,
do drop us your question in the comments section below and we will get back to you at the
earliest.
Stay tuned for more updates on Big Data and other technologies.
https://acadgild.com/blog/wp-admin/post.php?post=5395&action=edithttps://acadgild.com/blog/wp-admin/post.php?post=5395&action=edit