Embed Size (px)
Citation preview


Stalled is worse than dead -
combating stability issues
caused by stalling region
serversMikhail Antonov
Software Engineer @ Facebook

Building Reliable Systems from
Unreliable Components
Failure Modes
Fail-stopRealistic
misbehaviorByzantine

Simple (fail-stop) failures are
simple• Quorums
• Heartbeats / timeouts
• Multiple replicas
• WAL replay
• Etc

Simple (fail-stop) failures are
simple
Active-backup masters
WAL replay
HDFS QJM + ZKFC
HDFS block replicas

Byzantine failures
• … aren’t “real world”
• When did you see one last time?
• Preventable
• Don’t usually warrant engineering solution

Evolving beyond fail-stop mode


Easy, right?

What do we do?

What do we do now?

What do we look for?
• Latencies are up
• RPC time-in-queue is up
• RPC handlers thread pool is maxed out
• RPC call queues are clogged
• Machine load is up

Real-world HBase stalls

Why would we stall?
• GC
• RPC scheduling
• Metrics subsystem
• Memory sizing and management
• Linux kernel quirks
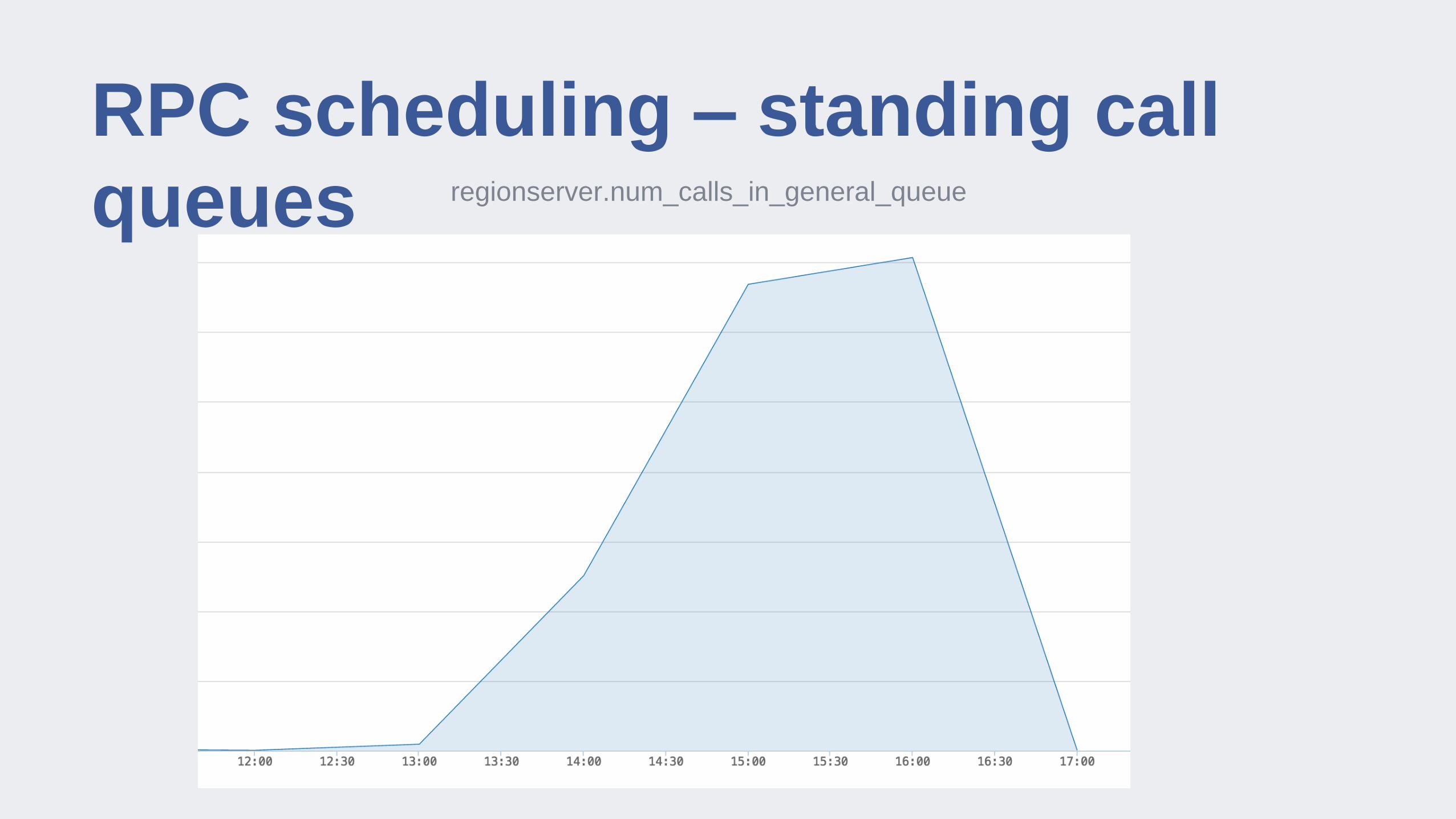
RPC scheduling – standing call
queues regionserver.num_calls_in_general_queue

Long call queues…
• … eat up memory
• ... Increase latency
• … make you do the work noboby needs anymore
• … cause waves of retries
Metrics
UselessOverhead

Metrics
• HBASE-15222
• Histograms can use a lot of resources
• Saw very high CPU util, most of it in metrics

Memory sizing
• Overhead of being part of advanced infrastructure
• Overhead of having neighbors
• There’s no free memory, only reclaimable one
• Abrupt performance degradations

Memory-related configurations
• Memory allocations tips and tricks• Up your /proc/sys/vm/min_free_kbytes
• Take care of page cache• HDFS drop-cache-behind

Kernel-related stalls
• Memory / pagecache issues on older kernels
• Hard / soft lockups (and Kernel can have bugs, too!)

What can we do about those stalls?

Solving from outside

Solving from outside
• Focus on elaborate tooling around
• Converge “stalled” problem to “fail-stop”
• External heuristic-based remediations

Solving from inside
• Focus on the root causes rather than symptoms
• Most complete context, most real-time metrics
• Classify root causes and reach accordingly
• Problems above you (hot region, traffic spikes)
• Problem below you (OS / Hardware) -

Solving from inside (top-down)
• “Stalled node” as a first-class citizen
• Distributing “cluster health map” across all nodes
• Centralized decision-making

Solving from inside (bottom-up)
• Local decisions based on most real-time metrics
• Better load shedding at RPC level

Takeaways
• Fail-stop failures are largely addressed
• Byzantine failures are notional
• Intermediate failures are real and challenging
• Let’s knock them out!






























