Embed Size (px)
Citation preview

PatternRecognitionandApplications Lab
UniversityofCagliari,Italy
DepartmentofElectricalandElectronic
Engineering
On Security and Sparsity of Linear Classifiersfor Adversarial Settings
AmbraDemontis,PaoloRussu,BattistaBiggio,GiorgioFumera,FabioRoli
Dept.OfElectrical andElectronicEngineeringUniversity ofCagliari,Italy
S+SSPR,Merida,Mexico,Dec.12016

http://pralab.diee.unica.it
Recent Applications of Machine Learning
• Consumer technologies for personal applications
2

http://pralab.diee.unica.it
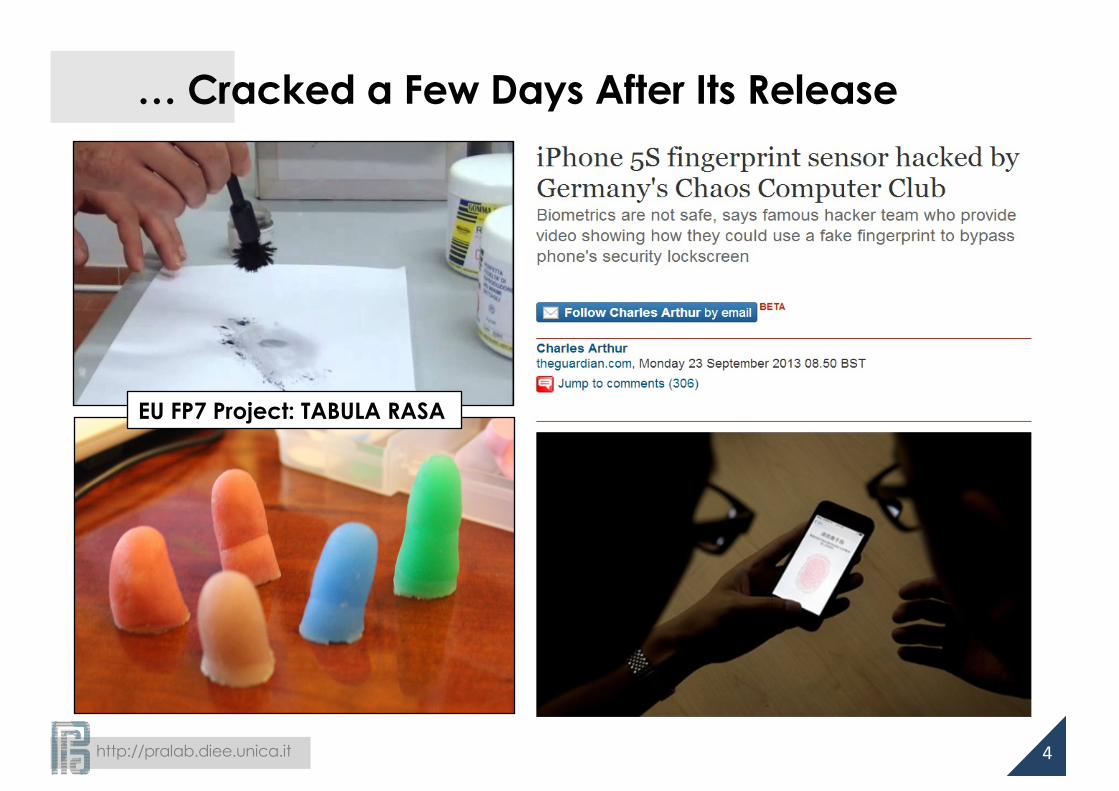
iPhone 5s with Fingerprint Recognition…
3
http://pralab.diee.unica.it
… Cracked a Few Days After Its Release
4
EU FP7 Project: TABULA RASA

http://pralab.diee.unica.it
New Challenges for Machine Learning
• The use of machine learning opens up new big possibilitiesbut also new security risks
• Proliferation and sophisticationof attacks and cyberthreats
– Skilled / economically-motivatedattackers (e.g., ransomware)
• Several security systems use machine learning to detect attacks– but … is machine learning secure enough?
5

http://pralab.diee.unica.it
Classifier Evasion
6
http://pralab.diee.unica.it
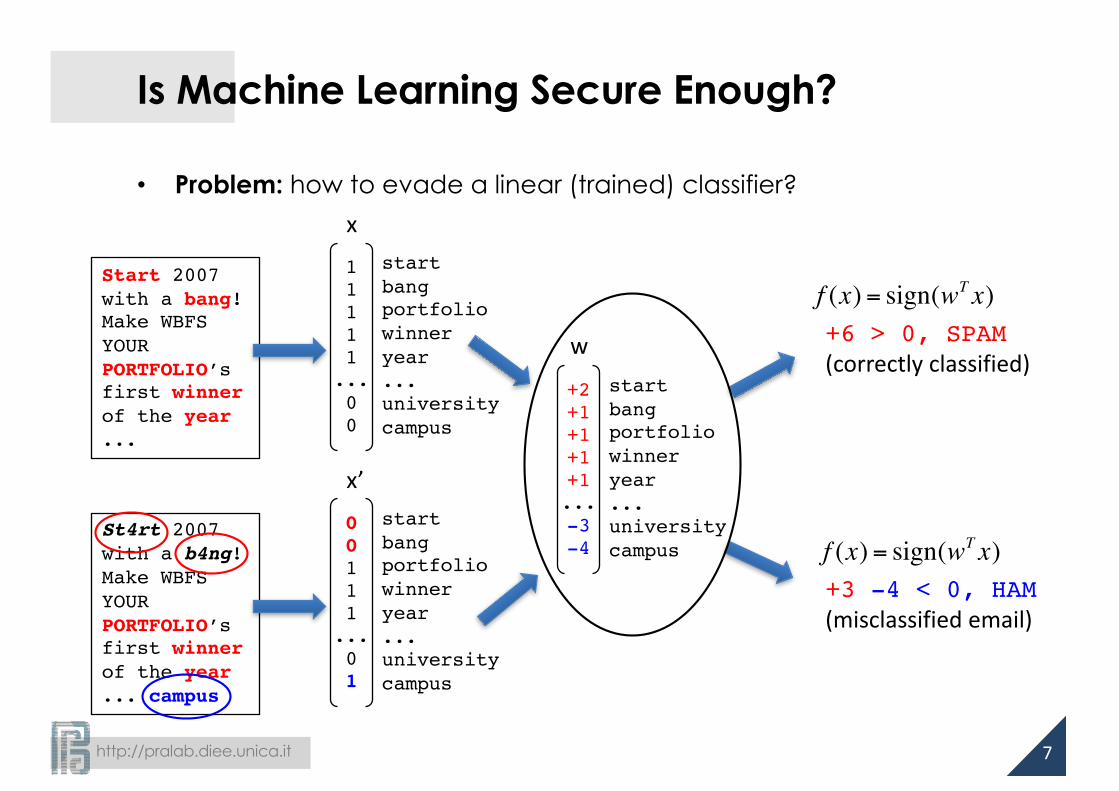
Is Machine Learning Secure Enough?
• Problem: how to evade a linear (trained) classifier?
Start 2007 with a bang!Make WBFS YOUR PORTFOLIO’sfirst winnerof the year...
startbangportfoliowinneryear...universitycampus
11111...00
+6 > 0, SPAM(correctlyclassified)
f (x) = sign(wT x)
x
startbangportfoliowinneryear...universitycampus
+2+1+1+1+1...-3-4
w
x’
St4rt 2007 with a b4ng!Make WBFS YOUR PORTFOLIO’sfirst winnerof the year... campus
startbangportfoliowinneryear...universitycampus
00111...01
+3 -4 < 0, HAM(misclassifiedemail)
f (x) = sign(wT x)
7

http://pralab.diee.unica.it
Evasion of Linear Classifiers
• Formalized as an optimization problem– Goal: to minimize the discriminant function
• i.e., to be classified as legitimate with the maximum confidence– Constraints on input data manipulation
• e.g., number of words to be modified in each spam email
8
min$% 𝑤(𝑥′𝑠. 𝑡. 𝑑(𝑥, 𝑥%) ≤ 𝑑34$

http://pralab.diee.unica.it
Dense and Sparse Evasion Attacks
• L2-norm noise corresponds to dense evasion attacks
– All features are modified by a small amount
• L1-norm noise corresponds to sparse evasion attacks
– Few features are significantly modified
9
min$% 𝑤(𝑥′𝑠. 𝑡. |𝑥 − 𝑥%|77 ≤ 𝑑34$
min$% 𝑤(𝑥%𝑠. 𝑡. |𝑥 − 𝑥%|8 ≤ 𝑑34$

http://pralab.diee.unica.it
Examples on Handwritten Digits (9 vs 8)
10
original sample
5 10 15 20 25
5
10
15
20
25
SVM g(x)= −0.216
5 10 15 20 25
5
10
15
20
25
Sparseevasionattacks(l1-normconstrained)
original sample
5 10 15 20 25
5
10
15
20
25
cSVM g(x)= 0.242
5 10 15 20 25
5
10
15
20
25
Denseevasionattacks(l2-normconstrained)
manipulated sample
manipulated sample

http://pralab.diee.unica.it
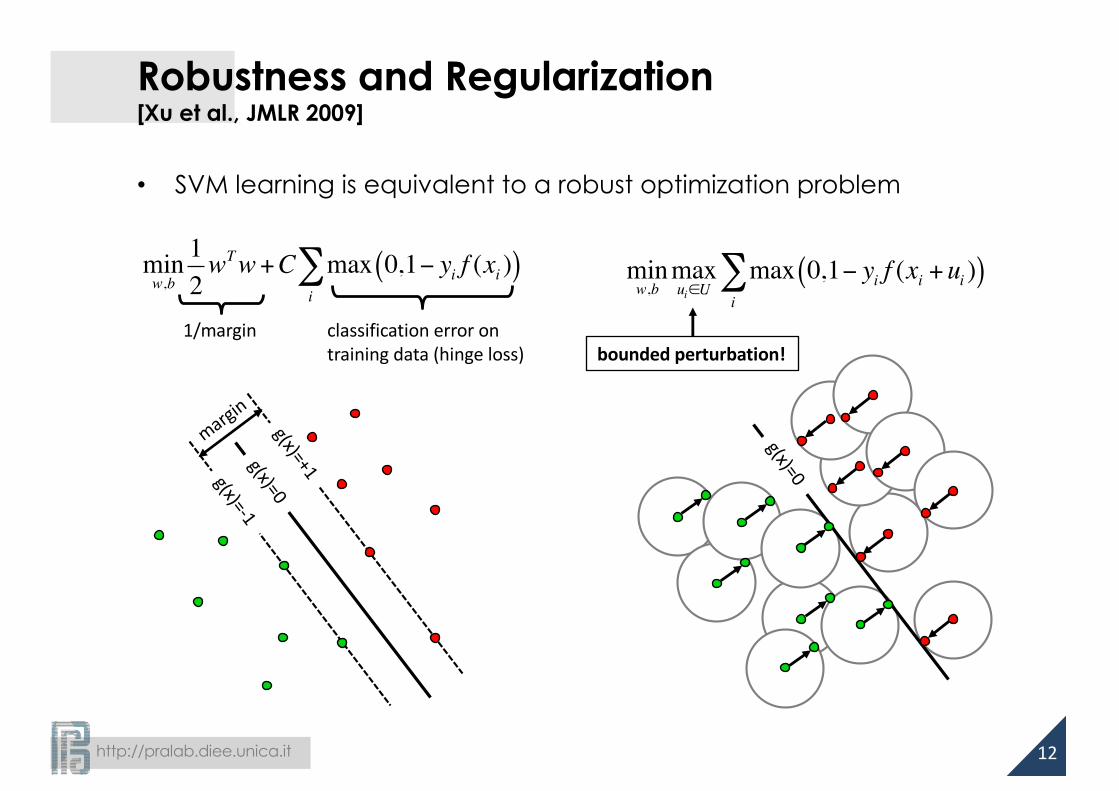
Robustness and Regularization
11
http://pralab.diee.unica.it
• SVM learning is equivalent to a robust optimization problem
Robustness and Regularization[Xu et al., JMLR 2009]
12
minw,b
12wTw+C max 0,1− yi f (xi )( )
i∑ min
w,bmaxui∈U
max 0,1− yi f (xi +ui )( )i∑
1/margin classification error ontrainingdata(hinge loss) boundedperturbation!

http://pralab.diee.unica.it
Generalizing to Other Norms
• Optimal regularizer should use dual norm of noise uncertainty sets
13
l2-norm regularization is optimal against l2-norm noise!
Infinity-norm regularization is optimal against l1-norm noise!
minw,b
12wTw+C max 0,1− yi f (xi )( )
i∑ min
w,bw
∞+C max 0,1− yi f (xi )( )
i∑ , w
∞=max
i=1,...,dwi
http://pralab.diee.unica.it
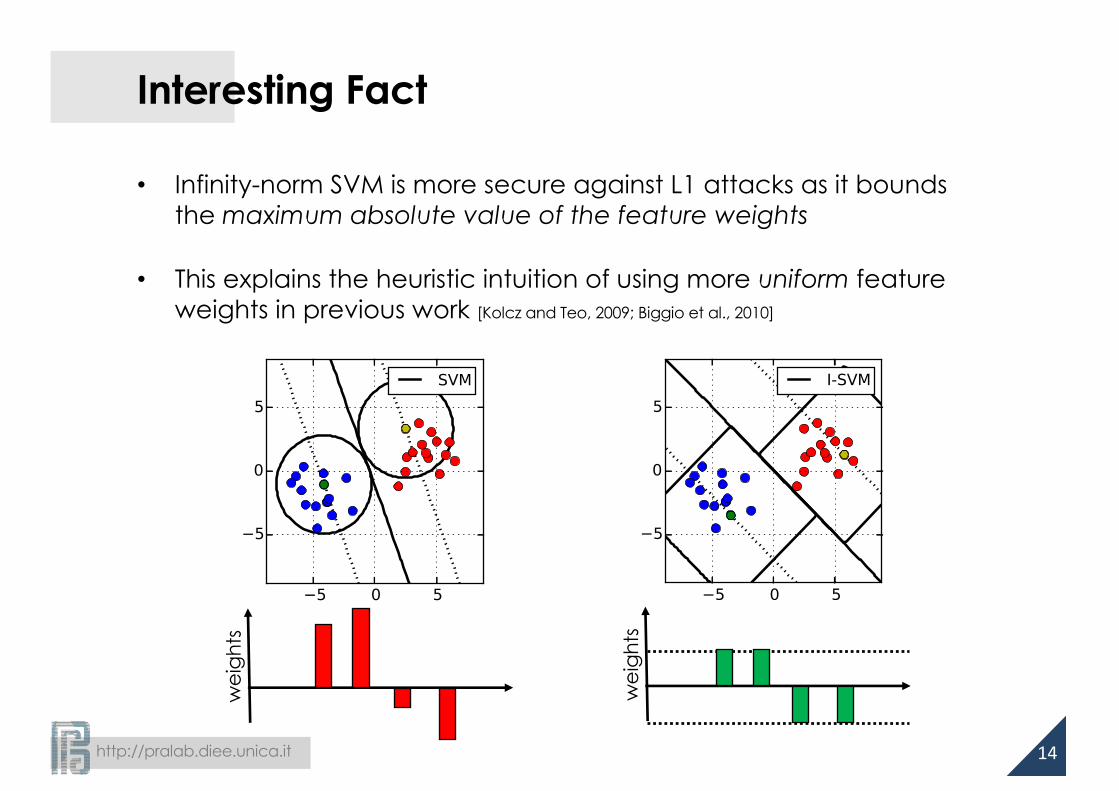
Interesting Fact
• Infinity-norm SVM is more secure against L1 attacks as it bounds the maximum absolute value of the feature weights
• This explains the heuristic intuition of using more uniform feature weights in previous work [Kolcz and Teo, 2009; Biggio et al., 2010]
14
wei
ghts
wei
ghts

http://pralab.diee.unica.it
Security and Sparsity of Linear Classifiers
15
http://pralab.diee.unica.it
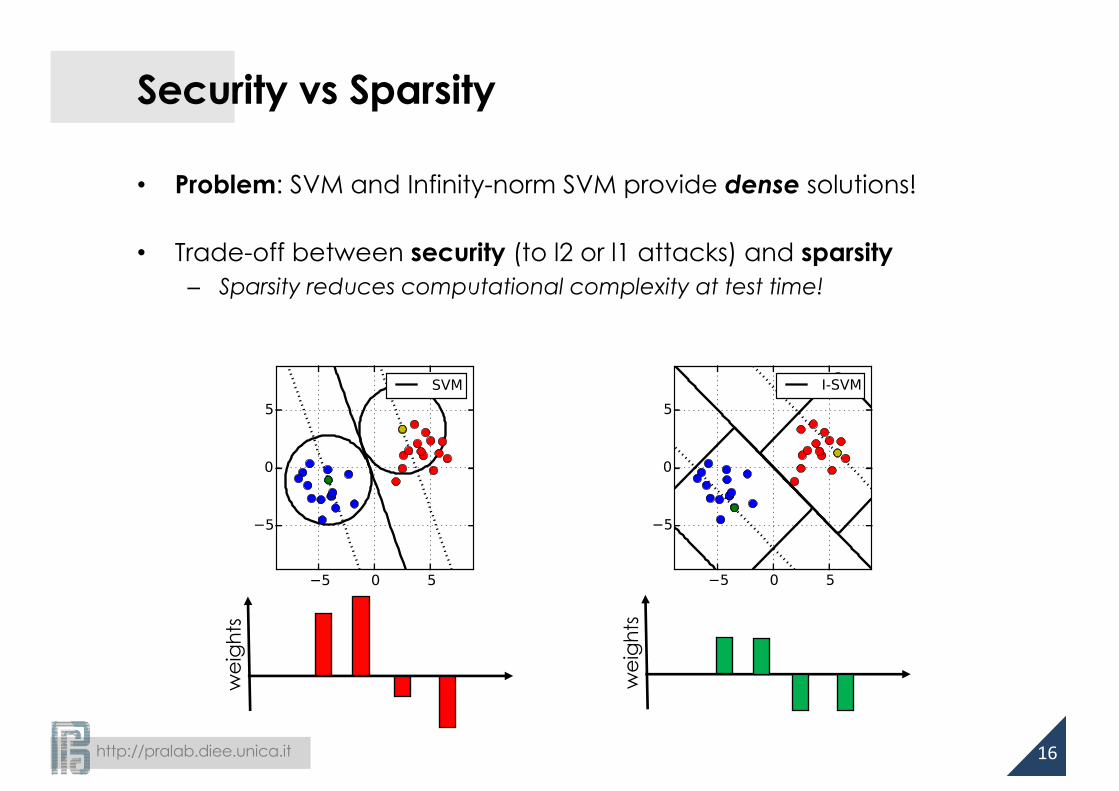
Security vs Sparsity
• Problem: SVM and Infinity-norm SVM provide dense solutions!
• Trade-off between security (to l2 or l1 attacks) and sparsity– Sparsity reduces computational complexity at test time!
16
wei
ghts
wei
ghts
http://pralab.diee.unica.it
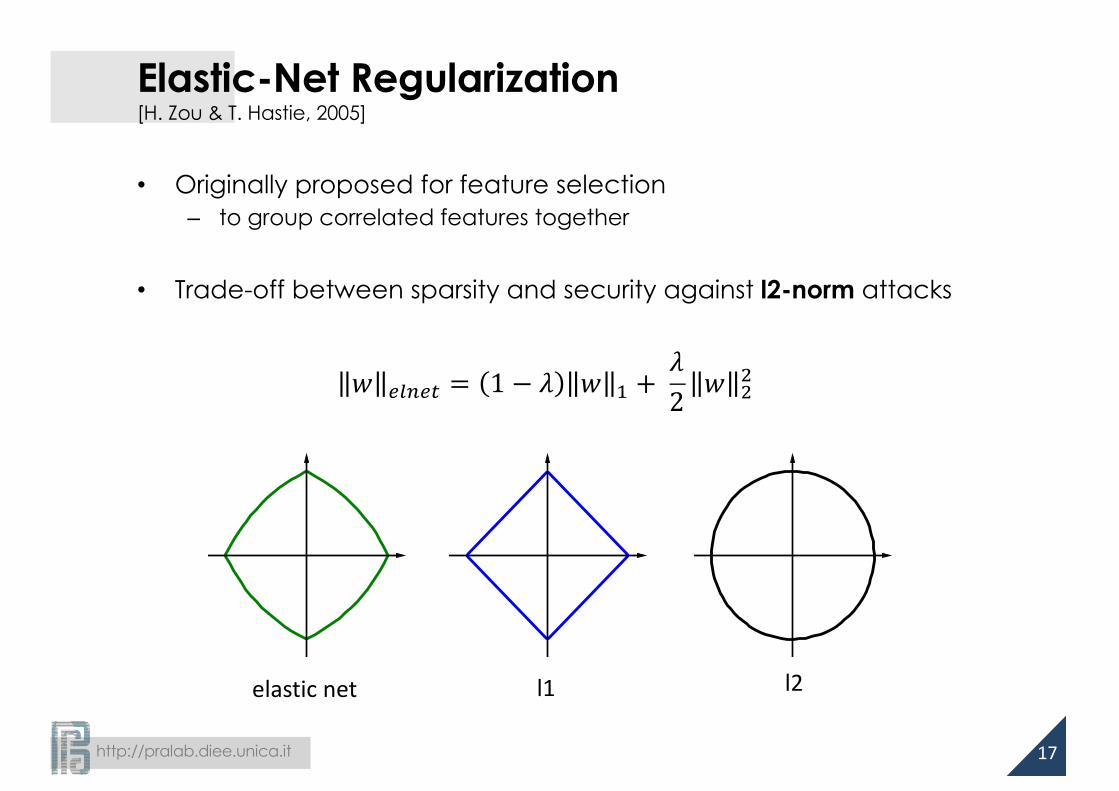
Elastic-Net Regularization[H. Zou & T. Hastie, 2005]
• Originally proposed for feature selection– to group correlated features together
• Trade-off between sparsity and security against l2-norm attacks
17
𝑤 9:;9< = 1 − 𝜆 𝑤 8 +𝜆2 𝑤 7
7
elasticnet l1 l2
http://pralab.diee.unica.it
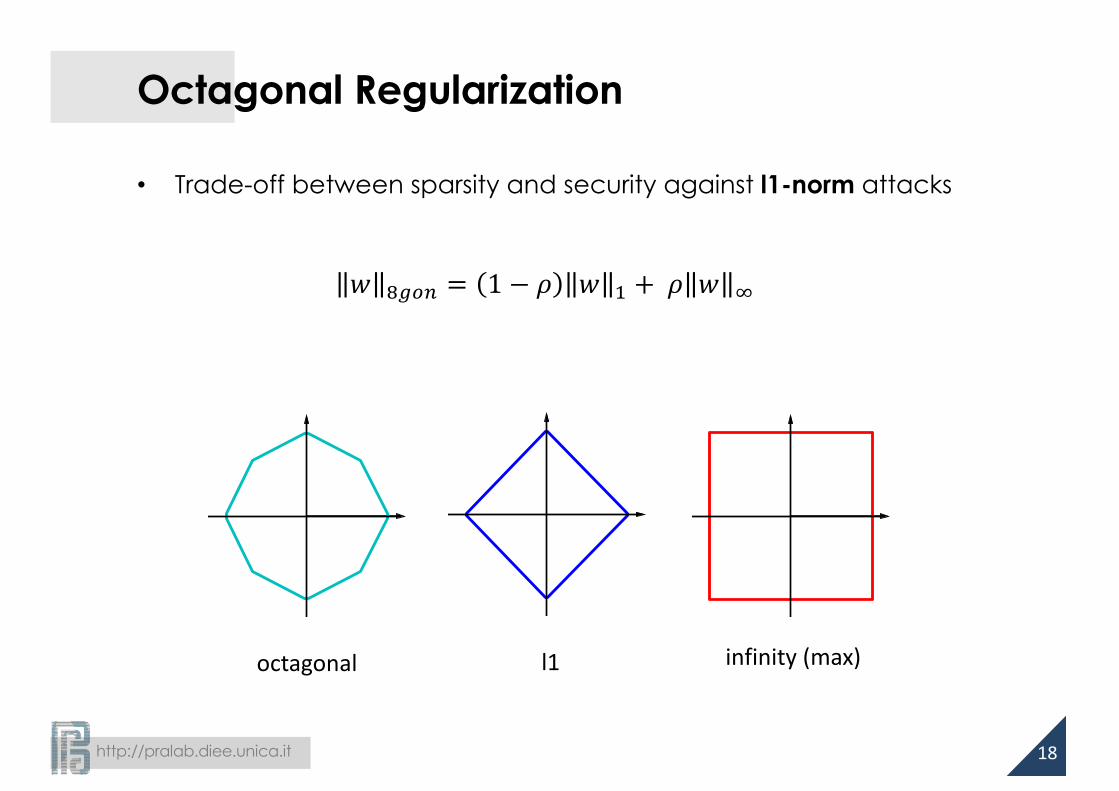
Octagonal Regularization
• Trade-off between sparsity and security against l1-norm attacks
18
𝑤 BCD; = 1 − 𝜌 𝑤 8 + 𝜌 𝑤 F
octagonal l1 infinity(max)

http://pralab.diee.unica.it
Experimental Analysis
19

http://pralab.diee.unica.it
Linear Classifiers
• SVM– quadratic prog.
• Infinity-norm SVM– linear prog.
• 1-norm SVM– linear prog.
• Elastic-net SVM– quadratic prog.
• Octagonal SVM– linear prog.
20
minG,H
12 𝑤 7
7 + 𝐶Jmax 0,1 − 𝑦O𝑓 𝑥O
;
OQ8
minG,H
𝑤 F + 𝐶Jmax 0,1 − 𝑦O𝑓 𝑥O
;
OQ8
minG,H
𝑤 8 + 𝐶Jmax 0,1 − 𝑦O𝑓 𝑥O
;
OQ8
minG,H
1 − 𝜆 𝑤 8 +𝜆2 𝑤 7
7 + 𝐶Jmax 0,1 − 𝑦O𝑓 𝑥O
;
OQ8
minG,H
1 − 𝜌 𝑤 8 + 𝜌 𝑤 F + 𝐶Jmax 0,1 − 𝑦O𝑓 𝑥O
;
OQ8
𝑓 𝑥 = 𝑤(𝑥 + 𝑏

http://pralab.diee.unica.it
Security and Sparsity Measures
• Sparsity– Fraction of weights equal to zero
• Security (Weight Evenness)– E=1/d if only one weight is different from zero– E=1 if all weights are equal in absolute value
• Parameter selection with 5-fold cross-validation optimizing:AUC + 0.1 S + 0.1 E
21
𝑆 =1𝑑 𝑤T|𝑤T = 0, 𝑘 = 1,… , 𝑑
𝐸 =1𝑑
𝑤 8
𝑤 F∈ [1𝑑 , 1]
http://pralab.diee.unica.it
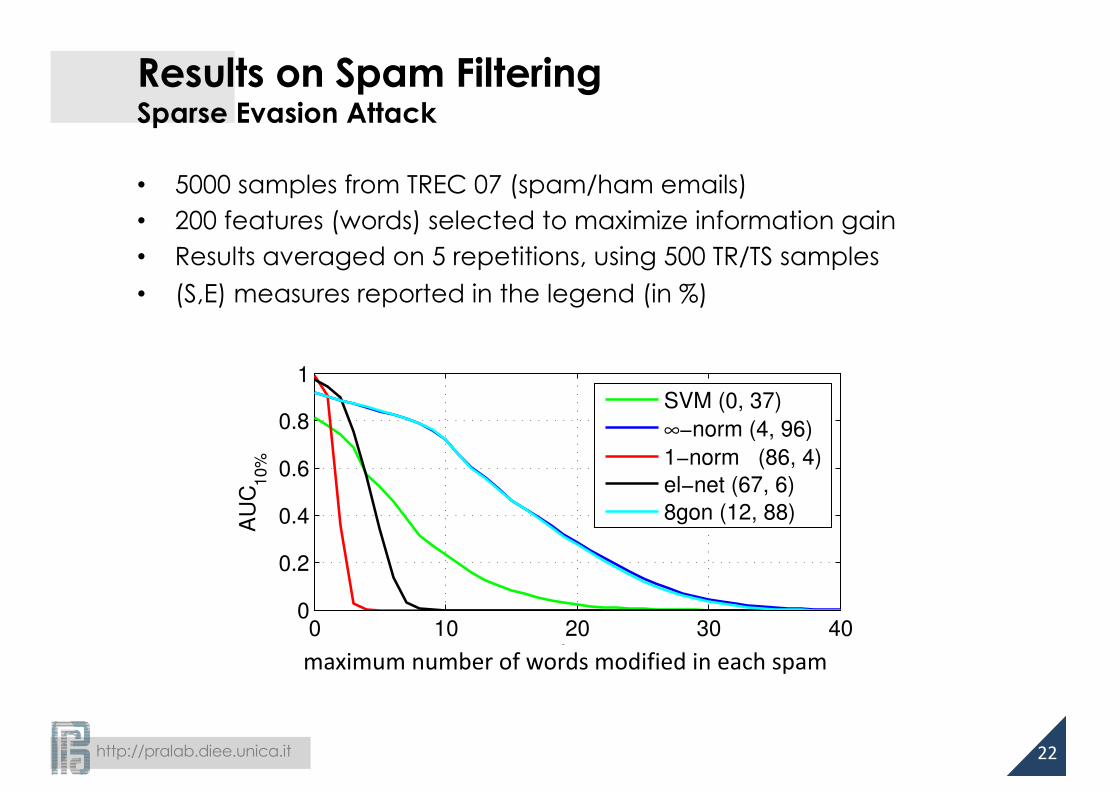
Results on Spam FilteringSparse Evasion Attack
• 5000 samples from TREC 07 (spam/ham emails)• 200 features (words) selected to maximize information gain• Results averaged on 5 repetitions, using 500 TR/TS samples• (S,E) measures reported in the legend (in %)
22
0 10 20 30 400
0.2
0.4
0.6
0.8
1Spam Filtering
AU
C1
0%
d max
SVM (0, 37)
∞−norm (4, 96)
1−norm (86, 4)el−net (67, 6)8gon (12, 88)
maximumnumberofwordsmodifiedineachspam

http://pralab.diee.unica.it
Results on PDF Malware DetectionSparse Evasion Attack
• PDF: hierarchy of interconnected objects (keyword/value pairs)
23
0 20 40 60 800
0.2
0.4
0.6
0.8
1PDF Malware Detection
AU
C1
0%
d max
SVM (0, 47)
∞−norm (0, 100)
1−norm (91, 2)el−net (55, 13)8gon (69, 29)
maximumnumberofkeywordsadded ineachmaliciousPDFfile
/Type 2/Page 1/Encoding 1…
130obj<</Kids[10R110R]/Type/Page... >>endobj170obj<</Type/Encoding...>>endobj
Features:keywordcount
11,500samples5reps- 500TR/TSsamples
114features(keywords)selectedwithinformationgain

http://pralab.diee.unica.it
Conclusions and Future Work
• We have shed light on the theoretical and practical implications of sparsity and security in linear classifiers
• We have defined a novel regularizer to tune the trade-off between sparsity and security against sparse evasion attacks
• Future work– To investigate a similar trade-off for
• poisoning (training) attacks• nonlinear classifiers
24

http://pralab.diee.unica.it
?Any questionsThanks foryour attention!
26
http://pralab.diee.unica.it
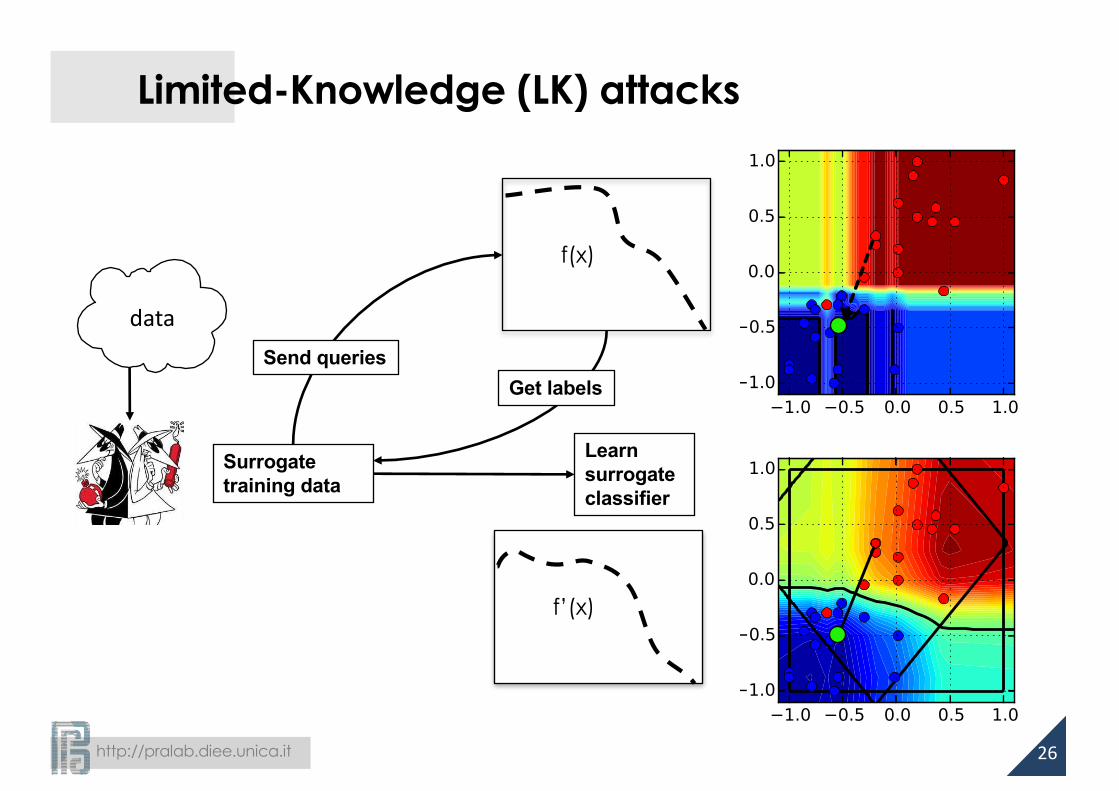
Limited-Knowledge (LK) attacks
26
PD(X,Y)data
Surrogate training data
f(x)
Send queriesGet labels
Learnsurrogate classifier
f’(x)





























