Embed Size (px)
DESCRIPTION
한국해양대학교 정보검색시스템 교재. 비불리언 모델에 관하여
Citation preview

제7장.
비불리언 모델 정보검색
INFORMATION RETRIEVAL
강의: 정창용 ([email protected]) http://www.facebook.com/hhuIR
Korea Maritime University Navis Control Inc.

용어의 가중치
벡터공간 모델
벡터공간 모델과 코사인 계수
유사계수에 의한 문헌의 순위화
벡터공간 모델에서 가중치 평가
확률 모델
통계언어 모델
Overview

비불리언 시스템
질의를 불리언 연산자로 표현하지 않음
문헌집단 내 모든 문헌을 대상으로 질의와의 유사도(적합성)에 따라 순
위화하는 시스템
유사도 계산을 위해서 용어(질의, 문헌)의 가중치가 중요
비불리언 모델

용어의 가중치
벡터공간 모델
벡터공간 모델과 코사인 계수
유사계수에 의한 문헌의 순위화
벡터공간 모델에서 가중치 평가
확률 모델
통계언어 모델
Outline

용어의 가중치(weight)
문헌에서 해당 용어의 중요도
용어 가중치 부여 방법
용어빈도 기법
문헌에 출현한 용어의 빈도수를 기반으로 부여
문헌빈도 기법
여러 문헌에 출현하는 단어보다 소수의 특정 문헌에 출현하는 단어에 더 높은 가중치를 추는 방법
문헌길이 정규화기법(normalization)
문헌이 길수록 용어의 출현빈도가 높음
문헌의 길이에 따라 용어의 가중치가 영향 받는 것을 최소화 함
용어의 가중치(Weight)

정의
TF (Term Frequency) : number of occurred term in a document
DF(Document Frequency) : number of documents where term occurs
IDF(Inverse Document Frequency) : Inverse DF
Weight = TF * IDF
TF가 크고, DF가 작을수록 가중치는 커진다.
전체문서에서 공통적으로 등장하는 단어들은 걸러지게 된다. 많은 문서에서 출현하는 term은 의미가 없다는 의미
tf * idf
문서의 총 개수
term을 포함한 문서의 개수

용어빈도(Term frequency)
b(binary) 1(출현), 0(비출현)
n(natural) tf
a(augmented) 𝑐 + 𝑐 ∗𝑡𝑓
𝑚𝑎𝑥𝑖𝑡𝑓
l(logarithm) 1 + log 𝑡𝑓
용어가중치 계산
tf (term frequency): 문헌이나 질의 내 용어 t의 출현 빈도수
참고

문헌빈도(Document frequency)
n(no) 1
c(cosine) log𝑁
𝑛
p(prob idf ) log𝑁 − 𝑛(+0.5)
𝑛(+0.5)
용어가중치 계산 – cont ’d
N : DB내 레코드(문헌) 총 수 n : DB내 용어 t가 출현하는 문헌 수

문헌길이 정규화(Document length normalization)
n(no) 1
c(cosine) 1
𝑤𝑖2
a(최대 tf 정규화) 1 − 𝑤𝑖 + 𝑤𝑖 × 𝑡𝑓
max 𝑡𝑓
b(byte크기 정규화) 𝑘 + 1 × 𝑡𝑓
𝑘 1 − 𝑏 + 𝑏 × 𝑑𝑙
𝑎𝑣𝑒𝑟𝑎𝑔𝑒 𝑑𝑙 + 𝑡𝑓
u(피벗고유단어 정규화) 1
1.0 − 𝑠𝑙𝑜𝑝𝑒 × 𝑝𝑖𝑣𝑜𝑡 + 𝑠𝑙𝑜𝑝𝑒 × # 𝑜𝑓 𝑢𝑛𝑖𝑞𝑢𝑒 𝑡𝑒𝑟𝑚𝑠
용어가중치 계산 – cont ’d
dl : 문헌에 출현하는 단어 수(문헌길이) (average dl은 평균문헌길이) n : DB내 용어 t가 출현하는 문헌 수

문헌(혹은 질의) 내 용어빈도수(tf )만 사용
bnn 1
nnn tf
lnn log 𝑡𝑓 + 1.0
용어가중치 조합 알고리즘

역문헌 빈도수(idf )만 사용
btn log𝑁
𝑛
bpn log𝑁 − 𝑛 + 0.5
𝑛 + 0.5
용어가중치 조합 알고리즘 – cont ’d

문헌(혹은 질의) 내 용어빈도수 × 역문헌 빈도수 사용
ntn 𝑡𝑓 × log𝑁
𝑛
atn 0.5 + 0.5 ×𝑡𝑓
max 𝑡𝑓× log
𝑁
𝑛
dtn 1 + log(1 + log 𝑡𝑓) ×𝑁+1
𝑛
용어가중치 조합 알고리즘 – cont ’d

정규화
lnc log(𝑡𝑓)+1.0
(log 𝑡𝑓+1.0)2
ntc 𝑡𝑓×log
𝑁
𝑛
𝑡𝑓×log𝑁
𝑛
2
ltc (log 𝑡𝑓+1.0)×log(
𝑁
𝑛)
log 𝑡𝑓+1.0 ×log𝑁
𝑛
2
anc 0.5+0.5×
𝑡𝑓
max 𝑡𝑓
0.5+0.5×𝑡𝑓
max 𝑡𝑓
2
용어가중치 조합 알고리즘 – cont ’d

atc 0.5+0.5×
𝑡𝑓
max 𝑡𝑓×log
𝑁
𝑛
0.5+0.5×𝑡𝑓
max 𝑡𝑓
2× log
𝑁
𝑛
2
lnu
1.0 + log 𝑡𝑓
1.0 + log(𝑎𝑣𝑡𝑓)
1.0 − 𝑠𝑙𝑜𝑝𝑒 × 𝑝𝑖𝑣𝑜𝑡 + 𝑠𝑙𝑜𝑝𝑒 × # 𝑜𝑓 𝑢𝑛𝑖𝑞𝑢𝑒 𝑡𝑒𝑟𝑚𝑠
ltu (1.0+log 𝑡𝑓)× log
𝑁
𝑛
1.0 − 𝑠𝑙𝑜𝑝𝑒 × 𝑝𝑖𝑣𝑜𝑡 + 𝑠𝑙𝑜𝑝𝑒 × # 𝑜𝑓 𝑢𝑛𝑖𝑞𝑢𝑒 𝑡𝑒𝑟𝑚𝑠
dnb 1 + log(1 + log 𝑡𝑓)
0.8 + 0.2 × 𝑑𝑙 (𝑖𝑛 𝑏𝑦𝑡𝑒)
𝑎𝑣𝑑𝑙 (𝑖𝑛 𝑏𝑦𝑡𝑒)
npb 𝑡𝑓
2 × 0.25 + 0.75 × 𝑑𝑙
𝑎𝑣𝑑𝑙 + 𝑡𝑓 × log
𝑁 − 𝑛 + 0.5
𝑛 + 0.5
용어가중치 조합 알고리즘 – cont ’d

용어의 가중치
벡터공간 모델
벡터공간 모델과 코사인 계수
유사계수에 의한 문헌의 순위화
벡터공간 모델에서 가중치 평가
확률 모델
통계언어 모델
Outline

불리안 검색모델 단점
검색문과 정확히 일치하지는 않으나 적합한 문헌을 검색하지 못함 ▷ 부분 매칭 불가
검색결과의 순위화 불가
용어의 가중치를 질의어나 색인에 반영할 수 없음 ▷ 이진(binary) 가중치 : 출현(1) or 비출현(0)
벡터공간 모델
Vector Model = Vector Space Model = Term Vector Model
불리안 모델의 단점 보완
부분 매칭(partial matching) 기법
문헌과 질의의 유사도(similarity)를 기준으로 순위화 가능
Cosine 유사도
벡터공간 모델
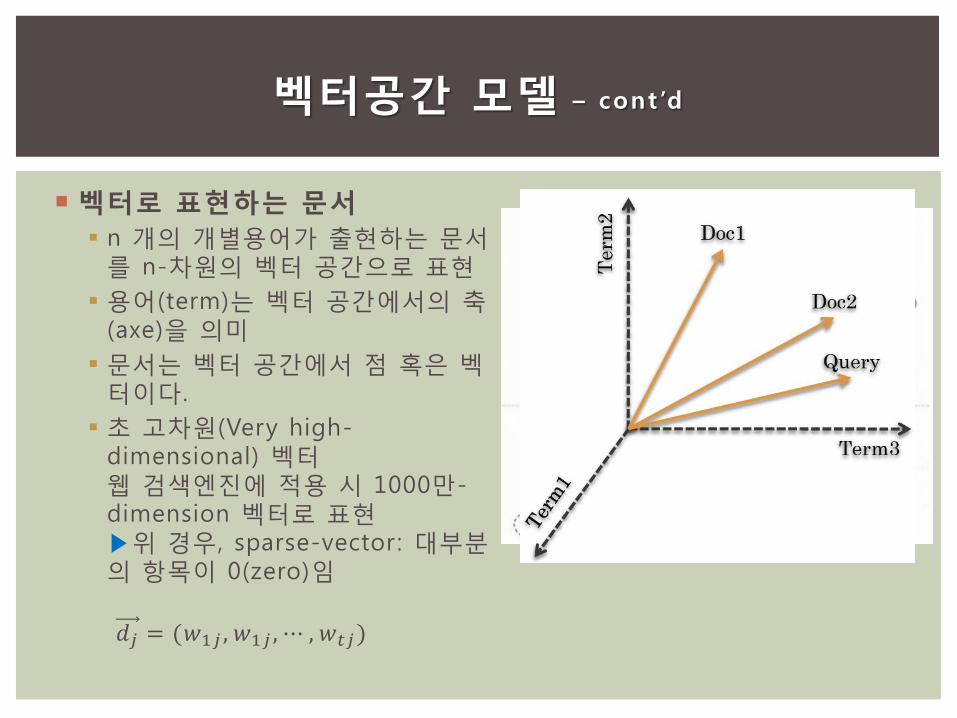
벡터로 표현하는 문서
n 개의 개별용어가 출현하는 문서를 n-차원의 벡터 공간으로 표현
용어(term)는 벡터 공간에서의 축(axe)을 의미
문서는 벡터 공간에서 점 혹은 벡터이다.
초 고차원(Very high-dimensional) 벡터 웹 검색엔진에 적용 시 1000만-dimension 벡터로 표현 ▶위 경우, sparse-vector: 대부분의 항목이 0(zero)임
𝑑𝑗 = (𝑤1𝑗 , 𝑤1𝑗 , ⋯ , 𝑤𝑡𝑗)
벡터공간 모델 – cont ’d

벡터로 표현하는 질의
Key idea 1: 질의를 같은 벡터 공간내의 벡터로 표현
Key idea 2: 벡터 공간 내에서 질의와 문서 근접도에 따라 순위화
근접도(proximity) = 벡터의 유사도(similarity)
문헌과 질의의 벡터 표현
𝑑𝑗 = (𝑤1𝑗 , 𝑤2𝑗 , ⋯ , 𝑤𝑡𝑗)
𝑞 = (𝑤1𝑞 , 𝑤2𝑞 , ⋯ , 𝑤𝑡𝑞)
TF * IDF 가중치를 주로 사용
벡터공간 모델 – cont ’d
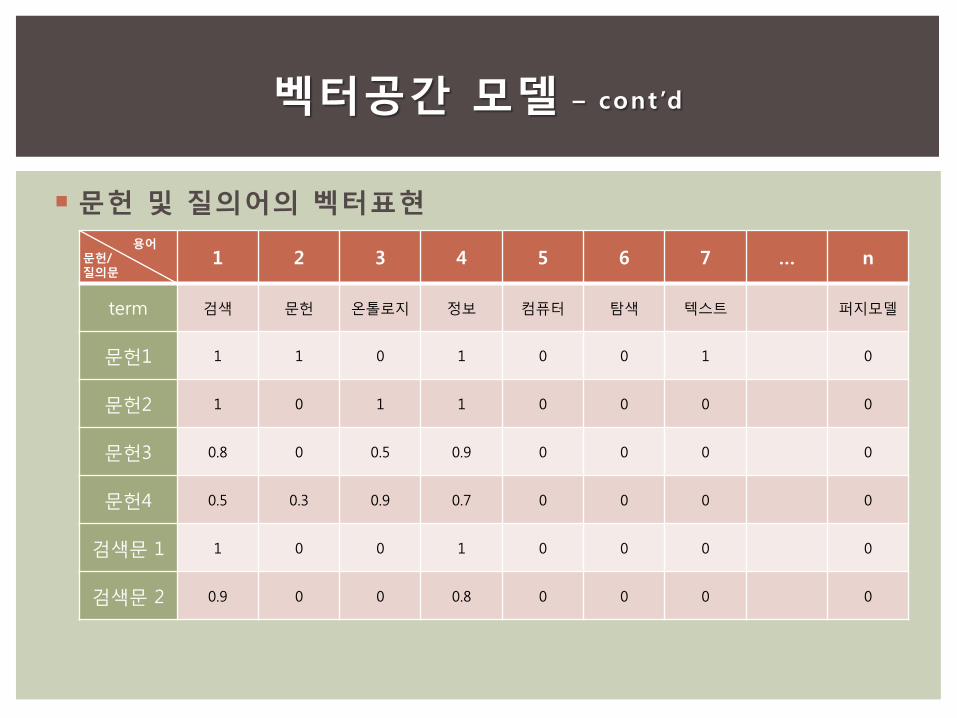
문헌 및 질의어의 벡터표현
벡터공간 모델 – cont ’d
용어 문헌/ 질의문
1 2 3 4 5 6 7 … n
term 검색 문헌 온톨로지 정보 컴퓨터 탐색 텍스트 퍼지모델
문헌1 1 1 0 1 0 0 1 0
문헌2 1 0 1 1 0 0 0 0
문헌3 0.8 0 0.5 0.9 0 0 0 0
문헌4 0.5 0.3 0.9 0.7 0 0 0 0
검색문 1 1 0 0 1 0 0 0 0
검색문 2 0.9 0 0 0.8 0 0 0 0
용어의 가중치
벡터공간 모델
벡터공간 모델과 코사인 계수
유사계수에 의한 문헌의 순위화
벡터공간 모델에서 가중치 평가
확률 모델
통계언어 모델
Outline

Euclidean distance
두 문헌 d1(w11, w12), d2(w21, w22) 사이의 거리
= (𝑤21 − 𝑤11)2+(𝑤22 − 𝑤12)
2
거리가 가까운 두 문헌의 유사도가 높음
문제점과 대안
거리가 짧으면 더욱 유사함
방향성 고려하지 않음
예) S(q, d2) vs. S(q, d1)
길이를 정규화한다.
거리를 이용한 유사도
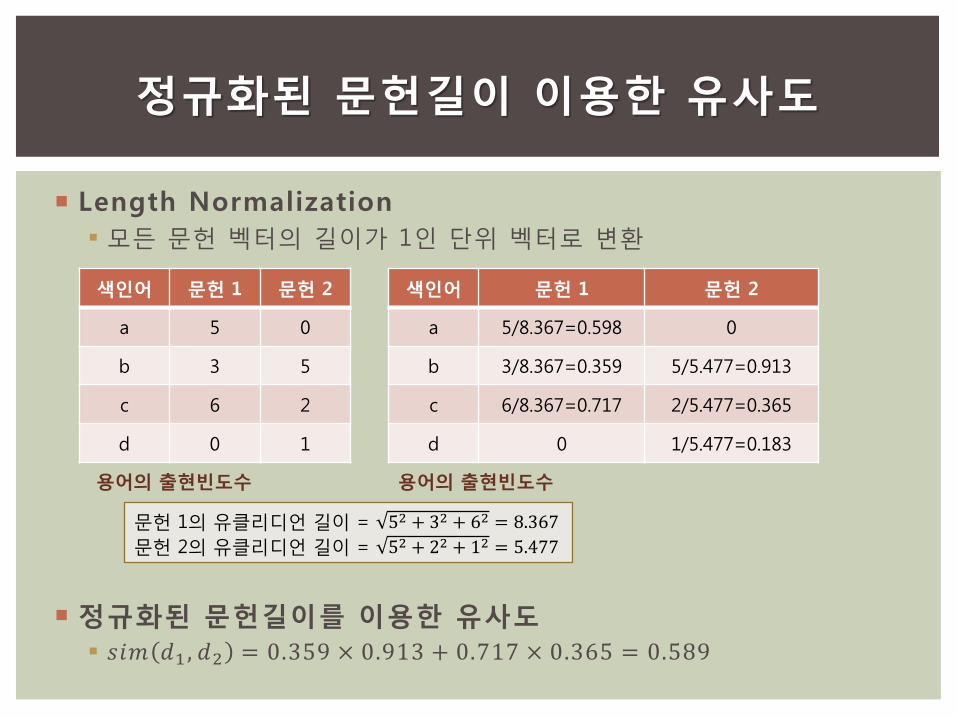
Length Normalization
모든 문헌 벡터의 길이가 1인 단위 벡터로 변환
정규화된 문헌길이를 이용한 유사도
𝑠𝑖𝑚 𝑑1 , 𝑑2 = 0.359 × 0.913 + 0.717 × 0.365 = 0.589
정규화된 문헌길이 이용한 유사도
색인어 문헌 1 문헌 2
a 5 0
b 3 5
c 6 2
d 0 1
색인어 문헌 1 문헌 2
a 5/8.367=0.598 0
b 3/8.367=0.359 5/5.477=0.913
c 6/8.367=0.717 2/5.477=0.365
d 0 1/5.477=0.183
용어의 출현빈도수 용어의 출현빈도수
문헌 1의 유클리디언 길이 = 52 + 32 + 62 = 8.367
문헌 2의 유클리디언 길이 = 52 + 22 + 12 = 5.477
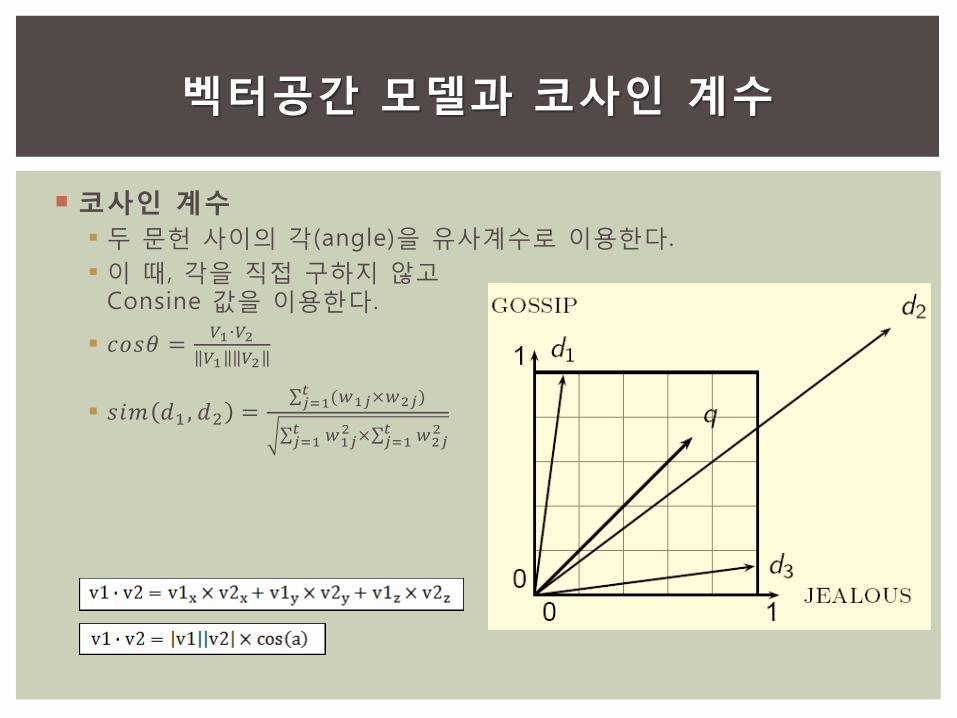
코사인 계수
두 문헌 사이의 각(angle)을 유사계수로 이용한다.
이 때, 각을 직접 구하지 않고 Consine 값을 이용한다.
𝑐𝑜𝑠𝜃 =𝑉1 ∙𝑉2
𝑉1 𝑉2
𝑠𝑖𝑚 𝑑1 , 𝑑2 = (𝑤1𝑗×𝑤2𝑗)𝑡𝑗=1
𝑤1𝑗2𝑡
𝑗=1 × 𝑤2𝑗2𝑡
𝑗=1
벡터공간 모델과 코사인 계수

예제
D1 = (전자도서관2, 장서1, 개발1, 보존1)
Q = (전자도서관1, 디지털도서관1, 장서1, 개발1)
▷assume, (t1, t2, t3, t4, t5) = (개발, 디지털도서관, 보존, 장서, 전자도서관)
D1 = (1, 0, 1, 1, 2)
Q = (1, 1, 0, 1, 1)
cos 𝐷1 , 𝑄 = 𝑠𝑖𝑚 𝐷1 , 𝑄 = 1×1+1×1+2×1
(12+12+12+22)×(12+12+12+12)= 0.76
벡터의 내적계수만으로 유사도를 산출하기도 함
벡터공간 모델과 코사인 계수 – cont ’d
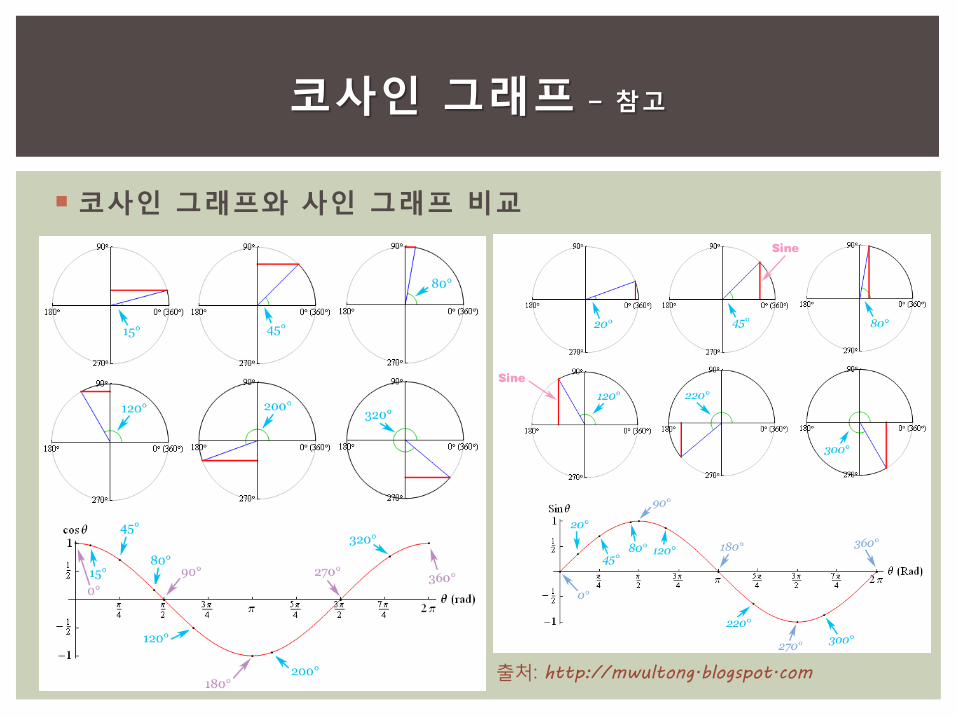
코사인 그래프와 사인 그래프 비교
코사인 그래프 – 참고
출처: http://mwultong.blogspot.com

용어의 가중치
벡터공간 모델
벡터공간 모델과 코사인 계수
유사계수에 의한 문헌의 순위화
벡터공간 모델에서 가중치 평가
확률 모델
통계언어 모델
Outline

등간 데이터(interval data)
유클리디안 거리(Euclidean distance)
𝐷 𝑋, 𝑌 = (𝑥𝑖 − 𝑦𝑖 )2
𝑖
제곱 유클리디안 거리
𝐷 𝑋, 𝑌 = (𝑥𝑖 − 𝑦𝑖 )2
𝑖
블록(block) 또는 맨하탄(Manhattan) 거리
𝐷 𝑋, 𝑌 = 𝑥𝑖 − 𝑦𝑖𝑖
민코브스키 거리(Minkowski metric)
𝐷 𝑋, 𝑌 = 𝑥𝑖 − 𝑦𝑖𝑖𝑝1
𝑝
유사계수에 의한 문헌의 순위화

등간 데이터(interval data)
피어슨 상관계수(Pearson correlation coefficient)
𝑆 𝑋, 𝑌 = (𝑥𝑖−𝑥 )(𝑦𝑖−𝑦 )𝑖
(𝑥𝑖−𝑥 )2
𝑖 × (𝑦𝑖−𝑦 )2
𝑖
코사인 계수(Cosine coefficient)
𝑆 𝑋, 𝑌 = (𝑥𝑖𝑦𝑖)𝑖
𝑥𝑖2
𝑖 × 𝑦𝑖2
𝑖
내적 계수(Vector 또는 Inner product)
𝑆 𝑋, 𝑌 = (𝑥𝑖𝑦𝑖)𝑖
유사계수에 의한 문헌의 순위화 – cont ’d

이진 데이터(binary data)
유클리디안 거리 𝐷 𝑋, 𝑌 = 𝑏 + 𝑐
크기 차이 𝐷 𝑋, 𝑌 =(𝑏−𝑐)2
(𝑎+𝑏+𝑐+𝑑)2
분산 𝐷 𝑋, 𝑌 =(𝑏+𝑐)
4(𝑎+𝑏+𝑐+𝑑)
랜스/윌리암스계수 𝐷 𝑋, 𝑌 =𝑏+𝑐
2𝑎+𝑏+𝑐
유사계수에 의한 문헌의 순위화 – cont ’d
질의(문헌)에서 용어 t
출현 비출현
문헌에서 용어 t 출현 a b
비출현 c d

이진 데이터(binary data)
단순일치 계수 S 𝑋, 𝑌 =𝑎+𝑑
𝑎+𝑏+𝑐+𝑑
러셀/라오 계수 S X, Y =𝑎
𝑎+𝑏+𝑐+𝑑
자카드 계수 S X, Y =𝑎
𝑎+𝑏+𝑐
다이스 계수 S X, Y =2𝑎
2𝑎+𝑏+𝑐
로저스/타니모토 계수 S X, Y =𝑎+𝑑
𝑎+𝑑+2(𝑏+𝑐)
율의 Y S X, Y =𝑎𝑑− 𝑏𝑐
𝑎𝑑+ 𝑏𝑐
율의 Q S X, Y =𝑎𝑑 −𝑏𝑐
𝑎𝑑+𝑏𝑐
오치아이 계수 S X, Y =𝑎
(𝑎+𝑏)× (𝑎+𝑐)
유사계수에 의한 문헌의 순위화 – cont ’d

문헌과 질의의 유사도 계산 예제
문헌 Di = (3, 2, 1, 0, 0, 0, 1, 1)
질의 Q = (1, 1, 1, 0, 0, 1, 0, 0)
다이스 계수 = 2 (𝑇𝑖𝑘×𝑇𝑞𝑘)𝑡𝑘=1
𝑇𝑖𝑘𝑡𝑘=1 + 𝑇𝑞𝑘
𝑡𝑘=1
=2×6
8+4= 1
자카드 계수 = (𝑇𝑖𝑘×𝑇𝑞𝑘)
𝑇𝑖𝑘+ 𝑇𝑞𝑘− (𝑇𝑖𝑘×𝑇𝑞𝑘)=
6
8+4−6= 1
코싸인 계수 = (𝑇𝑖𝑘×𝑇𝑞𝑘)
(𝑇𝑖𝑘)2× (𝑇𝑞𝑘)
2=
6
16×4=6
8
유사계수에 의한 문헌의 순위화 – 예제

장점
유사도(Similarity) 계산으로 검색결과의 순위화가 가능함
검색문에 복잡한 불리안 연산자를 사용하지 않음
단점
검색문 벡터와 모든 문헌벡터를 순차적으로 비교하기 때문에 반응속도 느림 ▶ 인터넷 같은 대용량 데이터 검색에 한계가 있음
단점 극복을 위한 노력
클러스터 모델(Cluster Model) 이용
역색인파일(Inverted index file)을 활용하여 최소 하나의 색인어라도 검색되는 문헌에 한하여 유사도를 계산
벡터공간 모델의 장단점

용어의 가중치
벡터공간 모델
벡터공간 모델과 코사인 계수
유사계수에 의한 문헌의 순위화
벡터공간 모델에서 가중치 평가
확률 모델
통계언어 모델
Outline

확률모델(Probabilistic Retrieval Model)
질의에 대해 각 문헌의 적합할 확률과 부적합할 확률을 계산
적합할(relevant) 확률 > 부적합할(non-relevant) 확률 ▶ 검색결과
가정
각 문헌은 주어진 질의에 적합 혹은 부적합하다
한 문헌에 대한 적합성 판정은 다른 문헌의 적합성에 영향을 끼치기 않음
확률 모델
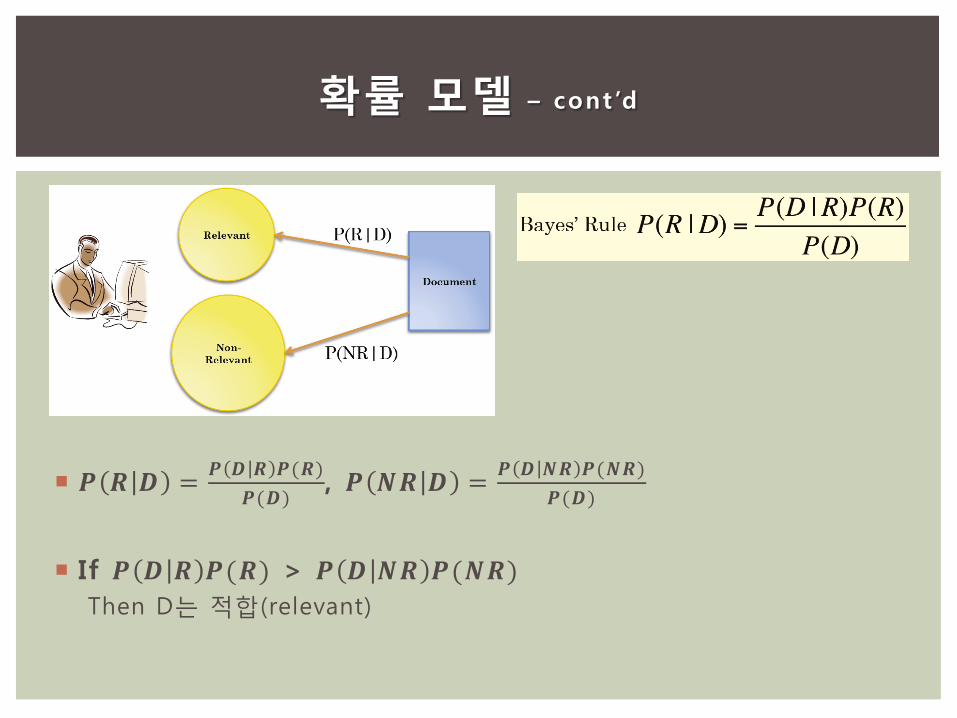
𝑷 𝑹 𝑫 =𝑷 𝑫 𝑹 𝑷(𝑹)
𝑷(𝑫), 𝑷 𝑵𝑹 𝑫 =
𝑷 𝑫 𝑵𝑹 𝑷(𝑵𝑹)
𝑷(𝑫)
If 𝑷 𝑫 𝑹 𝑷(𝑹) > 𝑷 𝑫 𝑵𝑹 𝑷(𝑵𝑹)
Then D는 적합(relevant)
확률 모델 – cont ’d

D=(d1, d2, …, d t) 일 때,
𝑃 𝐷 𝑅 = 𝑃(𝑑𝑖 |𝑅)𝑡𝑖=1
𝑃 𝐷 𝑁𝑅 = 𝑃(𝑑𝑖 |𝑁𝑅)𝑡𝑖=1
이진독립모델 (Binary Independence Model)
문헌 내의 용어는 서로 독립적
단어는 문헌 내에 0(absence) 혹은 1(presence)로 표현
P(D|R)과 P(D|NR) 추정

문헌의 적합성 평가
적합성 =적합문헌일 확률
부적합문헌일 확률
=𝑃(𝐷|𝑅)
𝑃(𝐷|𝑁𝑅)
= 𝑑𝑘 × 𝑙𝑜𝑔𝑝𝑘/(1 − 𝑝𝑘)
𝑞𝑘/(1 − 𝑞𝑘)+ 𝐶
𝑛
𝑘=0
문헌의 적합성
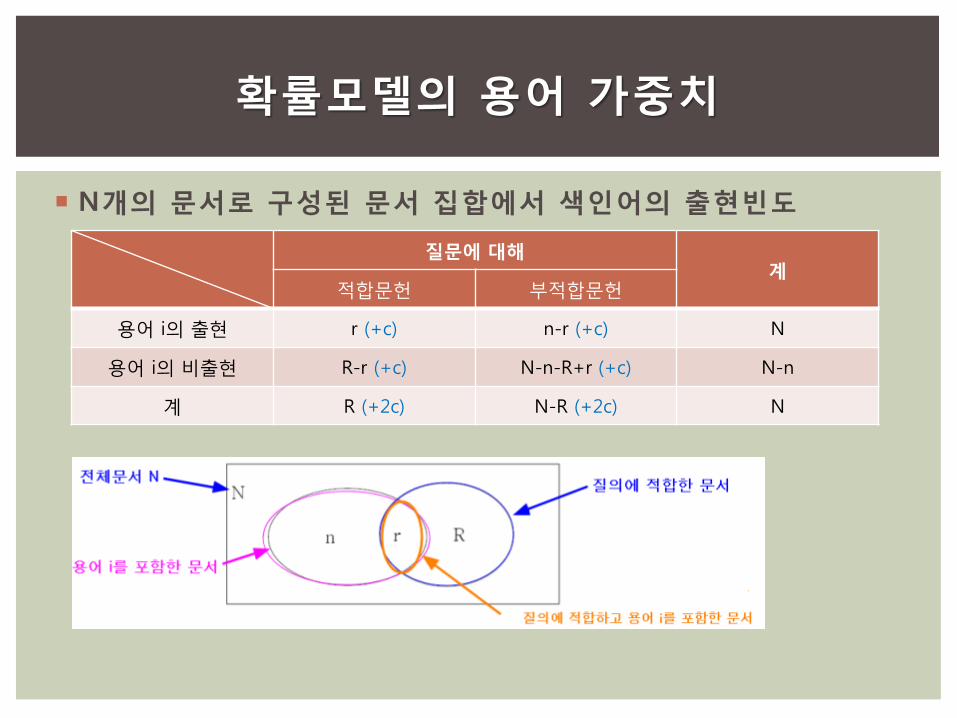
N개의 문서로 구성된 문서 집합에서 색인어의 출현빈도
확률모델의 용어 가중치
질문에 대해 계
적합문헌 부적합문헌
용어 i의 출현 r (+c) n-r (+c) N
용어 i의 비출현 R-r (+c) N-n-R+r (+c) N-n
계 R (+2c) N-R (+2c) N

𝐹1 = 𝑙𝑜𝑔𝑟/𝑅
𝑛/𝑁
𝐹2 = 𝑙𝑜𝑔𝑟/𝑅
(𝑛−𝑟)/(𝑁−𝑅)
𝐹3 = 𝑙𝑜𝑔𝑟/(𝑅−𝑟)
𝑛/(𝑁−𝑛)
𝐹4 = 𝑙𝑜𝑔𝑟/(𝑅−𝑟)
(𝑛−𝑟)/(𝑁−𝑛−𝑅+𝑟)= 𝑙𝑜𝑔
𝑟(𝑁−𝑛−𝑅+𝑟)
(𝑛−𝑟)(𝑅−𝑟)
𝐹4(𝑛
𝑁) = 𝑙𝑜𝑔
(𝑟+𝑛
𝑁)(𝑁−𝑛−𝑅+𝑟−
𝑛
𝑁+1)
(𝑛−𝑟+𝑛
𝑁)(𝑅−𝑟+
𝑛
𝑁+1)
𝐹4(.5) = 𝑙𝑜𝑔(𝑟+0.5)(𝑁−𝑛−𝑅+𝑟+0.5)
(𝑛−𝑟+0.5)(𝑅−𝑟+0.5)
확률모델의 용어 가중치 – cont ’d

𝐵𝑀15 = 𝐹4(.5) ×𝑡𝑓
𝑘1+𝑡𝑓×𝑞𝑡𝑓
𝑘3+𝑞𝑡𝑓
𝐵𝑀11 = 𝐹4(.5) ×𝑡𝑓
𝑘1×𝑑𝑙
𝑎𝑣𝑑𝑙+𝑡𝑓×𝑞𝑡𝑓
𝑘3+𝑞𝑡𝑓
𝐵𝑀25 = 𝐹4(.5) ×𝑡𝑓
𝑘1 1−𝑏 +𝑏𝑑𝑙
𝑎𝑣𝑑𝑙+𝑡𝑓×(𝑘3+1)𝑞𝑡𝑓
𝑘3+𝑞𝑡𝑓
𝐵𝑀25 수정
= 𝐹4(.5) ×𝑡𝑓
𝑘1 1 − 𝑏 + 𝑏𝑑𝑙𝑎𝑣𝑑𝑙
+ 𝑡𝑓
×(𝑘3 + 1)𝑞𝑡𝑓
𝑘3 + 𝑞𝑡𝑓+ 𝑘2 × 𝑛𝑞
𝑎𝑣𝑑𝑙 − 𝑑𝑙
𝑎𝑣𝑑𝑙 + 𝑑𝑙
용어의 출현빈도 고려한 공식들

K1=1~2, b=0.75, k 3=1~1000 주로 사용
문헌의 적합성
= 𝑁−𝑛+0.5
𝑛+0.5×
𝑘1+1 ×𝑡𝑓
𝑘1 1−𝑏 +𝑏𝑑𝑙
𝑎𝑣𝑑𝑙+𝑡𝑓×(𝑘3+1)×𝑞𝑡𝑓
𝑘3+𝑞𝑡𝑓
피벗정규화 공식
1+log (1+log 𝑡𝑓 )
1−𝑠 +𝑠𝑑𝑙
𝑎𝑣𝑑𝑙
× 𝑞𝑡𝑓 × 𝑙𝑜𝑔𝑁+1
𝑛
용어의 출현빈도 고려한 공식들 – cont ’d

용어의 가중치
벡터공간 모델
벡터공간 모델과 코사인 계수
유사계수에 의한 문헌의 순위화
벡터공간 모델에서 가중치 평가
확률 모델
통계언어 모델
Outline

언어 모델링(language modeling)
자연어의 문법, 구문, 단어 등의 규칙성을 찾는 것
음성인식, 기계번역, 문자인식, 철자교정 분야에서 연구
언어 모델링의 구분
지식기반 모델
정규문법(regular grammar)
문맥자유문법(context-free grammar)
비문법성에 의한 규칙을 정의하기 어려움
특정 영역에서의 자연언어 처리(NLP)에 일부 사용됨
통계 모델
말뭉치(corpus)에서 언어규칙을 확률로 표현
대규모 데이터 처리 분야에서 비교적 쉽고 효과적으로 사용됨
통계언어 모델

𝑷 𝒕𝟏 , 𝒕𝟐 , … , 𝒕𝒊 = 𝑷 𝒕𝟏 𝑷 𝒕𝟐 𝒕𝟏 𝑷 𝒕𝟑 𝒕𝟐 … 𝑷 𝒕𝒊 𝒕𝒊−𝟏
n-gram 모델
𝑃 𝑠 ≅ 𝑃 𝑡1 , 𝑡2 , … , 𝑡𝑖 = 𝑃(𝑡𝑖 |𝑡𝑖−𝑛+1 , … , 𝑡𝑖−1)
𝑃𝑢𝑛𝑖(𝑡1 , 𝑡2 , 𝑡3) = 𝑃 𝑡1 𝑃 𝑡2 𝑃(𝑡3)
𝑃𝑏𝑖(𝑡1 , 𝑡2 , 𝑡3) = 𝑃 𝑡1 𝑃 𝑡2|𝑡1 𝑃(𝑡3|𝑡2)
※ 음성인식, 기계번역 : 2 or 3-gram 주로 사용
※ 정보검색 : uni-gram 주로 사용
통계언어 모델 – cont ’d

Bayse 이론
𝑃 𝐷 𝑄 = 𝑃 𝐷 𝑞1 , 𝑞2 , … , 𝑞𝑖 =𝑃 𝑄 𝐷 𝑃(𝐷)
𝑃(𝑄)
Ponte & Croft (1998)
다변량 베르누이(multi-variate Bernoulli) 모델 사용
단어 출현 여부를 1, 0으로 표현
𝑃 𝑄 𝐷 = 𝑃 𝑞1 , 𝑞2 , … , 𝑞𝑖 D = 𝑃(𝑞𝑖 |𝐷) + (1 − 𝑃 𝑞𝑖 𝐷 )
Hiemstra (1998), Song & Croft (1999)
단어의 출현빈도 사용
𝑃 𝑞𝑖 𝐷 → 중요 용어가 생성될 확률
𝑃 𝑞𝑖 𝐶 → 비중요 용어가 생성될 확률
𝑃 𝑄 𝐷 = 𝑃 𝑞1 , 𝑞2 , … , 𝑞𝑖 D = (𝜆𝑃 𝑞𝑖 𝐷 + (1 − 𝜆)𝑃 𝑞𝑖 𝐶
통계언어 모델 – cont ’d

예문
d1 = Google was better than Yahoo in terms of precision
d2 = Google ranks pages by the pagerank algorithm
𝑃 𝑞𝑖 𝐷 =문헌 𝑑에서𝑞𝑖의 출현빈도문헌 𝑑의 길이(총빈도)
𝑃 𝑞𝑖 𝐶 =컬렉션내 𝑞𝑖의 출현빈도
컬렉션의 길이
𝑃 𝑄 𝐷1 = 0.51
9+2
16× 0.5
0
9+1
16=17
144×45
144= 0.0037
𝑃 𝑄 𝐷2 = 0.51
7+2
16× 0.5
0
7+1
16=15
112×11.5
112= 0.0137
통계언어 모델 - 예제
![12-제7장-직류전압제어(2).ppt [호환 모드]elearning.kocw.net/contents4/document/lec/2012/KonKuk/LeeYoungJin/12.pdf · 제7장 직류전력제어 . 전력전자이론](https://img.pdfslide.net/doc/110x75/5e0332ded9e2ea2f204237ed/12-oe7-eoe2ppt-eeoe-oe7-eeoe.jpg)














![[모델] 프로필-황수현](https://img.pdfslide.net/doc/110x75/5492cfbcb47959132c8b465b/-5492cfbcb47959132c8b465b.jpg)













