Embed Size (px)
Citation preview

© 2014 Aerospike. All rights reserved ‹#›
That ORM is Lying to You
Ronen Botzer
Aerospike

© 2014 Aerospike. All rights reserved ‹#›
Preamble
■ I owe you at least one slide that fits the abstract’s style.¹
■ Your ORM is not unlike a crazy significant-other.²
■ You’ve been told you need to go steady. That passed-down logic
is so old you forgot (or never knew) where it came from.
■ You’ve dated, now you’ve settled down. But you feel stuck.
■ ActiveRecord, Spring, Propel, SQLAlchemy, Storm. The names
practically promised you’re going to get some action. But your
ORM is more drama than action.³
■ You are scared to mention an end to the relationship.
■ Fear of going it alone.
■ Worry about the alternatives.
■ Fear of hysterical responses from the ORM community or others.
■ You may be in love, but others tell their horror stories.
■ I'm stopping now, since I'm approaching FIMS.⁴
■ Let’s get to the backstory.⁵

© 2014 Aerospike. All rights reserved ‹#›
Prehistory: The Relational Database Management System
■ 1970: ”A Relational Model of Data for Large Shared Data
Banks" by Edgar F. Codd describes relational modeling.¹
■ 1974: IBM starts developing System R (first commercial
use in 1977).
■ Includes SEQUEL, a query language based on Codd’s paper,
developed by Donald Chamberlain and Raymond Boyce.²
■ System R turns into SQL/DS(1981), which becomes DB2(1983).
■ 1977: Larry Ellison co-founds SDL after being inspired by
the 1970 Codd paper.
■ 1979: Now RSI, the company releases the Oracle database, which
includes an implementation of SQL.
■ While at IBM two UC Berkeley researchers, Eugene
Wong and Michael Stonebraker are inspired by the Codd
paper and initial System R work to create Ingres.

© 2014 Aerospike. All rights reserved ‹#›
Prehistory: The RDBMS [continued]
■ 1974: Ingres prototype is open sourced and is worked on
by teams of students.
■ Includes the Quel query language.¹
■ After three years commercializing Ingres, Stonebraker returns to
UC Berkeley in 1985 and starts work on Postgres.²
■ 1984: An ex-Ingres team starts Sybase (first commercial
release in 1987).
■ Sybase includes the T-SQL query language.
■ Sybase cooperates with Microsoft which licenses its product,
rebranding it in 1992 as SQL Server.
■ 1985: Informix RDBMS includes the ISQL query engine.
■ 1995: Postgres replaces Quel with SQL closely mirroring
Oracle’s SQL. Renames to PostgreSQL.
■ 1996: An open-source RDBMS named MySQL is
released.

© 2014 Aerospike. All rights reserved ‹#›
Here Come The Internets
■ 1989-1991: Tim Berners-Lee, while at CERN, works on
an information system which he names WWW, that uses
HTTP to transmit HTML from web server (CERN httpd) to
web browsers (WorldWideWeb Browser).
■ 1993: A team at NCSA led by Marc Andreessen releases
Mosaic, which becomes the first popular browser.¹
■ Commercialization of the World-Wide Web begins around
the mid-90s.
■ 1994: Netscape's Navigator browser and Commerce Server
include the scripting language JavaScript.
■ 1995: Microsoft's Internet Explorer browser and Internet
Information Server (IIS).
■ 1996: IIS gets an add-on scripting language, ASP.

© 2014 Aerospike. All rights reserved ‹#›
Here Come The Internets [continued]
■ Individuals, then startups use open-source tools.
■ Server-side scripting mostly done through the Common Gateway
Interface (CGI) using Perl.
■ 1997: PHP2/FI emerges as another popular CGI language, then as
a web server module (SAPI).
■ 1996: Java shows up, promising one language to rule
them all. jk, WORA, FTW¹
■ 1999: Java 1.2. A shadow falls on Greenwood. Marketing
call it: J2EE.

© 2014 Aerospike. All rights reserved ‹#›
“You Need an RDBMS”
■ Server-side engineers look around for persistent data
stores.
■ RDBMSs are what experienced engineers and recent
computer science graduates are familiar with.
■ The open-source databases MySQL and PostgreSQL are
picked up heavily by small projects and startups.
■ At first, scripts make direct use of SQL.
■ Data is loaded manually from SQL query results.
■ On writes, application-side data is broken up into one or more
DML operations (INSERT/UPDATE).
■ The concept of a persistent data store becomes
conflated with RDBMS at this point.

© 2014 Aerospike. All rights reserved ‹#›
“You Need an ORM”
■ J2EE ❤️ Patterns. 😍😍😍
■ "You can’t be enterprise grade™ without them!"
■ Relevant patterns: Business Objects, Database Abstraction Layer
(DBAL) / Data Access Layer (DAL), Data Access Objects
(database specific mappers), and later Active Record (2003).
■ Incessant chatter by the Java marketing machine ensues.¹
■ The "patterns" meme even invades the minds of once
hacker-minded, scripting-oriented developers.²
■ Everybody and their grandmother writes an ORM.
■ 16 years later, this has not stopped.³
■ There are well over 100 published ORMs.
■ PHP, for example, is still spewing new ORMs.⁴
■ You write your ORM or join one of many warring camps.

© 2014 Aerospike. All rights reserved ‹#›
Should we be using an ORM
to talk to the RDBMS?

© 2014 Aerospike. All rights reserved ‹#›
The Good Aspects of ORM
■ CRUD operations on a single table have repetitive
SQL/DML. An ORM reduces that boilerplate code.
■ Decent ORMs are mostly config-free.
■ Generate access methods for business objects by inspecting the
schema of the matching tables.
■ Allegedly, ORMs allows ‘non-SQL’ developers to work
against an RDBMS blissfully unaware.
■ Decent ORMs cache data, reducing the load on the
RDBMS.¹

© 2014 Aerospike. All rights reserved ‹#›
Some Bad Aspects of ORM…

© 2014 Aerospike. All rights reserved ‹#›
The Bad: Leaky Abstraction
■ The notion that ORMs support ‘non-SQL’ developers is a
hoax.¹
■ Mapping new classes to the relational model requires an
understanding of DDL.
■ Modifications to the data model (migrations) do too.²
■ When you use an ORM your code usually ends up looking
like SQL anyway. Doctrine example: ³
$query = $conn->createQueryBuilder()
->select('u')
->from('users', 'u')
->where('u.id = :user_id')
->setParameter(':user_id', 1);
SELECT * FROM users AS WHERE id = 1

© 2014 Aerospike. All rights reserved ‹#›
The Bad: A Lowest Common Denominator Database
■ A DBAL is a good idea if you are writing very generic
software for wide distribution, like a CMS.¹
■ Popular DBALs are like politicians - they need to appeal to the
dumbest database in the group.²
■ Like politicians, ORMs promote themselves with soothing
authoritative statements about how all data persistence problems
can be solved with one dogma…
■ Lowest common denominator features miss out on
optimizations specific to your database.³
■ Abstraction inversion: missing features must be emulated.⁴
■ Abstractions slow down your application with extra code.
■ Functional dependency.⁵
■ The notion that a DBAL allows you to switch databases
with ease is silly.⁶

© 2014 Aerospike. All rights reserved ‹#›
The Bad: Speed and Resource Consumption
■ CRUD operations are slower with an ORM.¹
■ Using an ORM for Queries, especially ones JOINing
tables is even slower.
■ Generated SQL is often hideously slow and expensive.²
■ SQL is a robust query language, native to the RDBMS.
■ If your ORM has problems coming up with the correct JOINs you
will inevitably see slow queries that eat up a lot of CPU and
memory.
■ ORMs facilitate bad coding. The “n+1” problem.³

© 2014 Aerospike. All rights reserved ‹#›
– High Scalability blog
‘The Case Against ORM Frameworks In
High Scalability Architectures’, 2008
“ORM frameworks are built to serve as wide an
audience as possible and while their success is
unquestionable in the commodity/middle market, they
are not and cannot possibly be tooled to
accommodate the atypical demands of high scalability
architecture.”

© 2014 Aerospike. All rights reserved ‹#›
Laurie Voss, CTO at npmjs
"In Defense of SQL", 2010
http://seldo.com/weblog/2010/07/12/in_de
fence_of_sql
“ORM is slower than just using SQL, because abstraction
layers always are. But unlike other abstraction layers,
which make up for their performance hit with faster
development, ORM layers add almost nothing.“
“I want to be very, very clear about this: ORM is a stupid
idea.”

© 2014 Aerospike. All rights reserved ‹#›
Mattias Geniar, Developer at Nucleus
"Bad ORM is infinitely worse than bad
SQL", 2012
http://ma.ttias.be/bad-orm-is-infinitely-
worse-than-bad-sql/
“As more and more developers use only ORM to create
applications, they lose their touch with the database
interaction, the queries behind it, the reasoning of why to
use a certain kind of query, the performance impact of an
INNER or OUTER joins, ...”

© 2014 Aerospike. All rights reserved ‹#›
Ted Neward, 2006 [Updated 2012]
http://blogs.tedneward.com/2006/06/26/Th
e+Vietnam+Of+Computer+Science.aspx
“Object-Relational Mapping is the Vietnam of Computer
Science”

© 2014 Aerospike. All rights reserved ‹#›
Is an RDBMS The Right Data
Store?

© 2014 Aerospike. All rights reserved ‹#›
Do You Really Need an RDBMS?
■ The majority of ORMs are tightly coupled with RDBMS.
■ Impedance Mismatch.¹
■ OO notions such as encapsulation (hiding representation),
private/public accessibility, inheritance and polymorphism do not
map to an RDBMs.²
■ Major difference in data types. RDBMSs only support scalar types
such as integer and string.³
■ Manipulation of data in objects is imperative, and usually operates
on lists and maps. In an RDBMS it’s declarative.
■ Transactional differences - granularity of transaction for object is
an individual assignment modifying its attribute. RDBMSs use
much larger sets of operations, and are inefficient at updating the
value of a single field.

© 2014 Aerospike. All rights reserved ‹#›
Do You Really Need an RDBMS? [continued]
■ Normalization kills web applications.¹
■ The goal in the 70s and 80s when normalization was formalized by
Codd and Boyce was for the data to be as small as possible.
■ The goal since the late 90s and web applications is speed.
■ No web application that is open to a global audience via
desktop and mobile apps is even in third normal form.²
■ Web applications quickly devolve to lower forms of normalization
(denormalization).
■ RESTful APIs are a particular example of modeling for the internet
age which is essentially single-table access.
http://example.com/api/:resource/:id

© 2014 Aerospike. All rights reserved ‹#›
So… what should I use in my
application?

© 2014 Aerospike. All rights reserved ‹#›
Perhaps You Actually Need a Key-Value Store
■ Don’t expect to go generic and get performance.
■ If you choose a specific database know why you’re doing so, and
optimize your app to its characteristics.
■ Use minimal abstractions, as they make sense to your particular
case (native client vs. ORM).¹
■ Key-value stores are often a more natural kind of data
store for a web application than an RDBMS.²
■ Support complex types which alleviate the need for a one:many
relationship to be expressed as a JOIN between two tables.
■ If you’re using an RDBMS as a key-value store, STOP. Use
something designed to do those operations much faster, with lower
latency.
■ If your database is fast enough you don’t need a cache nor
caching logic. Was caching your excuse? Less code means a
leaner, faster application, with less opportunity for bugs.
■ Don't shard yourself.³

© 2014 Aerospike. All rights reserved ‹#›
How do we do it?

© 2014 Aerospike. All rights reserved ‹#›
WRITING RELIABLY WITH HIGH PERFORMANCE
1. Write sent to row master
2. Latch against simultaneous writes
3. Apply write to master memory and replica memory synchronously
4. Queue operations to disk
5. Signal completed transaction (optional storage commit wait)
6. Master applies conflict resolution policy (rollback/ rollforward)
master replica
1. Cluster discovers new node via gossip protocol
2. Paxos vote determines new data organization
3. Partition migrations scheduled
4. When a partition migration starts, write journal starts on destination
5. Partition moves atomically
6. Journal is applied and source data deleted
transactions
continueWriting with Immediate Consistency Adding a Node
© 2014 Aerospike. All rights reserved ‹#›
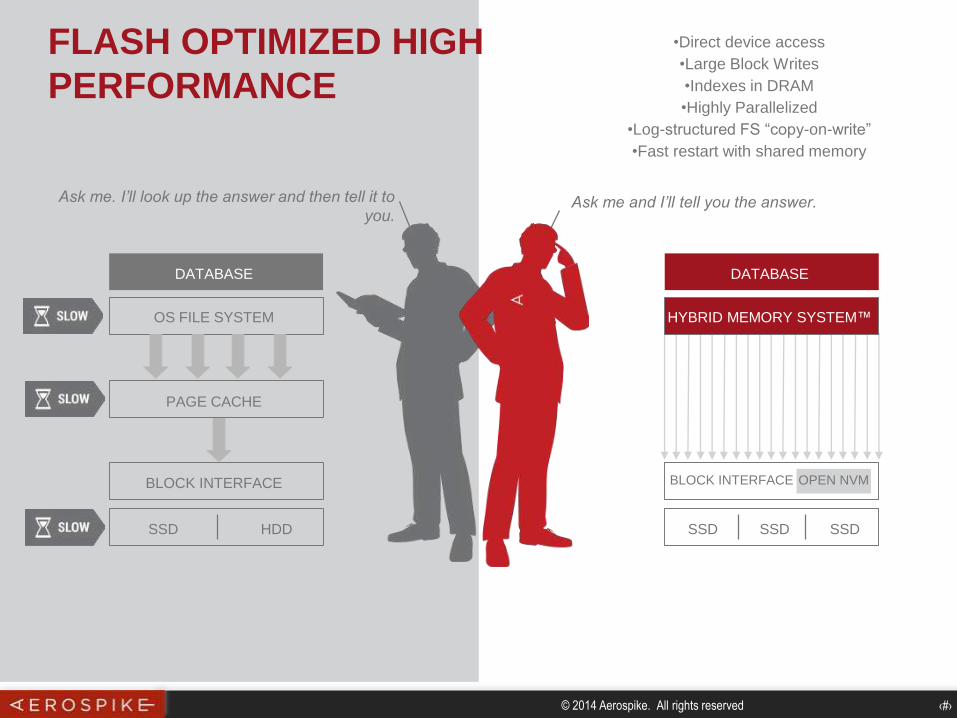
DATABASE
OS FILE SYSTEM
PAGE CACHE
BLOCK INTERFACE
SSD HDD
BLOCK INTERFACE
SSD SSD
OPEN NVM
SSD
Ask me and I’ll tell you the answer.Ask me. I’ll look up the answer and then tell it to
you.
DATABASE
HYBRID MEMORY SYSTEM™
•Direct device access
•Large Block Writes
•Indexes in DRAM
•Highly Parallelized
•Log-structured FS “copy-on-write”
•Fast restart with shared memory
FLASH OPTIMIZED HIGH
PERFORMANCE

© 2014 Aerospike. All rights reserved ‹#›
SHARED-NOTHING SYSTEM:100% DATA AVAILABILITY
■ Every node in a cluster is identical, handles both transactions and long running tasks
■ Data is replicated synchronously with immediate consistency within the cluster
■ Data is replicated asynchronouslyacross data centers
OHIO Data Center

© 2014 Aerospike. All rights reserved ‹#›





























