Embed Size (px)
DESCRIPTION
@HadoopSummit
Citation preview

Recent Developments in Spark MLlib and Beyond
Xiangrui Meng

What is MLlib?

What is MLlib?
MLlib is an Apache Spark component focusing on machine learning:!
• initial contribution from AMPLab, UC Berkeley
• shipped with Spark since version 0.8 (Sep 2013)
• 40 contributors
3

What is MLlib?Algorithms:!
• classification: logistic regression, linear support vector machine (SVM), naive Bayes, classification tree
• regression: generalized linear models (GLMs), regression tree
• collaborative filtering: alternating least squares (ALS), non-negative matrix factorization (NMF)
• clustering: k-means
• decomposition: singular value decomposition (SVD), principal component analysis (PCA)
4

Why MLlib?

scikit-learnAlgorithms:!
• classification: SVM, nearest neighbors, random forest, …
• regression: support vector regression (SVR), ridge regression, Lasso, logistic regression, …!
• clustering: k-means, spectral clustering, …
• decomposition: PCA, non-negative matrix factorization (NMF), independent component analysis (ICA), …
6

It is built on Apache Spark, a fast and general engine for large-scale data processing.
• Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
• Write applications quickly in Java, Scala, or Python.
Why MLlib?
7

Spark philosophy
Make life easy and productive for data scientists:
• well documented, expressive APIs
• powerful domain specific libraries
• easy integration with storage systems
• … and caching to avoid data movement
8

Word count (Scala)
val counts = sc.textFile("hdfs://...") .flatMap(line => line.split(" ")) .map(word => (word, 1L)) .reduceByKey(_ + _)
9

Gradient descent
val points = spark.textFile(...).map(parsePoint).cache() var w = Vector.zeros(d) for (i <- 1 to numIterations) { val gradient = points.map { p => (1 / (1 + exp(-p.y * w.dot(p.x)) - 1) * p.y * p.x ).reduce(_ + _) w -= alpha * gradient }
w w � ↵ ·nX
i=1
g(w;xi, yi)
10

K-means (scala)
// Load and parse the data. val data = sc.textFile("kmeans_data.txt") val parsedData = data.map(_.split(‘ ').map(_.toDouble)).cache() !// Cluster the data into two classes using KMeans. val clusters = KMeans.train(parsedData, 2, numIterations = 20) !// Compute the sum of squared errors. val cost = clusters.computeCost(parsedData) println("Sum of squared errors = " + cost)
11

K-means (python)# Load and parse the data data = sc.textFile("kmeans_data.txt") parsedData = data.map(lambda line: array([float(x) for x in line.split(' ‘)])).cache() !# Build the model (cluster the data) clusters = KMeans.train(parsedData, 2, maxIterations = 10, runs = 1, initialization_mode = "kmeans||") !# Evaluate clustering by computing the sum of squared errors def error(point): center = clusters.centers[clusters.predict(point)] return sqrt(sum([x**2 for x in (point - center)])) !cost = parsedData.map(lambda point: error(point)) .reduce(lambda x, y: x + y) print("Sum of squared error = " + str(cost))
12

Dimension reduction+ k-means
// compute principal components val points: RDD[Vector] = ... val mat = RowMatrix(points) val pc = mat.computePrincipalComponents(20) !// project points to a low-dimensional space val projected = mat.multiply(pc).rows !// train a k-means model on the projected data val model = KMeans.train(projected, 10)
13

Collaborative filtering// Load and parse the data val data = sc.textFile("mllib/data/als/test.data") val ratings = data.map(_.split(',') match { case Array(user, item, rate) => Rating(user.toInt, item.toInt, rate.toDouble) }) !// Build the recommendation model using ALS val numIterations = 20 val model = ALS.train(ratings, 1, 20, 0.01) !// Evaluate the model on rating data val usersProducts = ratings.map { case Rating(user, product, rate) => (user, product) } val predictions = model.predict(usersProducts)
14
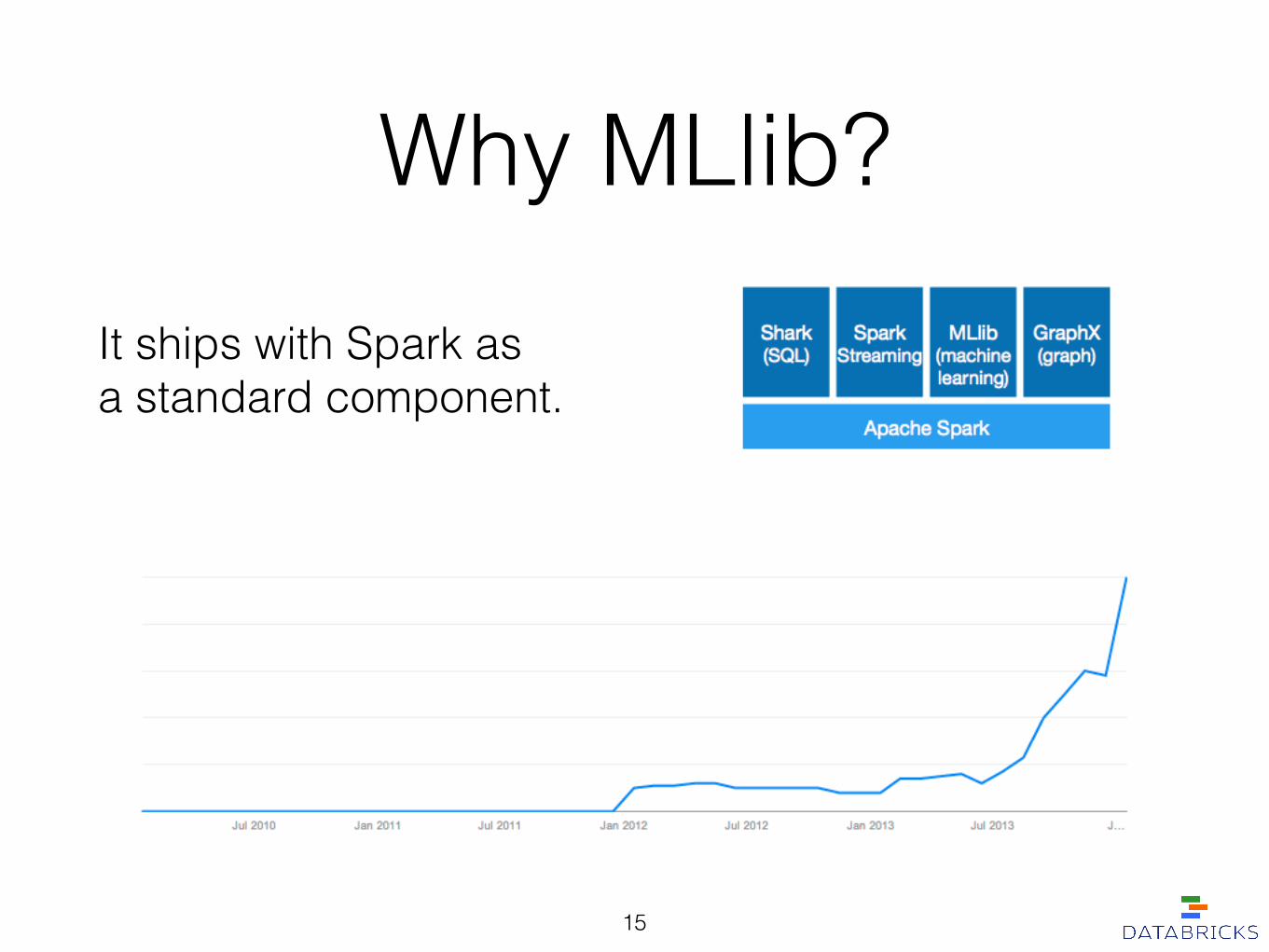
Why MLlib?It ships with Spark as a standard component.
15

Community

Spark community
One of the largest open source projects in big data:!
• 190+ developers contributing (40 for MLlib)
• 50+ companies contributing
• 400+ discussions per month on the mailing list
17

Spark community
The most active project in the Hadoop ecosystem:
JIRA 30 day summary
Spark Map/Reduce YARNcreated 296 30 100resolved 203 28 69
18

Unification
Out for dinner?!
• Search for a restaurant and make a reservation.
• Start navigation.
• Food looks good? Take a photo and share.
20

Why smartphone?
Out for dinner?!
• Search for a restaurant and make a reservation. (Yellow Pages?)
• Start navigation. (GPS?)
• Food looks good? Take a photo and share. (Camera?)
21

Why MLlib?
A special-purpose device may be better at one aspect than a general-purpose device. But the cost of context switching is high: • different languages or APIs
• different data formats
• different tuning tricks
22

Spark SQL + MLlib// Data can easily be extracted from existing sources, // such as Apache Hive. val trainingTable = sql(""" SELECT e.action, u.age, u.latitude, u.longitude FROM Users u JOIN Events e ON u.userId = e.userId""") !// Since `sql` returns an RDD, the results of the above // query can be easily used in MLlib. val training = trainingTable.map { row => val features = Vectors.dense(row(1), row(2), row(3)) LabeledPoint(row(0), features) } !val model = SVMWithSGD.train(training)
23

Streaming + MLlib
// collect tweets using streaming !// train a k-means model val model: KMmeansModel = ... !// apply model to filter tweets val tweets = TwitterUtils.createStream(ssc, Some(authorizations(0))) val statuses = tweets.map(_.getText) val filteredTweets = statuses.filter(t => model.predict(featurize(t)) == clusterNumber) !// print tweets within this particular cluster filteredTweets.print()
24

GraphX + MLlib// assemble link graph val graph = Graph(pages, links) val pageRank: RDD[(Long, Double)] = graph.staticPageRank(10).vertices !// load page labels (spam or not) and content features val labelAndFeatures: RDD[(Long, (Double, Seq((Int, Double)))] = ... val training: RDD[LabeledPoint] = labelAndFeatures.join(pageRank).map { case (id, ((label, features), pageRank)) => LabeledPoint(label, Vectors.sparse(features ++ (1000, pageRank)) } !// train a spam detector using logistic regression val model = LogisticRegressionWithSGD.train(training)
25

Why MLlib?• built on Spark’s lightweight yet powerful APIs
• Spark’s open source community
• seamless integration with Spark’s other components
26
• comparable to or even better than other libraries specialized in large-scale machine learning

Why MLlib?
In MLlib’s implementations, we care about!
• scalability
• performance
• user-friendly documentation and APIs
• cost of maintenance
27

v1.0

What’s new in MLlib• new user guide and code examples
• API stability
• sparse data support
• regression and classification tree
• distributed matrices
• tall-and-skinny PCA and SVD
• L-BFGS
• binary classification model evaluation
29

MLlib user guide• v0.9 (link)
• a single giant page
• mixed code snippets in different languages
• v1.0 (link)
• The content is more organized.
• Tabs are used to separate code snippets in different languages.
• Unified API docs.
30

Code examplesCode examples that can be used as templates to build standalone applications are included under the “examples/” folder with sample datasets: • binary classification (linear SVM and logistic regression) • decision tree • k-means • linear regression • naive Bayes • tall-and-skinny PCA and SVD • collaborative filtering
31

Code examplesMovieLensALS: an example app for ALS on MovieLens data. Usage: MovieLensALS [options] <input> ! --rank <value> rank, default: 10 --numIterations <value> number of iterations, default: 20 --lambda <value> lambda (smoothing constant), default: 1.0 --kryo use Kryo serialization --implicitPrefs use implicit preference <input> input paths to a MovieLens dataset of ratings
32

API stability
• Following Spark core, MLlib is guaranteeing binary compatibility for all 1.x releases on stable APIs.
• For changes in experimental and developer APIs, we will provide migration guide between releases.
33

Sparse data support

“large-scale sparse problems”
Sparse datasets appear almost everywhere in the world of big data, where the sparsity may come from many sources, e.g.,
• feature transformation: one-hot encoding, interaction, and bucketing,
• large feature space: n-grams,
• missing data: rating matrix,
• low-rank structure: images and signals.
35

Sparsity is almost everywhere
The Netflix Prize:!
• number of users: 480,189
• number of movies: 17,770
• number of observed ratings: 100,480,507
• sparsity = 1.17%
36

Sparsity is almost everywhere
rcv1.binary (test)!
• number of examples: 677,399
• number of features: 47,236
• sparsity: 0.15%
• storage: 270GB (dense) or 600MB (sparse)
37

Exploiting sparsity• In Spark v1.0, MLlib adds support for sparse input
data in Scala, Java, and Python.
• MLlib takes advantage of sparsity in both storage and computation in • linear methods (linear SVM, logistic regression, etc) • naive Bayes, • k-means, • summary statistics.
38
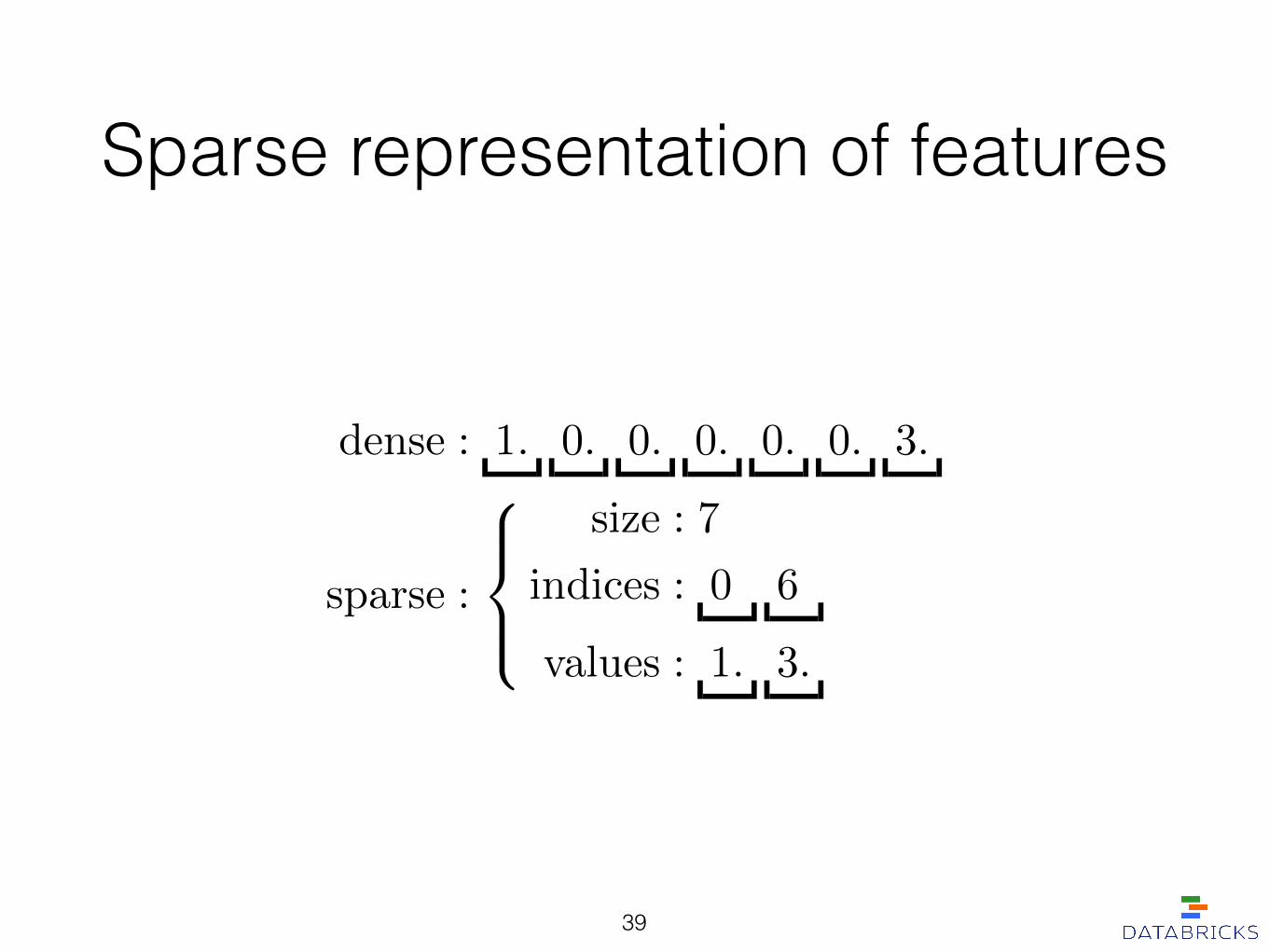
Sparse representation of features
39
dense : 1. 0. 0. 0. 0. 0. 3.
sparse :
8><
>:
size : 7
indices : 0 6
values : 1. 3.

Exploiting sparsity in k-means
Training set:!• number of examples: 12 million
• number of features: 500
• sparsity: 10%
!
Not only did we save 40GB of storage by switching to the sparse format, but we also received a 4x speedup.
dense sparsestorage 47GB 7GB
time 240s 58s
40

Implementation of sparse k-means
Algorithm:!
• For each point, find its closest center.
• Update cluster centers.
li = argminj
kxi � cjk22
cj =
Pi,li=j xjPi,li=j 1
41

Implementation of sparse k-meansThe points are usually sparse, but the centers are most likely to be dense. Computing the distance takes O(d) time. So the time complexity is O(n d k) per iteration. We don’t take any advantage of sparsity on the running time. However, we have
kx� ck22 = kxk22 + kck22 � 2hx, ci
Computing the inner product only needs non-zero elements. So we can cache the norms of the points and of the centers, and then only need the inner products to obtain the distances. This reduce the running time to O(nnz k + d k) per iteration.
42

Exploiting sparsity in linear methods
The essential part of the computation in a gradient-based method is computing the sum of gradients. For linear methods, the gradient is sparse if the feature vector is sparse. In our implementation, the total computation cost is linear on the input sparsity.
43

Acknowledgement
For sparse data support, special thanks go to!
• David Hall (breeze),
• Sam Halliday (netlib-java),
• and many others who joined the discussion.
44

Decision tree

Decision tree
• a major feature introduced in MLlib v1.0
• supports both classification and regression
• supports both continuous features and categorical features
• scales well on massive datasets
46

Decision tree
Come to to learn more:!
• Scalable distributed decision trees in Spark MLlib
• Manish Made, Hirakendu Das, Evan Sparks, Ameet Talwalkar
47

More features to explore
• distributed matrices
• tall-and-skinny PCA and SVD
• L-BFGS
• binary classification model evaluation
48

Beyond v1.0

Next release (v1.1)
Spark has a 3-month release cycle:!
• July 25: cut-off for new features
• August 1: QA period starts
• August 15+: RC’s and voting
50

MLlib roadmap for v1.1• Standardize interfaces!
• problem / formulation / algorithm / parameter set / model
• towards building an ecosystem
• Train multiple models in parallel!
• large-scale vs. medium-scale
• Statistical analysis!
• more descriptive statistics
• more sampling and bootstrapping
• hypothesis testing
51

MLlib roadmap for v1.1• Learning algorithms!
• Non-negative matrix factorization (NMF)
• Sparse SVD
• Multiclass support in decision tree
• Latent Dirichlet allocation (LDA)
• …
• Optimization algorithms!
• Alternating direction method of multipliers (ADMM)
• Accelerated gradient methods
52

Beyond v1.1?
What to expect from the community (and maybe you):!
• scalable implementations of well known and well understood machine learning algorithms
• user-friendly documentation and consistent APIs
• better integration with Spark SQL, Streaming, and GraphX
• addressing practical machine learning pipelines
53

Contributors
Ameet Talwalkar, Andrew Tulloch, Chen Chao, Nan Zhu, DB Tsai, Evan Sparks, Frank Dai, Ginger Smith, Henry Saputra, Holden Karau, Hossein Falaki, Jey Kottalam, Cheng Lian, Marek Kolodziej, Mark Hamstra, Martin Jaggi, Martin Weindel, Matei Zaharia, Nick Pentreath, Patrick Wendell, Prashant Sharma, Reynold Xin, Reza Zadeh, Sandy Ryza, Sean Owen, Shivaram Venkataraman, Tor Myklebust, Xiangrui Meng, Xinghao Pan, Xusen Yin, Jerry Shao, Sandeep Singh, Ryan LeCompte
54

Interested?• : http://spark-summit.org
• Website: http://spark.apache.org
• Tutorials: http://ampcamp.berkeley.edu
• Github: https://github.com/apache/spark
• Mailing lists: [email protected] [email protected]
55





























