Embed Size (px)
Citation preview

Document Image Segmentation using Fuzzy Classifier and the
Dual-Tree DWTJamal Saeedi, Reza Safabakhsh
from Amirkabir University of Technology
and Saeed Mozaffarifrom Semnan University
Presented By: Jamal Saeedi

Content
What is Document Image Segmentation (DIS)?
DIS Important Applications
Wavelet-based DIS Methods
The New DIS algorithm using Fuzzy Classifier and the
Dual-Tree DWT
Evaluation Methods and Results
Conclusion
2/31

What is Document Image Segmentation?
Document image segmentation (DIS) is the first step of
document image analysis and understanding.
DIS partitions a document image into distinct regions.
In the ideal case, these regions correspond to the image
entities such as:
Text and Non-Text blocks
Text, Picture and Background blocks
3/31
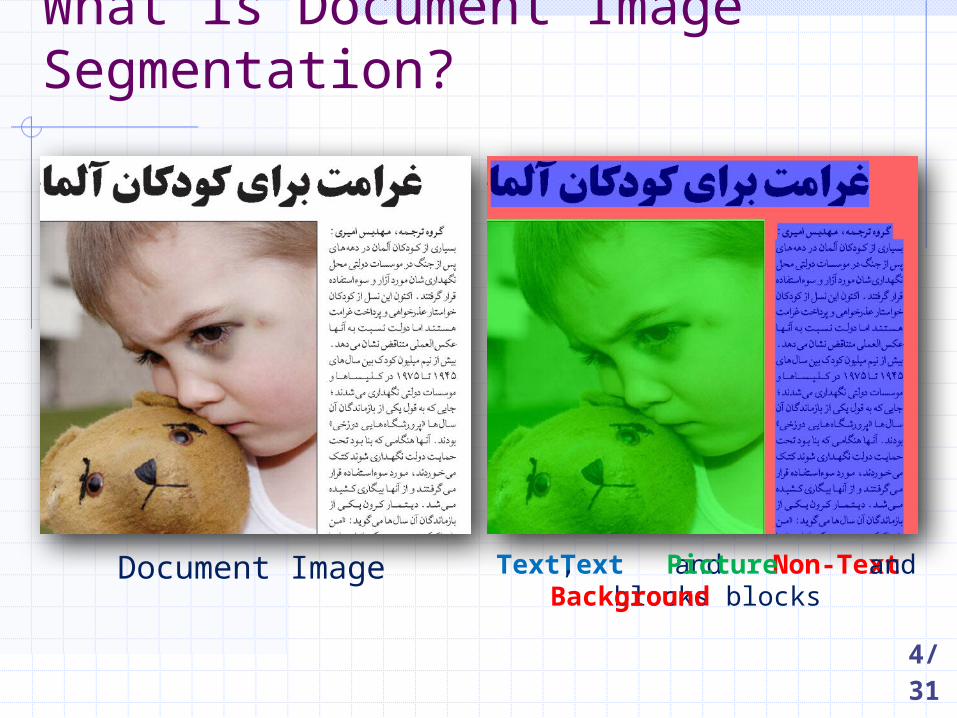
What is Document Image Segmentation?
Document Image Text and Non-Text blocksText, Picture and Background blocks
4/31

DIS Important Applications
Image and text database retrieval
Automated documents reading and processing
Digital documents storing
5/31

DIS MethodsTop-down Methods: Classic top-down techniques are based on the Run Length Smoothing (RLS) algorithm and projection profiles. After the document image is smoothed with RLS, projection profiles is used to split the document into blocks.
Bottom-down Methods: Bottom-up methods group small components (starting with pixels as connected components) into successively larger components until all regions are identified in the image.
Texture-based Methods: Texture-based methods use the observation that texts in images have distinct textural properties that distinguish them from the background.
6/31

Wavelet-based DIS MethodsThe wavelet transform, originally developed in the mid 80’s, is a signal analysis tool that provides a multi-resolution decomposition of an image .
Document Image DWT Sub-bands at first level
LL LH
HL HH
HH
LL
LH
HL
7/31

Wavelet-based DIS Methods
Document Image DWT Sub-bands at first level
or
Texture Feature Extraction Classification
K-means Clustering(Kundu and Acharya 2002)
(G. Lee et al. 2007)
Fisher Classifier(Y. Sheng et al. 2004)(S. Kumar et al. 2007)
Class Labels
LL LH
HL HH
8/31

K-means ClusteringAssuming samples should be divided into C clusters, algorithm is as follows: First, select the appropriate C as the initial centers. Second, for each sample, calculate the distances between this sample and centers. It belongs to the cluster from which the distance is min. Third, calculate the average of all samples that belongs to the same cluster as the new cluster center. Finally, calculate the error between the new cluster centers and the original center, if it is less than the value given beforehand, then the process finished. Otherwise go into the second step.
9/31

Fisher Classifier-1For a feature vector X, the Fisher classifier projects X onto one dimension Y in direction W:
The Fisher criterion finds the optimal projection direction W0 by maximizing the ratio of the between-class scatter to the within-class scatter, which benefits the classification:
10/31

Fisher Classifier-2The optimal projection direction is the eigenvector of the corresponding to its largest eigenvalue. For a two-class classification problem, we do not need to calculate the eigenvectors of It is shown that the optimal projection direction is:
Let Y1 and Y2 be the projections of two classes and let E[Y1] and E[Y2] be the means of Y1 and Y2, respectively. Suppose E[Y1] > E[Y2], then the decision can be made as:
11/31

The DWT has been shown to be an optimal representation of one-dimensional 1D piece-wise smooth signals. However, there are limitations of the separable DWT:
lack of shift invariance
Limited Angular Resolution
The DT-DWT was proposed to overcome shift variance and directionality limitations of the DWT while maintaining the perfect reconstruction property with limited redundancy.
The Dual-Tree DWT-1
12/31
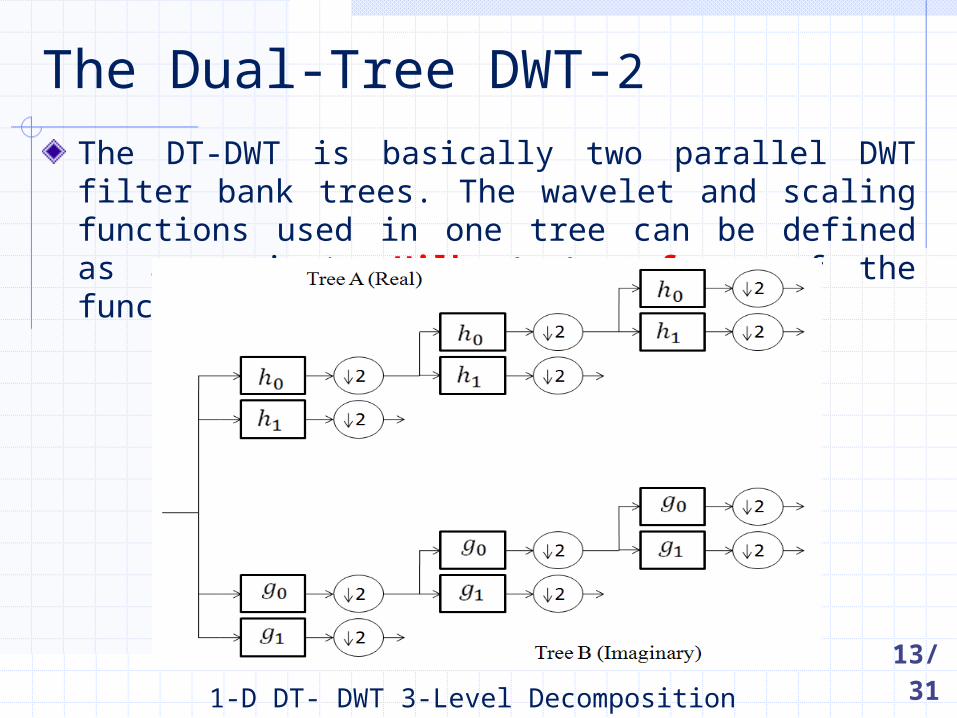
The DT-DWT is basically two parallel DWT filter bank trees. The wavelet and scaling functions used in one tree can be defined as approximate Hilbert transforms of the functions in the other tree .
The Dual-Tree DWT-2
1-D DT- DWT 3-Level Decomposition Filter Bank 13/31
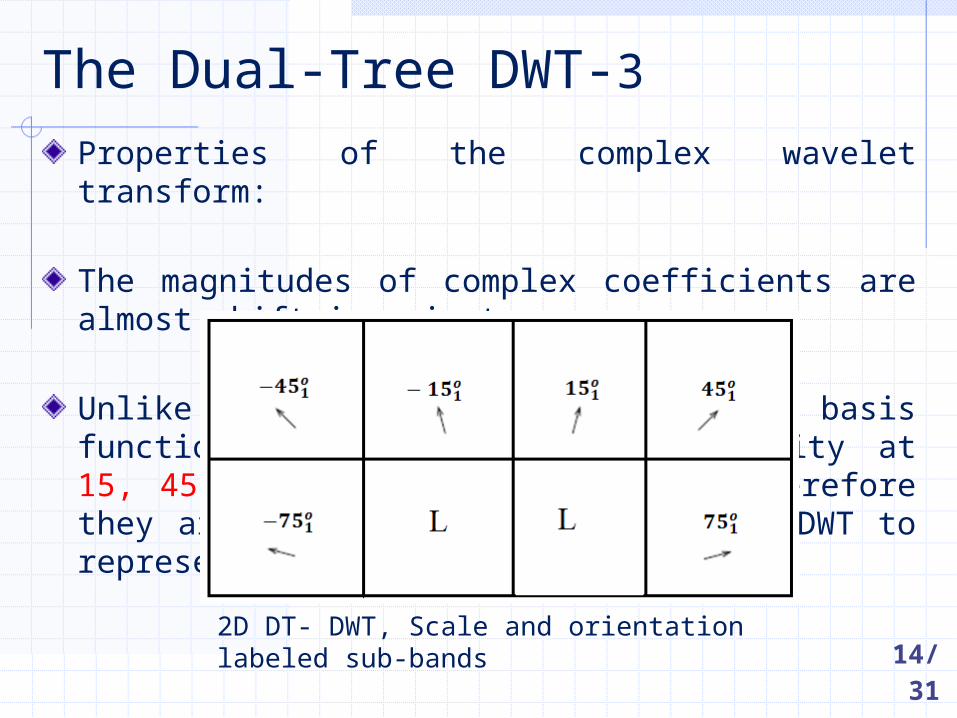
Properties of the complex wavelet transform:
The magnitudes of complex coefficients are almost shift invariant.
Unlike the orthogonal DWT, the basis functions have directional selectivity at 15, 45, 75, -75 –45,-15 degrees; therefore they are a more efficient tool than DWT to represent line or curve singularities.
The Dual-Tree DWT-3
2D DT- DWT, Scale and orientation labeled sub-bands
14/31

The Dual-Tree DWT of the document image:
Document Image
DT-DWT Sub-bands at first levelDT-DWT Sub-bands at second level
-15 +15-45 +45
-75 +75
-45 -15 +15 +45
-75 +75
The Dual-Tree DWT-4
15/31

Now the inverse DT-DWT is applied to generate The Gradient image while the low-frequency sub-bands are vanished.
DT-DWT Sub-bands at second levelThe Gradient Image
The Gradient Image
16/31

In the gradient image:
Text regions have large local variations.
Backgrounds are continuous tone low frequency regions with
monotonous features although mixed with noise.
Images are continuous tone regions falling in between text and
background.
In order to enhance the gradient image information, we use two
texture features to capture and magnify these variations making
the input image appropriate for the classification step.
Feature Extraction-1
17/31

The first feature calculates local entropy and the second one calculates local range of the gradient image:
Local Range Local Entropy
Feature Extraction-2
18/31
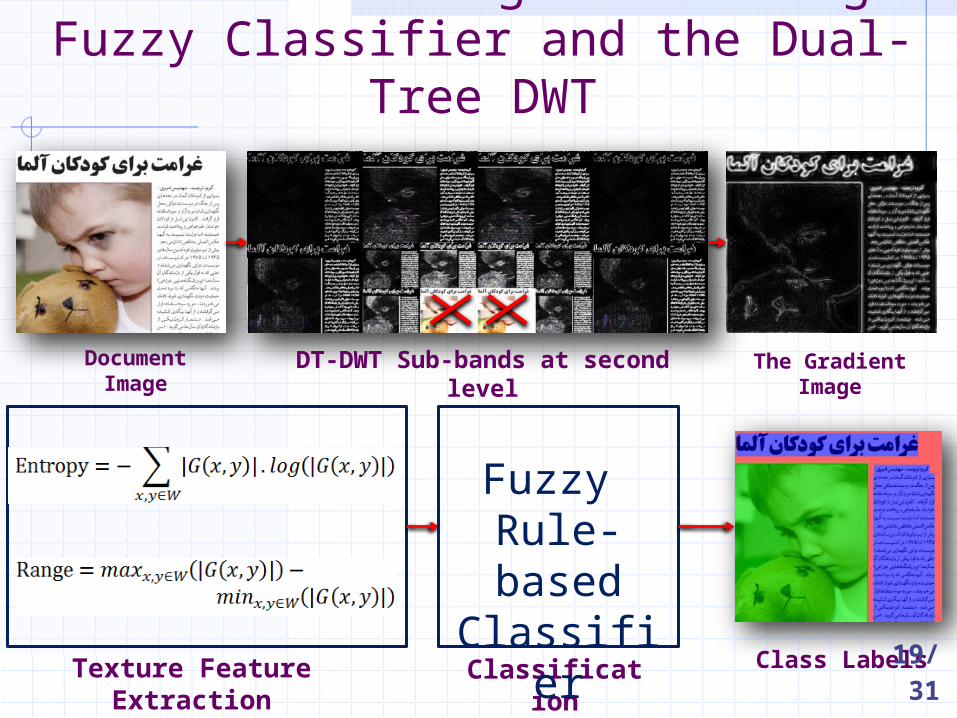
The New DIS algorithm using Fuzzy Classifier and the Dual-Tree DWT
Document Image DT-DWT Sub-bands at second level The Gradient Image
Texture Feature Extraction Classification
Fuzzy Rule-based Classifier
Class Labels19/31

Fuzzy rule-based classifier-1In this step we utilize a fuzzy rule-based classifier for classification of document image to:
Text and Non-Text classes
Text, Picture and Background classes
This classifier can be constructed by specifying classification rules as linguistic rules:
.
.
.
20/31

Fuzzy rule-based classifier-2Each linguistic value is represented by a membership function. Having the values of membership function, the firing strength of the rules are calculated as:
.
.
.
we use the train image and the confidence value of each class to assign class label for each rule:
21/31

Fuzzy rule-based classifier-3Specifying weight to rules has a great effect on fuzzy rule-based classifier performance, and the most proper definition of the rule weight would be as following (H. Ishibuchi 2005):
On the other hand, we also obtain a support for each rule:
Finally we utilize the fuzzy rules which their confidence and support are more than a predefined minimum value.
22/31

Fuzzy rule-based classifier-4In our test, the number of final rules is 5 that we have mentioned as sample below:
R1: IF F1 is large AND F2 is large THEN class is Text
R2: IF F1 is large AND F2 is small THEN class is Picture
R3: IF F1 is medium AND F2 is large THEN class is Text
R4: IF F1 is medium AND F2 is small THEN class is Picture
R5: IF F1 is small THEN class is Background
After finding the firing strength of each rule, the output of classifier is obtained:
23/31

Post-ProcessingAfter completion of classification, there may existed some misclassified pixels. In order to solve this problem, we have used a morphological reconstruction, namely region filling.
Before Post-Processing After Post-Processing 24/31

Evaluation Methods and ResultsSeveral images with different properties have been used in this section to demonstrate the performance of the proposed algorithm. The scanned images are taken from different websites.
25/31

Text/non-text classification results-1
Results of three different classification methods:
DWT+K-means DWT+Fisher
DT-DWT+Fuzzy DT-DWT+Fuzzy+Post-Processing 26/31
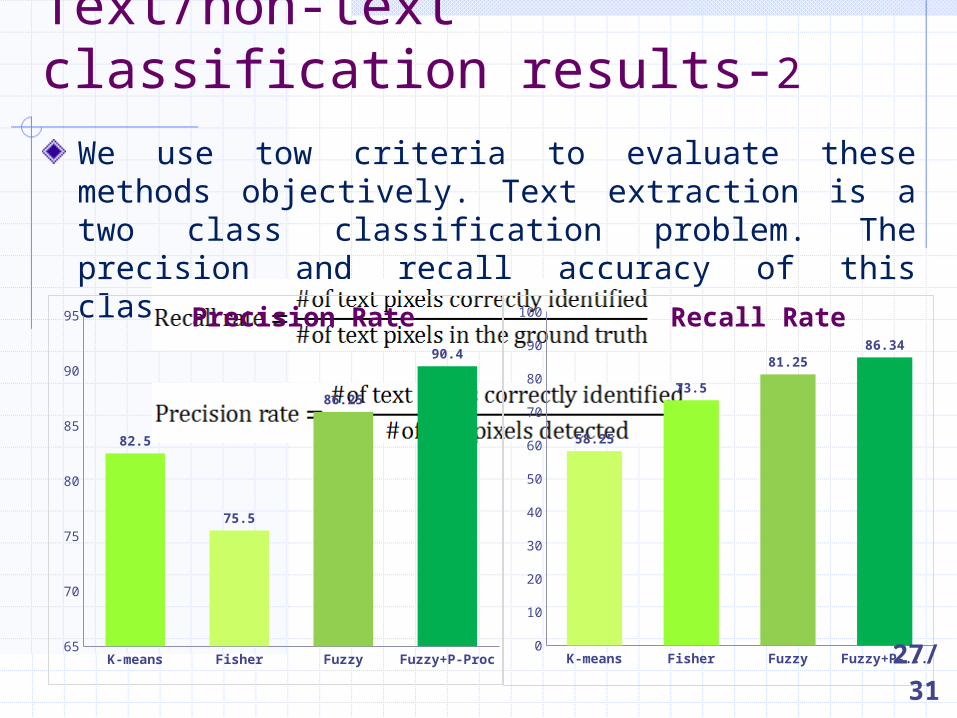
Text/non-text classification results-2
We use tow criteria to evaluate these methods objectively. Text extraction is a two class classification problem. The precision and recall accuracy of this classification is computed as:
K-means Fisher Fuzzy Fuzzy+P-Proc65
70
75
80
85
90
95
82.5
75.5
86.25
90.4
K-means Fisher Fuzzy Fuzzy+P-Proc0
10
20
30
40
50
60
70
80
90
100
58.25
73.581.25
86.34Precision Rate Recall Rate
27/31

Results of three different classification methods:
Text/picture/background classification results-1
DWT+Fisher
DT-DWT+Fuzzy DT-DWT+Fuzzy+Post-Processing 28/31

We performed other experiments to objectively evaluate these methods. Accuracy measurement is defined as follow:
Text/picture/background classification results-2
Fisher Fuzzy Fuzzy+P-Proc0
10
20
30
40
50
60
70
80
90
100
60.25
83.5 86.75
Accuracy
29/31

In this paper, we have presented a new algorithm for locating the text part based on textural attributes using the dual-tree DWT and fuzzy rule-based classifier. The proposed feature extraction method is simple, effective with low computational requirements. We have applied our algorithm on several document images with different characteristics and complex backgrounds. The obtained results are promising. Considering the input image as a three-class set and classifying it into text/picture/background components is another paper’s novelty.
Conclusion
30/31

Thanks for your attention
31/31





























