Embed Size (px)
Citation preview

Moment matching networkを用いた
音声パラメータのランダム生成の検討
○高道 慎之介 (東大院・情報理工)
郡山 知樹 (東工大)
猿渡 洋 (東大院・情報理工)
日本音響学会 2017年 春季研究発表会
2-6-9

/13
概要
目的: 自然音声のように「同一テキストでも発話毎に
音声特徴量が異なる」音声合成システム
– 同一テキストでも発話毎にスペクトルは違う [Inukai et al., 2013.]
– この音声のランダム性(発話間変動)を合成音声に持たせたい
提案:Moment-matching networkを用いた音声合成法
– 自然音声と合成音声のモーメントを揃えるようにDNNを学習
– サンプリングによる音声パラメータ生成
2
最尤生成と比較して音質劣化なしで,サンプリング生成を可能に

/13
通常の音声合成
(Mean squared errorの最小化)
3
Mean squared error
Linguistic feats.
Static-delta mean vectors
⋯ ⋯
⋯
⋯
time 𝑡 = 1
⋯ ⋯
⋯
⋯
⋯
time 𝑡 = 𝑇
⋯
Generated speech
params.
Natural speech params.
Parameter generation
⋯
[Wu et al., 2016.]
𝒚 𝒚 𝒙
条件付き分布𝑃 𝒚|𝒙 として正規分布を仮定した最尤推定

/13
提案法
(条件付きMMDの最小化)
4
Conditional MMD
Linguistic feats.
𝒚
Static-delta mean vectors
𝒚
⋯
Generated speech
params.
Natural speech params.
Parameter generation
⋯
𝑁 𝟎, 𝑰 Frame-wise noise generator
time 𝑡 = 1
time 𝑡 = 𝑇
𝒙
⋯ ⋯
⋯
⋯
⋯ ⋯
⋯
⋯
⋯
モーメントマッチングによる経験分布表現に基づくサンプリング

/13
MMD (Maximum Mean Discrepancy)
5
2つのデータセットの統計量の不一致指標
Moment-matching network [Li et al., 2015.]
– MMDを最小化するように、ノイズ入力のDNNを学習
𝑁 𝟎, 𝑰
𝒚
𝒚
MMD = Tr 𝟏 ⋅ 𝑲𝒚,𝒚 + Tr 𝟏 ⋅ 𝑲𝒚 ,𝒚 − 2Tr 𝟏 ⋅ 𝑲𝒚,𝒚
𝒚, 𝒚 のグラム行列 𝒚 , 𝒚 𝒚, 𝒚
⋯ ⋯
⋯
⋯

/13
条件付きMMD (CMMD: Conditional MMD)
条件付き分布の統計量の不一致を計算 [Ren et al., 2016.]
Conditional moment-matching network [Ren et al., 2016.]
– CMMDを最小化するように、 𝒙 &ノイズを入力とするDNNを学習
6
𝒙 , 𝒙 のグラム行列の逆行列を含む行列
𝑁 𝟎, 𝑰
𝒚
𝒙 ⋯ ⋯
⋯
⋯
𝒚
CMMD = Tr 𝑳𝒙 ⋅ 𝑲𝒚,𝒚 + Tr 𝑳𝒙 ⋅ 𝑲𝒚 ,𝒚 − 2Tr 𝑳𝒙 ⋅ 𝑲𝒚,𝒚
𝒙

/13
音声合成への適用
グラム行列のカーネル関数をどう設計する?
– 𝒚(音声パラメータ):ガウスカーネルなど
– 𝒙(コンテキストラベル):ガウスカーネル?
• ほとんどの要素は1-of-K hotベクトル,非常にスパース…
Bottleneck特徴量を用いたカーネル計算
– 連続空間に写像したコンテキストでカーネルを計算
7
Context Speech feats.
Squared error 最小化で学習
Conditional MMD 最小化で学習
Speech feats.
⋯ ⋯
⋯
⋯
⋯ ⋯
⋯
⋯ Noise

/13
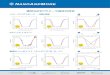
生成パラメータのサンプル
8

/13
従来手法との比較
9
項目 従来法 提案法
確率密度関数 Gaussian or GMM
(mixture density nets)
より複雑な分布
サンプリング 全共分散の正規分布
(trajectory model)
単純な事前分布
最適化問題 ミニマックス問題
(GAN [敵対的学習] )
最小化問題
従来法との関連 Divergenceに関連 (尤度比)
(GAN: Jensen-Shannon div.)
GV/MSに関連
(モーメント差)
Anti-spoofingの詐称 Replay-attack検出技術で検出
(最尤生成)
ランダム生成で
検出を緩和
[スペースの都合により引用を省略]
* GV/MS: 系列内変動/変調スペクトル
* GMM: 混合正規分布モデル

実験的評価
10
従来の生成と比較して,音質劣化なしでサンプリングできるか?

/13
実験条件
11
項目 値・設定
学習データ 音素バランス450文/話者 × 5話者
評価データ 53文/話者 × 1話者
入力特徴量 274次元コンテキスト + 5次元話者ID
出力特徴量 40次元メルケプストラム+動的特徴量(計120次元)
Bottleneck特徴量 128次元
入力ノイズ 3次元/フレーム.正規分布からランダム生成
ネットワーク構造 Feed-Forward, 131 – 512×3 (ReLU) – 120 (Linear)
評価対象
conv:従来のdeep neural network音声合成で最尤生成 [Zen et al., 2013.]
pro (w/ rand): 提案法(ランダム生成)
pro (w/o rand): 提案法(ノイズ項を最尤推定で固定して生成)

/13
主観評価指標
(音質に関するABテスト)
12
サンプリングによる音質劣化なし&従来法を上回る音質を達成
* エラーバーは95%信頼区間

/13
まとめ
目的:ランダム性を持つ音声合成を作りたい!
提案法:Moment-matching networkを用いた音声合成法
– 自然音声と合成音声のモーメントを揃えるようにDNNを学習
– サンプリングによる音声パラメータ生成
実験結果:
– サンプリングによる音質劣化なし
今後の予定:
– 動的特徴量の必要性
– 学習データ数の影響
– 自然音声の持つランダム性との比較
– 継続長決定・波形生成への応用 13