Embed Size (px)
Citation preview

1© Talend 2014
Big Data Hoopla Simplified –Hadoop, MapReduce, NoSQL …
TDWI Conference – Memphis, TN
Oct 29, 2014

2© Talend 2014
Rajan Kanitkar
• Senior Solutions Engineer
• Rajan Kanitkar is a Pre-Sales Consultant with Talend. He has been active in the broader Data Integration space for the past 15 years and has experience with several leading software companies in these areas. His areas of specialties at Talend include Data Integration (DI), Big Data (BD), Data Quality (DQ) and Master Data Management (MDM).
• Contact: [email protected]
About the Presenter

3© Talend 2014
Big Data Ecosystem

4© Talend 2014
Quick Reference – Big Data
Hadoop: Apache Hadoop is an open-source software framework for storage and large scale processing of data-sets on clusters of commodity hardware.
Hadoop v1.0 - Original version that focused on HDFS and MapReduce. The Resource Manager and Job Tracker were one entity.
Hadoop v2.0 – Sometimes called MapReduce 2 (MRv2). Splits out the Resource Manager and job monitoring into two separate daemons. Also called YARN. This new architecture allows for other processing engines to be managed/monitored aside from just the MapReduce engine.

5© Talend 2014
Quick Reference - Big Data
• Hadoop: the core project
• HDFS: the Hadoop Distributed File System
• MapReduce: the software framework for distributedprocessing of large data sets
• Hive: a data warehouse infrastructure that provides data summarization and a querying language
• Pig: a high-level data-flow language and executionframework for parallel computation
• HBase: this is the Hadoop database. Use it when youneed random, realtime read/write access to your Big Data
• And many many more: Sqoop, HCatalog, Zookeeper, Oozie, Cassandra, MongoDB, etc.
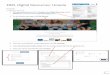
6© Talend 2014
Data Node
Hadoop Core – HDFS
Block Block
Block Block
Data Node
Block Block
Block Block
Data Node
Block Block
Block Block
Data Node
Block Block
Block Block
Name Node ClientMetadata Operations
Read/WriteControl
Replicate

7© Talend 2014
Hadoop Core – MapReduce
The „Word Count Example“

8© Talend 2014
Quick Reference – Data Services
HCatalog: a set of interfaces that open up access to Hive's metastore for tools inside and outside of the Hadoop grid. Hortonworks donated to Apache. In March 2013, merged with Hive. Enables users with different processing tools – Pig, MapReduce, and Hive – to more easily read and write data on the cluster.
Hbase: a non-relational, distributed database modeled after Google’s Big Table. Good at storing sparse data. Considered a key-value columnar database. Runs on top of HDFS. Useful for random real-time read/write access.
Hive: a data warehouse infrastructure built on top of Hadoop. Provides data summarization, ad-hoc query, and analysis of large datasets. Allows to query data using a SQL-like language called HiveQL(HQL).
Mahout: a library of scalable machine-learning algorithms, implemented on top of Hadoop. Mahout supports collaborative filtering, clustering, classification and item set mining.
Pig: allows you to write complex MapReduce transformations using a Pig Latin scripting language. Pig Latin defines a set of transformations such as aggregate, join and sort. Pig translates the Pig Latin script into MapReduce so that it can be executed within Hadoop.
SQOOP: utility for bulk data import/export between HDFS and structured data stores such as relational databases.

9© Talend 2014
Quick Reference – Operational Services
Oozie: Apache workflow scheduler for Hadoop. It allows for coordination between Hadoop jobs. A workflow in Oozie is defined in what is called a Directed Acyclical Graph (DAG).
Zookeeper: a distributed, highly available coordination service. Allows distributed processes to coordinate with each other through a shared hierarchical name space of data registers (called znodes). Writing distributed applications is hard. It’s hard primarily because of partial failure. ZooKeeper gives you a set of tools to build distributed applications that can safely handle partial failures.
Kerberos : a computer network authentication protocol which provides mutual authentication. The name is based on the three- headed dog . The three heads of Kerberos are 1) Key Distribution Center (KDC) 2) the client user 3) the server with the desired service to access. The KDC performs two service functions: Authentication (are you who you say you are) and the Ticket-Granting (gives you an expiring ticket that give you access to certain resources). A Kerberos principal is a unique identity to which Kerberos can assign tickets (like a username). A keytab is a file containing pairs of Kerberos principals and encrypted keys (these are derived from the Kerberos password).

10© Talend 2014
MapReduce 2.0, YARN, Storm, Spark
• Yarn: Ensures predictable performance & QoS for all apps
• Enables apps to run “IN” Hadoop rather than “ON”
• Streaming with Apache Storm
• Mini-Batch and In-Memory with Apache Spark
Applications Run Natively IN Hadoop
HDFS2 (Redundant, Reliable Storage)
YARN (Cluster Resource Management)
BATCH
(MapReduce)
INTERACTIVE
(Tez)
STREAMING
(Storm, Spark)
GRAPH
(Giraph)
NoSQL
(MongoDB)
EVENTS
(Falcon)
ONLINE
(HBase)
OTHER
(Search)
Source: Hortonworks

11© Talend 2014
Quick Reference – Hadoop 2.0 Additions
Storm: distributed realtime computation system. A Storm cluster is similar to a Hadoop cluster. On Hadoop you run "MapReduce jobs". On Storm you run "topologies". Jobs and topologies are very different -- in that a MapReduce job eventually finishes, but a topology processes messages forever (or until you kill it). Storm can run on top of YARN.
Spark: parallel computing program which can operate over any Hadoop input source: HDFS, HBase, Amazon S3, Avro, etc. Holds intermediate results in memory, rather than writing them to disk; this drastically reduces query return time. Like Hadoop cluster but supports more than just MapReduce.
Tez: framework which allows for a complex directed-acyclic-graph of tasks for processing data and is built atop Apache Hadoop YARN. MapReduce is batch-oriented and unsuited for interactive query. Tez allows Hive and Pig to be used to process interactive queries on petabyte scale. Support for machine learning.

12© Talend 2014
Apache SparkWhat is Spark?
• Spark Is An In-Memory Cluster Computing Engine that includes an HDFS compatible in-memory file system.
Hadoop MapReduce• Batch processing at scale • Storage: Hadoop HDFS• Runs on Hadoop
VSSpark• Batch, interactive, graph and real-time processing• Storage: – Hadoop HDFS, Amazon S3, Cassandra…• Runs on many platforms• Fast in-memory processing up to 100 x faster than MapReduce (M/R)

13© Talend 2014
Apache StormWhat Is Storm?
• Storm Is a Cluster Engine Executing Applications Performing Real-time Analysis of Streaming Data in Motion – Enabling the Internet of Things for data such as sensor data, aircraft parts data, traffic analysis etc
Storm• Real-time stream processing at scale• Storage: None - Data in Motion• Runs on Hadoop or on its own cluster• Fast in-memory processing
VS
Spark• Batch, interactive, graph and real-time processing• Storage: – Hadoop HDFS, Amazon S3, Cassandra…• Runs on many plaforms• Fast in-memory processing

14© Talend 2014
Quick Reference – Big Data
Vendors: The Apache Hadoop eco-system is a collection of many projects. Because of the complexities, “for profit” companies have packaged, added, enhanced and tried to differentiate one another in the Hadoop world. The main players are:
- Cloudera – CDH – Cloudera Distribution for Hadoop. Current version is CDH 5.2 (includes YARN)
- Hortonworks - HDP – Hortonworks Data Platform. Spun out of Yahoo in 2001. Current version is HDP 2.2 (YARN)
- MapR – M3 (Community), M5 (Enterprise), M7 (adds NoSQL). Apache Hadoop derivative. Uses NFS instead of HDFS.
- Pivotal - GPHD – Greenplum Hadoop. Spun out of EMC in 2013. Current is Pivotal HD 2.0 (YARN)

15© Talend 2014
Quick Reference – NoSQL
NoSQL: A NoSQL database provides a mechanism for storage and
retrieval of data that is modeled in means other than the tabular relations
used in relational databases – document, graph, columnar databases.
Excellent comparison of NoSQL databases by Kristof Kovacs:
http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
Includes a comparison of:
- Cassandra
- MongoDB
- Riak
- Couchbase
- … and many more

16© Talend 2014
Quick Reference – NoSQL
Document Storage: stores documents that encapsulate and encode data in some standard format (including XML, YAML, and JSON as well as binary forms like BSON, PDF and Microsoft Office documents. Different implementations offer different ways of organizing and/or grouping documents.
Documents are addressed in the database via a unique key that represents that document. Big feature is the database will offer an API or query language that will allow retrieval of documents based on their contents.
CouchDB: Apache database that focuses on embracing the web. Uses JSON to store data, Javascript as its query language using MapReduce, and HTTP for an API. The HTTP API is a differentiator between CouchDB and Couchbase.
Couchbase: designed to provide key-value or document access. Native JSON support. Membase + CouchDB = Couchbase. Couchbase architecture includes auto-sharding, memcache and 100% uptime redundancy over CouchDB alone. Couchbase has free version but is not open-source.
MongoDB: JSON/BSON style documents with flexible schemas to store data. A “collection” is a grouping of MongoDB documents. Collections do not enforce document structures.

17© Talend 2014
Quick Reference – NoSQL
Column Storage: stores data tables as sections of columns of data rather than as rows of data. Good for finding or aggregating on large set of similar data. Column storage serializes all data for one column contiguous on disk (so very quick read of a column). Organization of your data REALLY matters in columnar storage. No restriction on number of columns. One row in relational may be many rows in columnar.
Cassandra: Apache distributed database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure.
Dynamo: Amazon NoSQL database service. All data stored on solid state drives. Replicated across three timezones. Integrated with Amazon EMR and S3. Stores “Items” (collection of key-value pairs) given an ID.
Riak: a distributed fault-tolerant key-value database. HTTP/REST API. Can walk links (similar as graph). Best used for single-site scalability, availability and fault tolerance – places where even seconds of downtime hurt data collection. Good for point-of-sale or factory control system data collection.
HBase: non-relational data store on top of Hadoop. Think of column as key and data as value. Must create the Column family on table create. Look on Advanced tab to create families, then use when writing data.

18© Talend 2014
Big Data Integration Landscape

19© Talend 2014
Data-Driven Landscape
Hadoop & NoSQL
Data Quality
Latency & Velocity
Expanding Data
Volumes
Master Data Consistency
Lack of Talent / Skills
Siloed Data due to
SAAS
No End-2-End meta-data
visibility

20© Talend 2014
Macro Trends Revolutionizing
the Integration Market
20
The amount of data will grow
50X from 2010 to 2020
64% of enterprises surveyed indicate that they’re
deploying or planning Big Data projects
By 2020, 55% of CIOs will source all their critical apps
in the Cloud
Source: Gartner and Cisco reports
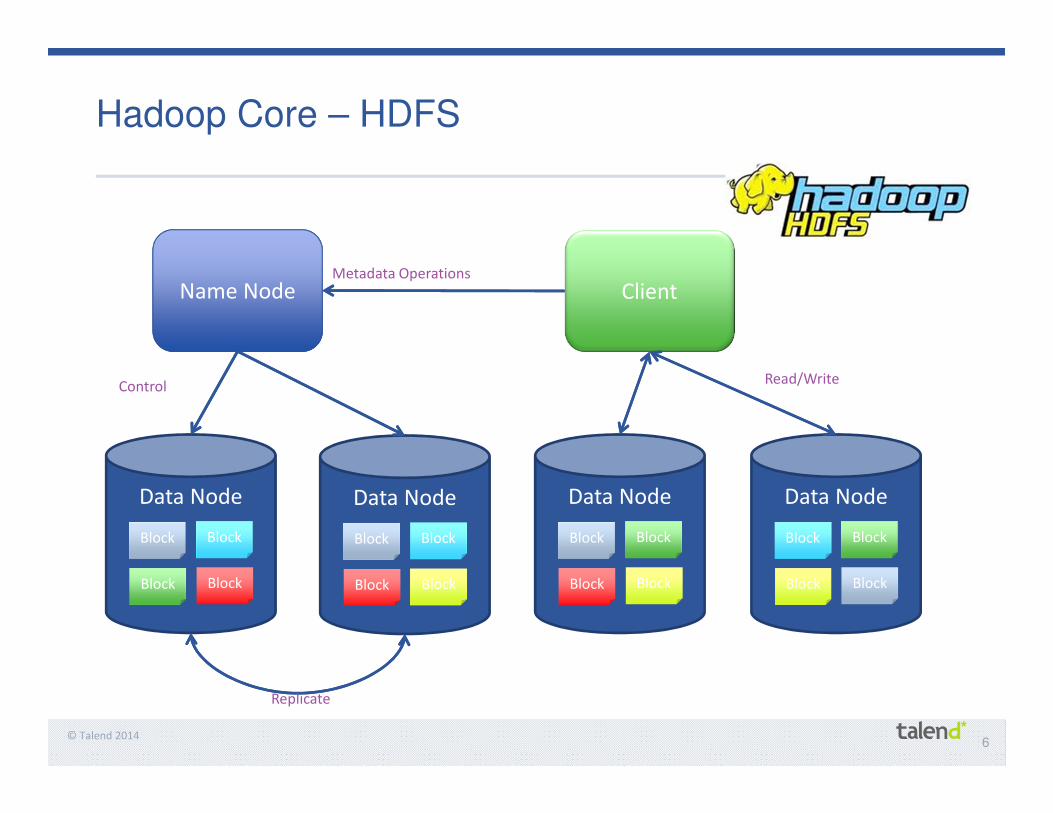
21© Talend 2014
“Big data is what happened when the cost of keeping information became less than the cost of throwing it away.”
– Technology Historian George Dyson
The New Data Integration Economics
45xsavings. $1,000/TB
for Hadoop vs $45,000/TB for
traditional
$600Brevenue shift by
2020 to companies that use big data
effectively
6xfaster ROI using big data analytics
tools vs traditional EDW
600xactive data.
Neustar moved from storing 1% of data for 60 days to 100% for one year

22© Talend 2014
Existing Infrastructures Under Distress: Architecturally and Economically
Batch toreal-time
Standard Reports
Data Mining
Ad-hoc Query Tools
MDD/OLAP
Relational Systems/ERP
Weblogs
AnalyticalApplications
Data explosion
Need moreactive data
Legacy Systems
Transform
External Data Sources
Metadata
Data Marts(the data warehouse)
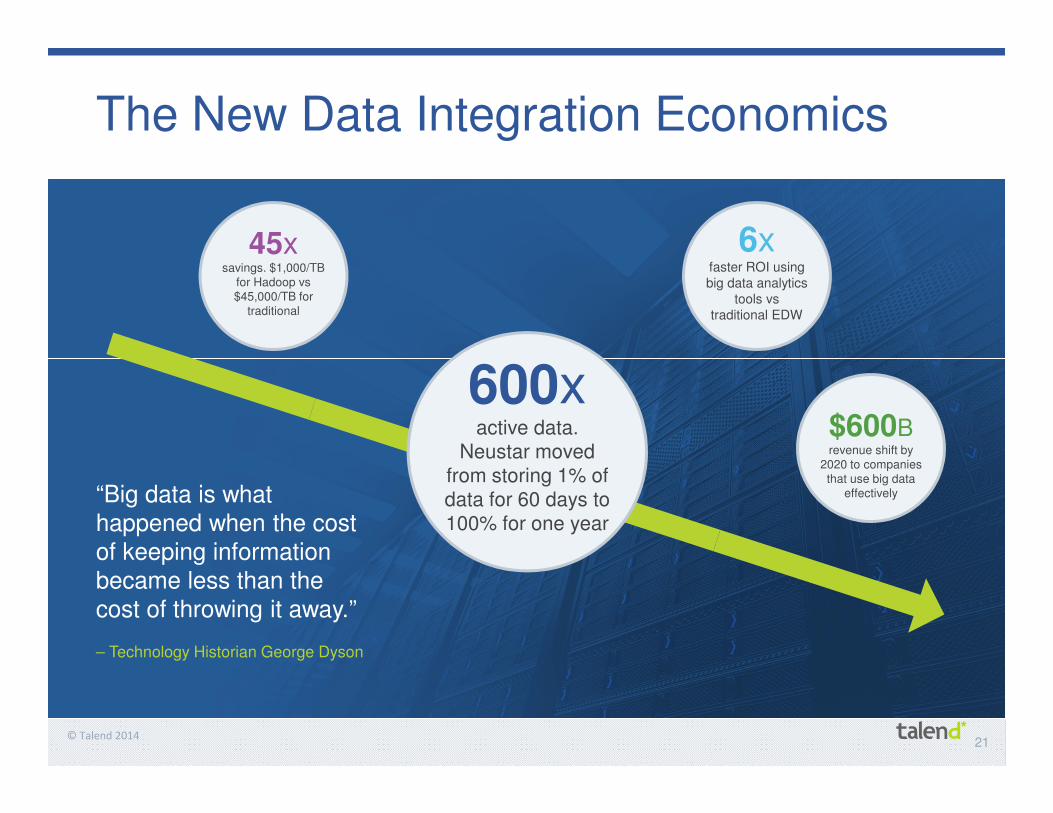
23© Talend 2014
Benefits of Hadoop and NoSQL
Data explosion
Batch toReal-Time
Longeractive data
IOT
NoSQLNoSQL
Web Logs
Data Marts(the data warehouse)
LegacySystems
ERP
DBMS /EDW
Standard Reports
Ad-hoc Query Tools
Data Mining
MDD/OLAP
AnalyticalApplications

24© Talend 2014
Top Big Data Challenges
Source: Gartner - Survey Analysis: Big Data Adoption in 2013 Shows Substance Behind the Hype - 12 September 2013 - G00255160
“How To” Challenges

25© Talend 2014
Big Data Integration Capabilities

26© Talend 2014
Top Big Data Challenges
Source: Gartner - Survey Analysis: Big Data Adoption in 2013 Shows Substance
Behind the Hype - 12 September 2013 - G00255160
Need Solutions that
Address these
Challenges

27© Talend 2014
ETL / ELT
Pa
rall
eli
zati
on
Convergence, Big Data & Consumerization
• Next-gen integration platforms need to be designed
& architected with big data requirements in mind
Processing needs to be
distributed & flexible
Big data technologies need
to be integrated seamlessly
with existing integration
investments
RDBMS

28© Talend 2014
Big Data Integration Landscape

29© Talend 2014
“I may say that this is the greatest factor: the way in which the expedition is equipped.”
Roald Amundsenrace to the south pole, 1911
Source of Roal Amundsen portrait: Norwegian National Library
© Talend 2014 29
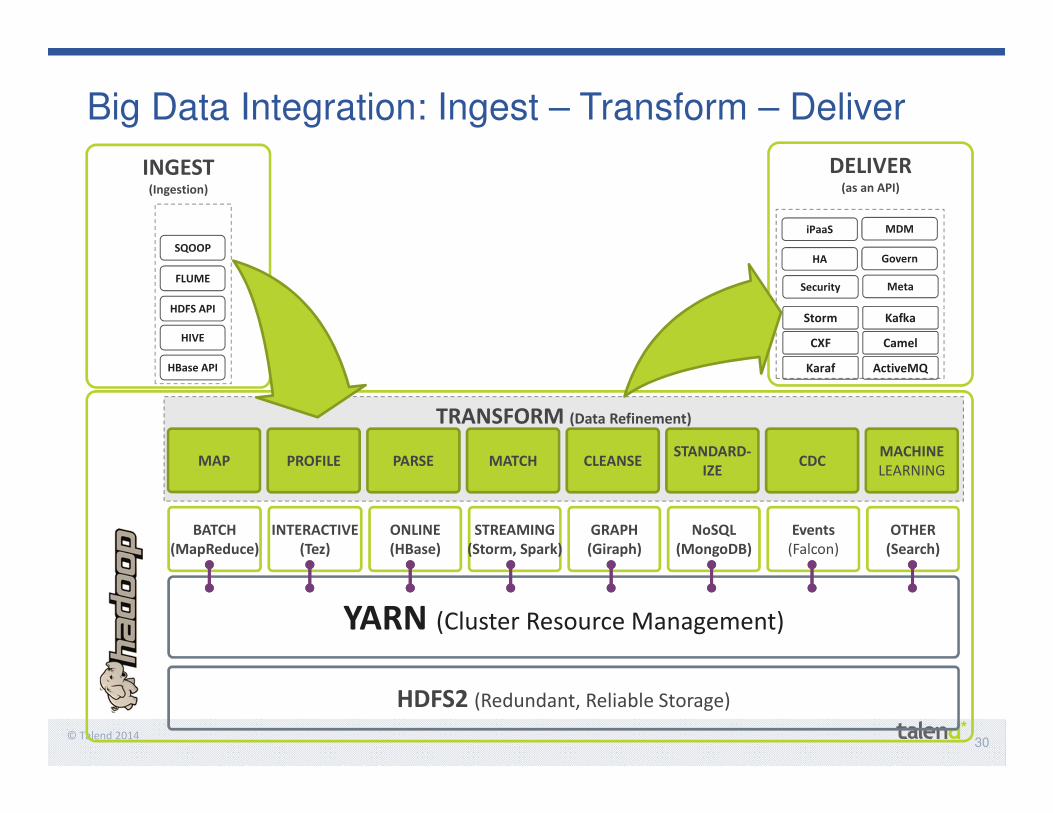
30© Talend 2014
HDFS2 (Redundant, Reliable Storage)
YARN (Cluster Resource Management)
BATCH
(MapReduce)
INTERACTIVE
(Tez)
STREAMING
(Storm, Spark)
GRAPH
(Giraph)
NoSQL
(MongoDB)
Events
(Falcon)
ONLINE
(HBase)
OTHER
(Search)
Big Data Integration: Ingest – Transform – Deliver
TRANSFORM (Data Refinement)
PROFILE PARSEMAP CDCCLEANSESTANDARD-
IZE
MACHINE
LEARNINGMATCH
INGEST(Ingestion)
SQOOP
FLUME
HDFS API
HBase API
HIVE
DELIVER(as an API)
ActiveMQKaraf
CamelCXF
KafkaStorm
MetaSecurity
MDMiPaaS
GovernHA

31© Talend 2014
Big Data Integration and Processing
Analytics Dashboard
Load to HDFSLoad to HDFSBIG DATA
(Integration)
BIG DATA
(Integration)
Federate to
analytics
Federate to
analytics
HADOOP
HDFS Map/Reduce
Data from Various
Source Systems
Hive

32© Talend 2014
Important Objectives
• Moving from hand-code to code generation – MapReduce, Pig, Hive, SQOOP etc. – using a graphical user interface
• Zero footprint on the Hadoop cluster
• Same graphical user interface for both standard data integration and Big Data integration

33© Talend 2014
Trying to get from this…

34© Talend 2014
“pure Hadoop” and MapReduceVisual design in Map Reduce and optimize before
deploying on Hadoop
to this…
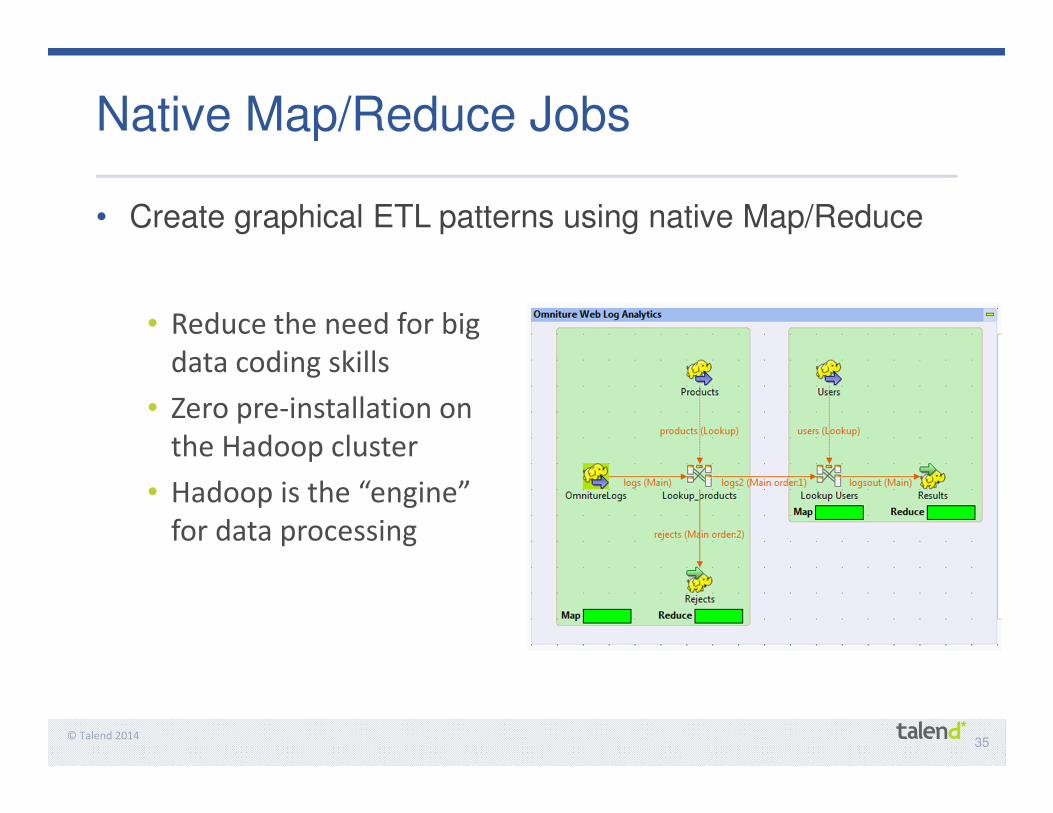
35© Talend 2014
Native Map/Reduce Jobs
• Create graphical ETL patterns using native Map/Reduce
• Reduce the need for big
data coding skills
• Zero pre-installation on
the Hadoop cluster
• Hadoop is the “engine”
for data processing

36© Talend 2014
Other Important Objectives
Enables organizations to leverage existing skills such as Java and other open source languages
A large collaborative community for support� A large number of components for data and applications including big data
and NoSQL
Works directly on Apache Hadoop API� Native support for YARN and Hadoop 2.0 support for better resource
optimization
Software created through open standards and development processes that eliminates vendor lock-in� Scalability, portability and performance come for “free” due to Hadoop
Page 36

37© Talend 2014
Talend Solution for Big Data Integration
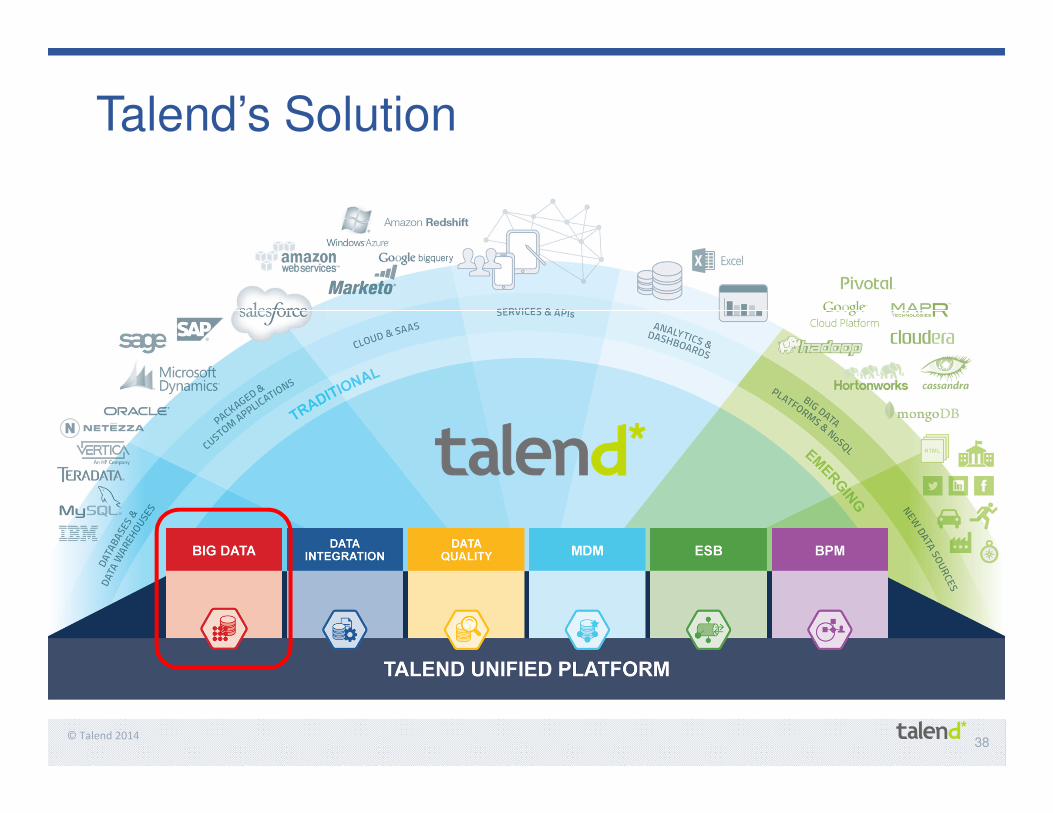
38© Talend 2014
Talend’s Solution
39© Talend 2014
The Value of Talend for Big Data
Leverage In-house Resources
- Easy-to-use familiar Eclipse-tools that generate big data code
- 100% standards-based, open source
- Lots of examples with a large collaborative community
Big Data Ready
- Native support for Hadoop, MapReduce, and NoSQL
- 800+ connectors to all data sources
- Built-in data quality, security and governance (Platform for Big Data)
Lower Costs
- A predictable and scalable subscription model
- Based only on users (not CPUs or connectors)
- Free to download, no runtimes to install on your cluster
$

40© Talend 2014
Talend’s Value for Big Data
• New frameworks like Spark and Storm are emerging on Hadoop and can run on other platforms
• Companies want to accelerate big data processing and do more sophisticated workloads by exploiting in-memory capabilities via Spark and for analyzing real-time data in motion via Storm
• Talend can generate Storm applications to analyze and filter data in real-time as well as use source data filtered by Storm applications
• Talend can help customers rapidly exploit new Big Data technologies to reduce time to value while insulating them from future extensions and advancements

41© Talend 2014
Thank You For Your Participation