Embed Size (px)
Citation preview

Deep Learning
Chainer34 2017
Researcher @ Preferred Networks
1

Agenda•
•
•
•
•
•
• Chainer
• numpy Chainer
•
•
• GAN
•
•
2

•
•
• 2010
• 2012
• 2013 - 2014 UC Berkeley (Visiting Student Researcher)
• 2015
• 2016 @ "Semantic Segmentation for Aerial Imagery with Convolutional Neural Network"
• 2016.9 Facebook, Inc.
• 2016.9 Preferred Networks, Inc.
3

• Preferred Networks
• PFN
• 106 8
•
• FANUC Toyota NTT
• We are hiring!
4
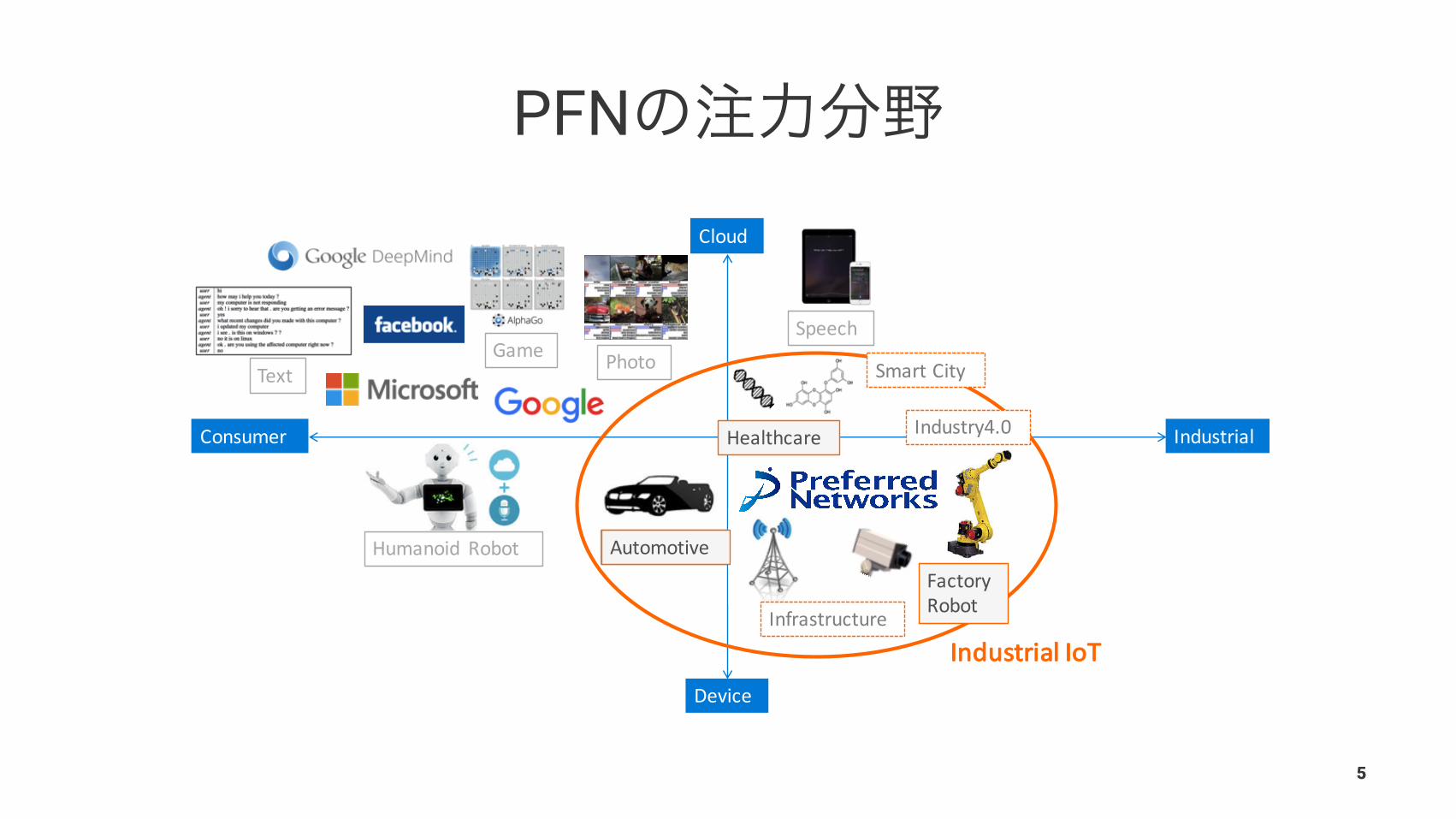
PFN
AutomotiveHumanoid Robot
Consumer Industrial
Cloud
Device
PhotoGameText
Speech
Infrastructure
FactoryRobot
Automotive
Healthcare
SmartCity
Industry4.0
IndustrialIoT
5

•
• Chainer Define-by-Run
• Chainer
• GAN
• ChaineCV ChainerRL6

7

8

•
•
fully-connected layer
9
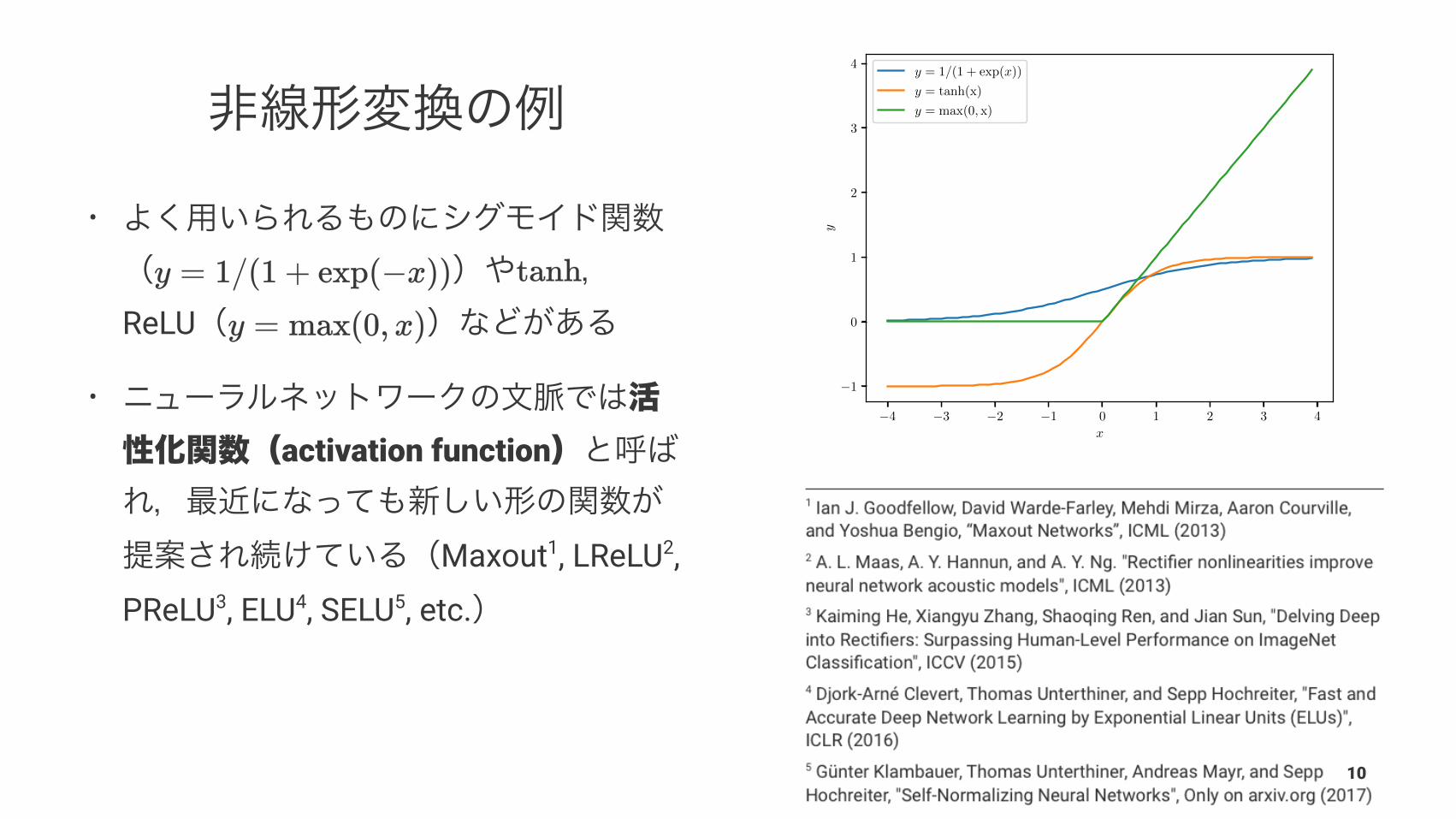
�4 �3 �2 �1 0 1 2 3 4x
�1
0
1
2
3
4
y
y = 1/(1 + exp(x))
y = tanh(x)
y = max(0, x)
•
ReLU
•
activation function
Maxout1, LReLU2,
PReLU3, ELU4, SELU5, etc.
10

"core idea"
The core idea in deep learning is that we assume that the data was generated by the composition of factors or features,
potentially at multiple levels in a hierarchy.
— Ian Goodfellow, Yoshua Bengio, Aaron Courville, "Deep Learning"
11

.
representation
12

h
(1) = a(1)(W(1)x+ b
(1))
h(l) = a(l)(W(l)h(l�1) + b(l�1))
o = a(o)(W(o)h
(o) + b
(o))
•
•
•
hidden layer 1
1
1 Kurt Hornik, Maxwell Stinchcombe, Halbert White, "Multilayer feedforward networks are universal approximators", Neural Networks (1989)
13
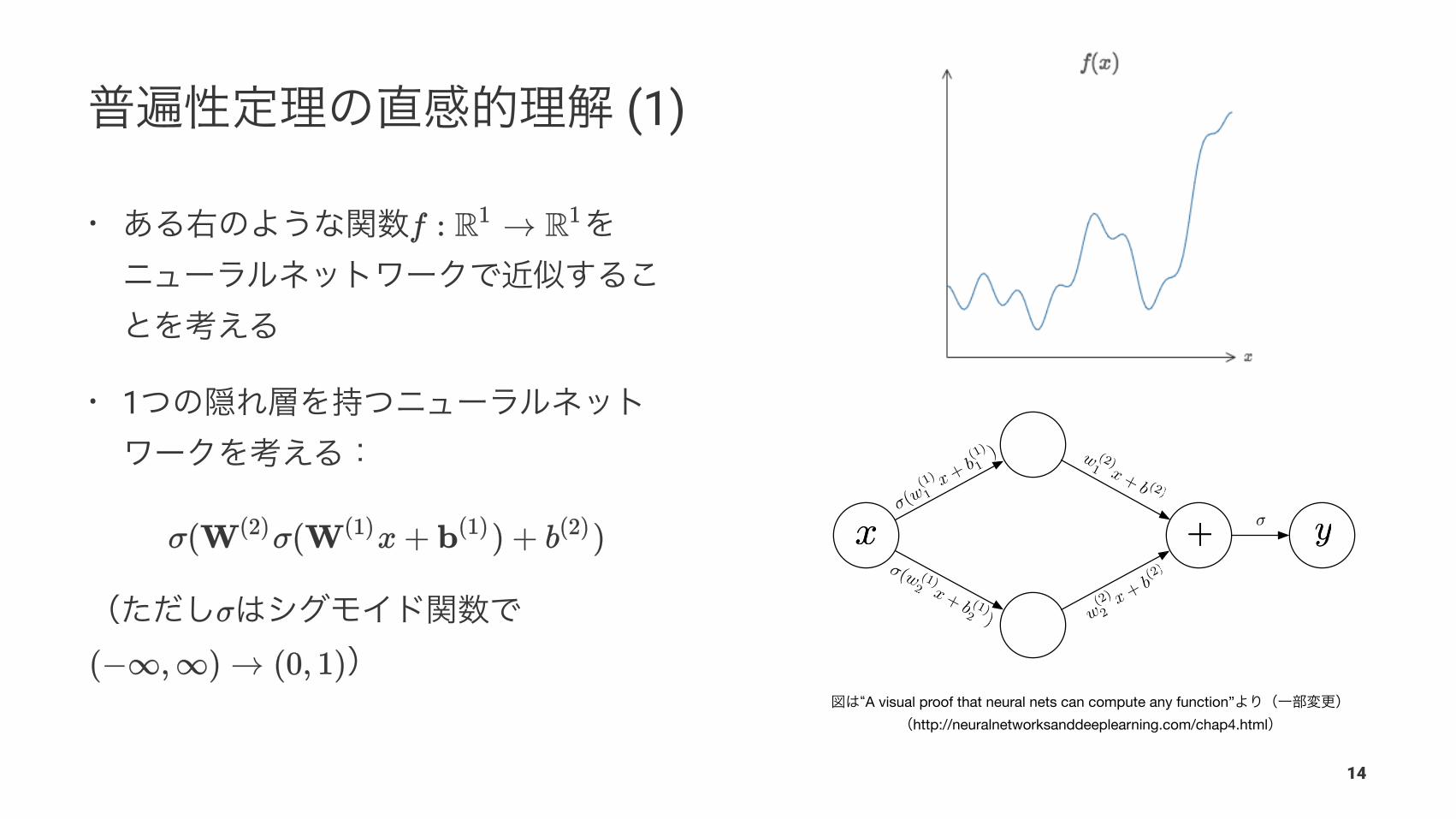
A visual proof that neural nets can compute any function”http://neuralnetworksanddeeplearning.com/chap4.html
(1)
•
• 1
14

A visual proof that neural nets can compute any function”http://neuralnetworksanddeeplearning.com/chap4.html
(2)
• 2
•
15
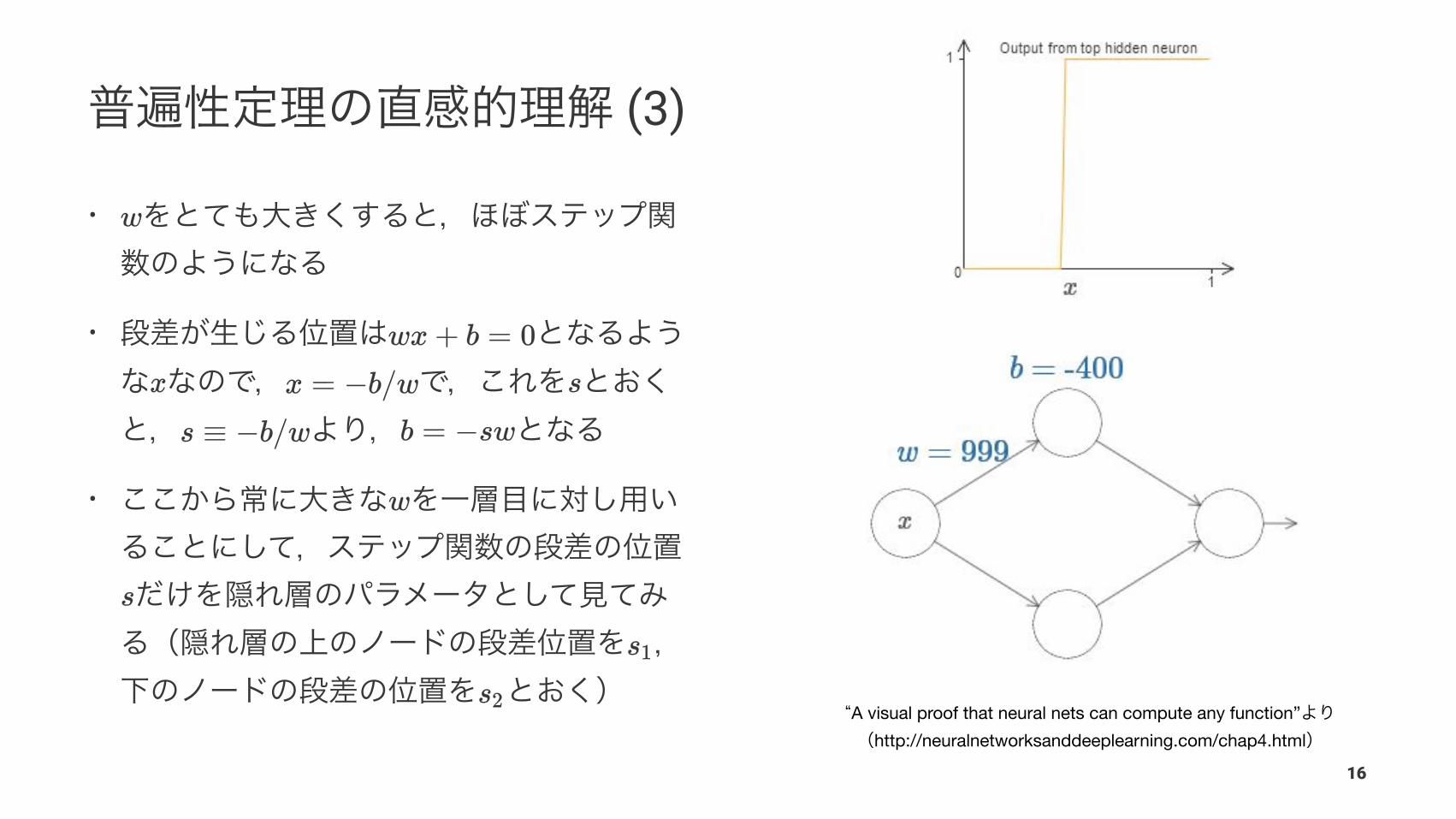
A visual proof that neural nets can compute any function”http://neuralnetworksanddeeplearning.com/chap4.html
(3)
•
•
•
16

A visual proof that neural nets can compute any function”http://neuralnetworksanddeeplearning.com/chap4.html
(4)
•
•
17

A visual proof that neural nets can compute any function”http://neuralnetworksanddeeplearning.com/chap4.html
(5)
•
•
• 4
18

(6)
•
6
•
2
6 “A visual proof that neural nets can compute any function”
http://neuralnetworksanddeeplearning.com/chap4.html
19

(7)
•
• 7
2
7 “A visual proof that neural nets can compute any function”
http://neuralnetworksanddeeplearning.com/chap4.html
20

so many nodes
Replacable?
• 1
•
21

•
•
… 8
• piecewise linear function9
9 Razvan Pascanu, Guido Montufar, and Yoshua Bengio, "On the number of response regions of deep feed forward networks with piece-wise linear activations", NIPS (2014)
8 Merrick Furst, James B. Saxe, and Michael Sipser, "Parity, Circuits, and the Polynomial-Time Hierarchy", Mathematical systems theory (1984)
22

•
training data
•
•
23

•
•
loss function
•
24

•
• softmax
• one-hot
• cross entropy
25

• gradient method
gradient descent
•
• learning rate
•
26

backpropagation
•
•
•
27

•
minibatch
•
An overview of gradient descent optimization algorithms
28

SGD without momentum
SGD with momentum
*
Stochastic gradient descent (SGD)
Momentum SGD15
15 A. Krizhevsky, I. Sutskever, G. E. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks", NIPS (2012)
29

Nesterov accelerated gradient (NAG)16
Momentum SGDRNN
AdaGrad17
AdaDelta18
AdaGrad
RMSProp19, Adam20, Eve21 …
30

: sigmoid cross entropy
•
•
31
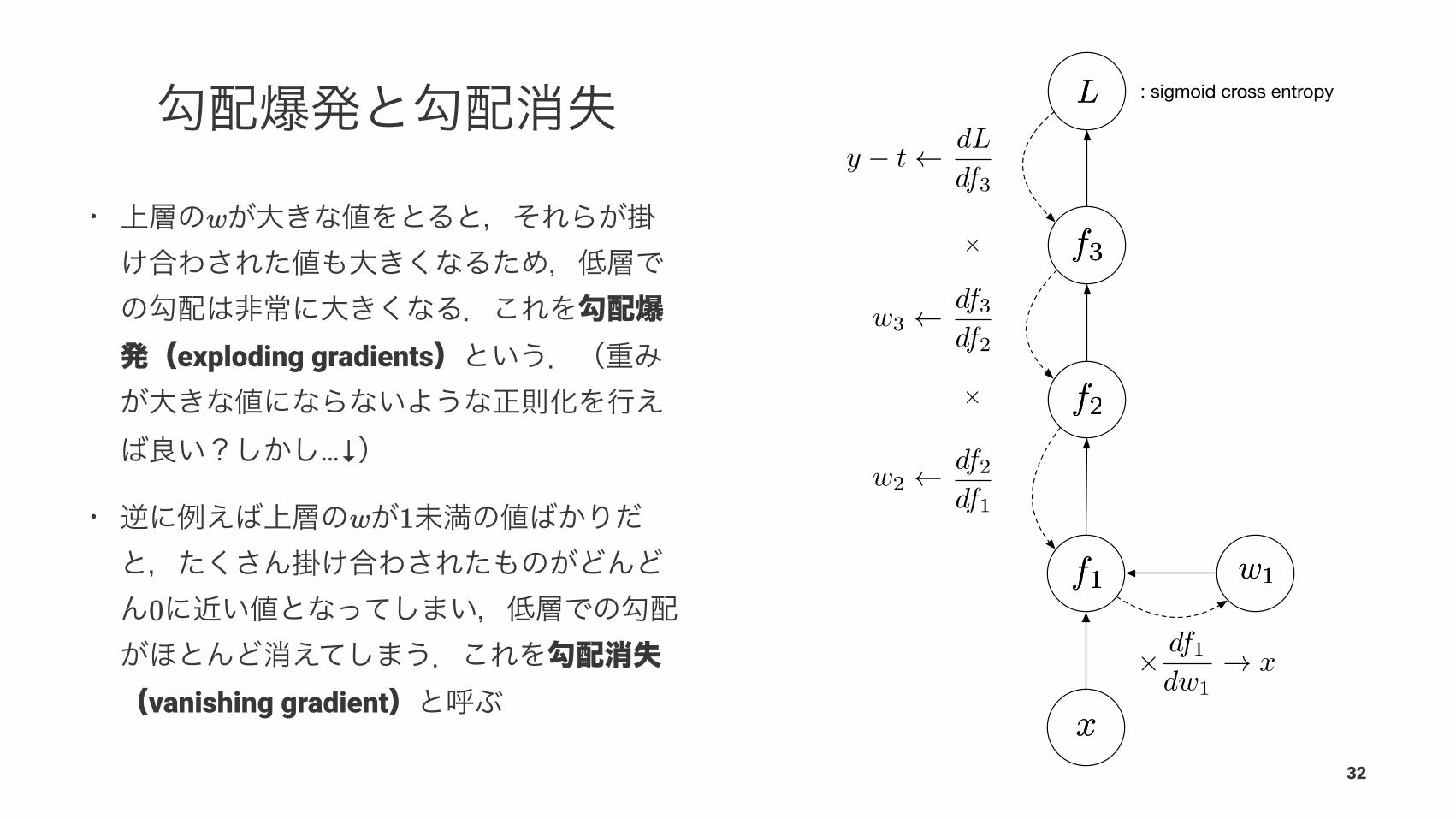
: sigmoid cross entropy
•
exploding gradients
…↓
•
vanishing gradient
32

33

Greedy layer-wise pre-training10
•
Yoshua Bengio ICML 2009
10 Y. Bengio, P. Lamblin, D. Popovici, H. Larochelle, "Greedy layer-wise training of deep networks", NIPS (2006)
34

ReLU rectified linear unit 11
• Sigmoid
0
11 Xavier Glorot, Antoine Bordes, and Yoshua Bengio, "Deep Sparse Rectifier Neural Networks", NIPS Workshop (2010)
35

Dropout12
•
[13] Figure 1 13
13 N. Srivastava, G. E. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, "Dropout: A Simple Way to Prevent Neural Networks from Overfitting", Journal of Machine Learning Research (2014)
12 G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, "Improving neural networks by preventing co-adaptation of feature detectors", On arxiv (2012)
36

[14]
Residual learning 14
•
•
14 K. He, X. Zhang, S. Ren, and J. Sun, "Deep Residual Learning for Image Recognition", CVPR (2016)
37

38

•
1. forward
Dropout
2. backward
3. autograd
2.
4. optimizer 3.
39

Chainer
Preferred Networks
Python
https://github.com/chainer/chainer
40
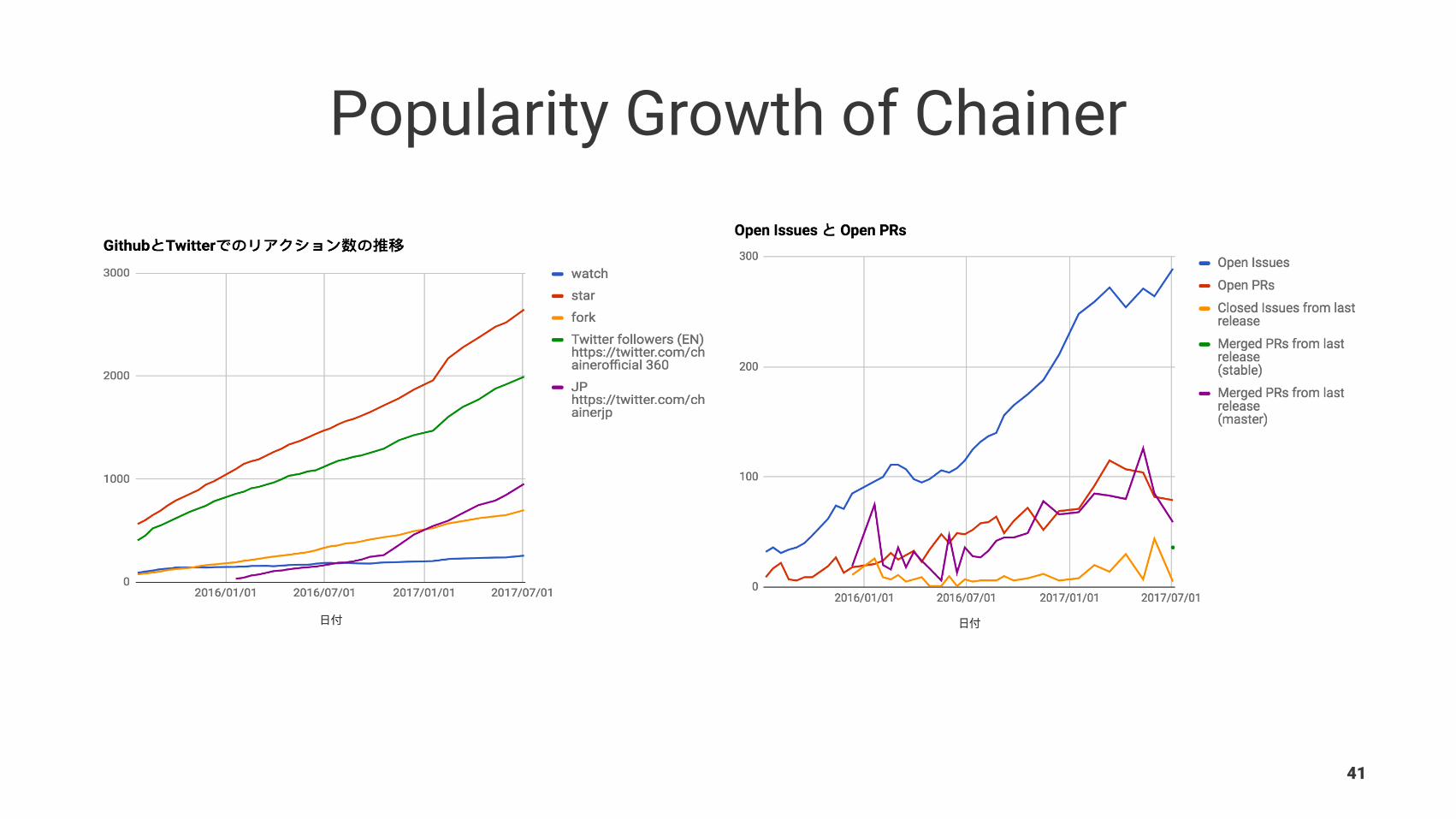
Popularity Growth of Chainer
41

Define-and-Run Define-by-Run
Define-and-Run Define-by-Run
Define-and-Run Define-by-Run
Define-and-Run Define-by-Run
Chainer
•
• Define-and-Run
• Define-by-Run
•
Define-and-Run
42

Define-and-Run Define-by-Run
43

Define-by-Run
•
• Python
• Caffeprototxt
• recurrent neural network; RNN for
BPTT backpropagation through time
44

numpy Chainer
45
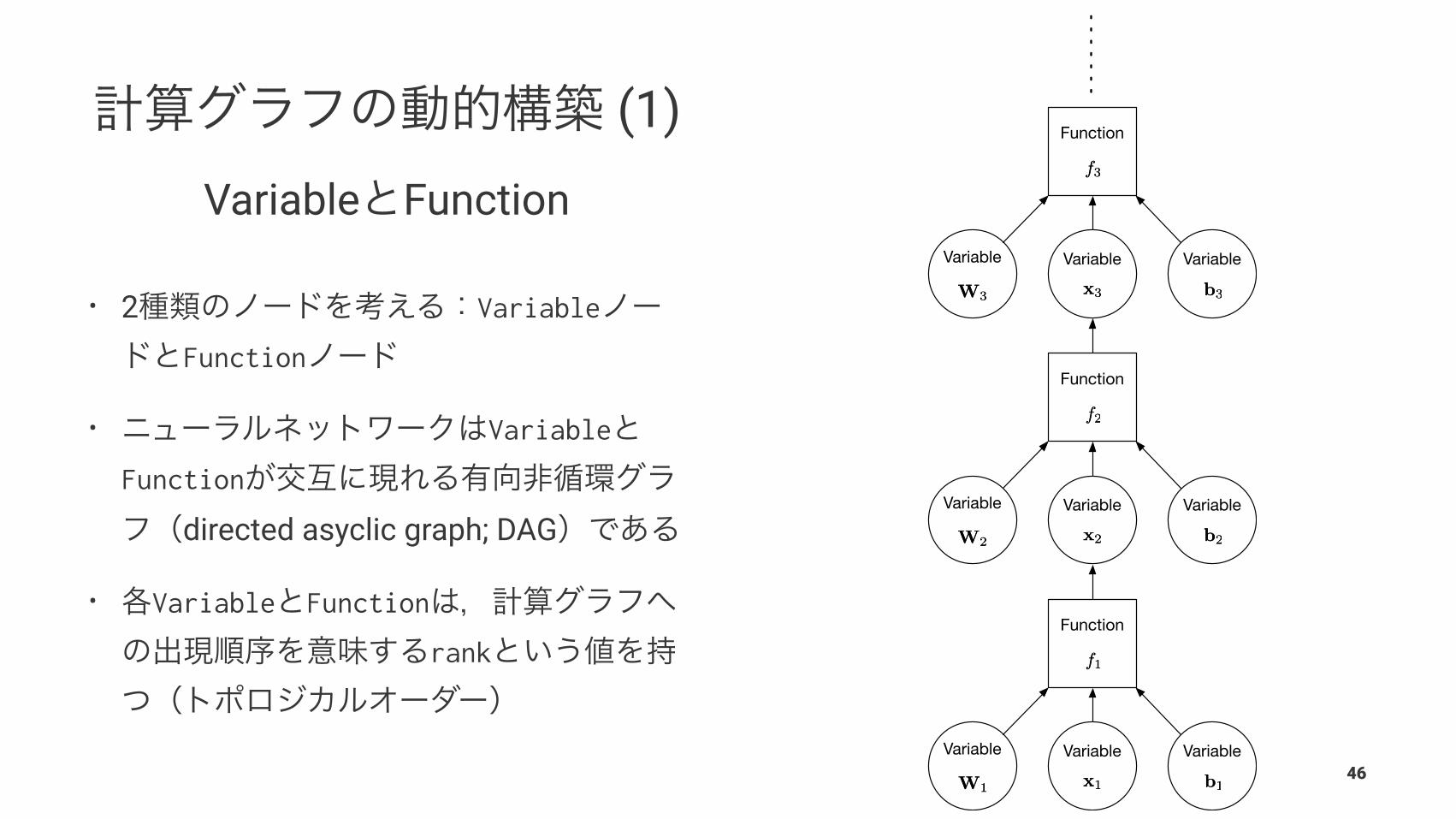
Variable
Function
Function
Function
Variable Variable
VariableVariable Variable
VariableVariable Variable
(1)
Variable Function
• 2 Variable
Function
• Variable
Function
directed asyclic graph; DAG
• Variable Function
rank
46

rank=0
rank=1
rank=2
Variable
Function
Function
Function
Variable Variable
VariableVariable Variable
VariableVariable Variable
creator
creator
inputs
inputs
inputs
(2)
• backward
• Function Variableinputs
• Function Variable
Function creator
• Function Variable rank
Function Variable Function
1 rank
47

ChainerChainer
48

grad_outputs
.backward(inputs, grad_outputs)
.backward(inputs, grad_outputs)
grad
Function
Function
.backward()
grad
Variable
.inputs
Variable Variable
grad_outputs
.cre
ator
.cre
ator
grad_outputs
grad grad grad
VariableVariable Variable
.backward(inputs, grad_outputs)
grad_outputs
grad grad grad
VariableVariable Variable
Function
.inputs
crea
tor
.inputs
=1
crea
tor
(1)
• Define-by-Runbackward Variable
• Variable backward()
Function
backward()
•
inputs
•
grad_outputs
49

(2)
• Variable
Chainer
•
•
grad
50

(3)
• Function backward()
• Function outputs
outputs→creator→outputs
• Function
Function
x, W, b = Variable(init_x), Variable(init_W), Variable(init_b)y = LinearFunction()(x, W, b) # forward
# ...backward, update ...
y = LinearFunction()(x, W, b) # forward
51

Link
• W, bFunction
• Link
•
params()
52

Chain
•
•
• Link
params() Link
53

Optimizer
• Optimizer setup()
Chain Link update()
• Optimizer
• Chainer state
54

• Linear
ReLUFunction
• ReLUReLUFunction
• ReLU (
55

• 2mean
squared error; MSE
• MSE
ReLU
56

•
: MNIST
• 100 1forward
• SGD Optimizer
setup()
57

• MNIST scikit-learn
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original', data_home='./')
x, t = mnist['data'] / 255, mnist['target']t = numpy.array([t == i for i in range(10)]).Ttrain_x, train_t = x[:60000], t[:60000]val_x, val_t = x[60000:], t[60000:]
• 1
• 150
58

Chainer
60

Trainer (1)
Optimizer
• Trainer
• Chainer Chain
• chainer.optimizer
SGD, MomentumSGD, NesterovAG, RMSprop, RMSpropGraves, AdaGrad, AdaDelta, Adam, etc...
61

Trainer (2)
• Chainer
• MNIST
• Validation
len(val)
62

Trainer (3)
•
• Chainer chainer.functions
chainer.links
• softmax cross entropy
63

Trainer
• Trainer
Optimizer
•
• Trainer Extension
importimport
64

Trainer (1)• Extension
• snapshot
• LogReport, PrintReport
• validation Evaluator
• PlotReport
• Graphviz dot dump_graph
• ParameterStatistics
•
• Trainer extensions (https://docs.chainer.org/en/stable/reference/extensions.html)
65

Trainer (2)•
•
• Trainer
• GPU ParallelUpdater, MultiprocessParallelUpdaterMultiprocessIterator
66

GPU•
• Chainer CuPy GPGPU
• CuPy NCCL NCCL2 GPU
• cuDNN NVIDIA v7 CUDA v9
• fp16
67

CuPy
• CuPy NumPyNVIDIA CUDA GPU
• NumPy APINumPy
GPU
•
GPU
• KMeans, Gaussian Mixture ModelExample
CuPy: https://github.com/cupy/cupy
68

69

•
•
• Semantic Segmentation
• Instanse-aware Segmentation
70

horse : 94%dog : 3% pig : 2%cat : 1%...
71

RG
B
72

•
• convolutional layer
• pooling
[A. Krizhevsky, 2016]15**
15 A. Krizhevsky, I. Sutskever, G. E. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks", NIPS (2012)
73

• convolutional neural network; CNN
•
• 1
74

•
•
• stride
• padding
CS231n Convolutional Neural Networks for Visual Recognition
75

•
•
receptive field
•
CS231n Convolutional Neural Networks for Visual Recognition
76

77

2012 Toronto Geoffry Hinton2 10%
28.19125.77
15.31511.743
6.6565.1
3.567 2.991 2.251
ILSVRCObjectClassification (Top-5Error)ImageNet Large Scale Visual Recognition Challenge
(ILSVRC)
• 1000 1128 1000
• 2010
• 2011 localization
• 2012 Fine-grained
• 2013 bounding box
• 2015
• 2016
78
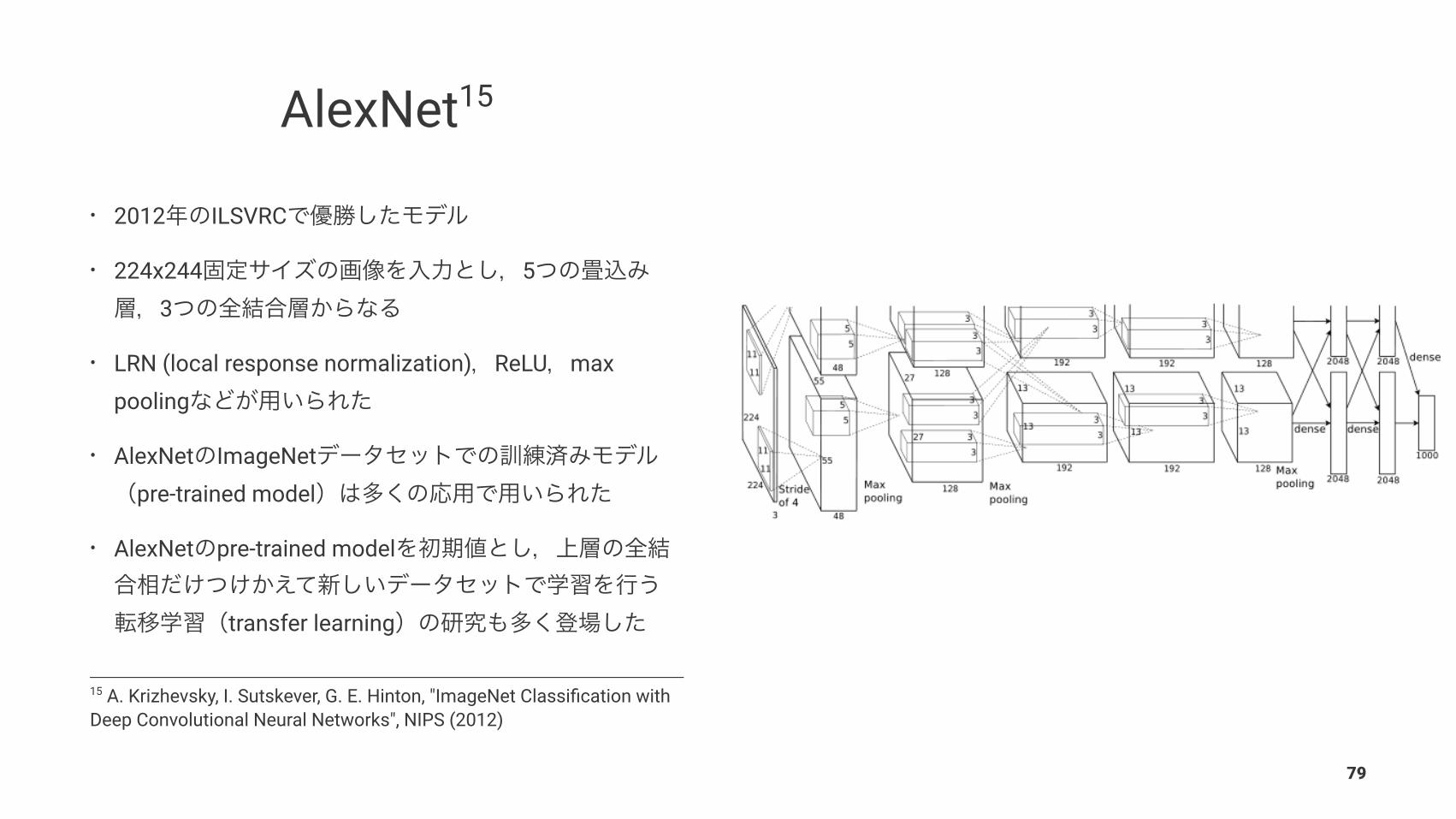
AlexNet15
• 2012 ILSVRC
• 224x244 53
• LRN (local response normalization) ReLU max pooling
• AlexNet ImageNetpre-trained model
• AlexNet pre-trained model
transfer learning
15 A. Krizhevsky, I. Sutskever, G. E. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks", NIPS (2012)
79

GoogleNet16
• 2014 ILSVRC Inception ResNet
• Inception22
• 1x1, 3x3, 5x5concat
• 1x1
16 C. Szegedy, et. al., "Going Deeper with Convolutions", CVPR (2015)
80
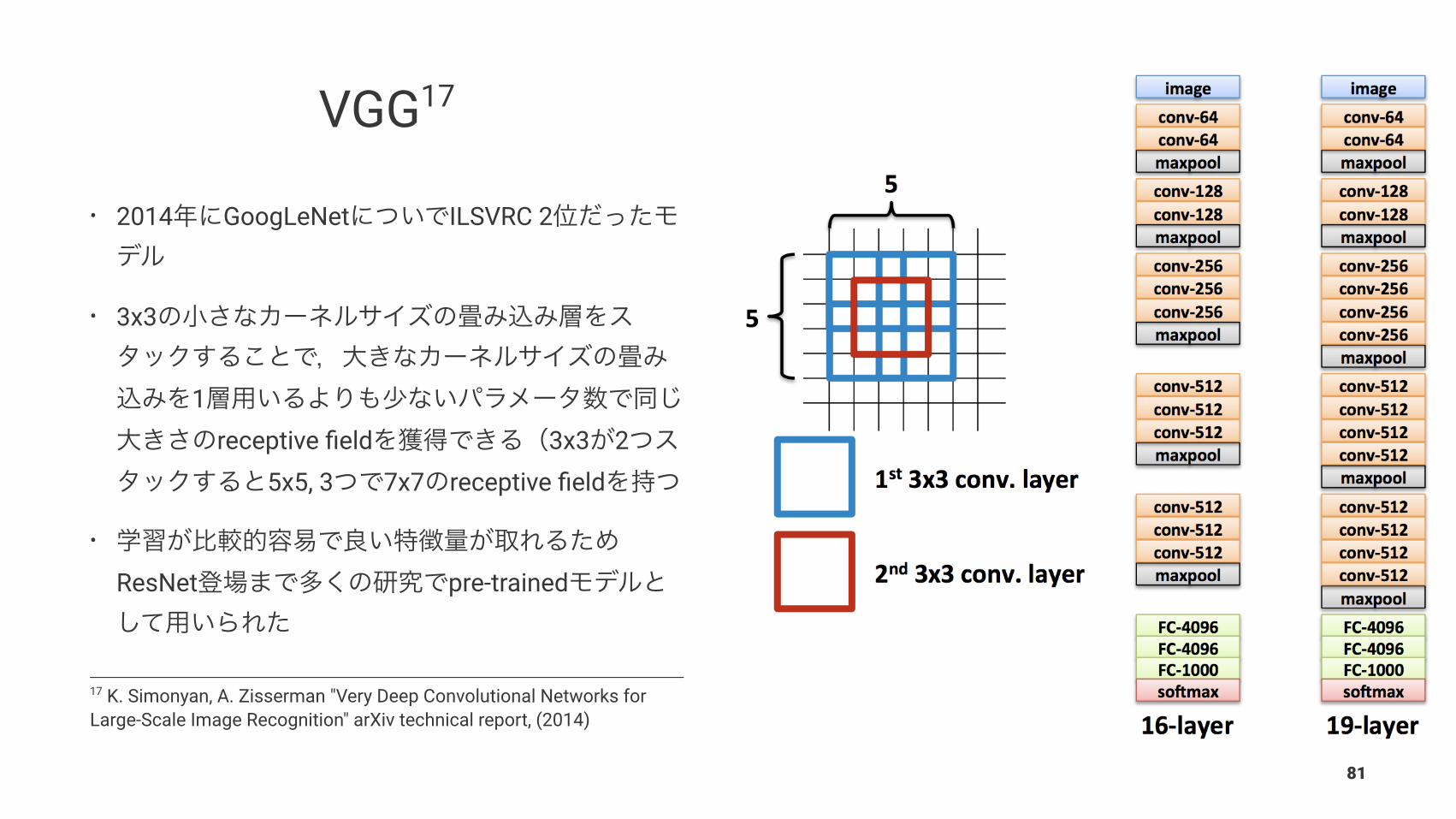
VGG17
• 2014 GoogLeNet ILSVRC 2
• 3x3
1receptive field 3x3 2
5x5, 3 7x7 receptive field
•
ResNet pre-trained
17 K. Simonyan, A. Zisserman "Very Deep Convolutional Networks for Large-Scale Image Recognition" arXiv technical report, (2014)
81

ResNet18
• ILSVRC 2015 GoogLeNet 22152
CIFAR1502
•
•
18 Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, "Deep Residual Learning for Image Recognition." arXiv:1512.03385 (2015)
82

Wide-ResNet19
• ResNet
" "ResNet
• Residual block Dropout ratio30~40%
19 Sergey Zagoruyko, Nikos Komodakis, "Wide Residual Networks", arXiv:1605.07146 (2016)
83

DenseNet20
• CVPR 2017 Residual connection 2 ResBlock
•
•
20 Gao Huang, Zhuang Liu, Kilian Q. Weinberger, Laurens van der Maaten, "Densely Connected Convolutional Networks", CVPR (2017)
84

ResNeXt21
• 2016 ILSVRC 2
•
• cardinality
•
cardinality
21 Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He, "Aggregated Residual Transformations for Deep Neural Networks", CVPR (2017)
85

Squeeze-and-Excitation22
• 2017 ILSVRC
• Inception
•
•
squeezeexcitation
22 Jie Hu, Li Shen, Gang Sun, "Squeeze-and-Excitation Networks", arXiv pre-print: 1709.01507 (2017)
86

- 2017 ILSVRCKaggle ImageNet Object Localization Challenge)-
- MSCOCO Dataset- Places Challenge (ADE20K)- YouTube-8M Video Understanding Challenge- Cityscapes Dataset- Mapillary Vistas Datset- VisualGenome
87

88

Fast R-CNN
Faster R-CNN
Faster/Fast R-CNN/R-CNN23
• R-CNN: region proposals selective search CNN
resize CNNSVM
• Fast R-CNN: RoI Pooling
bounding box bbox regression
• Faster R-CNN: Region proposal network (RPN)CNN RPN
/ bbox
23 Ren, Shaoqing, et al. "Faster R-CNN: Towards real-time object detection with region proposal networks." NIPS (2015)
89

You Only Look Once (YOLO)25
•
bounding box
• bounding box1
end-to-end
• FCN
YOLO9000 CVPR2017
25 Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." arXiv preprint arXiv:1506.02640 (2015)
90

Single Shot Multibox Detector (SSD)24
• YOLO Faster R-CNN
•
•
• End-to-end
24 Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." ECCV (2016)
91

Semantic Segmentation
92

Semantic Segmentation
•
•
" "
• Instance-aware
93

(1)
Dilated convolution51
•
•
51 "Multi-Scale Context Aggregation by Dilated Convolutions", ICLR 2016
94

(2)
Multi-scale feature ensemble
•
•
52
52 "Hypercolumns for Object Segmentation and Fine-grained Localization", CVPR 2015
95

(3)
Conditional random field (CRF)
• CNN refine
(DeepLab53)
• DeepLabrefine End-to-End
(DPN54, CRF as RNN55, Detections and
Superpixels56)
56 "Higher order conditional random fields in deep neural networks", ECCV 2016
55 "Conditional random fields as recurrent neural networks", ICCV 2015
54 "Semantic image segmentation via deep parsing network", ICCV 2015
53 "Semantic image segmentation with deep convolutional nets and fully connected crfs", ICLR 2015
96

(4)
Global average pooling (GAP)
•
• ParseNet57 Global average poolingFCN
57 "Parsenet: Looking wider to see better", ICLR 2016
97

(1)
Mismatched relationship
•
•
•
• FCN
98

(2)
Confusing Classes
•
• ADE20K17.6%
58
• FCN
•
58 "Semantic understanding of scenes through the ADE20K dataset", CVPR 2017
99

(3)
Inconspicuous Classes
•
•
FCN
•
sub-region
100

•
•
•
101

Fully Convolutional Network26
• Classificationpre-training
1x1
• Deconvolution
• semantic low level skip connection
26 Jonathan Long and Evan Shelhamer et al., "Fully Convolutional Networks for Semantic Segmentation", appeared in arxiv on Nov. 14, 2014
102

Deconvolution
• Deconvolution transposed convolution backward convolution
• Convolution
1. stride
2. -1
3. padding
4. Convolution
• stride
Convolution arithmetic https://github.com/vdumoulin/conv_arithmetic
103

Global Average Pooling (GAP)59
•
• ResNet receptive field
• GAP
•
59 "Parsenet: Looking wider to see better", ICLR 2016
104

SegNet27
•
• Max pooling
•
0
27 Vijay Badrinarayanan, Alex Kendall and Roberto Cipolla "SegNet: A
Deep Convolutional Encoder-Decoder Architecture for Image
Segmentation." PAMI, (2017)
105

U-Net28
•
• Max poolingDeconvolution
•
concat
• "U" U-Net
28 “U-Net: Convolutional Networks for Biomedical Image Segmentation”, Olaf Ronneberger, Philipp Fischer, Thomas Brox, 18 May 2015
106

PSPNet60
Pyramid Pooling Module
60 Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia, "Pyramid Scene Parsing Network", CVPR (2017)
107

Pose Estimation
108

Pose Affinity Field33
•
CNN Convolutional Pose MachinePart Affinity Field
CNN
• OpenPose
https://github.com/CMU-Perceptual-Computing-Lab/openpose
• Geforce GTX 1080 9fps
33 Zhe Cao and Tomas Simon and Shih-En Wei and Yaser Sheikh, "Realtime Multi-Person Pose Estimation using Part Affinity Fields", CVPR (2017)
109

•
→ Faster R-CNN
•
→
110

repeatability
reproducibility
repeatability reproducibility
repeatability
reproducibility
ACM Repeatability (same team, same experimental setup), Replicability(different team, same experimental setup), Reproducibility (different
team, different experiental setup)http://www.acm.org/publications/policies/artifact-review-badging
111

ChainerCVhttps://github.com/chainer/chainercv
ChainerCV
•
•
•
• pre-trained
112

ChainerCV
113

- Faster R-CNN (VGG16-based, )- SSD300, SSD512
:
- SegNet- PSPNet (coming soon)
- PASCAL VOC (bounding box, segmentation)- Stanford Online Products (classification)- CamVid (segmentation)- Caltech-UCSD Birds-200 (classification, key-points)- Cityscapes (segmentation)
114

: pretrained-model
ChainerCV pretarined_model
model = FasterRCNNVGG16() #
# PASCAL VOC2007
model = FasterRCNNVGG16(pretrained_model='voc07')
model = SSD300(pretrained_model='voc0712')model = SegNet(pretrained_model='camvid')
115

predict()
ChainerCV predict()
#
bboxes, labels, scores = model.predict(imgs)
#
labels = model.predict(imgs)
116

predict()
1.
2. forward
3. non-maximum supression
117

[37] D. Xu, Y. Zhu, C. B. Choy, L. Fei-Fei, “Scene Graph Generation by Iterative Message Passing”, CVPR (2017)
•
Faster R-CNN Region Proposal network (RPN)
• RPN…
•
118

ChainerCV• Chainer
• public
•
from chainercv.datasets import VOCDetectionDataset
dataset = VOCDetectionDatset(split='trainval', year='2007')
# "trainval" 34
img, bbox, label = dataset[34]
119

ChainerCV transforms
•
data augmentation
• ChainerCVdata augmentation
•
• center_crop, pca_lighting, random_crop, random_expand, random_flip, random_rotate, ten_crop, etc...
120

ChainerCV transformsTransformDataset Chainer
from chainercv import transforms
def transform(in_data): img, bbox, label = in_data img, param = transforms.random_flip(img, x_flip=True, return_param=True) bbox = transforms.flip_bbox(bbox, x_flip=param['x_flip']) return img, bbox, label
dataset = TransformDataset(dataset, transform)
bounding box
121

bounding box
ChainerCV
•
•
• bounding box
• matplotlib
122

ChainerCV
mean Intersection over Union (mIoU) mean
Average Precision (mAP)
Chainer Trainer Extension
# mAP Trainer Extension
evaluator = chainercv.extension.DetectionVOCEvaluator(iterator, model)
#
# e.g., result['main/map']
result = evaluator()
123

GAN
125

•
•
• RBM restricted boltzmann machine 34
Variational Auto-Encoder (VAE)35
Generative Adversarial Nets (GAN)
35 Diederik P Kingma and Max Welling, "Auto-Encoding Variational Bayes", ICLR (2014)
34 Smolensky, Paul, "Chapter 6: Information Processing in Dynamical Systems: Foundations of Harmony Theory", Parallel Distributed Processing: Explorations in the Microstructure of Cognition (1986)
126

Generator
Discriminator
Dataset
OR from dataset?
Generative Adversarial Nets36
•
unsupervised learning
• G D
• D G
• G D
36 I. J. Goodfellowm, et. al., "Generative Adversarial Nets", NIPS (2014)
127

GAN
•
• Discriminator
• Generator Discriminator
128

GAN
•
Generator
• Generator
129

DCGAN37
• GAN
• Generator 1Deconvolution
• Discriminator Generator
•
•
37 Alec Radford, Luke Metz, Soumith Chintala, "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks", ICLR (2016)
130

DCGAN37
• GAN DCGAN
• Dstride=2
• D Global Average Pooling
• D Leaky ReLU
• G D Batch Normalization GD
37 Alec Radford, Luke Metz, Soumith Chintala, "Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks", ICLR (2016)
131

Improved Techniques for Training GANs38
• GAN
• Feature matching: D fake real
• Minibatch discrimination: G D1 mode cllapse
Dconcat
•
38 T. Salimans, I. Goodfellow, et. al., "Improved Techniques for Training GANs", NIPS (2016)
132

Improved Techniques for Training GANs38
• Generator
Semi-supervised learning
• ImageNet DCGAN
• Inception score GANpre-trained model
38 T. Salimans, I. Goodfellow, et. al., "Improved Techniques for Training GANs", NIPS (2016)
133

Wasserstein GAN (WGAN)39 (1)• GAN Generator
Wasserstein Earth Mover's Distance
WGAN
• Generator 2
Wasserstein
39 Martin Arjovsky, Soumith Chintala, Léon Bottou, "Wasserstein GAN", arXiv:1701.07875 (2017)
134

Wasserstein GAN (WGAN)39 (2)• WGAN Discriminator Wasserstein
• Discriminator(D)
D Wasserstein
•
39 Martin Arjovsky, Soumith Chintala, Léon Bottou, "Wasserstein GAN", arXiv:1701.07875 (2017)
135

Wasserstein GAN (WGAN)39 (3)• WGAN Discriminator Wasserstein
Wasserstein
• Generator Wasserstein
• Generator Wasserstein
39 Martin Arjovsky, Soumith Chintala, Léon Bottou, "Wasserstein GAN", arXiv:1701.07875 (2017)
136

Wasserstein GAN (WGAN)39 (4)
1. Discriminator
2. 0.01
3. Generator
4. 39 Martin Arjovsky, Soumith Chintala, Léon Bottou, "Wasserstein GAN", arXiv:1701.07875 (2017)
137

WGAN with Gradient Penalty (WGAN-GP) 40
• WGAN Discriminator
Gradient Penalty
• Chainer v3
40 Gulrajani, Ishaan, et al. "Improved training of wasserstein gans." arXiv preprint arXiv:1704.00028 (2017).
138

Temporal Generative Adversarial Nets (TGAN)41
• WGAN
•
Video Generator
Image Generator
41 Masaki Saito, Eiichi Matsumoto, Shunta Saito, "Temporal Generative Adversarial Nets with Singular Value Clipping", ICCV (2017)
139

Temporal Generative Adversarial Nets (TGAN)41
•
GAN WGAN
1singular
value clipping
• Inception score
41 Masaki Saito, Eiichi Matsumoto, Shunta Saito, "Temporal Generative Adversarial Nets with Singular Value Clipping", ICCV (2017)
140

SimGAN42
•
CG Refiner
• Refiner Discriminatoradversarial loss
self-regularization
• Apple, inc. CVPR 2017
"Improving the Realism of Synthetic Images"
42 A. Shrivastava, et. al. "Learning from Simulated and Unsupervised Images through Adversarial Training", CVPR (2017)
141

Chainer-GAN-lib
GAN ChainerChainer Trainer GANhttps://github.com/pfnet-research/chainer-gan-lib
142

Adversarial examples70
• " "
•
NIPS 2017: Non-targeted Adversarial Attack
Google Brain "Non-targeted"
70 Ian J. Goodfellow, Jonathon Shlens, Christian Szegedy, "Explaining and Harnessing Adversarial Examples." ICLR (2015)
143

144
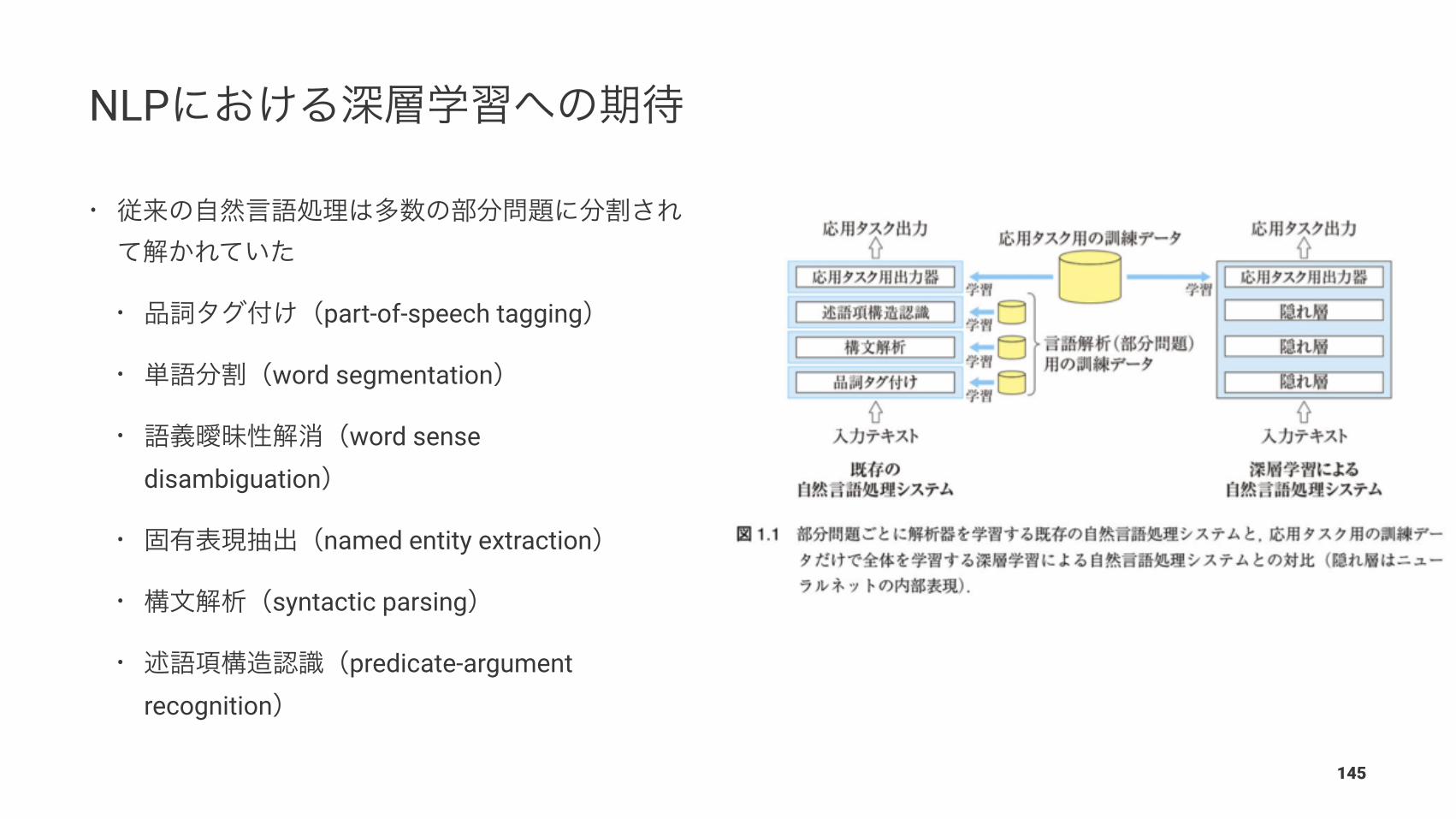
NLP
•
• part-of-speech tagging
• word segmentation
• word sense disambiguation
• named entity extraction
• syntactic parsing
• predicate-argument recognition
145

NLP
•
•
•
146

147

RNN
• RNN (recurrent neural networks)
•
RNN
148

http://qiita.com/t_Signull/items/21b82be280b46f467d1b
LSTM•
• 1 3
•
:
• 1
•
•
149

2.11
Gated recurrent unit (GRU)
• LSTM
• reset 1
• update) 1
• GRU LSTM
150

RNN
one-hot
RNN
RNN
151

s.t.
perplexity; PPL 2
PPL PPL
152

1. Penn Treebank ptb90 1
Chainer example ptb examplehttps://github.com/chainer/chainer/
tree/master/examples/ptb
2. One Biliion Word8 80
3. Hutter90MB/5MB/5MB
train/val/test
153

sequence-to-sequence
•
•
RNN
•
•
•
154

155

greedy algorithm
156

157

attention mechanism
LSTM
158

Attention is all you need65
RNN/CNN Attention TransformerSOTA
Transformer: A Novel Neural Network Architecture for Language Understanding
65 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, "Attention Is All You Need", (2017)
159

160

policy
1.
2.
3.
4.
161

•
→ return
• discounted total reward
•
state value
162

state value function
optimal policy
163

action value function
164

greedy
ε-greedy
greedyε-greedy ε
greedy
165

Q Q-learning
Q
Q
166

Q (1)
Q Q
167

Q (2)
Q
Q
→MSE SGD
168

Deep Q-Network (DQN)43
• Q
• Q NNDQN
• Experience replay
• Target Q-Network
• clipping
DQN SPACE INVADERS (uploaded by DeepMind)
43 Mnih, Volodymyr, et al. "Playing Atari with Deep Reinforcement Learning", NIPS (2013)
169

DQNExperience replay- replay memory
- Q
Target Q-Network-
Q
- Q $\theta$ Q
clipping
- clip
170

• Q
•
•
171

•
172

• 45
•
45 Pierre Andry, et. al., "Learning invariant sensorimotor behaviors: A developmental approach to imitation mechanisms." Adaptive behavior (2004)
173

Actor-Critic• Actor
Critic
•
•
174

Asynchronous Advantage Actor-Critic (A3C)44
•
•
Actor-Critic
• Experience replayRNN
•
44 V. Mnih, et. al., "Asynchronous Methods for Deep Reinforcement Learning", ICML (2016)
175

DDPG46
• Deep Deterministic Policy Gradient (DDPG) Actor-Critic
• Deep Q-NetworkEnd-to-End
•
Deep Reinforcement Learning (DDPG) demonstration
46 Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning." arXiv preprint arXiv:1509.02971 (2015)
176

ChainerRL :• ChainerRL OpenAI Gym Gym
• reset step
env = YourEnv()# reset
obs = env.reset()action = 0# step
# 4
obs, r, done, info = env.step(action)
178

ChainerRL : (1)•
• Chainer
Q
class CustomDiscreteQFunction(chainer.Chain): def __init__(self): super().__init__(l1=L.Linear(100, 50) l2=L.Linear(50, 4)) def __call__(self, x, test=False): h = F.relu(self.l1(x)) h = self.l2(h) return chainerrl.action_value.DiscreteActionValue(h)
179

ChainerRL : (2)
class CustomGaussianPolicy(chainer.Chain): def __init__(self): super().__init__(l1=L.Linear(100, 50) mean=L.Linear(50, 4), var=L.Linear(50, 4)) def __call__(self, x, test=False): h = F.relu(self.l1(x)) mean = self.mean(h) var = self.var(h) return chainerrl.distribution.GaussianDistribution(mean, var)
180

ChainerRL :
Q
Chainer Optimizer
q_func = CustomDiscreteQFunction()optimizer = chainer.Adam()optimizer.setup(q_func)agent = chainerrl.agents.DQN(q_func, optimizer, ...) #
181

ChainerRL : (1)
ChainerRL
• ChainerRL
chainerrl.experiments.train_agent_with_evaluation( agent, env, steps=100000, eval_frequency=10000, eval_n_runs=10, outdir='results')
182

ChainerRL : (1)
obs = env.reset()r = 0done = Falsefor _ in range(10000): while not done: action = agent.act_and_train(obs, r) obs, r, done, info = env.step(action) agent.stop_episode_and_train(obs, r, done) obs = env.reset() r, done = 0, Falseagent.save('final_agent')
183

ChainerRL Quick Start Guide
https://github.com/chainer/chainerrl/blob/master/examples/quickstart/quickstart.ipynb
OpenAI Gym DQN
184

Chainer
185














![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://img.pdfslide.net/doc/110x75/5a6478457f8b9a31568b4567/ai08-chainer-microsoft-.jpg)

















