Embed Size (px)
Citation preview

MultimodalPerson Discoveryin TV Broadcast
Hervé Bredin / Camille Guinaudeau / Claude Barras

Motivation
• Huge TV archives are useless if not searchable
• People ❤ people
• Need for person-based indexes
2
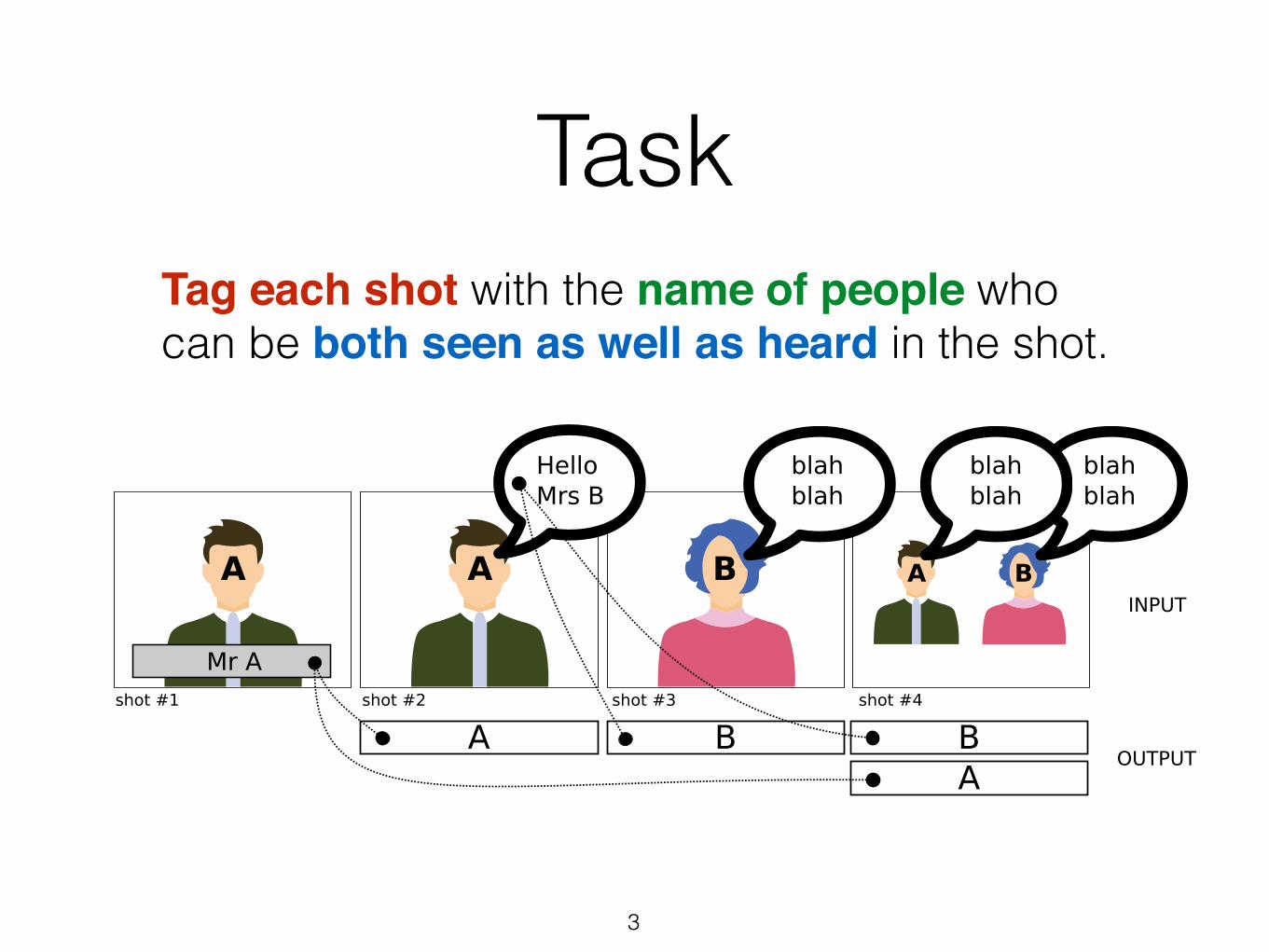
Task
A BA
HelloMrs B
Mr A
blahblah
shot #1 shot #2 shot #3
A B B
blahblah
shot #4 speaking face
evidence
A B
blahblah
A
text overlay
speechtranscript
INPUT
OUTPUT
LEGEND
3
Tag each shot with the name of people who can be both seen as well as heard in the shot.
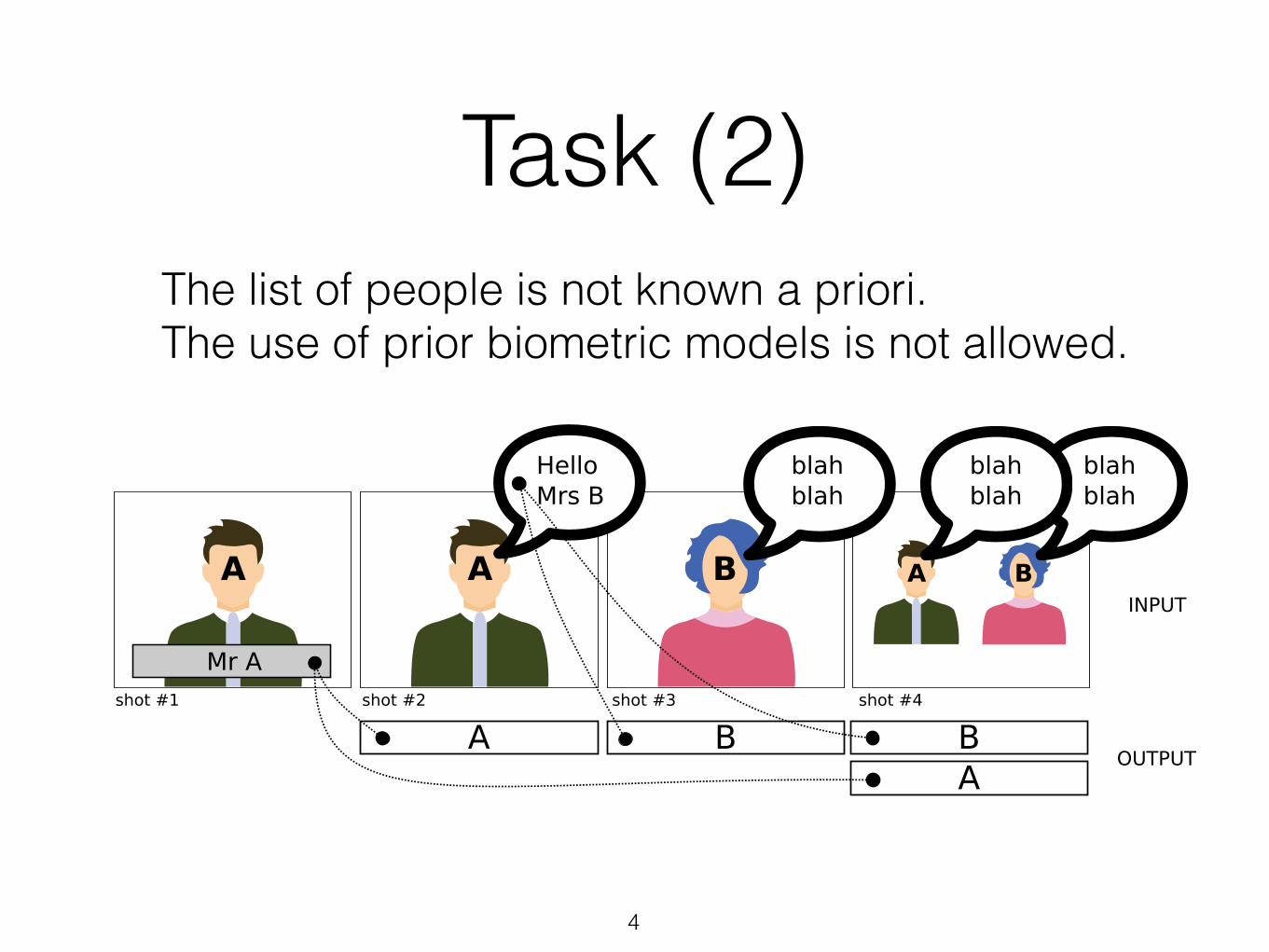
Task (2)
A BA
HelloMrs B
Mr A
blahblah
shot #1 shot #2 shot #3
A B B
blahblah
shot #4 speaking face
evidence
A B
blahblah
A
text overlay
speechtranscript
INPUT
OUTPUT
LEGEND
4
The list of people is not known a priori. The use of prior biometric models is not allowed.
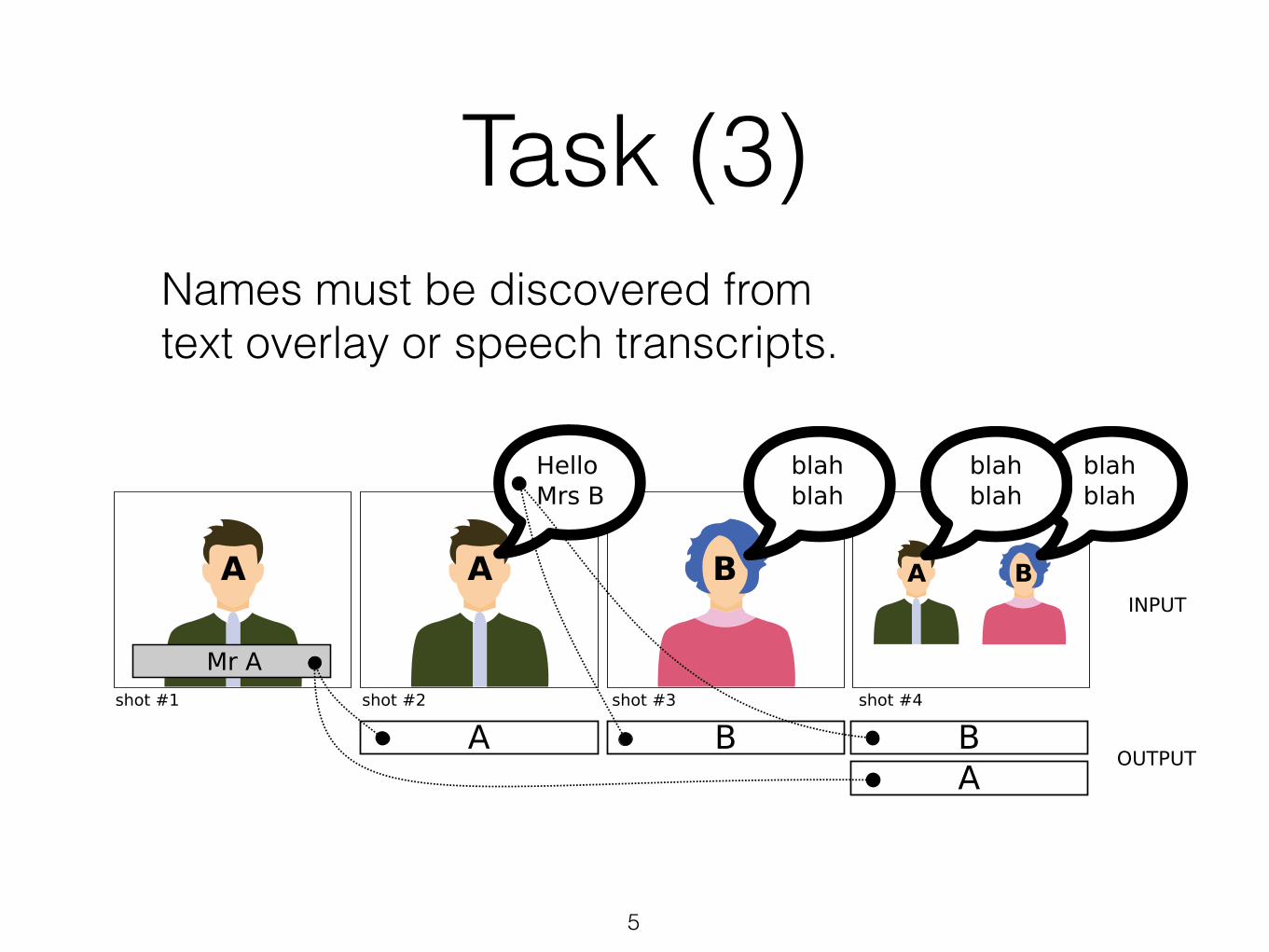
Task (3)
A BA
HelloMrs B
Mr A
blahblah
shot #1 shot #2 shot #3
A B B
blahblah
shot #4 speaking face
evidence
A B
blahblah
A
text overlay
speechtranscript
INPUT
OUTPUT
LEGEND
5
Names must be discovered from text overlay or speech transcripts.
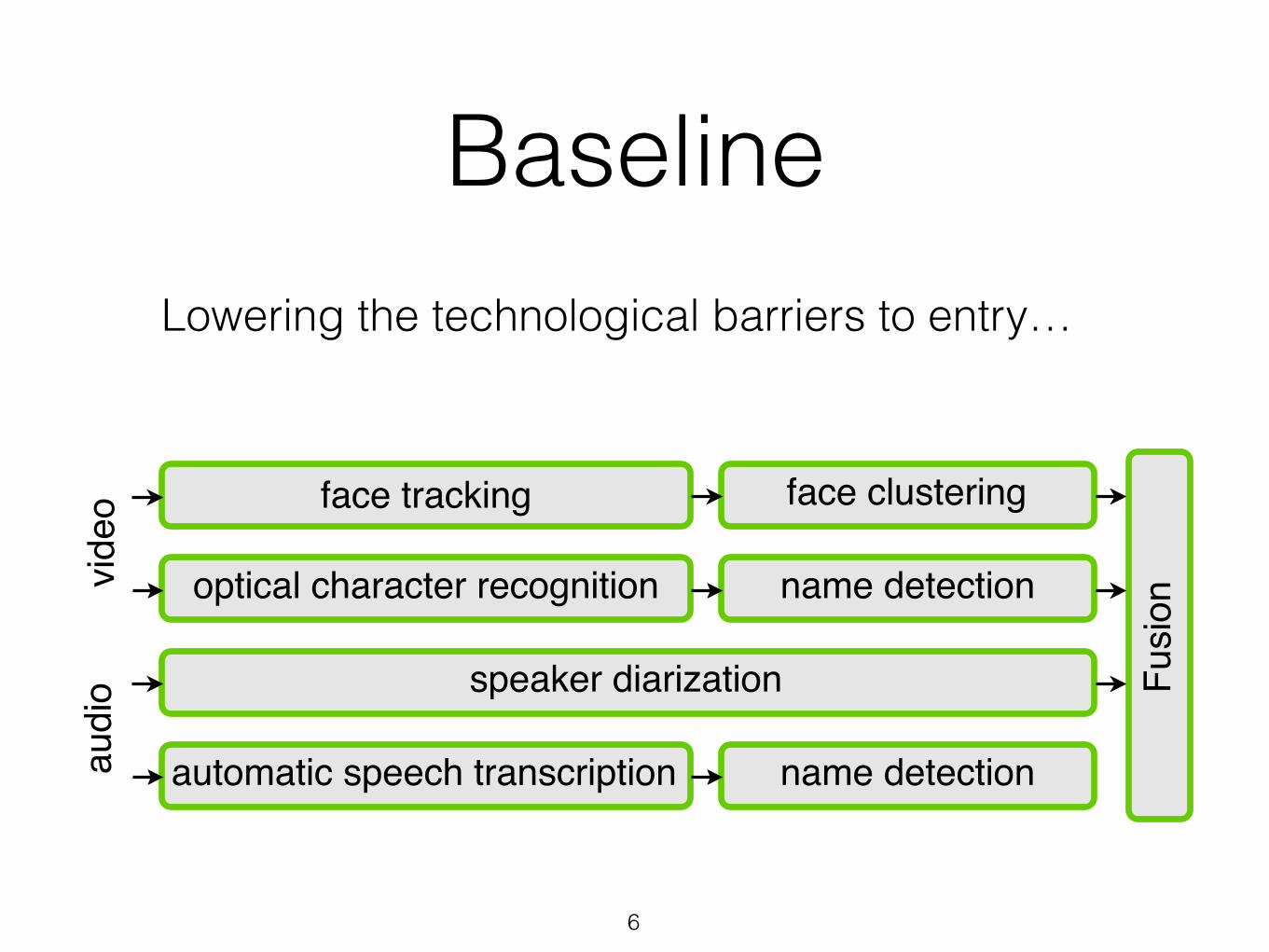
Baseline
6
Lowering the technological barriers to entry…

Baseline (2)
• "audio" baseline speaker diarization + propagation of OCR names
• "video" baselineface clustering + propagation of OCR names
• "audio-visual" baseline temporal intersection of both
7

DatasetsINA
French
France 2France 5
90 hours
63k shots
DW
German / English
EuromaxxDW News
50 hours
28k shots
3-24
Catalan
3-24
13 hours
3k shots
8

Evaluation• Submissionsshot_id firstname_lastname confidence
• Queries firstname_lastname
• Sort shots by ⤴ edit distance to the query ⤵ confidence scores
• Mean average precision @ 10
9

Practical aspects
10
Submissionwebpage
Collaborativeannotation
Liveleaderboard
More technical details tomorrow…
1 primary run 4 contrastive runs
as simple as possible
1/5 of test set updated daily

Participants
MOTIF
11
GTM-UVigo TokyoTech
EUMSSI HCMUSUPC
"#
$
$
%#
&
'
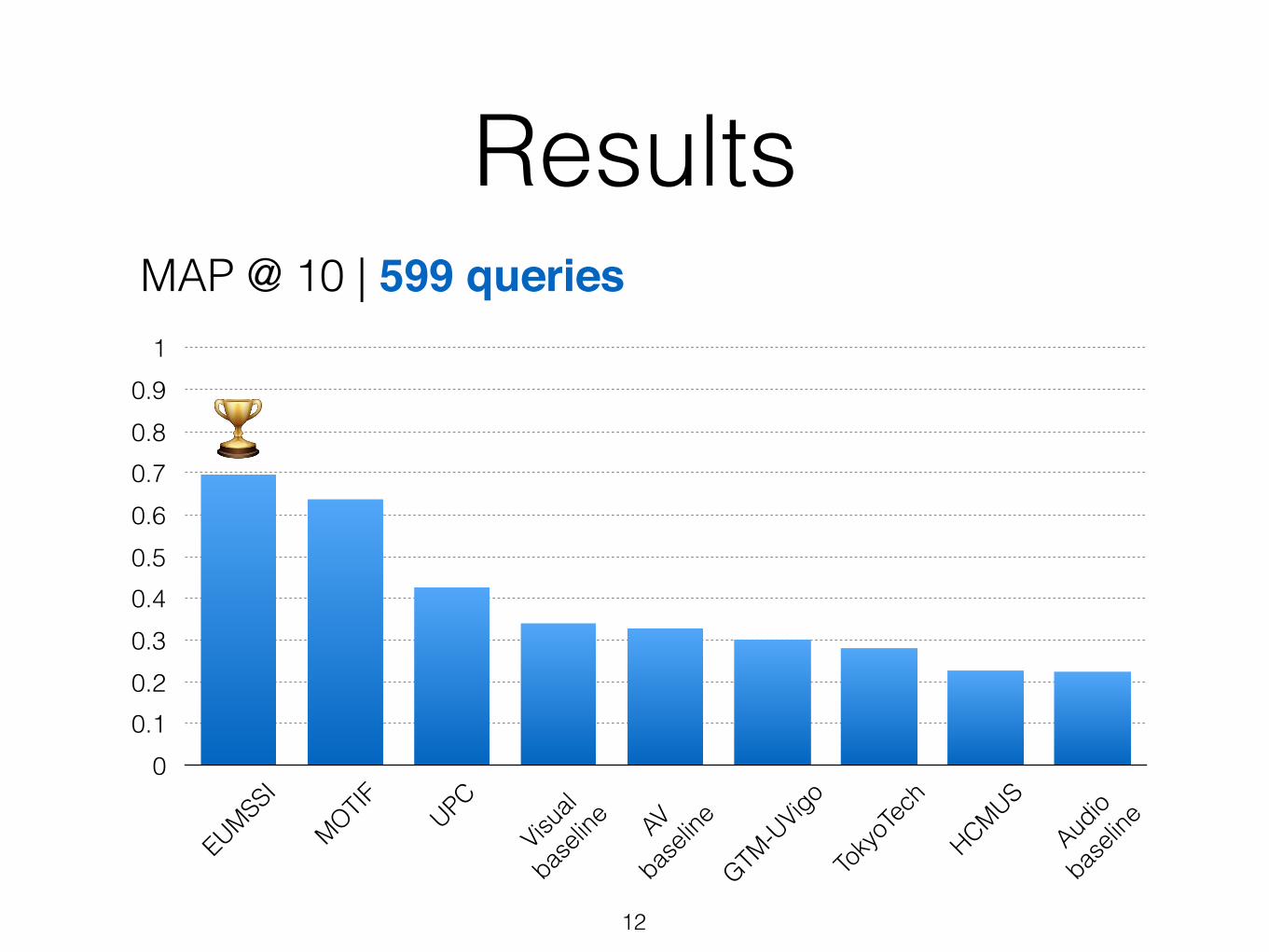
Results
12
00.10.20.30.40.50.60.70.80.9
1
EUMSSI
MOTIF UPCVisu
al
baselin
e AV
baselin
e
GTM-U
Vigo
Tokyo
Tech
HCMUS
Audio
baselin
e
MAP @ 10 | 599 queries
🏆

Results
13
00.10.20.30.40.50.60.70.80.9
1
EUMSSI
MOTIF UPCVisu
al
baselin
e AV
baselin
e
GTM-U
Vigo
Tokyo
Tech
HCMUS
Audio
baselin
e
MAP @ 10 | 599 queries | 156 queries (2+ videos)

Tested approaches• {speech turn | face} clustering
followed by cluster tagging
• {speech turn | face} taggingfollowed by "supervised" recognition
• fusion at {decision | score} level
• joint multimodal clustering and tagging with graph-based tag propagation
• talking-face detection
• nobody used speech transcripts
14
🙁

Tested approaches• {speech turn | face} clustering
followed by cluster tagging
• {speech turn | face} taggingfollowed by "supervised" recognition
• fusion at {decision | score} level
• joint multimodal clustering and tagging with graph-based tag propagation
• talking-face detection
• nobody used speech transcripts
14
🙁
#1
#1
#1

Tested approaches• {speech turn | face} clustering
followed by cluster tagging
• {speech turn | face} taggingfollowed by "supervised" recognition
• fusion at {decision | score} level
• joint multimodal clustering and tagging with graph-based tag propagation
• talking-face detection
• nobody used speech transcripts
14
🙁
#1
#1
#1
#2

Tested approaches• {speech turn | face} clustering
followed by cluster tagging
• {speech turn | face} taggingfollowed by "supervised" recognition
• fusion at {decision | score} level
• joint multimodal clustering and tagging with graph-based tag propagation
• talking-face detection
• nobody used speech transcripts
14
🙁
#1
#1
#1
#2
#3
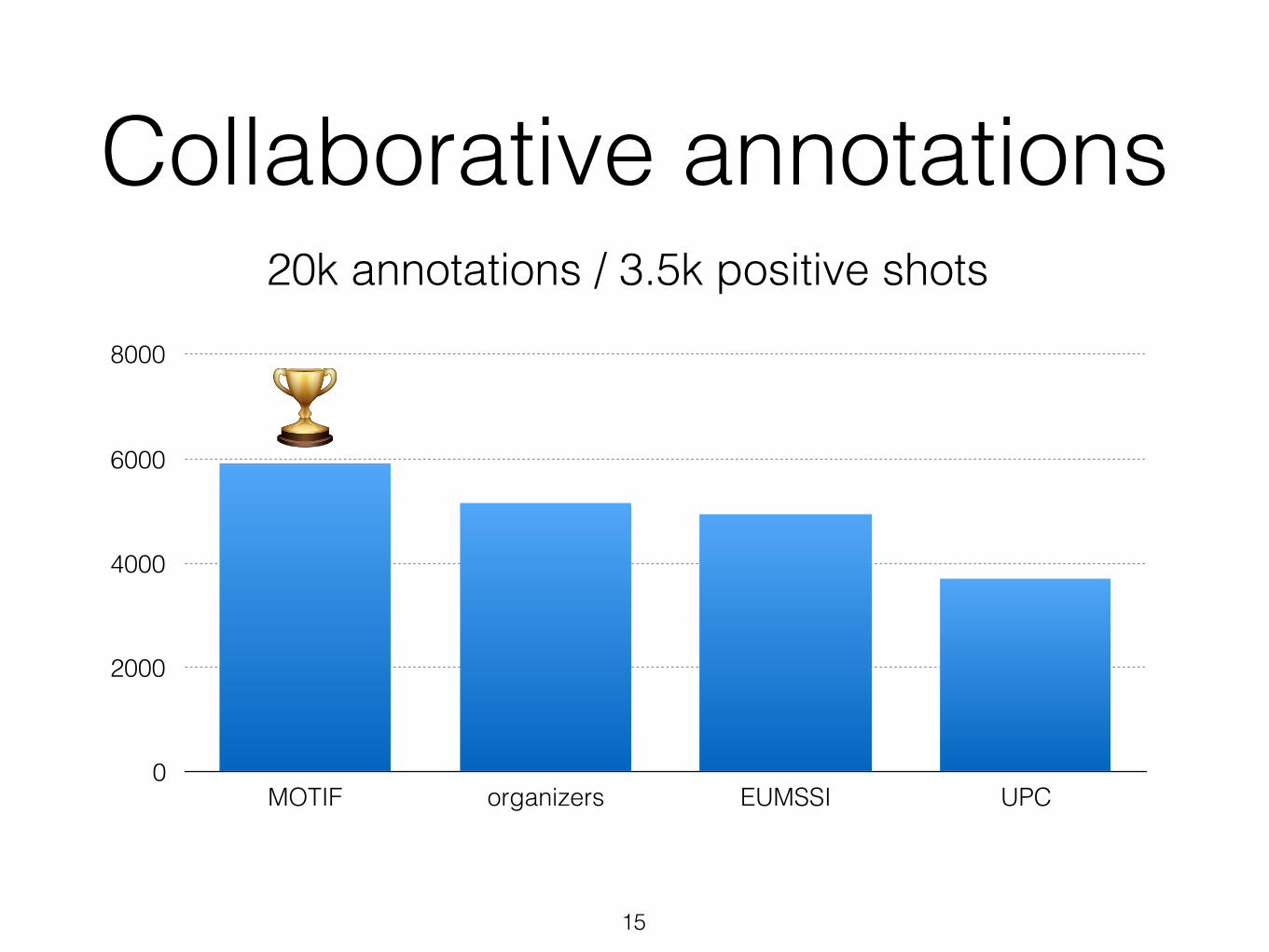
Collaborative annotations
15
0
2000
4000
6000
8000
MOTIF organizers EUMSSI UPC
20k annotations / 3.5k positive shots
🏆

Acknowledgments





























