Embed Size (px)
Citation preview

PyTorch for Tensor�ow Developers
OverviewPyTorch constructsDynamic Graphs
--- Abdul Muneer
https://www.minds.ai/

Why do we use any Framework?
Model PredictionGradient computation ---- (automatic differentiation)

Why should we explore non TF frameworks?
Engineering is a key component in Deep Learning practiceWhat engineering problems are existing tools fails to solve?
Improves our understanding of TF
We do not end up being one trick pony
Helps understand n/w implementation in those frameworks.

alternative paradigm for implementing neural networkssimple and intuitive to program and debug

What is PyTorch?
It’s a Python based scienti�c computing package targeted at two sets of audiences:
A replacement for numpy to use the power of GPUsa deep learning research platform that provides maximum �exibility and speed

In [ ]: # MNIST example
import torch import torch.nn as nn from torch.autograd import Variable
class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1, 16, kernel_size=5, padding=2), nn.BatchNorm2d(16), nn.ReLU(), nn.MaxPool2d(2)) self.layer2 = nn.Sequential( nn.Conv2d(16, 32, kernel_size=5, padding=2), nn.BatchNorm2d(32), nn.ReLU(), nn.MaxPool2d(2)) self.fc = nn.Linear(7*7*32, 10) def forward(self, x): out = self.layer1(x) out = self.layer2(out) out = out.view(out.size(0), -1) out = self.fc(out) return out

In [ ]: cnn = CNN()
# Loss and Optimizer criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate) # Train the Model for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): images = Variable(images) labels = Variable(labels) # Forward + Backward + Optimize optimizer.zero_grad() outputs = cnn(images) loss = criterion(outputs, labels) loss.backward() optimizer.step()
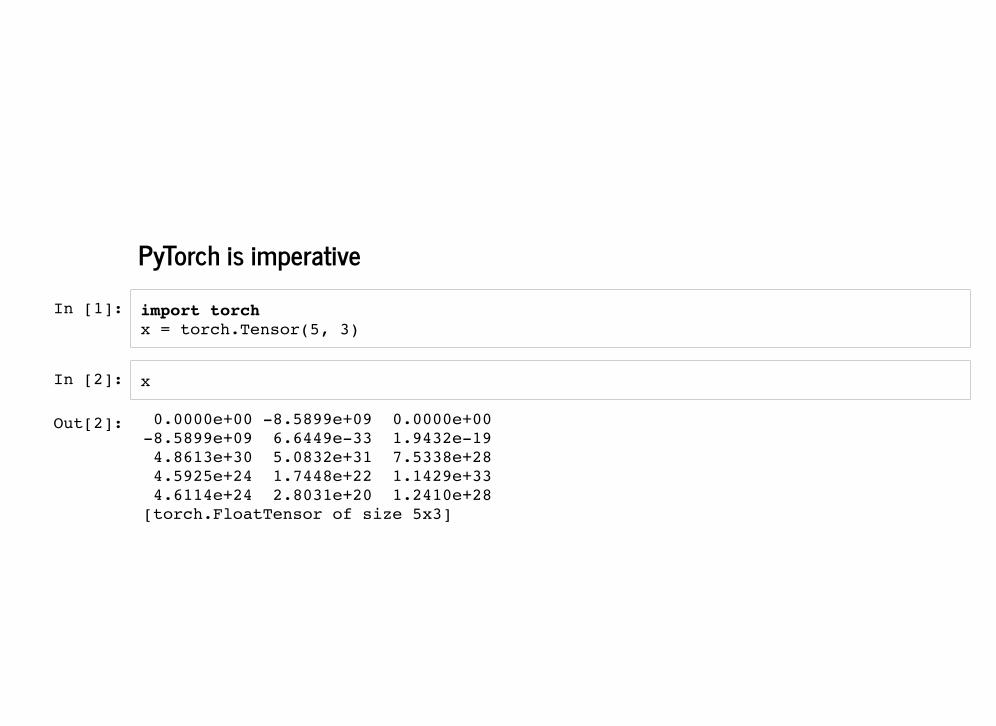
PyTorch is imperative
In [1]:
In [2]:
import torch x = torch.Tensor(5, 3)
x
Out[2]: 0.0000e+00 -8.5899e+09 0.0000e+00 -8.5899e+09 6.6449e-33 1.9432e-19 4.8613e+30 5.0832e+31 7.5338e+28 4.5925e+24 1.7448e+22 1.1429e+33 4.6114e+24 2.8031e+20 1.2410e+28 [torch.FloatTensor of size 5x3]

PyTorch is imperative
No need for placeholders, everything is a tensor.
Debug it with a regular python debugger.
You can go almost as high level as keras and as low level as pure Tensor�ow.

Let's talk about Tensors and Variables

Tensors
similar to numpy’s ndarrayscan also be used on a GPU to accelerate computing.
In [2]: import torch x = torch.Tensor(5, 3) print(x)
0.0000 0.0000 0.0000 -2.0005 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 [torch.FloatTensor of size 5x3]
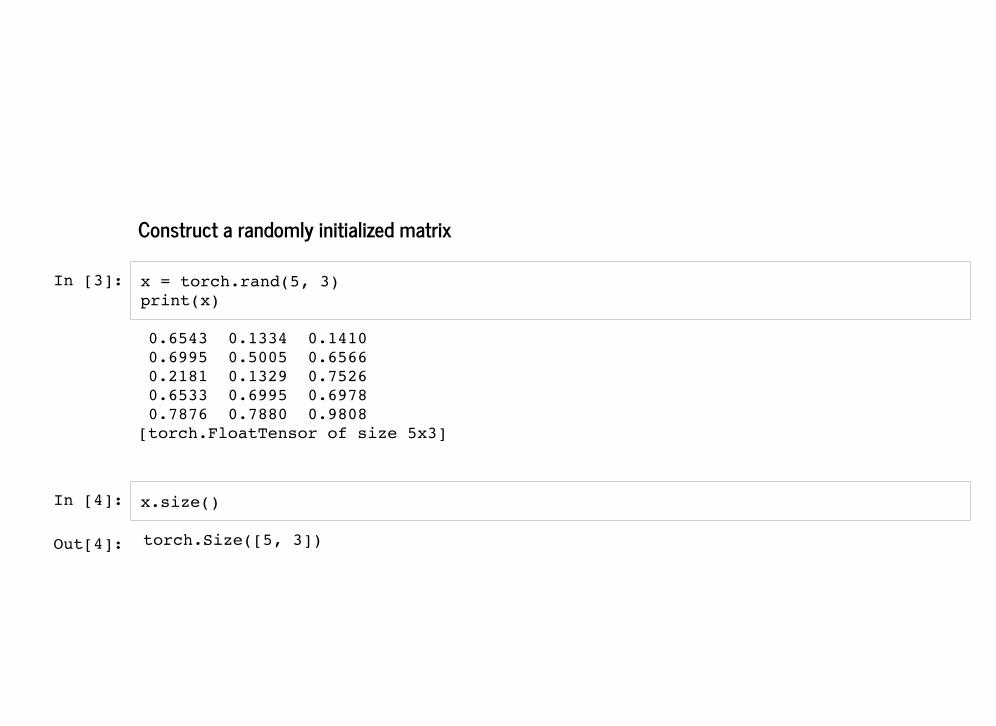
Construct a randomly initialized matrix
In [3]:
In [4]:
x = torch.rand(5, 3) print(x)
x.size()
0.6543 0.1334 0.1410 0.6995 0.5005 0.6566 0.2181 0.1329 0.7526 0.6533 0.6995 0.6978 0.7876 0.7880 0.9808 [torch.FloatTensor of size 5x3]
Out[4]: torch.Size([5, 3])

Operations
Addition
In [5]:
In [6]:
y = torch.rand(5, 3) print(x + y)
print(torch.add(x, y))
0.9243 0.3856 0.7254 1.6529 0.9123 1.4620 0.3295 1.0813 1.4391 1.5626 1.5122 0.8225 1.2842 1.1281 1.1330 [torch.FloatTensor of size 5x3]
0.9243 0.3856 0.7254 1.6529 0.9123 1.4620 0.3295 1.0813 1.4391 1.5626 1.5122 0.8225 1.2842 1.1281 1.1330 [torch.FloatTensor of size 5x3]

Operations
Any operation that mutates a tensor in-place is post-�xed with an _
For example: x.copy_(y), x.t_() etc. will change x.

Addition: in-place
In [8]:
In [9]:
print(y)
# adds x to y y.add_(x) print(y)
0.9243 0.3856 0.7254 1.6529 0.9123 1.4620 0.3295 1.0813 1.4391 1.5626 1.5122 0.8225 1.2842 1.1281 1.1330 [torch.FloatTensor of size 5x3]
1.5786 0.5190 0.8664 2.3523 1.4128 2.1186 0.5476 1.2142 2.1917 2.2159 2.2116 1.5204 2.0718 1.9161 2.1138 [torch.FloatTensor of size 5x3]

numpy-like indexing applies..
In [13]: y[:,1]
Out[13]: 0.5190 1.4128 1.2142 2.2116 1.9161 [torch.FloatTensor of size 5]

Numpy Bridge
The torch Tensor and numpy array will share their underlying memory locations,
Changing one will change the other.
In [6]:
In [7]:
a = torch.ones(3) print(a)
b = a.numpy() print(b)
1 1 1 [torch.FloatTensor of size 3]
[ 1. 1. 1.]

In [8]: a.add_(1) print(a) print(b)
2 2 2 [torch.FloatTensor of size 3]
[ 2. 2. 2.]

Converting numpy Array to torch Tensor
In [13]:
In [16]:
In [17]:
import numpy as np a = np.ones(5) b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a) print(b)
Out[16]: array([ 4., 4., 4., 4., 4.])
[ 4. 4. 4. 4. 4.] 4 4 4 4 4 [torch.DoubleTensor of size 5]

Autograd: automatic di�erentiation
autograd package is central to all neural networks in PyTorch.

Variable
The central class of the autograd package
datathe raw tensor
gradthe gradient w.r.t. this variable
creatorcreator of this Variable in the graph

Function
Function is another class which is very important for autograd implementation (think
operations in TF)
Variable and Function are interconnected and build up an acyclic graph
The graph encodes a complete history of computation.

Variables and Functions examples:

In [18]: import torch from torch.autograd import Variable

In [21]: # Create a variable: x = Variable(torch.ones(2, 2), requires_grad=True) print(x)
Variable containing: 1 1 1 1 [torch.FloatTensor of size 2x2]

In [22]: print(x.data)
1 1 1 1 [torch.FloatTensor of size 2x2]

In [24]: print(x.grad)
None

In [25]: print(x.creator)
None

In [26]: #Do an operation of variable: y = x + 2 print(y)
Variable containing: 3 3 3 3 [torch.FloatTensor of size 2x2]

In [27]: print(y.data)
3 3 3 3 [torch.FloatTensor of size 2x2]
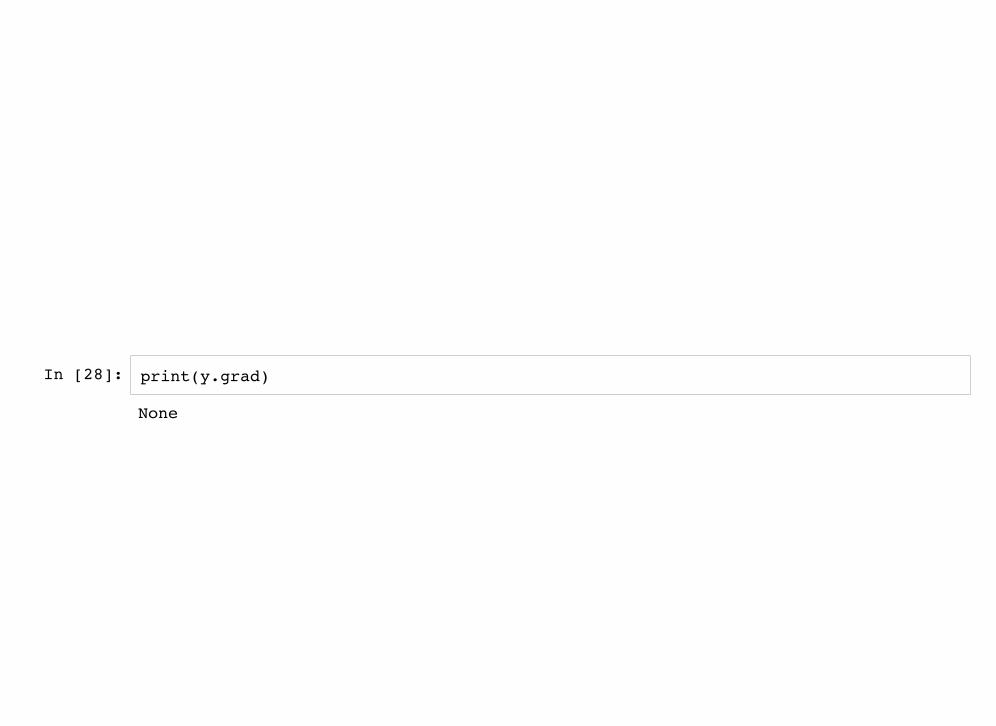
In [28]: print(y.grad)
None

In [29]: print(y.creator)
<torch.autograd._functions.basic_ops.AddConstant object at 0x106b449e8>
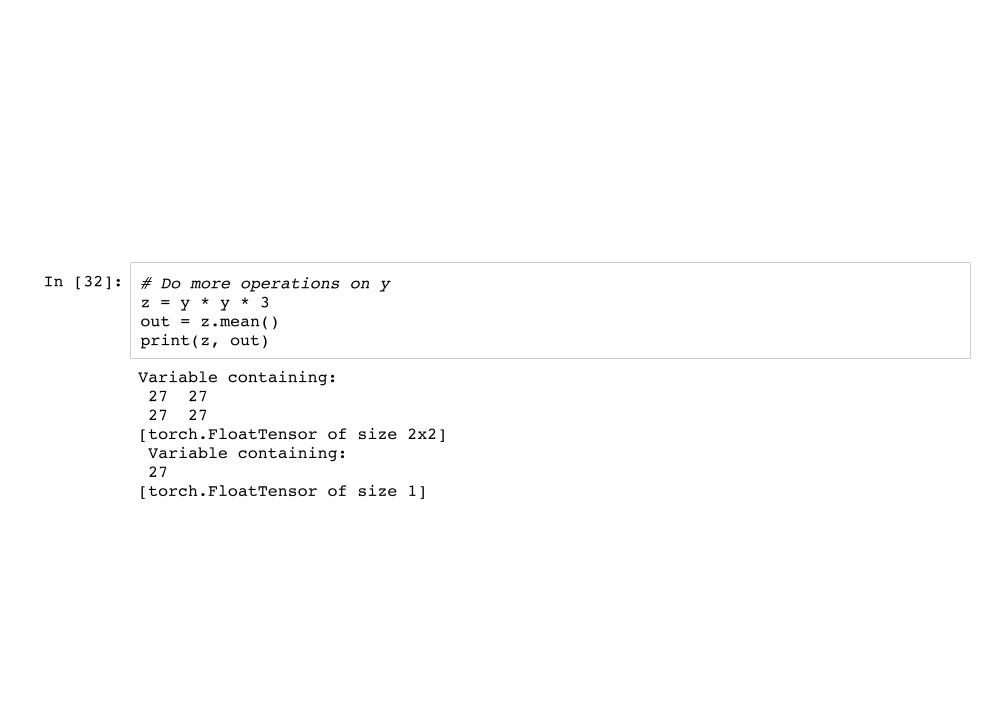
In [32]: # Do more operations on y z = y * y * 3 out = z.mean() print(z, out)
Variable containing: 27 27 27 27 [torch.FloatTensor of size 2x2] Variable containing: 27 [torch.FloatTensor of size 1]

Gradients
gradients computed automatically upon invoking the .backward method
In [33]: out.backward() print(x.grad)
Variable containing: 4.5000 4.5000 4.5000 4.5000 [torch.FloatTensor of size 2x2]


Updating Weights
weight = weight - learning_rate * gradient
In [ ]: learning_rate = 0.01 # The learnable parameters of a model are returned by net.parameters() for f in net.parameters(): f.data.sub_(f.grad.data * learning_rate) # weight = weight - learning_rate * gradient

Use Optimizers instead of updating weights by hand.
In [ ]: import torch.optim as optim
# create your optimizer optimizer = optim.SGD(net.parameters(), lr=0.01)
for i in range(num_epochs): # in your training loop: optimizer.zero_grad() # zero the gradient buffers output = net(input) loss = criterion(output, target) loss.backward() optimizer.step()

Dynamic Computational Graph

Why should we have a Graph in the �rst place?
TF begins everything by talking about the graph and sessions

What is Dynamic Graph
Backprop is de�ned by how the code is run.Every single iteration can be different.

Dynamic Computational Graph

Dynamic Computational Graph

Dynamic Computational Graph

Dynamic Computational Graph

Dynamic Computational Graph

DL frameworks usually consists two “interpreters” in the framework.
1. The host language (i.e. Python)
2. The computational graph.
i.e. , a language that sets up the computational graph
and
an execution mechanism that is different from the host language.

Static computational graphs can optimize computation.
Dynamic computational graphs are valuable when you cannotdetermine the computation.
e.g. recursive computations that are based on variable data.

Case against dynamic graphs

case against dynamic graphs
You don’t always need a dynamic graph.

Case against dynamic graphs
Dynamic capabilities can be added to a static computation graph.

.. probably not a natural �t that your head will appreciate.
exhibit A: tf.while_loop
exhibit B: A whole new library called tensorflow fold

Problems of achieving same result with static graphs
Dif�culty in expressing complex �ow-control logic
look very different in the graph than in the imperative coding style of thehost language
requires sophistication on the developer’s part.
Complexity of the computation graph implementation
Forced to address all possible cases.
Reduces opportunity for optimization

Case FOR dynamic graphs
Suits well for dynamic data
Any kind of additional convenience will help speed up in your explorations
it works just like Python
** no split-brain experience that there’s another execution engine that running thecomputation.
Easier to debug
Easier to create unique extensions.

Use cases of Dynamic Graphs
Variably sized inputs
Variably structured inputs
Nontrivial inference algorithms
Variably structured outputs

Why Dynamic Computation Graphs are awesome
Deep Learning architectures will traverse the same evolutionary path astraditional computation.monolithic stand-alone programs, to more modular programsIn the old days we had monolithic DL systems with single analytic objectivefunctions.With dynamic graphs, systems can have multiple networks competing/coperating.Richer modularity. Similar to Information Encapsulation in OOP

Future Prospects
I predict it will coexist with TFsort of like Angular vs React in JS world, with pytorch similar to Reactsort of like java vs python, with pytorch similar to python.
Increased developer adoptionBetter supports for visualization and input management tools

Java
Python
public class HelloWorld { public static void main(String[] args) { System.out.println("Hello World"); } }
print("Hellow World")

Thank You






























