Embed Size (px)
Citation preview

Japan.R 2016LT
doradora09

本日のお話1. LDA-Vis パッケージのご紹介2. doradora09 からお知らせ

自己紹介• 大城信晃• @doradora09
• データ分析屋• ヤフー -> DATUM STUDIO
• Tokyo.R のスタッフ (2010 年〜 )• 主に初心者セッションと懇親会
(BAR doradora)

自己紹介• 大城信晃• @doradora09
• データ分析屋• ヤフー -> DATUM STUDIO
• Tokyo.R のスタッフ (2010 年〜 )• 主に初心者セッションと懇親会
(BAR doradora)

1.LDA-Vis パッケージのご紹介

LDA とは• “Latent Dirichlet Allocation” の略• 文書中の単語の「トピック」を確率的に求める言語モデル• 各単語が「隠れトピック」 ( 話題、カテゴリー ) から生成されている、と想定して、そのトピックを文書集合から教師無しで推定することが目的

トピック分類できると何が嬉しいか• ( 大量の ) 文章の要約や分類ができる• 文章の概要把握、効率的な情報収集
• 論点を見つける• 商品のユーザーレビューの解析
• 背景のトピックの発見• りんごの「 apple 」と企業の「 apple 」の区別

例:以下の3つのニュース記事を LDA1. 博多駅前 再び道路7センチほど沈み込む 通行止めに
• 26日未明、福岡市のJR博多駅前の大規模に道路が陥没した現場付近で、再び道路が最大で深さ7センチほど沈んでいるのが見つかり、警察は周辺の交通を規制して、詳しい状態などを調べています。・・・
2. 陥没めど立たぬ休業補償 飲食店など博多駅前事業者 福岡市に問い合わせ50件• 福岡市のJR博多駅前の道路陥没事故で休業を余儀なくされた飲食店などの事業者から損失補償に関する問い合わせが市に相次ぎ、11日までに50件を超えた。・・・
3. 陥没周辺の建物は? 福岡市「倒壊の恐れなし」 専門家「地震の揺れに注意を」• 陥没事故の周辺では、建物の倒壊など二次被害も懸念された。福岡市は8日、陥没箇所を中心に東西約400メートル、南北約150メートルにある42棟で応急危険度判定を実施。・・・

例:以下の3つのニュース記事を LDA1. 博多駅前 再び道路7センチほど沈み込む 通行止めに
• 26日未明、福岡市のJR博多駅前の大規模に道路が陥没した現場付近で、再び道路が最大で深さ7センチほど沈んでいるのが見つかり、警察は周辺の交通を規制して、詳しい状態などを調べています。・・・
2. 陥没めど立たぬ休業補償 飲食店など博多駅前事業者 福岡市に問い合わせ50件• 福岡市のJR博多駅前の道路陥没事故で休業を余儀なくされた飲食店などの事業者から損失補償に関する問い合わせが市に相次ぎ、11日までに50件を超えた。・・・
3. 陥没周辺の建物は? 福岡市「倒壊の恐れなし」 専門家「地震の揺れに注意を」• 陥没事故の周辺では、建物の倒壊など二次被害も懸念された。福岡市は8日、陥没箇所を中心に東西約400メートル、南北約150メートルにある42棟で応急危険度判定を実施。・・・
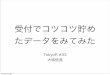
今回用いるパッケージ• RMeCab : 日本語の形態素解析• lda : LDA の実行• LDAvis : LDAをいい感じに可視化
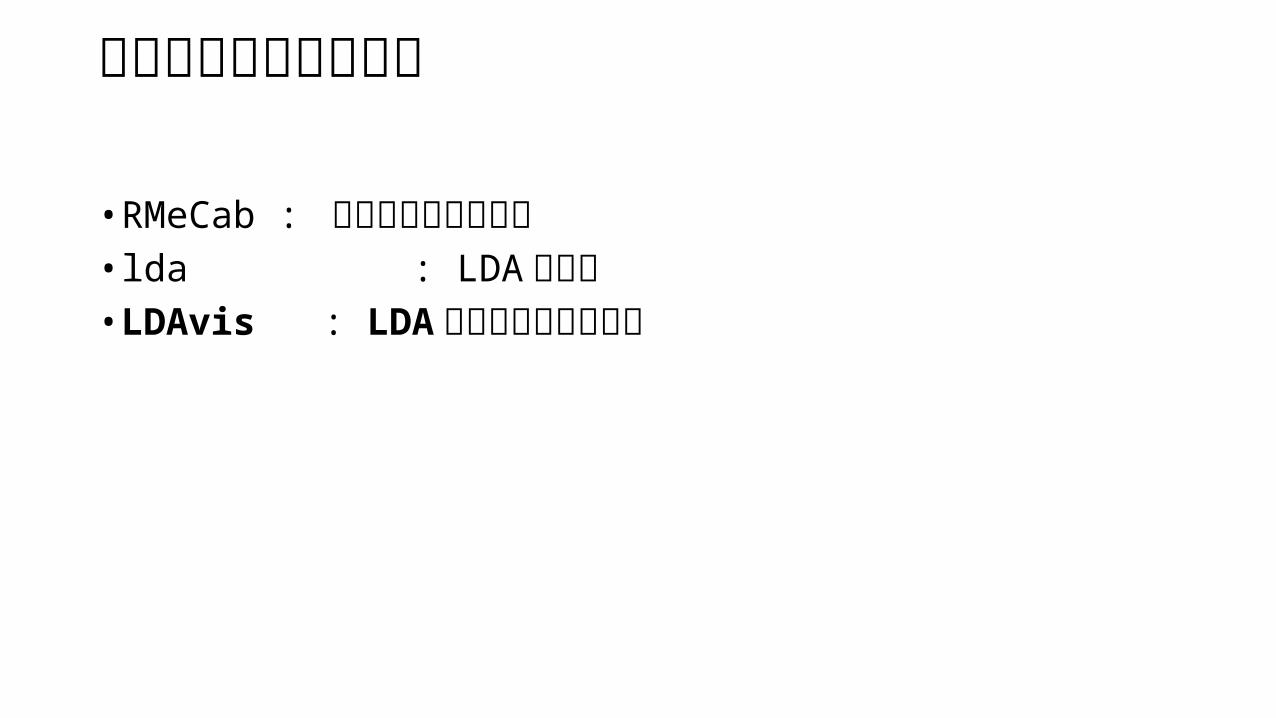
RMeCab• RMeCab を使って名詞、形容詞のみに限定
setwd('/Users/apple/Desktop/ldavis_lt')
library(RMeCab)
tmp_doc.1 <- NULLtmp_doc.1 <- RMeCabText("text_1.txt")doc.1 <- NULLfor (i in 1:length(tmp_doc.1)) { if (tmp_doc.1[[i]][2] %in% c("名詞 ", "形容詞 ")) { doc.1 <- c(doc.1, paste(tmp_doc.1[[i]][1], sep = "", collapse = " ")) }}
> head(doc.1)[1] " 博多 " " 駅 " " 前 " " 道路 " " 7 " " センチ "
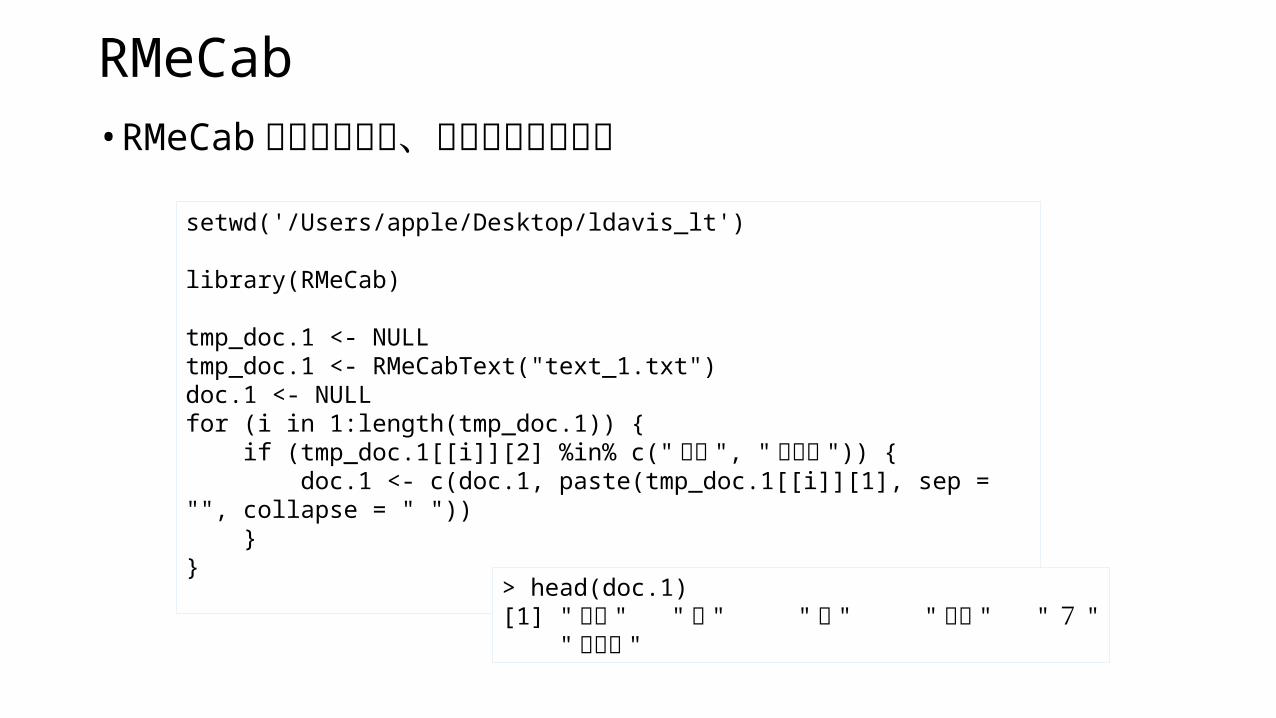
LDA準備• 単語をカウント
# 他の 2 記事も doc.2, doc.2 として同様に読み込む (省略 )
#複数文章をリスト化doc.list <- NULLdoc.list <- list(doc.1, doc.2, doc.3)names(doc.list) <- c("doc1", "doc2", "doc3")
library(lda)# ターム行列作成 ( 単語ごとにカウント )term.table <- table(unlist(doc.list))term.table <- sort(term.table, decreasing = TRUE)
# 単語一覧vocab <- NULLvocab <- names(term.table)
> head(term.table) > 市 陥没 補償 1 道路 福岡 > 22 14 13 11 11 11

LDA準備• 文章がどの単語に一致するかで index化
get.terms <- function(x) { index <- match(x, vocab) index <- index[!is.na(index)] rbind(as.integer(index - 1), as.integer(rep(1, length(index))))}documents <- NULLdocuments <- lapply(doc.list, get.terms)> head(documents)
>$doc1> [,1] [,2] [,3] [,4] [,5] >[1,] 17 46 231 4 42 >[2,] 1 1 1 1 1

LDA準備• LDA用の各種パラメータの準備
D <- length(documents) # 記事の数W <- length(vocab) # 単語の数doc.length <- sapply(documents, function(x) sum(x[2, ])) # 記事ごとの単語数N <- sum(doc.length) # トータルの単語数term.frequency <- as.integer(term.table)
K <- 10 ## トピック数G <- 200 ## 反復回数alpha <- 0.02 #α パラメータeta <- 0.02 #η パラメータ
トピック数は試行錯誤しながら調整
LDA実行• LDA の実施とトピックの単語確認
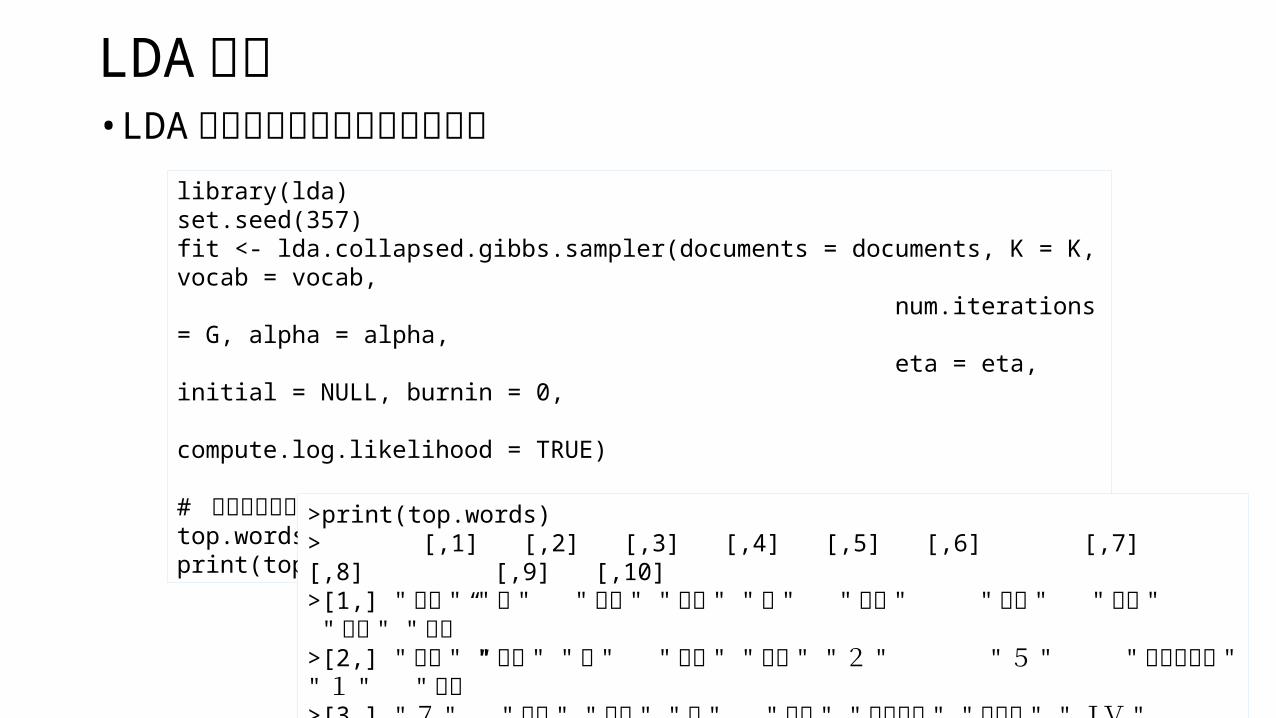
library(lda)set.seed(357)fit <- lda.collapsed.gibbs.sampler(documents = documents, K = K, vocab = vocab, num.iterations = G, alpha = alpha, eta = eta, initial = NULL, burnin = 0, compute.log.likelihood = TRUE)
# 各トピックにおける上位 3位の単語の行列。top.words <- top.topic.words(fit$topics, 3, by.score = TRUE)print(top.words)
>print(top.words) > [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] >[1,] " 規模 " " 市 " " 補償 " " くい " "棟 " " こと " " 福岡 " " 事業 " " 陥没" " 現場”>[2,] " 警察 " " 事故 " " 者 " "危険 " " 倒壊 " " 2 " " 5 " " 問い合わせ " " 1 " " 道路”>[3,] " 7 " "工事 " " 損失 " "力 " " 福岡 " "メートル " " 詳しい " " JV " " 4" " 付近 "
LDA実行• LDA の実施とトピックの単語確認
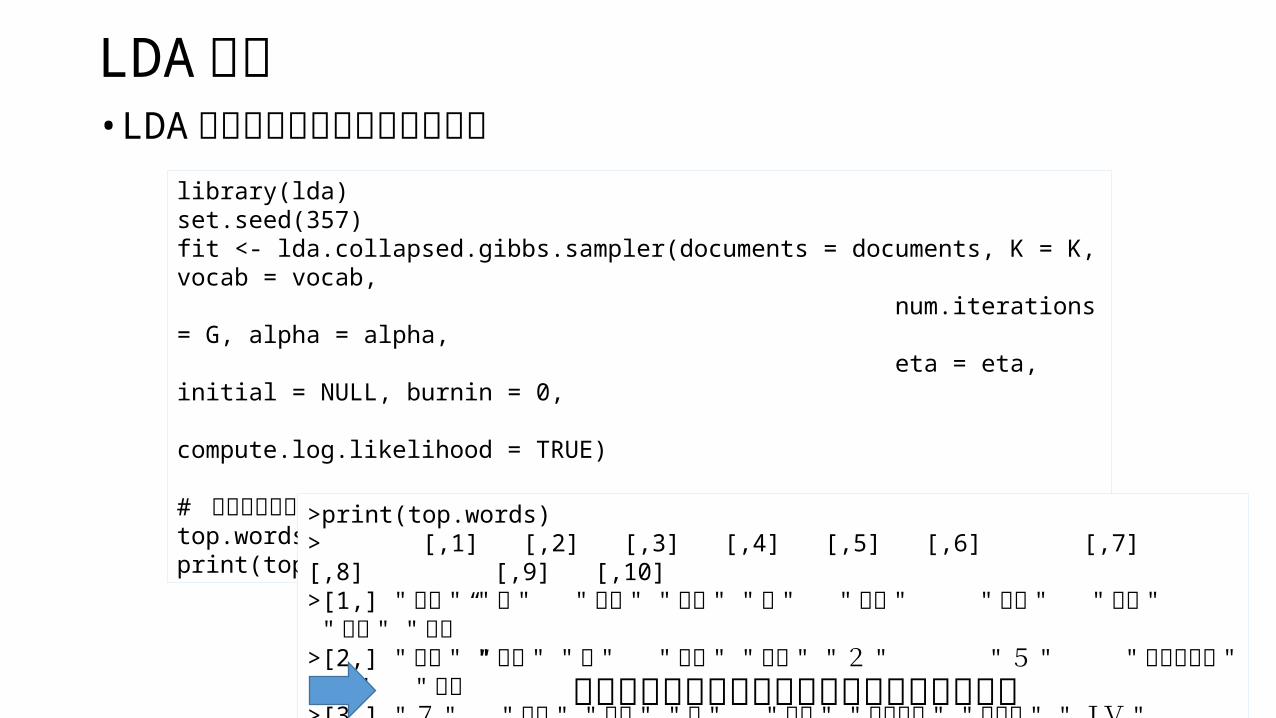
library(lda)set.seed(357)fit <- lda.collapsed.gibbs.sampler(documents = documents, K = K, vocab = vocab, num.iterations = G, alpha = alpha, eta = eta, initial = NULL, burnin = 0, compute.log.likelihood = TRUE)
# 各トピックにおける上位 3位の単語の行列。top.words <- top.topic.words(fit$topics, 3, by.score = TRUE)print(top.words)
>print(top.words) > [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] >[1,] " 規模 " " 市 " " 補償 " " くい " "棟 " " こと " " 福岡 " " 事業 " " 陥没" " 現場”>[2,] " 警察 " " 事故 " " 者 " "危険 " " 倒壊 " " 2 " " 5 " " 問い合わせ " " 1 " " 道路”>[3,] " 7 " "工事 " " 損失 " "力 " " 福岡 " "メートル " " 詳しい " " JV " " 4" " 付近 "この状態だとよく分からないので可視化する
LDA-Vis• パラメータ設定と実行
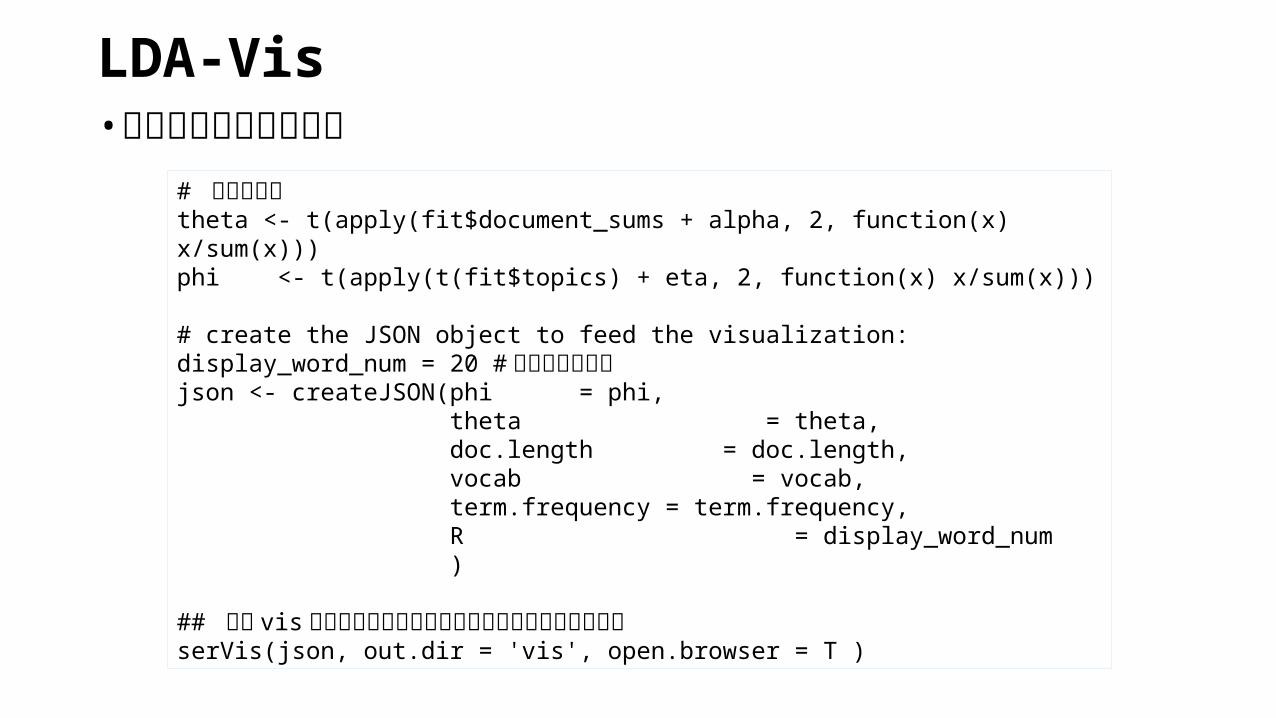
# パラメータtheta <- t(apply(fit$document_sums + alpha, 2, function(x) x/sum(x)))phi <- t(apply(t(fit$topics) + eta, 2, function(x) x/sum(x)))
# create the JSON object to feed the visualization:display_word_num = 20 #表示する単語数json <- createJSON(phi = phi, theta = theta, doc.length = doc.length, vocab = vocab, term.frequency = term.frequency, R = display_word_num )
## 古い vis フォルダがある場合はエラー出るので削除する事serVis(json, out.dir = 'vis', open.browser = T )

デモ
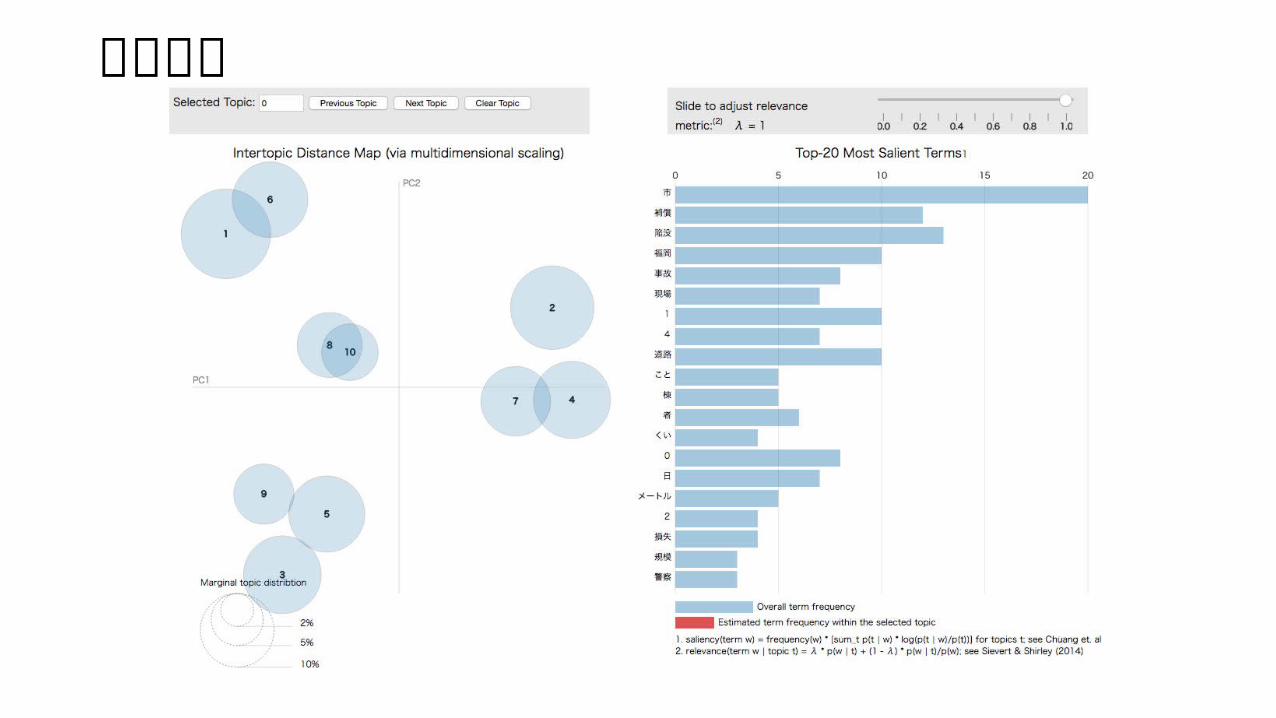
実行結果
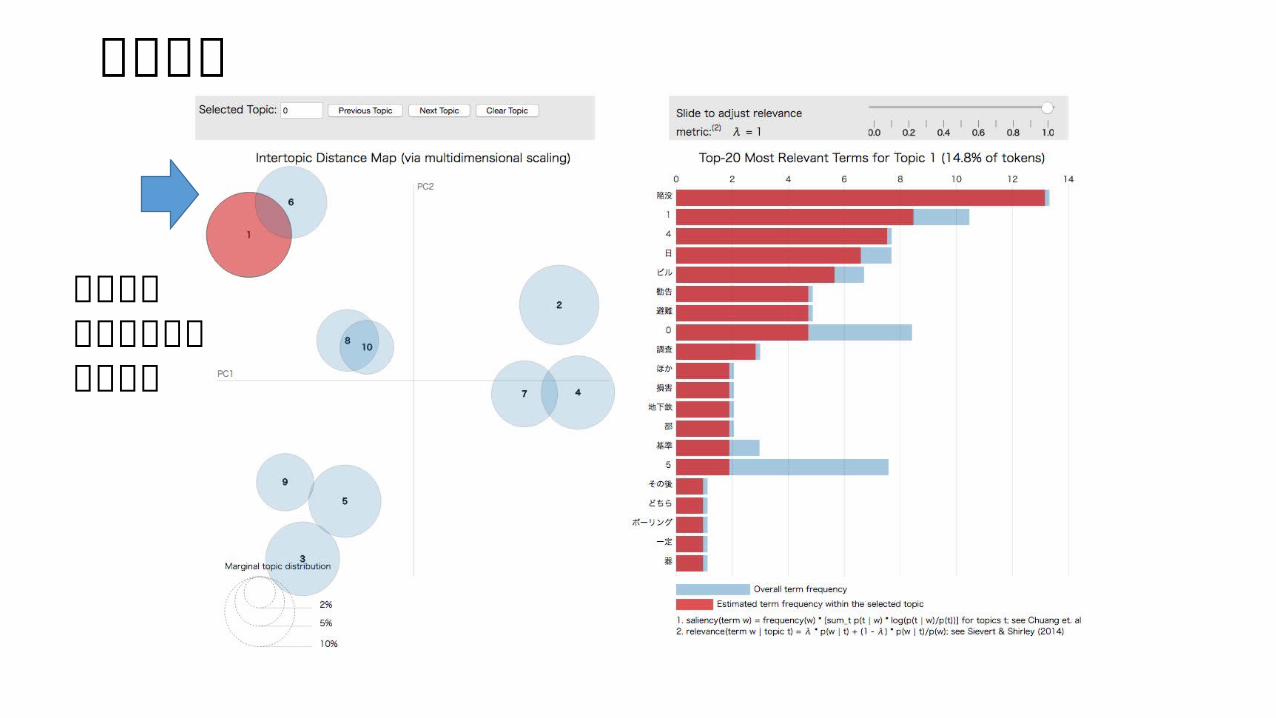
実行結果
陥没への保証に関するトピック
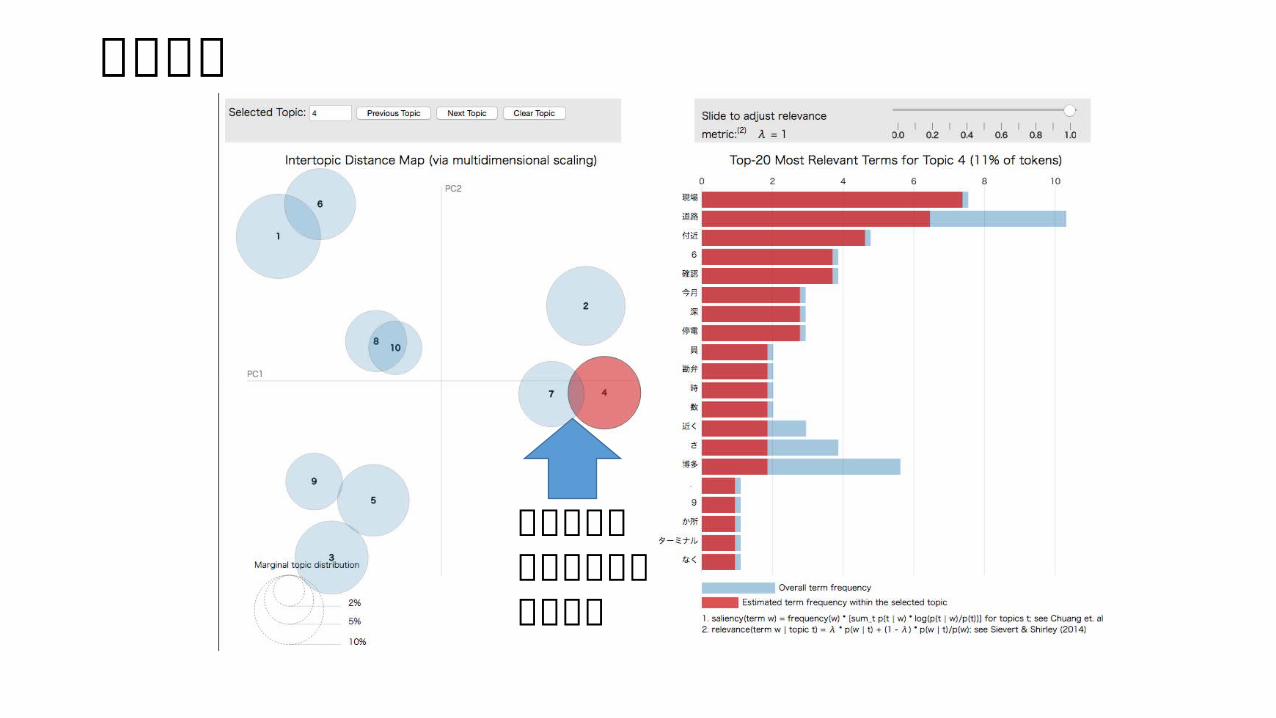
実行結果
現場状況や停電に関するトピック
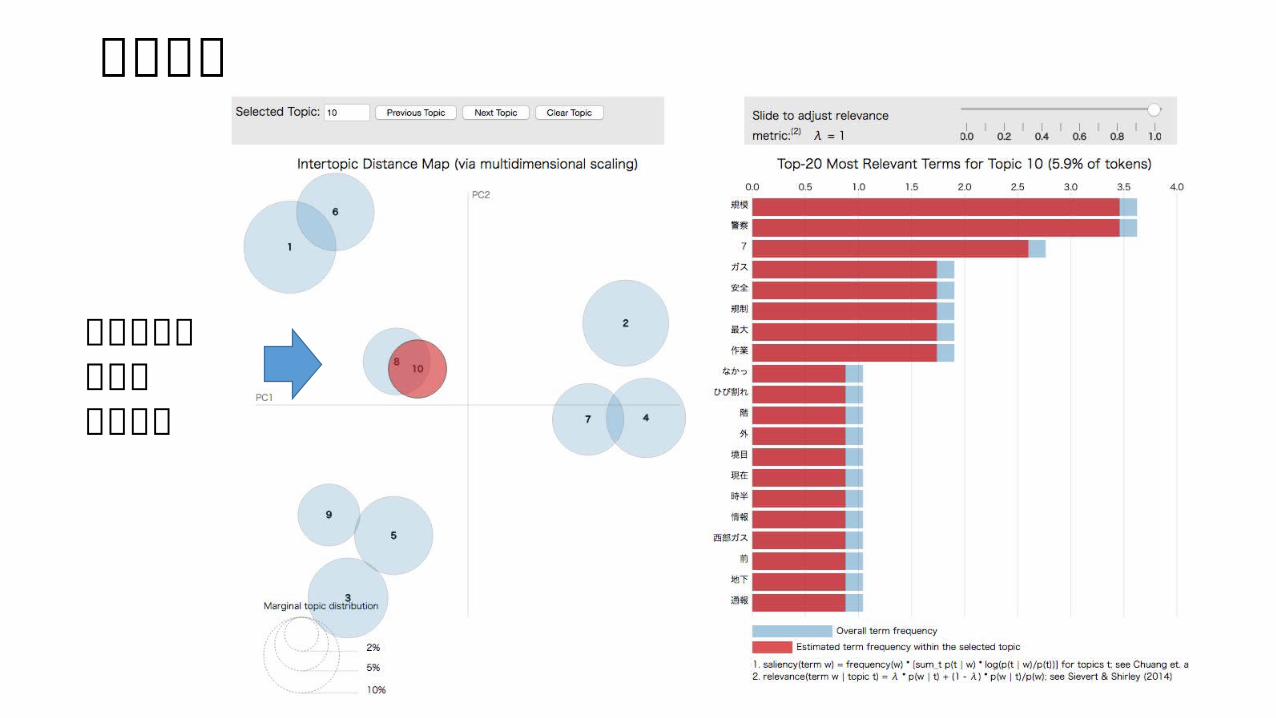
実行結果
警察による規制のトピック

LDA-Vis 所感• LDA実行の状態から一手間加えるだけで使えて便利!•探索的な発見に期待
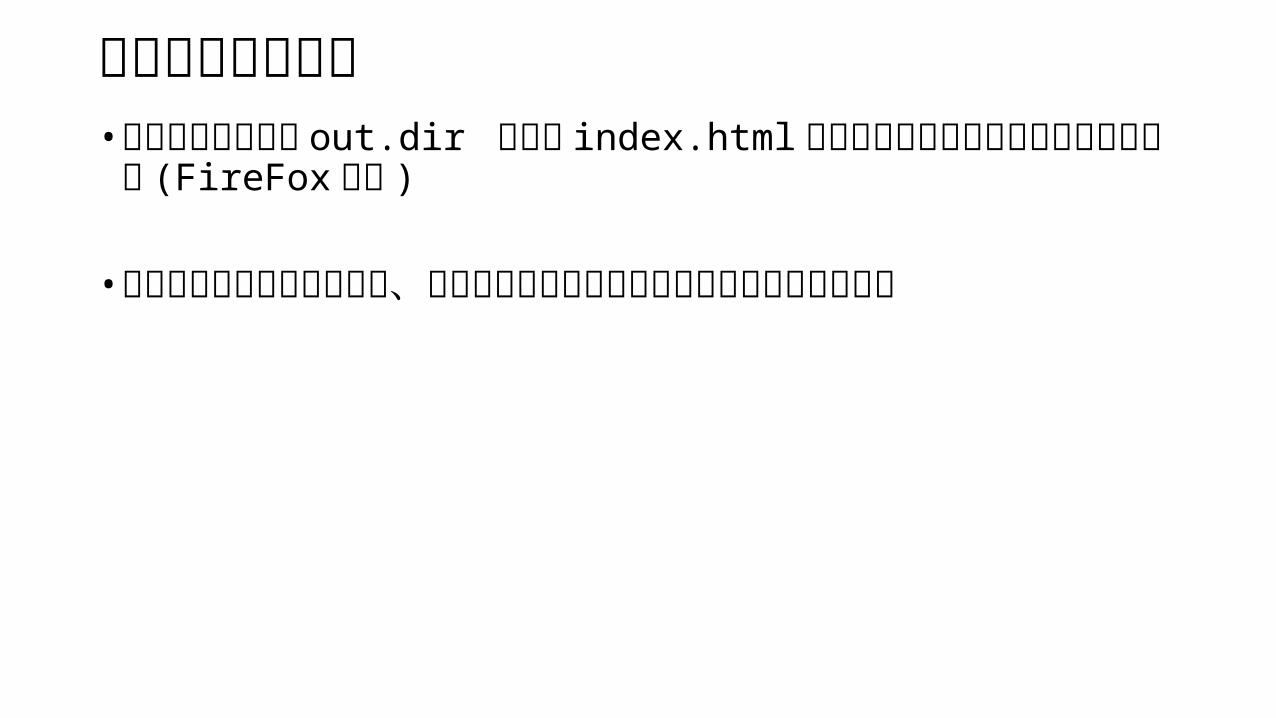
ブラウザでの確認•実行時に指定した out.dir にある index.html を実行するとブラウザでも確認が可能 (FireFox 推奨 )
•マウスオーバーやクリック、パラメータ変更によりインタラクティブに動作

参考情報• RMeCab• http://rmecab.jp/wiki/index.php?RMeCab
• LDA(+RMeCab)• http://qiita.com/HirofumiYashima/items/faaf857e49a065b5e0f1
• LDA-Vis• https://github.com/cpsievert/LDAvis/blob/master/README.md• http://cpsievert.github.io/LDAvis/reviews/reviews.html

2.doradora09 からお知らせ

2010年よりご愛顧いただいていたBAR doradoraですが

この度、諸事情により移転することになりました!

場所
だいたいこのあたり
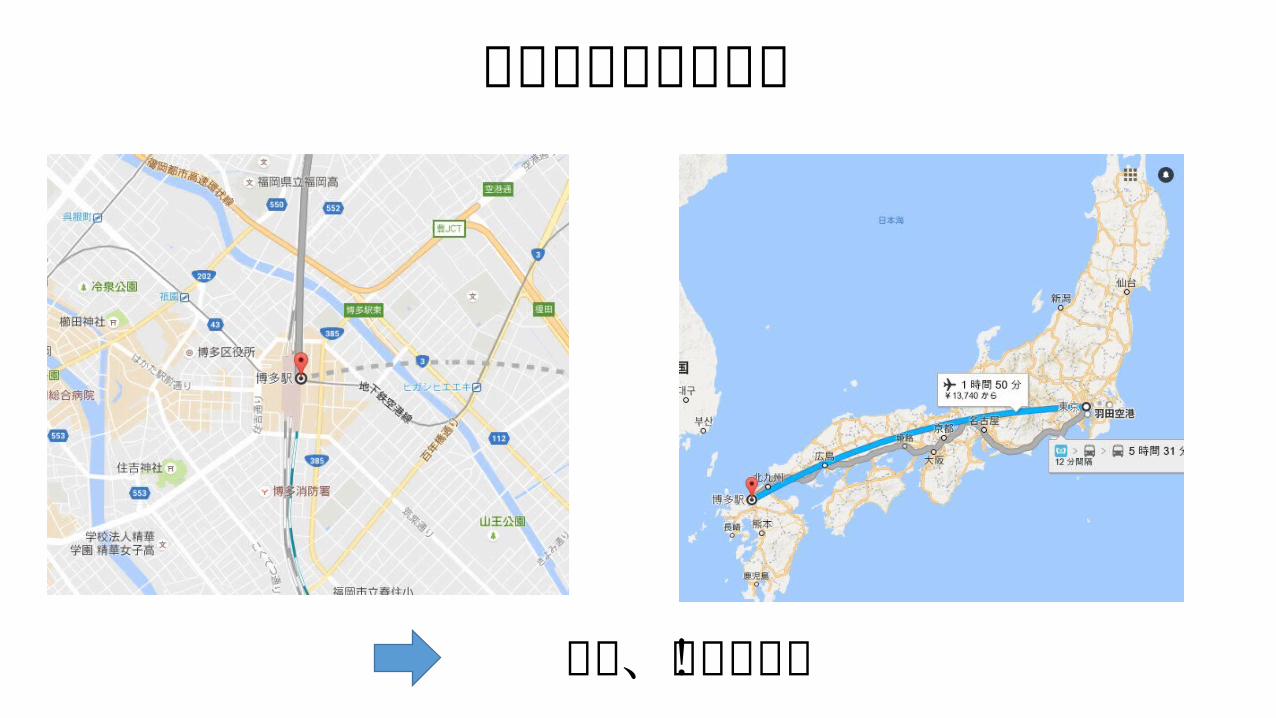
だいたいこのあたり
福岡、博多近辺!

BAR doradora 福岡移転のお知らせ•諸事情にて、年明け頃から福岡に引っ越し予定• ( 注:リアルに脱サラしての BAR開業ではないです・・ )
• Tokyo.R の後任スタッフ +BAR担当募集中• fukuoka.R に参加できると嬉しいです!!• 土地勘がないため九州出身の方、是非お話聞かせてください• あとは分析ごった煮勉強会とかも需要あれば。• 遠方からの発表者も募集します。特典はもつ鍋。
• 詳細は懇親会にて!

Enjoy!!