Embed Size (px)
Citation preview

Aligning Sentences from Standard Wikipedia to Simple WikipediaWilliam Hwang; Hannaneh Hajishirzi;
Mari Ostendorf; Wei WuUniversity of Washington
Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human
Language Technologies
1
プレゼンテーション:小平 知範

Introduction• 課題: 英語の利用できるパラレルコーパスが小さかったり、 ノイズ混じりのものが多い
• 手法: simpleとstandardのWikipediaを貪欲法で対の文を整列 相対的に並んでいると仮定しない Wikitionaryベースの類似度計測を用いる
• 結果: 先行研究の手法よりかなりよくなった
2

BackGround• Sentence-LevelScoring 1.Wikipedia alignment(Kauchak, 2013)の、各文の単語の tf.idfスコアの代表ベクトル間のcos距離として類似度を計算 2.単語レベルの意味類似度のスコアに依存する手法
• Sequence-Level Search1.(Zhu et al., 2010)simpleとstandardの記事間のアライメントは 制約なしに計算され、スコアが閾値を超えていれば文は並べられる。2.連続てきな制約をつかって文アライメントを計算する(Coster and Kauchak, 2011: Bazilay and Elhadad)
3

Simplification DatasetsManually Annotated
• standard Wikipediaの記事中のすべての文にたいして対応するsimpleの記事の文をアノテーション
4
• アノテータはネイティブの大学生(時給制)Wikipediaからランダムに46記事のペアを選択total67,853文(277 good, 281 good partial, 117 partial and 67178 bad)kappa係数0.68(13% dual annotated)
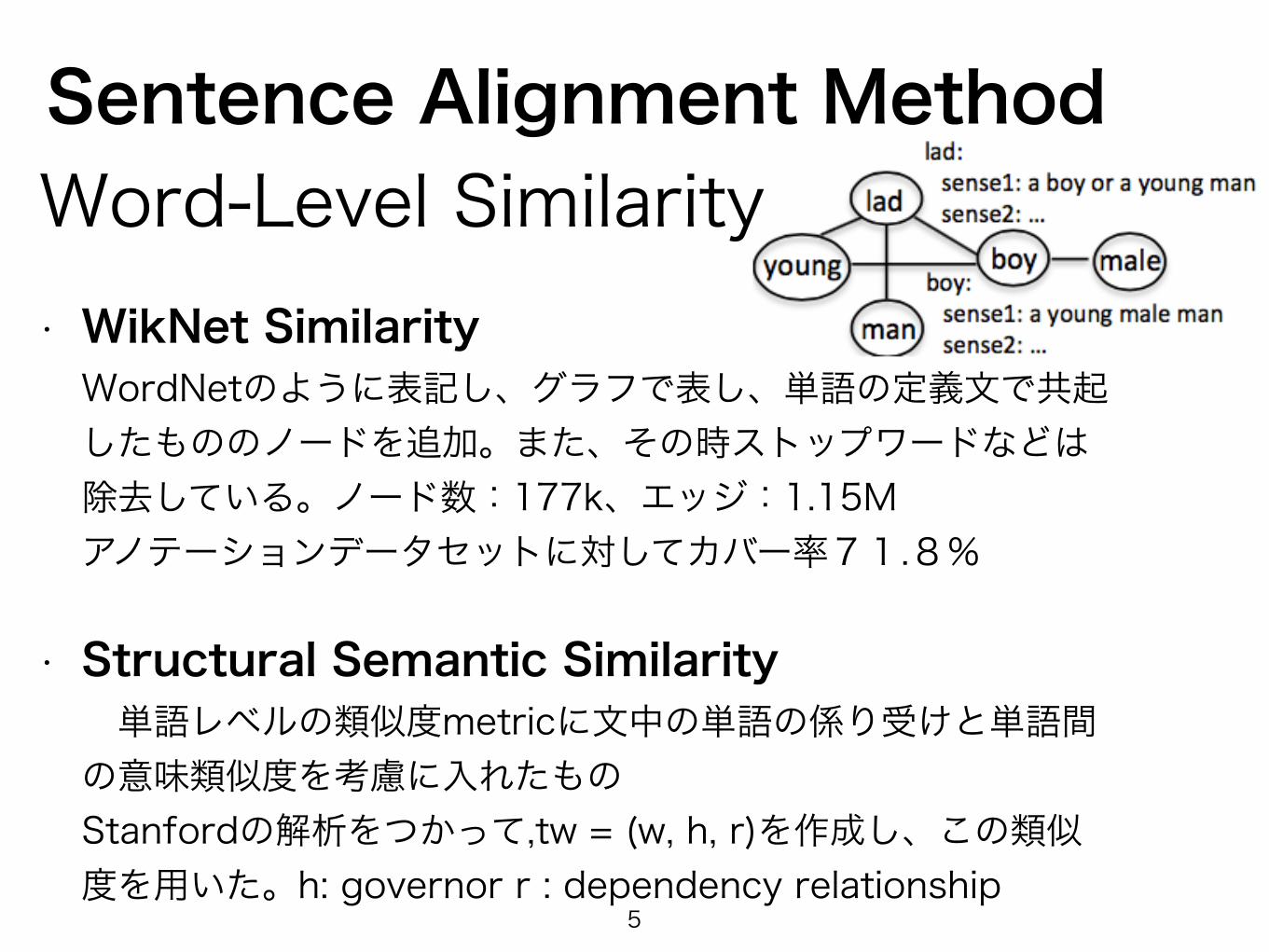
Sentence Alignment Method Word-Level Similarity• WikNet Similarity WordNetのように表記し、グラフで表し、単語の定義文で共起したもののノードを追加。また、その時ストップワードなどは除去している。ノード数:177k、エッジ:1.15Mアノテーションデータセットに対してカバー率71.8%
• Structural Semantic Similarity 単語レベルの類似度metricに文中の単語の係り受けと単語間の意味類似度を考慮に入れたものStanfordの解析をつかって,tw = (w, h, r)を作成し、この類似度を用いた。h: governor r : dependency relationship
5

Sentence Alignment Method Greedy Sequence-level Alignment
• 貪欲法をつかって、simpleとstandardの文を一対一でマッチさせる必要が有る ・simple記事のすべての文Sjとstandard記事の すべての文Aiの文レベル類似度のスコアを計算 ・最も類似しているペアarg max s(Sj, Ai)を選択
• 多くのsimple文がstandard文のfragmentにマッチ・Stanfordの構文解析木からfragmentを抽出 ・それから、SjとAiとを計算し、同様にAikも計算 ・同じアルゴリズムを用いてsimple文と standard文かfragmentsを並べた。
6

Experiments: Results• 人手でアノテーションしたデータの各記事に対しstandardとsimpleの文すべてのペアに対し提案手法、先行研究の手法(ベースライン)を行った。*前処理としてタイトル等を除去、stanfordCoreNLPで解析
• ベースラインUnconstrained WordNet(Mohler and Mihalcea, 2009)Unconstrained Vector Space(Zhu et al., 2010)Ordered Vector Space (Coster and Kauchak, 2010)
7

Result Comparison to Baseline
8

Experiment: Automatically Aligned Data• 類似度スコアで、simple,standardの文のペアを並べたパラレルコーパスを作成
• 22kのsimple,standardの記事から文を並べた。
• 閾値を0.45に設定した文のペアを公開 *F1(precision,recall)を元に、 閾値0.67で、good match (150k) 閾値0.53で、good partial match(130k) 閾値0.45で、uncategorized match(110k) これ以下の51.5million potential matches はカット
9

Conclusion and Future Work
• 新しい単語レベルの類似度(using Wikitionary and dependency structure)と貪欲法を使った、テキスト平易化のための文アラインメントの方法を紹介
• 実験では、先行研究のベースラインを上回った
• 人手で並べたものと、自動で並べたデータを公開
• Future Work 作ったデータセットを使って、テキスト平易化の開発 アライメント技術の改善 フレーズアラインメント技術の改善
10





























