Embed Size (px)
Citation preview

ゆるふわJava8入門
株式会社ビズリーチ大内允介

Who Are You?
大内 允介 (おおうち まさゆき)
30歳 Webエンジニア
某メーカー系SIer 5年半
→ビズリーチ 約1年
Java大好きエンジニア

Java’s History
・Java5 (2004/05〜2009/10)
・Java6 (2006/12〜2013/02)
・Java7 (2011/07〜2015/04)
・Java8 (2014/03〜2017/09予定)
・Java9 (2017/03〜予定)

What’s Java8?
public void java8() { Stream.of("A001", "B001", "AB001", "BA001") .filter(e -> e.startsWith("A")) .forEach(System.out::println);}
Question
文字列リスト(A001, B001, AB001, BA001)の中から、
「A」で始まる文字列のみを抽出してコンソールに出力する。
Answer
public void java7() { List<String> strs = Arrays.asList("A001", "B001", "AB001", "BA001"); for (String str : strs) { if (str.startsWith("A")) { System.out.println(str); } }} 1年前の僕「えっ、何これ怖い。。。」

Lambda式
メソッド参照
Stream
Optional
What’s Java8?
Comparator<String> comparator = (a, b) -> { Integer.compare(a.length(), b.length()); };
Consumer<String> consumer = System.out::println;
List<String> newList = list.stream().filter(e -> e.length() >= 3).collect(Collectors.toList());
Optional<String> langCd = getConfigValue("langCd");return langCd.orElse("en");

Today’s Goal

Today’s Goal
・Java8の目玉「ラムダ式」「Stream」の基礎が分かる。
・ラムダ式(->)が怖くなくなる。
・メソッド参照(::)が怖くなくなる。
・Streamを触ってみたい、という気になる。
・なんとなくJavaが好きになる。

What’s Lambda?

() -> { 処理 } // 引数が0個(str) -> { 処理 } // 引数が1個str -> { 処理 } // 引数が1個の場合、括弧の省略可
(str, n) -> { 処理 } // 引数が2個の場合
( 引数 ) -> System.out.println(str);( 引数 ) -> { System.out.println(str); return n;}
What’s Lambda?
Comparator<String> comparator = (a, b) -> { Integer.compare(a.length(), b.length()); };
基本文法: ( 引数 ) -> { 処理 }
Comparator<String> comparator = new Comparator<String>() { @Override public int compare(String a, String b) { return Integer.compare(a.length(), b.length()); }};
慣れるまでは一度Java7で実装してから
ラムダ式に直すようにすると覚えやすいかも?IDE頼みという手も。

What’s Functional Interface?ラムダ式やメソッド参照の代入先になれるインターフェース。
実装が必要な抽象メソッドが1つだけ。
関数インターフェース メソッドシグネチャ
Function<T, R> R apply(T)
Consumer<T> void accept(T)
Supplier<R> R get()
Predicate<T> boolean test(T)
Comparator<T> int compare(T, T)

Function<List<String>, String> function = (list) -> list.isEmpty() ? null : list.get(0);
List<String> list = Arrays.asList("A", "B", "C");String firstElement = function.apply(list);System.out.println(firstElement);
What’s “Function”?引数を一つとって戻り値を返す関数型インターフェース
関数インターフェース メソッドシグネチャ 引数型 → 戻り値型
Function<T, R> R apply(T) T → R
BiFunction<T, U, R> R apply(T, U) T × U → R
A

What’s “Consumer”?Consumerは消費者。引数を受け、戻り値なしの処理を行うインターフェース。
値を返さないので、基本的に副作用を起こす目的で使用する。
返り値のない(返り値が void の) Functionと思えばOK。
関数インターフェース メソッドシグネチャ 引数型 → 戻り値型
Consumer<T> void accept(T) T → ()
BiConsumer<T, U> void accept(T, U) T × U → ()
Consumer<String> hoge = string -> System.out.println("hoge : " + string);Consumer<String> fuga = string -> System.out.println("fuga : " + string);Consumer<String> consumer = hoge.andThen(fuga);consumer.accept("piyo");
hoge : piyofuga : piyo
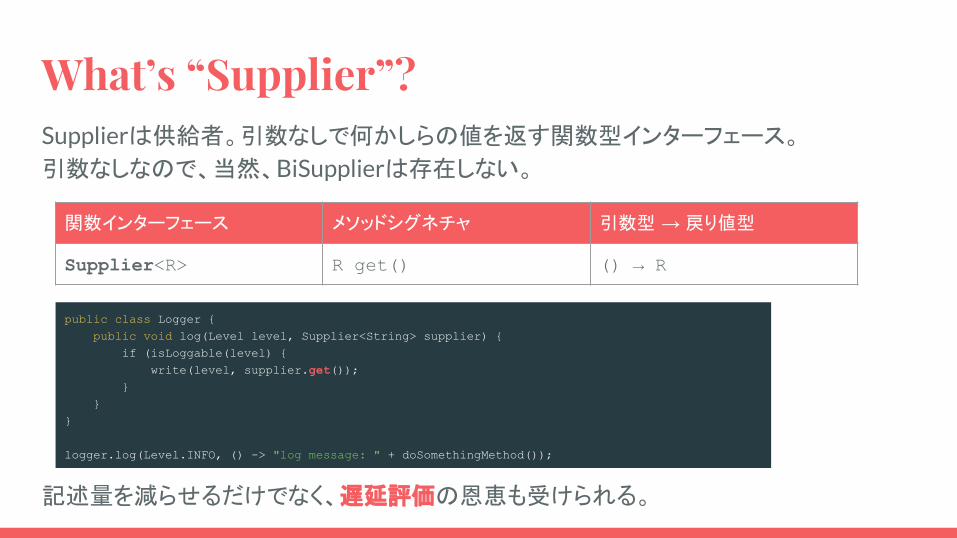
What’s “Supplier”?Supplierは供給者。引数なしで何かしらの値を返す関数型インターフェース。
引数なしなので、当然、BiSupplierは存在しない。
関数インターフェース メソッドシグネチャ 引数型 → 戻り値型
Supplier<R> R get() () → R
public class Logger { public void log(Level level, Supplier<String> supplier) { if (isLoggable(level) { write(level, supplier.get()); } }}
logger.log(Level.INFO, () -> "log message: " + doSomethingMethod());
記述量を減らせるだけでなく、遅延評価の恩恵も受けられる。

What’s “Predicate”?Predicateは判定を行う為の関数型インターフェース。
引数を一つとり、boolean型の引数を返す。
関数インターフェース メソッドシグネチャ 引数型 → 戻り値型
Predicate<T> boolean test(T) T → boolean
BiPredicate<T,U> boolean test(T, U) T × U → boolean
Predicate<String> isUpperCase = string -> string.matches("[A-Z]+");Predicate<String> isAlphabet = string -> string.matches("[a-zA-Z]+");Predicate<String> predicate = isAlphabet.and(isUpperCase);System.out.println(predicate.test("HOGE"));System.out.println(predicate.test("hoge"));
truefalse

Lambda’s Benefit ?記述の簡潔化
Comparator<String> comparator = new Comparator<String>() { @Override public int compare(String a, String b) { return Integer.compare(a.length(), b.length()); }};
ラムダ式を前提に導入された新機能(Stream etc.)
Comparator<String> comparator = (a, b) -> { Integer.compare(a.length(), b.length()); };
public void java8() { Stream.of("A001", "B001", "AB001", "BA001") .filter(e -> e.startsWith("A")) .forEach(System.out::println);}

What’s Method Reference?

BiFunction<List<String>, String, Boolean> function = (list, str) -> list.add(str);function.apply(list, "A001");
BiFunction<List<String>, String, Boolean> function = List<String>::add;function.apply(list, "A001");
What’s Method Reference?関数型インターフェースの変数にメソッドそのものを代入することが出来る。
class GenericsExample { static <T> void method(T arg) { }
static void test() { Consumer<String> c = GenericsExample::<String> method; }}
戻り値の型を明示的に指定したい場合
基本文法: ClassName::methodName ※()がつかないことに注意

IntFunction<List<String>> factory = ArrayList::new;List<String> array = factory.apply(10);
What’s Constructor Reference?コンストラクターも関数型インターフェースの変数に代入することが出来る。
IntFunction<List<String>> factory = (int n) -> new ArrayList<>(n);List<String> array = factory.apply(10);
基本文法: ClassName::new ※()がつかないことに注意

What’s Stream?

What’s Stream ?配列やCollectionなどの集合に対して、何らかの処理(変換や集計)を行う。
// 本を検索
List<Book> books = bookSearcher.select(condition);
List<String> titles = books.stream() .filter(book -> book.getPublishYear() > 2001) // 2001年以降に発行された本で絞込み
.sorted(Comparator.comparing(Book::getPublishYear)) // 発行年で並び替え
.map(Book::getTitle) // 本のタイトルのみを抽出
.collect(Collectors.toList()); // リストに変換
Question
本(Book)の検索結果から、発行年(publishYear)が2001年以降の本を抽出し、
本のタイトル(title)の文字列リストを作る。また、タイトルは発行年順に並び替えること。
Answer

What’s Stream ?// 発行年で並び替え
Collections.sort(books, new Comparator<Book>() { @Override public int compare(Book book1, Book book2) { return book1.getPublishYear() - book2.getPublishYear(); }};// 2001年以降に発行された本で絞込み & 本のタイトルのみを抽出
List<String> titles = new ArrayList<>();for (Book book : books) { if (book.getPublishYear() >= 2001) { titles.add(book.getTitle()); }}
List<String> bookNames = books.stream() .filter(book -> book.getPublishYear() >= 2001) // 2001年以降に発行された本で絞込み
.sorted(Comparator.comparing(Book::getPublishYear)) // 発行年で並び替え
.map(Book::getTitle) // 本のタイトルのみを抽出
.collect(Collectors.toList()); // リストに変換
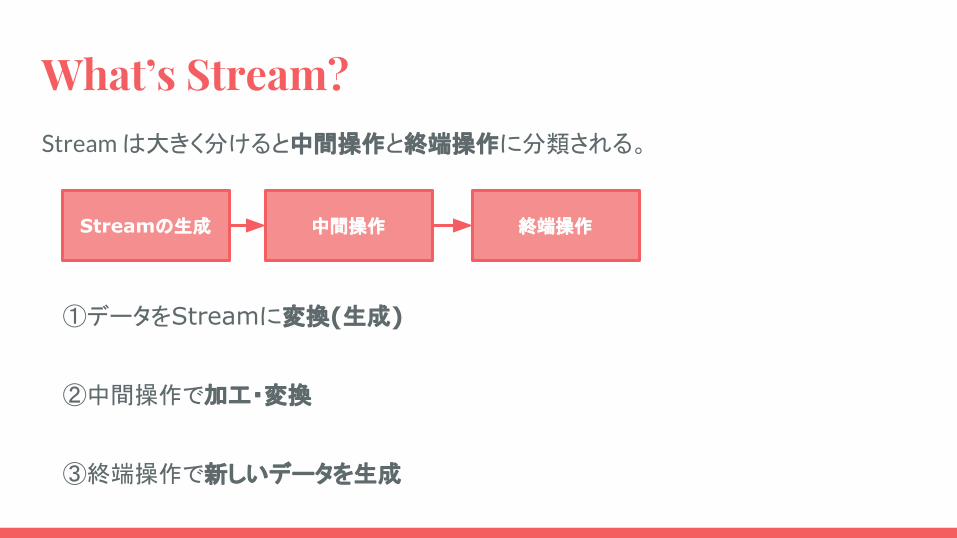
What’s Stream?Stream は大きく分けると中間操作と終端操作に分類される。
Streamの生成 中間操作 終端操作
①データをStreamに変換(生成)
②中間操作で加工・変換
③終端操作で新しいデータを生成

Create “Stream”List, Map, Array など様々なデータ形式からStreamを生成可能。
List<String> list = Arrays.asList("hoge", "fuga", "bar");Stream<String> stream = list.stream();
Stream<String> stream = Arrays.stream(new String[] {"hoge", "fuga"});
Stream<Map.Entry<Integer, String>> stream = map.entrySet().stream();
Builder<String> builder = Stream.builder();Stream<String> stream = builder.add("hoge").add("fuga").build();
Stream<String> stream = Stream.empty();
Stream<String> stream = Stream.of("hoge", "fuga", "bar", "foo");

try (Stream<String> stream = Files.lines(Paths.get("test.txt"))) { stream.forEach(System.out::println);} catch (IOException e) { // 例外処理
}
Stream<Integer> stream = Stream.iterate(1, i -> i + 1).limit(100); // UnaryOperator を引数にとる
// => 1, 2, 3, … , 100
Stream<String> stream = Stream.generate(() -> "test").limit(5); // Supplier を引数にとる
// => "test", "test", "test", "test", "test"
Create “Stream”
IntStream stream = IntStream.rangeClosed(1, 100);// => 1, 2, 3, … , 100
テストデータ作りにも便利(実務ではあまり使わないかも?)
ファイル操作も便利

Intermediate OperationStreamのデータ加工を行います。
終端操作時にまとめて実行される。つまり、実際にループが行われるのは基本的に1回。
メソッド名 メソッドシグネチャ
map Stream<R> map(Function<T, R>) 変換(1:1)
filter Stream<T> filter(Predicate<T>) 絞り込み
flatMap Stream<R> flatMap(Function<T, Stream<R>) 変換(1:N)
distinct Stream<T> distinct() 重複要素の集約
limit Stream<T> limit(long) 要素数の指定
skip Stream<T> skip(long) 要素のスキップ
sorted Stream<T> sorted(Comparator<T>) 並び替え
peek Stream<T> peek(Consumer<T>) 状態確認(デバッグ目的)

mapメソッドは1:1のデータの変換処理を行う中間操作。 めっちゃよく使う。
引数を1つだけ受け取り、すべての要素に対し同じ処理を行い、戻り値を返します。
What’s “map”?
List<String> bookTitles = books.stream() .map(Book::getTitle) // 本のタイトルのみを抽出
.collect(Collectors.toList()); // リストに変換
List<String> bookTitles = books.stream() .map(book -> { return book.getTitle(); } .collect(Collectors.toList());
List<String> prefixList = books.stream() .map(Book::getTitle) // タイトルを取得
.map(title -> title.substring(0,1)); // 1つ目のmapの処理結果を元に頭文字をとる
.collect(Collectors.toList()); // リストに変換

What’s “filter”?filterメソッドはPredicate<T>を引数に取り、Streamから条件に一致するものを抽出する中間操作。
これもめっちゃよく使う。
Set<String> bookTitles = books.stream() .map(Book::getTitle) .filter(title -> title.startsWith("A")) // 本のタイトルが「A」で始まるもののみを抽出
.collect(Collectors.toSet()); // リストに変換
List<String> prefixList = books.stream() .filter(book -> book.getPublishYear() >= 2001) // 発行年が2001年以降の本のみを抽出
.map(Book::getTitle) .filter(title -> title.startsWith("A")) // 本のタイトルが「A」で始まるもののみを抽出
.collect(Collectors.toList()); // リストに変換

flatMapメソッドはFunction<T, Stream<R>>を引数に取り、要素TからStream<R>を生成する。
Collectionの中にネストしたCollectionがある場合に使える。
What’s “flatMap”?
final int totalStringCount = books.stream() .flatMap(book -> book.getPages().stream()) .collect(Collectors.summingInt(Page::getStringCount));
@Dataclass Book { String title; Integer publishYear; List<Page> pages;}@Dataclass Page { String content; Integer stringCount;}

Terminal OperationStreamの全データを一括で別のデータに変換する。
終端操作は1つのStreamに1度しか実行できない。(再利用すると例外が発生する。)
メソッド名x メソッドシグネチャ
collect R collect(Collector<T,A,R>) 集合化
forEach void forEach(Consumer<T>) 副作用
anyMatch/allMatch/noneMatch boolean anyMatch(Predicate<T>) 条件判定
findAny / findFirst Optional<T> findAny() 任意/最初の要素
count long count() 要素数
max / min Optional<T> max(Comparator<T>) 最大/最小の要素

What’s “collect”?
List<Book> books = selectBookList(condition);
List<Integer> bookIds = books.stream() .map(Book::getId) .collect(Collectors.toList());
Streamを元に新しいデータ構造に変換する操作。めっちゃ使う。
Map<Integer, Book> bookMapByPublishedYear = books.stream() .collect(Collectors.toMap(Book::getPublishedYear, book -> book));
long booksCount = books.stream().collect(Collectors.counting());long allStockCount = books.stream().collect(Collectors.summingInt(Book::getStock));
Stream joinedTitle = books.stream() .map(Book::getTitle) .collect(Collectors.joining(", ", "[[", "]]"));// => "[[ABN-10987012, SDX-36107012, YIC-7844401]]"

What’s “forEach”?従来のfor文にあたるもの。めっちゃ使う。
books.forEach(book -> { book.setDeleteFlg(true); bookUpdater.update(book); System.out.println("[updated] : " + book.getId()));}
処理件数をカウントすることができません。
break; continue; ができない。
欠点:
int count = 0;books.forEach(book -> { count++; // <= ここでcountはスコープ外なのでコンパイルエラー
System.out.println(book.getId()));}

Stream’s Benefit ?・ソートや抽出処理が混ざったfor文が簡潔に書ける。
・並列処理が簡単に使える。(Stream#parallelStream()
List<String> bookNames = books.stream() .filter(book -> book.getPublishYear() >= 2001) // 2001年以降に発行された本で絞込み
.sorted(Comparator.comparing(Book::getPublishYear)) // 発行年で並び替え
.map(Book::getTitle) // 本のタイトルのみを抽出
.collect(Collectors.toList()); // リストに変換
List<String> bookNames = books.parallelStream() .filter(book -> book.getPublishYear() >= 2001) // 2001年以降に発行された本で絞込み
.sorted(Comparator.comparing(Book::getPublishYear)) // 発行年で並び替え
.map(Book::getTitle) // 本のタイトルのみを抽出
.collect(Collectors.toList()); // リストに変換
→とはいえ、苦手なこともあるので、既存の拡張for文はまだ現役です。

Summary

Summary
public void java8() { Stream.of("A001", "B001", "AB001", "BA001") .filter(e -> e.startsWith("A")) .forEach(System.out::println);}
Answer
Question
文字列リスト(A001, B001, AB001, BA001)の中から、
「A」で始まる文字列のみを抽出してコンソールに出力する。
public void java8() { Stream.of("A001", "B001", "AB001", "BA001") .filter(e -> e.startsWith("A"))}
public void java8() { Stream.of("A001", "B001", "AB001", "BA001")}
public void java8() {}
「ラムダ式」「Stream」の基礎が分かるようになりましたか?

Summary
・Java8の目玉「ラムダ式」「Stream」の基礎が分かる。
・ラムダ式(->)が怖くなくなる。
・メソッド参照(::)が怖くなくなる。
・Streamを触ってみたい、という気になる。
・なんとなくJavaが好きになる。

















![Projeto OpenJDK [Java8]](https://img.pdfslide.net/doc/110x75/558e69591a28ab0a668b45ba/projeto-openjdk-java8.jpg)










