Embed Size (px)
Citation preview


“Carrot” for data deposit “Submit data paper” button on repository Researcher gets
– Another publication/citation opportunity– (Data preserved)
Publisher gets– More data paper submissions– Better quality (metadata already curated by the repo)– Link referrals from data repositories
Repositories get– More data deposits– Better metadata
Funders get
– More re-use– More impact

Phase 1 – Feasibility Study RDA Publisher Workflow Analysis
– Straw Man spec for Helper app/API
Questionnaire for Repositories and Publishers
– Confirm requirements– Gauge interest in proposal
Overwhelmingly positive feedback
– Offers of collaboration
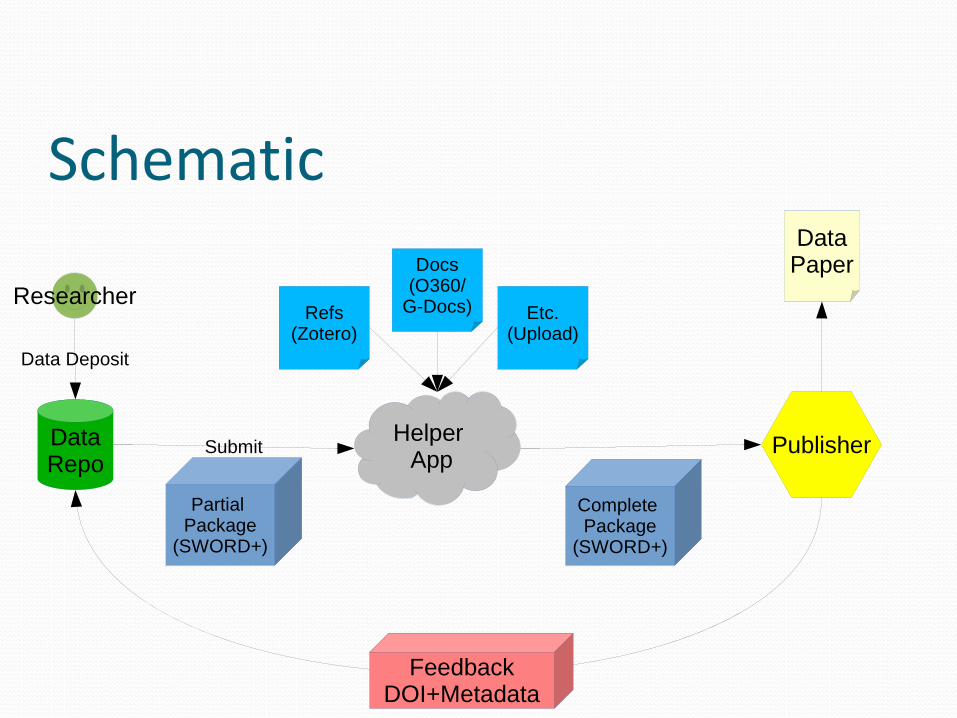
Schematic
Researcher
Helper App
DataRepo
Partial Package
(SWORD+)
Complete Package
(SWORD+)
Publisher
DataPaper
Data Deposit
Submit
Refs(Zotero)
Etc.(Upload)
Docs(O360/
G-Docs)
FeedbackDOI+Metadata

Phase 2 – Proof of Concept Detailed API Spec (SWORD2/DataCite) Protoype helper app “Data Paper Companion”
– Fedora Repository/Hydra– Sword Client/ServerRuby Gems
Community building
– F1000 Research, Elsevier(Data in Brief and Mendeley), ORCID, RDA/THOR
– Many more collaboration offers than we could handle● Figshare, OJS, Dryad, Nature...
– Presentations/outreach
Join up with “Streamlining Deposit”

Phase 3 – The Business Case We started to look for indications of the time this app
would save scholars to quantify the possible benefits... We were expecting to measure efficiency gains of
maybe tens of minutes per submission or a bit more... What we found rather exceeded our expectations!
And explains why everyone was so keen...
#submissionsystems
#datamanagement

Phase 3 - Consolidation Demonstrate real paper(s) published using the workflow Join forces with Streamlining Deposit team
– UX expertise– Align metadata requirements– Expect repo-led and publication-led workflows to co-exist– Need to “close the loop”
Sustainability– Steering Committee to initiate governance structures – API Spec as a formal publication
● Code as a reference implementation/test harness● Include generalised version of Streamlining workflow
– THOR project – identifier ecosystem for research entities– Jisc shared services– ORCID– Cloud hosting: Azure (Microsoft Research), AWS

Phase 3 - Expansion Expanding reach/integration
– More outreach activities– Updated SWORD modules for EPrints, Dspace, OSP– Work with structured repositories such as EBI, NCBI etc. (domain/data specific) – Take up other publisher offers: Nature, OUP– Datasets in ORCID– Journal Policy Registry as a reference source
Roadmap (not development) for additional use cases
– Multiple datasets– Other people's data– Embargoed data (DataShield?)– Automated publication– Not just data papers– REF/Impact friendliness

Resourcing PI & Project Manager - Lucie Burgess/Neil Jefferies (Bodleian), Fiona Murphy (MMC Ltd)
– Community engagement– Overall co-ordination
Lead Developer - Anusha Ranganathan (Digital Nest)– Some hands on development– “Cloud ready” build process for helper app – Primarily co-ordination/support of partner technical efforts
UX Specialist – Stephann Makri (City)
– Streamline/optimise Data Paper Companion experience
Technical Author (tbd)– Formal API specification document – Developer guidelines
Partners (F1000Research, Nature, OUP, Elsevier, Figshare, OJS, Microsoft Research etc.)
– Outreach, technical partners, Steering Committee, governance





























