Embed Size (px)
Citation preview

NoSQL with MySQL Cluster トランザクション対応NoSQLとしてのMySQL Cluster
MyNA・JPUG合同DB勉強会 in 東京 Twitter: @RDBMS
2015/06/26

免責事項
本内容は個人の見解であり、
所属組織を代表するものではありません。

Agenda
- MySQL Cluster概要 概要、特性、アーキテクチャー
- MySQL Clusterへの接続
SQL , NoSQL
- デモ(ClusterJによるデータ処理)
環境、トランザクション、デモ&確認

MySQL Cluster概要

5

History of MySQL Cluster ”NDB”
90年代後期
Ericsson (Alzato) にて設計/開発
2003年
MySQL ABが NDB Cluster ProjectをEricssonから引き継ぎ開発 (MySQL 4.1)
2008年
SunがNDB Cluster Projectを引き継ぎ開発(MySQL 5.1/Cluster 6.x~ )
2010年
OracleがNDB Cluster Projectを引き 継ぎ開発(MySQL 5.1 / Cluster 7.x~)
Original design paper: Design and Modelling of a Parallel Data Server for Telecom Application
MySQL Clusterの基礎となっている技術は、通信機器ベンダのエリクソンで携帯通信網の加入者 データベース向けに開発されたEricsson Network Data Base(NDB)と呼ばれていた技術が起源
Changes in MySQL 5.0.9 (2005-07-15)
Changes in MySQL 5.0.8 (Not released)
Changes in MySQL 5.0.7 (2005-06-10)

MySQL Clusterとは?
•MySQLとは開発ツリーの異なる別製品
•共有ディスクを使わずに、アクティブ-アクティブのクラスタ構成が組める
•元々はSQLを使わないデータベース(NOSQL)だったが、MySQLと統合され SQLも追加で使えるようになった(NoSQLとSQL 共に使えるデータベース)
•各テーブルのストレージエンジンを選択する事が出来る(InnoDB or NDB)
• SQL, NoSQL共にACID処理可能なインメモリーデータベース
適したシステム •高可用性が求められるシステム
•同時多発的に大量の短いトランザクションが発生するシステム
•読込み処理だけでなく、書込み処理に対しても拡張性が求められるシステム
参照:MySQL Cluster Evaluation Guide

補足:MySQLから見たNDB(Storage Engine)
参考:18.1.5.1. NDB および InnoDB ストレージエンジンの違い
NDB (ndbcluster) in-memory clustered storage engine called NDB (which stands for “Network DataBase”).
NDB ClusterはMySQL Clusterの基礎となる分散データベース·システムです。 NDB API (C++)を経由してアクセスする事で,MySQLから独立して利用する事が可能です。 MySQLサーバの観点からは,NDB Clusterは行のテーブルを格納するためのストレージエンジンです。 NDB Clusterの観点からは、MySQLサーバインスタンスがクラスタに接続されているAPIのプロセスの一つです。
(NDB)
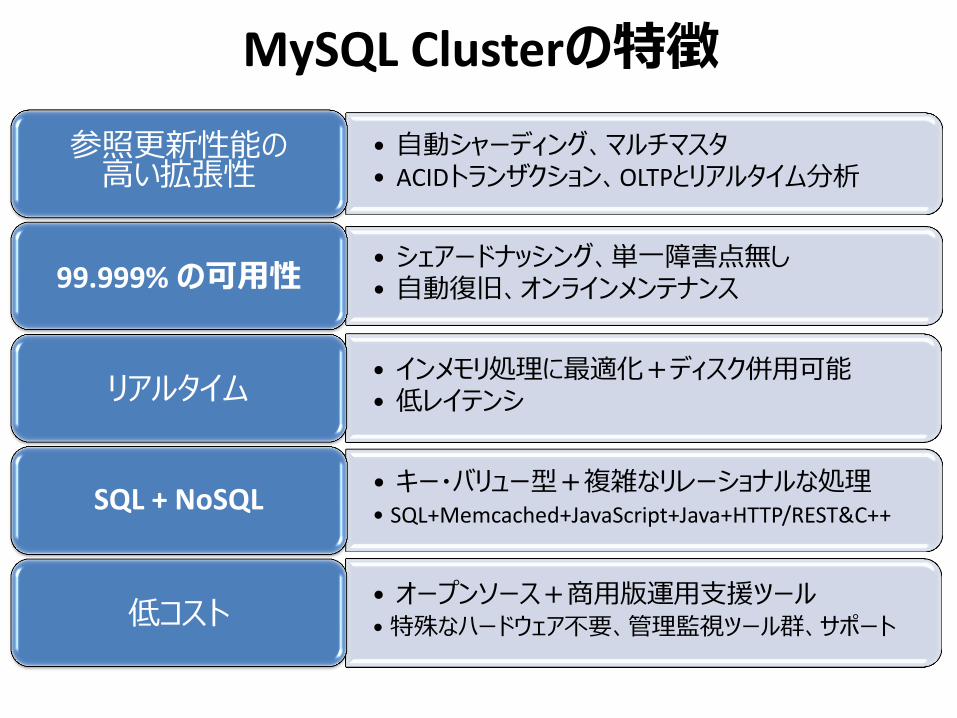
MySQL Clusterの特徴
• 自動シャーディング、マルチマスタ • ACIDトランザクション、OLTPとリアルタイム分析
参照更新性能の 高い拡張性
• シェアードナッシング、単一障害点無し • 自動復旧、オンラインメンテナンス 99.999% の可用性
• インメモリ処理に最適化+ディスク併用可能 • 低レイテンシ リアルタイム
• キー・バリュー型+複雑なリレーショナルな処理 • SQL+Memcached+JavaScript+Java+HTTP/REST&C++
SQL + NoSQL
• オープンソース+商用版運用支援ツール • 特殊なハードウェア不要、管理監視ツール群、サポート 低コスト

MySQL Cluster アーキテクチャ
データ・ノード (冗長化・データ分散)
ノード・グループ1
F1
F3
F3
F1
ノード
1
ノード
2
ノード・グールプ 2
F2
F4
F4
F2
ノード
3
ノード
4
アプリケーション・ノード (SQL, NoSQL)
REST JPA
管理ノード 管理ノード (構成、調停) Syn
c
Sync

Data Nodeの拡張(例)
SMALL Medium Large
例) Max 200M QPM and 20M UPM.
例) Max 600M QPM and 55M UPM.
例) Max 1100M QPM and 110M UPM
Data nodeは最大48台まで増設可能 (Node IDは、1~48を使用) → ノードを増やすことで、処理とデータの分散を行うので負荷を分散する事が可能
例) 100GB/Node 例) 100GB/2Group=50GB/Node 例) 100GB/4Group=25GB/Node

参照: http://ascii.jp/elem/000/000/985/985073/

• インメモリーテーブル – 永続性のあるインメモリテーブル
– ディスクテーブルも併用可能
• 大規模なOTLP処理に向く
• 分析のためにJOINも可能
• インデックスが使えない検索は 並列でスキャン
• MySQL Cluster 7.4 FlexAsych
– 2億NoSQL 読込み/秒
MySQL Cluster 7.4 NoSQL パフォーマンス 2億NoSQL読込み/秒
-
50,000,000
100,000,000
150,000,000
200,000,000
250,000,000
2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32
Readspersecond
DataNodes
FlexAsyncReads

• インメモリーテーブル – 永続性のあるインメモリテーブル
– ディスクテーブルも併用可能
• 大規模なOTLP処理に向く
• 分析のためにJOINも可能
• インデックスが使えない検索は 並列でスキャン
• MySQL Cluster 7.4 DBT2 BM
– 250万SQL/秒
MySQL Cluster 7.4 SQL パフォーマンス 250万SQL/秒
-
500,000
1,000,000
1,500,000
2,000,000
2,500,000
3,000,000
2 4 6 8 10 12 14 16
SQLStatements/sec
DataNodes
DBT2SQLStatementsperSecond

Connect to MySQL Cluster アプリケーションノード


NoSQL & SQL Access to MySQL Cluster data
Ndbcluster (NDB)

本日は時間も限られているので,ClusterJにフォーカスして説明させて頂きます。 Memcachedに関しては,次のセッションで ご確認下さい。
【参考】 概要: MySQL Cluster API Developer Guide Java: 4.2.1. Getting, Installing, and Setting Up MySQL Cluster Connector for Java
Node.JS: Using JavaScript and Node.js with MySQL Cluster – First steps MySQL NoSQL Connector for node.js Memcached: Chapter 6. ndbmemcache—Memcache API for MySQL Cluster NDB API: Chapter 2. The NDB API JPA: 4.2.3. Using JPA with MySQL Cluster

• ドメイン・オブジェクト・モデル
– Java API
– 高パフォーマンス、低レイテンシ
– 豊富な機能
– ClusterJ
• ClusterJの上位レイヤーとしてJPA インターフェース
– JPA準拠 (Persistence API)
• OpenJPA のプラグインとして実装
– 可能な場合はClusterJを使用、 いくつかの処理はJDBC経由に迂回する。
– 全体としてJDBC単独よりも高速化を狙う
– Javaアプリ開発者にとってより扱いやすく
– WebアプリでのMySQL Cluster利用を簡素化
NoSQL: Connector for Java (ClusterJ/JPA)
clusterj: Required for building MySQL Cluster with ClusterJ support. openjpa: Required for building MySQL Cluster with ClusterJPA support.

NoSQL: Connector for Java (ClusterJ/JPA)
参照: http://dev.mysql.com/doc/ndbapi/en/mccj.html JTie: framework for mapping any C++ API to Java

SQL: MySQL Connection すべての標準MySQLコネクタへの接続を提供します。一般的なWeb 開発言語および フレームワーク:PHP, Perl, Python, Django, Ruby, Ruby on Rails等JDBC (または EclipseLink、Hibernate等を含むORMへの追加的接続性); .NET, ODBC等
CREATE TABLE `T20150319` ( `id` int(11) NOT NULL AUTO_INCREMENT, `memo` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=ndbcluster AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4

デモ

デモ環境
抜粋: IANA
仮想サーバー #3 ClusterJ Client
java version "1.6.0_35“ 192.168.56.108
仮想サーバー #1 SQL / Data / Mgt
192.168.56.114
仮想サーバー #2 SQL / Data
192.168.56.115
データ
書き込み
処理
@@version: 5.6.24-ndb-7.4.6-cluster-commercial-advanced

デモ用スクリプト(トランザクション処理) • トランザクションを明示することも可能
– begin() – commit() – rollback()
• トランザクションのロールバックを指示することも可能 – setRollbackOnly() – getRollbackOnly()
※ これらの関数が使用されない場合、それぞれの処理が単一トランザクションとして扱われる。 Transaction: There is one transaction per session at any point in time. By default, each operation (query, insert, update, or delete) is run under a new transaction.
[Annotation] Employee.class Employee.java [Application] Main.class Main.java [Connection] clusterj.properties
ここでは、パフォーマンスを
考慮して、トランザクションを1つにまとめ、データベースに1回で書き込まれるようにしています。

デモ内容
ClusterJによるデータ処理 ~ NoSQL処理確認~
1.データINSERT処理 (1件) 2.データ更新処理 (1件) 3.データINSERT LOOP処理(100件) 4.データ削除処理 (全件)
※NoSQLにて処理したデータをSQLコマンドにて並行して確認。(各処理後) ※ndbinfo.memory_per_fragmentからデータ分散状況確認。(3でデータを投入後) ※SQL側の処理が無い事を、Generalログにて確認。(最後)
MySQL Cluster Data Nodes
Data Layer
Apps Apps Apps Apps
JPA
Cluster JPA
JDBC Cluster J
MySQL JNI
NDB API (C++)

まとめ MySQL Clusterは,NoSQL,SQL共にトランザクション処理可能なデータベースです。 また、システム運用において重要な高可用性 と,柔軟なスケールアウトをサポートします。 コミュニティ、コマーシャル共に利用可能ですので,是非お試しください。 ※コマーシャル版では、管理ツール(MCM)が利用可能です。
【ダウンロード】 http://dev.mysql.com/downloads/cluster/ https://edelivery.oracle.com/
【MySQL Cluster Manager】 https://www-jp.mysql.com/products/cluster/mcm/

補足:詳細は、こちらを参照下さい。
https://dev.mysql.com/doc/refman/5.6/ja/index.html
https://www-jp.mysql.com/products/cluster/

有難うございました





























