Embed Size (px)
Citation preview

Defending Yarbus: Eye movements reveal observers’ task
ALI BORJI, LAURENT ITTI
UNIVERSITY OF SOUTHERN CALIFORNIA

What do the eyes tell us?Yarbus’s hypothesis:
Eye movements can result from top-down attention, focusing on most informational parts of a scene
As a result, gaze patterns can reveal information about
a person’s intended task or mental state

Yarbus’s proof of concept

Research Question 1: is Yarbus right?
Several quantitative studies have come out in support of Yarbus, but quantitative counterexamples exist as well.
Furthermore, several supporting studies are subject to bias.
Can a non-biased experimental procedure support Yarbus’s claim by both disproving a counterexample and independently verifying the hypothesis?

RQ 2: Which details matter? What image/observer/procedural details are important for decoding task from gaze patterns?
Does spatial information matter? What about saliency?
What types of tasks are indistinguishable?
How much variation exists between different images and different observers, and why?

2 Experiments, 1 Procedure Experiment 1: Reanalyze the experimental data from a counterexample to consider their evaluation procedure.
Experiment 2: Apply counterexample’s nonbiased experimental procedure to a new set of images (including Yemus’s test) and observers. Does the hypothesis hold?

2 Experiments, 1 Procedure Experimental Procedure:
◦ Subject is asked to answer a question given an image ◦ ie what are the relationships of the people in the picture?
◦ Each person views a new image for each task (no memory bias)◦ Each image is used for multiple tasks (no stimulus bias)
Evaluation Procedure: Classification by features◦ Counterexample:
◦ Visual features only (no spatial)◦ Linear Classifiers
◦ Here: include spatial information, try nonlinear classifiers

Data Collection Experiment 1: paper’s authors gave Borji and Itti their experimental data
◦ 17 observers, 20 images, 4 tasks
Experiment 2: Borji and Itti recruit USC students and create their own dataset based on images like The Unexpected Visitor. They use Yarbus’s tasks.
◦ 21 students, 15 images, 7 tasks

Sample image examples Experiment 1: Experiment 2:

Experiment 1 Results Given spatial information (NSS maps) and a boosting classifier, task decoding accuracy is increased to slightly but significantly above chance.
Why did original authors not find significant results?
Proposed reasons:
1) Classification method matters
2) Image content matters
3) Spatial nature of fixations matter

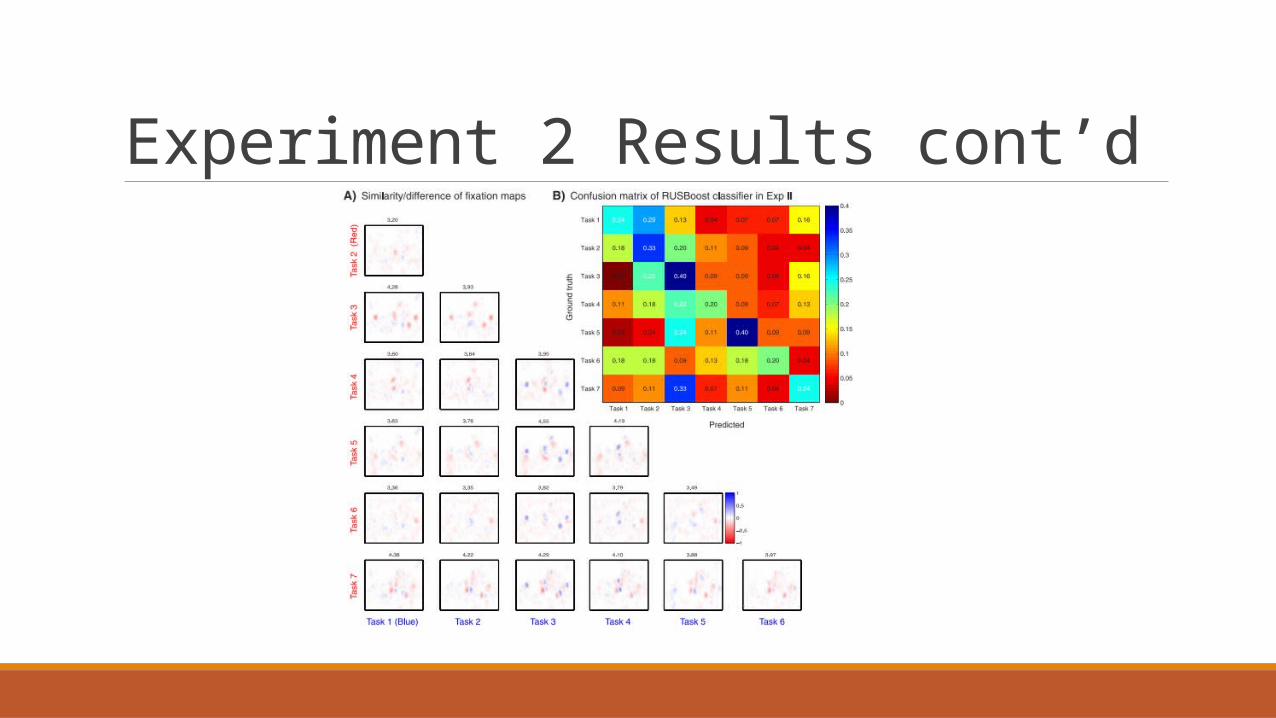
Experiment 2 Results Tasks:
1) Free examination
2) Subjects’ wealth
3) Subjects’ age
4) Activity prior to visitor’s arrival
5) Remember clothing
6) Remember persons and objects’ locations
7) Estimate how long visitor was away
Experiment 2 Results cont’d

3 main factors for task-decoding accuracy
1) Task set separability : little overlap between tasks
2) Stimulus set : images must have enough information for answering the question
3) Observer knowledge : observer must have enough external information to strategize

SummaryExperiments 1 and 2 support Yarbus’s hypothesis for top-down regulation of eye movements and refute a counterexample.
They DO NOT guarantee that we can decode the task a person is performing by their gaze patterns. However, they do help provide guidelines for task decoding success/failure.

Why do we care? MD2K:
◦ Gaze can provide insight to a user’s intentions, and provide context for their external state.◦ Experiments like these can help us define what kinds of task or mental state-decoding may be possible,
and their potential difficulty level.
Paper-provided examples:◦ Task detection
◦ Predicting intention prior to action◦ Learning style, expertise level
◦ Mental state detection◦ Diagnosis: ADHD, autism ◦ Confusion, concentration, arousal, deception

Critique◦ Small datasets◦ Static images – how do these patterns differ for videos?◦ Would like to see a better definition for task-separability





























