Embed Size (px)
Citation preview

Naive Bays Classifier and Sentiment Analysis

Overview• User-generated content on the Internet has risen exponentially over the last
decade.
• Nearly all our decision-making is social.
• Sentiment analysis:
– The computational study of how
– opinions,
– attitudes,
– emotions, and
– perspectives
• Are expressed in language
• Provides a rich set of tools and techniques for extracting this evaluative, subjective information from large datasets and summarizing it.

Applications• Understanding customer feedback
• Understanding public opinion
– We analyze several surveys on consumer confidence and political opinion over the 2008 to 2009 period, and find they correlate to sentiment word frequencies in contemporaneous Twitter messages.(O'Connor, Balasubramanyan, Routledge, and Smith 2010)
• Media studies
– Sentiment analysis is being used to study media coverage and media bias
• Realistic text-to-speech
– Text-to-speech technology is increasingly reliable and sophisticated, but it continues to stumble when it comes to predicting where and how the affect will change
• Financial prediction
– The number of emotional words on Twitter could be used to predict daily moves in the Dow Jones Industrial Average. A change in emotions expressed online would be followed between two and six days later by a move in the index, the researchers said, and this information let them predict its movements with 87.6 percent accuracy
– Which movies will open big
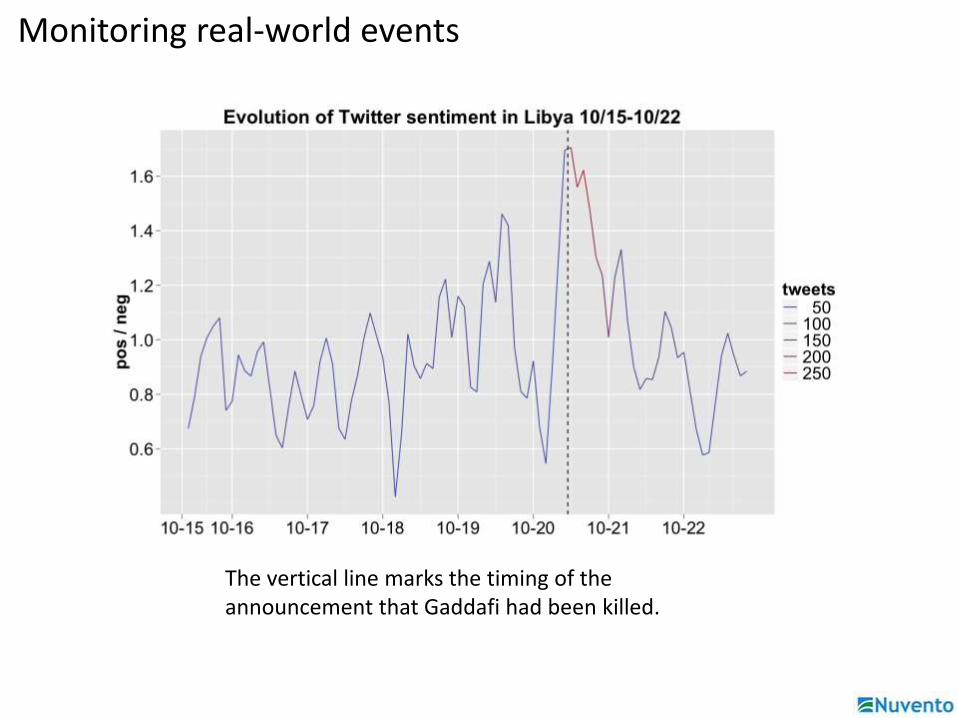
Monitoring real-world events
The vertical line marks the timing of the announcement that Gaddafi had been killed.

The emotions of a nation• Facebook's Gross National Happiness interface. Holidays register large
happiness spikes. The happiness dips in January correspond roughly with the earthquake in Haiti (Jan 12) and its most serious aftershock (Jan 20).

http://www.wefeelfine.org/
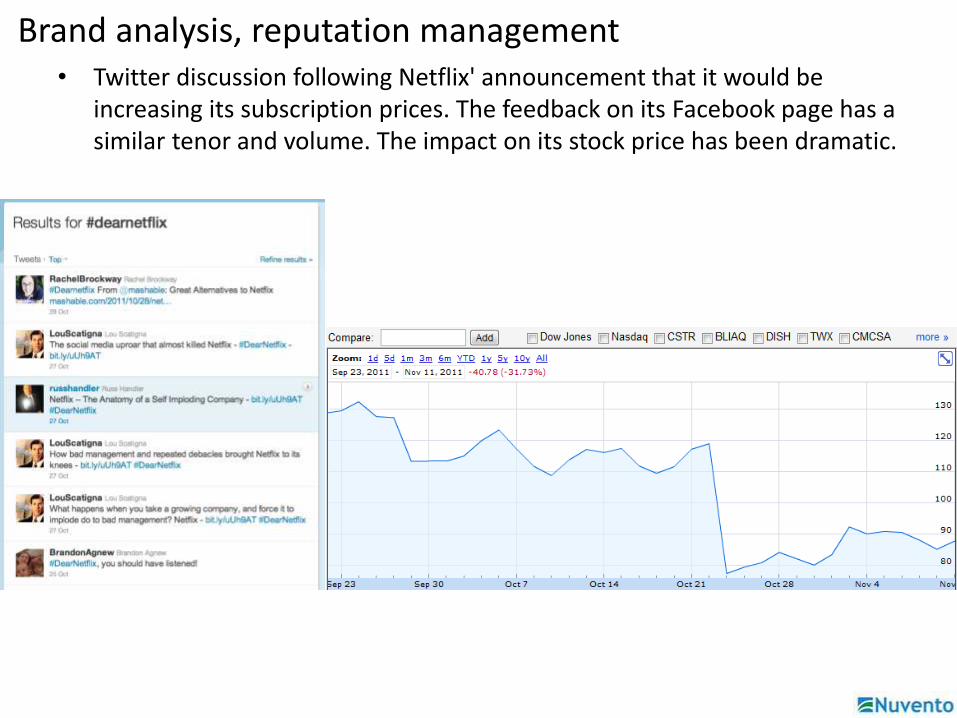
Brand analysis, reputation management• Twitter discussion following Netflix' announcement that it would be
increasing its subscription prices. The feedback on its Facebook page has a similar tenor and volume. The impact on its stock price has been dramatic.

A pervasive, challenging phenomenon• Part of the challenge is that sentiment information is blended and
multidimensional.
• We try to approximate it as a classification problem, but this is often inappropriate.
• Emotionally blended 'confessions' from the Experience Project.
I have a crush on my boss! *blush* eeek *back to work*
I fell over in the playground this afternoon, in front of all the parents and kids. I fell backwards over a cone. It was pretty funny, but now my neck hurts like crazy.
When I left my workplace today I kinda felt like I had to pee. But I was in rush to go home and figured it would be ok. So I have to take the bus and then walk for about another 15 minutes to get home. By the time I got on to the bus I knew I really had to pee. I was sitting down and had my legs tightly crossed and pretty much in agony scared of peeing myself in front of all the people in the bus. [...]
I really hate being shy ... I just want to be able to talk to someone about anything and everything and be myself.. That's all I’ve ever wanted.

Problems• Most robust, fast computational models treat documents as bags of words.
In some areas of sentiment, this is basically appropriate, because some sentiment words and expressions are not directly influenced by what is around them:
– That was fun :)
– That was miserable :(
• In other cases, where the sentiment words are influenced by what is around them, a bag of words might nonetheless do the job:
– I stubbed my damn toe
– What's with these friggin QR codes?
• However, the normal situation is for sentiment words to be influenced in complicated ways by the material around them:
– It was wonderful.
– He knows if it is wonderful.
– This "wonderful" movie turned out to be boring.
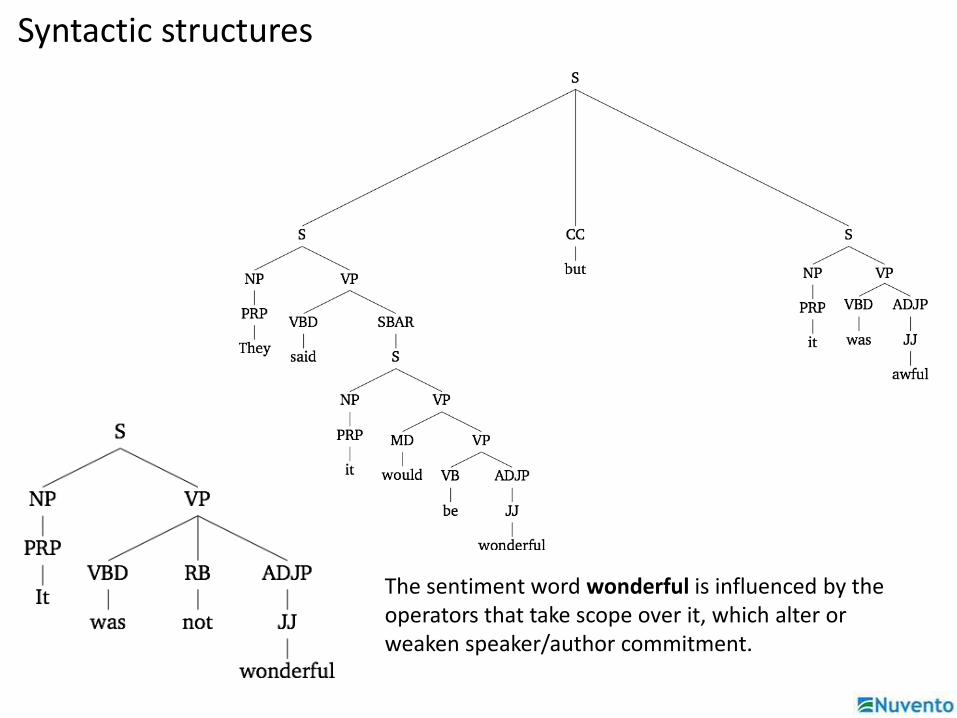
Syntactic structures
The sentiment word wonderful is influenced by the operators that take scope over it, which alter or weaken speaker/author commitment.

Non-literal language
• The effects of non-literal language are extremely challenging.
• Even humans are apt to get confused about the intended meaning of some expressions of this form.
• We can hope to approximate their effects with sentiment analysis systems, but they are still likely to be a leading cause of errors.– Irony and sarcasm: Oh, this is just great!, as clear as mud
– Implicit comparison: He did a good job for a linguist.
– Hypallage: He's not exactly brilliant.
– Hyperbole: No one goes there anymore.

Text preparation: Tokenization• Tokenizing (splitting a string into its desired constituent parts) is fundamental to
all NLP tasks.• There is no single right way to do tokenization. • The right algorithm depends on the application.• Whitespace tokenizer: The whitespace tokenizer simply downcases the string
and splits the text on any sequence of whitespace, tab, or newline characters.• Treebank-style: The Treebank-style is the one used by the Penn Treebank and
many other important large-scale corpora for NLP. Thus, it is a de facto standard. This alone makes it worth considering, since it can facilitate the use of other tools.
• Sentiment-aware tokenizer– Emoticons are extremely common in many forms of social media, and they are
reliable carriers of sentiment.– Twitter includes topic and user mark-up that is useful for advanced sentiment
modeling. Your tokenizer should capture this mark-up if you are processing Twitter data.• User Name: @+[\w_]+• #tag: \#+[\w_]+[\w\'_\-]*[\w_]+
– Informative HTML tags - Basic HTML mark-up like the strong, b, em, and i tags can be indicators of sentiment.
– Masked curses - (****, s***t)– Capitalization, Lengthening, Additional punctuation

Text preparation: Stemming• Stemming is a method for collapsing distinct word forms.
• This could help reduce the vocabulary size, thereby sharpening one's results, especially for small data sets.
• The Porter stemmer is one of the earliest and best-known stemming algorithms. It works by heuristically identifying word suffixes (endings) and stripping them off, with some regularization of the endings.
• The Porter stemmer often collapses sentiment distinctions, by mapping two words with different sentiment into the same stemmed form.
• Suggestion: see its effect and decide – for Twitter may not be effective or have negative effect. for sentiment analysis, running a stemmer is costly in terms of resources and performance accuracy.
Positiv Negativ Stemmed
captivation captive captiv
common commoner common
defend defendant defend
defense defensive defens
dependability dependent depend
dependable dependent depend

Negation marking• Append a _NEG suffix to every word appearing between a negation and a
clause-level punctuation mark.
• Example: No one enjoys it. -> no one_NEG enjoys_NEG it_NEG.
Definition: NegationA negation is any word matching the following regular expression:(?:
^(?:never|no|nothing|nowhere|noone|none|not|havent|hasnt|hadnt|cant|couldnt|shouldnt|wont|wouldnt|dont|doesnt|didnt|isnt|arent|aint
)$)|n't
Definition: Clause-level punctuationA clause-level punctuation mark is any word matching the following regular expression:^[.:;!?]$
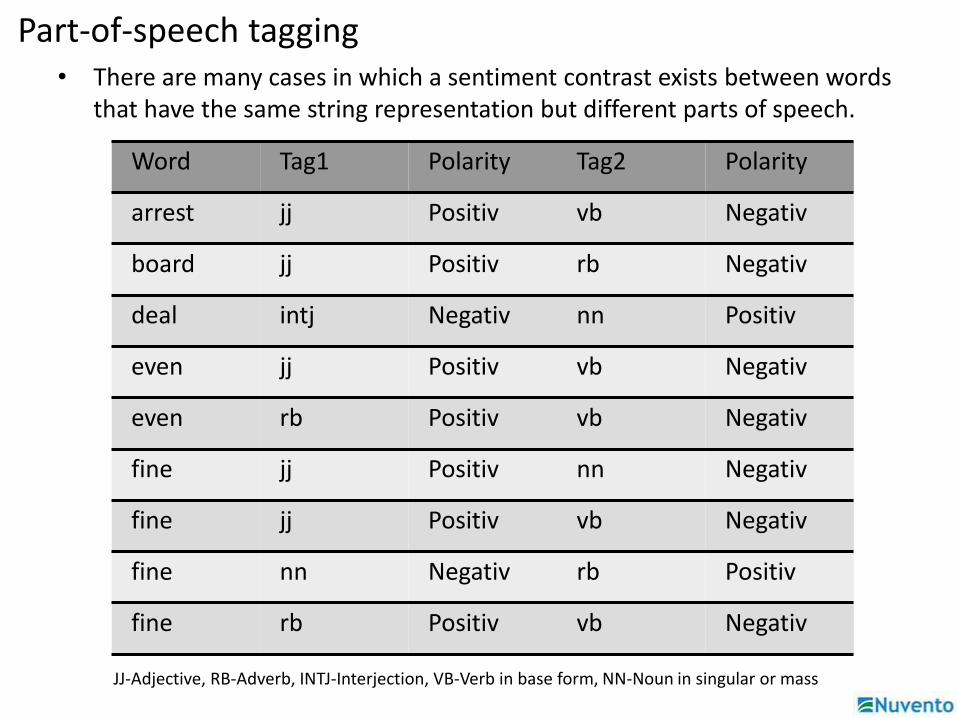
Part-of-speech tagging• There are many cases in which a sentiment contrast exists between words
that have the same string representation but different parts of speech.
Word Tag1 Polarity Tag2 Polarity
arrest jj Positiv vb Negativ
board jj Positiv rb Negativ
deal intj Negativ nn Positiv
even jj Positiv vb Negativ
even rb Positiv vb Negativ
fine jj Positiv nn Negativ
fine jj Positiv vb Negativ
fine nn Negativ rb Positiv
fine rb Positiv vb Negativ
JJ-Adjective, RB-Adverb, INTJ-Interjection, VB-Verb in base form, NN-Noun in singular or mass

Categorization/Classification
• Given:
– A description of an instance, x X, where X is the instance language or instance space.
– A fixed set of classes:
C = {c1, c2,…, cJ}
• Determine:
– The category of x: c(x)C, where c(x) is a classification function whose domain is X and whose range is C.
• We want to know how to build classification functions (“classifiers”).

Recall a few probability basics
• For events a and b:
• Bayes’ Rule
• Odds:
aaxxpxbp
apabp
bp
apabpbap
apabpbpbap
apabpbpbapbapbap
,)()|(
)()|(
)(
)()|()|(
)()|()()|(
)()|()()|()(),(
)(1
)(
)(
)()(
ap
ap
ap
apaO
Posterior
Prior

Bayes’ Rule
P (C ,D ) P (C | D )P (D ) P (D | C )P (C )
P(C |D) P (D |C)P (C)
P (D)

Naive Bayes Classifiers
Task: Classify a new instance D based on a tuple of attribute values
into one of the classes cj C
nxxxD ,,, 21
),,,|(argmax 21 njCc
MAP xxxcPcj
),,,(
)()|,,,(argmax
21
21
n
jjn
Cc xxxP
cPcxxxP
j
)()|,,,(argmax 21 jjnCc
cPcxxxPj
MAP = Maximum Aposteriori Probability

Naïve Bayes Classifier: Naïve Bayes Assumption
• P(cj)
– Can be estimated from the frequency of classes in the training examples.
• P(x1,x2,…,xn|cj)
– O(|X|n•|C|) parameters
– Could be estimated if large number of training examples was available.
Naïve Bayes Conditional Independence Assumption:
• Assume that the probability of observing the conjunction of attributes is equal to the product of the individual probabilities P(xi|cj).
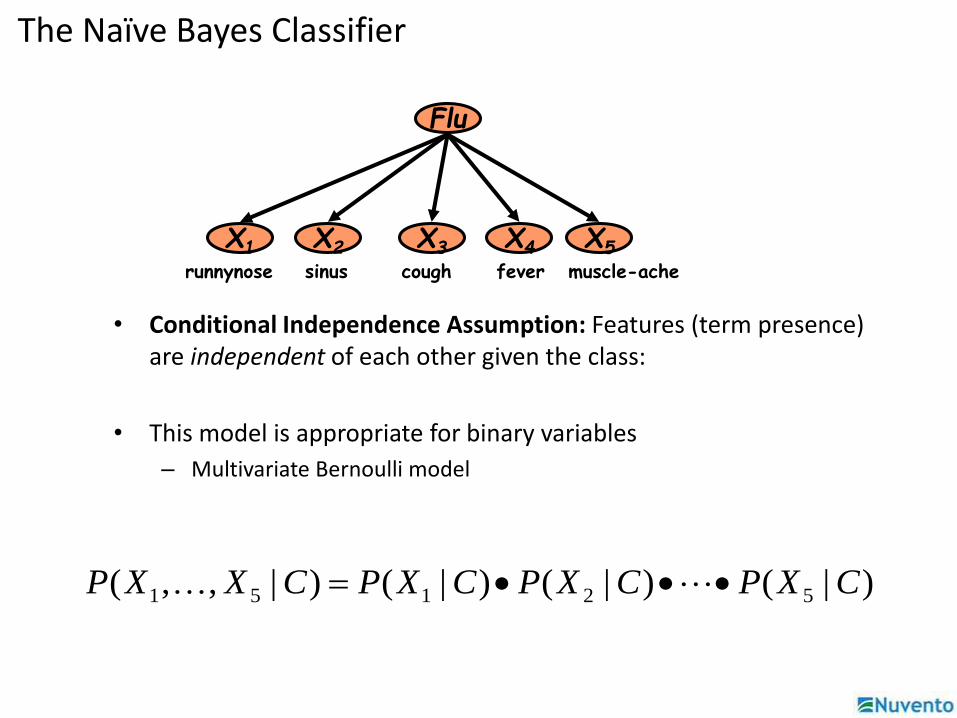
Flu
X1 X2 X5X3 X4
feversinus coughrunnynose muscle-ache
The Naïve Bayes Classifier
• Conditional Independence Assumption: Features (term presence) are independent of each other given the class:
• This model is appropriate for binary variables
– Multivariate Bernoulli model
)|()|()|()|,,( 52151 CXPCXPCXPCXXP

Learning the Model
• First attempt: maximum likelihood estimates
– simply use the frequencies in the data
)(
),()|(ˆ
j
jii
jicCN
cCxXNcxP
C
X1 X2 X5X3 X4 X6
N
cCNcP
j
j
)()(ˆ
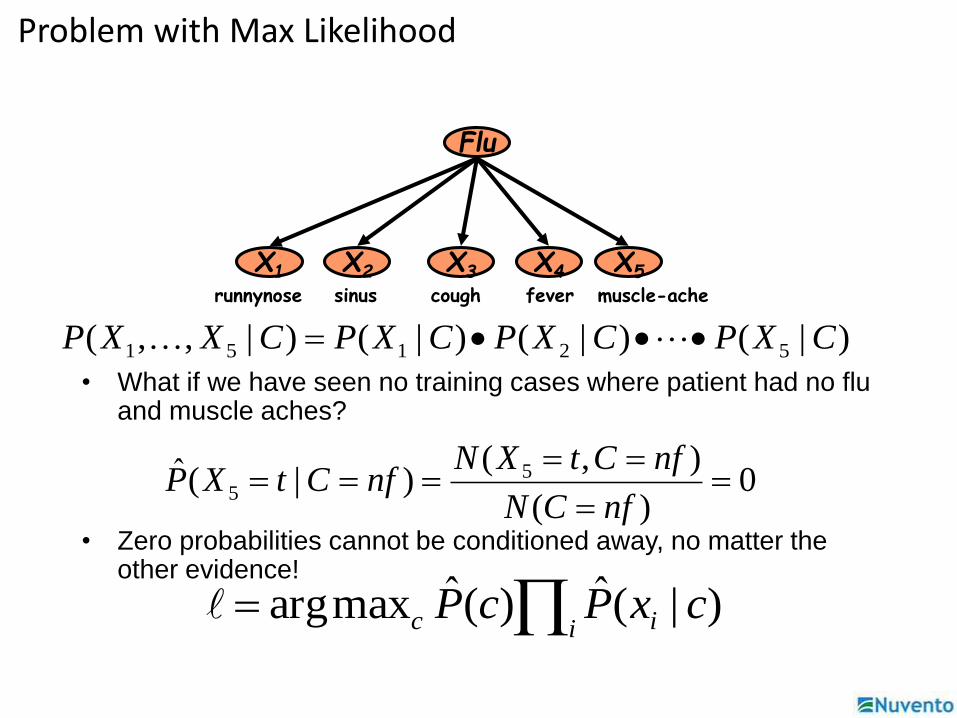
• What if we have seen no training cases where patient had no flu and muscle aches?
• Zero probabilities cannot be conditioned away, no matter the other evidence!
0)(
),()|(ˆ 5
5
nfCN
nfCtXNnfCtXP
i ic cxPcP )|(ˆ)(ˆmaxarg
Flu
X1 X2 X5X3 X4
feversinus coughrunnynose muscle-ache
)|()|()|()|,,( 52151 CXPCXPCXPCXXP
Problem with Max Likelihood

kcCN
cCxXNcxP
j
jii
ji
)(
1),()|(ˆ
# of values of Xi
Smoothing to Avoid Overfitting

kcCN
cCxXNcxP
j
jii
ji
)(
1),()|(ˆ
• Somewhat more subtle version
# of values of Xi
mcCN
mpcCxXNcxP
j
kijkii
jki
)(
),()|(ˆ
,,
,
overall fraction in data where Xi=xi,k
extent of“smoothing”
Smoothing to Avoid Overfitting

Textj single document containing all docsj
for each word xk in Vocabulary
nk number of occurrences of xk in Textj
Naïve Bayes: Learning Algorithm
• From training corpus, extract Vocabulary
• Calculate required P(cj) and P(xk | cj) terms– For each cj in C do
• docsj subset of documents for which the target class is cj
•
• alpha is “tuning/smoothing” factor that can be set to 1
||)|(
Vocabularyn
ncxP
j
kjk
|documents # total|
||)(
j
j
docscP

OVERALL APPROACH
• General idea – Bayesian (robustness due to qualitative approach)
– multinomial (counts of terms)
– multivariate Bernoulli (counts of documents)
• Simplifying assumption for computational tractability
– conditional independence; positional independence
• Dealing with idiosyncrasies of training data
– smoothening technique
– avoid underflow using log
• Improving efficiency (noise reduction)
– feature selection

Exercise• Vocabulary = all words over all documents in Training Set
• Calculate number of documents in positive class, and in negative class
• Find total number of documents
• Calculate
• Textpos single document containing all docspos
• npos = number of distinct words in Textpos
• for each word xk in Vocabulary
– nk number of occurrences of xk in Textpos
– Compute:
• Write map-reduce pseudo-code to compute the above steps.
• Implement in Python using supporting modules that are given for: Tokenization, Stop word removal, and Steaming. (Duration: 90 mins)
• Team presentation and discussion (Duration: 45 mins)
|documents # total|
||)(
pos
pos
docscP
|documents # total|
||)(
neg
neg
docscP
||
1)|(
Vocabularyn
ncxP
pos
kposk

End of session
Day – 3: Naive Bays Classifier and Sentiment Analysis





























