Embed Size (px)
Citation preview

CENTRAL PLACES IN WIKIPEDIA
Carsten Keßler Department of Geography & Center for Advanced Research of Spatial Information · Hunter College · CUNY
http://carsten.io · @carstenkessler
https://flic.kr/p/e6Spjs

Fifth-order center
Fourth-order center
Third-order center
Second-order center
First-order center

Fifth-order center
Fourth-order center
Third-order center
Second-order center
First-order center

Fifth-order center
Fourth-order center
Third-order center
Second-order center
First-order center

Fifth-order center
Fourth-order center
Third-order center
Second-order center
First-order center

Fifth-order center
Fourth-order center
Third-order center
Second-order center
First-order center

Fifth-order center
Fourth-order center
Third-order center
Second-order center
First-order center

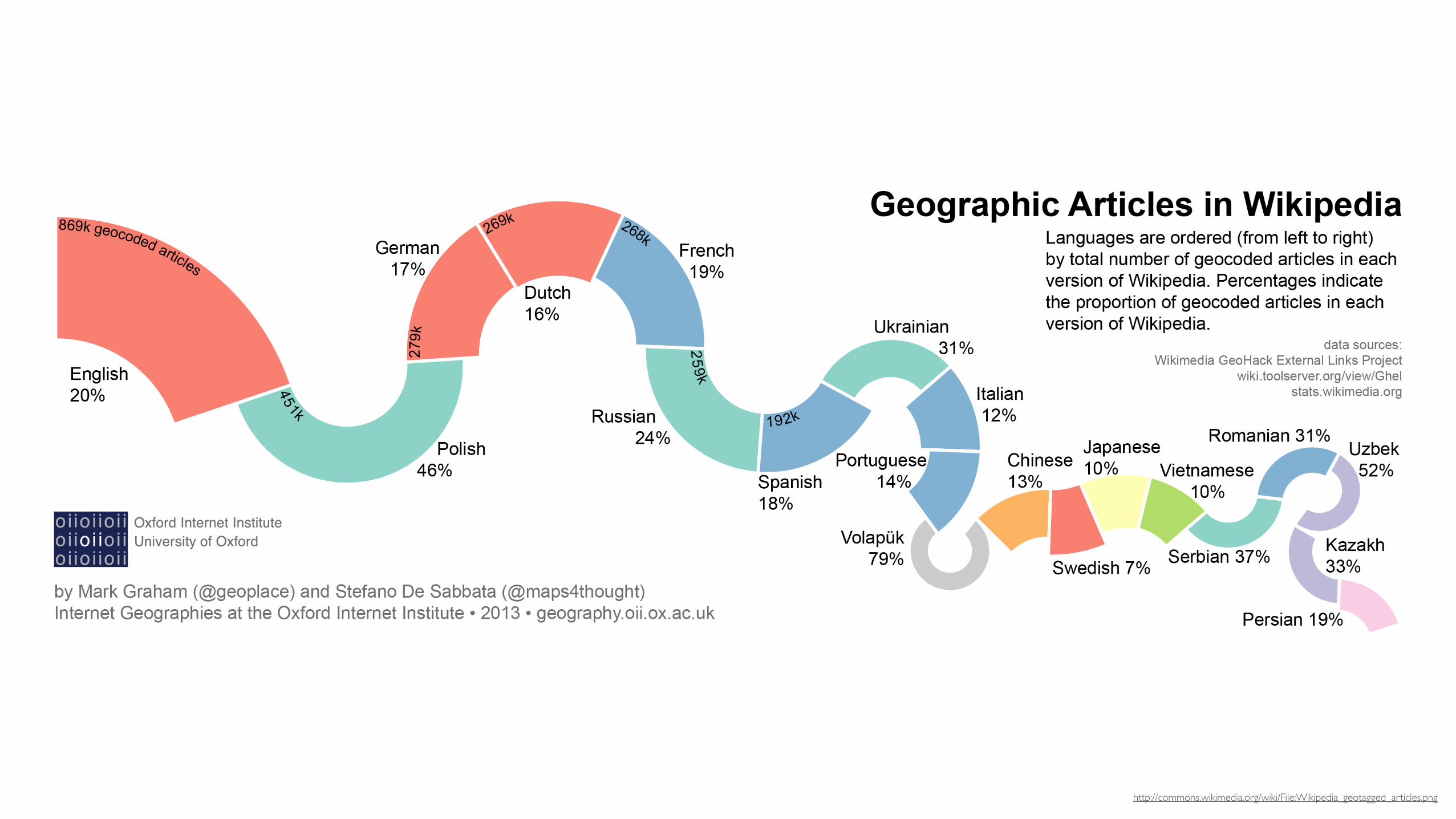
http://commons.wikimedia.org/wiki/File:Wikipedia_geotagged_articles.png


WHAT ABOUT RELATIONSHIPS?


DOES THE LINK STRUCTURE IN WIKIPEDIA REFLECT CENTRAL PLACE THEORY?

STUDY AREA

DATA PROCESSING APPROACH
• List of places in bounding box queried from DBpedia
• Pages for places exported via Wikipedia API
• Link structure for a place scraped from pages
• Results fed into MongoDB
• Turned into network structure based on CPT and link counts

OUTPUT
• Collection of pages:
• URL
• location
• Collection of links:
• from URL
• to URL
• number of links
• number of mentions
• distance

SOME STATS…
• 242,896 pages in
bounding box
• 1,517,772 unique links
from page a to page b
1. United States
2. California
3. Ohio
4. New York
5. Illinois
6. Wisconsin
7. Indiana
8. Texas
9. Florida
10. Kentucky
199,605
35,990
29,598
28,928
27,600
27,125
26,893
25,132
20,981
17,776
References Page

LINKING DISTANCE
• Only nearby places link to each other really often

REVEALING THE CENTRAL PLACE STRUCTURE OF A PLACE P
1. Retrieve all links pointing to P.
2. Remove all links that either of:
1. “children” of P in the admin hierarchy
2. not some kind of settlement
3. From the remaining candidates, keep the top 6 closest
places according to their weighted distance
4. Rinse and repeat (recursion)

DISTANCE WEIGHTING
• Idea: Decrease distance for “important” pages
distanceweighted =distance
references

SOME EXAMPLES







CONCLUSIONS AND NEXT STEPS
• Link structure seems to (mostly) reflect what is going on in
the real world
• Need to try different approaches, compare results
• Why are the results different from CPT?
• And how can we measure this?
• A more efficient computational approach is required

Carsten Keßler Department of Geography & Center for Advanced Research of Spatial Information · Hunter College · CUNY
http://carsten.io · @carstenkessler
https://flic.kr/p/e6Spjs
THANK YOU!





























