Embed Size (px)
Citation preview

We

• Full python microservices (~30 / env)
• Elasticsearch
• REST API for synchronous calls
• Rabbitmq for asynchronous calls
Clustree stack


• 12 factor
• Git commit as docker tag
• docker-compose and kubernetes
• develop branch vs master branch
Engineering practices


• ~ 12 people in tech team
• Developers in charge of their app up to production
• Infrastructure team provides:• Tools• Guidelines• Expertise
Organization

• Why GKE ?
• GKE Cluster (15 nodes) • ~280 pods• 200GB / 225 GB of memory allocated
• Inside Kubernetes• All stateless applications for all environments • All stateful applications for integration environments
• Outside Kubernetes• staging / production stateful app• Infrastructure• Spark
Infrastructure
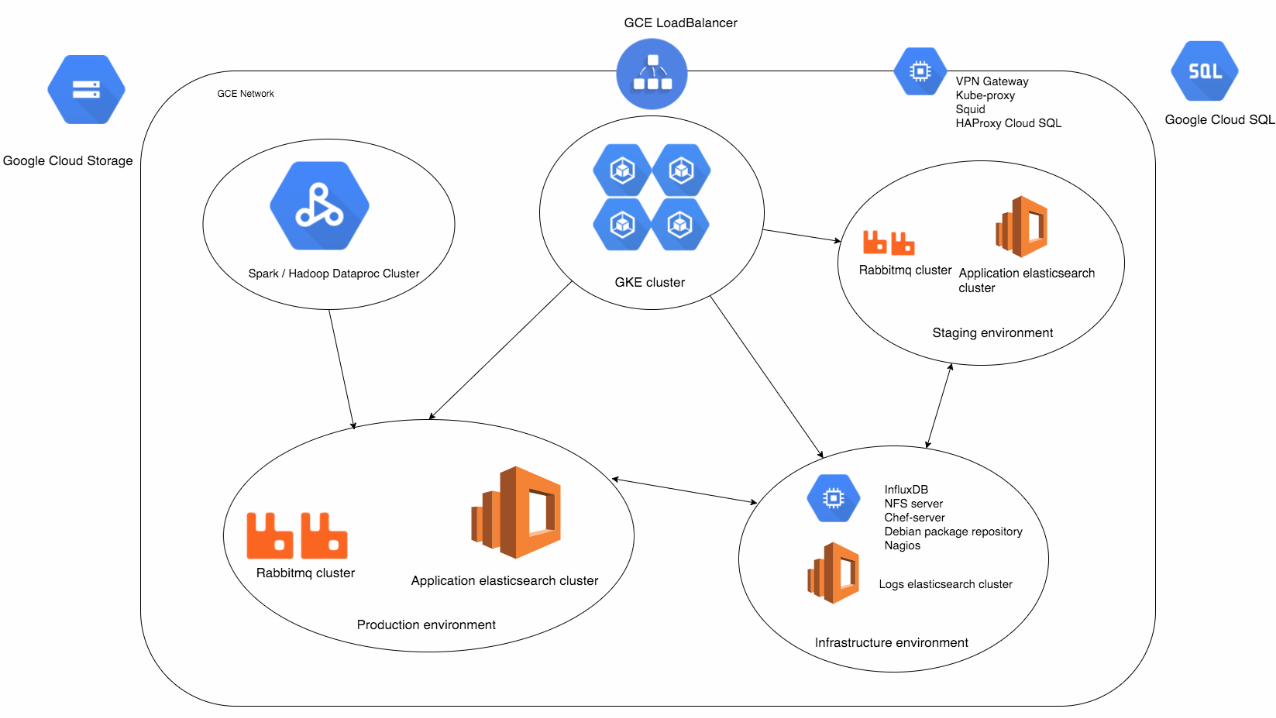

• Namespaces to isolate environments• RC everywhere (even for single pods)• Service discovery• Secrets• Volumes • Jobs
Features used

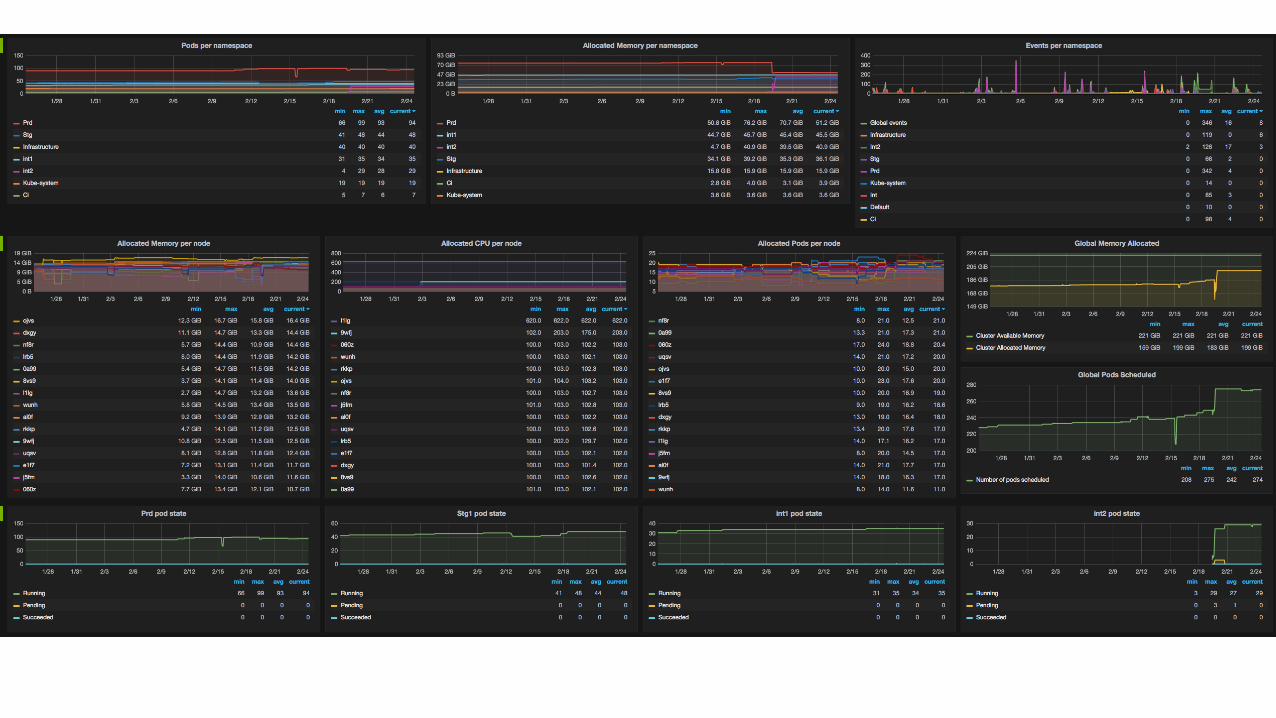
Production tooling

• 1 heapster with Google Cloud Monitoring sink (not used)• 1 heapster with an influxdb sink• telegraf• prometheus inputs for all nodes• custom python script to gather cluster wide metrics• 1 telegraf instance running on each node
• Influxdb 0.10.x and Grafana
Metrics
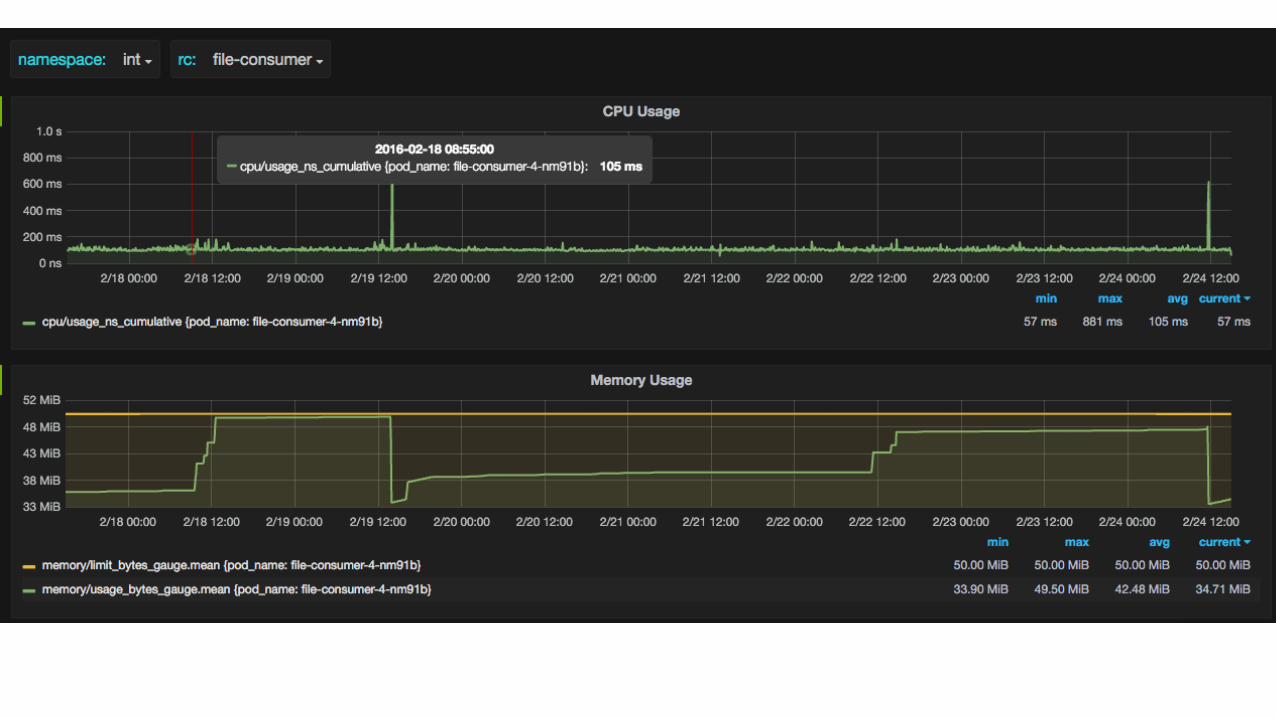

• 1 fluentd per node to push to Google Cloud Logging (not used)• 200 MB per node
• 1 logstash per node to push to elasticsearch• 500 MB per node …• kubernetes plugin (container name, namespaces, pod, rc, etc..)• interlaced logs => structured logs !• OOM pattern detection (ram limits are difficult to find !)
Logging system

• Auto healing cluster• Pods hooks + nagios + consul + consul-template => failed• Sentry• Still need to decide push vs pull monitoring• pull : prometheus• push : kapacitor / watcher • Google Cloud Monitoring ?
• How to monitor kubernetes events ?
Monitoring


• Migration 1.0 -> 1.1 : DNS discovery outage (#18171)
• Loss of 1/3 of node cluster (… yesterday) (#13346)
• Volumes (#14642)
• Memory pressure on nodes
A handful of issues
# references github issues numbers

• private services access outside cluster (#14545)
• No public IP from public Load Balancers
• IAM
• network isolation
• kubectl exec (timeout / TERM) (#12179, #13585)
• node resizing on GKE
A few painful points

• Spawn a new environment in a few minutes (to test a new feature)
• Super easy rolling-upgrade and rollback
• Fully declarative infrastructure
But a lot of joy !

• Ubernetes
• ScheduledJob
• PetSet
• HPA on custom metrics
• Network policy
The future is bright

• Google-container ML
• Slack
• Github (Read the proposals !)
• GKE support
Great community

• So much to do / discover / learn but really exciting !
• Docker evolutions are way less important for us than kubernetes new features
• Kubernetes is really a powerful abstraction and enable team autonomy and velocity
• Still a young project / ecosystem but evolving really quickly
Conclusion

Thank you

• Logstash kubernetes plugin : https://github.com/vaijab/logstash-filter-kubernetes
• Network policy : http://www.projectcalico.org/a-sneak-peek-at-kubernetes-policy/
• Kubernetes proposals : https://github.com/kubernetes/kubernetes/tree/master/docs/proposals
References















![kQGI N]g GkE](https://img.pdfslide.net/doc/110x75/5cc5c10988c99307608b5d99/kqgi-ng-gke.jpg)














