Embed Size (px)
Citation preview

2016年8月24日
1
@shoe116
黄色いゾウさんと
愉快な仲間たちの
近況報告

0. 本日の内容
1. 自己紹介
2. 注目キーワード紹介
3. 黄色いゾウさんと愉快な仲間たちの近況
4. 個人的な所感
注) 内容は筆者の個人的見解であり、筆者の所属組織とは無関係です
2

1. 自己紹介:@shoe116
なまえ:しゅう (@shoe116)
お仕事:データプラットフォーム部データフィード
- いろんなデータをETLしてHDFSに置いておく
これまで:広告システム→Qubitalデータサイエンス
言語:Python, Java > JavaScript > Scala, C++
興味:No music, no life. No idol, no life.
課外活動:お歌を歌ったり、戯言を並べたり
- https://shoe116.tumblr.com/3

2. 注目キーワード紹介

#HS16SJの注目キーワード
独断と偏見で選んだ、Hadoop界隈注目キーワード。
1. data in motion, data at rest
2. Stream Processing
3. Enterprise
5
[1]
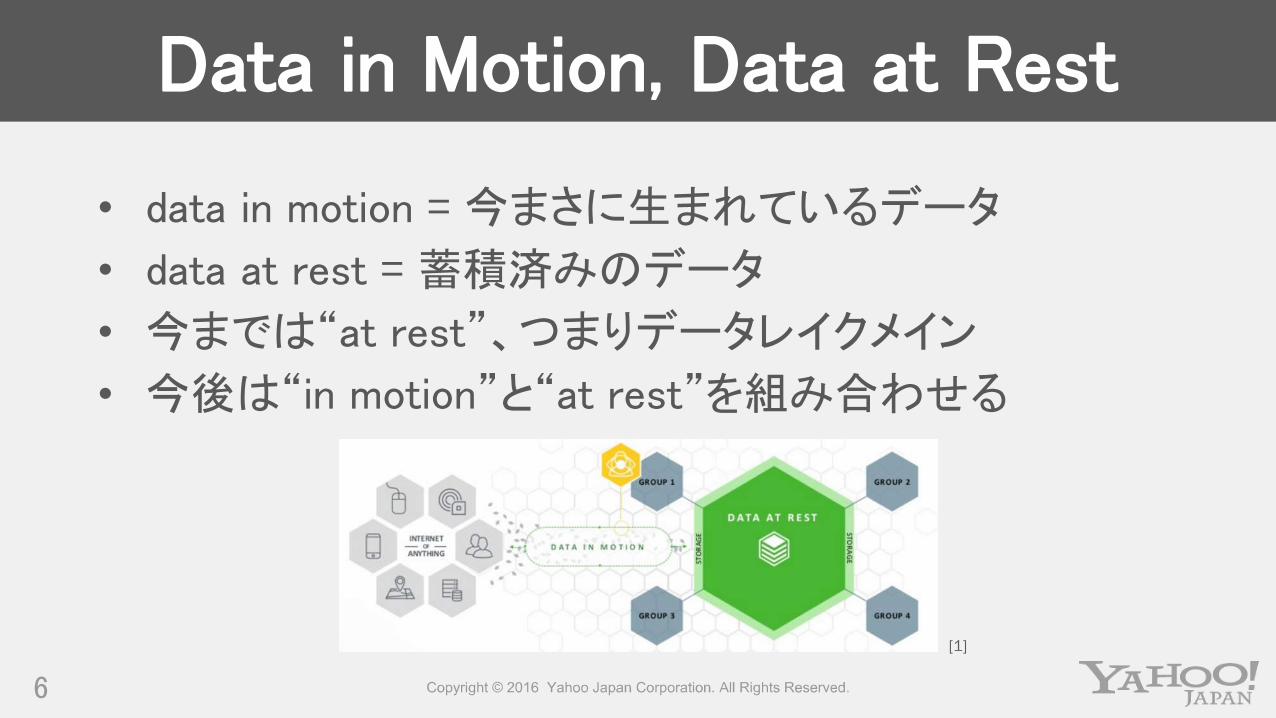
Data in Motion, Data at Rest
• data in motion = 今まさに生まれているデータ
• data at rest = 蓄積済みのデータ
• 今までは“at rest”、つまりデータレイクメイン
• 今後は“in motion”と“at rest”を組み合わせる
6
[1]

Stream Processing
• 生まれ続けるデータ(“data in motion”)から、いかに速く価値をだすか?
• 全セッションの1/4はデータの継続的な逐次処理、いわゆるストリーム処理がテーマ
• 今までbatchでしか処理出来なかったことを、どうやってStreamで処理するか
7

Enterprise
• 簡単に言うと、HAとセキュリテイ(ACL)のこと。keynoteでは大人気(ある意味当たり前)
• HAは、各社具体的な取り組み報告あり
• セキュリティは「Enterpriseにはセキュリティ大事だよね!」「うんうん!」という感じ
• ACLの話を始めると、HDFSが結局“ファイルシステム”であるという問題が顕在化する
8

3. 黄色いゾウさんと
愉快な仲間たちの
近況報告

Hadoopとエコシステムの現状
独断と偏見で選んだ、最近のエコシステムのあり方。
1. Kafkaはデファクトスタンダード
2. Stream処理エンジンは群雄割拠
3. HDFSへのSQLはHiveへ収束
4. Sparkは分析ツール
10
[1]
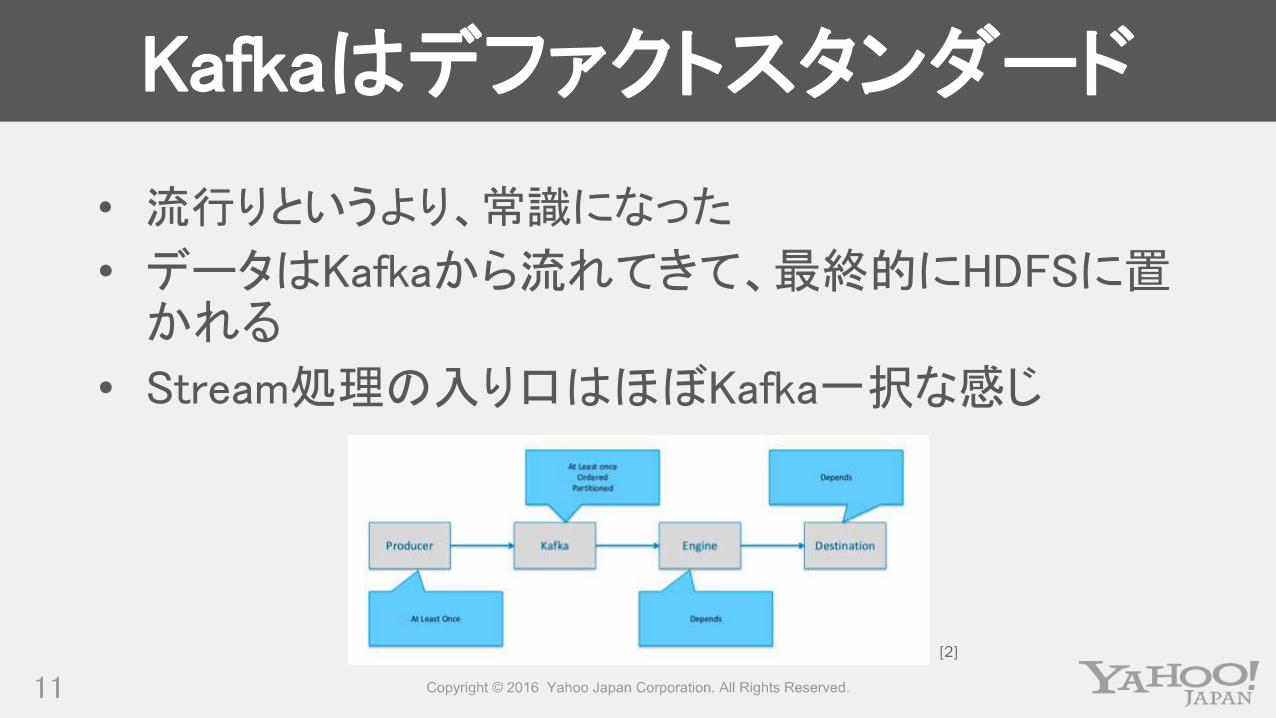
Kafkaはデファクトスタンダード
• 流行りというより、常識になった
• データはKafkaから流れてきて、最終的にHDFSに置かれる
• Stream処理の入り口はほぼKafka一択な感じ
11
[2]

Stream処理エンジンは群雄割拠
• Storm, Spark Streaming, Flink, Flume, Kafka Streams, Heron, and etc
• プロダクションの実績ではStromが一歩リード。
• 注力領域だけあってポジショントークがすごい• Hortonworks 「Strom1.0がでたよ!2系も来るよ!」
• Cloudera 「Stormは直に歴史の1ページ」
• “Ingest and Stream Processing - What will you choose?”[3]にまとまっている
12

HDFSへのSQLはHiveへ収束
• HDFSへのSQL(いわゆるSQL on Hadoop)はHiveに落ち着いた。特にメモリに載り切らないSQLはHive一択
• Presto, Drill, Impala等はmassively-parallel processing (MPP)でインタラクティブ、かつデータソースを跨ぐ部分で競争中
• “Apache Hive 2.0: SQL, Speed, Scale”[4]に一通りまとまっている
13

Sparkは分析ツール
• パフォーマンスというより、多機能でプログラミングしやすいインターフェースが売り
• Hiveやprestoと同じ、データから価値を出すツール
14
[5]

4. 個人的な所感

#HS16SJの個人的な感想
Hadoop Summit 2016に行った個人的な感想。
1. セキュリティ、特にACLについて
2. オンプレとクラウドの使い分け
3. アメリカすごい、日本ヤバい
16
[1]

セキュリティ、特にACLについて
• file systemであるHDFSに直接アクセスされると、schemaでのACLは当然かけられない
• 列指向フォーマットファイル(ORC等)に、抽象化したアクセスを提供するレイヤが待たれる
• つまりそれがLLAP(+Renger)で、目下開発中
17

オンプレとクラウドの使い分け
• ちょっと前までは「とりあえずデータはクラウド」って言う感じ
• “data in motion”の処理は当然プロダクションから近いほど有利
• クラウドとオンプレを組み合わせる• “data at rest”はクラウド• “data in motion”はプロダクション環境
18

アメリカすごい、日本ヤバい
• HDFS+kafkaをmongoDB+rabbitMQくらいの感じでみんな自然に使ってる
• 日本のビッグデータはまだ目的な気がする、アメリカではすでに手段になっている
• 抱えている課題は日米同レベル、違うのは解決力
19

参考資料等
[1] Hortonworks Modern Architecture
http://www.slideshare.net/MatsJohansson4/data-in-motion-data-at-rest-hortonworks-a-modern-architecture
[2][3] Ingest and Stream Processing - What will you choose?
http://www.slideshare.net/HadoopSummit/ingest-and-stream-processing-what-will-you-choose?qid=bcf794fa-e2eb-4eb9-9478-67d42c5a790c&v=&b=&from_search=2
[4] Apache Hive 2.0: SQL, Speed, Scale
http://www.slideshare.net/HadoopSummit/apache-hive-20-sql-speed-scale-63920205
[5] Producing Spark on YARN for ETL
http://www.slideshare.net/HadoopSummit/producing-spark-on-yarn-for-etl
20
























![都心で寛ぎ、愉しむ、谷町四丁目の新生活...都心で寛ぎ、愉しむ、谷町四丁目の新生活 ハイグレード都市型レジデンス [ ブエナビスタシリーズ]誕生](https://img.pdfslide.net/doc/110x75/5f1d53cb3064b552fb3b1762/effeccc-effeccc.jpg)




