Embed Size (px)
Citation preview
Chainer を用いた対話ボットの作り方

自己紹介 名前:宮本圭一郎
SIer で ERP 開発( C#,VB ) freelance深層学習サービスの開発( python )
@miyamotok0105 https://www.facebook.com/keiichirou.miyamoto

実装例紹介対話で使われているモデルchainer での実装紹介データの作り方紹介

実装例紹介

Conchylicultor/DeepQA
https://github.com/Conchylicultor/DeepQA

nicolas-ivanov/tf_seq2seq_chatbot
Sequence-to-sequence model with attention
multiple buckets
multi-layer recurrent neural network as encoder,
and an attention-based decoderhttps://github.com/nicolas-ivanov/tf_seq2seq_chatbot

macournoyer/neuralconvo
https://github.com/macournoyer/neuralconvo

データと論文
Corpora
・ AlJohri/OpenSubtitles
Get a lot of raw movie subtitles (~1.2Gb)
・ Cornell Movie-Dialogs Corpus
~ 40Mb after clearing out the technical data.
Papers
[1] Sequence to Sequence Learning with Neural Networks
[2] A Neural Conversational Model
https://github.com/nicolas-ivanov/seq2seq_chatbot_links

対話で使われているモデル

キーワードword2vec
RNN,LSTM
A simple Seq2Seq
Seq2seq with attention
Encoder-decoder 翻訳
DSSM+RNN GRU
Hierarchical Neural NetworkLatent Variable Hierarchical Recurrent Encoder-Decoder
Google Neural Machine Translation(GNMT)
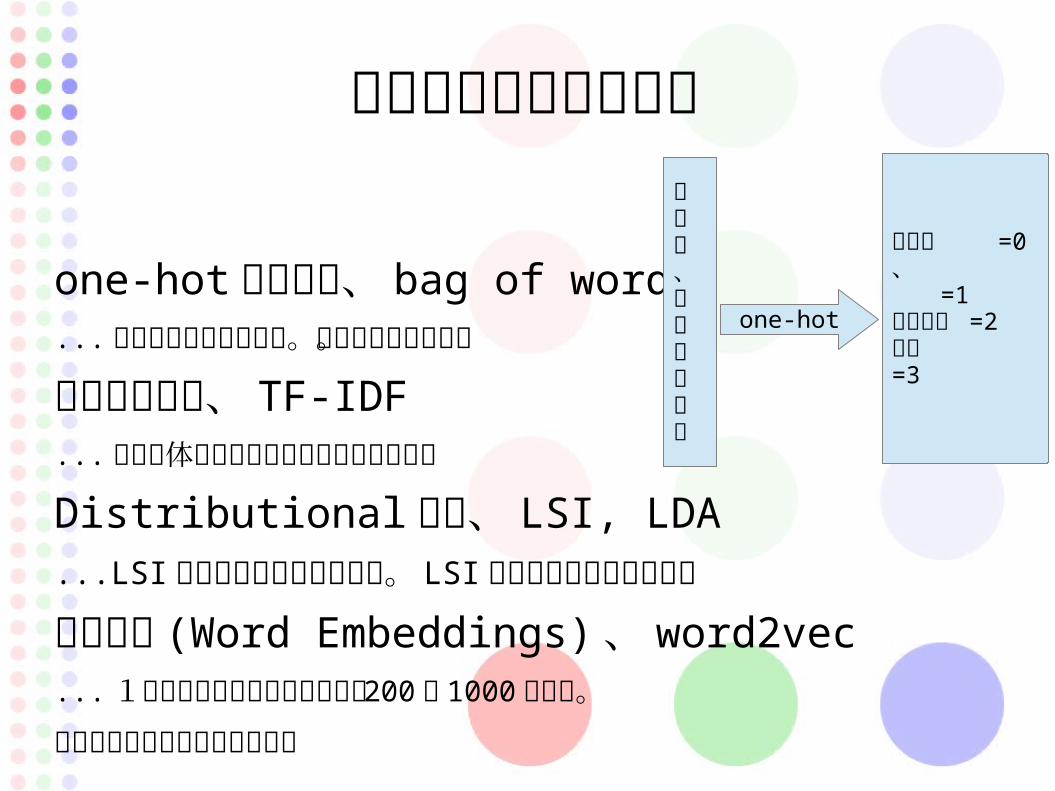
文字をベクトル化する
one-hot ベクトル、 bag of words... 未知語に対応できない。次元が増えすぎる。
文脈ベクトル、 TF-IDF... 文章全体に占める割合も重みとして考慮
Distributional 表現、 LSI, LDA...LSI は特異値分解で次元圧縮。 LSI モデルに確率分布を付与
分散表現 (Word Embeddings) 、 word2vec... 1層のニューラルネットで通常 200 〜 1000 次元程。
単語の定義によってベクトル化
ですね、人工知能です
ですね =0 、
=1 人工知能 =2
です =3
one-hot
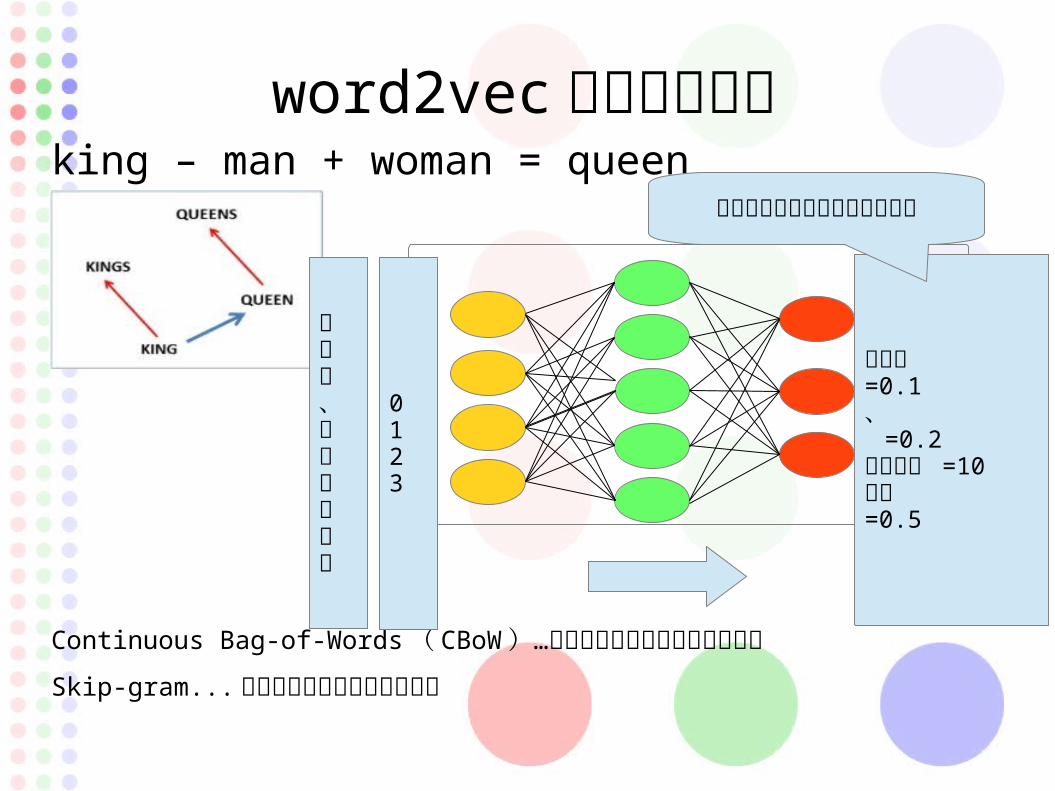
word2vec でベクトル化king – man + woman = queen
Continuous Bag-of-Words ( CBoW …) 前後の単語から対象単語を予測
Skip-gram... 単語からその周辺単語を予測
ですね、人工知能です
0123
ですね =0.1 、 =0.2
人工知能 =10 です =0.5
単語の定義によってベクトル化

word2vecking – man + woman = queen
EmbedID 、、、
one-hot ベクトル入力に効率のよい層。 embed_id 関数のラッパー。
one-hot ベクトルは文字に対しベクトル化すること。
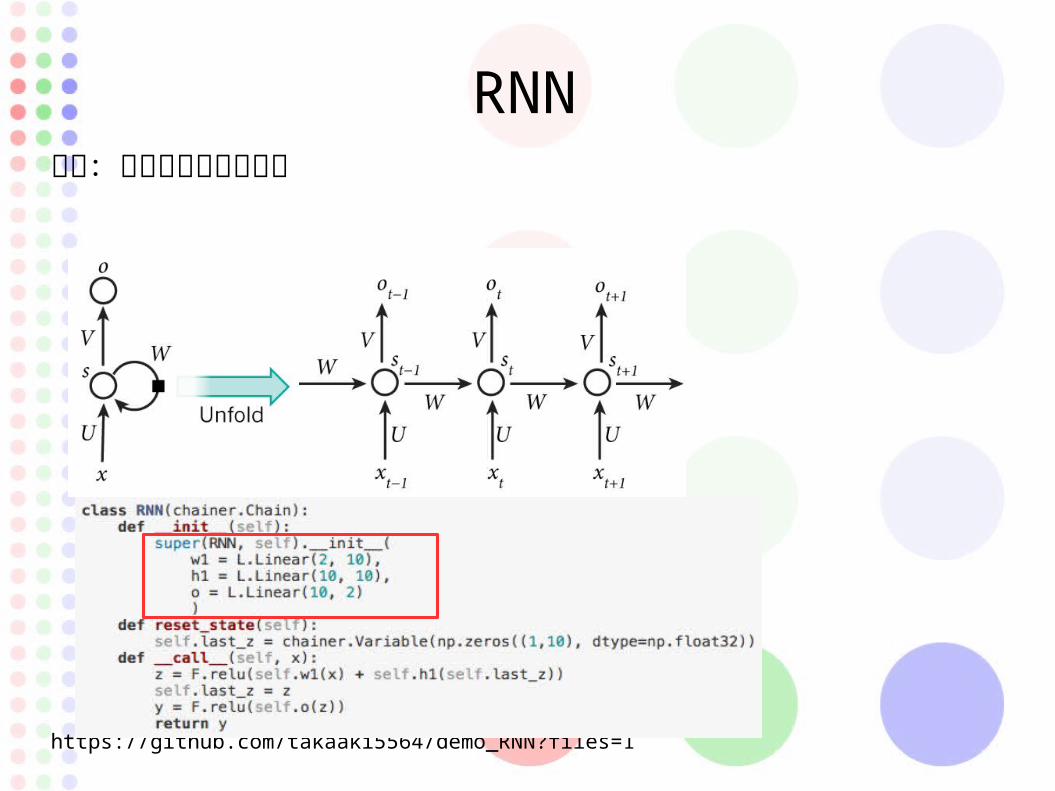
RNN問題:次に来る文字の予想
https://github.com/takaaki5564/demo_RNN?files=1
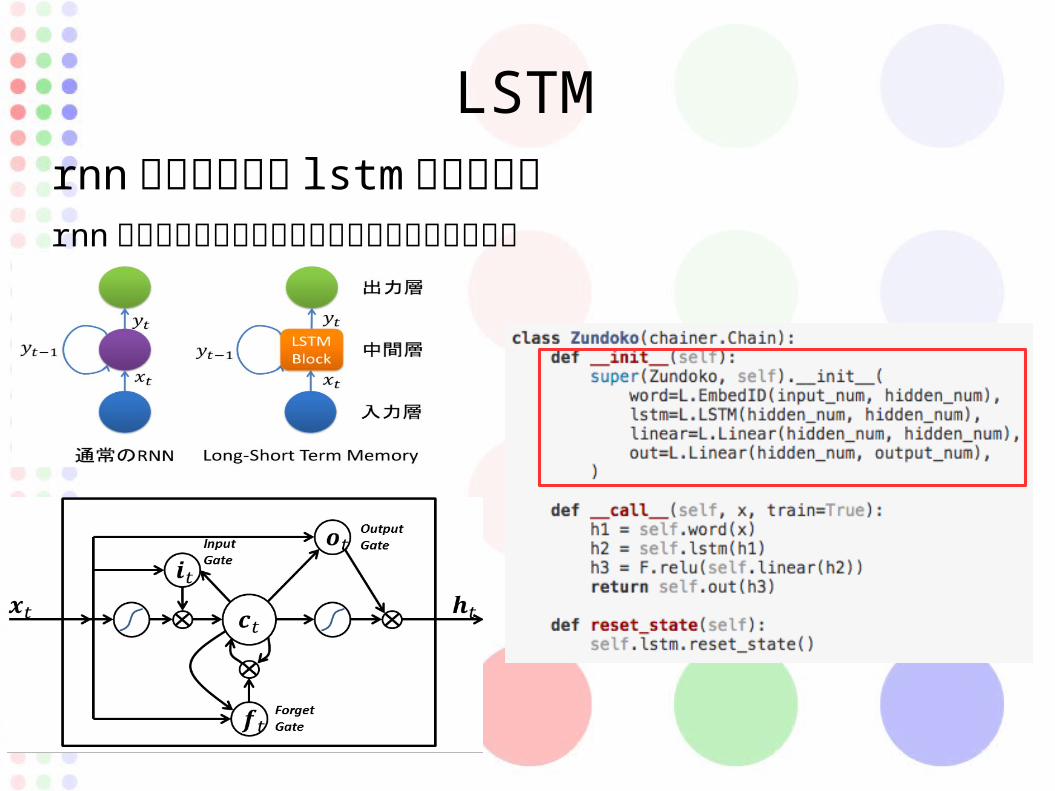
LSTMrnn のブロックを lstm に変更するrnn の多層にしたときの勾配消失爆発の問題を解決
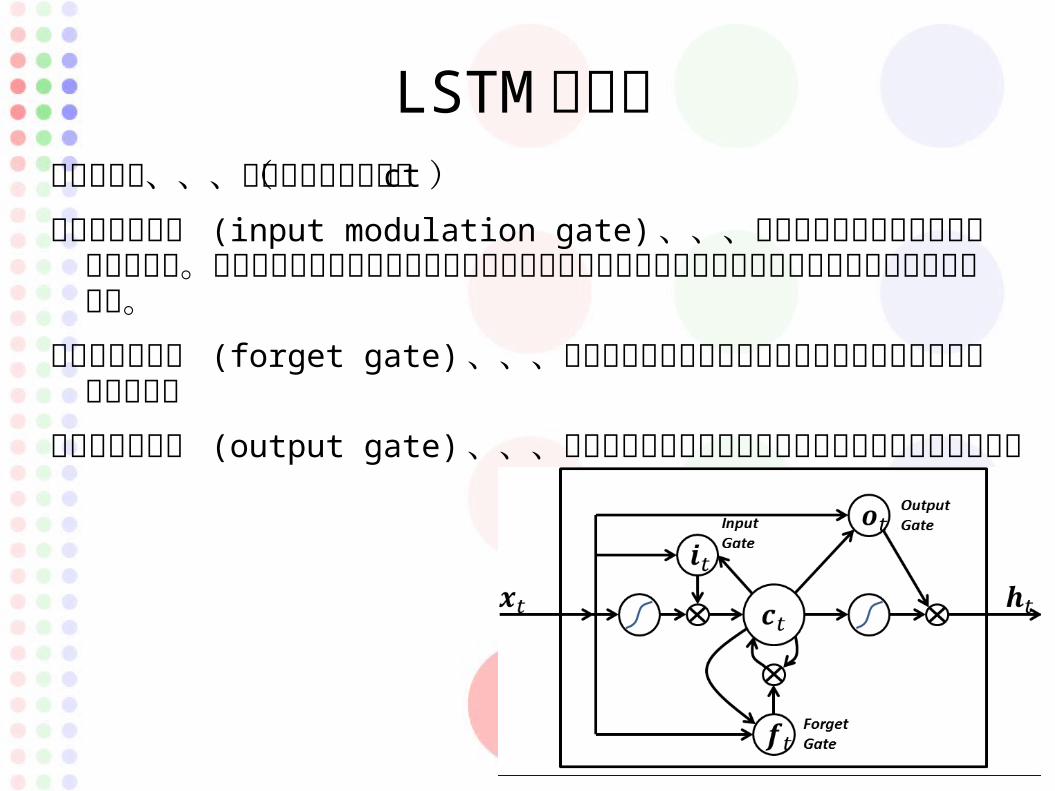
LSTM の機能メモリセル、、、過去の状態を記憶( ct )
入力判断ゲート (input modulation gate) 、、、メモリセルに加算される値を調整する。直近のあまり関係ない情報が影響してメモリセルが持つ重要な情報が消失してしまうのを防ぐ。
忘却判断ゲート (forget gate) 、、、メモリセルの値が次の時刻でどれくらい保持されるかを調整
出力判断ゲート (output gate) 、、、メモリセルの値が次の層にどれだけ影響するかを調整
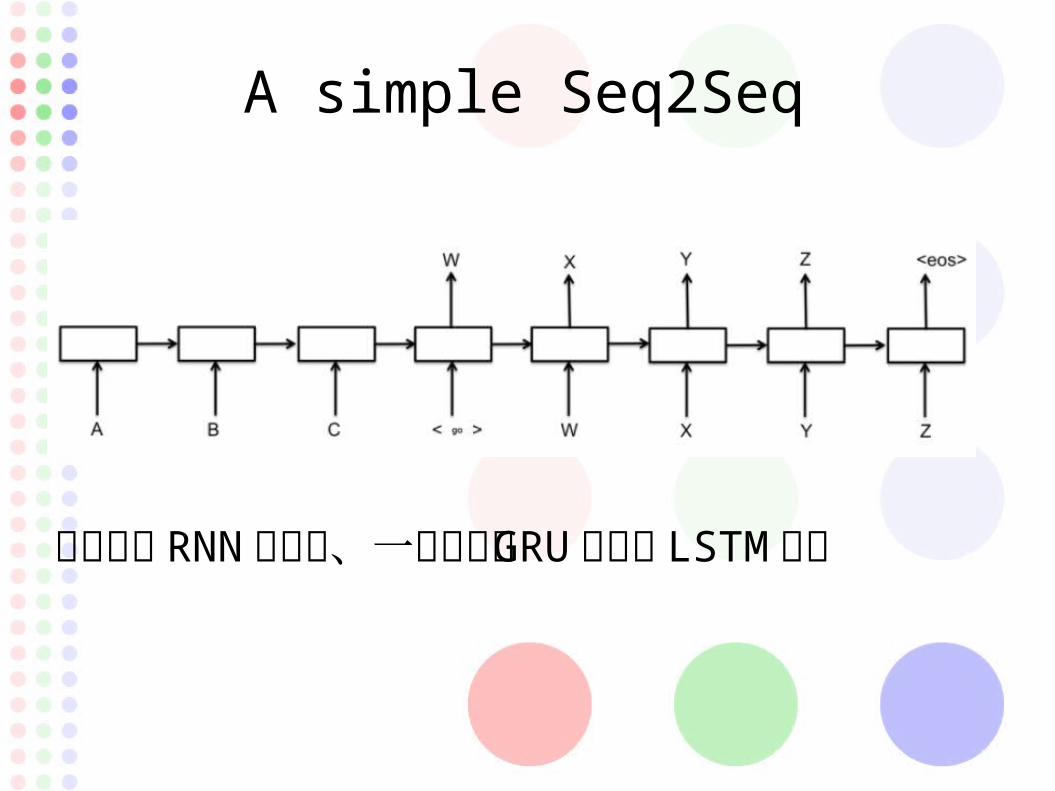
A simple Seq2Seq
各セルが RNN のセル、一般的には GRU セルやLSTM セル
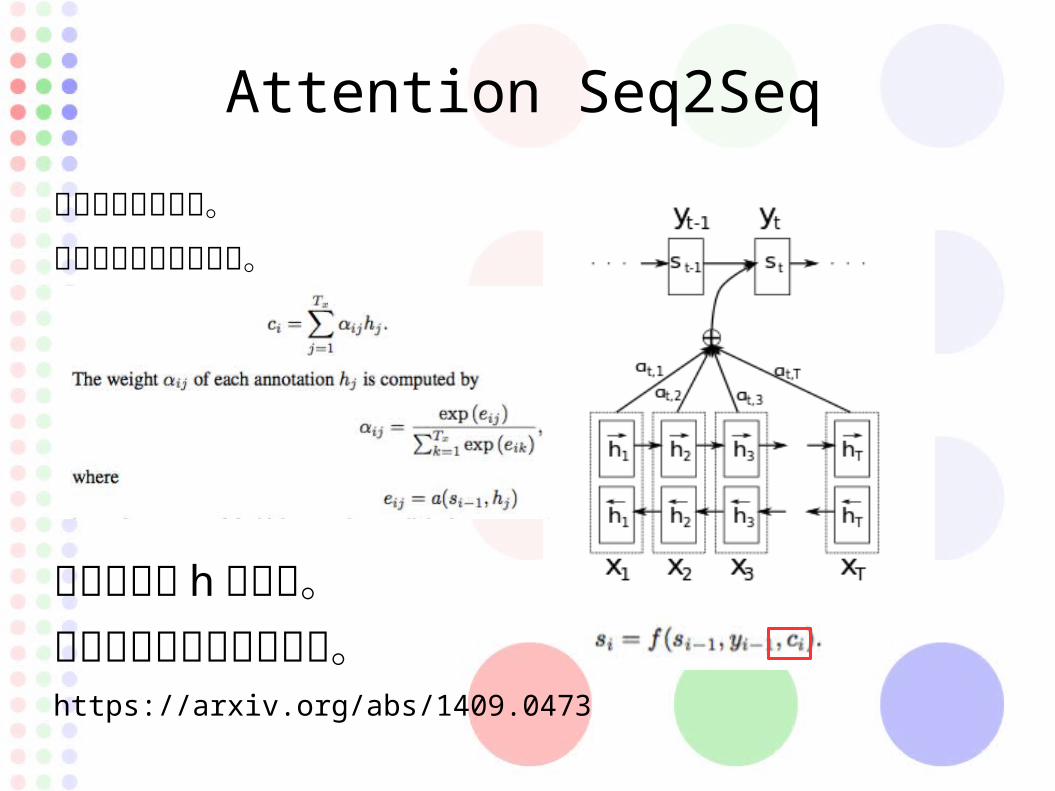
Attention Seq2Seq
長い文字列に対応。
学習回数も減るらしい。
入力文字に h を保持。入力と出力の内積をとる。https://arxiv.org/abs/1409.0473
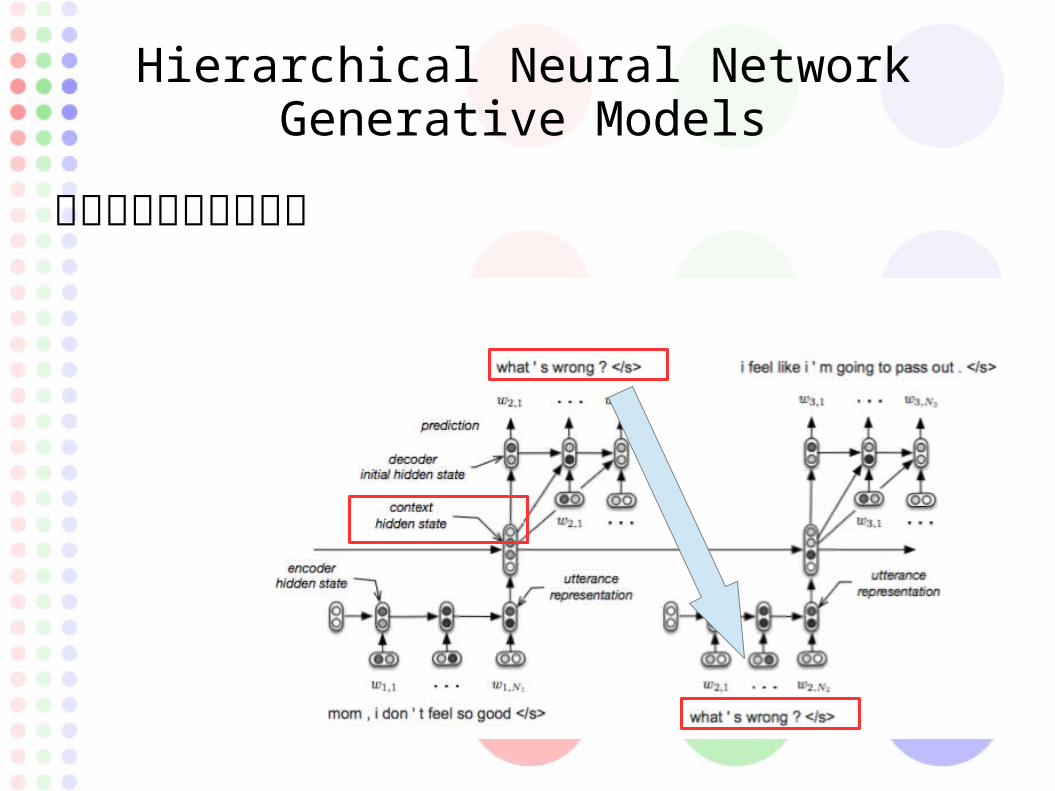
Hierarchical Neural Network Generative Models
映画対話の為のモデル
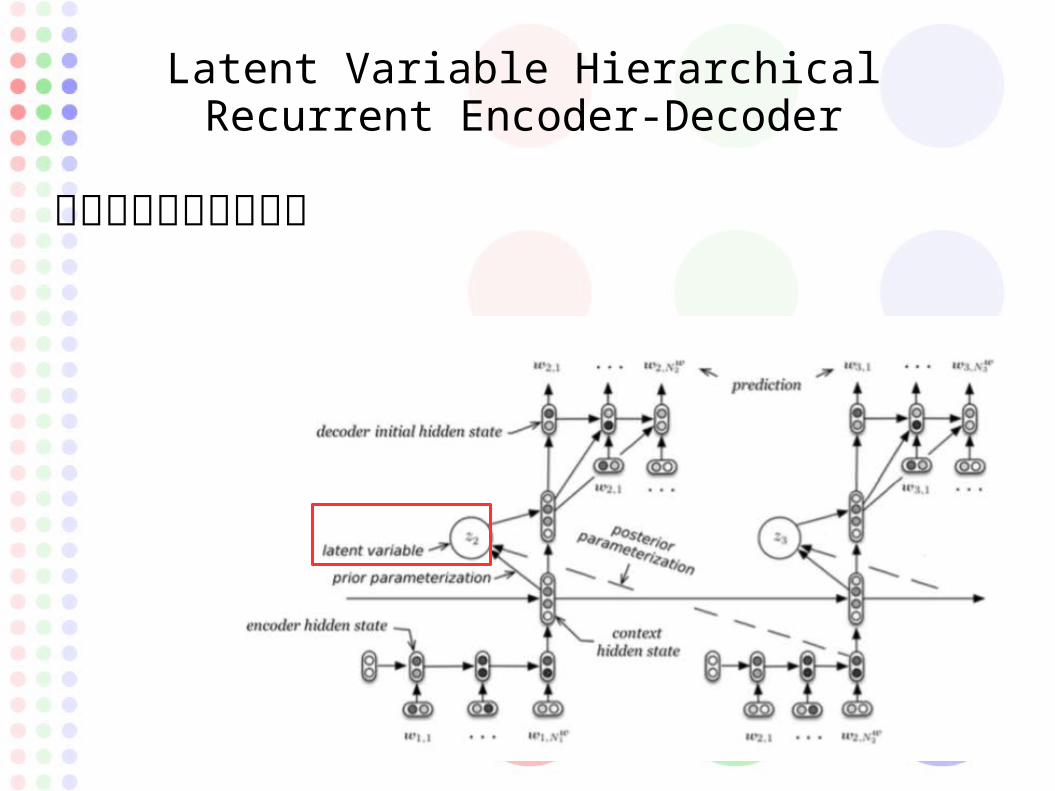
Latent Variable Hierarchical Recurrent Encoder-Decoder
さらに長い文章に対応
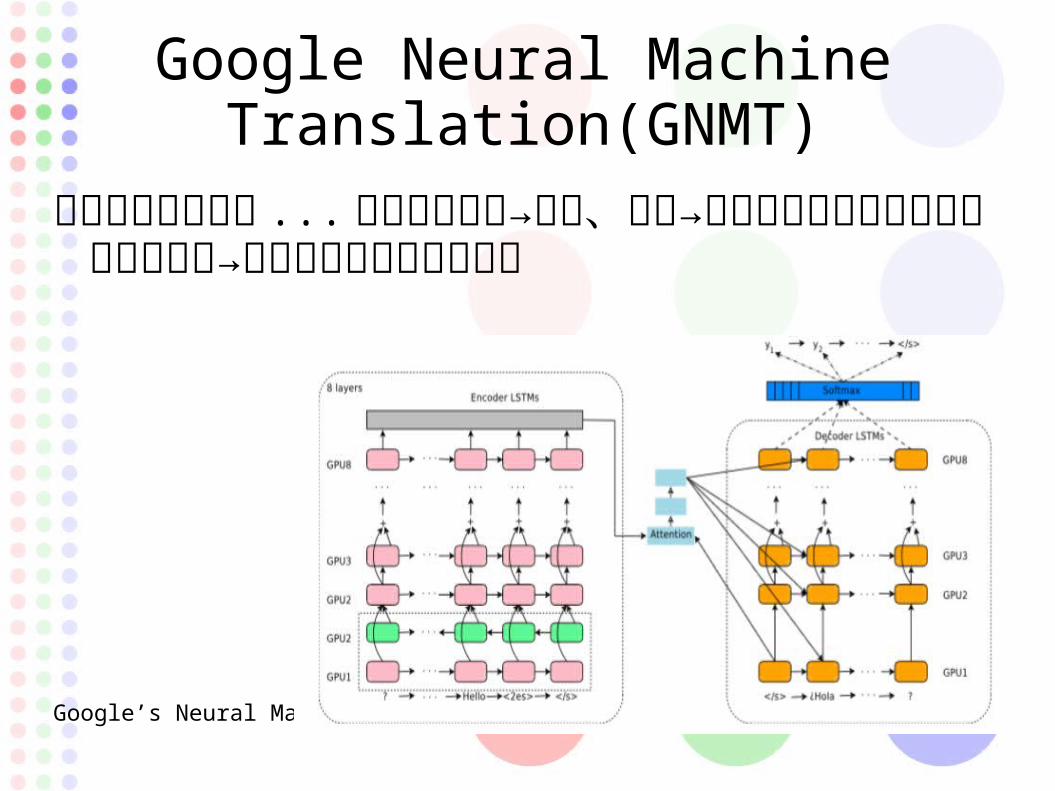
Google Neural Machine Translation(GNMT)
ゼロショット学習 ... ポルトガル語→英語、英語→スペイン語を学習してポルトガル語→スペイン語の翻訳が可能
Google’s Neural Machine Translation System

chainer での実装紹介

Chainer の主なクラス
・ Variable... 変数の値の変化を記録する。
・ Function... ネットワークの管理を行う。
・ Link... ネットワークのパラメータを持つ。
・ Chain...Link をまとめたもの。
・ Optimizer... ネットワークを操作する。
・ Dataset.Iterator... 学習対象を辞書型で指定。 (<1.11.0)
・ Training.Trainer... エポック数などを指定 (<1.11.0)
・ Updater... 最適化手法の指定など。 (<1.11.0)
・ Extension... 途中経過の保存など。 (<1.11.0)
モデル定義
変数の変化を記録
AdaGrad 等
単純な順伝搬での実装の流れ
データの事前処理モデル定義値予想学習モデル保存
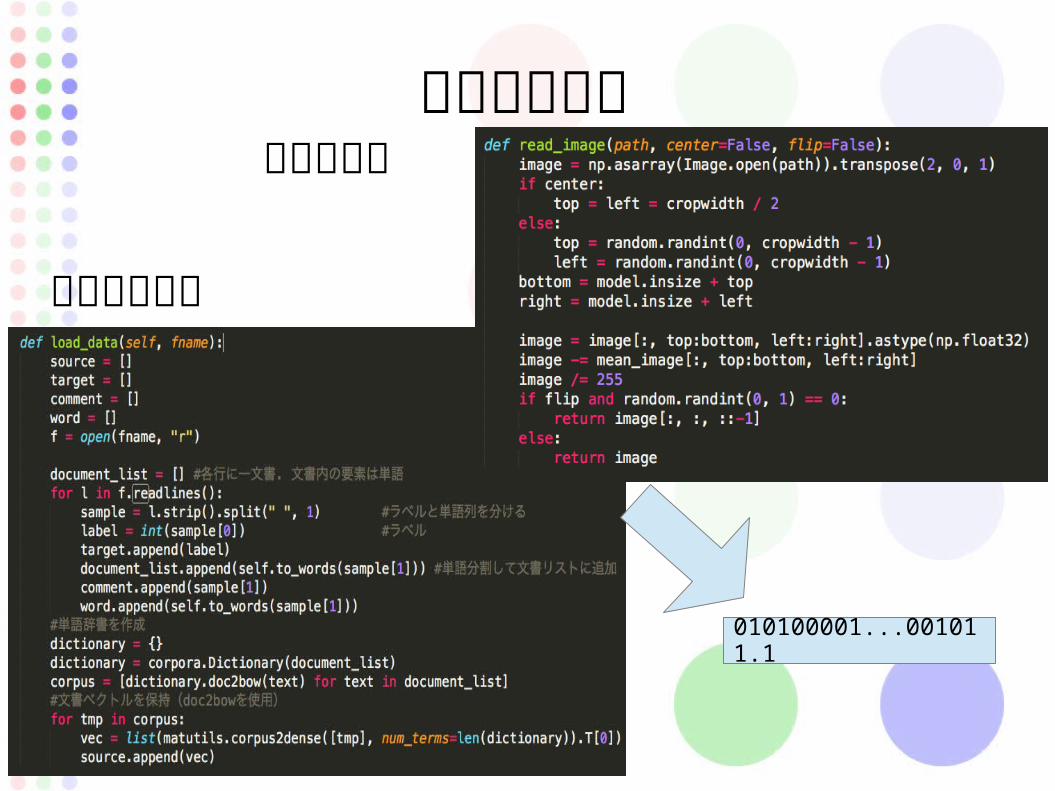
データの用意 画像の場合
文字列の場合
010100001...001011.1
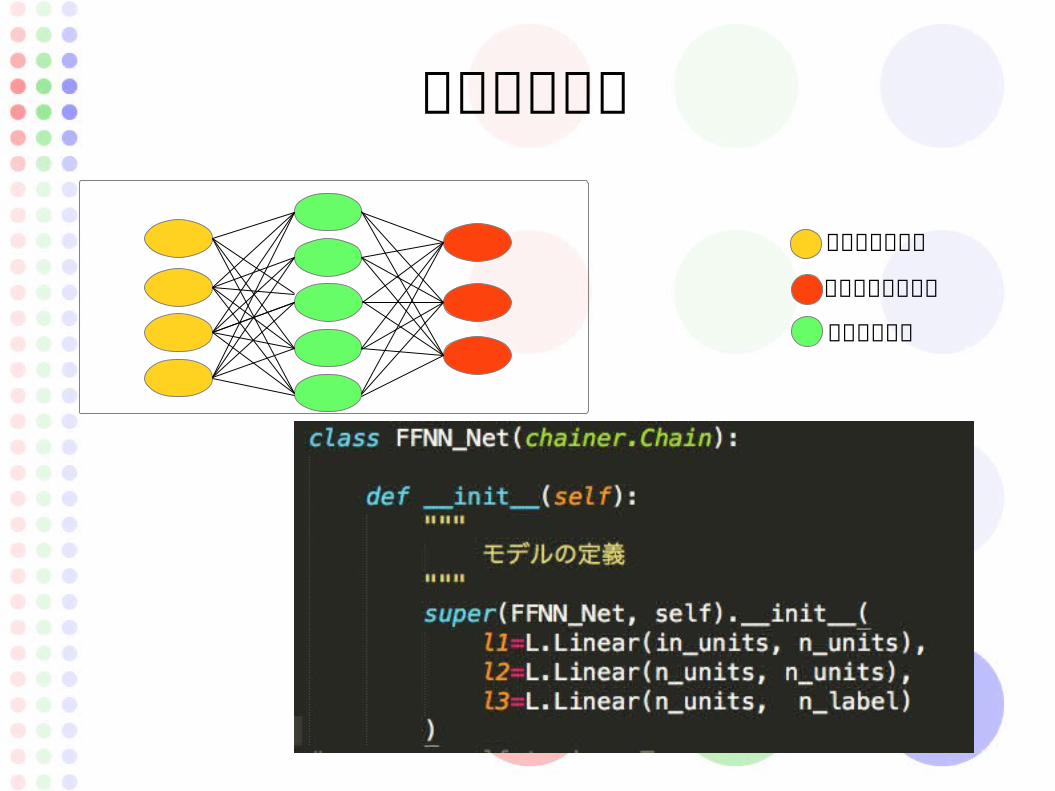
モデルの定義
インプットセル
アウトプットセル
隠れ層のセル
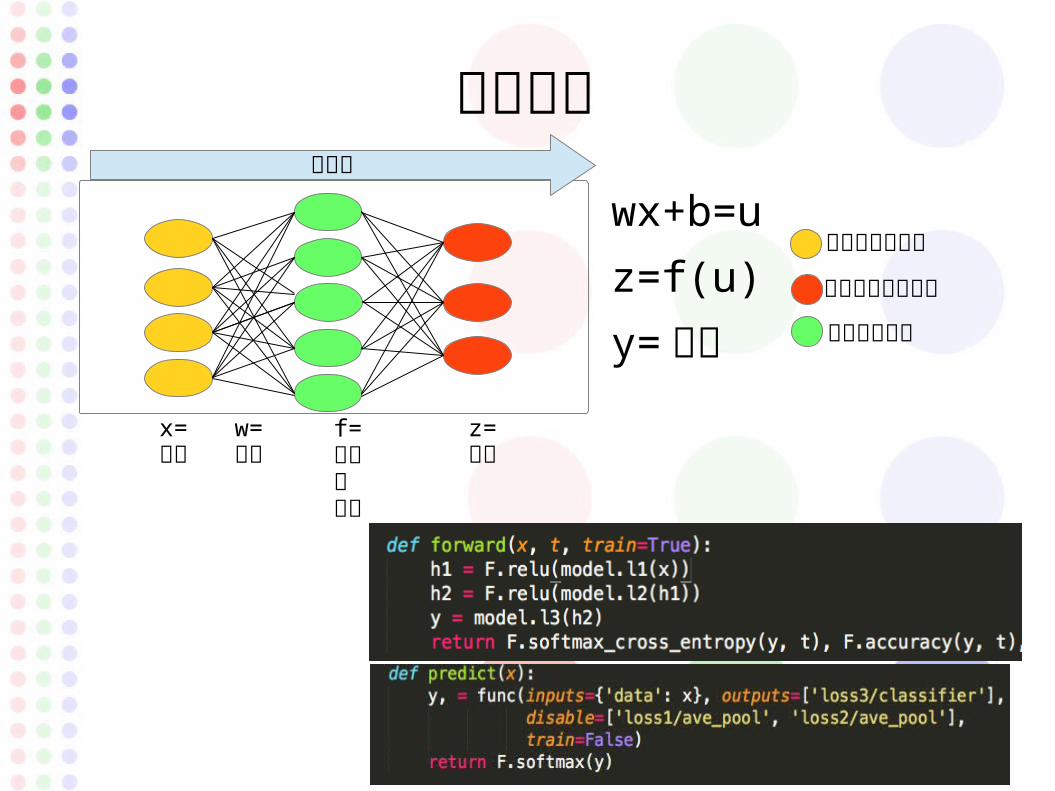
値の予想
wx+b=uz=f(u)y= 正解
インプットセル
アウトプットセル
隠れ層のセル
x=入力
z=出力
w=重み
f=活性化関数
順伝搬
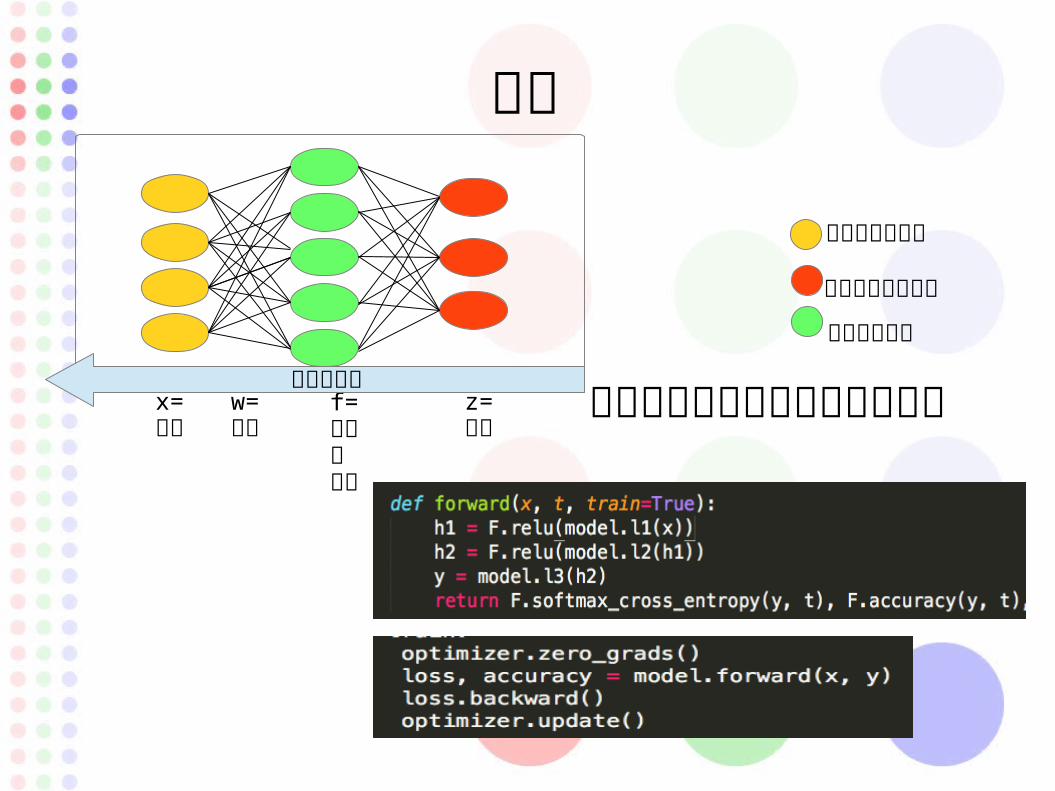
学習
偏微分で勾配を求めて重み更新
インプットセル
アウトプットセル
隠れ層のセル
x=入力
z=出力
w=重み
f=活性化関数
誤差逆伝搬
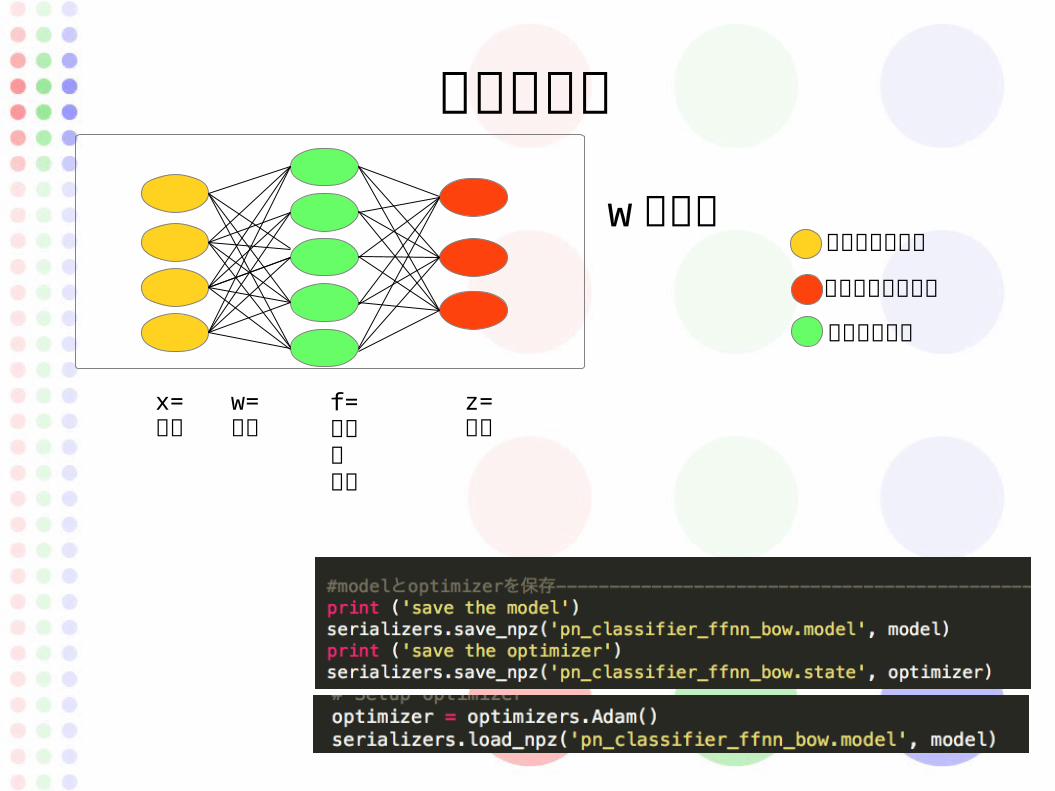
重みの保存
w を保存 インプットセル
アウトプットセル
隠れ層のセル
x=入力
z=出力
w=重み
f=活性化関数
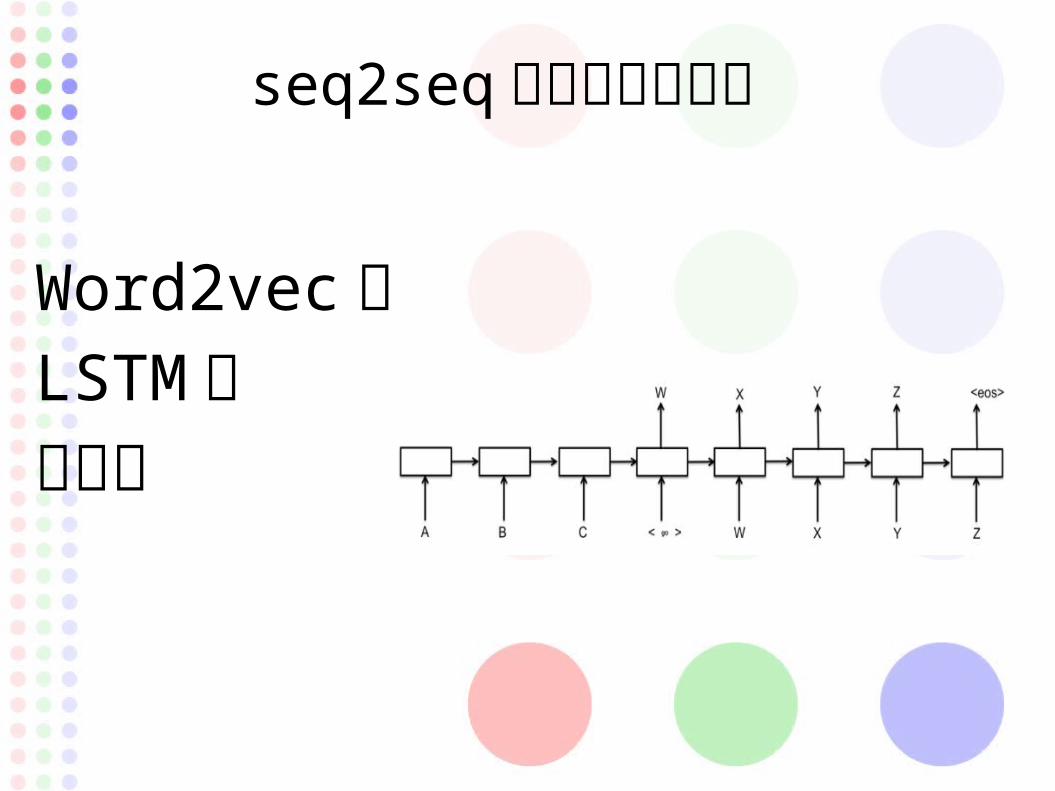
seq2seq の実装について
Word2vec 層LSTM 層出力層
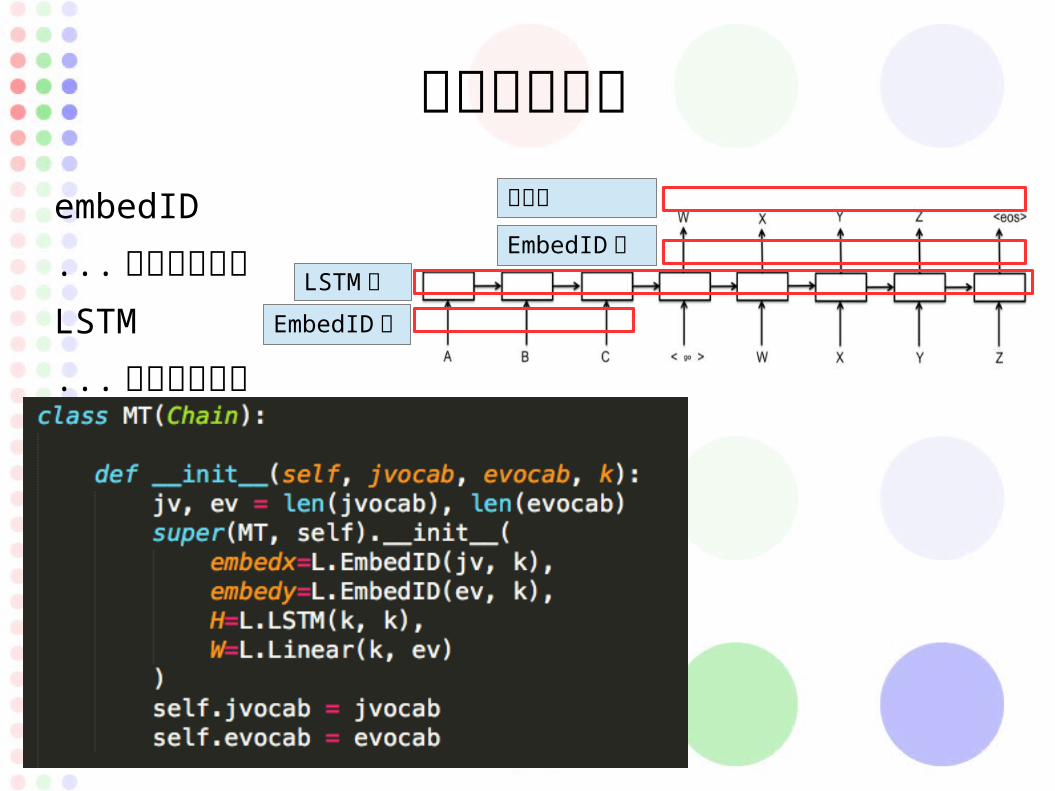
モデルを定義
embedID
... 分散表現の層
LSTM
... 次の文章予想
LSTM 層EmbedID層
EmbedID 層
出力層
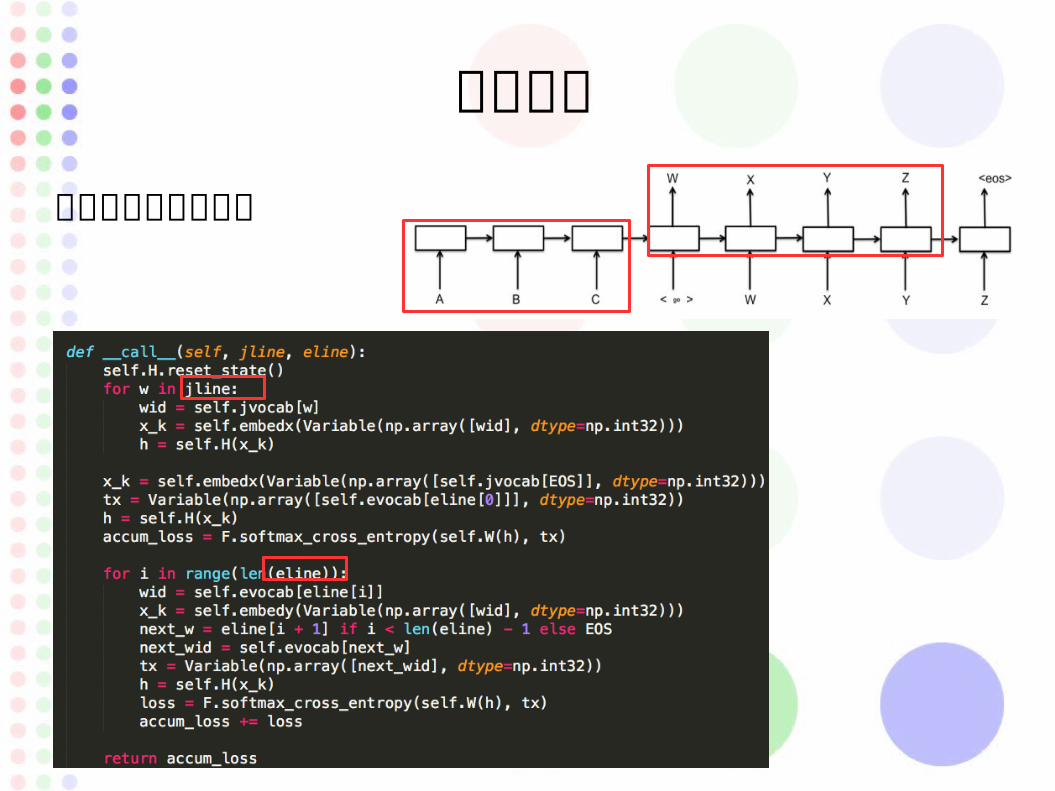
値の予想
原文と目的文を格納
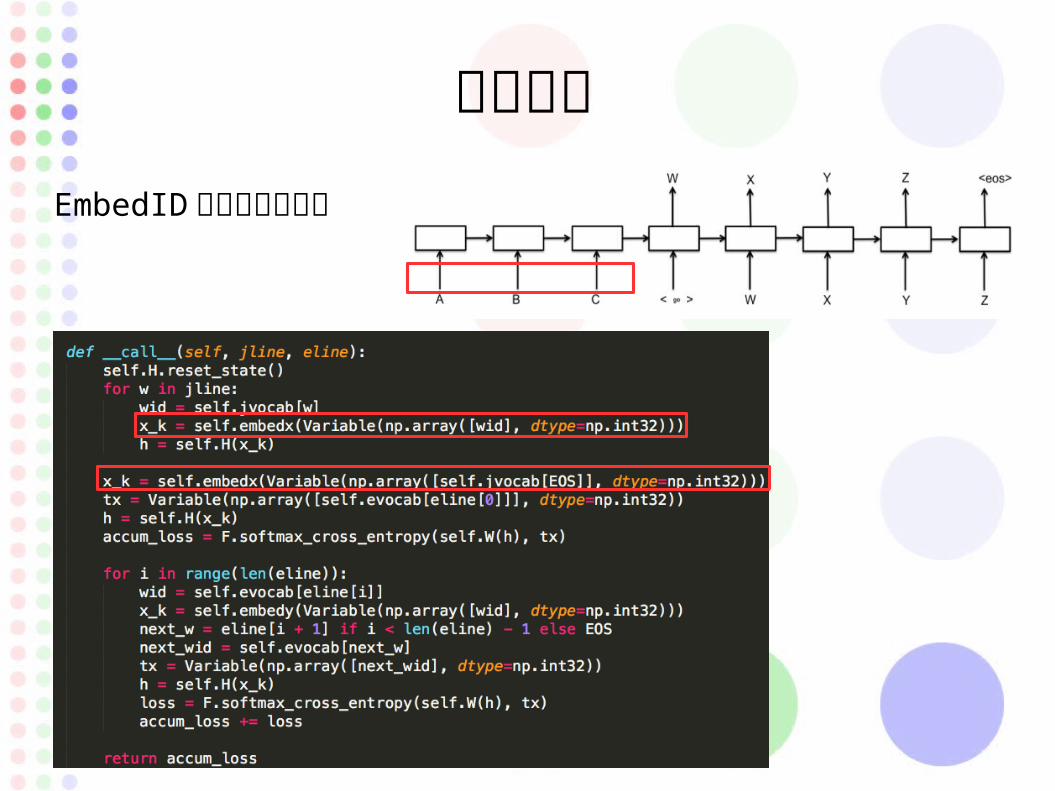
値の予想
EmbedID 層でベクトル化
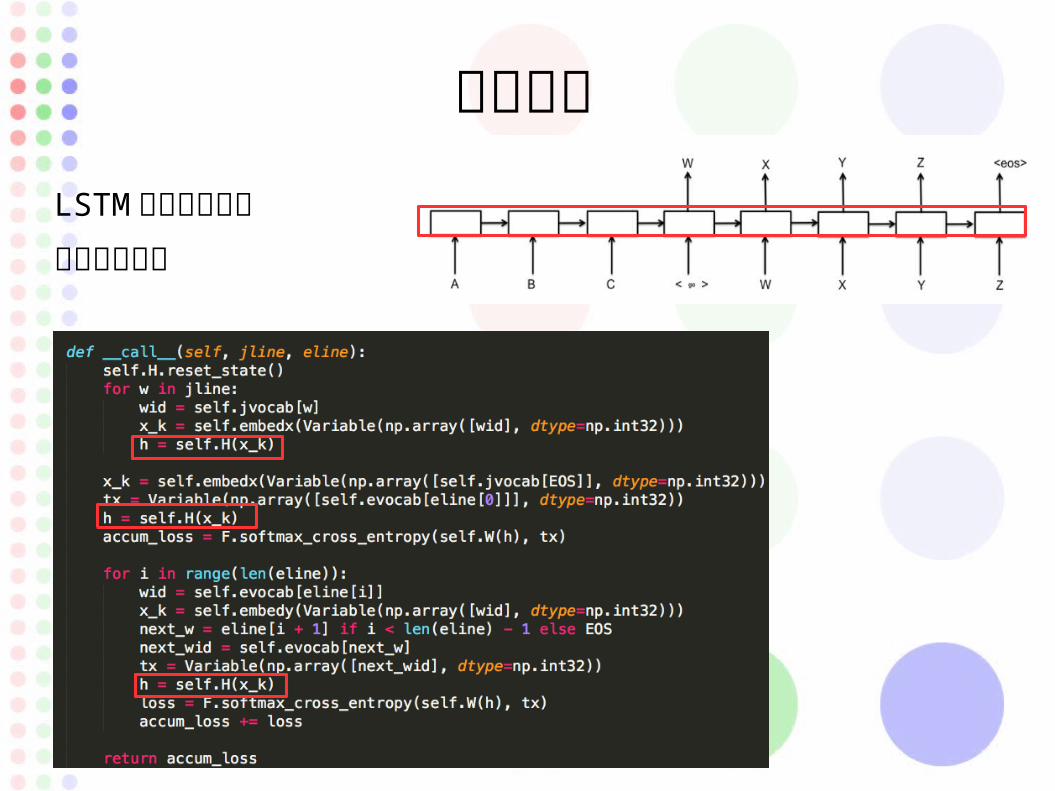
値の予想
LSTM で伝搬させて
次の値を予想
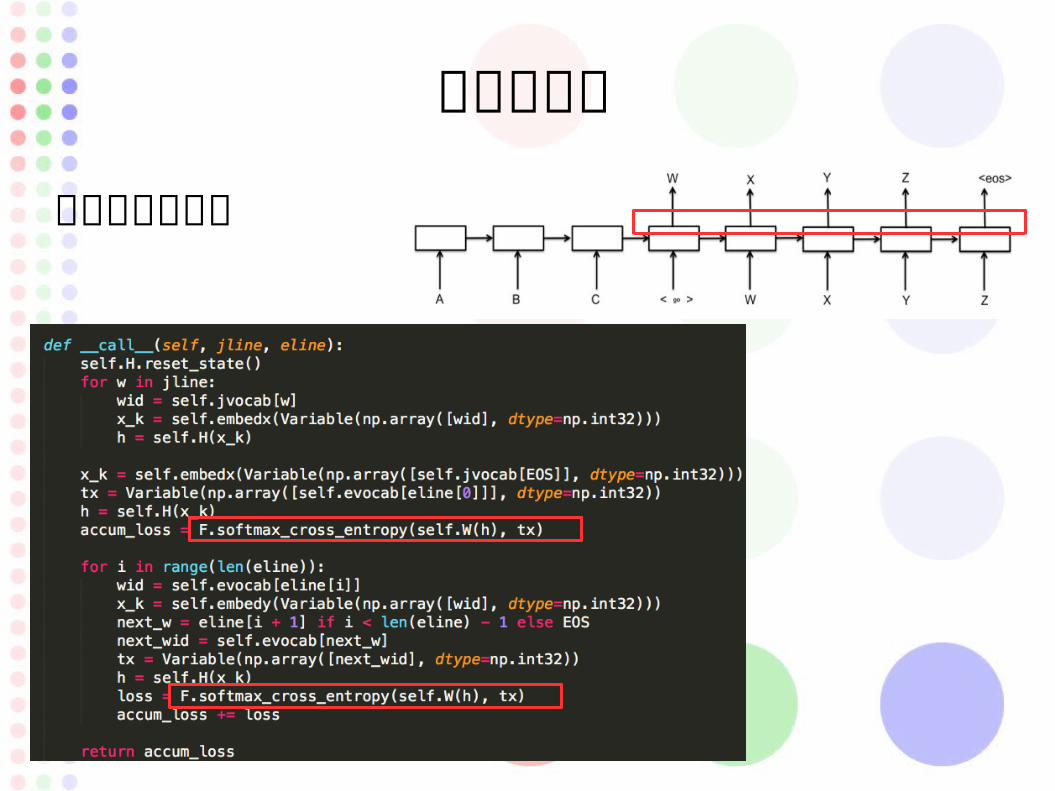
誤差の計算
誤差関数を使う
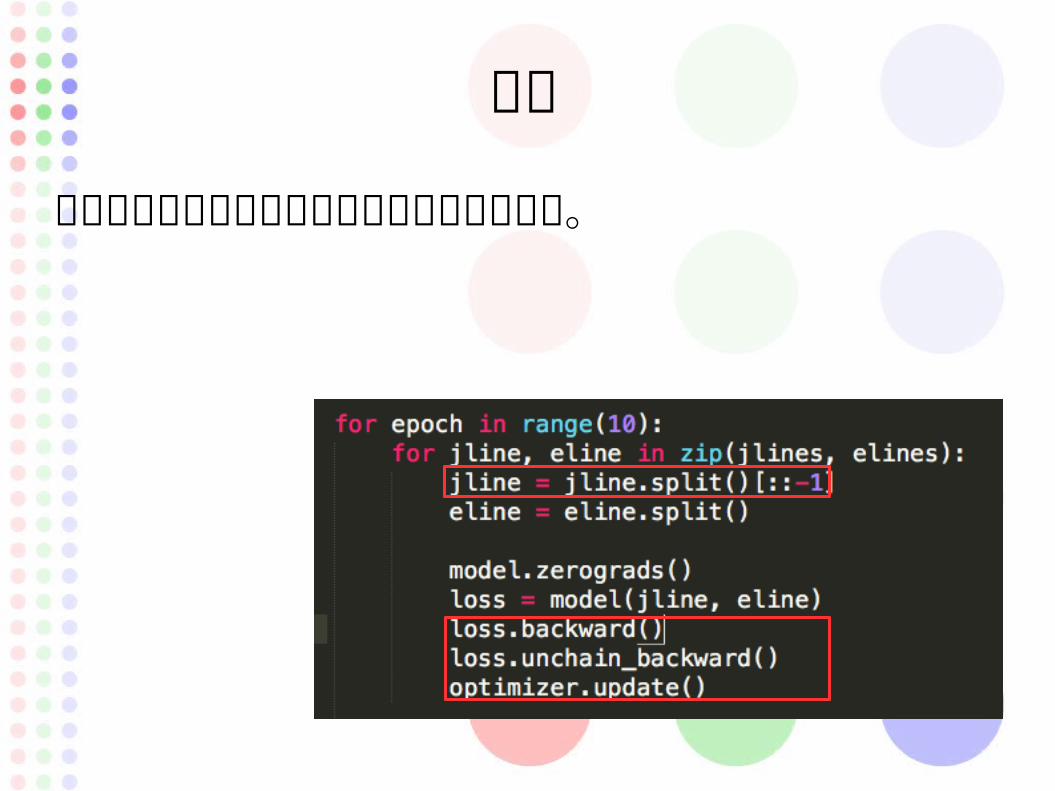
学習
入力値を逆方向に変換して精度をあげている。

データの作り方紹介
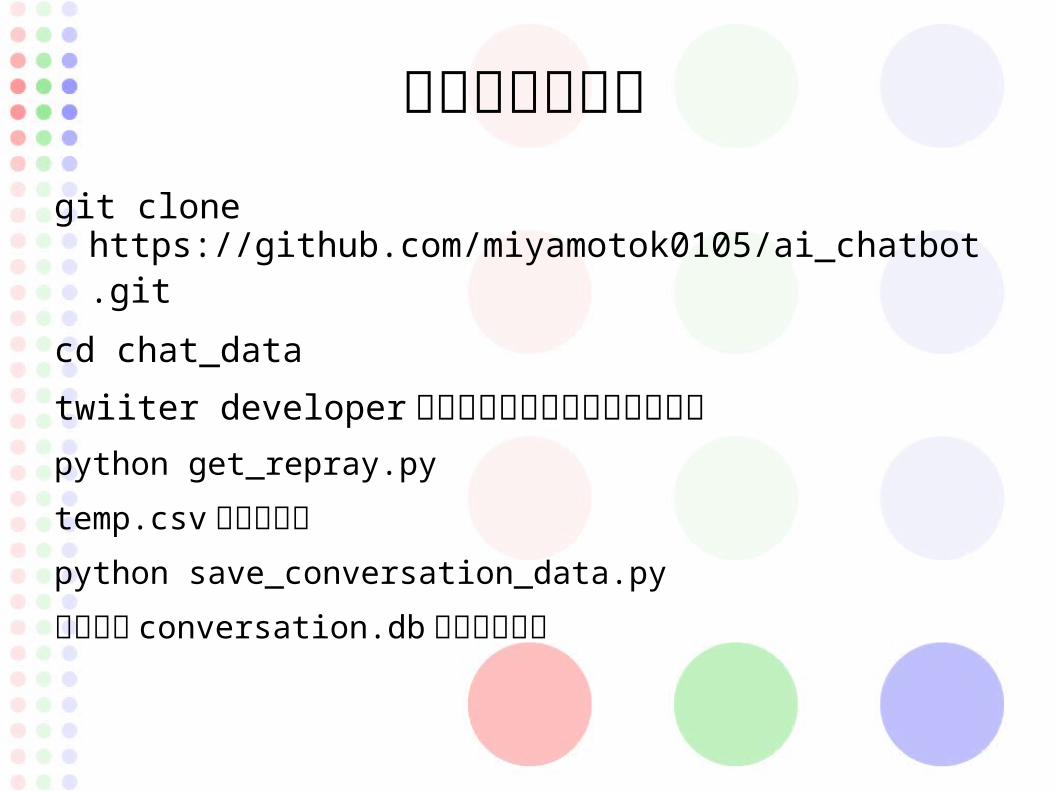
データの集め方
git clone https://github.com/miyamotok0105/ai_chatbot.git cd chat_datatwiiter developer に登録してアクセスキーを取得
python get_repray.pytemp.csvに貼り付け
python save_conversation_data.py対話文が conversation.dbに保存される