Embed Size (px)
Citation preview

PFNはどのようにして APCの認識問題に取り組んだか?
齋藤真樹 (Preferred Networks inc.)
GPU Deep Learning Community
2016/09/13

(自己|会社)紹介
齋藤 真樹,博士(情報科学)
– 岡谷研(東北大),DC2
– グラフィカルモデルを効率的かつ
高精度に最適化する理論研究に従事
Preferred Networks inc.
– Deep Intelligence in-Motion (DIMo)
プラットフォームをベースにした
ソリューションの研究開発
2

あめちゃん受付に置いてあります
3

Amazon Picking Challengeとは
Amazonが主催するロボットコンテスト
今回、6/29-7/3, ドイツ, ライプツィヒ
RoboCup2016 と併設,2015年からスタート
Amazon kiva systemのような倉庫のさらなる自動化を目指す
15分以内に指示された12個のitemを棚から取ってくる
ソースコード開示必須

アイテムと棚
• 39種類のアイテム • 光沢や透明なもの、重いもの、
大きなもの、小さいものも 含まれる

結果
Pickタスクで2位(1位と同スコア)
Stowタスクで4位(3位と僅差)
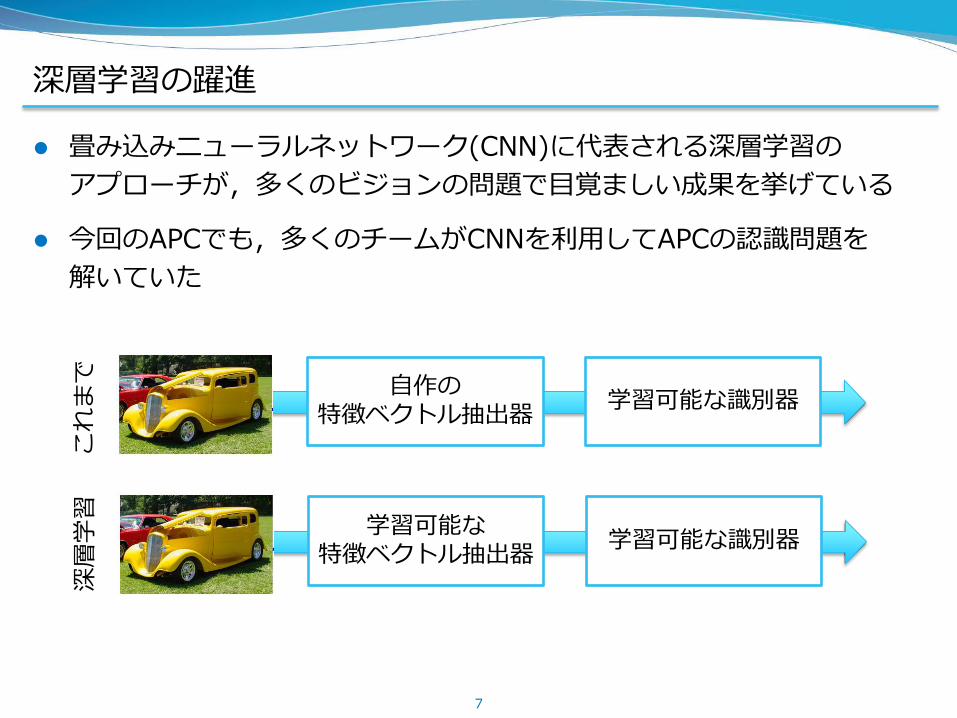
深層学習の躍進
畳み込みニューラルネットワーク(CNN)に代表される深層学習の
アプローチが,多くのビジョンの問題で目覚ましい成果を挙げている
今回のAPCでも,多くのチームがCNNを利用してAPCの認識問題を
解いていた
7
自作の
特徴ベクトル抽出器 学習可能な識別器
これ
まで
学習可能な
特徴ベクトル抽出器 学習可能な識別器
深層
学習

End-to-end trainingは,深層学習において重要
入力データから推定解を出力するまでの計算過程をすべて一括して
学習するアプローチは深層学習の領域において重要
「解きたい問題に応じてモデルを適切に定義し,学習させる」
8
CNN
従来
手法
物体毎に
ピッキング
戦略を構築
提案
手法
CNN

Position Segmentation
Convolutional Neural Networkによる画像認識
最終的なネットワーク構成自体はシンプル
– Chainerの特徴である”Flexibility”が役立った (ポジショントーク)
RGB image
CNN depth image

試行錯誤は重要
10
FCN
Conv-D
econv
以前別の研究(遊び)で試していたConv-Deconv Networkを使用
全く違う分野の成果が思わぬ分野の成果につながる
– 研究者の遊びは重要なので止めてはならない(???)

深層学習はデータ量とアノテーションがすべてを決める
カテゴリ数: 約40個
学習に使用した画像枚数: 約1600枚
– 参考: セグメンテーションに必要な枚数は数千から数万枚程度
グラフィックボード: GTX Titan X (学習には高速なGPUが必要)
– 推定はノートブック付属のGPUで十分
11
撮影 アノテーション 学習 推論
約1週間 約1週間 約一日 一秒未満
AMTでなく
すべて自社

内製アノテーションツール
アノテーションは重要なのにも関わらず,適したツールが無かった
12

定量的評価の重要性
Confusion matrixをプロット.小さいオブジェクトの識別率が
比較的低いことが判明
– ロス関数中の小さいオブジェクトのウェイトを上げる事で対処
深度情報が識別率の向上に大きく寄与していることも判明
13

CGを使った事前学習はそこまで重要でなかった
CGを使ってデータを増やすことで,実写単体よりも推定精度を改善で
きることが知られている
Blenderを使ってデータを大量に生成,事前学習に使用
労力の割に見合う精度改善かというと微妙・・・・
– 撮影枚数やアノテーションデータを増やしたほうが良い
14
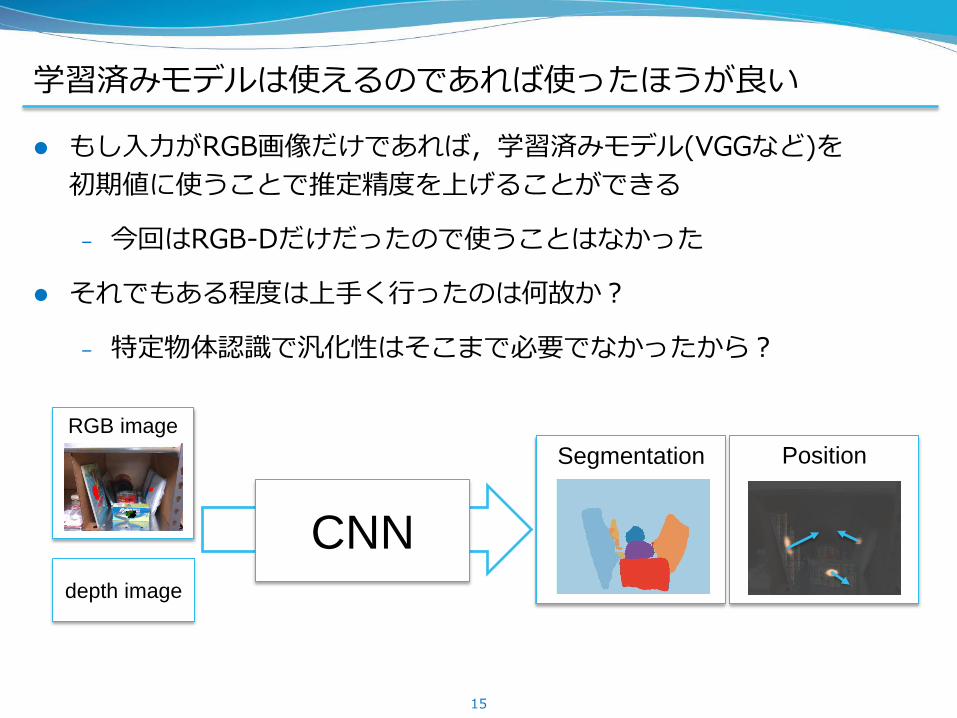
学習済みモデルは使えるのであれば使ったほうが良い
もし入力がRGB画像だけであれば,学習済みモデル(VGGなど)を
初期値に使うことで推定精度を上げることができる
– 今回はRGB-Dだけだったので使うことはなかった
それでもある程度は上手く行ったのは何故か?
– 特定物体認識で汎化性はそこまで必要でなかったから?
15
Position Segmentation
RGB image
CNN depth image

その他いろんな工夫
人間が識別できるレベルまで解像度を落とすと推定精度が上がった
– 計算コストが低い,次元の呪いを回避する効果
Data augmentation(入力画像を確率的に劣化させる処理)は重要
– ホワイトノイズ,ブラー,回転,色相変換,ミラー
16

まとめ
End-to-end trainingは,深層学習において重要
データ量とアノテーションがすべてを決める
試行錯誤は重要,定量的評価は重要
サボりがちな当たり前のことを当たり前にやるのが一番大事
17






























