Embed Size (px)
Citation preview

PasDas Summit 2016 Thomas Kurz
2016/10/04Passau, Deutschland
Suche – ein effizientes Mittel zur Datenintegration

Redlink wurde 2013 gegündet und hat seinen Sitz in , Österreich.SALZBURG
SuchlösungenTextanalyse Apps
Daten verstehen Daten organisieren Daten nutzen

Kunden & Partner

04/36
"We are drowning in information and starved for knowledge."John Naisbitt
Suche als effizienter, zentraler Zugang zu Informationen und Daten
• Digitale Inhalte sind immer und überall abrufbar
• Inhalte sind oft unstrukturiert
• Information sind über Personen, Systeme und
Dokumente verteilt
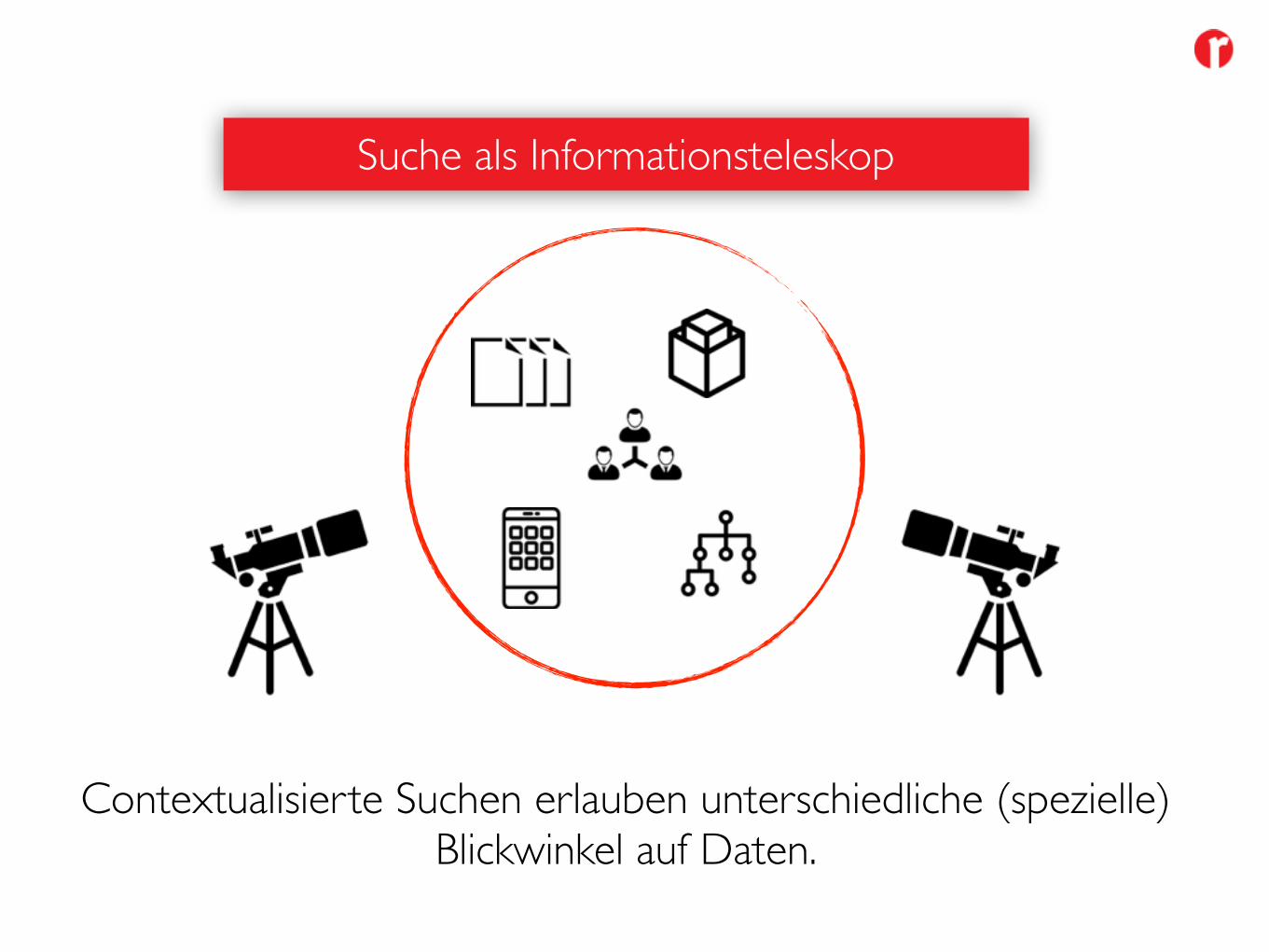
Suche als Informationsteleskop
Contextualisierte Suchen erlauben unterschiedliche (spezielle)Blickwinkel auf Daten.

Was verstehen wir heute unter Suche und wo geht die Reise hin ?
Wo und wie kann Suchtechnology die integrierte Sicht auf Daten verbessern ? Wie kann man das mit Open Source Software umsetzen ?
Roadmap

Suche – State of the Art and beyond
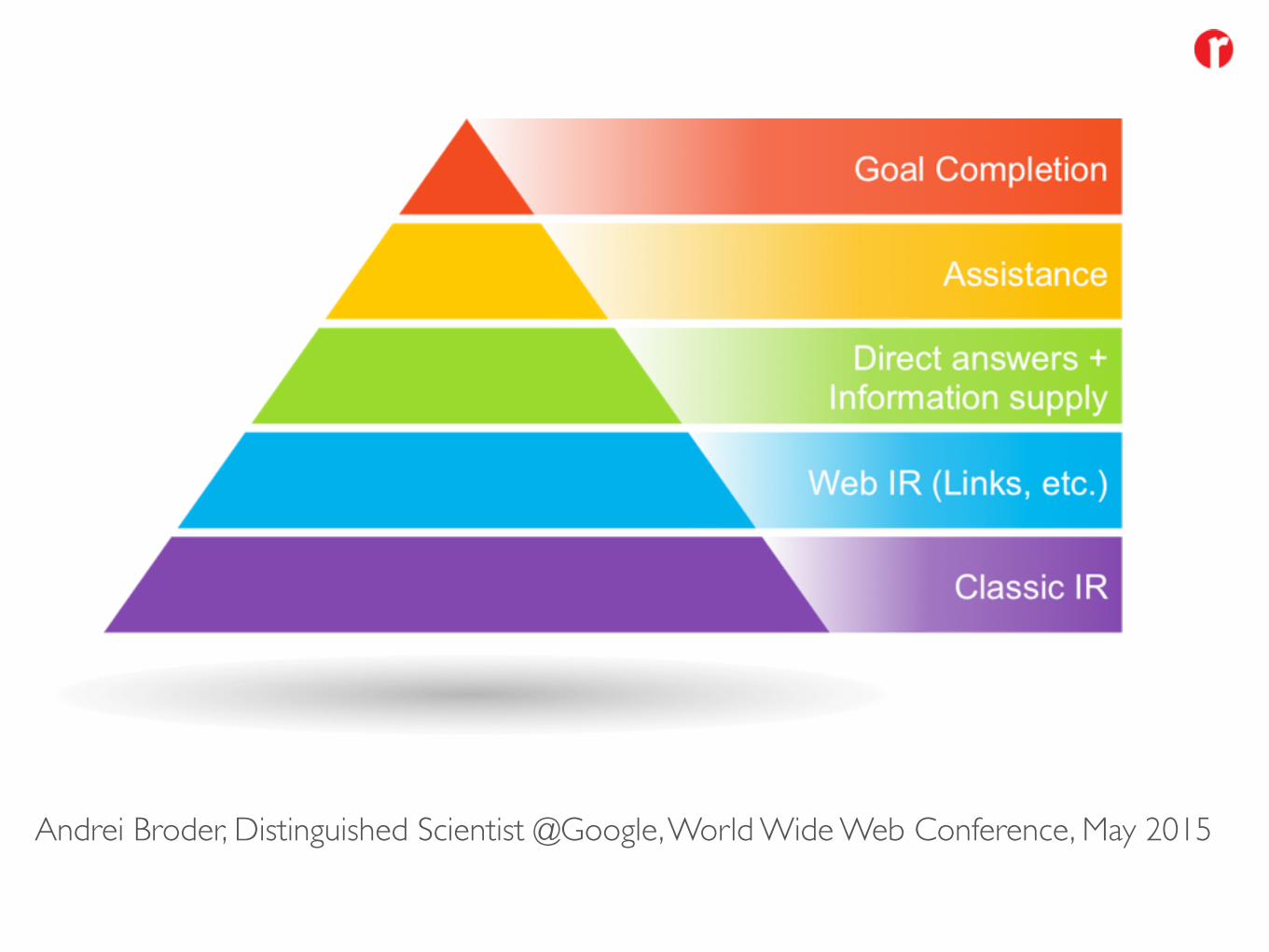
Andrei Broder, Distinguished Scientist @Google, World Wide Web Conference, May 2015
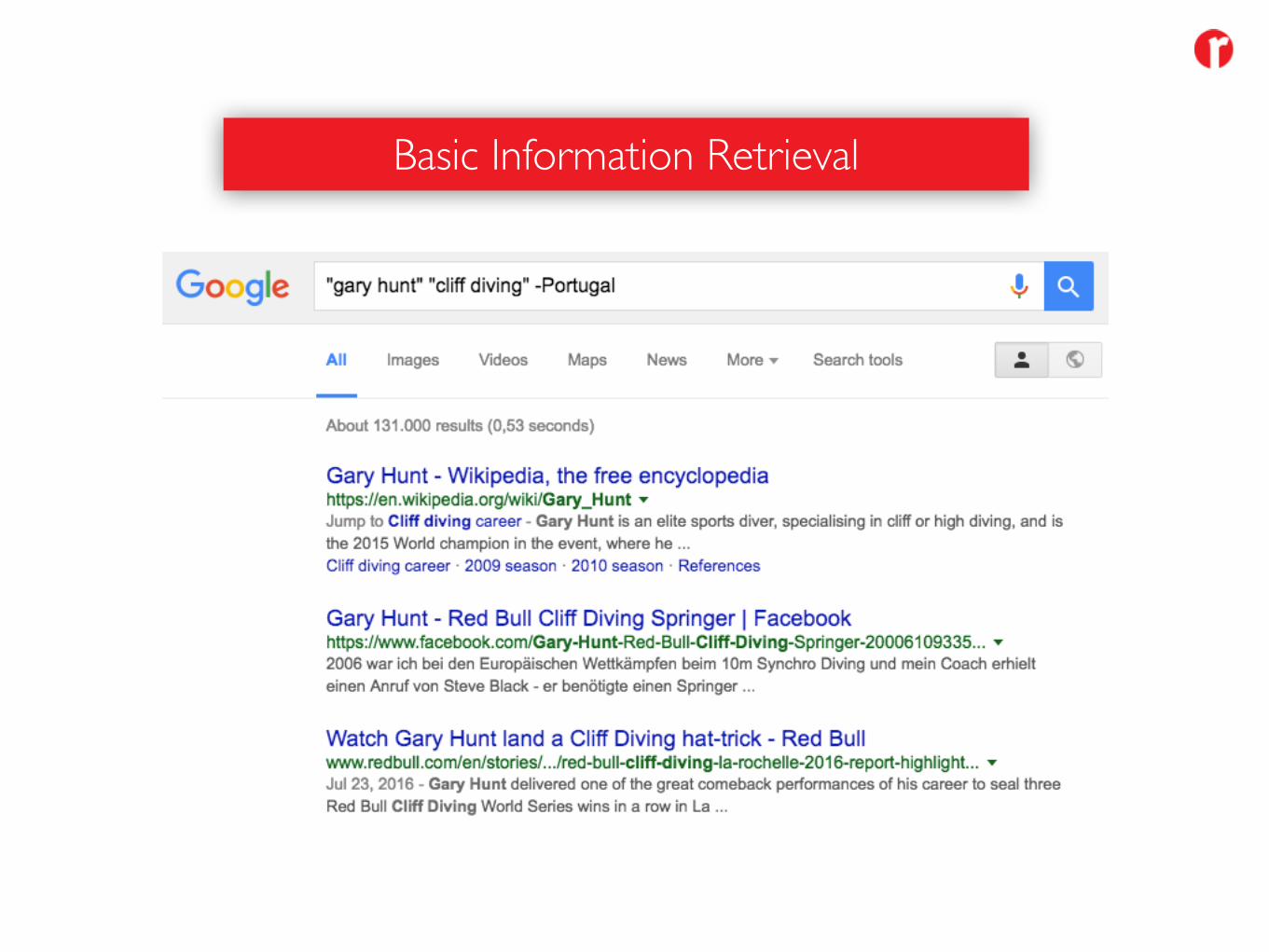
Basic Information Retrieval

Basic Information Retrieval
• Fulltext Search• Boolean Operators• Field Types / Processing• Weighting, Scoring
Add-ons: • Synonyms / Controlled Vocabularies• Spellchecking• Complex Functions (grouping, joining)• Boosting• Facetting• Filtering
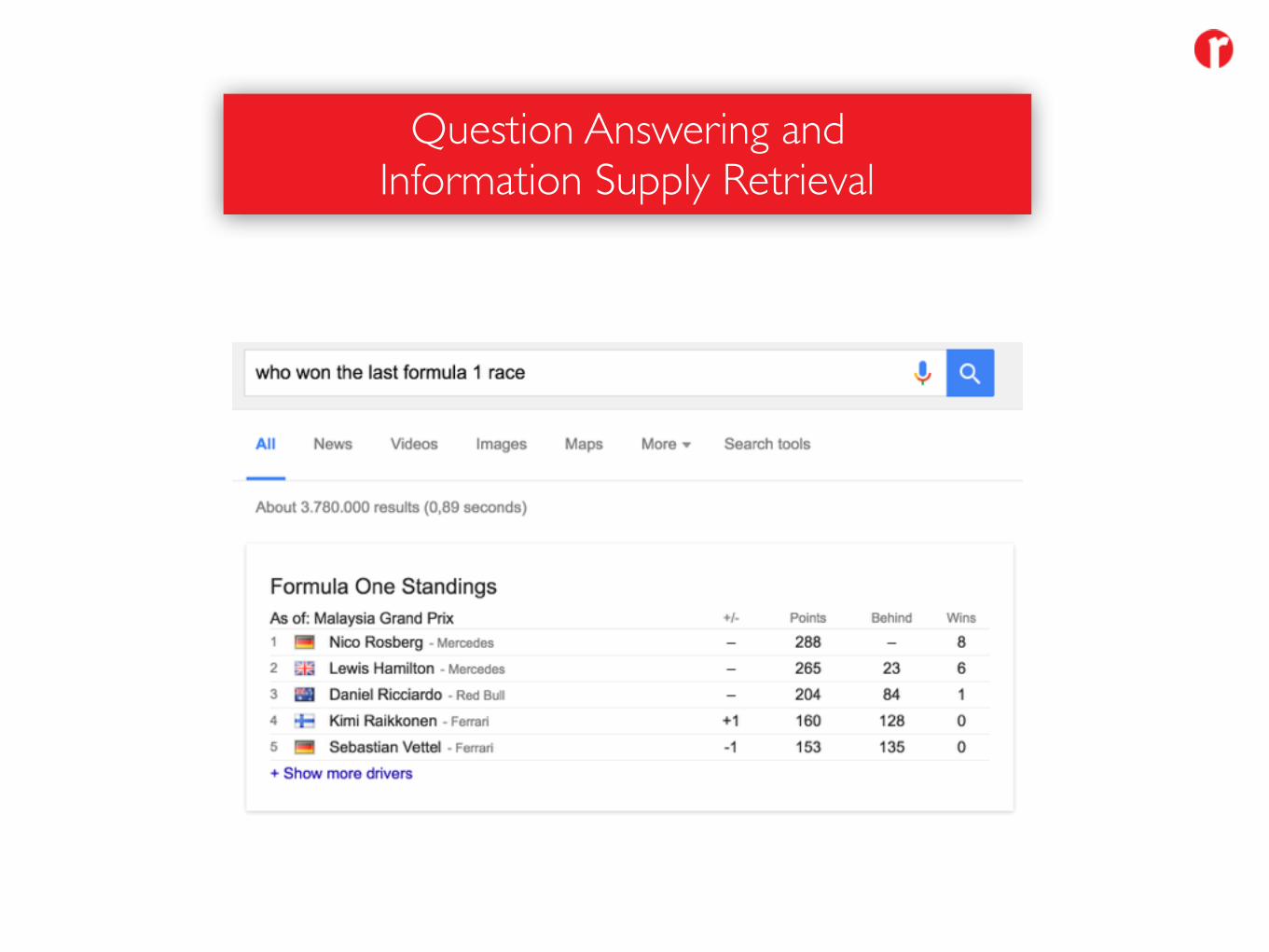
Question Answering andInformation Supply Retrieval

Question Answering andInformation Supply Retrieval
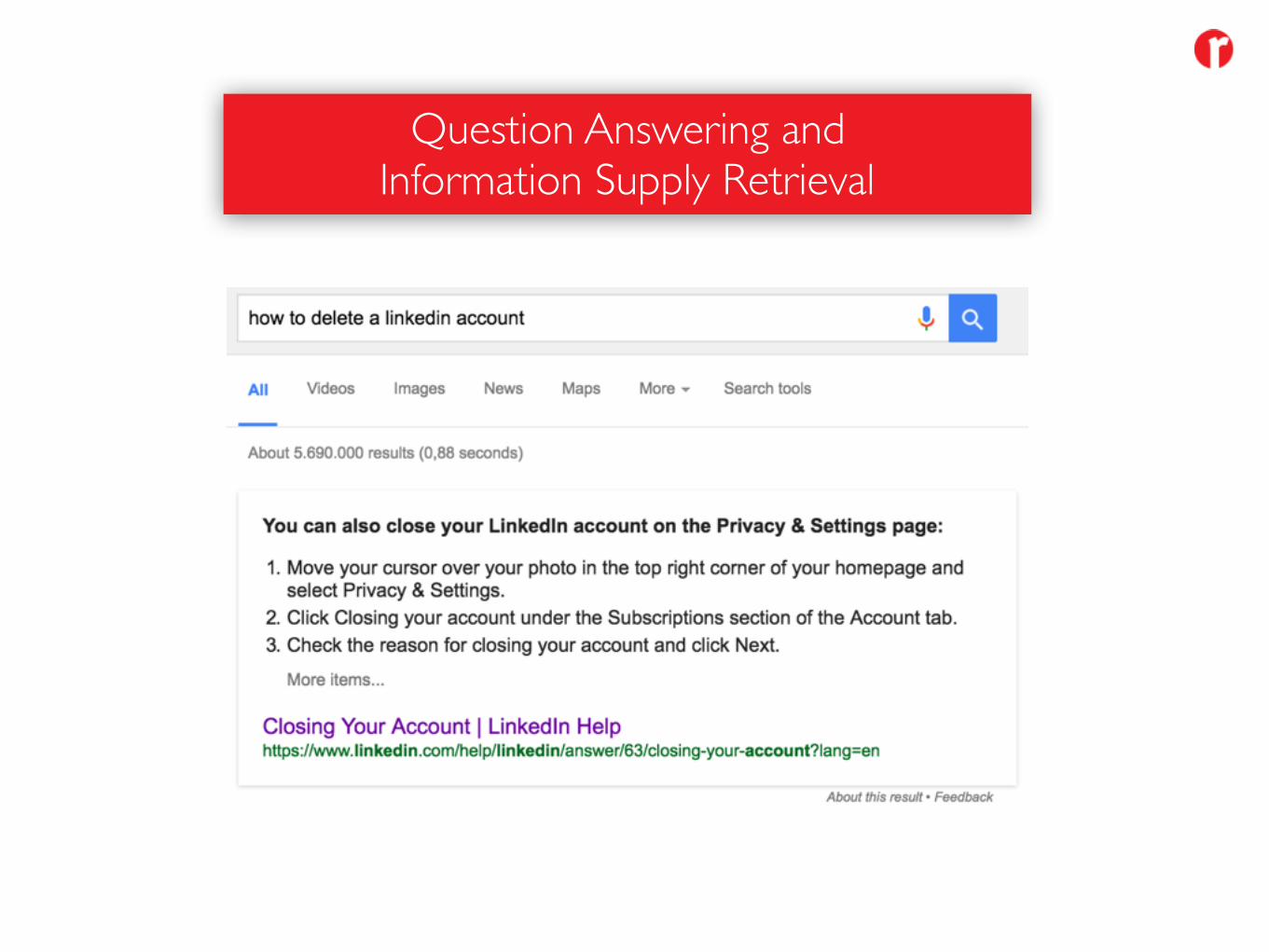
Question Answering andInformation Supply Retrieval

Question Answering andInformation Supply Retrieval
• Curated Information Resources (Knowledge Graph)• Information / Data Aggregation• Question Patterns / Natural Language Processing• Answering Patterns / Information Templates• Speech to Text Components• Multilinguality• Personalisation
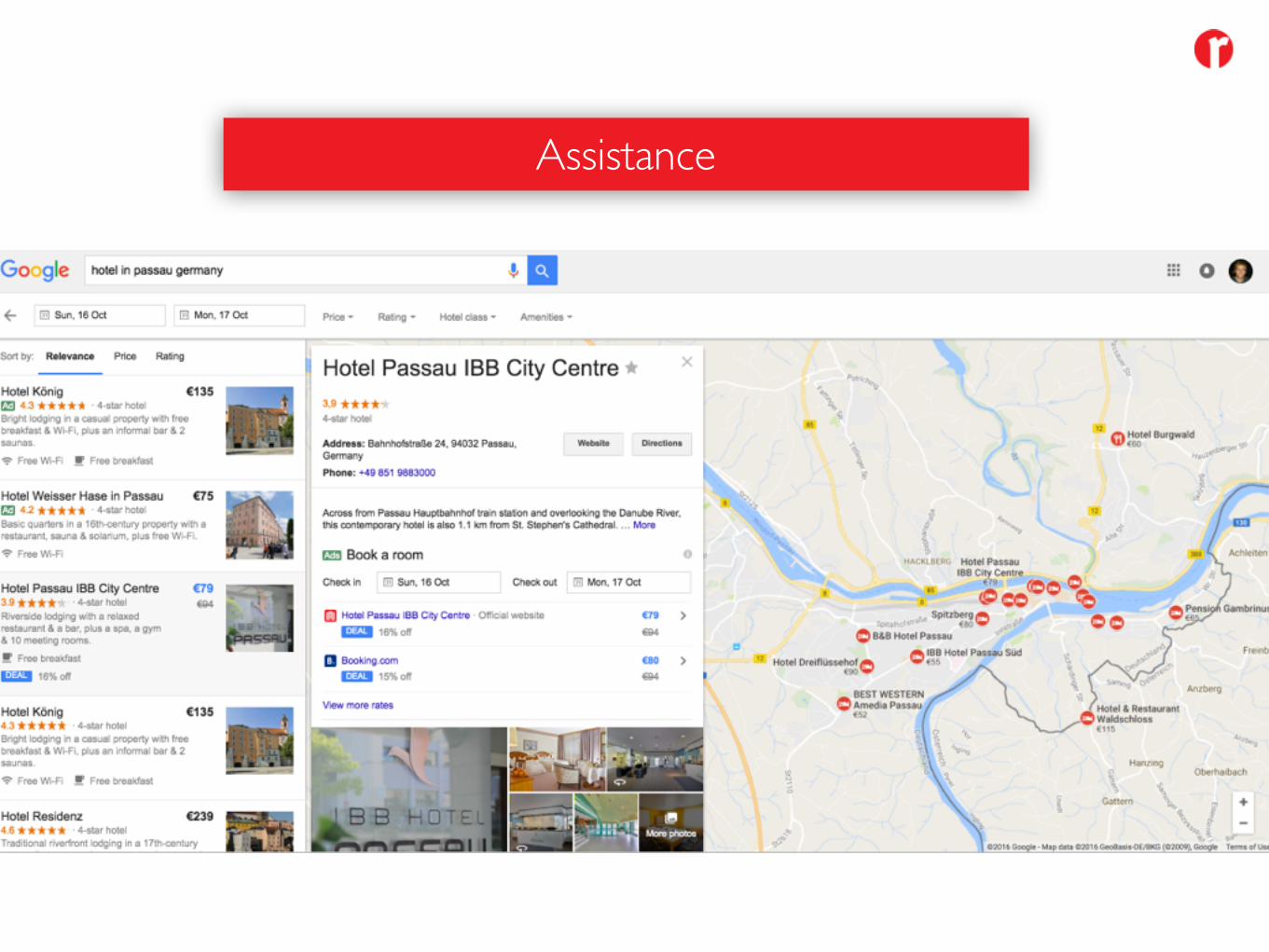
Assistance
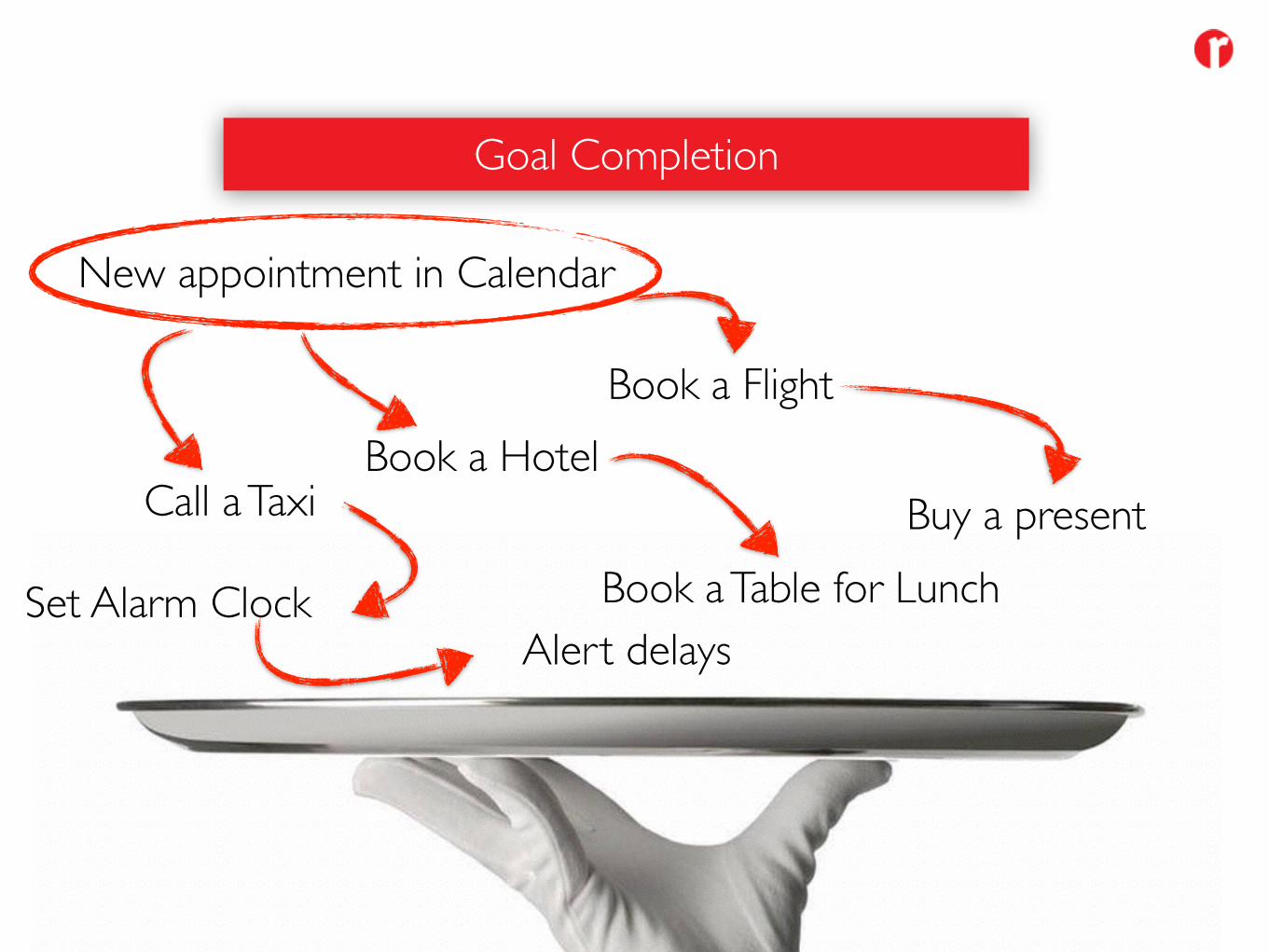
Goal Completion
New appointment in Calendar
Book a FlightBook a Hotel
Set Alarm Clock
Call a Taxi
Book a Table for LunchAlert delays
Buy a present

Eine integrierte Sicht auf Daten und Informationen

Mike leitet einen Copy Shop mit 5 festen Mitarbeitern und 10 studentischen Aushilfen. Er benutzt ein CRM System zur Kunden- verwaltung, Email zur Kommunikation, ein Erfassungs- und Abrechnungssystem für seine Aufträge und ein Filesharing System zur Datenverwaltung.
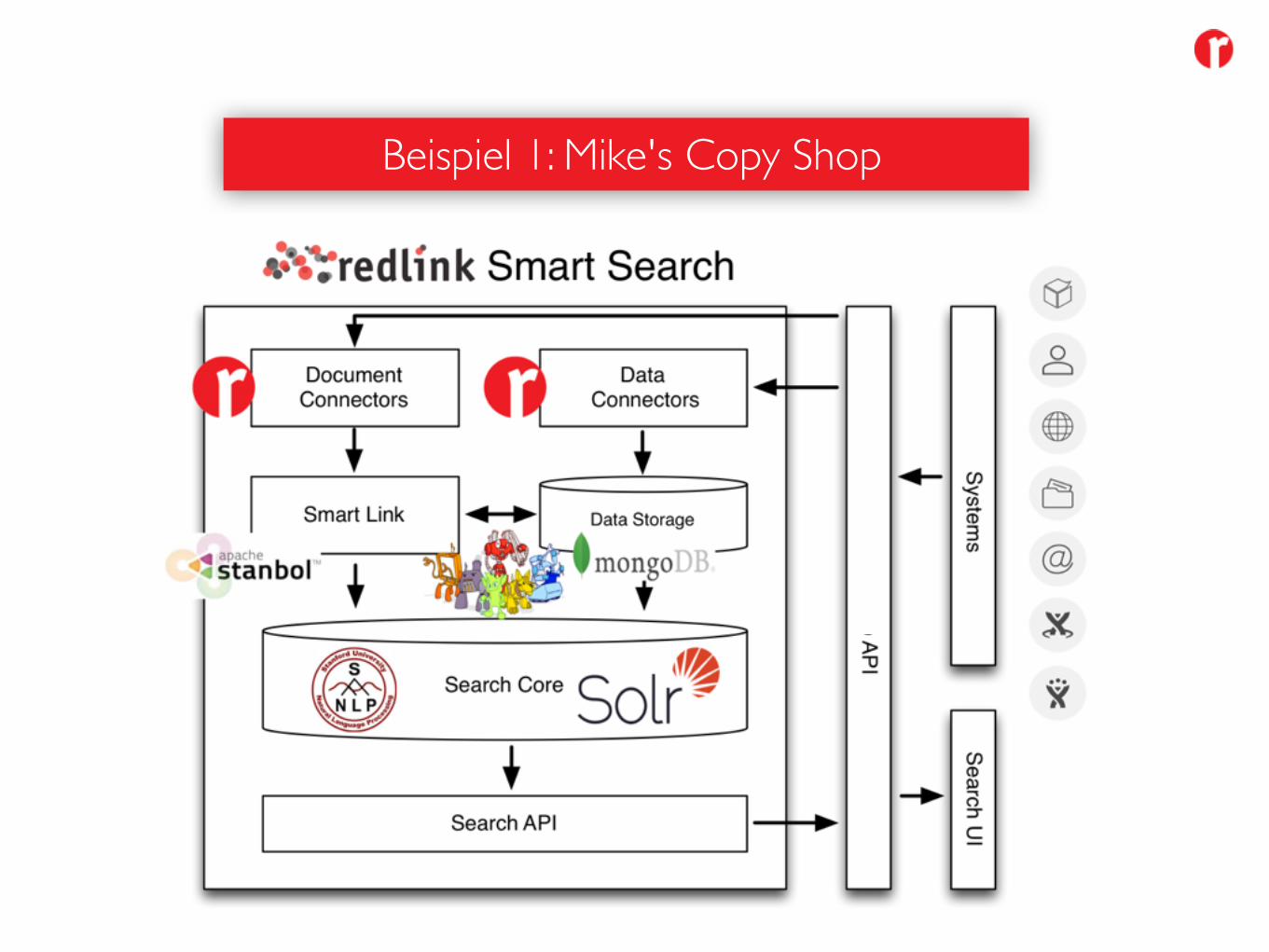
Beispiel 1: Mike's Copy Shop
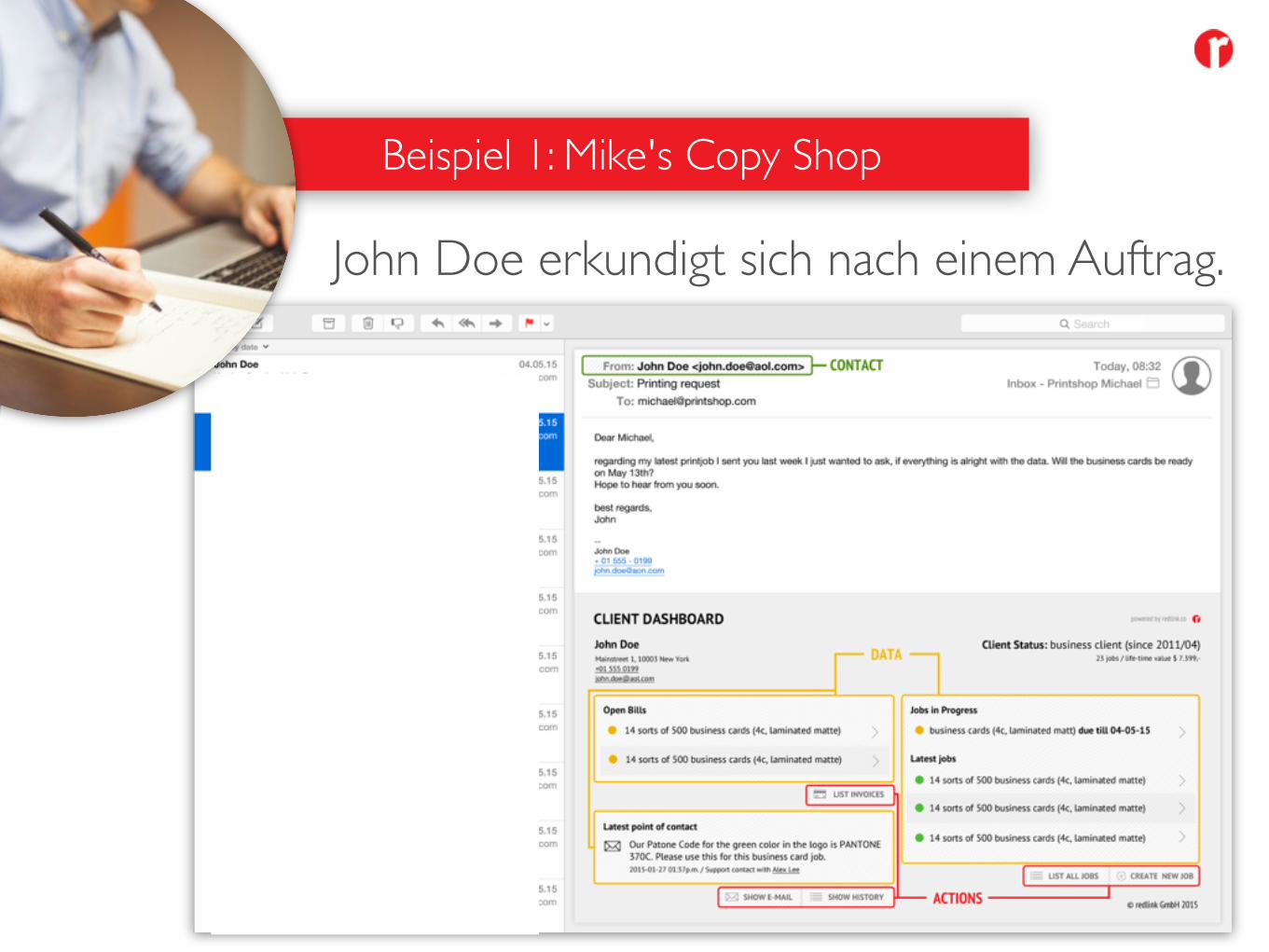
Beispiel 1: Mike's Copy Shop
John Doe erkundigt sich nach einem Auftrag.
Beispiel 1: Mike's Copy Shop
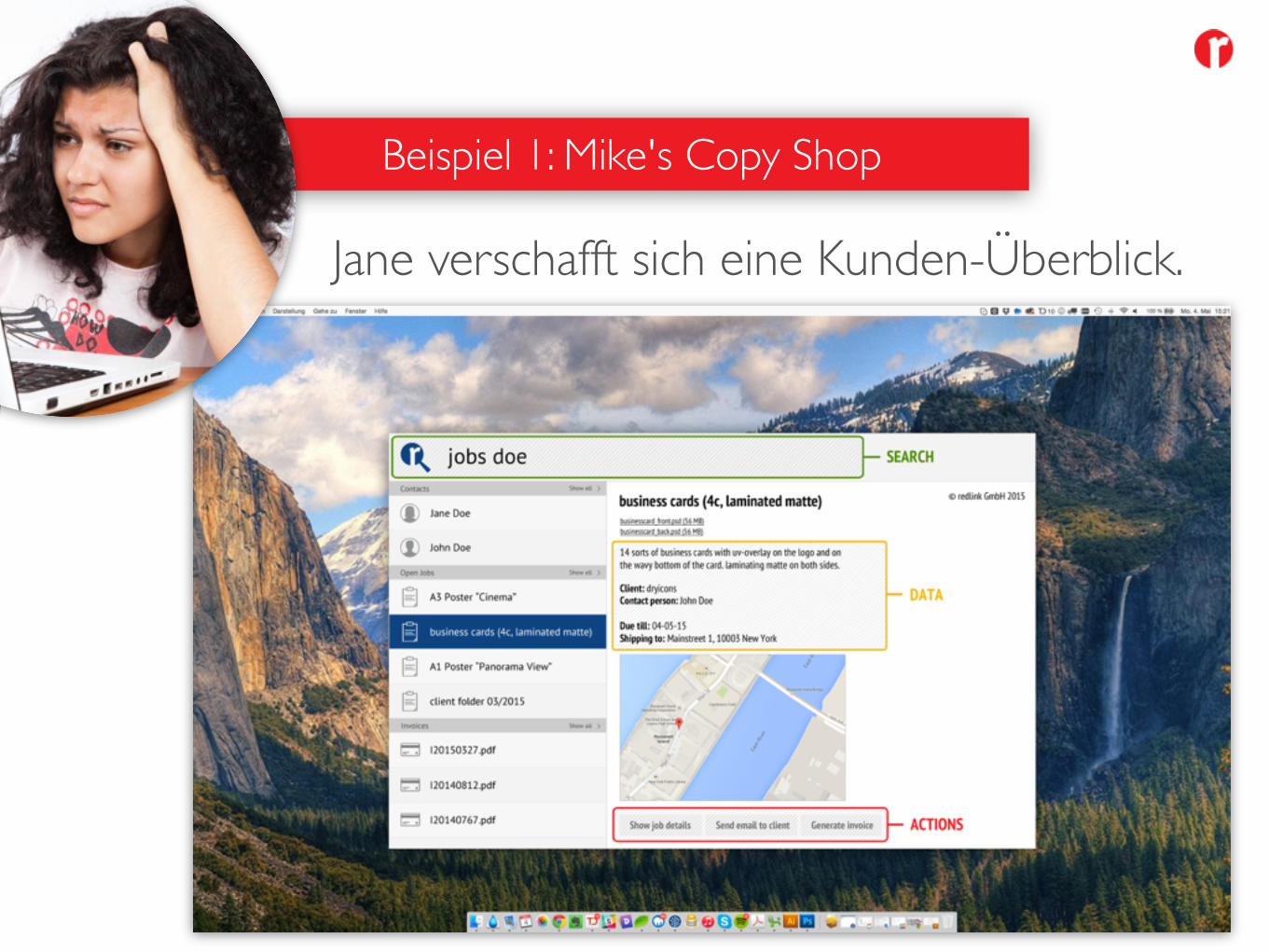
Jane verschafft sich eine Kunden-Überblick.

Beispiel 1: Mike's Copy Shop
Ziel: integrierte Suche durch Datenverknüpfung
• Sammeln der Daten (inkl. Zugriffsrechte)
• Integration der verschiedenen Daten durch Verlinkung (z.B. über Entitäten) mittel genormter Schemen
• Aggregation gleicher Daten aus verschiedenen Applikationen (Matching)
• Evtl. Metadaten erheben (z.B. pagerank)
• Zentraler, effizienter Zugriff durch Indizierung
02/36

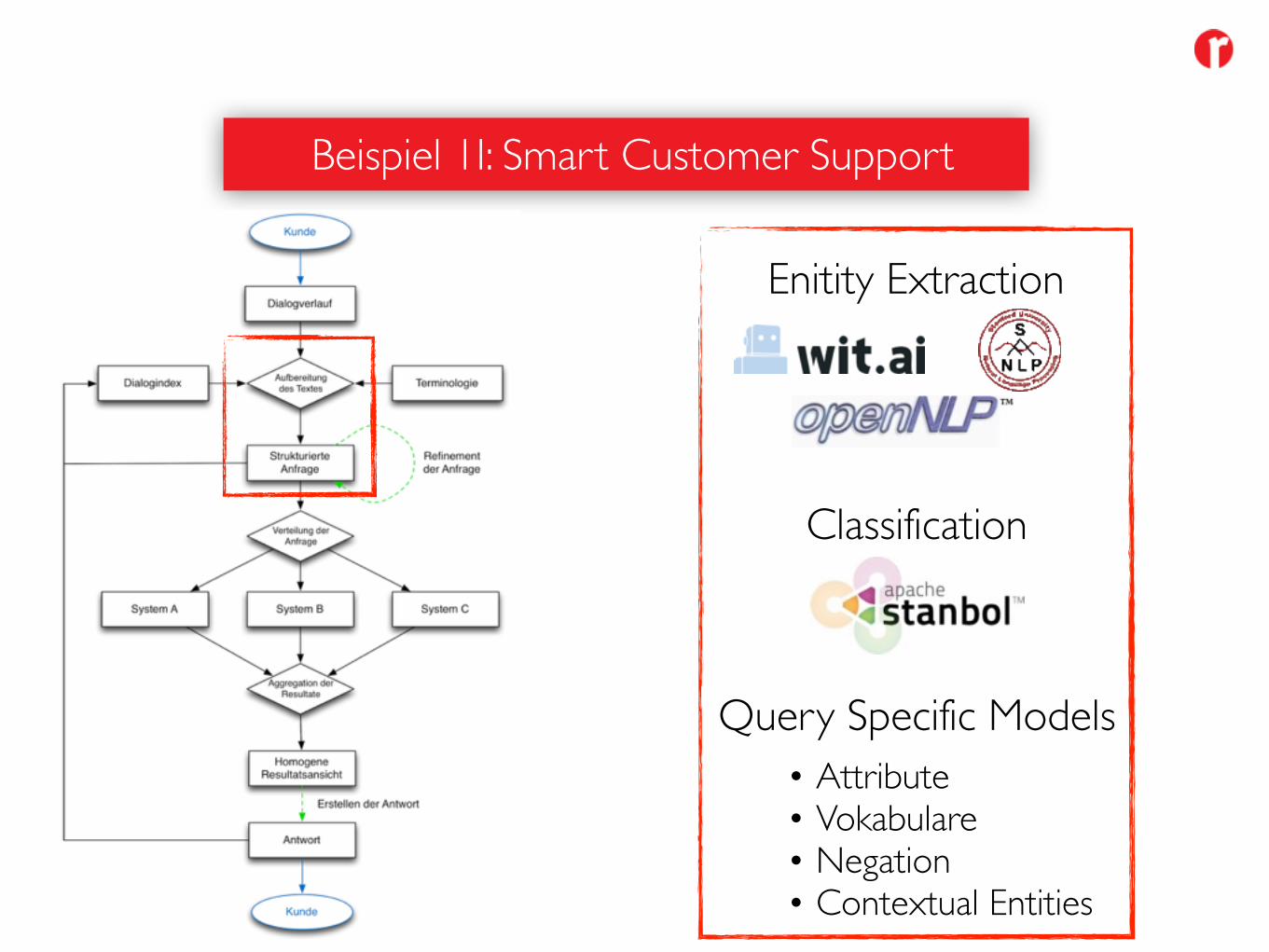
Beispiel 1I: Smart Customer Support
Die Deutsche Bahn betreibt mit dem "Reisebuddy" einen Concierge Service rund um das Thema Reise. Anfragen werden vom Kunden per SMS/Messenger gestellt und von Servicemitarbeitern bearbeitet. Diese nutzen für die benötigten Informationen interne und externe Quellsysteme.
02/36
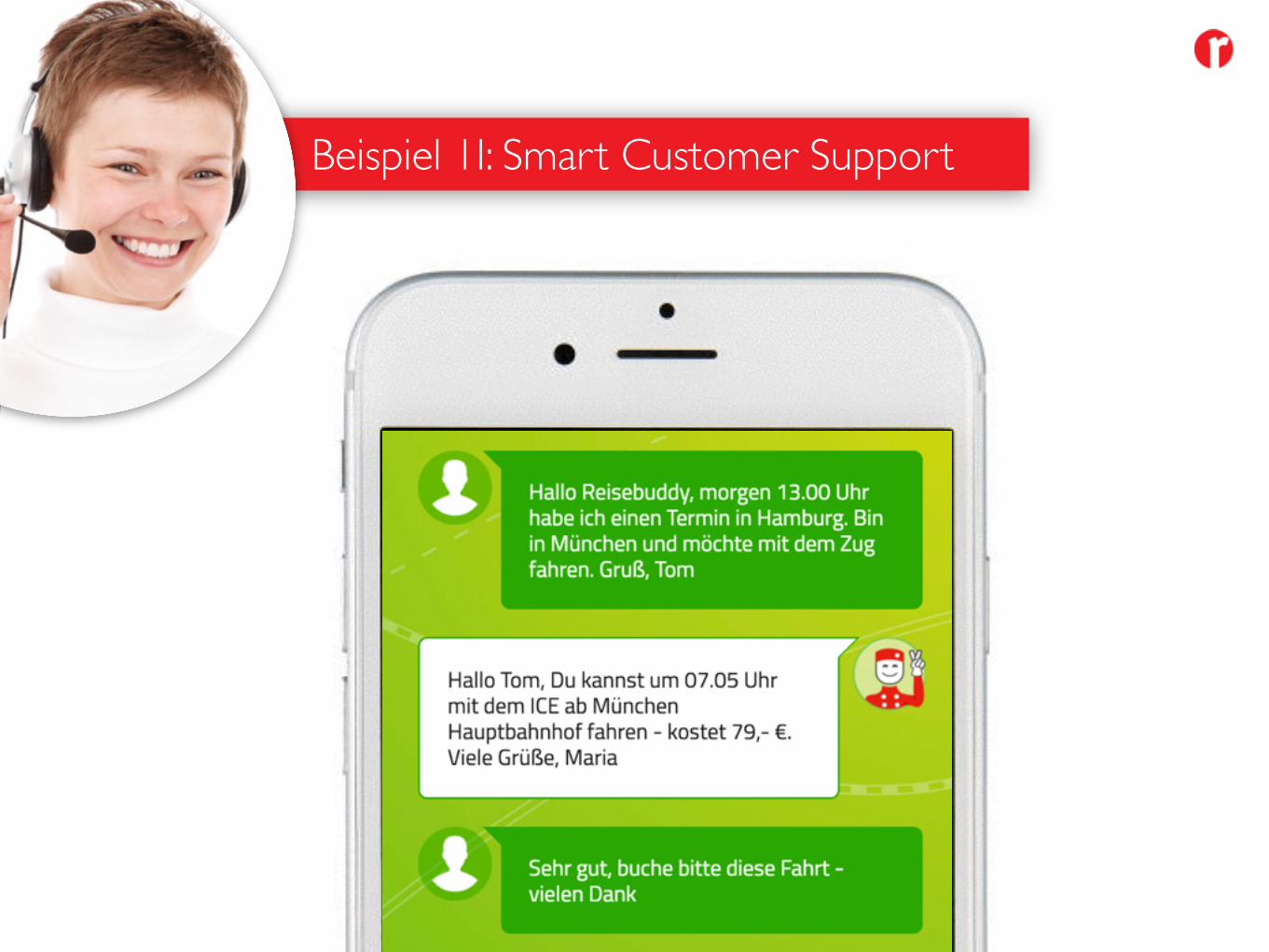
Beispiel 1I: Smart Customer Support
02/36

Beispiel 1I: Smart Customer Support
02/36
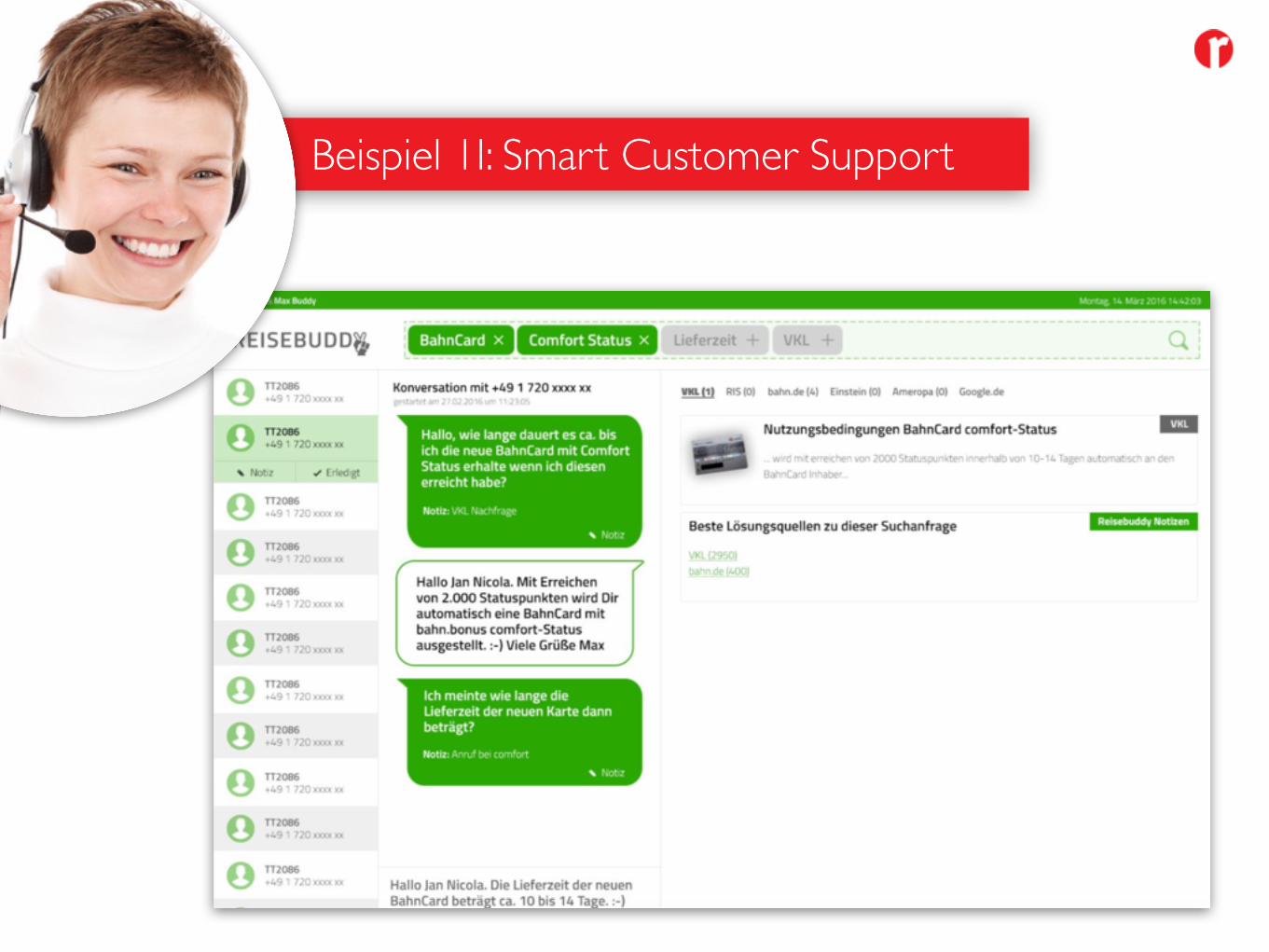
Beispiel 1I: Smart Customer Support
02/36

Beispiel 1I: Smart Customer Support
Ziel: integrierte Suche durch Klassifizierung und Verteilung auf eine Menge von Endpunkten
• Klassifizieren der Anfrage (z.B. Reiseanfrage)
• Extraktion such-relevanter Entitäten (Information Units)
• Aufbau der Anfrage
• Evtl. Aggregation und Gewichtung
• Generieren der Antwort

Lösungen mit Open Source Software
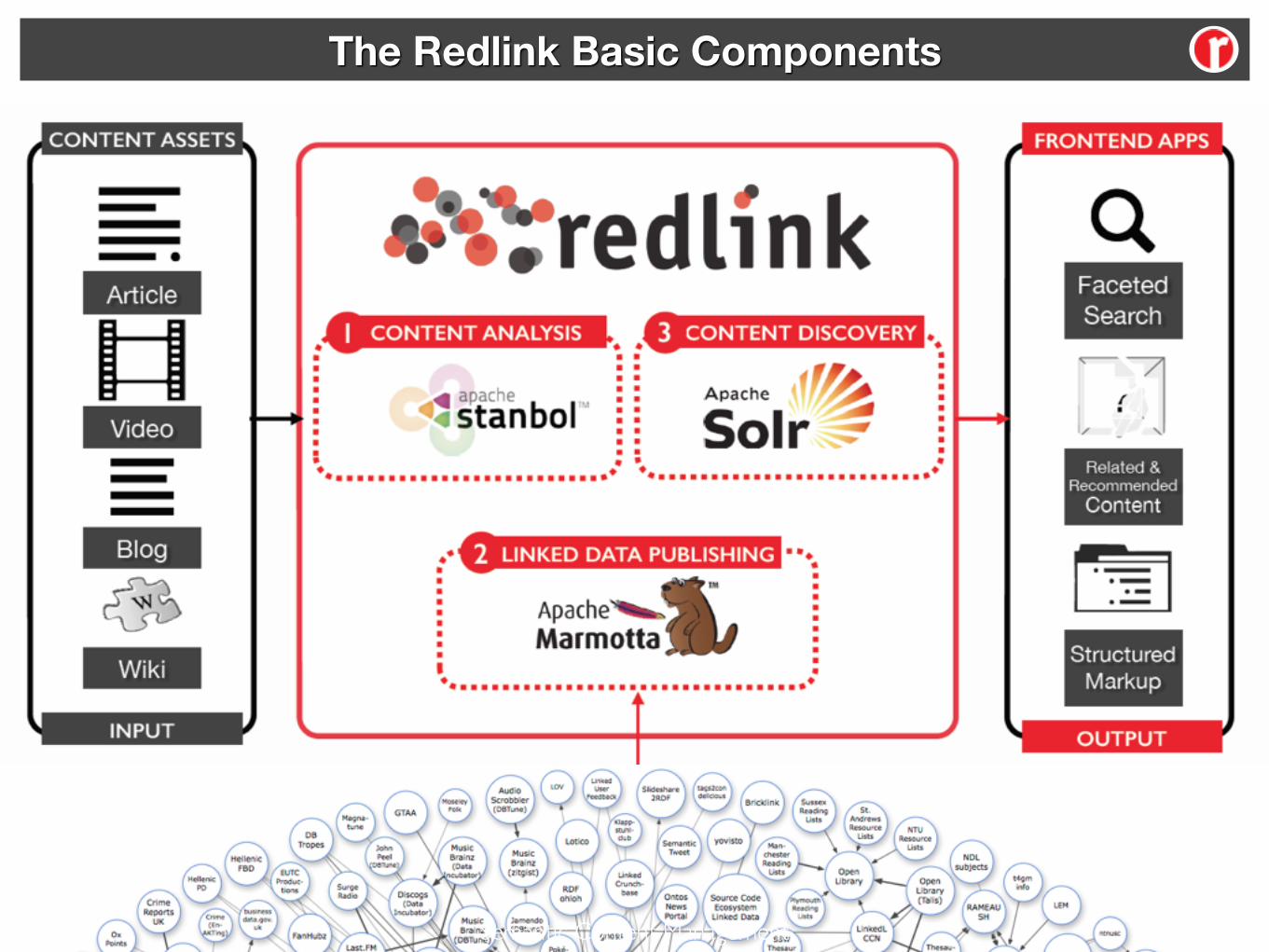
Semantic Content Management 01/02
The Redlink Basic Components
Semantic Content Management 15/36

• Qualität der Software steigt
• Qualität der Dokumentation steigt
• Manpower kann drastisch steigen
• Offene Libraries steigern Qualität und senken Entwicklungskosten
• Produkt wird besser wahrgenommen
• Marketing Kosten können sinken
• Geringeren Einfluss auf Roadmap und Entwicklungsziele
• keine SLAs bei Fremdsoftware
• Verlust von Kontrolle und Einzigartigkeit
• Keine Garantie (die Community bestimmt)
• Overhead (Community Building, Licensing, usw.)
• evtl. Einschränkungen durch Lizenzrechte
Warum Open Source ?
Pros Cons

Semantic Content Management 16/36
• Read-Write Linked Data
• Triple Store mit Versionierung und Reasoning
• SPARQL und LDPath Anfragesupport
• Transparentes Linked Data Caching
The Open Platform for Linked Data
http://marmotta.apache.org/

17/36
• Framework für Semantic Enhancement
• Natural Language Processing und Entity Recognition
• Mehrsprachigkeit
• Klassifikation und Sentiment Analyse
http://stanbol.apache.org
The Toolbox for Semantic Lifting

Semantic Content Management 18/36
• Apache Lucene basiertes Suchframework
• Mehrsprachigkeit
• Hoch skalierbar (Solr cloud) und ultra schnell
• Hoch konfigurierbar
http://lucene.apache.org/solr/
The highgly scalable Search Server

Semantic Content Management 18/36
Andere Komponenten
Apache TinkerPop™
...
Beispiel 1: Mike's Copy Shop

Beispiel 1: Mike's Copy Shop
Beispiel 1I: Smart Customer Support
Enitity Extraction
Classification
Query Specific Models• Attribute• Vokabulare• Negation• Contextual Entities

Take aways
Suche bietet heute mehr als klassisches Information Retrieval.
Suche ist ein gutes Mittel um eine integrierte Sicht auf Daten zu erhalten.
Natürlichsprachliche Eingabe ist State of the Art.
Open Source Software kann viele notwendige Schritte sehr gut abdecken.

are you
ready to make sense
of your data?
Vielen Dank für die Aufmerksamkeit !





























