Embed Size (px)
Citation preview

COUNTERS AT SCALE
A Cautionary Tale

Eric Lubow @elubow #CassandraSummit
PERSONAL VANITY
๏ CTO of SimpleReach
๏ Co-Author of Practical Cassandra
๏ Skydiver, Mixed Martial Artist, Motorcyclist, Dog Dad (IG: @charliedognyc), NY Giants fan
Eric Lubow @elubow #CassandraSummit
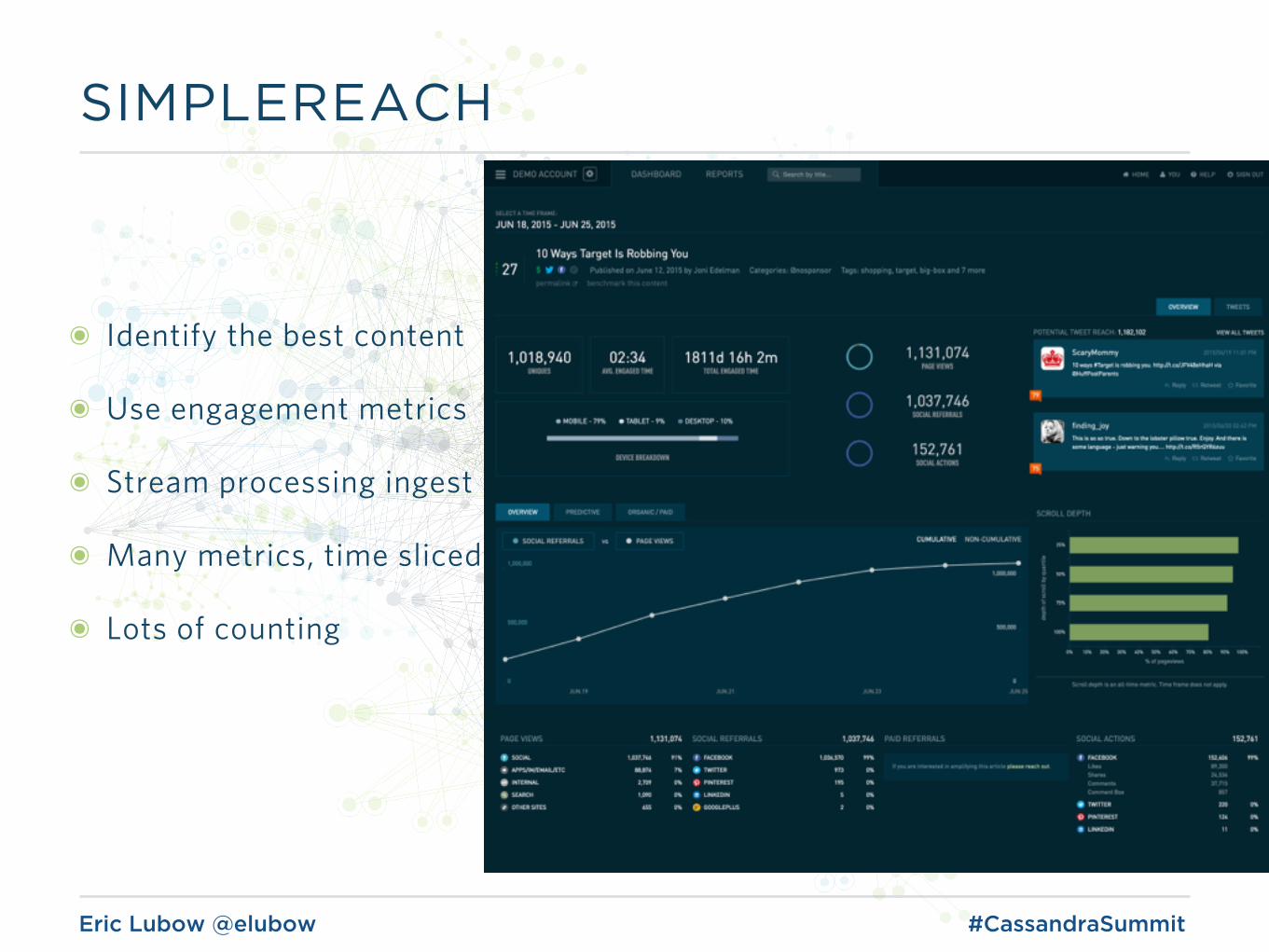
SIMPLEREACH
๏ Identify the best content
๏ Use engagement metrics
๏ Stream processing ingest
๏ Many metrics, time sliced
๏ Lots of counting

Eric Lubow @elubow #CassandraSummit
SIMPLEREACH CONTEXT
๏ 100 million URLs
๏ 350 million Tweets
๏ 50k - 100k events per second (tens of billions of events per day)
๏ Average 250k-300k counter writes per second
๏ 225G new per hour
๏ 800T of total compressed data (10T per month)
๏ 10T of hot data
๏ 72 nodes Cassandra cluster
๏ 52 i2.2xlarge Realtime Nodes
๏ 9 i2.xlarge Search Nodes
๏ 11 i2.2xlarge Spark Nodes

Eric Lubow @elubow #CassandraSummit
LET’S LOOK AT THE USE-CASE

Eric Lubow @elubow #CassandraSummit
Solr
Solr
Vertica + Cassandra
Vertica + Cassandra
Vertica
Mongo

Eric Lubow @elubow #CassandraSummit
EARLY CHALLENGES
๏ Startup with a serious budget
๏ Had to think through how we would scale (can’t throw money at it)
๏ Told not to use counters, but there was nothing better
๏ Knew nothing about Cassandra, knew more about Mongo and Redis
๏ Didn’t want to write our own (support)
๏ Were no drivers for our languages
๏ No ideas about counter failure scenarios
๏ Neither did Datastax

Eric Lubow @elubow #CassandraSummit
HOW DID SIMPLEREACH GET FROM …
๏ Server/DB level locking
๏ Shards/Replica sets
๏ Mongostat
๏ Leader election headaches
๏ Locking counters
๏ Read before write
๏ All in one (no master/slave)
๏ JMX instrumentation/monitoring
๏ Better fault tolerance
๏ Better counters

Eric Lubow @elubow #CassandraSummit
๏ Originally one large table
๏ Each row is a URL
๏ 0-200 cells per hour per row that saw activity
๏ Counter tables are now broken down by month (avoid wide rows)
๏ Counters are primarily CPU bound operations
๏ Requires SSD nodes and many core machines (memory not a factor)
WHAT DO COUNTERS LOOK LIKE?

Eric Lubow @elubow #CassandraSummit
HOW DID WE MAKE IT WORK?

Eric Lubow @elubow #CassandraSummit
1. All things possible through monitoring
2. Pre-aggregate writes (saved us 10x the writes)
3. Use counter batches
4. Trying to defeat the counter time bomb
5. Breaking the rules with CASSANDRA-8150, much JVM tuning
6. Upgraded every node in the cluster by hand one at a time
7. Upgrading to 2.1 definitely sealed the deal
BEAT COUNTERS WITH OUR 7 STEP PROCESS

Eric Lubow @elubow #CassandraSummit
1. MONITOR EVERYTHING

Eric Lubow @elubow #CassandraSummit
2. HELPERS FOR AN AFFORDABLE CLUSTER
Aggregator
Mongo Writer
Broadcast
Redis Writer
Cassandra Writer
Solr Writer
Calculator
NSQ
Vertica Writer
10x Improvement

Eric Lubow @elubow #CassandraSummit
๏ Roughly 1k batches per second
๏ Each batch contains approximately 100 statements
๏ Totals 100k/sec
๏ With an RF=3, that’s 300k counter writes per second
๏ Without batches (using async writes), this would be 4x the load
3. WE DON’T NEED NO STINKIN’ BATCHES
Eric Lubow @elubow #CassandraSummit
ASYNC WRITES

Eric Lubow @elubow #CassandraSummit
BATCH WRITES

Eric Lubow @elubow #CassandraSummit
๏ A slow node might make the entire cluster unusable
๏ A poorly gossiping node might overwork itself out of the cluster
๏ ReplicateOnWrite (and others) shared thread with gossip
๏ Occasional problematic GC pause durations
๏ Potential accuracy issues due to timeouts, retries, and non-
idempotent writes
๏ Counter time bomb
4. FAILURE IS INEVITABLE

Eric Lubow @elubow #CassandraSummit
๏ Normally writes return to client and background jobs occur (SEDA)
๏ Counters write, return to client, and then reconcile
๏ Similar in work to every write doing a read repair
๏ Overloaded ReplicateOnWrite thread (now called Counter
Mutation)
๏ Also (sometimes) overloaded the event thread backing up gossip
๏ Could happen at any time (seemingly randomly)
4. COUNTER TIME BOMB

Eric Lubow @elubow #CassandraSummit
๏ internode_compression: turned off for additional CPU cycles to be dedicated to
counters
๏ heap_new_size: 3G: created a larger young gen to handle the objects allocated for
counters
๏ -UseBiasedLocking: Biased locking limits an objects lock to a single thread. If
many threads are using that object, then removing biased locking will likely
increase performance.
๏ +UseGCTaskAffinity: Allocates GC tasks to threads using an affinity parameter
๏ +BindGCTaskThreadsToCPUs: Binds GC threads to individual CPUs.
๏ ParGCCardsPerStrideChunk=32768: Greatly increases the number of chunks that
ParNew GC is doing. This allows GC threads to be more efficient with the work to
be done and steal yet to be completed work from other GC threads.
5. BREAKING THE RULES WITH 8150 1/2

Eric Lubow @elubow #CassandraSummit
๏ +CMSScavengeBeforeRemark: Forces a minor collection to occur before
the remark thus shortening the remark phase.
๏ +CMSMaxAbortablePrecleanTime=60000: The fixed amount of time
before starting the remark during the precleaning phase where the top of
the young gen is sampled.
๏ CMSWaitDuration=30000: Sets a cap on the amount of time CMS cycle
should work. CMS can slow down with very large objects.
๏ MaxGCPauseMillis=5: prevents long GC pauses from making the machine
become unavailable
๏ +PerfDisableSharedMem: Prevents the writing of JVM stats to an
MMAP’d file (hsperfdata) from blocking I/O
5. BREAKING THE RULES WITH 8150 2/2

Eric Lubow @elubow #CassandraSummit
5. CAN YOU SPOT THE CHANGE?
New JVM Settings
๏ Each message has roughly 100 counter operations
๏ 100 operations * 52 million messages = 5.2 billion operations per hour
๏ 1.5 million counter operations per second

Eric Lubow @elubow #CassandraSummit
๏ 50+ nodes w/ 500+ gigs per node
๏ i2.xlarge => i2.2xlarge
๏ Additional cores and CPU
๏ Additional space on each node
๏ Better networking throughput
๏ Upgrading 10+ nodes at a time
๏ Would have been much easier with static internal IP addresses
6. MAKE IT BIGGER

Eric Lubow @elubow #CassandraSummit
๏ < 2.1: Counter deltas written directly to the commit logs
๏ Contentious counters created large problems for GC
๏ >= 2.1: Reads the current value for the counter, applies delta and
adds final value to the MemTable
๏ Better garbage collection of outstanding objects (fewer objects)
๏ Created CounterCache for hot counters used for conflict resolution
only (for better performance on contentious counters)
๏ For full details, read this post: http://www.datastax.com/dev/blog/
whats-new-in-cassandra-2-1-a-better-implementation-of-counters
7. COUNTERS THEN AND NOW

Eric Lubow @elubow #CassandraSummit
WHAT SHOULD YOU WALK AWAY WITH?
๏ Incredibly important to have a deep
understanding around your cases
๏ Sometimes database tuning has nothing to do
with database settings
๏ Understand failure scenarios
๏ #monitoring / #instrumentation
๏ Ignoring best practices is ALMOST never a good
idea

Eric Lubow @elubow #CassandraSummit
THANKS FOR LISTENING

Eric Lubow @elubow #CassandraSummit
QUESTIONS IN LIFE ARE GUARANTEED,
ANSWERS AREN’T.
Eric Lubow
@elubow
#CassandraSummit





























