Embed Size (px)
Citation preview

R 入門編
2016年11月19日AITC女子会 「データ分析勉強会第6回&交流会」資料 1.01版(配布用)
1

はじめに 本資料作成に当たり本日の講師が所属している日科技連
SQiPコミュニティ 関東メトリクス・データ分析勉強会のR関係資料を参考にしています。https://sites.google.com/site/kantometrics/home
上記勉強会サイトに記載されている情報ならびに資料の内容を一部または全面的
に引用していますので、資料の著作権は部分的に上記勉強会サイトの作成者に
帰属します。
ただし、一部の画像等の著作権は原著作者が所有しています。
また、この資料の情報や資料を用いて行う一切の行為についていかなる責任も負い
ません。被った被害・損失に対してもいかなる場合でも一切の責任を負いません。
2

"R"とは? R言語の慣用的な呼び方
統計解析向け言語・開発実行環境
基礎的な統計学の知識が必要
CRANからの一元的配信◦ The Comprehensive R Archive Network
CRANの読み方は「しーらん」派と「くらん」派でわかれるそうです。
◦ オープンソース、マルチプラットフォーム対応
3

“R”の利用環境について Rを単体起動した”R Console”はCUIで初学者が使用するのは熟練がいりそう
利用者のタイプに合わせてRの利用環境を拡張するのがおススメ
Rのプログラミング知識より手っ取り早くデータを統計的に分析したい方向けR Commander が使いやすいです
Rのプログラミングを本格的にやりたいR Studio の使用がお勧めです
4

R + R Commander
R言語プログラミングの知識が無くてもできます
Rを使って統計の基礎を復習しながら簡単なデータ分析をしてみよう
5
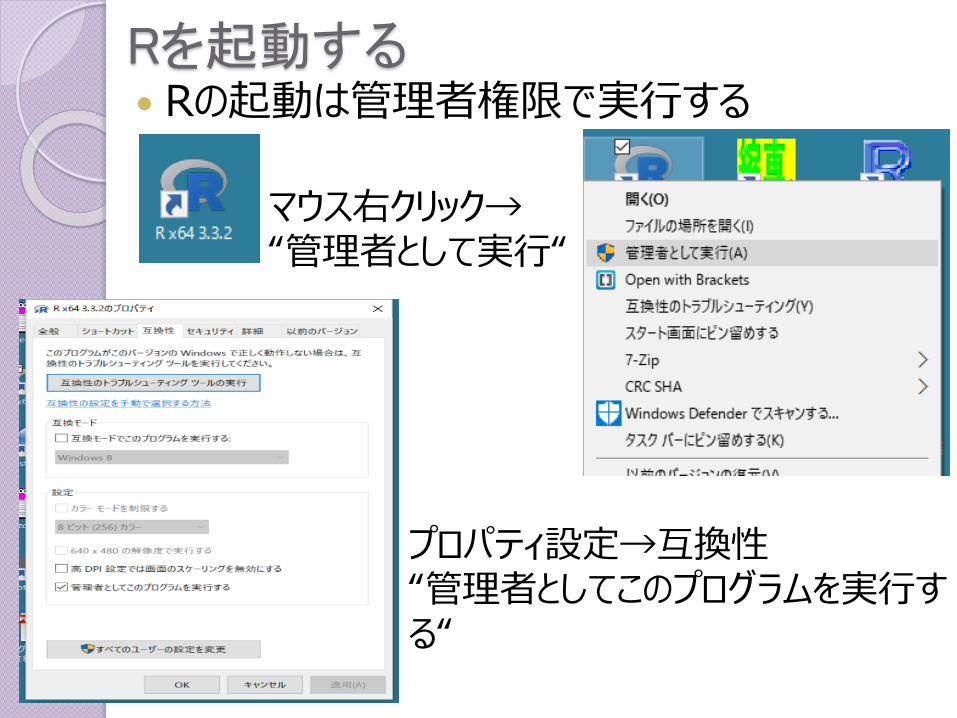
Rを起動する Rの起動は管理者権限で実行する
マウス右クリック→“管理者として実行“
6
プロパティ設定→互換性“管理者としてこのプログラムを実行する“
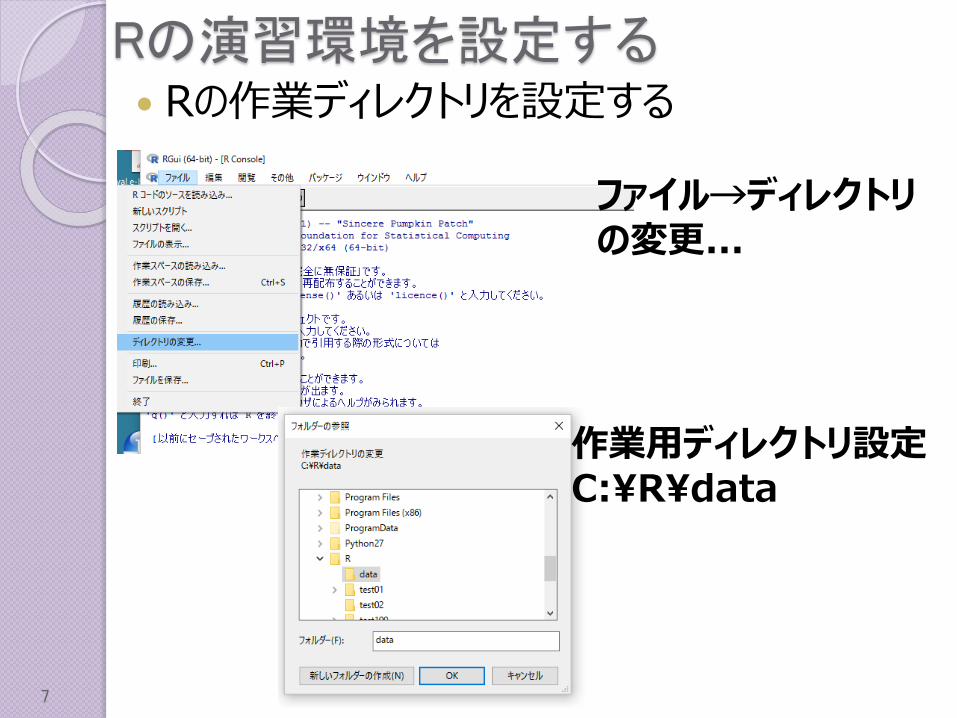
Rの演習環境を設定する Rの作業ディレクトリを設定する
7
ファイル→ディレクトリの変更...
作業用ディレクトリ設定C:¥R¥data
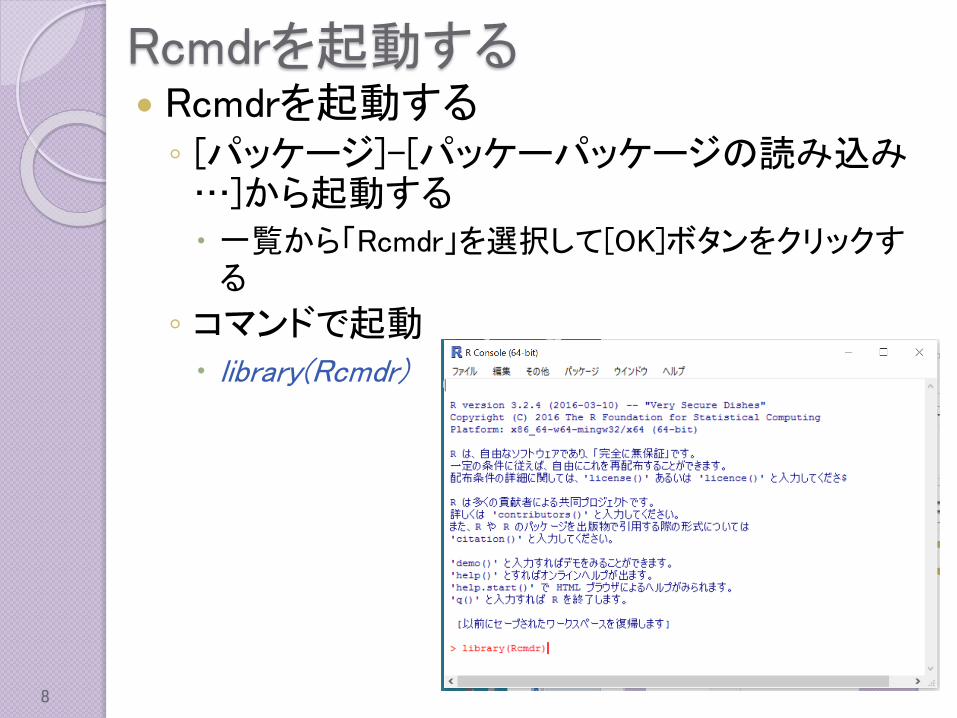
Rcmdrを起動する Rcmdrを起動する◦ [パッケージ]-[パッケーパッケージの読み込み…]から起動する 一覧から「Rcmdr」を選択して[OK]ボタンをクリックする
◦ コマンドで起動 library(Rcmdr)
8

Rcmdrを起動する Rcmdrを再起動する◦ 間違ってRcmdrを終了させてしまったら Commander()
Rcmdrを解放する◦ あんまり使うことはないと思いますが… detach("package:Rcmdr", unload=TRUE)
9

Rcmdrを起動する
10

Rcmdrのメニュー概説 [データ]◦ データセットを扱うためのメニュー
[統計量]◦ 統計量算出、検定、分析、モデル適合(回帰分析)
[グラフ]◦ 各種グラフの描画
[モデル]◦ モデル適合結果に対する診断等
[分布]◦ 各種分布に基づく計算、描画
[ツール]◦ R/Rcmdr用のパッケージ選択、オプション設定
11

Rcmdrのメニュー概説 [統計量] [要約] 各種統計量の算出、および、統計量に対する検定
[分割表]分割表に対する検定
[平均]平均値に対する検定
[比率]比率に対する検定
[分散]分散に対する検定
[ノンパラメトリック検定]
◦ ノンパラメトリックな検定
[次元解析]
◦ 主成分分析、因子分析、クラスタ分析等の多変量解析
[モデルへの適合]
◦ 回帰分析関係
統計量とは?(Wikipedia)要約統計量:標本の性質を表すもの順序統計量:大小の順番で表すもの検定統計量:検定に利用するための
これらを算出するのが[統計量]メニュー青色のメニューは全て検定に関わるもの
12
標本から仮説の正しさを判定することを統計的仮説検定

Rcmdrのメニュー概説 [グラフ]
[色パレット]
◦ 利用する色を変更する
[インデックスプロット…]
[ヒストグラム…]
[密度推定…]
[幹葉表示…]
[箱ひげ図…]
[QQプロット…]
----------
[散布図…]
[散布図行列…]
› [折れ線グラフ…]
› [条件付き散布図]
› [平均値のプロット…]
› [ドットチャート]
----------
› [棒グラフ…]
› [円グラフ…]
----------
› [3次元グラフ…]
› [グラフをファイルに保存]
13

R Commanderのサンプルデータを使ってデータ分析
14

利用するデータセットについて データセット iris(Edgar Anderson's Iris Data)
◦ 別名:フィッシャーのあやめのデータ
北米に生息する菖蒲の萼片と花弁に関するデータ
◦ データ項目はSepal(しーぱる)と
Petal(ぺたる)
Sepal.Length : 萼片の長さ
Sepal.Width : 萼片の幅
Petal.Length : 花弁の長さ
Petal.Width : 花弁の幅
Species : 菖蒲の種類(品種)
setosa
versicolor
virginica
出典:http://biostor.org/reference/11559
Sepal
Petal
15

データの読み込み Rcmdrでサンプルデータを読み込む
◦ [データ]-[パッケージ内のデータ]-[アタッチされたパッケージからデータセットを読み込む…]を実行する
◦ 「dataset」-「iris」を選択し[OK]ボタンを押下する
◦ または、[データセット名を入力]欄に「iris」と入力して[OK]ボタンを押下する
◦ または
data(iris)
16
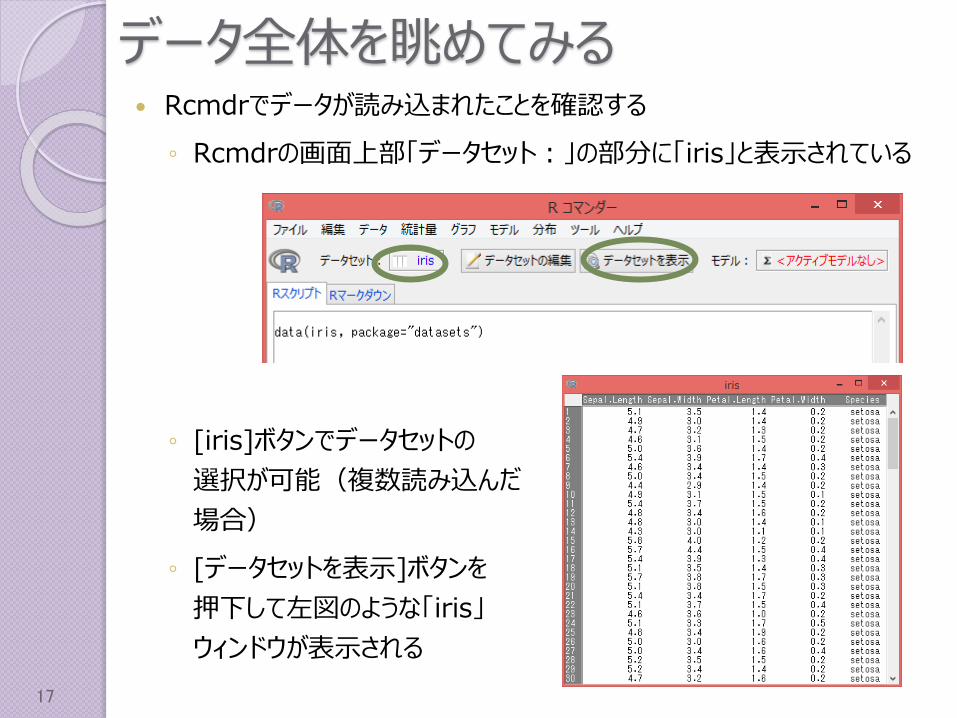
データ全体を眺めてみる Rcmdrでデータが読み込まれたことを確認する
◦ Rcmdrの画面上部「データセット:」の部分に「iris」と表示されている
◦ [iris]ボタンでデータセットの
選択が可能(複数読み込んだ
場合)
◦ [データセットを表示]ボタンを
押下して左図のような「iris」
ウィンドウが表示される
17
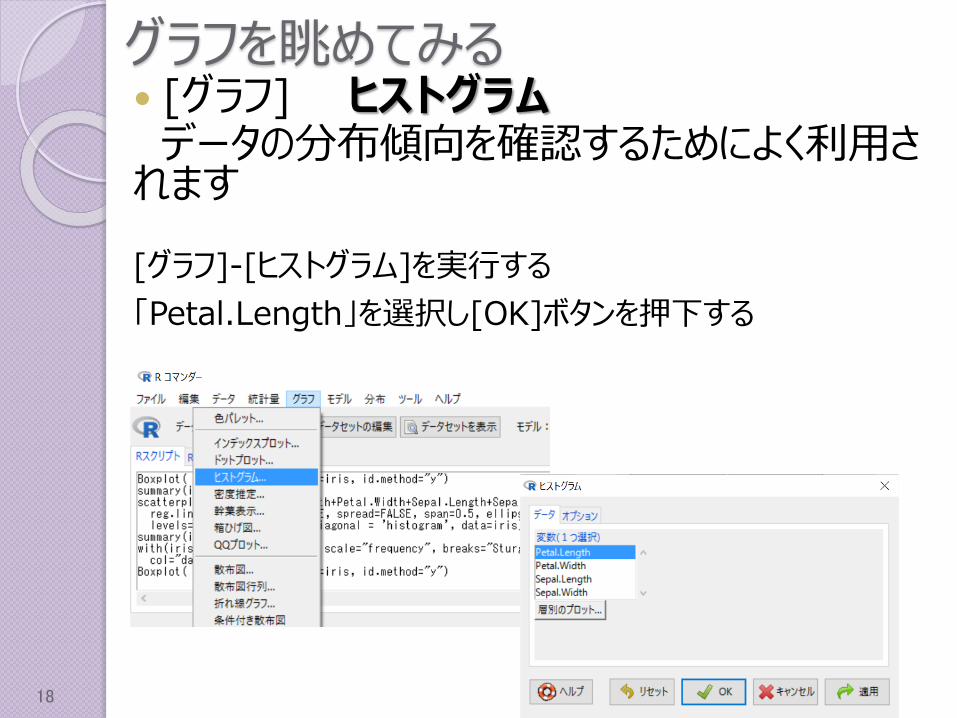
グラフを眺めてみる [グラフ] ヒストグラムデータの分布傾向を確認するためによく利用されます
[グラフ]-[ヒストグラム]を実行する
「Petal.Length」を選択し[OK]ボタンを押下する
18
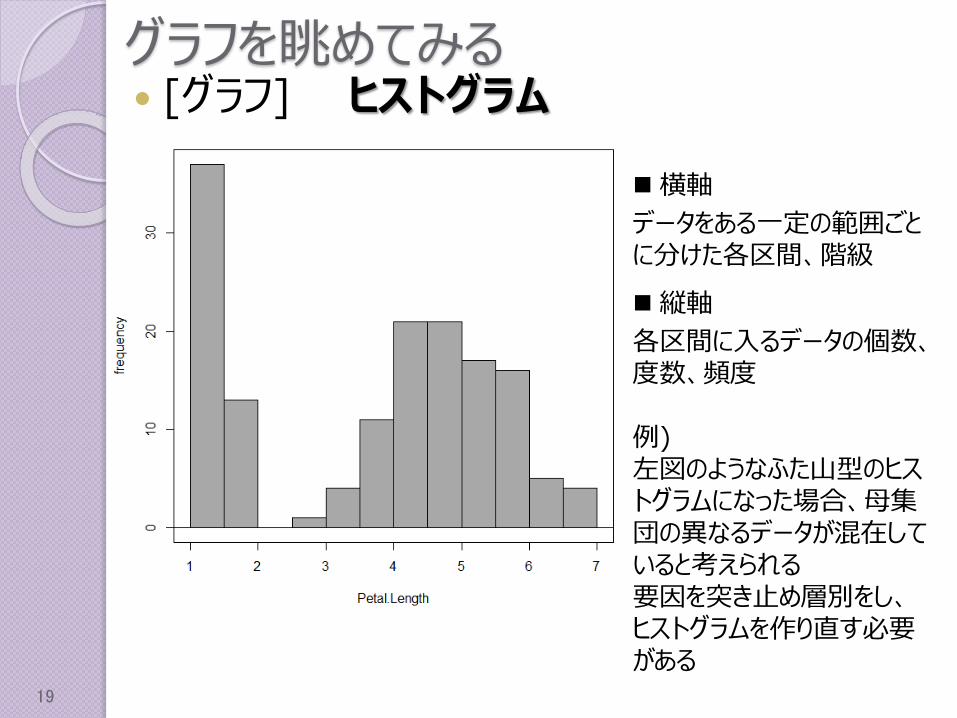
グラフを眺めてみる [グラフ] ヒストグラム
横軸
データをある一定の範囲ごとに分けた各区間、階級
縦軸
各区間に入るデータの個数、度数、頻度
例)左図のようなふた山型のヒストグラムになった場合、母集団の異なるデータが混在していると考えられる要因を突き止め層別をし、ヒストグラムを作り直す必要がある
19
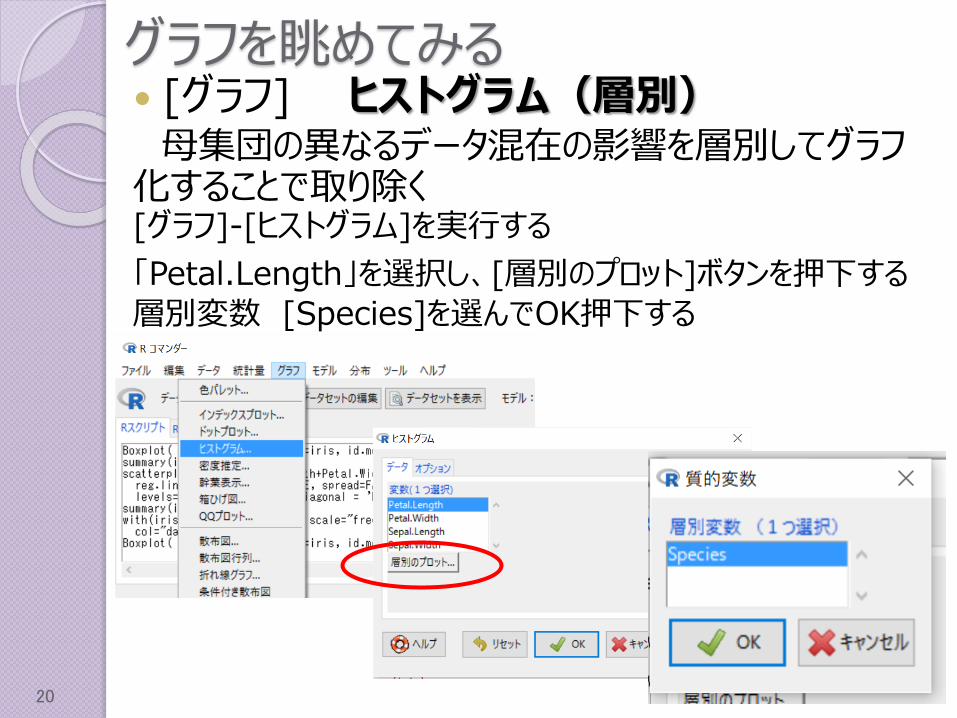
グラフを眺めてみる [グラフ] ヒストグラム(層別)母集団の異なるデータ混在の影響を層別してグラフ化することで取り除く[グラフ]-[ヒストグラム]を実行する
「Petal.Length」を選択し、[層別のプロット]ボタンを押下する層別変数 [Species]を選んでOK押下する
20

グラフを眺めてみる [グラフ] ヒストグラム(層別)
層別=種類別に分けてグラフからデータの傾向を眺める
21

グラフを眺めてみる [グラフ] 箱ひげ図(boxplot)◦ データの分布傾向(バラツキ)を確認するためによく利用されます
22
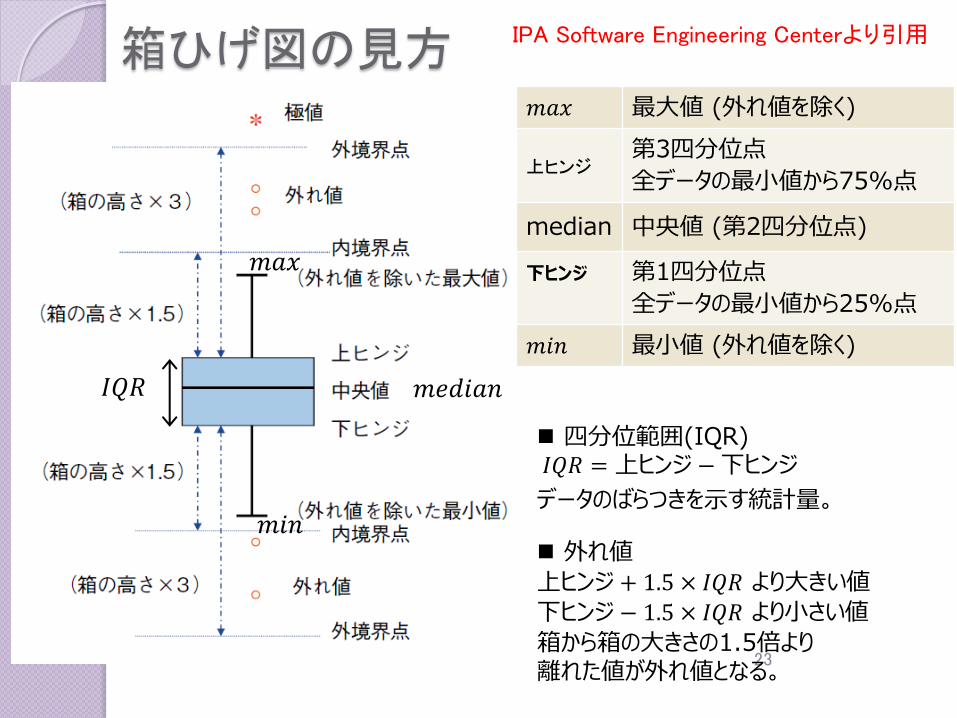
箱ひげ図の見方
23
𝑚𝑎𝑥 最大値 (外れ値を除く)
上ヒンジ第3四分位点
全データの最小値から75%点
median 中央値 (第2四分位点)
下ヒンジ 第1四分位点
全データの最小値から25%点
𝑚𝑖𝑛 最小値 (外れ値を除く)
𝑚𝑎𝑥
四分位範囲(IQR)𝐼𝑄𝑅 =上ヒンジ −下ヒンジ
データのばらつきを示す統計量。
外れ値
上ヒンジ+ 1.5 × 𝐼𝑄𝑅 より大きい値
下ヒンジ− 1.5 × 𝐼𝑄𝑅 より小さい値
箱から箱の大きさの1.5倍より離れた値が外れ値となる。
𝑚𝑖𝑛
𝐼𝑄𝑅 𝑚𝑒𝑑𝑖𝑎𝑛
IPA Software Engineering Centerより引用

グラフを眺めてみる [グラフ] 箱ひげ図(層別)
【簡単な演習】層別=種類別に分けてグラフからデータの傾向を眺めて
「何がグラフから読み取れるか考えてみてください」
24
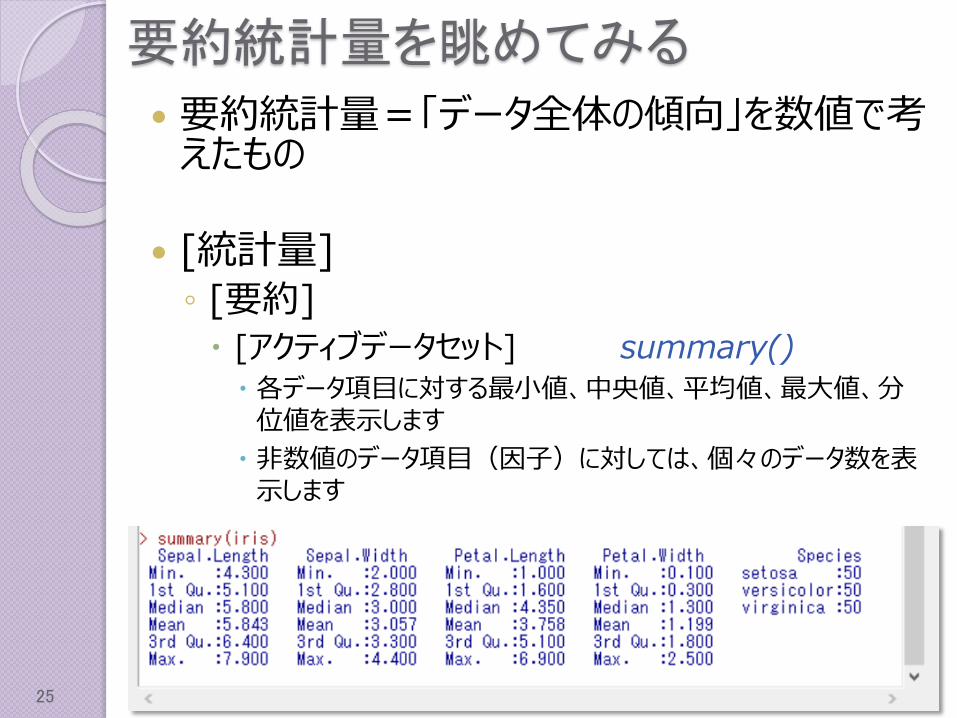
要約統計量を眺めてみる
要約統計量=「データ全体の傾向」を数値で考えたもの
[統計量]◦ [要約] [アクティブデータセット] summary()
各データ項目に対する最小値、中央値、平均値、最大値、分位値を表示します
非数値のデータ項目(因子)に対しては、個々のデータ数を表示します
25

要約統計量を眺めてみる
要約統計量=「データ全体の傾向」を数値で考えたもの
最小値→第1四分位→中央値→平均値→第3四分位→最大値→
26

要約統計量を眺めてみる
[統計量][要約] [数値による要約] numSummary()
任意のデータ項目に対する平均値、標準偏差、平均の標準誤差、分位範囲、変動係数、歪度、尖度の中から任意の項目を表示します
27

中心位置を推測するための統計量
平均
𝑥 =𝑥1 + 𝑥2 + ⋯+ 𝑥𝑛
𝑛=
𝑖=1𝑛 𝑥𝑖
𝑛
メディアン (中央値) 𝑥
データを大きさの順に並べて
データが奇数個ならば中央の値
データが偶数個ならば中央の2つの値の平均値
最頻値
データの中で最も頻繁に出現する値
後述するヒストグラムにおいて、棒状のグラフが最も高い (頻度の最
も多い) 区間の中心値
28
メディアン (中央値) や最頻値は異常値や外れ値の影響を受けにくい。このような統計量はロバスト (頑健) であるといいます
代表値と呼ばれ、たくさんのデータをひとつの数値で表す

さらにグラフを眺めてみる [グラフ] 散布図2変数のデータの同士の関連性を確認するためによく利用されます2種類のデータを横軸と縦軸に取り、データを点でプロットしたグラフで、
2種類のデータの相関を観察するために作成します
29

さらにグラフを眺めてみる [グラフ] 散布図「Petal.Length」と「Petal.Width」を選択し[OK]ボタンを押下する
30

さらにグラフを眺めてみる [グラフ] 散布図
31

さらにグラフを眺めてみる [グラフ] 散布図(層別)
【簡単な演習】層別=種類別に分けてグラフからデータの傾向を眺めて「何がグラフから読み取れるか考えてみてください」
32
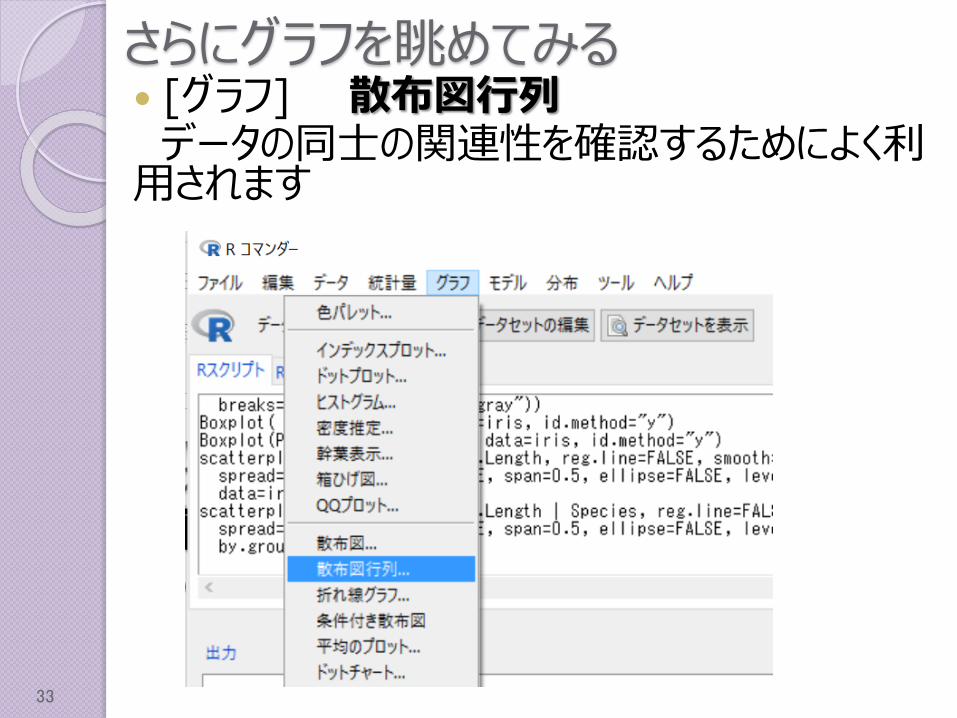
さらにグラフを眺めてみる [グラフ] 散布図行列データの同士の関連性を確認するためによく利用されます
33

さらにグラフを眺めてみる [グラフ] 散布図行列「Petal.Length」,「Petal.Width」,「Sepal.Length」,「Sepal.Width」を
選択し[OK]ボタンを押下する
34

さらにグラフを眺めてみる [グラフ] 散布図行列 散布図行列
このグラフの意味は、多数の変数を組み合わせて散布図にしたものです。
この散布図行列を見れば、どのデータの組み合わせで「正の相関・負の相関・相関なし」のどれに該当するのかを一目でざっくりわかると思います。
もちろんこれだけで何か統計的な結論を出せるわけではありませんが、詳細な分析をするデータを絞り込む際に活用します。
35
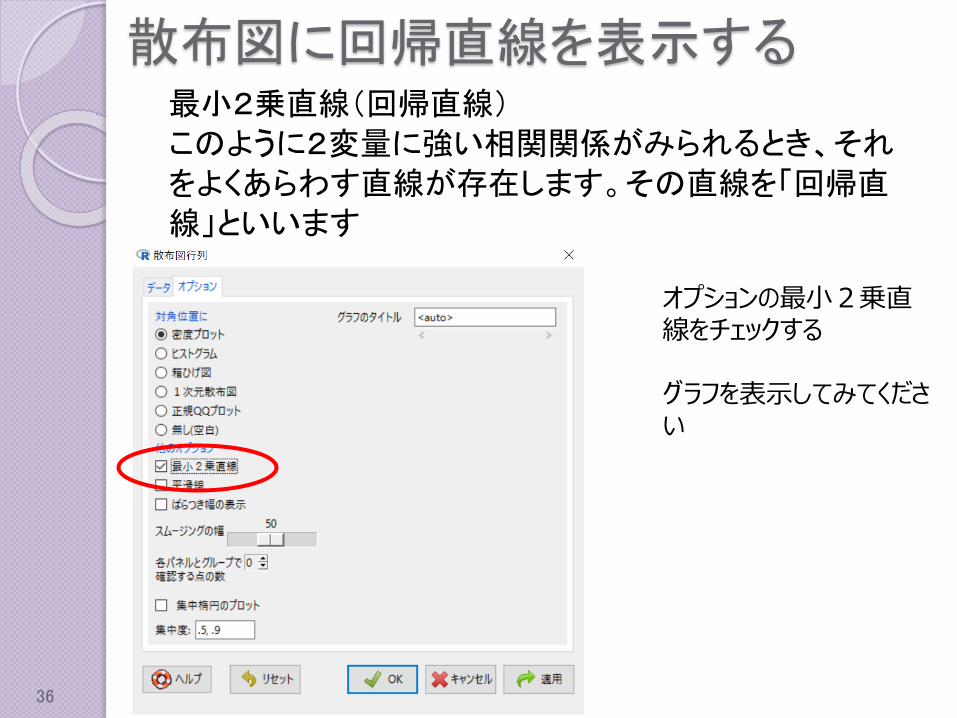
散布図に回帰直線を表示する最小2乗直線(回帰直線)このように2変量に強い相関関係がみられるとき、それをよくあらわす直線が存在します。その直線を「回帰直線」といいます
オプションの最小2乗直線をチェックする
グラフを表示してみてください
36

グラフと要約統計量を眺めて傾向からデータの本来持つ性質についての可能性(仮説)を考えてみる
グラフ 要約統計量
仮説
37

ヒストグラムで身近な「代表値 ~ 平均・中央値・最頻値 ~」を眺めてみる 厚生労働省 国民生活基礎調査を見てみよう
http://www.mhlw.go.jp/toukei/list/20-21kekka.html
38
平成7年から比較してどんなことが言えるのでしょうか?考えてみてください

R Commanderへ外部のデータを使ってデータ分析
39

利用するデータセットについて データセット football01.xlsx
◦ 日刊スポーツから引用
◦ http://www.nikkansports.com/soccer/japan/member/jp-
member01.html
◦データ項目は A代表、五輪代表、U-20代表、U-17代表名前、位置、背番号、所属、生年月日、年齢、身長、体重、代表(A代表、五輪代表、U-20代表、U-17代表)
40

利用するデータセットについて データセット football01.xlsx
41
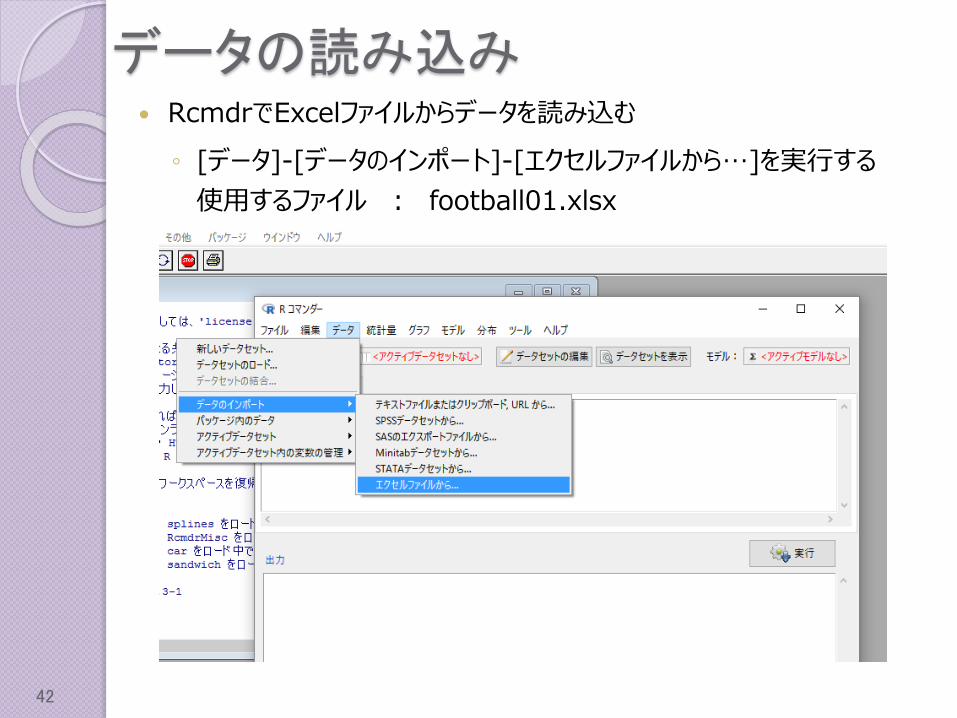
データの読み込み RcmdrでExcelファイルからデータを読み込む
◦ [データ]-[データのインポート]-[エクセルファイルから…]を実行する
使用するファイル : football01.xlsx
◦
42
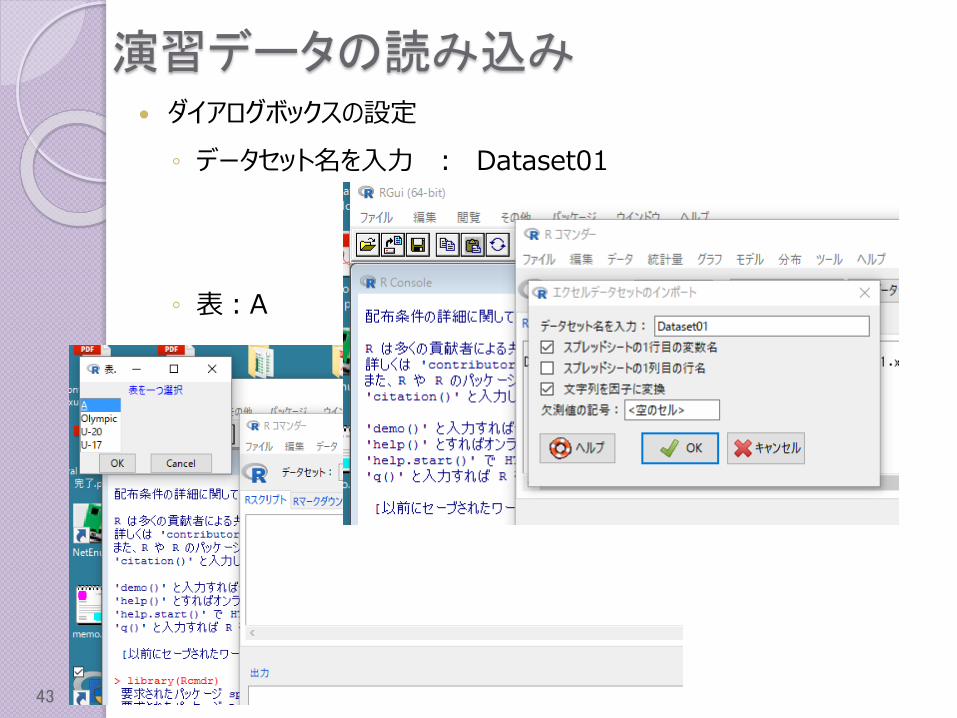
演習データの読み込み ダイアログボックスの設定
◦ データセット名を入力 : Dataset01
◦ 表:A
◦
43
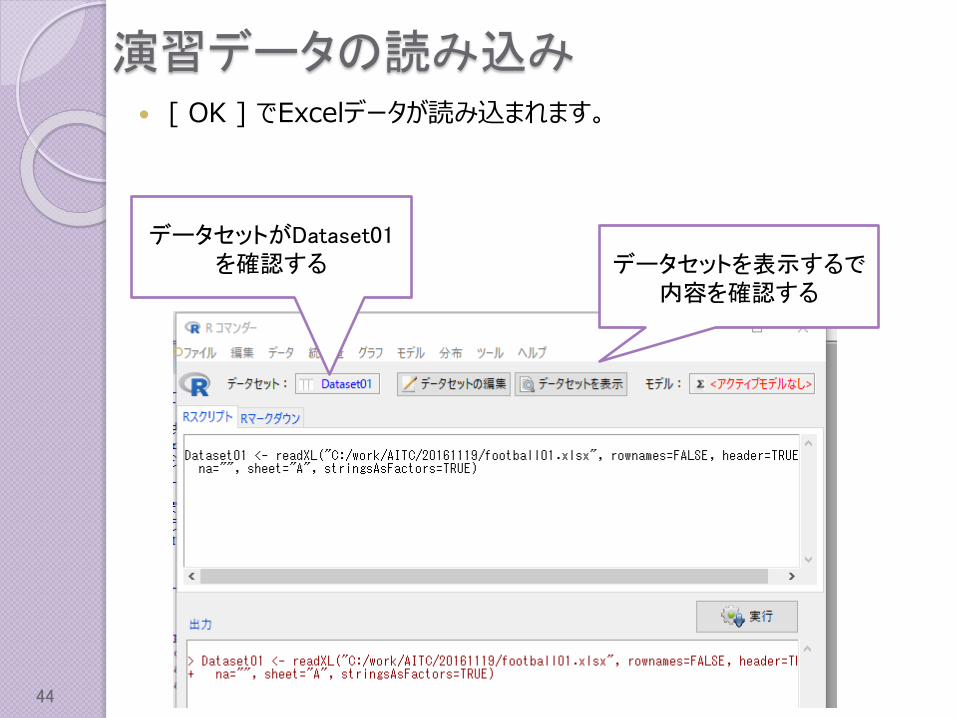
演習データの読み込み [ OK ] でExcelデータが読み込まれます。
◦
データセットを表示するで内容を確認する
データセットがDataset01を確認する
44

データ分析の基本をやってみよう
1. データから最初にグラフを書いてみるヒストグラム、箱ひげ図
2. 要約統計量を見てみるこれによってデータの全体的傾向をつかんでみる
3. 散布図または散布図行列で関連性を確認してみる
4. 傾向からデータの本来持つ性質についての可能性(仮説)を考えてみる
45

Rで最頻値を求めてみよう
46
C:¥R¥data¥mode1.txtファイルをメモ帳やテキストエディタで開きます
テキストデータを全部選択してRcommanderのRスクリプトというウィンドウへ貼り付けます

Rで最頻値を求めてみよう
47
Rスクリプトウィンドウでコマンドの行にカーソル位置を合わせてCTRL+Rで1ラインづつ実行します。

平均を利用したデータの散らばり具合
分散散らばりの程度を指標化した数値
標準偏差分散の平方根を取って元の単位に戻した数値散らばりの程度を指標化した数値
48

平均を利用したデータの散らばりの指標 - 標準偏差
49
分散
分散の平方根

50
平均を利用したデータの散らばりの指標 - 標準偏差
平均
標準偏差5.818
平均 178.48CM
標準偏差5.818CM
「データが平均値の周辺にどのくらいの広がりや散らばりを持っているか」ということを表す統計量です。

51
平均を利用したデータの散らばりの指標 - 標準偏差
Rcommanderで確認してみましょう

52
平均を利用したデータの散らばりの指標 - 標準偏差
標準偏差は、平均値と合わせて見ることによって、データを正しく把握することができます。なぜ「平均値」だけでは、正しく把握できないのでしょうか?
りんご
品種 平均重量 100グラム単価 売価
①アップルペン 200グラム 150円 200円
②あっぽーぺん 200グラム 100円 200円
あなたは、200グラムのりんごが良く売れる果物屋さんを経営している立場で、PPAP効果でりんごブーム到来のため10個仕入れて売るなら、どちらを仕入れますか?
どちらも平均200グラムで色も味も同じとします。
単価の安い「あっぽーぺん」仕入れることにしました。
正しい判断でしょうか?

53
平均を利用したデータの散らばりの指標 - 標準偏差
注文してから標準偏差のデータを仕入れ先いただきました
りんご
品種 平均重量 100グラム単価 売価 重さ標準偏差
①アップルペン 200グラム 150円 200円 5
②あっぽーぺん 200グラム 100円 200円 100
①アップルペン バラツキの範囲 195グラム~205グラム
②あっぽーぺん バラツキの範囲 100グラム~300グラム
届いた②のりんごは 100グラムが5個 300グラムが5個でした。200グラムのりんごが良く売れるのに200グラムぐらいのリンゴはゼロ

54
中央値利用したデータの散らばりの指標 –パーセンタイル
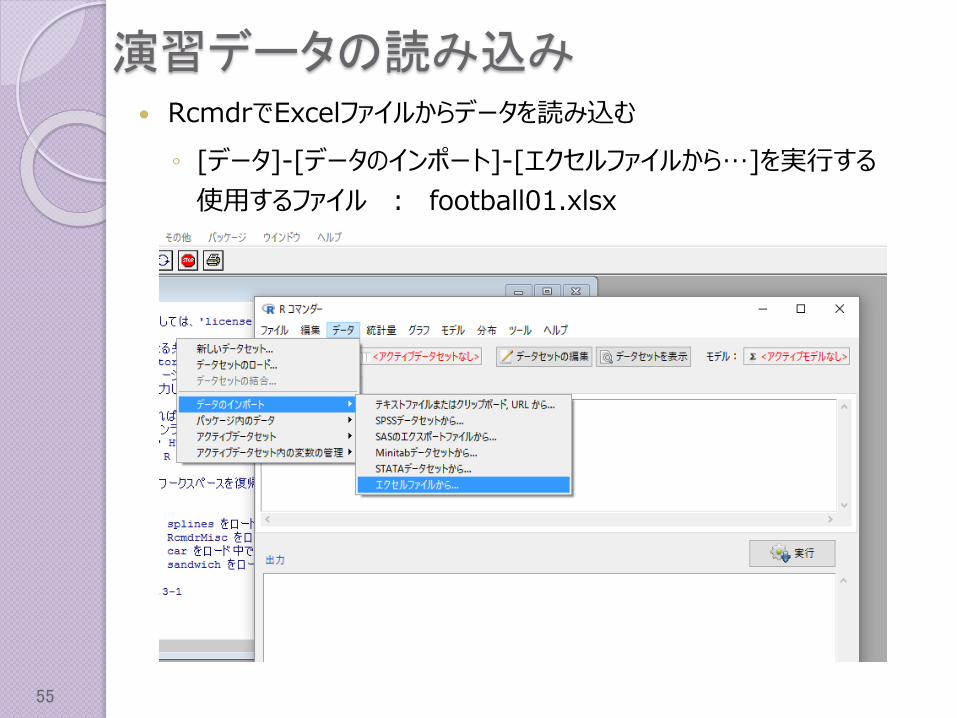
演習データの読み込み RcmdrでExcelファイルからデータを読み込む
◦ [データ]-[データのインポート]-[エクセルファイルから…]を実行する
使用するファイル : football01.xlsx
◦
55
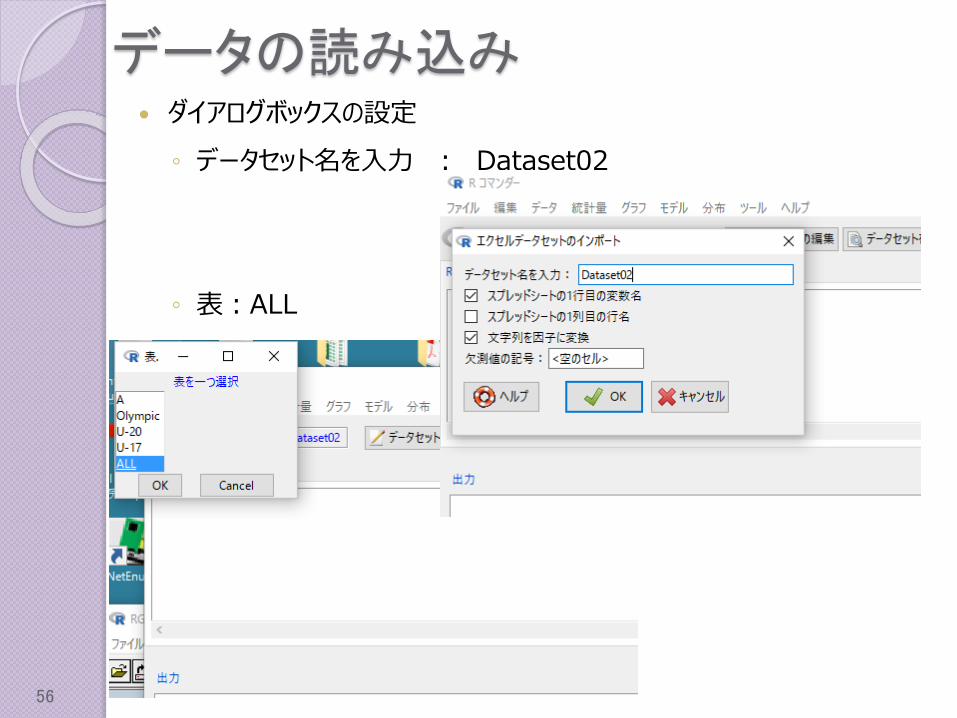
データの読み込み ダイアログボックスの設定
◦ データセット名を入力 : Dataset02
◦ 表:ALL
◦
56

データ分析の基本をやってみよう
1. データから最初にグラフを書いてみるヒストグラム、箱ひげ図を層別に確認してみる
2. 要約統計量を見てみるこれによってデータの全体的傾向をつかんでみる
3. 散布図または散布図行列で関連性を確認してみる
4. 傾向からデータの本来持つ性質についての可能性(仮説)を考えてみる
57

58
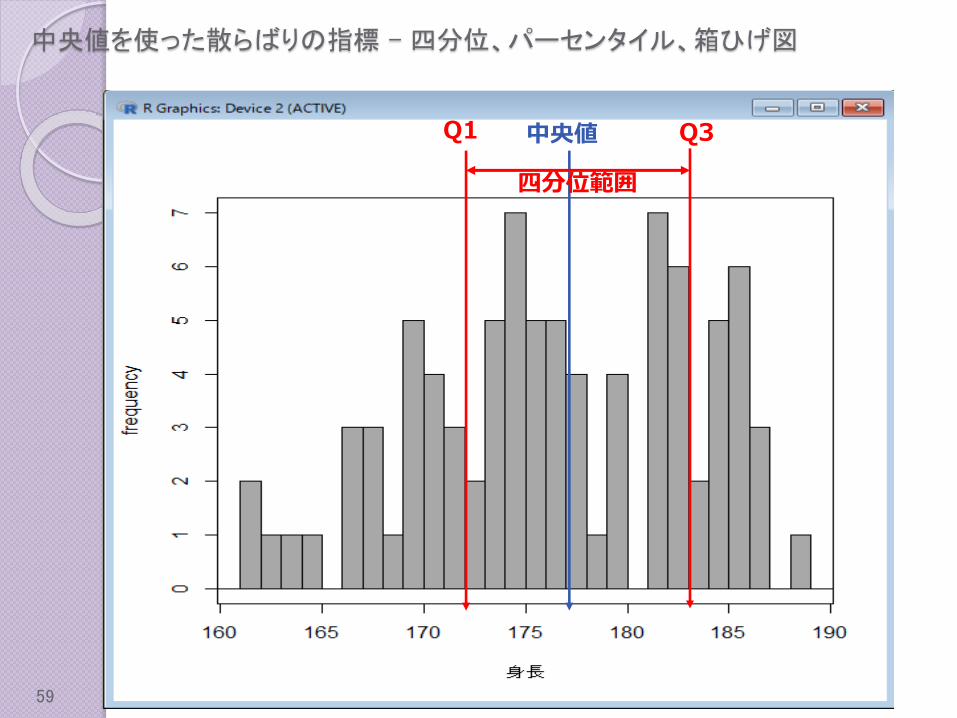
中央値を使った散らばりの指標 – 四分位、パーセンタイル、箱ひげ図
Rcommanderで要約統計量を確認する
身長の中央値は?
身長の範囲は?
59
中央値を使った散らばりの指標 – 四分位、パーセンタイル、箱ひげ図
中央値
四分位範囲
Q1 Q3

60
中央値を使った散らばりの指標 – 四分位、パーセンタイル、箱ひげ図
中央値
四分位範囲
Q1 Q3
75パーセンタイル
25パーセンタイル

61
中央値を使った散らばりの指標 – 四分位、パーセンタイル、箱ひげ図
中央値
四分位範囲
Q1 Q3
75パーセンタイル
25パーセンタイル
四分位範囲×1.5
四分位範囲×1.5を超えなくてデータのあるところまで

62
中央値を使った散らばりの指標 – 四分位、パーセンタイル、箱ひげ図
Rcommanderで箱ひげ図を確認して比較してみます

63
データとデータの関係の見方 – 相関係数
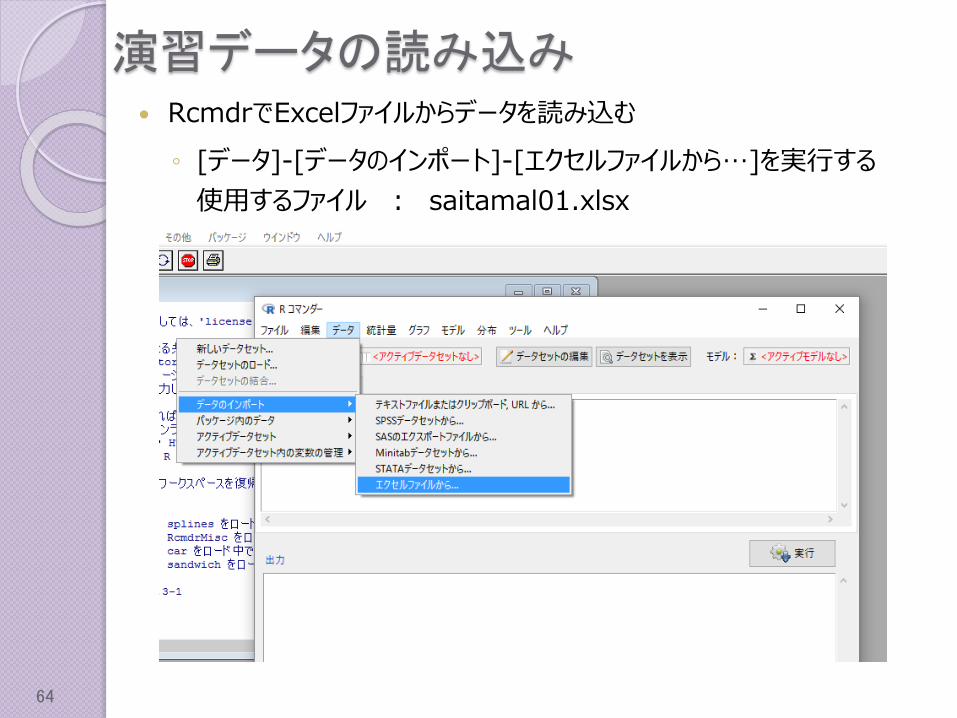
演習データの読み込み RcmdrでExcelファイルからデータを読み込む
◦ [データ]-[データのインポート]-[エクセルファイルから…]を実行する
使用するファイル : saitamal01.xlsx
◦
64

データの読み込み ダイアログボックスの設定
◦ データセット名を入力 : saitama
65
注:使用するデータは正規分布とは言えないため計算方法を理解してください。

データ分析の基本をやってみよう
1. 要約統計量を見てみるこれによってデータの全体的傾向をつかんでみる
2. 散布図または散布図行列で関連性を確認してみる
3. 傾向からデータの本来持つ性質についての可能性(仮説)を考えてみる
66

データとデータの関係の見方 – 相関係数
67
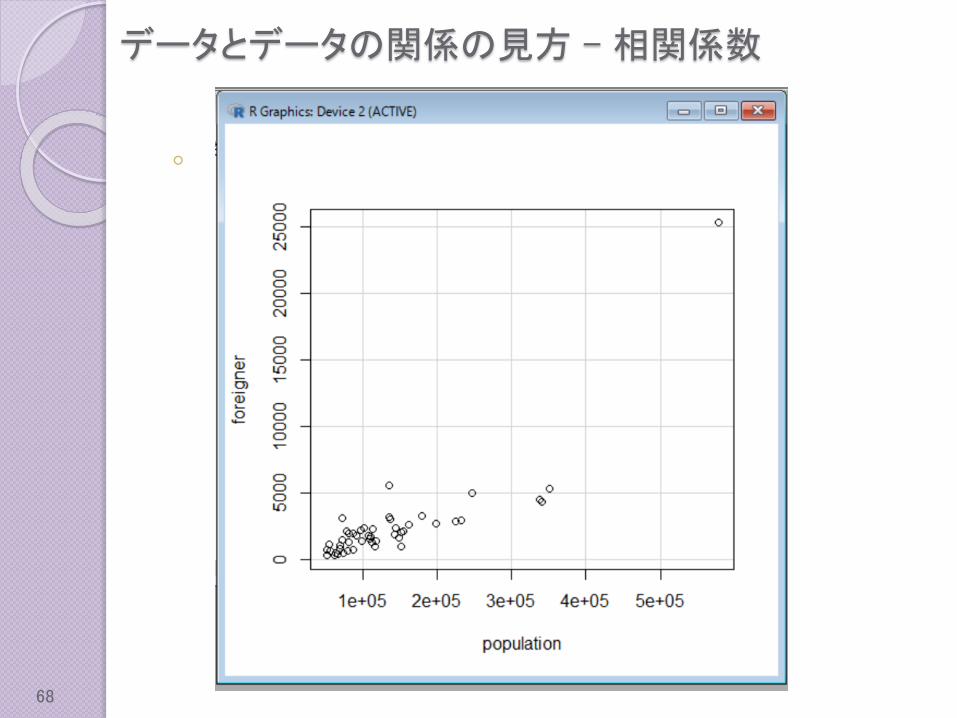
Rcmdrで散布図を表示する。
◦ 人口と外国人数
◦
データとデータの関係の見方 – 相関係数
68
◦
データとデータの関係の見方 – 相関係数
69
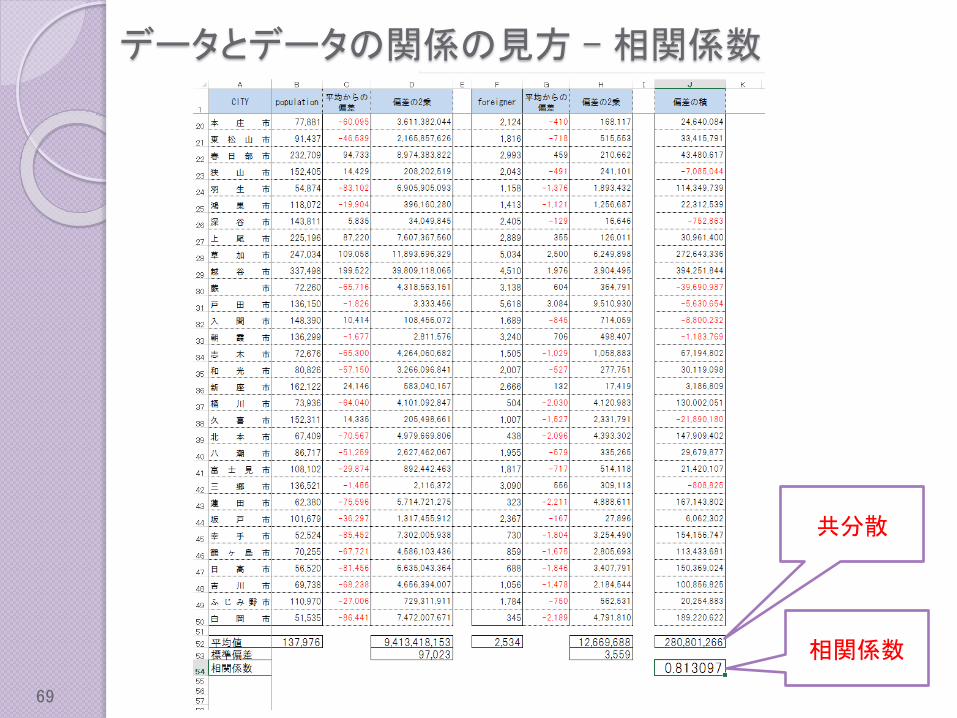
共分散
相関係数

70
データとデータの関係の見方 – 相関係数
相関係数はー1~1の範囲の値
相関係数は直線的な関係を示す
1に近いほど直線的な正の強さ
-1に近いほど直線的な負の強さ
相関係数は因果関係を表す指標ではない

71
データとデータの関係の見方 – 相関係数
Rcommanderで統計量を確認してみてください。

統計的データ分析推薦図書
データ指向のソフトウェア品質マネジメント(日科技連)
ソフトウェアメトリクス統計分析
入門(日科技連)
72

無料のお勉強情報 おススメ:データ分析勉強会サイト
https://sites.google.com/site/kantometrics/home
73

無料のお勉強情報
総務省統計局提供のデータ分析系のWEB講座が定期的に開講されています。データ
分析にご興味のある方はご検討を
無料です(^^)b
「社会人のためのデータサイエンス演習」講座概要
http://gacco.org/stat-japan2/
講座内容(詳細はリンク先にて)
https://lms.gacco.org/c…/course-v1:gacco+ga063+2016_04/about
74

引用、参考、参照資料
IPAソフトウェア開発データ白書2012-2013
ソフトウェアメトリクス統計分析入門 現場エンジニアによる直観的解説と実践ドリル
著者:小池利和
データ思考のソフトウェア品質マネジメント メトリクス分析による「事実にもとづく管理」の
実践 著者;野中誠、小池利和、小室睦
無料で学べる大学講座 gacco 社会人のためのデータサイエンス入門
総務省統計局
厚生労働省 国民生活基礎調査
日刊スポーツWebサイト
埼玉県市町村公開統計データ
76
EOF
77


![[AWS Black Belt Online Seminar] AWS Glue...データ分析のプロセス例(Big Dataが注目される前) 収集 保存 分析 活用 データ ユーザー 分析対象のほとんどはCSVやRDB上のデータ](https://img.pdfslide.net/doc/110x75/5f2ff63e816ba37d836b4a27/aws-black-belt-online-seminar-aws-glue-ffffbig.jpg)












![複合データ分析技術とNTF[Ⅰ]混合ダイバージェンス分析手法(3.2),会員購買・非会 員購買データ-Ⅱ&Ⅳを分析する異粒度分析手法(3.3)](https://img.pdfslide.net/doc/110x75/5f71657db4cf8d0eb1691913/effentfa-ffffi32iioeeefe.jpg)














