Embed Size (px)
Citation preview

ZooKeeper (and other things)
@jhalt

Part 1: The User’s Perspective

What is ZooKeeper?
A highly available, scalable, consistent, distributed, configuration, consensus, group membership, leader election, queuing, naming, file system, and coordination service.

…but for real
• It’s just a datastore• That’s durable– (data syncs to disk)
• And replicated– (disks on different servers)
• And ordered– (data is ordered the same on all servers)
• And consistent *– (clients see the same data at the same time) *
https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying

ZK Guarantees
• Reliability– Durable writes, network partition handling
• Atomicity– No partial failures
• Sequential Consistency– Updates applied in order they were sent
• Single System Image *– All clients see the same view
• Timeliness– Timely eventing, failure detection
http://zookeeper.apache.org/doc/r3.4.6/zookeeperProgrammers.html#ch_zkGuarantees

ZK Features / Concepts
• Znode– Data object– Hierarchical– Identified by a path– Version tagged
• Watchers– Watch for Znode creation / changes / deletion
• Emphemeral Znodes– Go away when a client session ends

ZooKeeper API
• create (path, nodeType)• get (path, watcher)• set (path, value, version)• delete (path)• exists (path, watcher)• getChildren (path, watcher)• multi (ops)• sync (path)
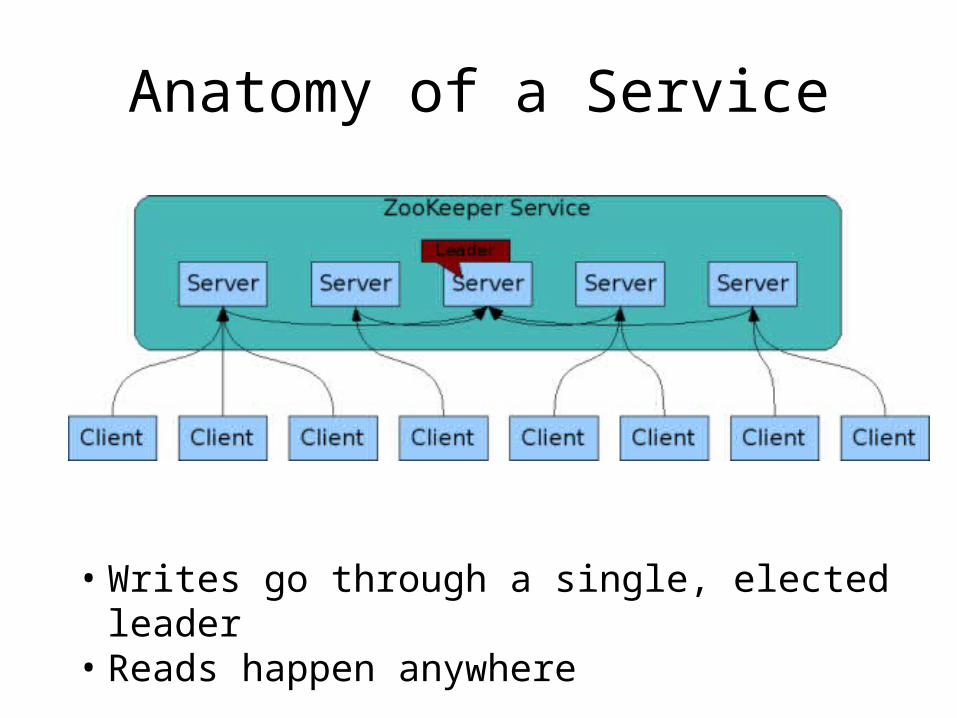
Anatomy of a Service
• Writes go through a single, elected leader• Reads happen anywhere

Anatomy of a Client Session
• Client connects to one of a list of servers• Client heartbeats regularly to maintain session• If client fails to send heartbeat, ZK cluster
deletes client’s ephemeral Znodes• If server fails to respond to heartbeat, client
will attempt to migrate session to another server

Anatomy of a Write
1. Client sends write to node2. Node forwards write to leader3. Leader sends write to all followers4. Followers commit write5. After W followers respond:
1. Leader commits write2. Leader responds to client

Common Use Cases• Configuration Management– Storm, Cassandra, S4
• Leader Election– Hadoop, Hbase, Kafka, Spark, Solr, Pig, Hive, Neo4j
• Cluster Management– ElasticSearch, Mesos, Akka, Juju, Flume, Accumulo
• Work Queues– TaskFlow
• Load Balancing• Sharding• Distributed Locks

Configuration Management
Administrator ProcesssetData(“/config/param1”, “value”)
Client ProcessgetData(“config/param1”, watcher)

Leader Election
Candidate Process// Check for a leadergetData(“/servers/leader”, watch)
// If empty, create a leadercreate(“/servers/leader”, hostname, EPHEMERAL)

Cluster Management
Master process1. Create watch on “/nodes”2. On alert, getChildren(“/nodes”)3. Check for changes
Node processes4. Create ephemeral “/nodes/node-[i]”5. Update periodically with status changes

Work QueuesMaster process1. Create watch on “/tasks”2. On alert, getChildren(“/tasks”)3. Assign tasks to workers via:
1. create “/workers/worker-[i]/task-[j]”4. Watch for deletion indicating task complete
Worker process5. Create watch on “/workers/worker-[i]”6. On alert, getChildren for worker and do work7. Delete tasks when complete

Part 2: The Scientist’s Perspective

Fallacies of Distributed Computing
• 1. The network is reliable– Partitions can cause diverging data (inconsistency)
• 2. Latency is zero– Clients can see stale data (eventual consistency)
• 3. Bandwidth is infinite• 4. The network is secure• 5. Topology doesn't change• 6. There is one administrator• 7. Transport cost is zero• 8. The network is homogeneoushttps://blogs.oracle.com/jag/resource/Fallacies.html - Conceived by Peter Deutschhttps://aphyr.com/posts/288-the-network-is-reliable

Achieving Consistency
• It’s all about CONSENSUS– Multiple processes agreeing on a value
• Distributed consensus is hard• ZK uses consensus to ensure consistency• With consensus we can safely do– Atomic commits– Distributed locks– Group membership– Leader election– Service discovery

Consensus in ZooKeeper
• ZooKeeper uses leader election• All writes go through the leader• Leader is elected via consensus

Availability in ZooKeeper
• ZooKeeper uses majority quorums• “Ensembles” should be even numbers– 1 – Fine for testing– 3 – Can survive 1 failure– 5 – Can survive 2 failures
• Multi-way partitions can cause other havoc

Consistency Models
• Linearizable consistency– Writes are processed in order– Writes are immediately visible to all participants– Allows safe state mutation, CAS
• Sequential consistency– Writes are processed in order– Writes may not be visible to other participants till later
• Serializable consistency– Writes are processed in any order, at any time
http://www.ics.forth.gr/tech-reports/2013/2013.TR439_Survey_on_Consistency_Conditions.pdfhttp://www.bailis.org/blog/linearizability-versus-serializability/https://aphyr.com/posts/313-strong-consistency-models

Consistency Tradeoffs

Consistency in ZooKeeper
• Writes are Linearizable– Threading through leader ensures linearizability
• Reads are Sequential– Followers may not have latest writes, but writes
are seen in order• Linearizable reads via sync/read?– No. No. No.– Could only work if operations were executed
atomically by the leaderhttps://ramcloud.stanford.edu/~ongaro/thesis.pdf - Section 6.3 covers linearizable reads from followers

What about CAP?
• CP or AP?– AP – Every request receives a response– CP – All nodes see the same data at the same time
• ZooKeeper requires majority quorum– It’s not AP
• ZooKeeper reads are not linearizable– It’s not CP
• 3.4 adds read-only mode– It can be AP!
https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.htmlhttp://www.tcs.hut.fi/Studies/T-79.5001/reports/2012-deSouzaMedeiros.pdf

ZooKeeper Pitfalls
• Log purging• Session timeouts– Causes ephemeral data is deletion– Client side GC or swapping?
• Server side disk/NIC IO latency– Lack of dedicated disks for ZK servers

ZooKeeper Limitations
• Consistency comes at a cost• Not Horizontally scalable– Data is not partitioned – fully replicated• 1mb data entries by default• Entire dataset lives in memory
– All writes go through leader and require quorum• Max ops/sec
– All sessions are replicated• Max sessions

Takeaways
• ZooKeeper is a distributed datastore• It provides sequential consistency• It is resilient to (N/2)-1 failures• It is not horizontally scalable• It can be highly available for reads only

fin.
Questions?





























