Embed Size (px)
Citation preview

Understanding Views in Couchbase Server
Perry Krug | Solutions Engineering Manager, Couchbase

©2015 Couchbase Inc. 2
Agenda
Introduction - Ways to Query
Views in Couchbase
Database Design Considerations for Views
How Views Work
Configuration Settings and their Effects
Resource Requirements

©2015 Couchbase Inc. 3
Introduction

©2015 Couchbase Inc. 4
Introduction – Data Access with Couchbase Server
Couchbase provides multiple forms of data access and indexing
Key-value/document access:
– Pro: operations are extremely and predictably fast
• Data is cached in memcached-like layer
• Reads and writes are evenly distributed across all nodes through consistent hashing
– Con: Limited application flexibility
• More complexity required for maintaining lists and retrieving data by non-primary key
• No dynamic querying

©2015 Couchbase Inc. 5
Introduction – Data Access with Couchbase Server
Couchbase provides multiple forms of data access and indexing
Global Secondary Indexes (as of 4.0)
– Indexes are partitioned independently from data
– Pro: Much faster index scan
• All (or most) of index is in one place
• Built-in managed cache
– Con: More resources needed to keep up-to-date
• All mutations are flowing to one point for a given index
• Faster disk and CPU needed in general

©2015 Couchbase Inc. 6
Introduction – Data Access with Couchbase Server
Couchbase provides multiple forms of data access and indexing
Views in Couchbase are “local indexes”:
– Indexes are partitioned alongside data
– Pro: Incremental map-reduce keeps indexes updated incrementally
• Append-only B-Tree format
• Each node only processes it’s own changes, whole index is updated in parallel
– Con: Querying has limited performance and scalability due to “scatter-gather”
• Latencies of 50-100ms
• Throughput up to 4k queries/sec
• More than 20 nodes not ideal
©2015 Couchbase Inc. 7
Introduction – Data Access with Couchbase Server
Patch
Management
Many others..
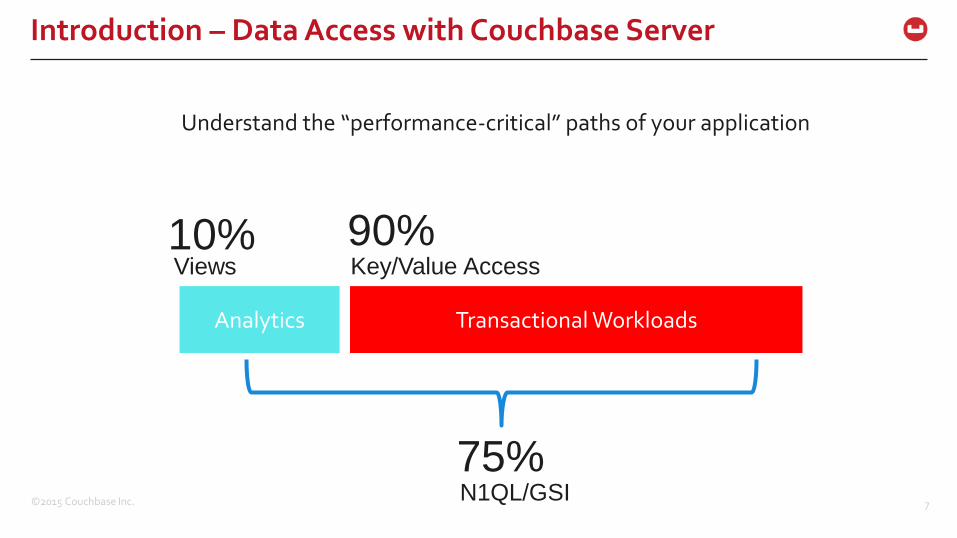
90%Views Key/Value Access
Analytics Transactional Workloads
10%
75%N1QL/GSI
Understand the “performance-critical” paths of your application

©2015 Couchbase Inc. 8
Couchbase Server Views
©2015 Couchbase Inc. 9
Indexing and Querying via Views
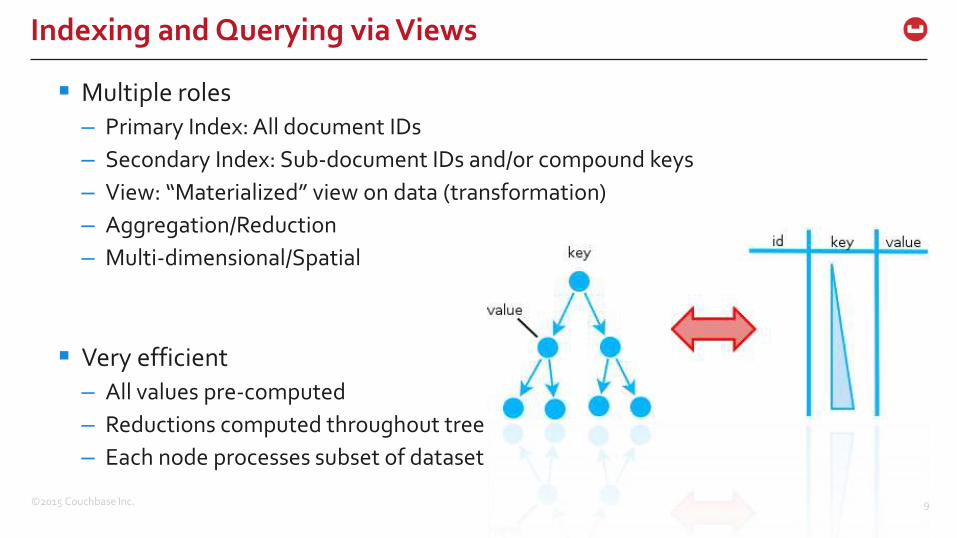
Multiple roles
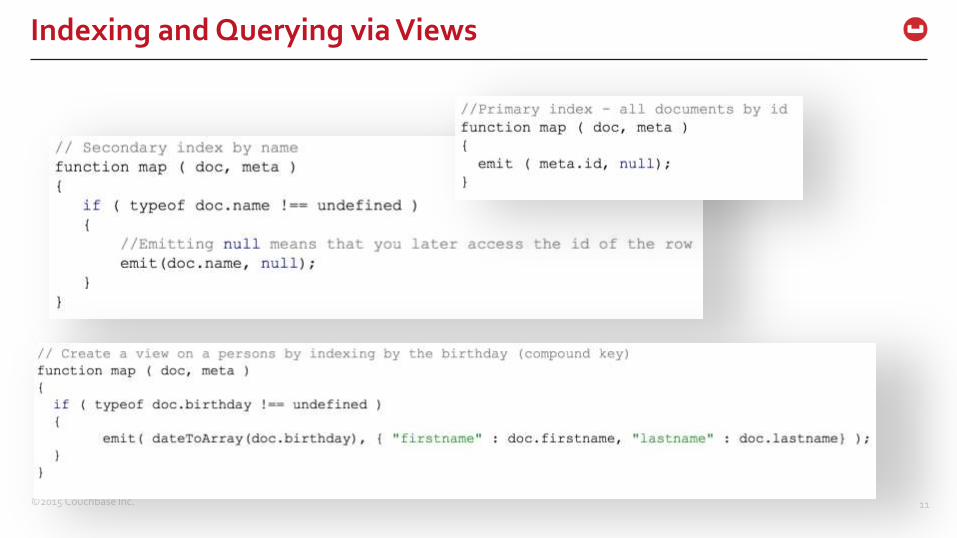
– Primary Index: All document IDs
– Secondary Index: Sub-document IDs and/or compound keys
– View: “Materialized” view on data (transformation)
– Aggregation/Reduction
– Multi-dimensional/Spatial
Very efficient
– All values pre-computed
– Reductions computed throughout tree
– Each node processes subset of dataset

©2015 Couchbase Inc. 10
Indexing and Querying via Views
Use Cases:
Best for “low-volume” querying, i.e. semi-offline or not directly user facing
Real-time Analytics:
– Incremental map-reduce keeps very large indexes updated efficiently
Spatial Views for Geospatial/Multidimensional indexing:
– True R-tree == More accurate results than other implementations
– Bounding Box queries (Polygon / n-way on the roadmap)
– Fully supported as of 4.0 (previously experimental)
©2015 Couchbase Inc. 11
Indexing and Querying via Views

©2015 Couchbase Inc. 12
Indexing and Querying via Views
Exact match query
Range query
With/without reduction
With/without grouping

©2015 Couchbase Inc. 13
Staleness/Consistency/Updating
Stale = OK
– Give me whatever you’ve got!
– Might not include most recent changes
– Fastest and predictable
Stale = false
– Make my query consistent!
– Include all latest changes
– Will be slower and variable depending on how many changes are waiting
Stale = “update after”
– Give me whatever you’ve got!
– But also kick off an update in the background
Couchbase updates view indexes in the background periodically

©2015 Couchbase Inc. 14
How Views Work

©2015 Couchbase Inc. 15
Views over the years…
Couchbase Server 1.8: No Views
Couchbase Server 2.0:
– Introduction of views
– View processing only happens after mutation is persisted to disk
– Stale=false didn’t account for changes in RAM
Couchbase Server 3.0:
– View processing rewritten in C++
– View processing happens from RAM
– Drastic improvement in latency for stale=false and is now strongly consistent
– Geo-spatial views experimental
Couchbase Server 4.0:
– Geo-Spatial views fully supported
– Introduction of GSI
©2015 Couchbase Inc. 16
Indexing and Querying via Views
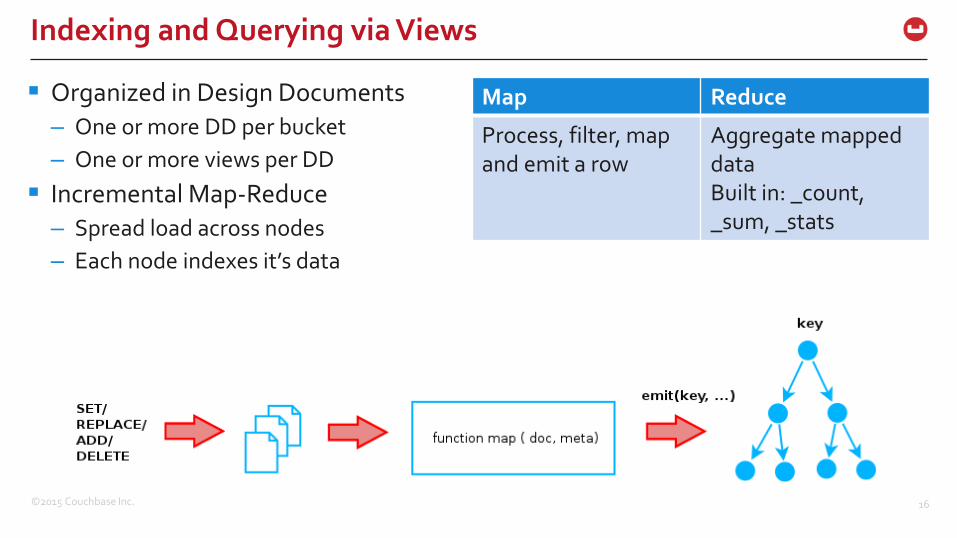
Organized in Design Documents
– One or more DD per bucket
– One or more views per DD
Incremental Map-Reduce
– Spread load across nodes
– Each node indexes it’s data
Map Reduce
Process, filter, map and emit a row
Aggregate mappeddataBuilt in: _count, _sum, _stats
©2015 Couchbase Inc. 17
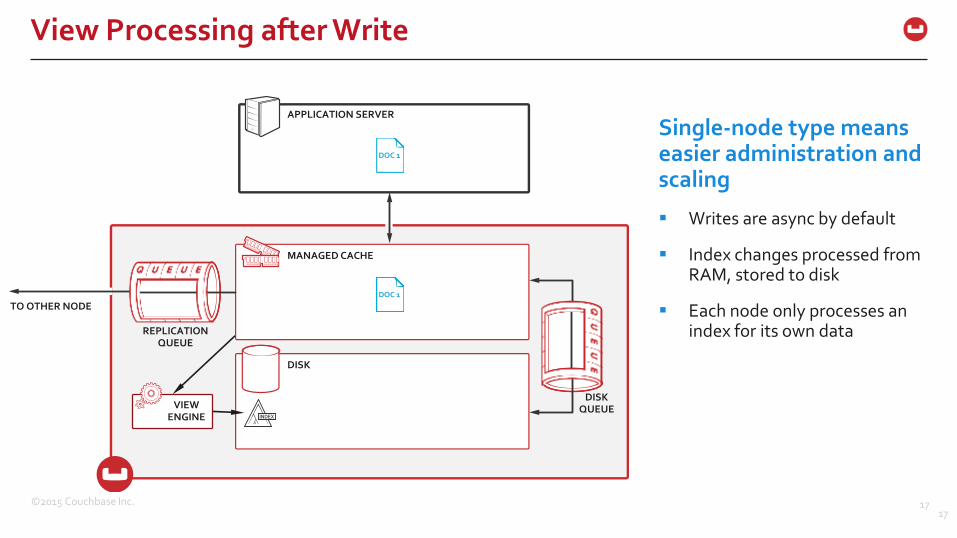
View Processing after Write
17
APPLICATION SERVER
MANAGED CACHE
DISK
DISKQUEUE
REPLICATIONQUEUE
VIEWENGINE
TO OTHER NODE
DOC 1
DOC 1DOC 1DOC 1
Single-node type means easier administration and scaling
Writes are async by default
Index changes processed from RAM, stored to disk
Each node only processes an index for its own data
©2015 Couchbase Inc. 18
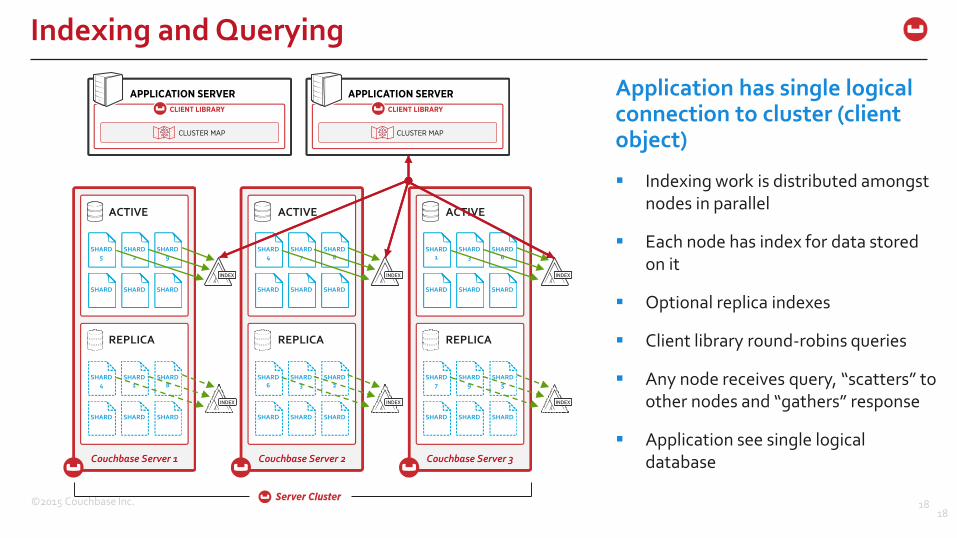
Indexing and Querying
18
ACTIVE ACTIVE ACTIVE
REPLICA REPLICA REPLICA
Couchbase Server 1 Couchbase Server 2 Couchbase Server 3
SHARD5
SHARD2
SHARD SHARD
SHARD4
SHARD SHARD
SHARD1
SHARD3
SHARD SHARD
SHARD4
SHARD1
SHARD8
SHARD SHARD SHARD
SHARD6
SHARD3
SHARD2
SHARD SHARD SHARD
SHARD7
SHARD9
SHARD5
SHARD SHARD SHARD
SHARD7
SHARD
SHARD6
SHARD
SHARD8
SHARD9
SHARD
Application has single logical connection to cluster (client object)
Indexing work is distributed amongst nodes in parallel
Each node has index for data stored on it
Optional replica indexes
Client library round-robins queries
Any node receives query, “scatters” to other nodes and “gathers” response
Application see single logical database

©2015 Couchbase Inc. 19
Design Considerations

©2015 Couchbase Inc. 20
Best Practices - Selection, Projection, Aggregation
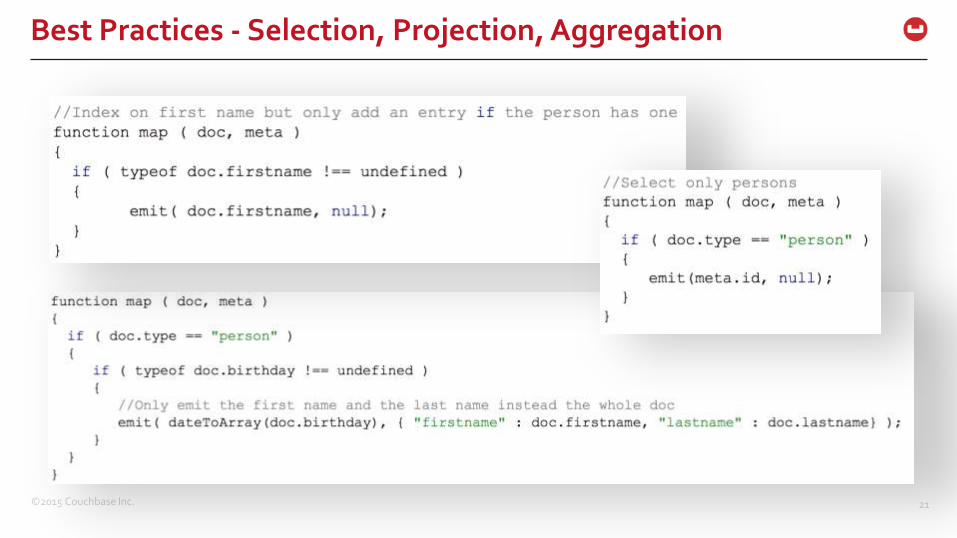
Try avoid computing too many things in a View
Check for attribute existence
Pre-Filter data to avoid unnecessary entries in the View
– Use document types to make Views more selective
Project (map) only necessary data by emitting it as part of the value
– Do not emit the full document
– Back-reference via the original document id (SDKs have built-in functionality)
Use the built-in reduce functions if possible
Leverage default “staleness” (update_after) instead of stale=false
©2015 Couchbase Inc. 21
Best Practices - Selection, Projection, Aggregation

©2015 Couchbase Inc. 22
Number of Design Documents per Bucket
Indexers are allocated per Design Document
Bad cases
– One Design Document contains all Views
All Views are updated the same time
A lot to do for the Indexer
– One View per Design Document
Resource intensive because one Indexer per View
Good balance!

©2015 Couchbase Inc. 23
Separated Buckets for Indexing / Querying
Creating a View for one large Bucket may be heavy weighted
– Extra processing of data that doesn’t need to be indexed
– Slower overall indexing of data that does
Separate data to be indexed / queried
– Short-lived data
– High write rate (if doesn’t need to be indexed)
– Binary data separate from metadata (JSON or other)
Don’t create too many Buckets!
©2015 Couchbase Inc. 24
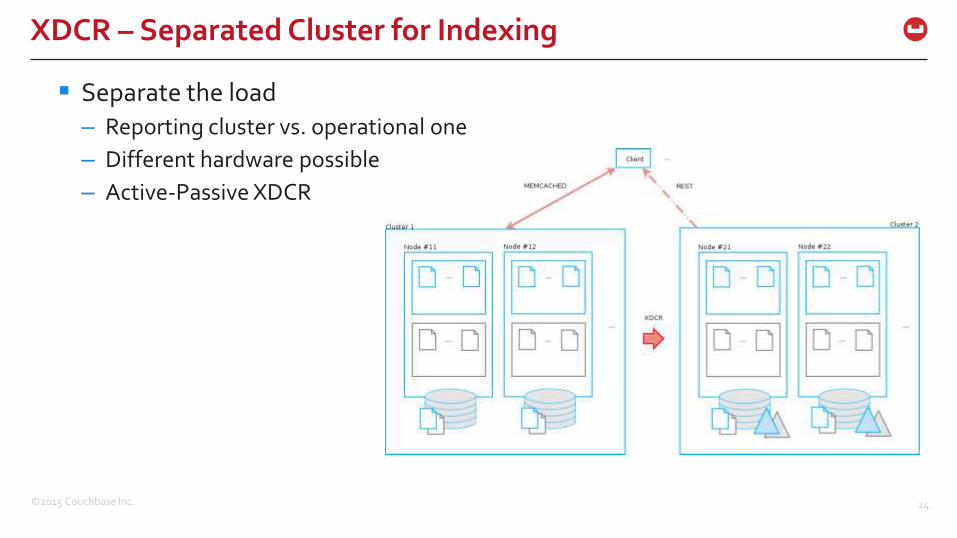
XDCR – Separated Cluster for Indexing
Separate the load
– Reporting cluster vs. operational one
– Different hardware possible
– Active-Passive XDCR

©2015 Couchbase Inc. 25
Configuration Settings
and their Effects
©2015 Couchbase Inc. 26
Indexing Settings
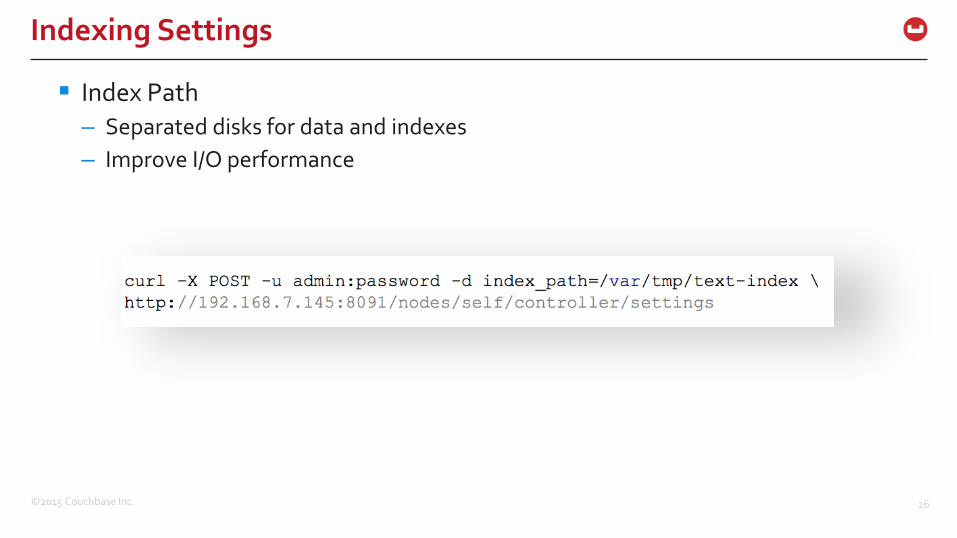
Index Path
– Separated disks for data and indexes
– Improve I/O performance
©2015 Couchbase Inc. 27
Indexing Settings
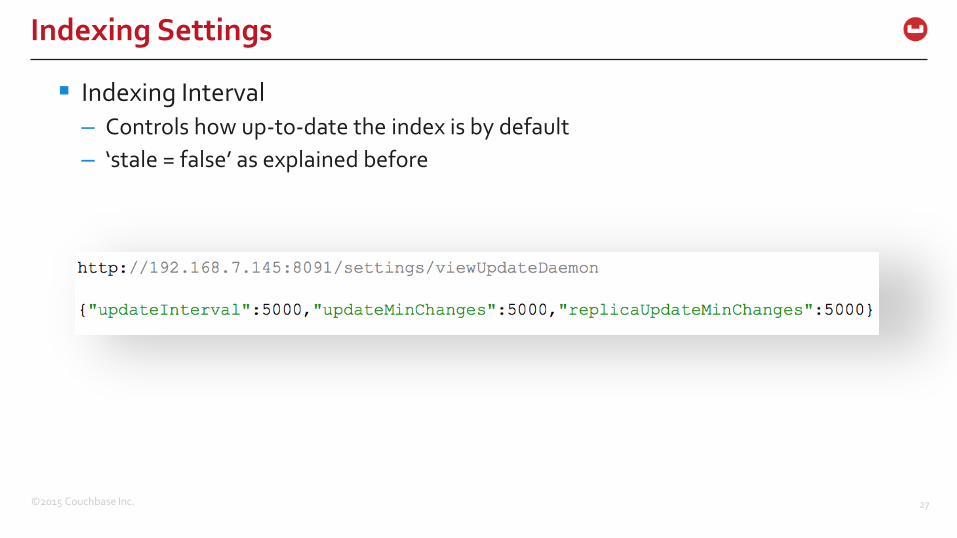
Indexing Interval
– Controls how up-to-date the index is by default
– ‘stale = false’ as explained before

©2015 Couchbase Inc. 28
Indexing Settings
Max. number of in parallel working indexers
– Increase the number of threads per node
– Higher level of concurrency
– Higher disk and CPU load

©2015 Couchbase Inc. 29
Rebalance Settings
Index-aware rebalance
– Indexing by default as part of rebalancing
– Ensures that you get query results from a new node during rebalance that are consistent with the query results you would have received from the node before rebalance started
– Performance impact if enabled, so rebalance takes significantly more time
©2015 Couchbase Inc. 30
Rebalance Settings
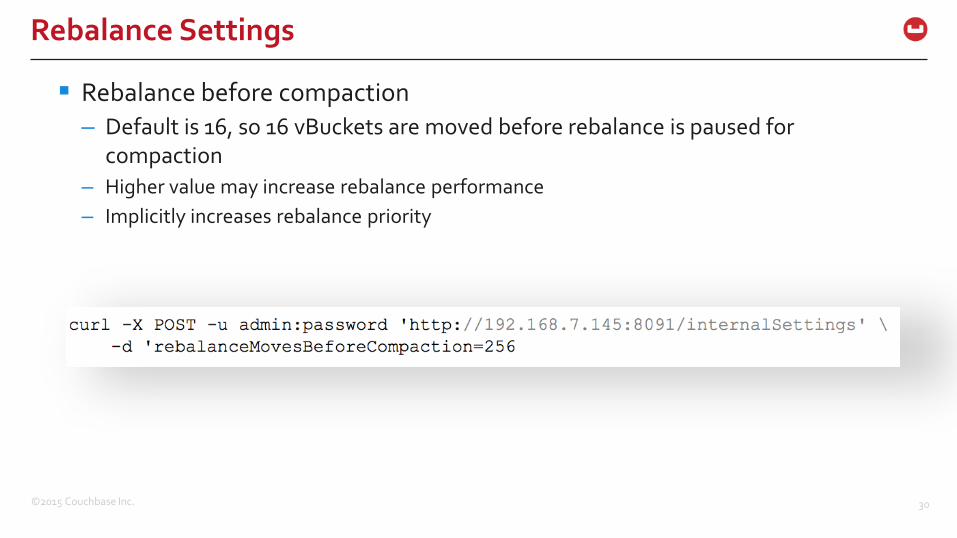
Rebalance before compaction
– Default is 16, so 16 vBuckets are moved before rebalance is paused for compaction
– Higher value may increase rebalance performance
– Implicitly increases rebalance priority
©2015 Couchbase Inc. 31
Rebalance Settings
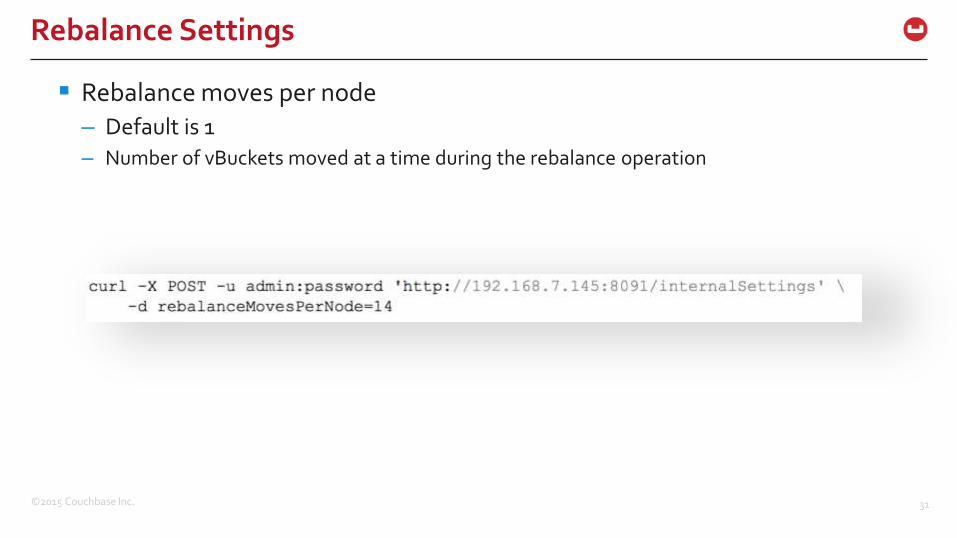
Rebalance moves per node
– Default is 1
– Number of vBuckets moved at a time during the rebalance operation

©2015 Couchbase Inc. 32
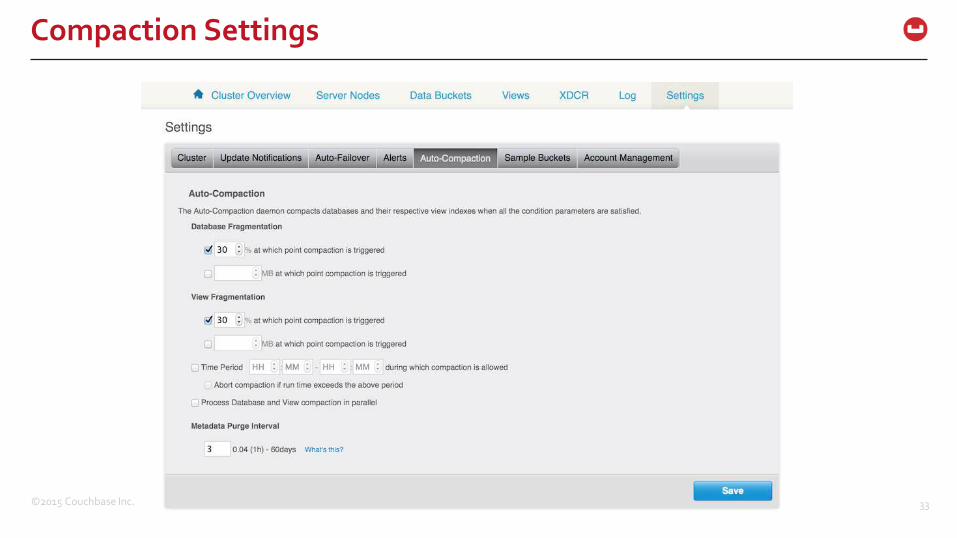
Compaction Settings
(Auto) Compaction
– Append only storage engine
– In-place updates are expensive
– Removes tombstone objects and fragmentation
Process Data and View compaction in parallel
– Implies a heavier processing and disk I/O load during compaction process
©2015 Couchbase Inc. 33
Compaction Settings

©2015 Couchbase Inc. 34
Resource Requirements
©2015 Couchbase Inc. 35
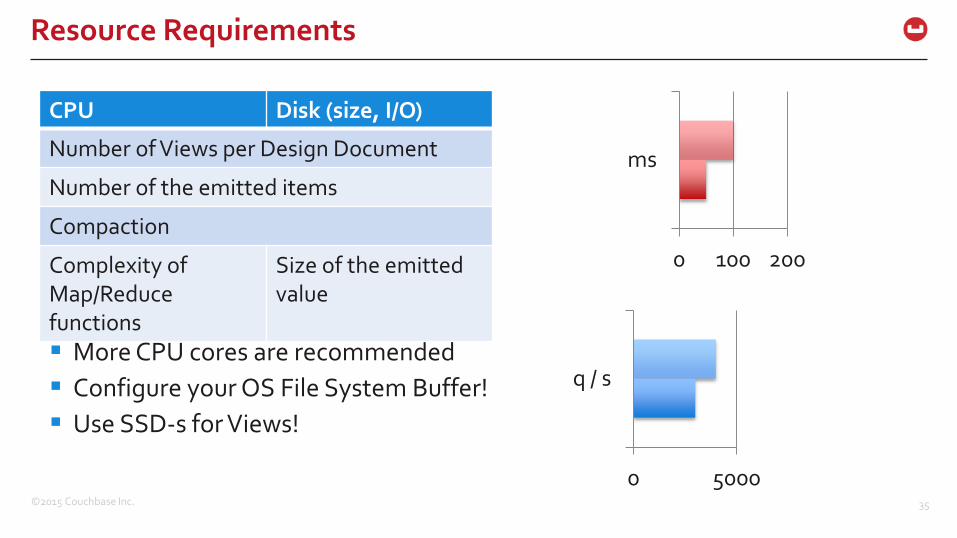
Resource Requirements
More CPU cores are recommended
Configure your OS File System Buffer!
Use SSD-s for Views!
CPU Disk (size, I/O)
Number of Views per Design Document
Number of the emitted items
Compaction
Complexity of Map/Reduce functions
Size of the emitted value
0 100 200
ms
0 5000
q / s

Thank you





























