Embed Size (px)
Citation preview

Spark vs TezBy David Gruzman, BigDataCraft.com

Why we compare them?Both frameworks came as MapReduce replacementBoth essentially provide DAG of computationsBoth are YARN applications.Both reduce latency of MRBoth promise to improve SQL capabilities

Our plan for todayTo understand what is TezTo recall what is sparkTo understand what is in common and what differentiate them.To try identifying when each one of them is more applicable

MapReduce extensionWhile MapReduce can solve virtually any data transformation problems, not all of them are done efficiently.One of the main drawbacks of the current MapReduce implementation is latency, especially in job cascades.

MapReduce latency causes1. Obtain and initialize containers2. Poll oriented scheduling3. In series of jobs - persistence of intermediate
resultsa. Serialization and Deserialization costsb. IO Costsc. HDFS costs

Common Solutions to latency problems in Spark and Tez
Container start overhead - container reusePolling style scheduling - event driven controlBuilding DAG of computations to eliminate need of fixing intermediate results.

TezImplementation language - JavaClient language - JavaMain abstraction - DAG of computationsIn best of my understanding - improvement of MR as much as possible.

DAG - Vertexes and Edges

VertexVertex is collection of tasks, running in clusterTask consists from inputs, outputs and processors.Inputs can be from other vertices or from HDFSOutputs can be sorted or not, and go to HDFS or other Vertices
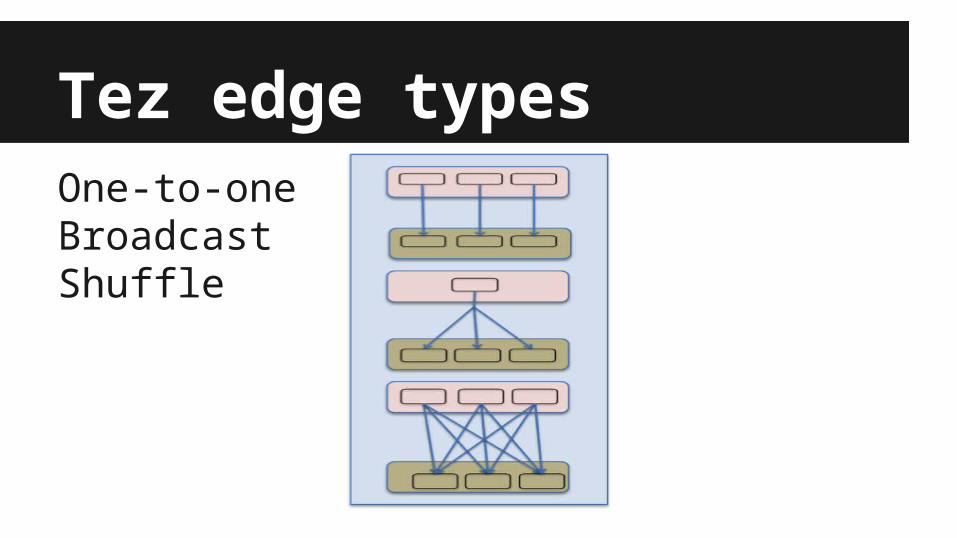
Tez edge typesOne-to-oneBroadcastShuffle

Edge Data sources● Persisted: Output will be available after the task exits. Output may be lost later on.
● Persisted-Reliable: Output is reliably stored and will always be available
● Ephemeral: Output is available only while the producer task is running
Persistent - after the task life. Local FSPersistent - Reliable. HDFSEphemeral - in memory

Tez edge schedulingSequential - next task run after current task is finishedConcurrent - next task can be run

Vertex Management
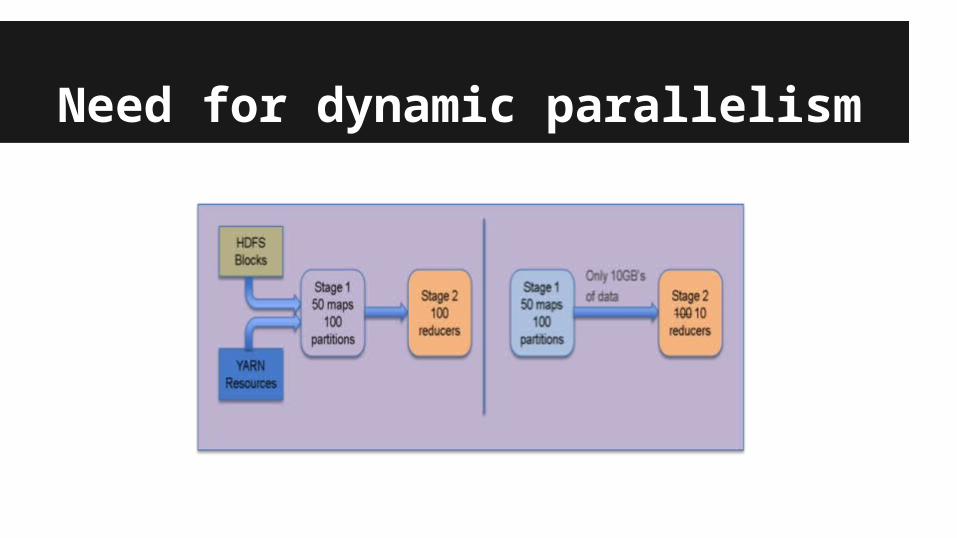
Need for dynamic parallelism

Tez Vs MapReduceMapReduce can be expressed in Tez efficientlyIt can be stated that Tez is somewhat lower level than MapReduce

Tez sessionTez session allow us to reuse tez application master for different DAG.Tez AM capable of caching containers.IMO it contradict YARN in some extent.Tez sessions are similar as concept to Spark context

Tez - summaryTez enable us explicitly define DAG of computations, and tune its execution.Tez tightly integrated with YARN.MR can be efficiently expressed in terms of TezTez programming is more complicated than MR.

Tez performance vs MR

Tez performance vs MR

Spark - word of thanksI want to mention help of Raynold Xin from DataBricks (http://www.cs.berkeley.edu/~rxin/) who helped me to verify findings of this presentation.Spark today is most popular apache project with more then 400 contributors.

SparkSpark is a framework which enables us manipulation of distributed collections, called RDD.RDD is Resilient distributed datasets.We also can view these manipulations as DAG of computations

RDD storage optionsRDD can live in cluster in 3 forms.- As native scala objects. Fastest, more RAM- As serialized blocks. Slower, less RAM- As persisted blocks. Slowest, but minimal
RAM.

DAG in Spark

Spark - usabilityWhile in MR (or in Tez) Simple WordCount is pages of code, in Spark it is a few linesval file = spark.textFile("hdfs://...")val counts = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _)counts.saveAsTextFile("hdfs://...")

Implicit DAG definitionWhen we define Map in Spark - we define one-to-one, or “non-shuffle” dependency.When we do join or group by - we define “shuffle” dependency.

Explicit DAG definitionWhile it is not common, Spark does enable explicit DAG definition.Spark SQL is using this for performance reasons.

Spark architecture

Spark serializationSpark is using pluggable serialization. You can write your own or re-use existing serialization frameworks.Java serialization is default and works transparently.Kryo fastest in best of my knowledge.

Spark deploymentSpark can be deployed standalone as well as in form of YARN application.It means that Spark can be used without Hadoop.

Spark usage
Spark
Spark SQL
MLib GraphX Applications/Shell

Storage modelTez is working with HDFS data. Tez job transforms data from HDFS to HDFS.Spark has notion of RDD, which can live in memory or on HDFS.RDD can be in form of native Scala objects, something Tez can not offer.
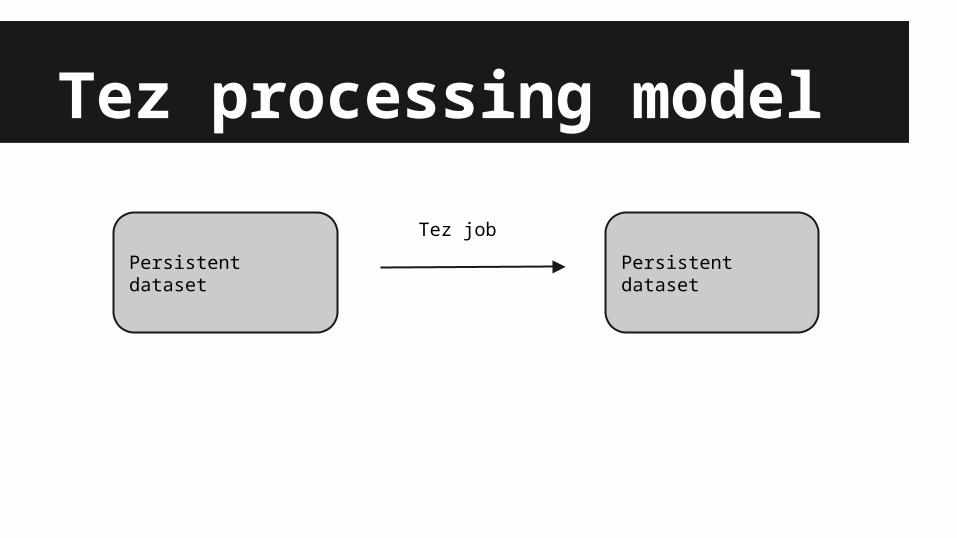
Tez processing model
Persistent dataset Persistent dataset
Tez job
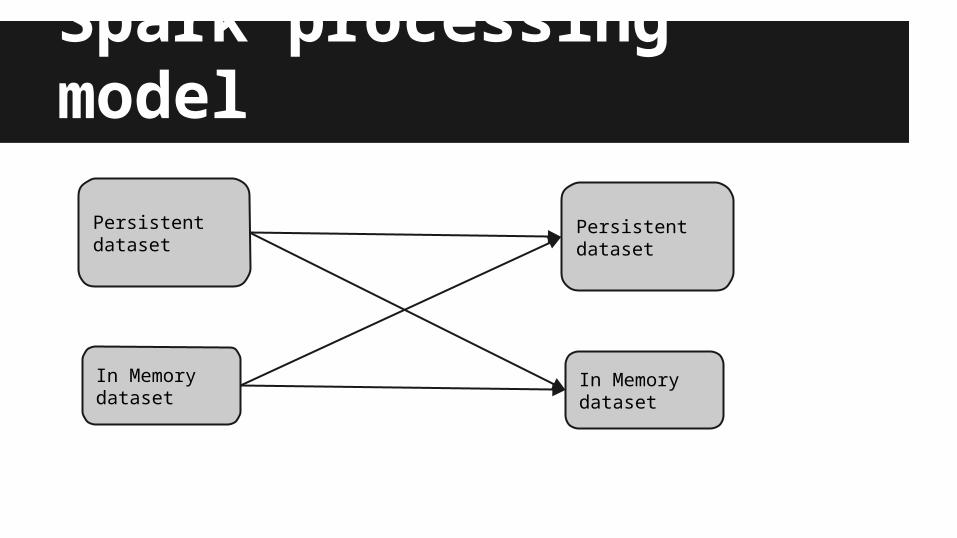
Spark processing model
Persistent dataset
In Memorydataset
Persistent dataset
In Memorydataset

Job definition levelTez is low level - we explicitly define vertices and edgeSpark is “high level” oriented, while low level API exists.

Target audienceTez is built ground up to be underlying execution engine for high level languages, like Hive and PigSpark is built to be very usable as is. In the same time there are a few frameworks built on top of it - Spark SQL, MLib, GraphX.

YARN integrationTez is ground up Yarn applicationSpark is “moving” toward YARN.Spark recently added “dynamic” executors execution in YARN.In near future it should be similar, for now Tez has some edge.

Note on similarity1. There is initiative to run Hive on Sparkhttps://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark2. There is intiative to reuse MR shuffling for Spark:http://hortonworks.com/blog/improving-spark-data-pipelines-native-yarn-integration/

Applicability : Spark vs TezInteractive work with data, ad-hoc analysis : Spark is much easier.

Data >> RAMProcessing huge data volumes, much bigger than cluster RAM : Tez might be better, since it is more “stream oriented”, has more mature shuffling implementation, closer Yarn integration.

Data << RAMSince Spark can cache in memory parsed data - it can be much better when we process data smaller than cluster’s memory.

Building own DSLFor Tez low level interface is “main” so building your own framework or language on top of Tez can be simpler than for Spark.
Linkshttp://www.slideshare.net/ydn/hive-hughttp://ampcamp.berkeley.edu/wp-content/uploads/2012/06/josh-rosen-amp-camp-2012-spark-python-api-final.pdfhttp://www.quora.com/When-would-someone-use-Apache-Tez-instead-of-Apache-Spark-or-vice-versahttps://yhemanth.wordpress.com/2013/11/07/comparing-apache-tez-and-microsoft-dryad/soft-dryad/

Update on ImpalaToGoImpalaToGo is “light” version of ClouderaImpala optimized to work with S3
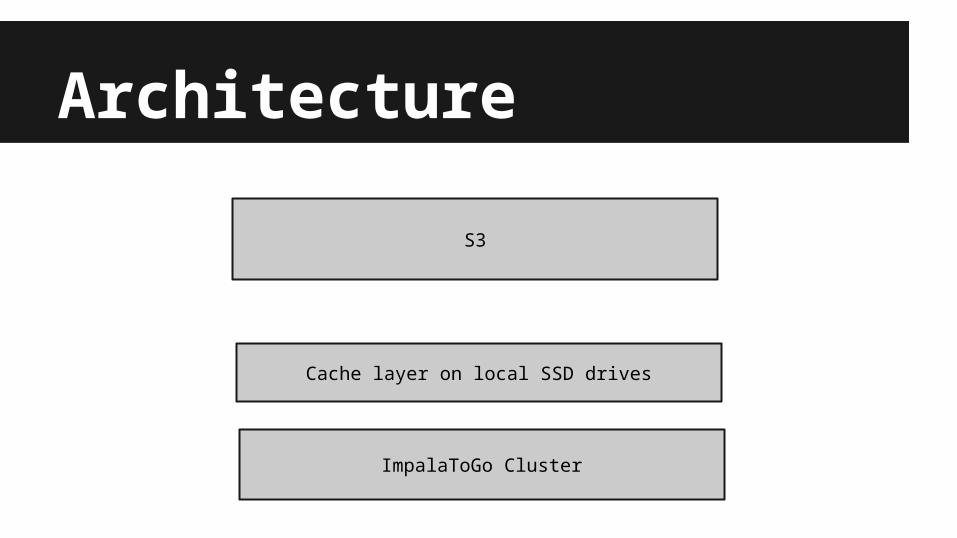
Architecture
S3
Cache layer on local SSD drives
ImpalaToGo Cluster

DataTable with 28 billion records, one string, and a few numbers.Size : 6 TB CSV. Stored as 1 TB of Parquet with Snappy compression.

Hardware14 Amazon m3.2xlarge instances. 30 GB RAM, 8 Cores, 2 * 80 GB SSD.
Cost of this HW - about $7 an hour.

PerformanceFirst read : select count(*) from … where …20 minutes.Subsequent reads:where on numeric column : 1 minute.“grep” on string : 10 minutes.

Cost Scan of about 5 TB of strings cost us $1.16Cost per TB is about $0.24 per TB.Just to compare cost of processing of 1 TB of data in BigQuery is $5 - 40 times more

POCIf you have data in S3 you want to query -we can do POC together.





















![[Spark meetup] Spark Streaming Overview](https://img.pdfslide.net/doc/110x75/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)






