Embed Size (px)
Citation preview

Ethics in Data Science and Machine Learning
Thierry Silbermann
> 3000 members in the group !
1

Disclaimer
• Most of this presentation is taken from this class:
• https://www.edx.org/course/data-science-ethics-michiganx-ds101x-1
2

3
Machine Learning

What are Ethics?
• Ethics tells us about right and wrong
• They are shared value / societal rule
• Ethic is not law
• No philosophical questions, but ethical practice of Data Science
4

Inform Consent
5

Informed Consent• Human Subject must be
• Informed about the experiment
• Must consent to the experiment
• Voluntarily
• Must have the right to withdraw consent at any time
6

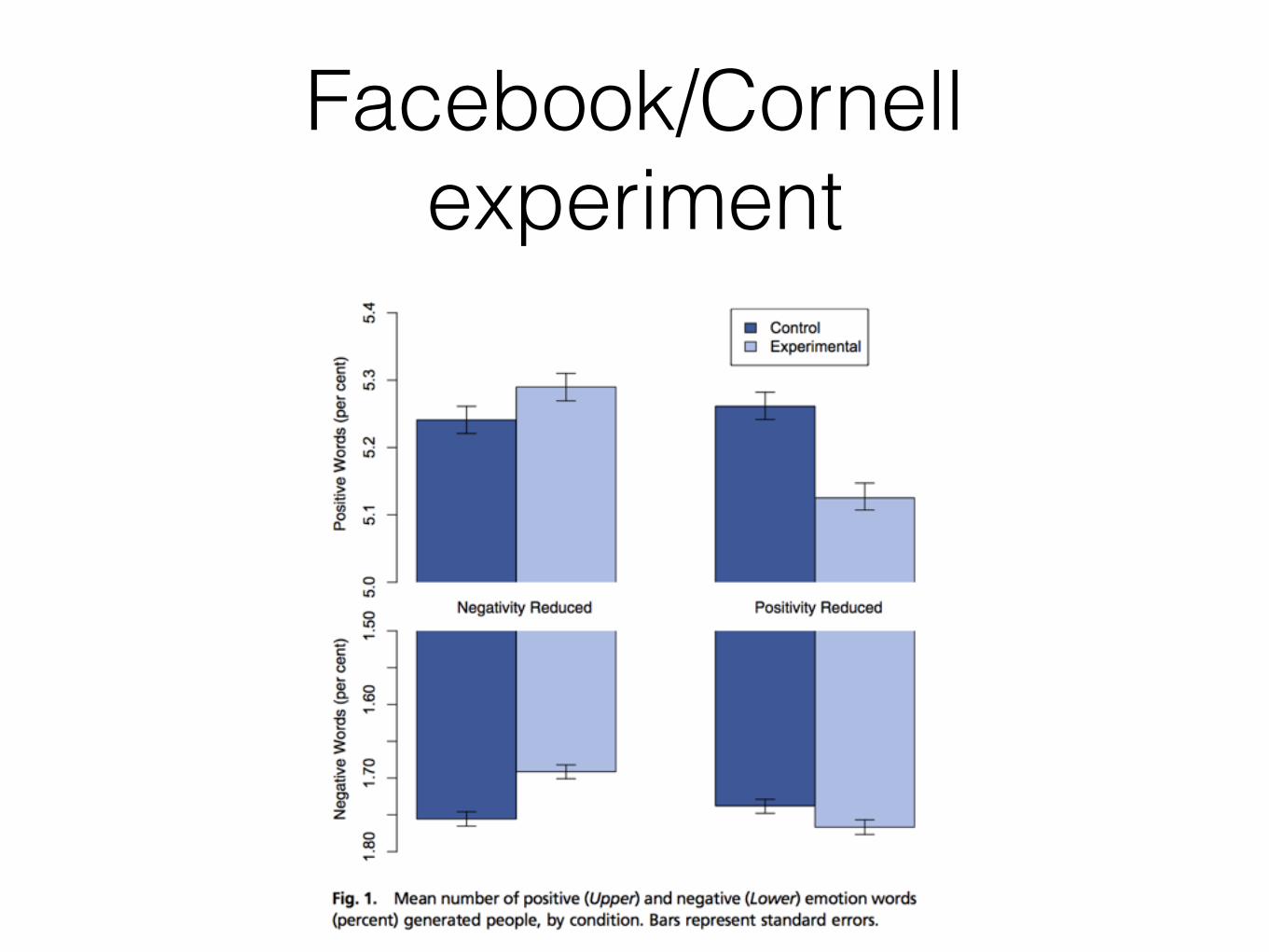
Facebook/Cornell experiment
• Study of “emotional contagion”
7

Facebook/Cornell experiment
• 689,003 people experiment
• One week period in 2012
• Facebook changed deliberately the content of the feed
• Group A: Removed negative content from feed
• Group B: Removed positive content from feed
8
Facebook/Cornell experiment
9

Data Ownership
10

• Most of the time you don’t own the data about you. The data belongs to the company who collected it
• Nevertheless we might have some control over these data that aren’t ours because they are about us
Data Ownership
11

• We need to create the principle to reason about this control and that’s the main concern of a discussion about the right to privacy
• If the company goes bankrupt, the company buying it should keep the same privacy
Data Ownership
12

Privacy
13

• Privacy, of course is the first concern that comes to so many minds when we talk about Big Data.
• How do we get the value we would like by collecting, linking, and analyzing data, while at the same time avoiding the harms that can occur due to data about us being collected, linked, analyzed, and propagated?
• Can we define reasonable rules that all would agree to?
• Can we make these tradeoffs, knowing that maintaining anonymity is very hard?
Privacy
14

• People have different privacy boundaries.
• As society adapt to new technologies, attitude change
• But different boundaries doesn’t mean no boundary
Privacy
15

No option to exit• In the past, one could get a fresh start by:
• moving to a new place
• waiting till the past fades (reputation can rebuild over time)
• Big Data is universal and never forgets
• Data Science results in major asymmetries in knowledge
16

Wayback Machine• Archives pages on the web (https://archive.org/
web/ - 300 billion pages saved over time)
• almost everything that is accessible
• should be retain forever
• If you have an unflattering page written about you, it will survive for ever in the archive (even if the original is removed)
17

Right to be forgotten
• Laws are often written to clear a person’s record after some years.
• Law in EU and Argentina since 2006
• impacts search engines (not removed completely but hard to find)
18

Collection vs Use• Privacy is usually harmed only upon use of data
• Collection is a necessary first step before use
• Existence of collection can quickly lead to use
• But collection without use may sometimes be right
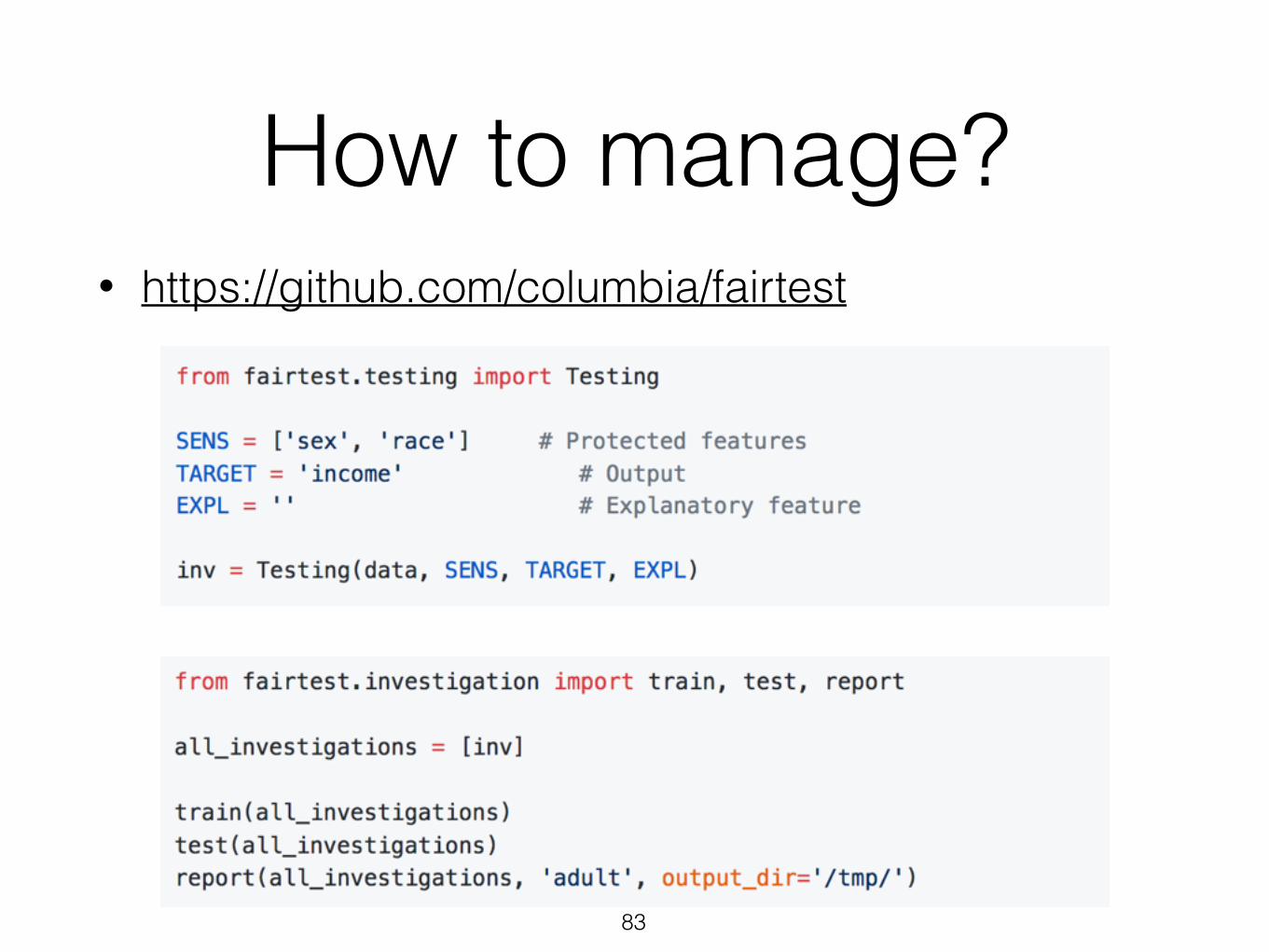
• E.g surveillance
• By the time you know what you need, it is too late to go back and get it
19

Loss of Privacy
• Due to loss of control over personal data
• I am ok with you having certain data about me that I have chosen to share with you or that is public, but I really do not want you to share my data in ways that I do not approve
20

‘Waste’ Data Collection
• Your ID is taken at the club (Name, address, age)
• How this data is being used ? Is it stored ?
21

Metadata
• Data about the data
• Often distinguish from data content
22

Metadata• E.g phone call, metadata includes
• Caller
• Callee
• Time of Date of Call
• Duration
• Location
23

Underestimating Analysis
• A smart meter at your house can recognise “signatures” of water use every time you flush the toilet, take a shower, or wash clothes
24

Privacy is a basic human need
• Even for people who have nothing to hide
25

Sneaky mobile App• There was a time where App didn’t tell you what kind
of data they were collecting
• Many app asks for far more permissions that they need
• Might be used for future functionality
• But most of the time just for adware
• Picture management app that needs your location
26

Anonymity
27

On the internet, nobody knows you are a dog
• You can say whoever you are
• You can say whatever you are
• You can make up a persona
• But today, we find it less and less true
28

Many transactions need ID
• You must provide an address to receive goods
• You must give your name for travel booking
• You must reveal your location to get cellular service
• You must disclose intimate details of your health care and lifestyle to get effective medical care
29

Facebook real name policy
• Robin Kills The Enemy
• Hiroko Yoda
• Phuc Dat Bich (pronunced: Phoo Da Bi)
https://en.wikipedia.org/wiki/Facebook_real-name_policy_controversy30

Enough history tells all
• Search pattern for person can reveal your identity
• If we have a log of all your web searches over some period, we can form a very good idea of who you are, and quite likely identify you
31

De-identification
• Given zip code, birth date and sex, about 87% of Social Security Numbers can be determined uniquely
• Those three fields are usually not considered PII (Personally Identifiable Information)
32

Netflix Prize• User_ID, Movie, Ratings, Date
• Merge with data from IMDb
• With only a few ratings, user could be linked across the two systems
• Their movie choices could be used to determined sexual orientation, even if all their IMDb reviews revealed no such information
• Bad already for only movie recommendation, so what about medical records ?
33

Four Types of Leakage
• Reveal identity
• Reveal value hidden attribute
• Reveal link between two entities
• Reveal group membership
34

Anonymity is Impossible• Anonymity is virtually impossible, with enough other
data
• Diversity of entity sets can be eliminated through joining external data
• Aggregation works only if there is no known structure among entities aggregated
• Face can be recognised in image data
35

Should we prevent sharing data ?
• If anonymity is not possible, the simplest way to prevent misuse is not to publish the dataset
• E.g. government agencies should not make public potentially sensitive data
• Yes access to data is crucial for many desirable purposes
• Medical data
• Public watchdog
36

Little game• For the next questions, assume the following approximate
numbers:
• Population of Brazil = 210,000,000
• Number of states in Brazil: 26
• Number of zip codes in the Brazil = 100,000
• Number of days in a year = 350
• Assume also that each person lives for exactly 75 years
• Finally assume that all distributions are perfectly uniform.
37

Little game
• How many people live in any one zip code in the Brazil?
38
Brazil population
Nb States Nb zip Code Nb days in a year
Life expectation
210,000,000 26 100,000 350 75

Little game
• How many people live in any one zip code in the Brazil? Answer: 2,100
39
Brazil population
Nb States Nb zip Code Nb days in a year
Life expectation
210,000,000 26 100,000 350 75

Little game
• How many people live in any one zip code in the Brazil? Answer: 2,100
• How many people in the Brazil share the same gender, zip code and birthday (but not birth year)?
40
Brazil population
Nb States Nb zip Code Nb days in a year
Life expectation
210,000,000 26 100,000 350 75

Little game
• How many people live in any one zip code in the Brazil? Answer: 2,100
• How many people in the Brazil share the same gender, zip code and birthday (but not birth year)? Answer: 3
41
Brazil population
Nb States Nb zip Code Nb days in a year
Life expectation
210,000,000 26 100,000 350 75
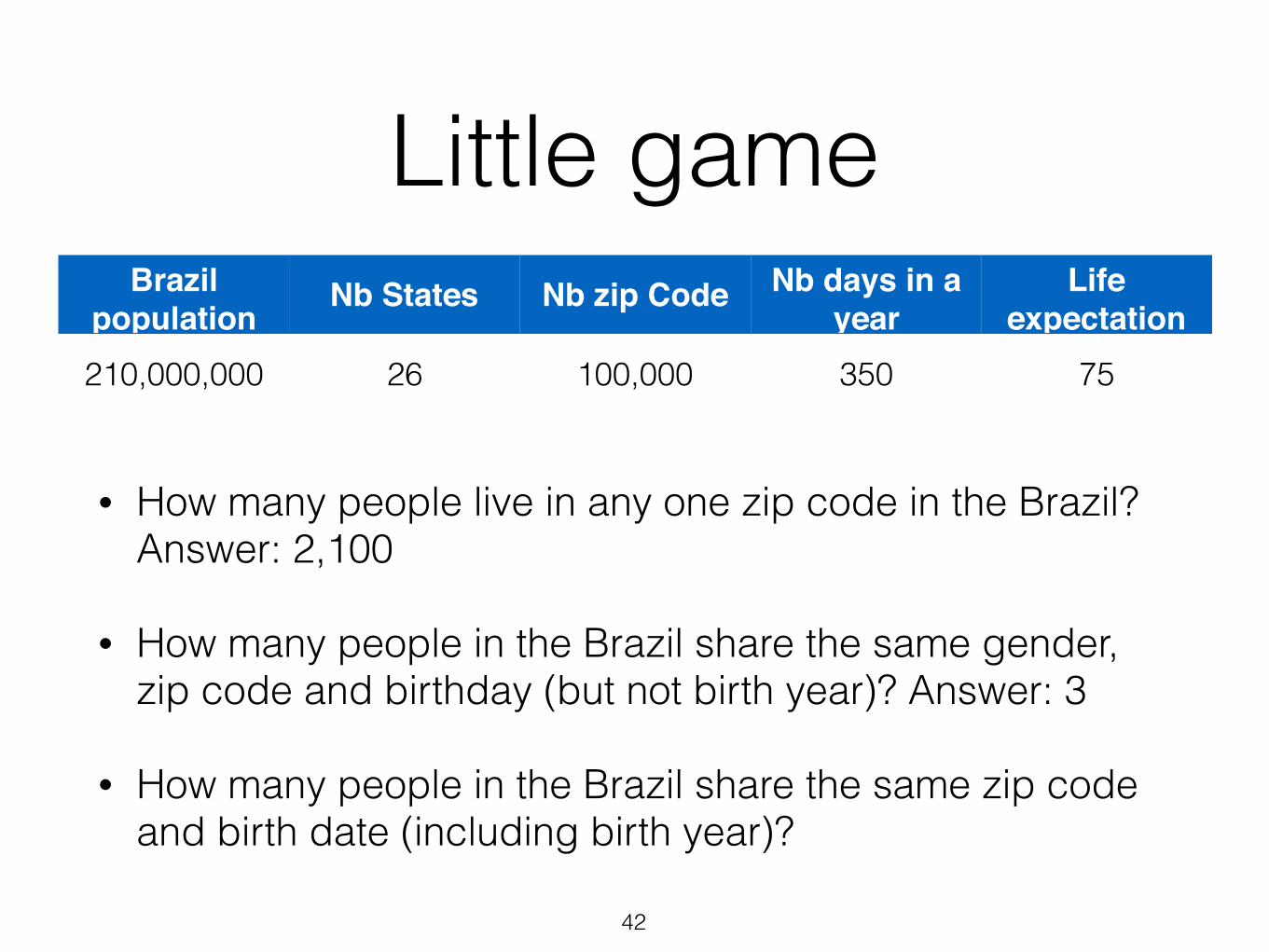
Little game
• How many people live in any one zip code in the Brazil? Answer: 2,100
• How many people in the Brazil share the same gender, zip code and birthday (but not birth year)? Answer: 3
• How many people in the Brazil share the same zip code and birth date (including birth year)?
42
Brazil population
Nb States Nb zip Code Nb days in a year
Life expectation
210,000,000 26 100,000 350 75
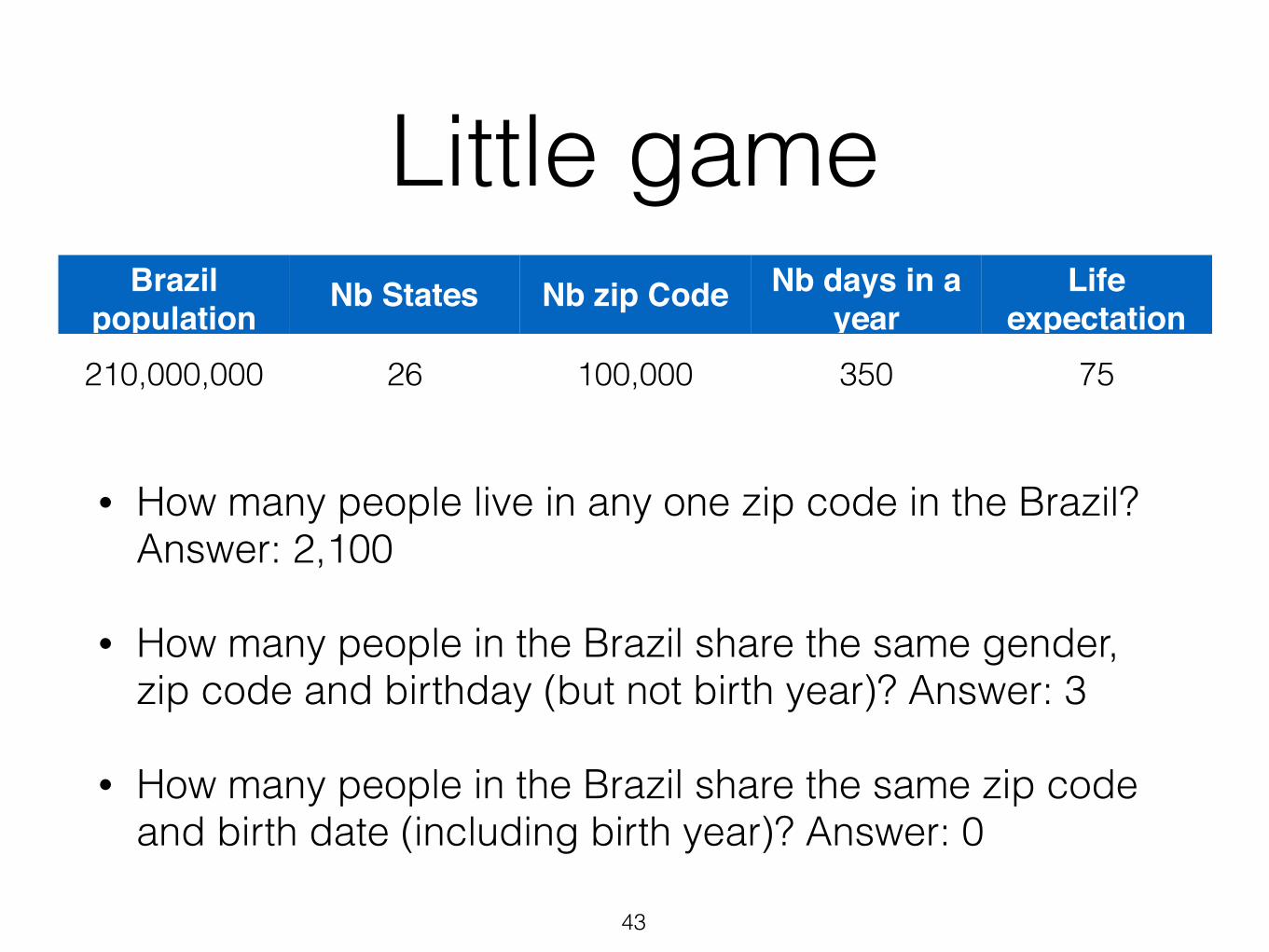
Little game
• How many people live in any one zip code in the Brazil? Answer: 2,100
• How many people in the Brazil share the same gender, zip code and birthday (but not birth year)? Answer: 3
• How many people in the Brazil share the same zip code and birth date (including birth year)? Answer: 0
43
Brazil population
Nb States Nb zip Code Nb days in a year
Life expectation
210,000,000 26 100,000 350 75

Data Validity
44

Validity
• Bad Data and Bad Models lead to bad decisions
• If decision making is opaque, results can be bad in the aggregate, and catastrophic for an individual
• What if someone has a loan denied because of an error in the data analysed
45

Sources of Error1. Choice of representative sample
2. Choice of attributes and measures
3. Errors in the Data
4. Errors in Model Design
5. Errors in Data Processing
6. Managing change
46

1) Choice of representative sample
• Twitterverse (young, tech-savvy, richer than average population)
• Should make sure that race, gender, age are well-balanced
47

Example: Google Labelling Error
• Due to poor representative sample, Google image recognition technology used to classify picture of black people as gorilla…
• You rarely can think of how your model can go wrong
• Most likely the training set contained very few dark faces
48

2) Choice of attributes and measures
• Usually limited to what is available
• Additional attributes can sometimes be purchased or collected
• Require cost to value tradeoff
• Still, need to think about missing attributes
49

3) Errors in the Data• In the US in 2012, FTC found that 26% of the
consumers had at least one error in their credit report
• 20% of these errors resulted in substantially lower credit score
• Credit reporting agencies have a correction process
• By 2015, about 20% still had unresolved errors
50

Third Party Data• Material decisions can often be made on the basis
of public data or data provided by third party
• There are often errors in these data
• Does the affected subject have a mechanism to correct errors ?
• Does the affected subject even know what data were used ?
51

Solutions
• Are data sources authoritative, complete and timely ?
• Will subject have access ?
• How are mistakes and unintended consequences detected and corrected ?
52

4) Errors in Model Design• Ending up with invalid conclusions even with perfect
inputs, perfect data going in…
• Many ways model could be incorrect
1. Model structure and Extrapolation
2. Feature Selection
3. Ecological Fallacy
4. Simpson’s Paradox
53

4.1) Model Structure and Extrapolation
• Most machine learning model just estimates parameters to fit a pre-determined model
• Do you know the model is appropriate ?
• Are you trying to fit a linear model to a complex non-linear reality ? Or the opposite ?
54
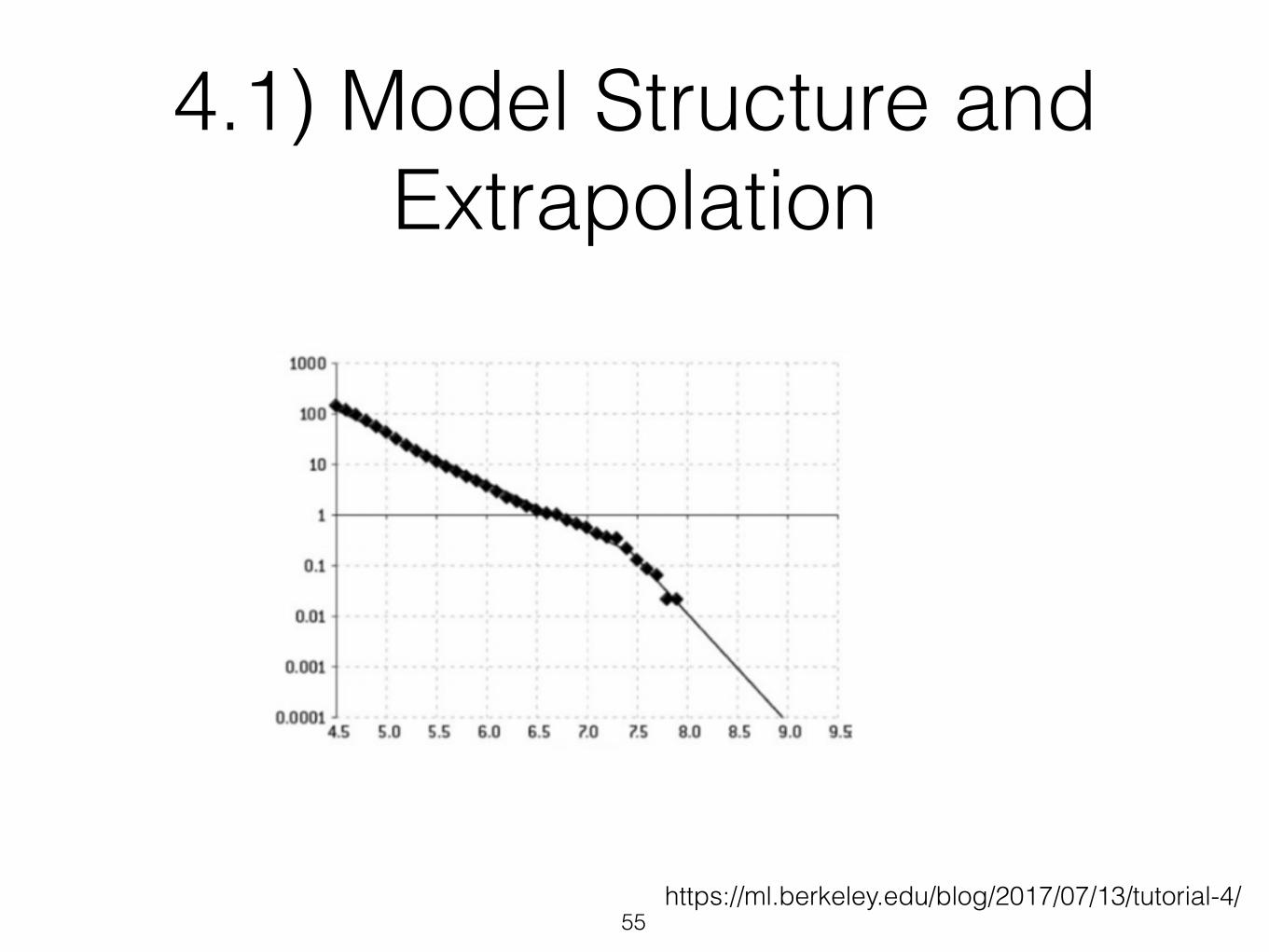
https://ml.berkeley.edu/blog/2017/07/13/tutorial-4/55
4.1) Model Structure and Extrapolation
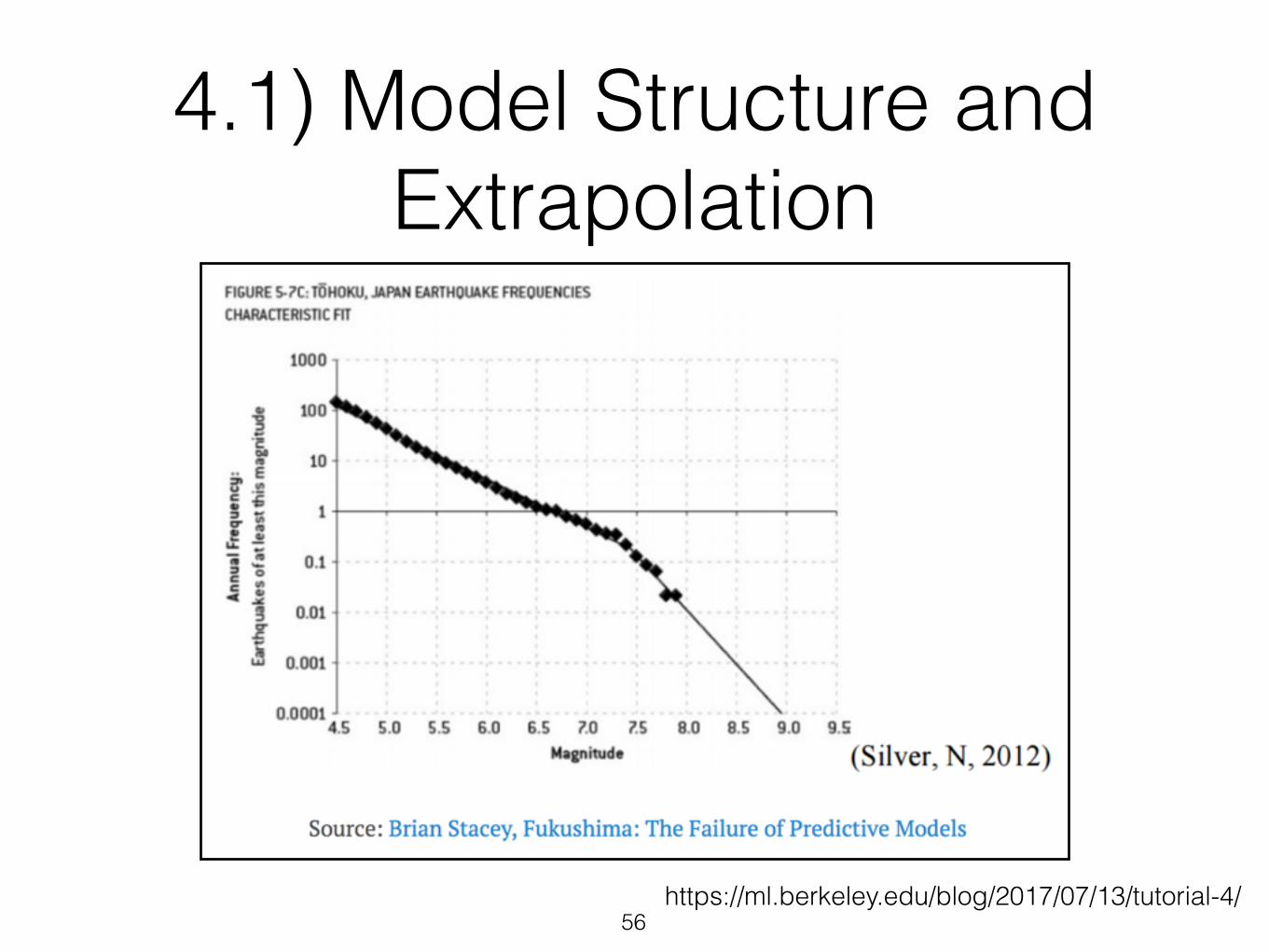
https://ml.berkeley.edu/blog/2017/07/13/tutorial-4/56
4.1) Model Structure and Extrapolation
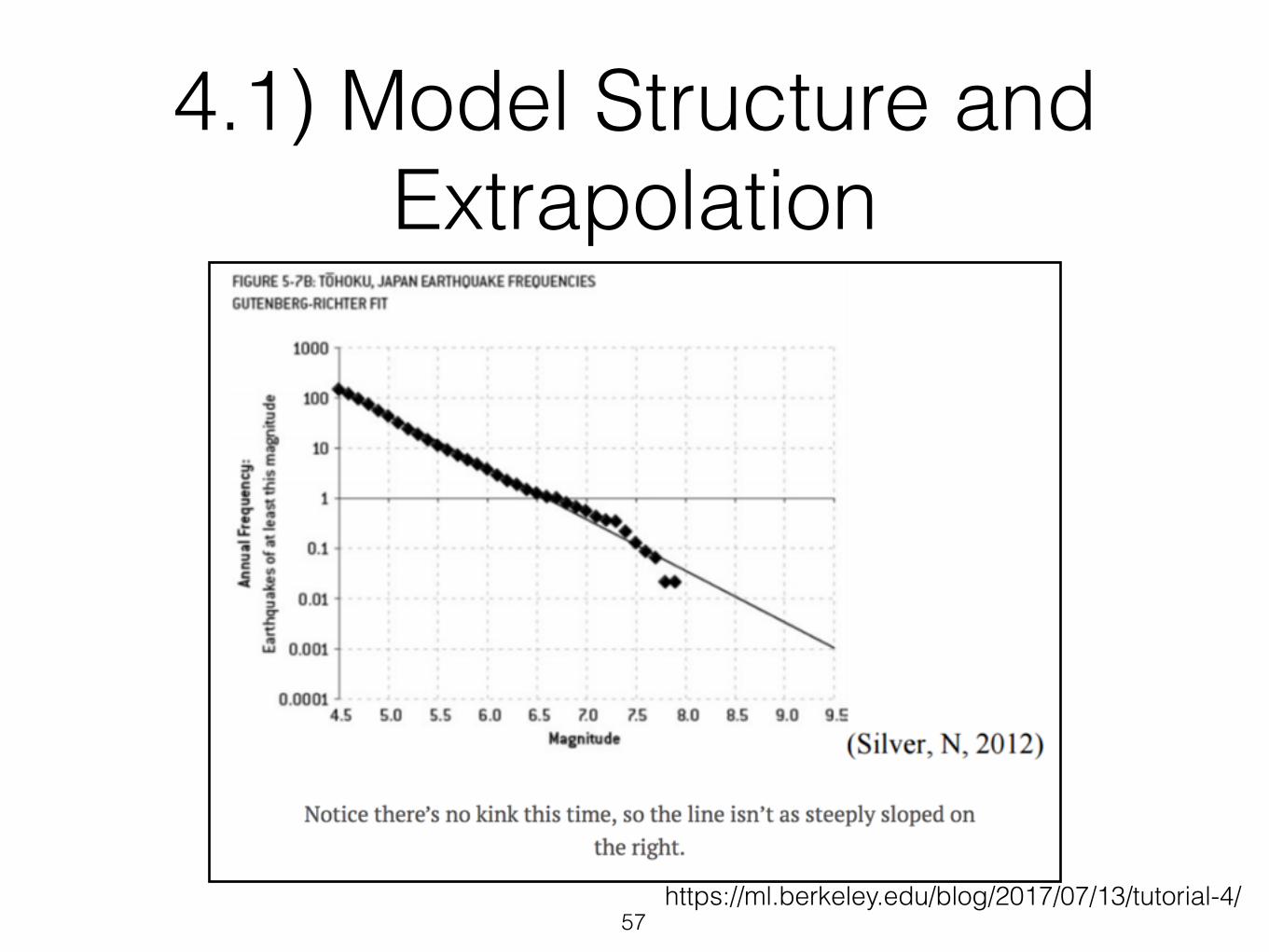
https://ml.berkeley.edu/blog/2017/07/13/tutorial-4/57
4.1) Model Structure and Extrapolation
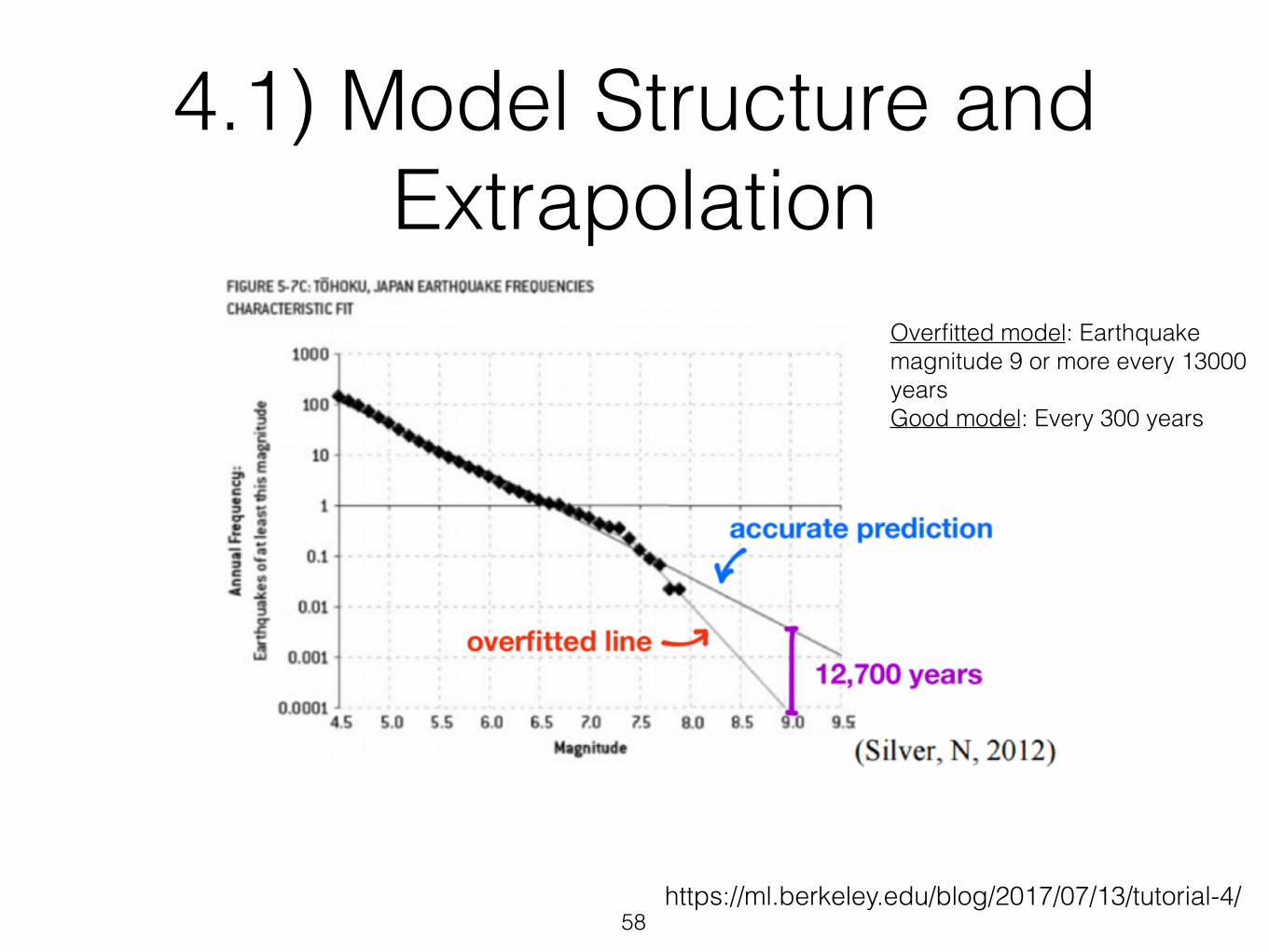
Overfitted model: Earthquake magnitude 9 or more every 13000 years Good model: Every 300 years
https://ml.berkeley.edu/blog/2017/07/13/tutorial-4/58
4.1) Model Structure and Extrapolation

4.2) Feature selection
• Did you know that taller people are more likely to grow beards?
59

4.2) Feature selection
• Did you know that taller people are more likely to grow beards?
• Women are generally shorter
• They don’t grow beards
60

4.3) Ecological Fallacy
• Analysing results for a group and assign results to individual
• Districts with higher income have lower crime rates
• => richer individual less likely to be a criminal
61

4.4) Other Game
Men Women
Easy University
Hard University
62
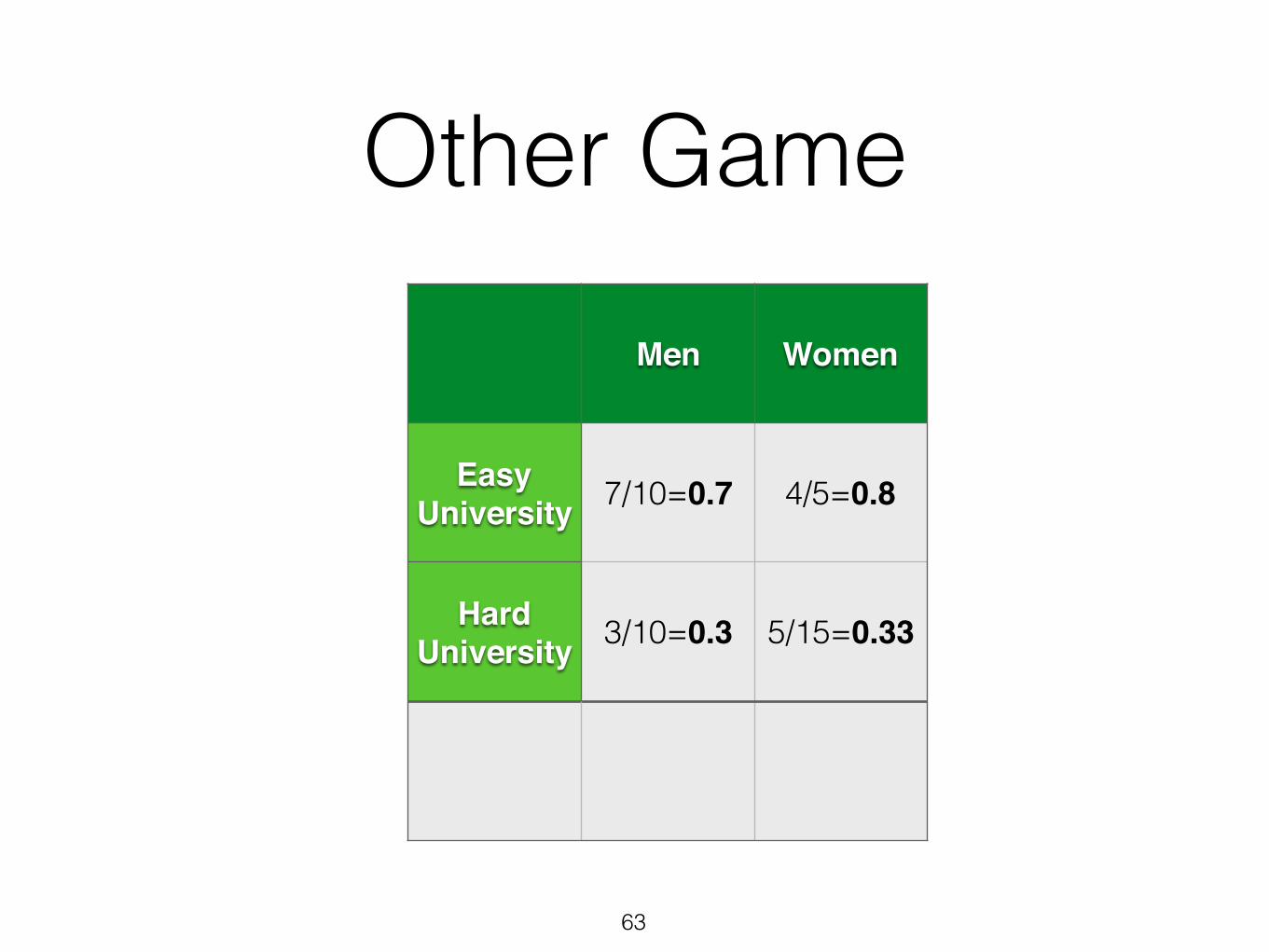
Other Game
Men Women
Easy University 7/10=0.7 4/5=0.8
Hard University 3/10=0.3 5/15=0.33
63

Other Game
Men Women
Easy University 7/10=0.7 4/5=0.8
Hard University 3/10=0.3 5/15=0.33
All 10/20=0.5 9/20=0.45
64

Simpson’s Paradox
Men Women
Easy University 7/10=0.7 4/5=0.8
Hard University 3/10=0.3 5/15=0.33
All 10/20=0.5 9/20=0.45
What happened ?
Aggregate data is reflecting the combination of two separate ratios
65

5) Error in Data Processing
• Wrong entry for example
• Bug in code
66

6) Managing Change• System change continuously
• Is analysis still valid?
• Most changes may not impact analysis
• But some do and we might not know which one
• Famous case of “Google Flu”
• Predictor worked beautifully for a while
• Then crashed
67

Campbell’s Law
• “The more any quantitative social indicator (or even some qualitative indicator) is used for social decision making, the more subject it will be to corruption pressures and the more apt it will be distort and corrupt the social processes it is intended to monitor” — Donal Campbell, 1979
68

Equivalent for DS
• If the metric are known, and they matter, people will work towards the metrics
• If critical analysis inputs can be manipulated, they will be
69

Algorithmic Fairness
70

Algorithmic Fairness• Can algorithm be biased?
• Can we make algorithms unbiased?
Is training data set representative of the population?
Is past population representative of future population?
Are observed correlations due to confounding processes?
71

Example: Algorithmic Vicious Cycle
• Company has only 10% women employees
• Company has “‘boys’ club culture” that makes it difficult for women to succeed
• Hiring algorithm trained on current data, based on current employee success, scores women candidates lower
• Company ends up hiring fewer women
72

Bad Analysis from Good Data
• Correlated attributes
• Correct but misleading results
• P-Hacking
73

Racial Discrimination• Universities prohibited by law from considering
race in admission
• Can find surrogate features that get them close, without violating the law
• Lender prohibited by law from redlining on race
• Can find surrogate features
• In general, proxy can be found
74

Discrimination Intent
• Big Data provides the technology to facilitate such proxy discrimination
• Whether this technology is used this way becomes a matter of intent
• It also provides the technology to detect and address discrimination
75
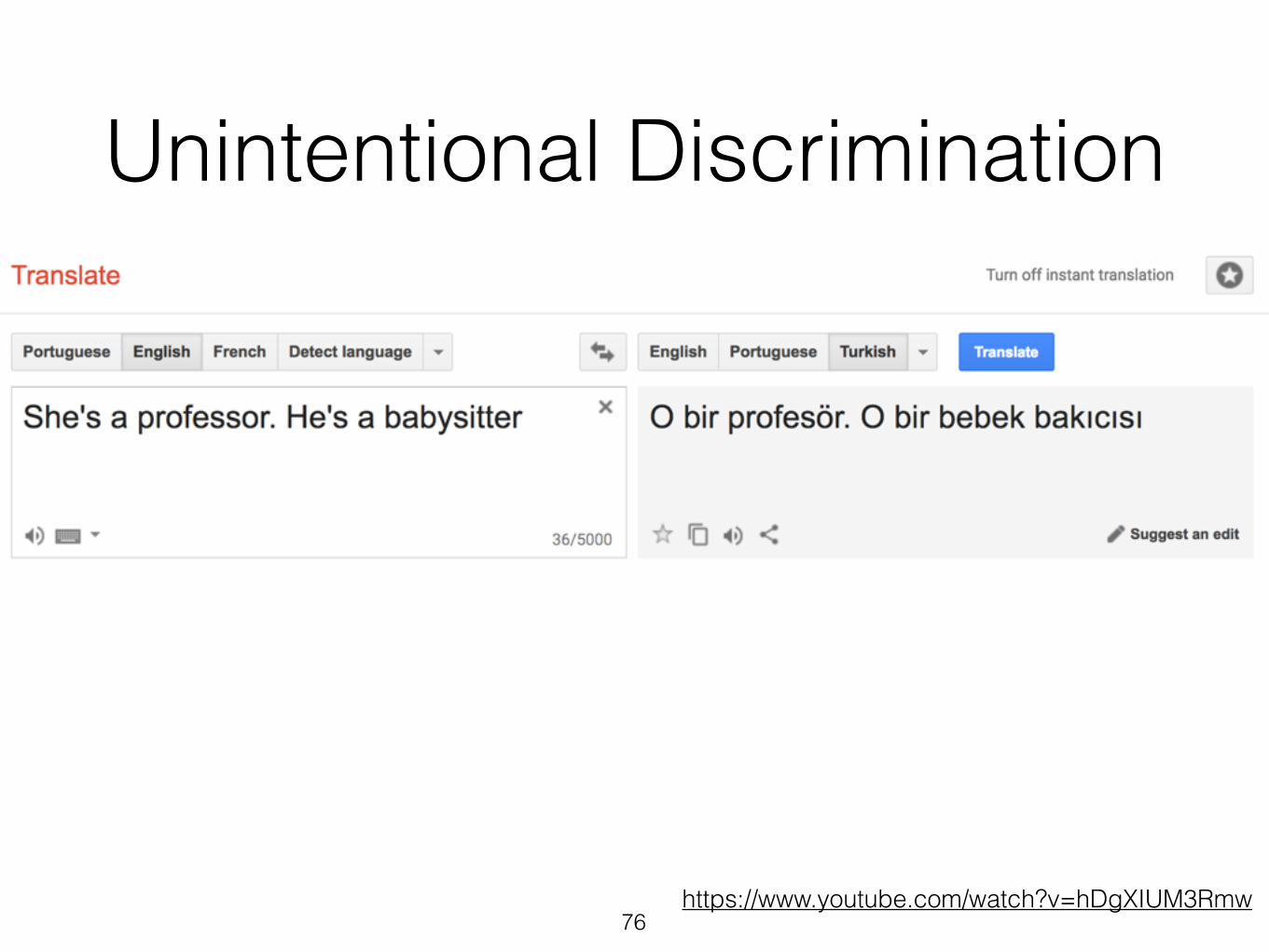
Unintentional Discrimination
76https://www.youtube.com/watch?v=hDgXIUM3Rmw
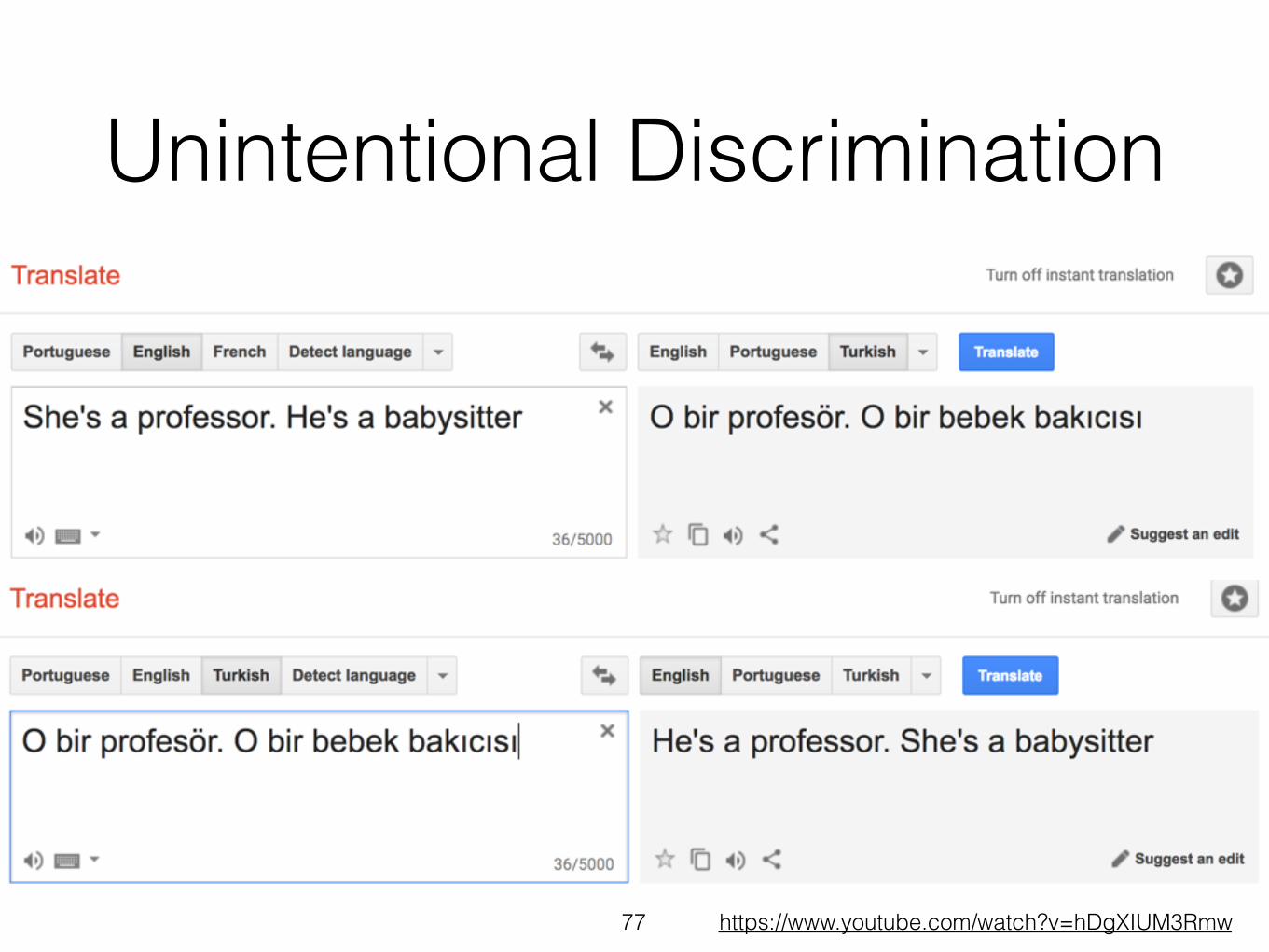
Unintentional Discrimination
77 https://www.youtube.com/watch?v=hDgXIUM3Rmw

Unintentional Discrimination
78
https://blog.conceptnet.io/2017/07/13/how-to-make-a-racist-ai-without-really-trying/

Unintentional Discrimination
79
https://blog.conceptnet.io/2017/07/13/how-to-make-a-racist-ai-without-really-trying/

Unintentional Discrimination
80
https://blog.conceptnet.io/2017/07/13/how-to-make-a-racist-ai-without-really-trying/
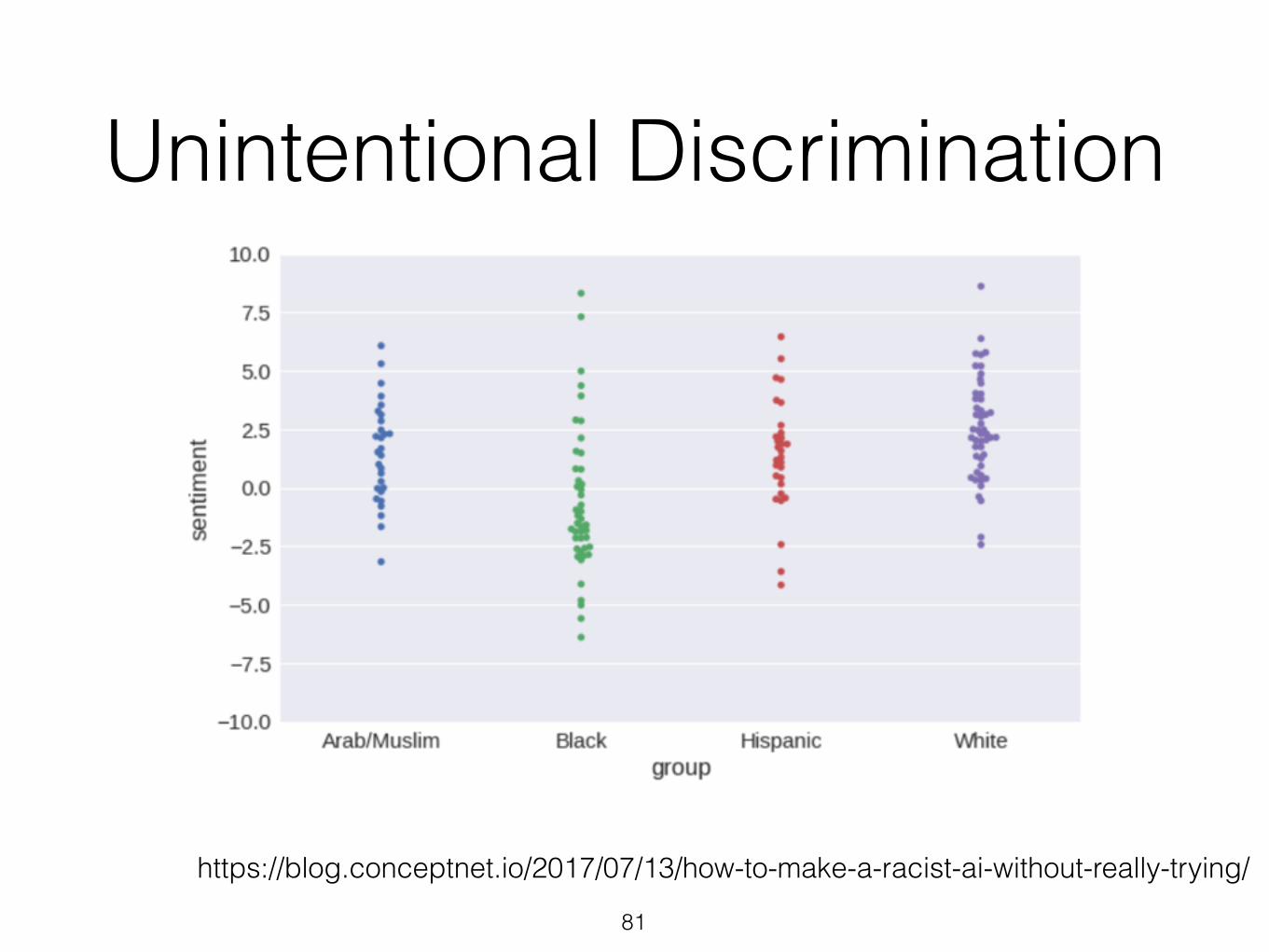
Unintentional Discrimination
81
https://blog.conceptnet.io/2017/07/13/how-to-make-a-racist-ai-without-really-trying/
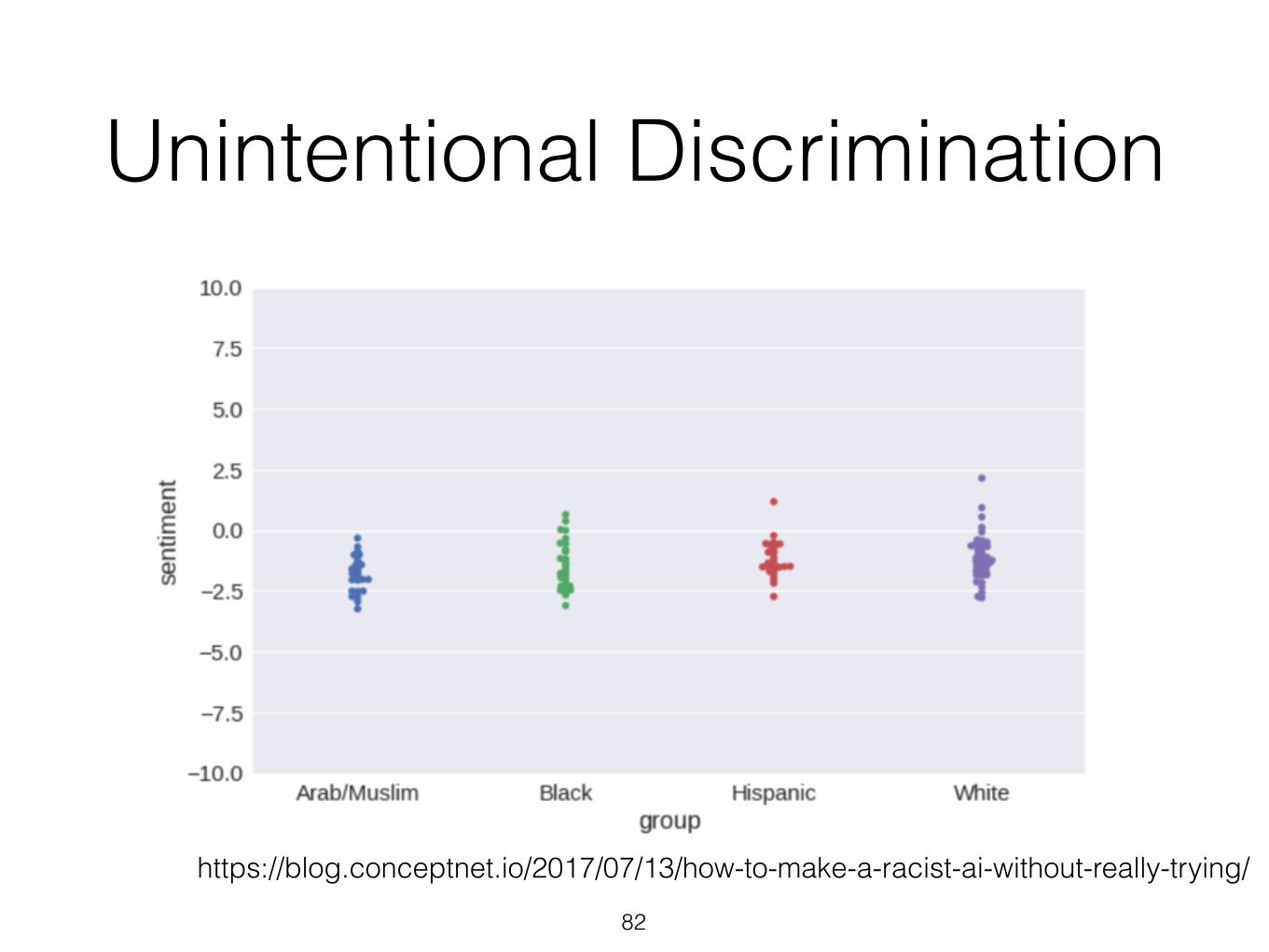
Unintentional Discrimination
82
https://blog.conceptnet.io/2017/07/13/how-to-make-a-racist-ai-without-really-trying/

Ossification / Echo chamber
• When optimising for a metric only, we might forget about some other issues
• Problem in Recommendation
84

Correct but misleading
85

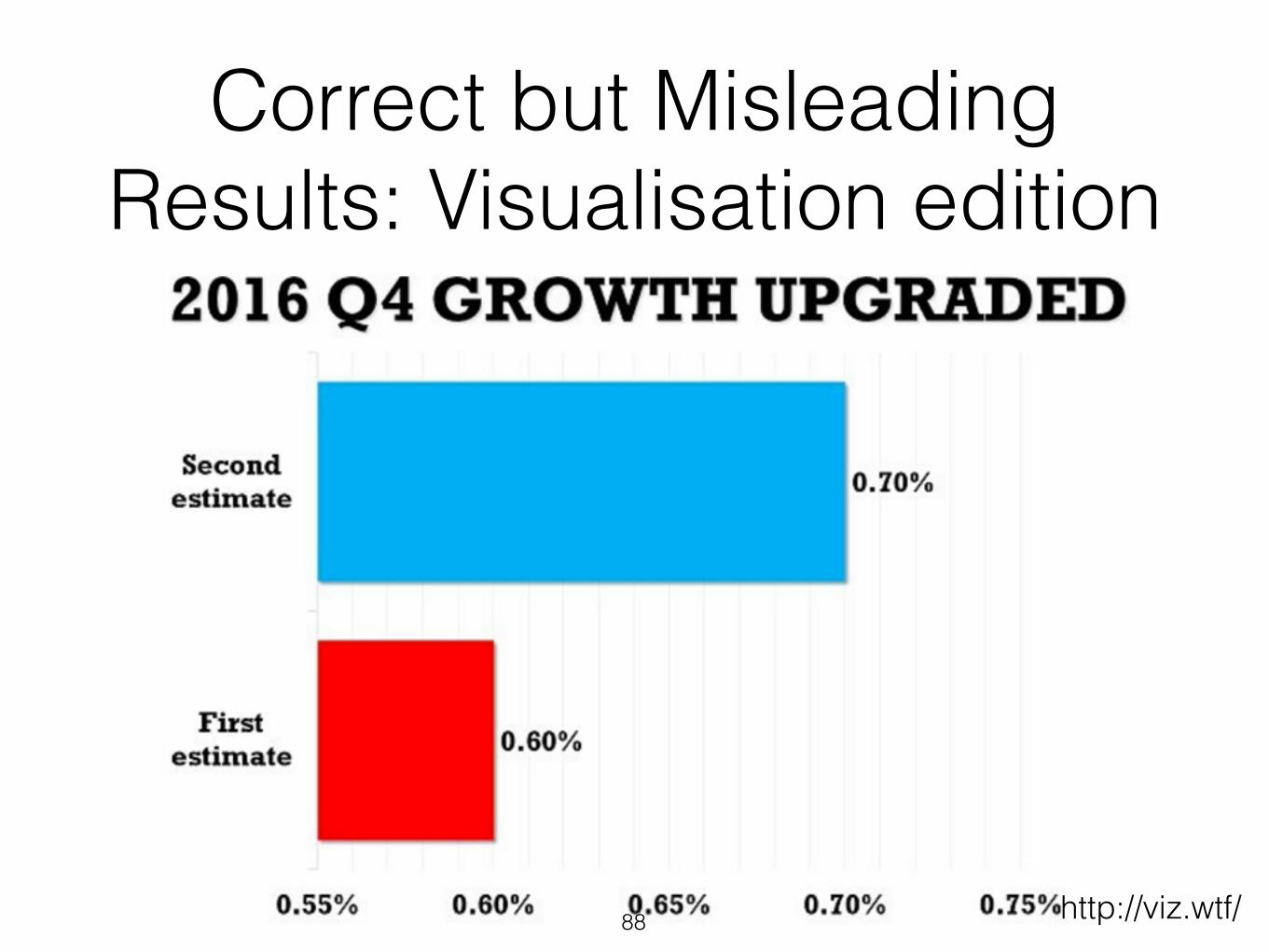
Correct but Misleading Results: Visualisation edition
86 http://viz.wtf/

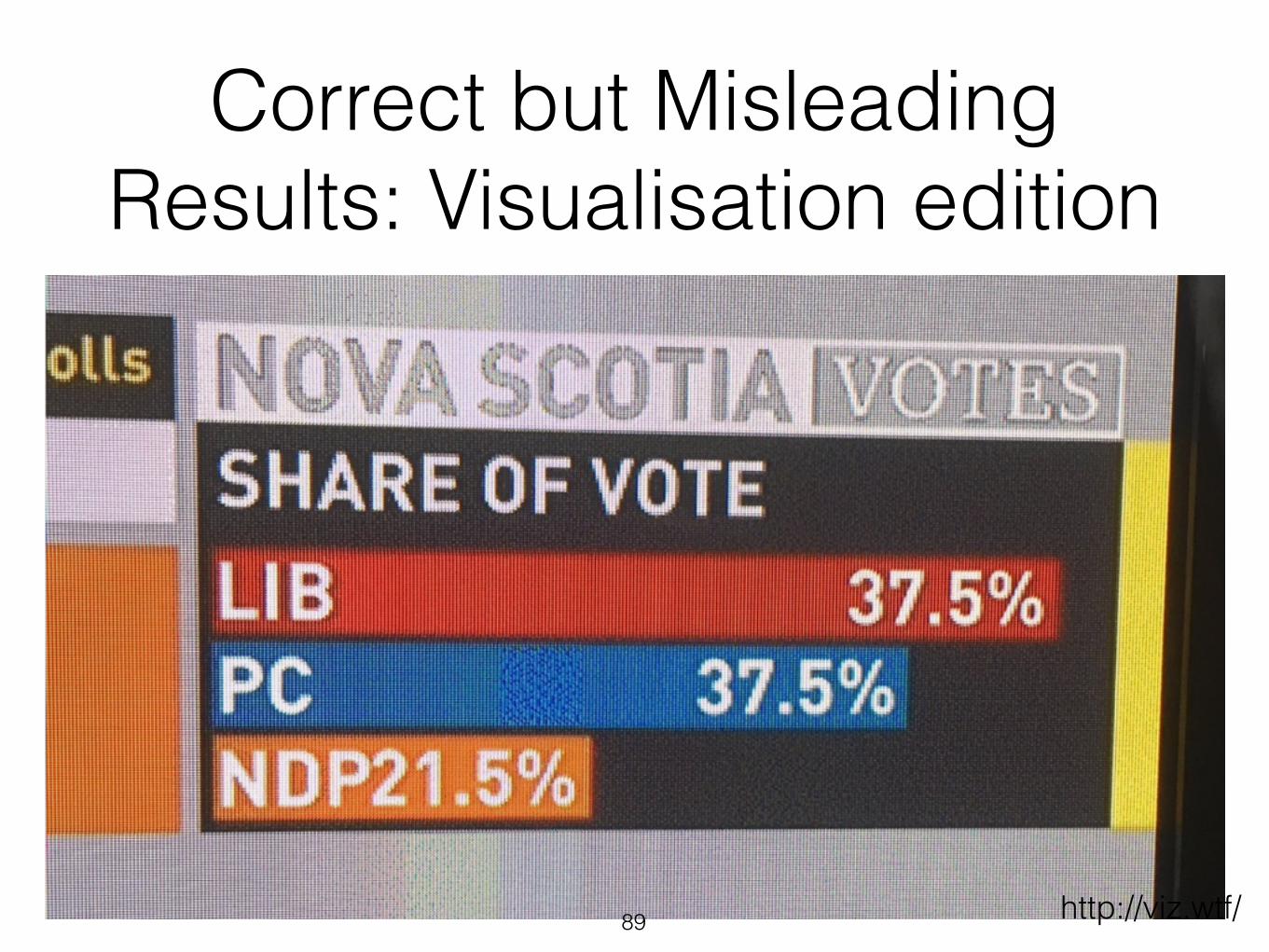
Correct but Misleading Results: Visualisation edition
87 http://viz.wtf/
Correct but Misleading Results: Visualisation edition
88 http://viz.wtf/
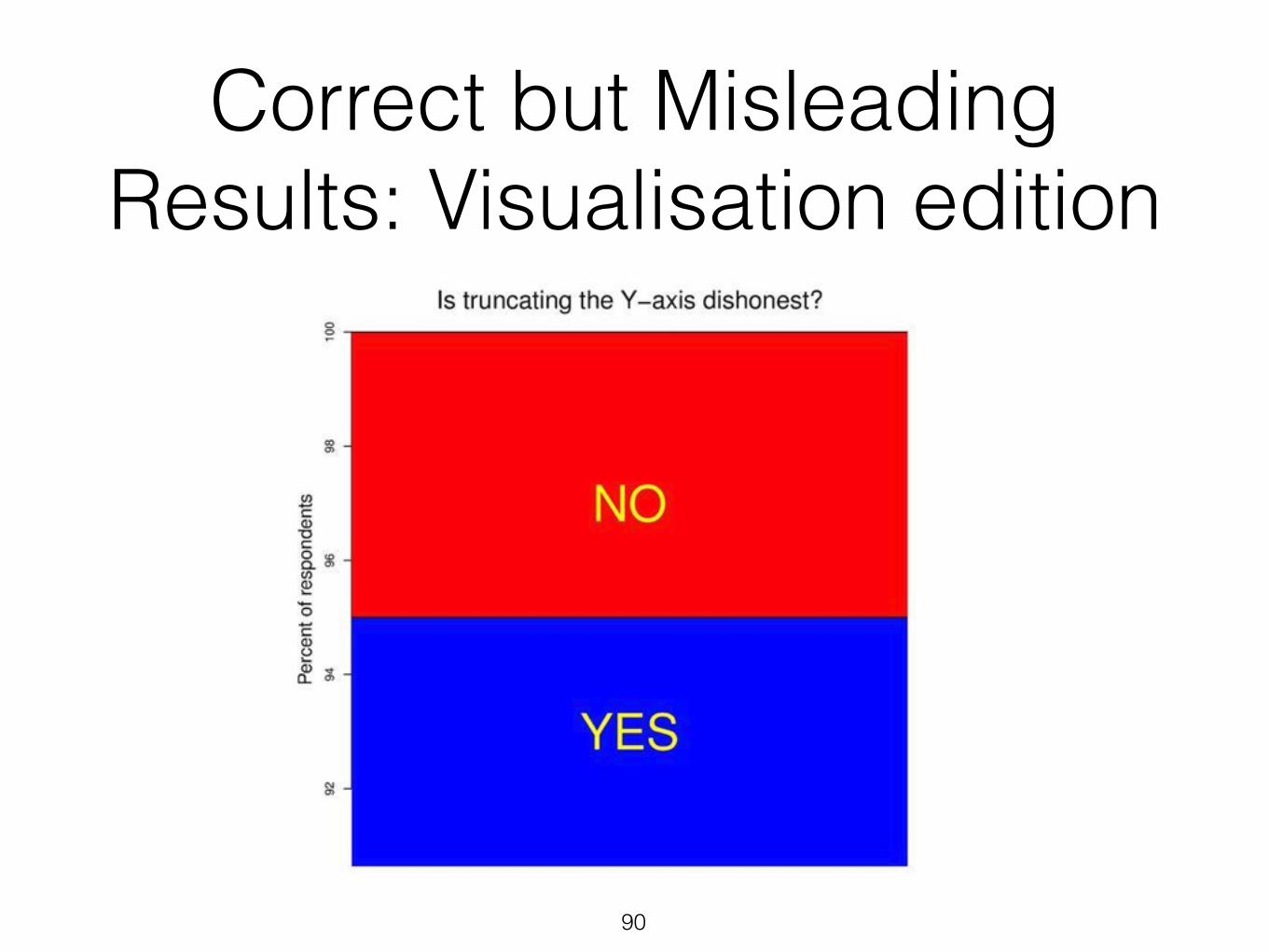
Correct but Misleading Results: Visualisation edition
89 http://viz.wtf/
Correct but Misleading Results: Visualisation edition
90

Correct but Misleading Results: Score Edition
• Hotel A gets average 3.2, with a mix of mostly 3 and 4
• Hotel B gets average 3.2, with a mix of mostly 1 and 5
91
Correct but Misleading Results: Score Edition
• Hotel A gets average 4.5, based on 2 reviews
• Hotel B gets average 4.4, based on 200 reviews
92
Correct but Misleading Results: Score Edition
• Hotel A gets average 4.5, based on 10 reviews
• Hotel B gets average 4.4, based on 500 reviews
93
Correct but Misleading Results: Score Edition
• Hotel A gets average 4.5, based on 10 reviews
• Hotel B gets average 4.4, based on 500 reviews
• Hotel A has 5 rooms, while hotel B has 500 rooms.
94
95
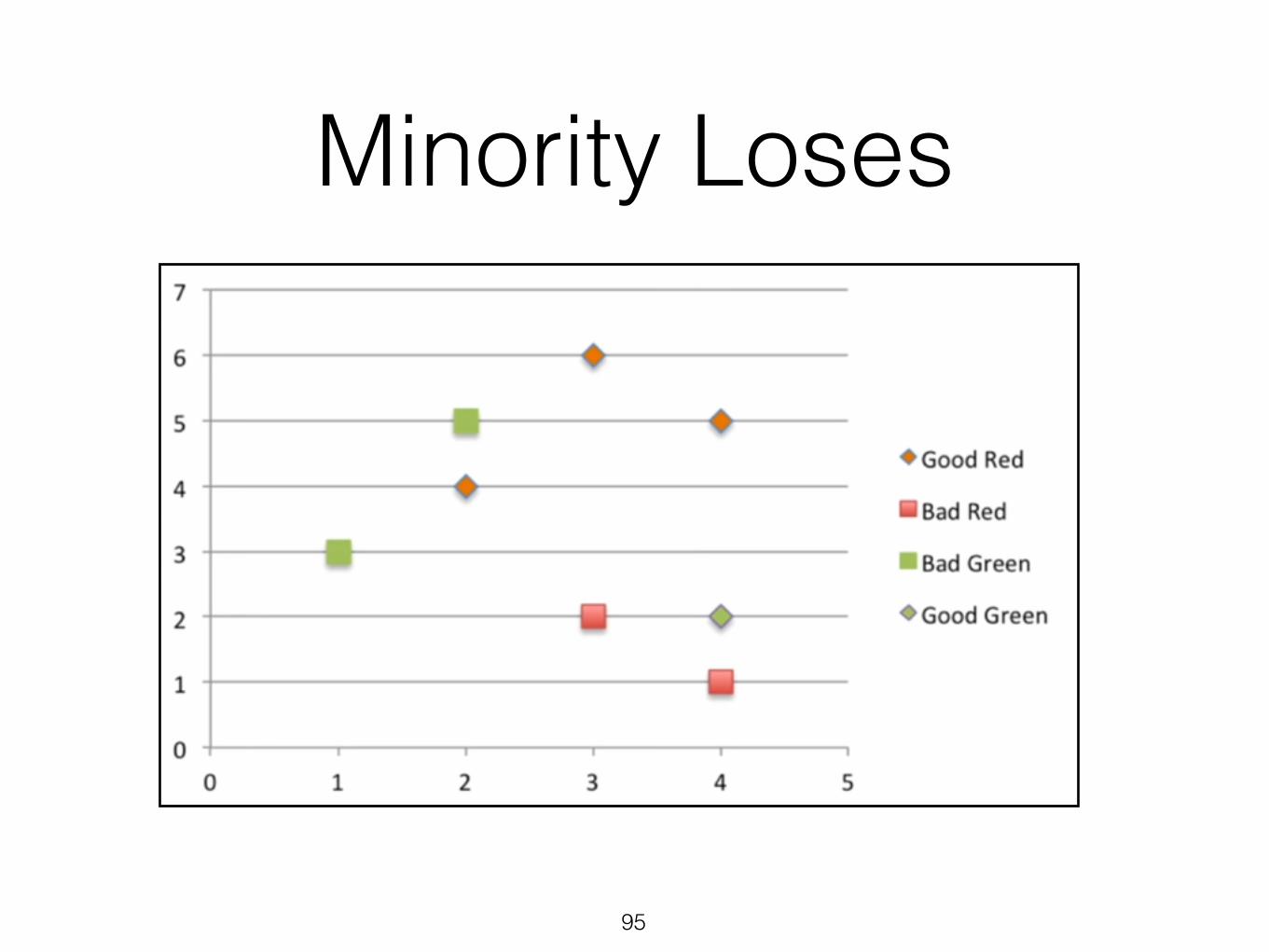
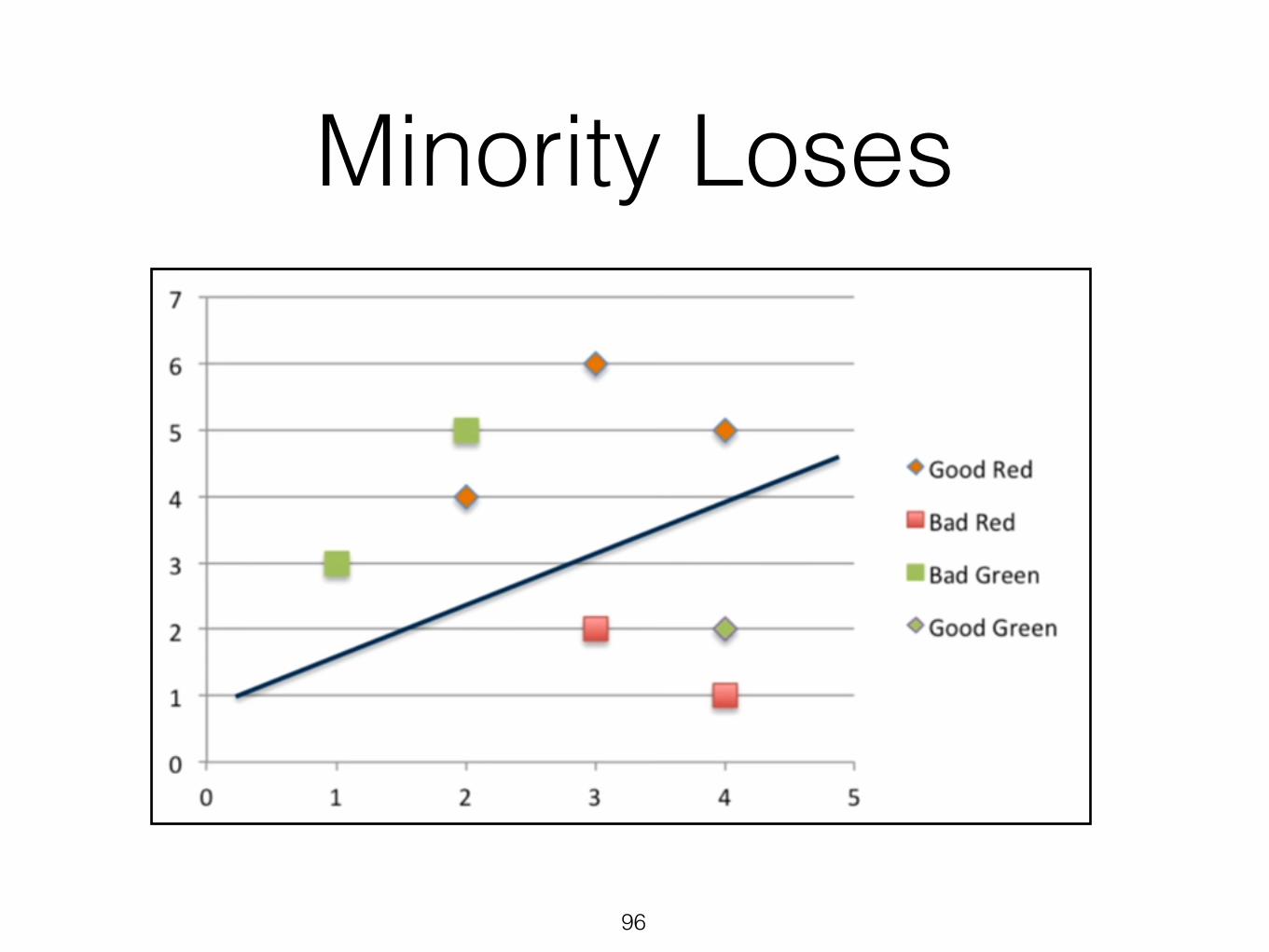
Minority Loses
96
Minority Loses

97
Diversity Suppression (Hiring)
• Use Data Science to find promising prospects
• Criteria are tuned to fit the majority
• Algorithm performs poorly on (some) minorities
• Best minority applicants are not hired

98
Diversity Suppression (Medical)
• Group A in Majority
• Drug is found effective with suitable significance level
• Patients in group B are also given this drug
• Group B in majority
• Drug is not found effective with sufficient significance over the whole population
• Drug is not approved, even though minority (group A) patients could have benefitted from it

P-Value Hacking
• Please read extensively about it before reporting any result saying that your experiment has a p value < 0.05
• Standard p-value mathematics was developed for traditional experimental techniques where you design the experiment first and then collect the data
99

Algorithmic Fairness Conlusion
• Human have many biases
No human is perfectly fair even with the best of intentions and biases are hard to detect sometime
• Biases in algorithms usually easier to measure, even if outcome is no fairer
100

Model interpretability
• Have a right to understand an algorithm decision
101

Code of Ethics
102

Code of Ethics• Doctor have Hippocratic oath
• Journalists, lawyers, etc…
• Regulation?
• Trade associations
• Companies lose if they annoy customers
• They self-regulate
103

Code of Ethics
• Can’t just take data and spit out what the algorithm spit out
• Need to understand the outcomes
• Need to own the outcomes
104

(One) Code of Ethics• Do not surprise
• Who owns the data?
• What can the data be used for?
• What can you hide in exposed data?
• Own the outcome
• Is the data analysis valid?
• Is the data analysis fair?
• What are the societal consequences?
105

Conclusion: Ethics Matter• Data Science has great power — to harm or to help
• Data Scientists must care about how this power is used
• Cannot hide behind a claim of “neutral technology”
• We are all better off if we voluntarily limit how this power is used
106

Questions?• Resources:
• https://www.youtube.com/watch?v=hDgXIUM3Rmw
• https://blog.conceptnet.io/2017/07/13/how-to-make-a-racist-ai-without-really-trying/
• https://www.edx.org/course/data-science-ethics-michiganx-ds101x-1
• https://www.socialcooling.com/
• http://www.fatml.org/
• http://viz.wtf
107https://creativecommons.org/licenses/by-nc-nd/4.0/

The rise of social cooling
• Like oil leads to global warming, data leads to social cooling
• If you feel you are being watched, you change your behaviour
• Your data is turned into thousands of different scores.
108

109
110

Social cooling• People are starting to realise that this ‘digital
reputation’ could limit their opportunities
• People are changing their behaviour to get better scores
111