Embed Size (px)
Citation preview

論文紹介S.Reedetal.
Genera-veAdversarialText-to-ImageSynthesis(ICML’16)
2016/6/10
hFp://arxiv.org/abs/1605.05396
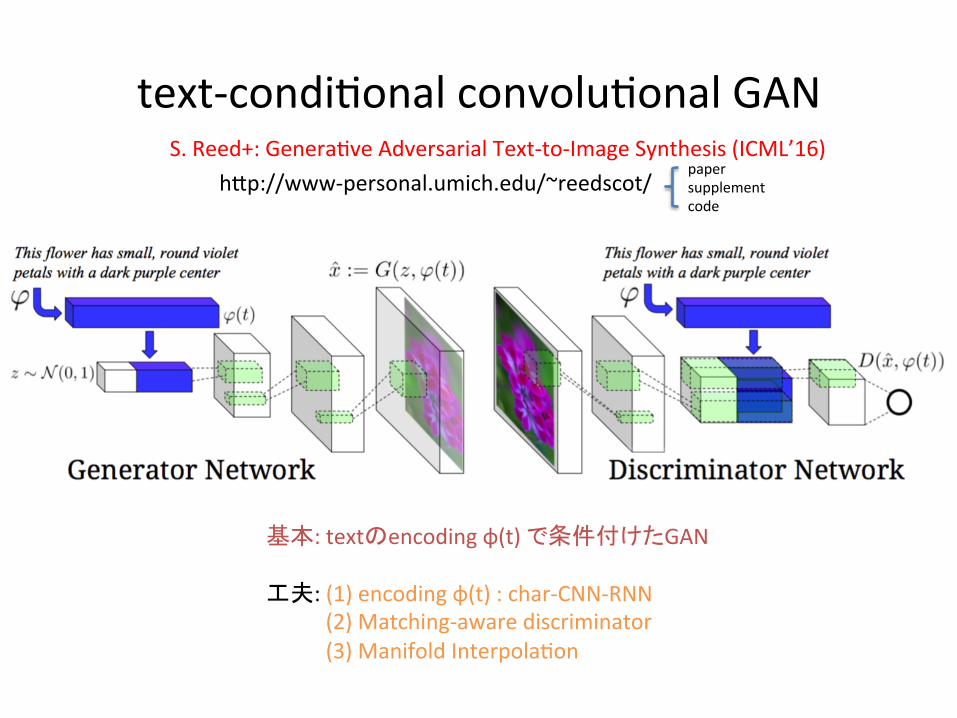
text-condi-onalconvolu-onalGAN
基本:textのencodingφ(t)で条件付けたGAN工夫:(1)encodingφ(t):char-CNN-RNN(2)Matching-awarediscriminator(3)ManifoldInterpola-on
hFp://www-personal.umich.edu/~reedscot/papersupplementcode
S.Reed+:Genera-veAdversarialText-to-ImageSynthesis(ICML’16)

(1)char-CNN-RNN
• 以下の損失を最小化するようにencoderを訓練
• このencodingは学習の速さに寄与
Imageencoder
textencoder(character-levelCNNorLSTM)
Δ:0-1loss,yn:classlabelvn:image,tn:text
S.Reed+:LearningDeepRepresenta-onsofFine-GrainedVisualDescrip-on(CVPR’16)

(2)Matching-awareDiscriminator(GAN-CLS)
• na-veGAN:以下のようになるようDを学習1. D(本物の画像,正解文章)=12. D(合成画像,任意の文章)=0
• 実際に判定すべき誤りには以下の二種類がある
– (合成画像,任意の文章)– (本物の画像,間違った文章)
• そこで訓練時に(本物の画像,間違った文章)のペアを利用するようにアルゴリズムを修正

(2)Matching-awareDiscriminator(GAN-CLS)
目標出力:1
目標出力:0

(3)ManifoldInterpola-on(GAN-INT)
• 多様体仮説– 訓練データのembeddingsを補間したものもデータの多様体近くに存
在
• φ(t)を重ね合わせたものを訓練に利用• Generator の目的関数で以下を最小化する
• β=0.5で十分うまくいくことを確認

実験パラメータ
• 画像サイズ (64,64,3)• textencoderφ(t):1024 次元• φ(t)はFCで128次元にした後,leaky-ReLUを掛け,zと結合• stride2convolu-on• 全てのconvolu-onの後にBNを適用• discriminatorのspa-alな次元:4x4• ADAMsolver,momentum0.5,minibatchsize64,600epoch
1x1conv,ReLU,4x4conv

実験データ
• CUBbirds– 1万枚程度,200カテゴリ
• Oxfordflower102– 計8189枚
• MSCOCO– 8万枚程度
• CUBとflowersは著者らがキャプションをつけた?– キャプションデータは公開されている– MSCOCOは大きすぎるので,CUBやflowersは検証データとして良いか
も

interpola-onの効果
実験結果(CUB)
Zero-shot(i.e.condi-onedontextfromunseentestsetcategories)generatedbirdimages

実験結果(flowers)

実験結果(MSCOCO)

styleとcontentに関する考察
• テキスト情報:contentinforma-on(鳥の種類,形,大きさ等)– 背景や鳥の姿勢等の情報(style)は一般に含まない– ノイズzがstyleを表現するように学習されるべき
• styleencoderを学習
• 評価実験 – クラスタリングでposeとbackgroundに関して画像をグループ分け– 同一グループの画像のペアをstyleencoderに入力し,最終的に得ら
れた出力のコサイン類似度を計算– AUC-ROCで評価
S:StyleEncoderNetwork
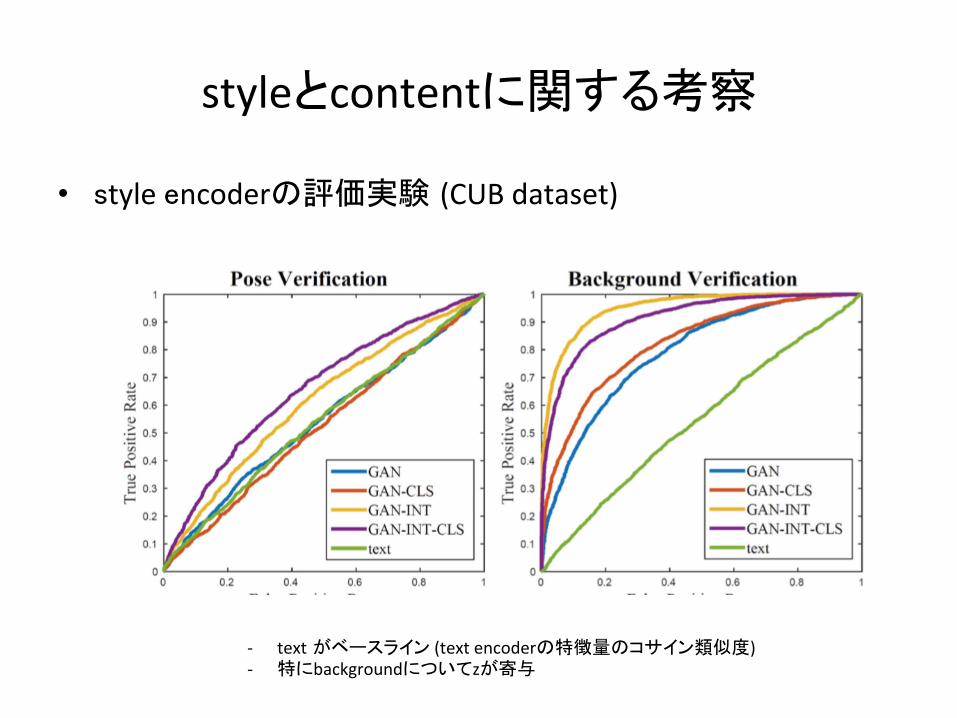
styleとcontentに関する考察
• styleencoderの評価実験 (CUBdataset)
- text がベースライン(textencoderの特徴量のコサイン類似度)- 特にbackgroundについてzが寄与

textのcontent(色など)を変えた場合

2つのランダムなzを補間2つのtextencodingを補間

訓練してみる
• hFps://github.com/reedscot/icml2016
• ベースはdcgan.torch
• 訓練データ(キャプション含む)も公開されている– ただしCUB,flowersに関しては一部データが不完全なような..?
• まだ自分で訓練できてはいない

学習結果(MSCOCO,10epoch(4hr~))
(論文は600epoch?)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adversarial Networks](https://img.pdfslide.net/doc/110x75/58b87a1b1a28ab44078b4819/dlwasserstein-gantowards-principled-methods-for-training-generative.jpg)


![[DL輪読会]StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks](https://img.pdfslide.net/doc/110x75/58ce7c991a28ab210a8b4a81/dlstackgan-text-to-photo-realistic-image-synthesis-with-stacked.jpg)






![[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation](https://img.pdfslide.net/doc/110x75/5a6479317f8b9a2c568b473f/dlstargan-unified-generative-adversarial-networks-for-multi-domain.jpg)





![[Dl輪読会]semi supervised learning with context-conditional generative adversarial networks](https://img.pdfslide.net/doc/110x75/587148651a28ab55588b5edd/dlsemi-supervised-learning-with-context-conditional-generative-adversarial.jpg)











![[DL輪読会]Energy-based generative adversarial networks](https://img.pdfslide.net/doc/110x75/5a6479ae7f8b9a4c568b46fd/dlenergy-based-generative-adversarial-networks.jpg)