Embed Size (px)
Citation preview

A Mixed Discrete-Continuous Attribute List Representation for Large Scale
Classification DomainsJaume Bacardit
Natalio Krasnogor
{jqb,nxk}@cs.nott.ac.uk
University of Nottingham

Outline
• Motivation and objectives
• Framework: The BioHEL GBML system
• Improving the Attribute List Knowledge Representation
• Experimental design
• Results and discussion
• Conclusions and further work

Motivation
• We live in times of a great “data deluge”
• Many different disciplines and industries generate vast amounts of data
• Large scale can mean– Many records, many dimensions, many classes, …
• Our work is focused on representations that– Can deal with large attribute spaces
– Are efficient, as this can make a big difference when dealing with really large datasets

The Attribute List knowledge representation (ALKR)
• This representation was recently proposed [Bacardit et al., 09] to achieve these aims
• This representation exploits a very frequent situation– In high-dimensionality domains it is usual that each rule only uses a
very small subset of the attributes
• Example of a rule for predicting a Bioinformatics dataset [Bacardit and Krasnogor, 2009]
• Att Leu-2 ∈ [-0.51,7] and Glu ∈ [0.19,8] and
Asp+1 ∈ [-5.01,2.67] and Met+1∈ [-3.98,10] and
Pro+2 ∈ [-7,-4.02] and Pro+3 ∈ [-7,-1.89] and
Trp+3 ∈ [-8,13] and Glu+4 ∈ [0.70,5.52] and
Lys+4 ∈ [-0.43,4.94] alpha
• Only 9 attributes out of 300 were actually in the rule
– Can we get rid of the 291 irrelevant attributes?

The Attribute List knowledge representation
• Thus, if we can get rid of the irrelevant attributes– The representation will be more efficient, avoiding the
waste of cycles dealing with irrelevant data
– Exploration will be more focused, as the chromosomes will only contain data that matters
• This representation automatically identifies the relevant attributes in the domain for each rule
• It was tested on several small datasets and a couple of large protein datasets, showing good performance

Objectives of this work
• We propose an efficient extension of the representation that can deal at the same time with continuous and discrete attributes– The original representation only dealt with continuous
variables
• We evaluate the representation using several large-scale domains– To assess its performance, and to identify where to
improve it
• We compare ALKR against other standard machine learning techniques

The BioHEL GBML System
• BIOinformatics-oriented Hiearchical Evolutionary Learning – BioHEL (Bacardit et al., 2007)
• BioHEL is a GBML system that employs the Iterative Rule Learning (IRL) paradigm– First used in EC in Venturini’s SIA system (Venturini, 1993)
– Widely used for both Fuzzy and non-fuzzy evolutionary learning
• BioHEL inherits most of its components from GAssist [Bacardit, 04], a Pittsburgh GBML system

Iterative Rule Learning
• IRL has been used for many years in the ML community, with the name of separate-and-conquer

Characteristics of BioHEL
• A fitness function based on the Minimum-Description-Length (MDL) (Rissanen,1978) principle that tries to– Evolve accurate rules– Evolve high coverage rules– Evolve rules with low complexity, as general as possible
• The Attribute List Knowledge representation– Representation designed to handle high-dimensionality domains
• The ILAS windowing scheme– Efficiency enhancement method, not all training points are used for
each fitness computation• An explicit default rule mechanism
– Generating more compact rule sets• Ensembles for consensus prediction
– Easy system to boost robustness

Fitness function of BioHEL
• Coverage term penalizes rules that do not cover a minimum percentage of examples
• Choice of the coverage break is crucial for the proper performance of the system

Improving the Attribute List Knowledge Representation
• Mixed discrete-continuous representation– Intervalar represenation for continuous variables [Llora et al.,
07]• If Att ∈ [ LB, UB]
• 2 real-valued parameters, specifying the bounds
– GABIL binary representation [De Jong & Spears, 91] for discrete variables
• If Att takes value A or B
• One bit for each possible value, indicating if value is included in the disjunction
• If Att1∈ [0.2,0.5] and Att2 is (A or B) Class 1
• {0.2,0.5|1,1,0|1}

Improving the Attribute List Knowledge Representation
• Each rule contains:

Improving the Attribute List Knowledge Representation
The match process is a crucial element in the performance of the system
This code is run millions of times
Do you think that this code is efficient?Look at the If

Improving the Attribute List Knowledge Representation
• Doing supervised learning allows us to exploit one trick– When we evaluate a rule, we
test it against each example in the training set
– Thus, we can precalculate two lists, of discrete and continuous attributes
• The match process is performed separately for both kinds of attributes
• Essentially, we have unrolled the loop

Improving the Attribute List Knowledge Representation
• Recombination remains unchanged– Simulated 1-point crossover to deal with the
variable-length lists of attributes
– Standard GA mutation
– Two operators (specialize and generalize) add or remove attributes from the list with a given probability, hence exploring the space of the relevant attributes for this rule

Experimental design
• Seven datasets were used– They represent a broad range of characteristics in
terms of instances, attributes, classes, type of attributes and class balance/unbalance

Experimental design• First, ALKR was compared against BioHEL using its
original representation (labelled orig)
• Also, three standard machine learning techniques were used in the comparison:– C4.5 [Quinlan, 93]
– Naive Bayes [John and Langley, 95]
– LIBSVM [Chang & Lin, 01]
• The default parameters of BioHEL were used, except for two of them:– The number of strata of the ILAS windowing scheme
– The coverage breakpoint of BioHEL’s fitness function
– These two parameters were strongly problem-dependant

The traditional big table of results
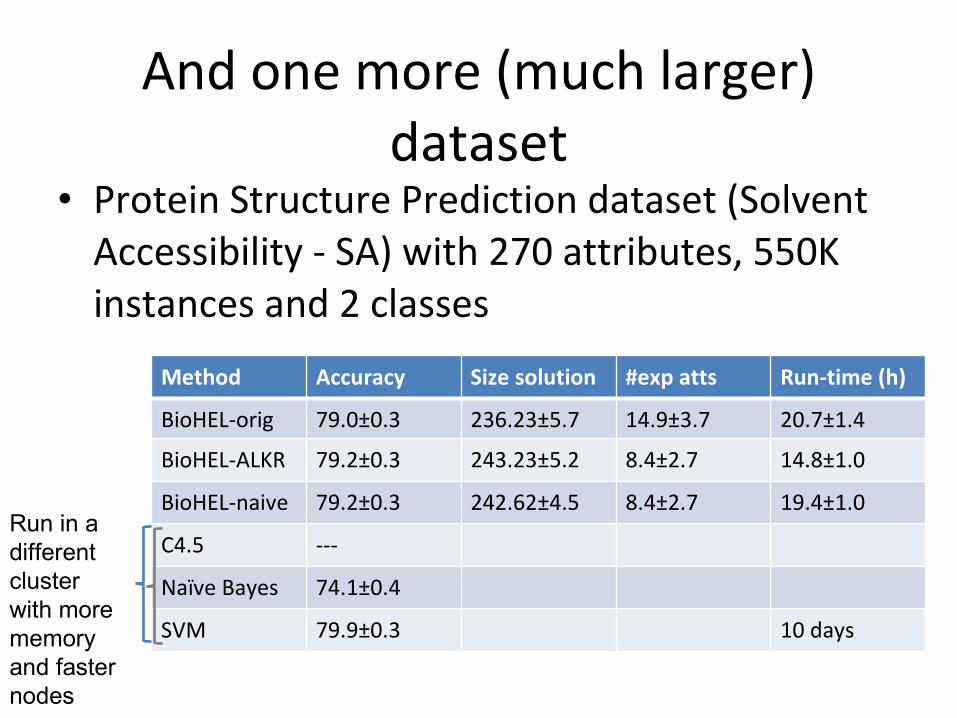
And one more (much larger) dataset
• Protein Structure Prediction dataset (Solvent Accessibility - SA) with 270 attributes, 550K instances and 2 classes
Method Accuracy Size solution #exp atts Run-time (h)
BioHEL-orig 79.0±0.3 236.23±5.7 14.9±3.7 20.7±1.4
BioHEL-ALKR 79.2±0.3 243.23±5.2 8.4±2.7 14.8±1.0
BioHEL-naive 79.2±0.3 242.62±4.5 8.4±2.7 19.4±1.0
C4.5 ---
Naïve Bayes 74.1±0.4
SVM 79.9±0.3 10 days
Run in a different cluster with more memory and faster nodes

ALKR vs Original BioHEL
• Except for one dataset (and the difference is minor), ALKR always obtains better accuracy
• Datasets where is ALKR is much better are those with larger number of attributes– ALKR is better at exploring the search space
• ALKR generates more compact solutions, in #rules and, specially, in #attributes
• Except for the ParMX domain (with a very small number of attributes), ALKR is always faster (72 times faster in the Germ dataset!)

BioHEL vs other ML methods
• The accuracy results were analyzed overall using a Friedman test for multiple comparisons
• The test detected with a 97.77% confidence that there were significant differences in the performance of the compared methods
• A post-hoc Holm test indicated that ALKR was significantly better than Naive Bayes with 95% confidence.
• If we look at individual datasets, BioHEL is only outperformed largely in the wav and SA datasets by SVM
• BioHEL’s advantage in the Germ dataset is specially large

Where can we improve BioHEL?• ParMX is a synthetic
dataset for which the optimal solution consists in 257 rules. BioHEL generated 402 rules
• The rules were accurate but suboptimal
• The coverage pressure introduced by the coverage breakpoint parameter was not appropiate for the whole learning process
• BioHEL also had some problems in datasets with class unbalance (c-4)

Conclusions• In this work we have
– Extended the Attribute List Knowledge Representation of the BioHEL LCS to deal with mixed discrete-continuous domains in an efficient way
– Assessed the performance of BioHEL using a broad range of large-scale scenarios
– Compared BioHEL’s performance against other representations/learning techniques
• The experiments have shown that BioHEL+ALKR is efficient, it generates compact and accurate solutions and it is competitive against other machine learning methods
• We also identified several directions of improvement

Future work
• Identify the causes and address the issues that were observed in these experiments about BioHEL’s performance
• Compare and combine ALKR against similar recent LCS work [Butz et al., 08]
• Is possible to create a parameter-less BioHEL?
• The development of theoretical models that can explain the behavior of both BioHEL and ALKR would – Made all of the above easier
– Be an important milestone in the principled application of LCS to large-scale domains

Questions?





























