Embed Size (px)
Citation preview


Advanced data science algorithms applied to scalable stream processing
David Piris Valenzuela
Nacho García Fernández
@0xNacho
@davidpiris

3
About Treelogic R&D intensive company with the mission of adapting technological knowledge to
improve quality standards in our daily life
8 ongoing H2020 projects (coordinating 3 of them)
8 ongoing FP7 projects (coordinating 5 of them)
Focused on providing Big Data Analytics in all the world
Internal organizationResearch lines
Big Data
Computer vision
Data science
Social Media Analysis
Security
ICT solutions
Security & Safety
Justice
Health
Transport
Financial Services
ICT tailored solutions

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE WANT6. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms
3. A distributed data storage system
4. A use case
5. A visualization layer

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE WANT6. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms
3. A distributed data storage system
4. A use case
5. A visualization layer

6
Why we need Big Data

7
Why we need Big Data Public and private sector companies store a huge mount of data
Countries with huge databases store data from Population
Medical records
Taxes
Online transactions
Mobile transactions
Social Networks
In a single day, tweets generates 12 TB!!

8
Why we need Big Data
2.5 Exabytes are produced every day!!!
530.000.000 million songs
150.000.000 iPhones
5 million laptops
90 years of HD Video

9
Why we need Big DataHow can we manage all data?

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE WANT6. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms
3. A distributed data storage system
4. A use case
5. A visualization layer

11
Big Data: SolutionsFirst we can manage all historical repository, and retrieve some value fromdata stored
Batch architecture
MapReduce
Hadoop Ecosystem

12
Big Data: Solutions

13
Big Data: SolutionsBatch processing with Hadoop takes a lot of time and the need to processingested data and display results in a shortest way possible brings newarchitecture and tools
Lambda architecture
Spark (memory vs disk)
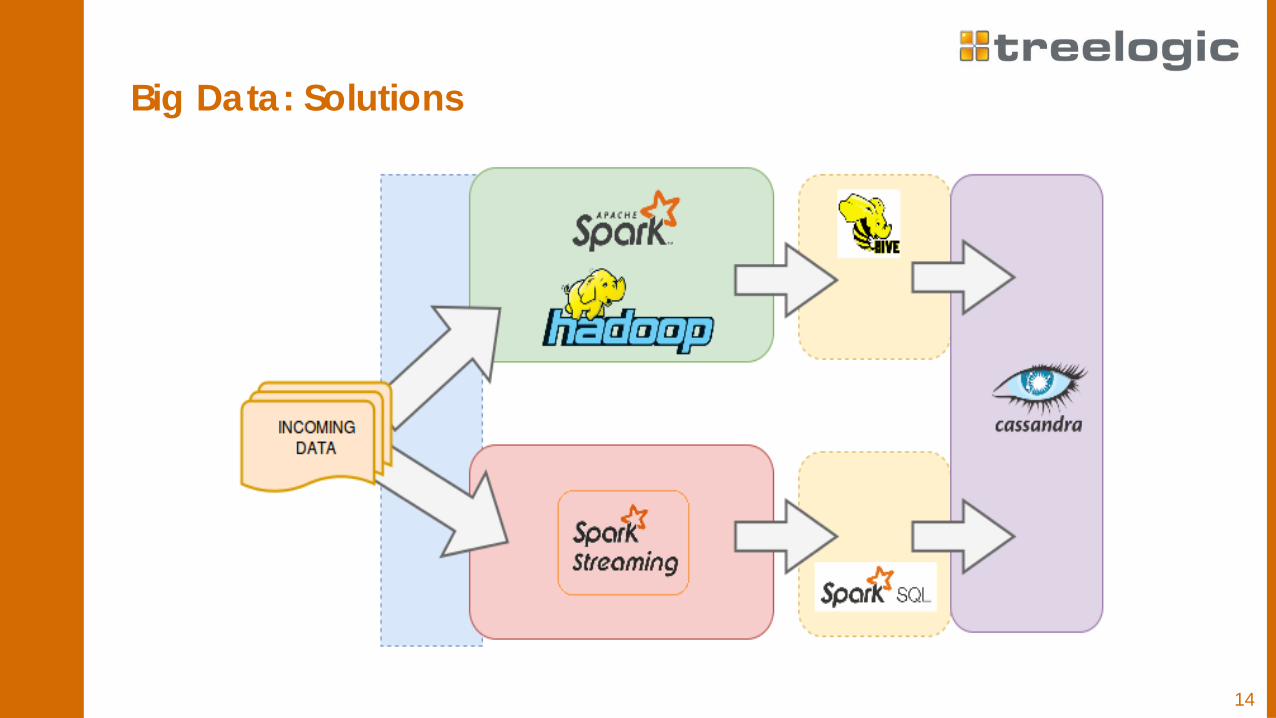
14
Big Data: Solutions

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE WANT6. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms
3. A distributed data storage system
4. A use case
5. A visualization layer

16
Big data: real-time processing Faster results
Accurate results
Less expense
Please consumers

17
Big data: real-time processingAs previously said, we need to extract and visualize information in near realtime…

18
Big data: real-time processing Flink as engine process
Stream processing
Windowing with events time semantics
Streaming and batch processing
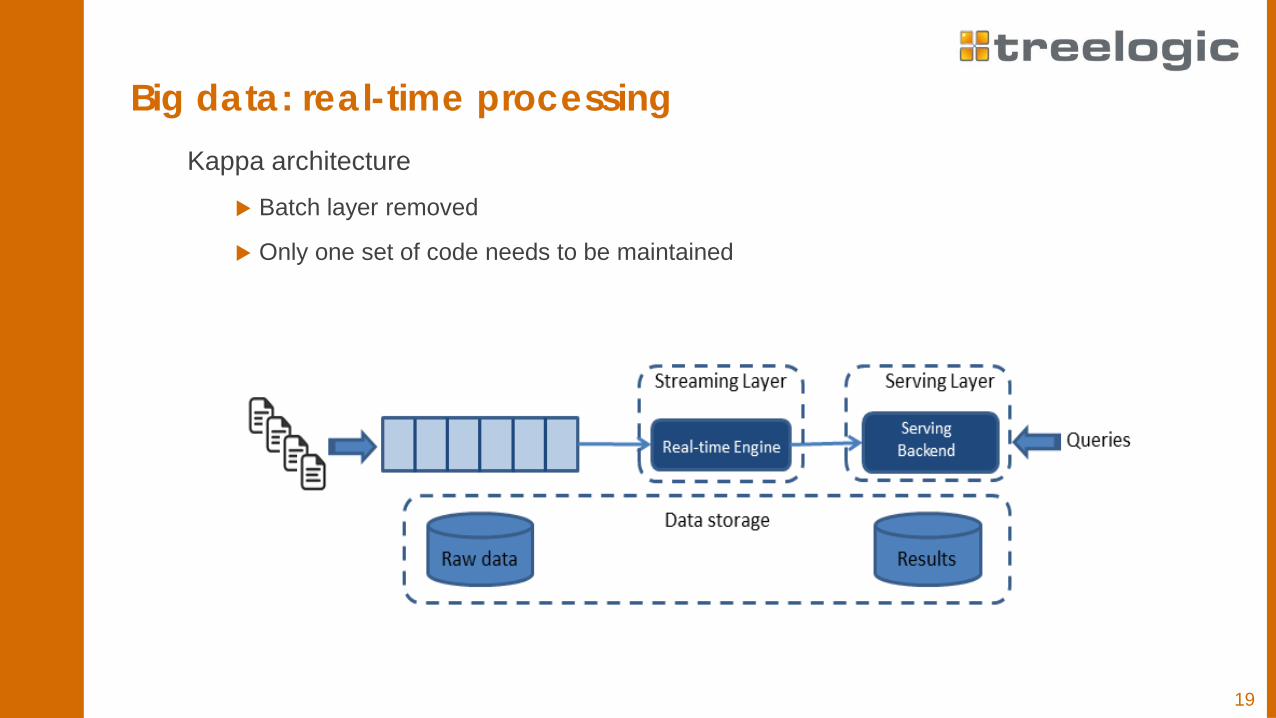
19
Big data: real-time processingKappa architecture
Batch layer removed
Only one set of code needs to be maintained

20
Big data: real-time processing No need to use batch layer
Avoid use disk in engine process (latency)

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE WANT6. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms
3. A distributed data storage system
4. A use case
5. A visualization layer

22
Big data: available tools

23
Incremental algorithms BI & BA people always want to made some common operations to retrieve
value and visualize data We have operational tools in a relational or batch environment How we can obtain average for a data stream that is changing every
second, minutes or even milliseconds…? Common average operation is indicated for historical repository, data input
without any changes in the moment we start the process to obtain it. Do we have tools to make it possible in a real time deployment?

24
Incremental algorithms
Answer is NO!

25
Incremental algorithmsFlink gives us the chance to operate with a new window processing concept.We can decide and configure "small time pieces", and make someoperations or manipulate data in that time space.
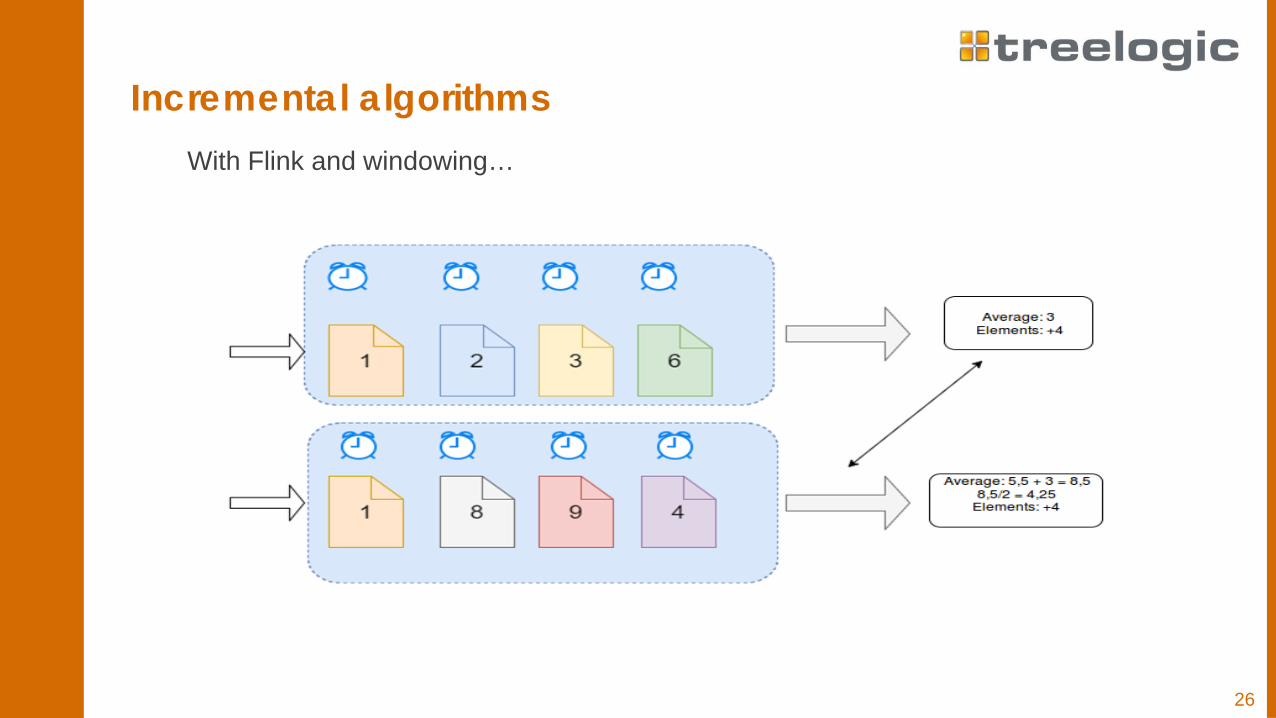
26
Incremental algorithmsWith Flink and windowing…

27
Incremental algorithms These algorithms consume streams of data and are able to update their
results in a parallel manner without the need of saving the processed data
Using checkpoints in windowing, allows us to store result from previouswindow process

28
Incremental algorithmsOur analytics & visualization solution implemented in a real time architecture

29
Incremental algorithmsIf you are a BI or BA professional...we care about you!

30
Incremental algorithms Currently, we have implemented:
Average
Mode
Variance
Correlation
Covariance
Min
Max

31
Incremental algorithms Currently we are working on:
Median

32
Incremental algorithms In roadmap…
Standard deviation
Order by
Discretization
Contains
Split
Validate range values
Set default value to specific output

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE NEED
1. A stream processing engine2. Online incremental algorithms
3. A distributed data storage system
4. A use case
5. A visualization layer
34
Apache Flink vs Apache Spark
Pure streams for all workloads
Optimizer
Low latency, high throughput
Global, session, time and count based
window criteria
Provides automatic memory management
Micro-batches for all workloads
No job optimizer
High latency as compared to Flink
Time-based window criteria
Configurable memory management. Spark
1.6+ has move towards automating
memory management

35

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms3. A distributed data storage system
4. A use case
5. A visualization layer
37
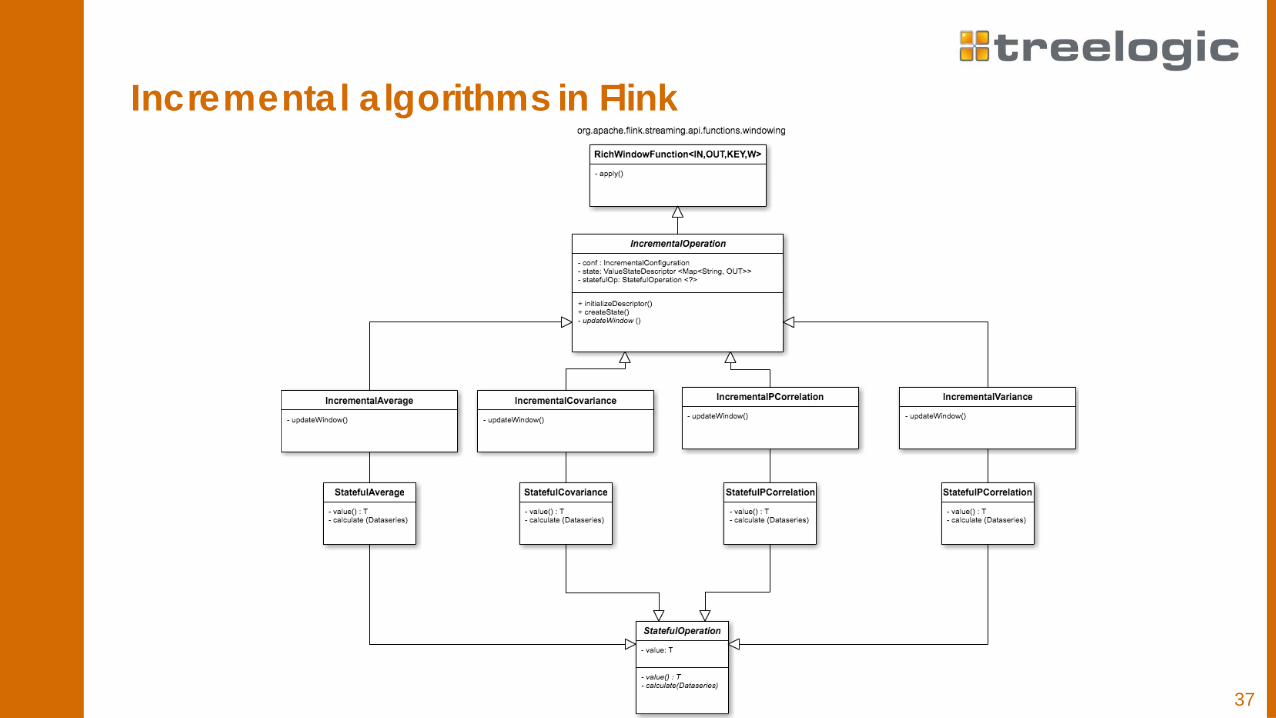
Incremental algorithms in Flink
38
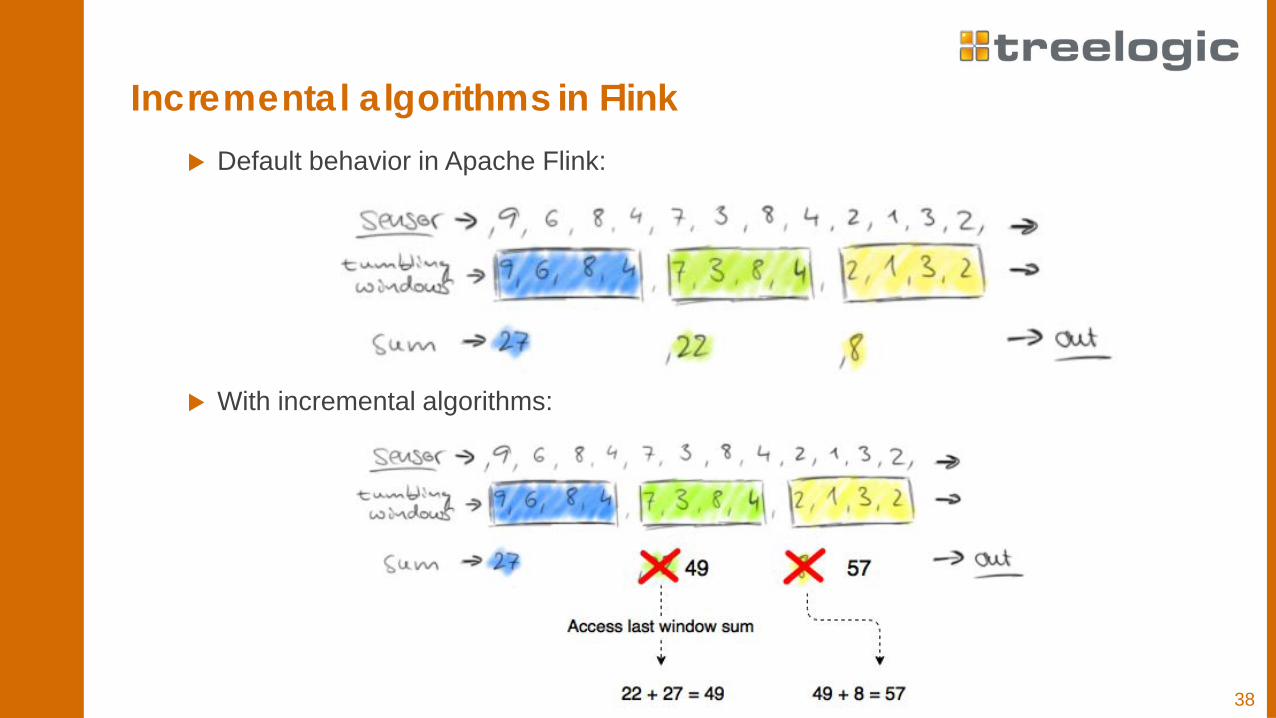
Incremental algorithms in Flink Default behavior in Apache Flink:
With incremental algorithms:
39
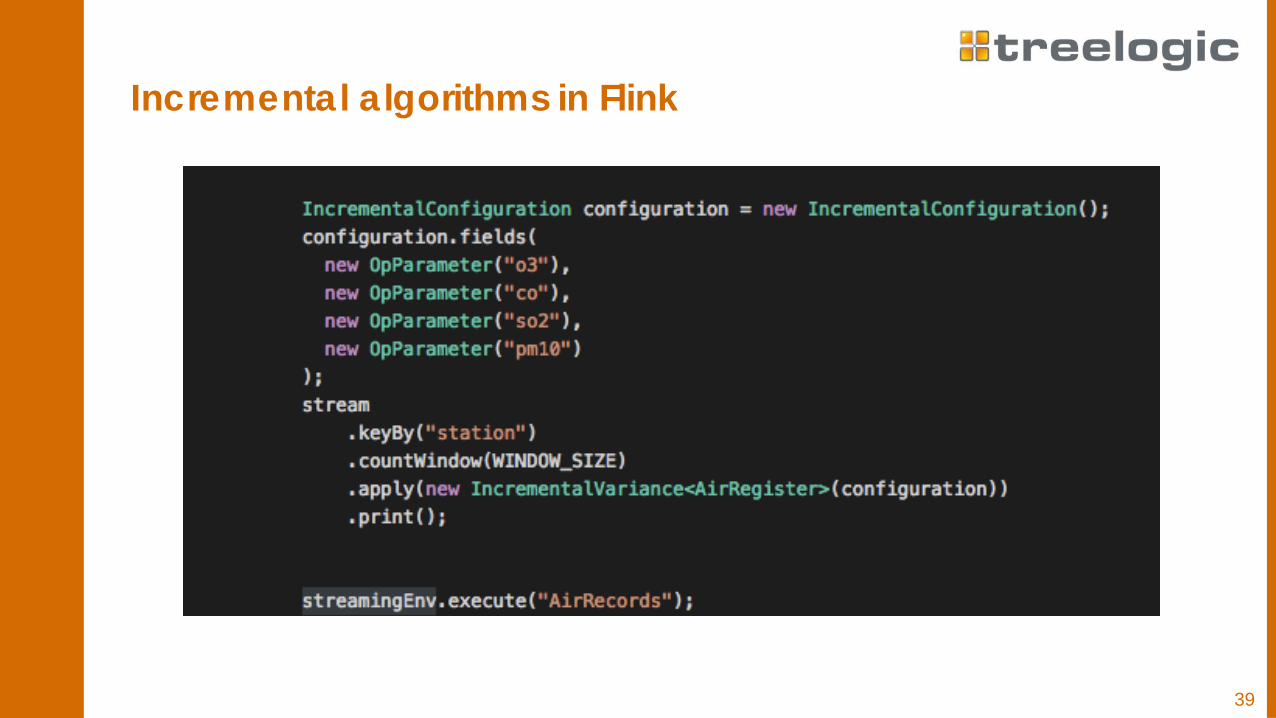
Incremental algorithms in Flink

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms
3. A distributed data storage system4. A use case
5. A visualization layer

41
Apache Kudu Provides a combination of fast inserts / updates and efficient columnar
scans to enable real-time analytic workloads
It is a new complements to HDFS and HBase
Designed for use cases that require fast analytics on fast data
Low query latency
V1.0.1 was released on October 11, 2016

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms
3. A distributed data storage system
4. A use case5. A visualization layer

43
PROTEUS: a steel making scenario Steel industry is a key sector for the European community.
PROTEUS was introduced last year at Big Data Spain by Treelogic *
Hot Strip mills (sometimes) produces steel with defects
Predict coil parameters (thickness, width, flatness) using real-time and historical data
Detecting defective coils in an early stage saves money. The production process can bemodified / stopped.
Proposed architecture is being validated in this project
7870 variables with a frequency of 500ms: data-in-motion
700.000 registers for each variables. 500GB time series and flatness map: data-at-rest
* https://www.youtube.com/watch?v=EIH7HLyqhfE

44
PROTEUS: a steel-making scenario Steel industry is a key sector for the European community.
PROTEUS was introduced last year at Big Data Spain by Treelogic *
Hot Strip mills (sometimes) produces steel with defects
Predict coil parameters (thickness, width, flatness) using real-time and historical data
Detecting defective coils in an early stage saves money. The production process can bemodified / stopped.
Proposed architecture is being validated in this project
7870 variables with a frequency of 500ms: data-in-motion
700.000 registers for each variables. 500GB time series and flatness map: data-at-rest
* https://www.youtube.com/watch?v=EIH7HLyqhfE

CONTENTS
1. WHY WE NEED BIG DATA2. BIG DATA: SOLUTIONS3. BIG DATA: REAL-TIME PROCESSING4. INCREMENTAL ALGORITHMS5. WHAT WE NEED
1. A stream processing engine
2. Online incremental algorithms
3. A distributed data storage system
4. A use case
5. A visualization layer
46
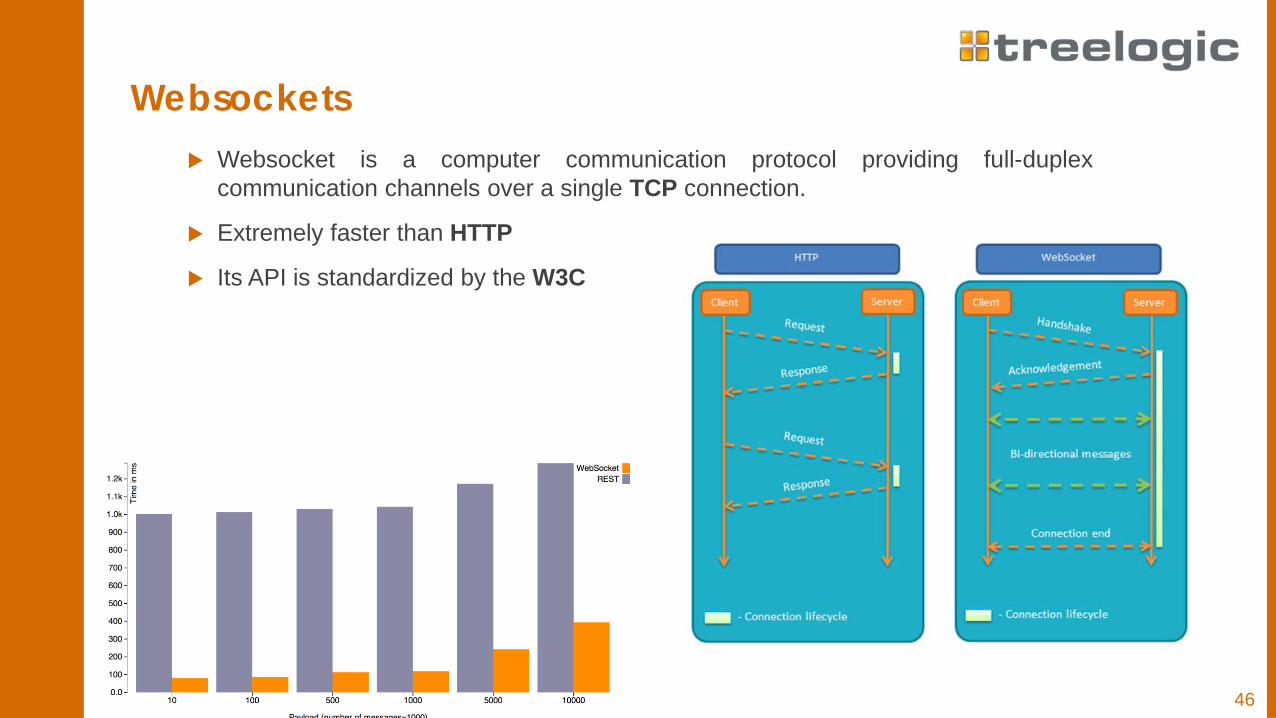
Websockets Websocket is a computer communication protocol providing full-duplex
communication channels over a single TCP connection.
Extremely faster than HTTP
Its API is standardized by the W3C

47
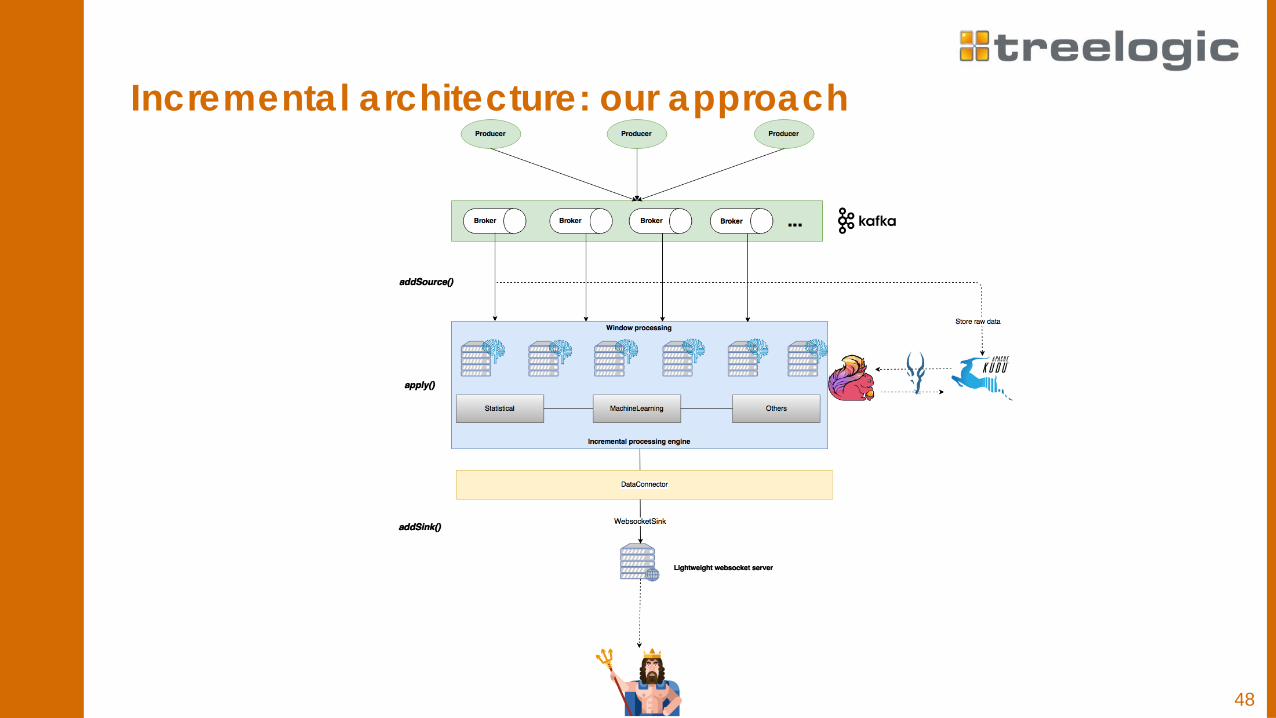
Apache Flink & Websockets Data sinks consume DataSets and are used to store or return them.
Flink comes with a variety of built-in output formats that are encapsulated behindoperations on the DataSet: writeAsText()
writeAsFormattedText()
writeAsCsv()
print()
write()
We’ve developed a WebsocketSink enabling Flink to send outputs to a givenwebsocket endpoint. Based on the javax-websocket-client-api 1.1 spec.
48
Incremental architecture: our approach

49

50
ProteicJS
https://github.com/proteus-h2020/proteic/

51
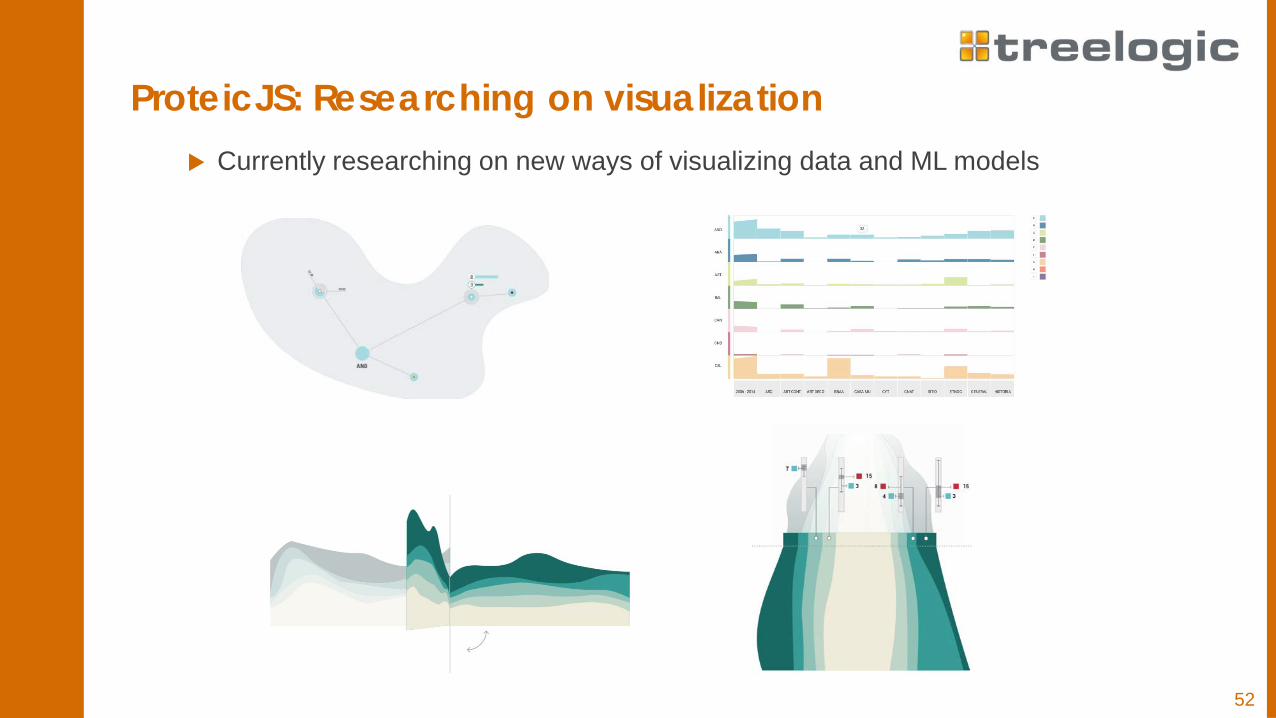
ProteicJS: Visualizations
52
ProteicJS: Researching on visualization Currently researching on new ways of visualizing data and ML models

53
ProteicJS & Apache Flink

54
How to get it all
https://github.com/proteus-h2020/proteus-docker

Advanced data science algorithms applied to scalable stream processing
David Piris Valenzuela
Nacho García Fernández
@0xNacho
@davidpiris

![Assisting with Scalable Scalable Vector Graphics and ... · SVG Scalable Vector Graphics [6] SSVG Scalable Scalable Vector Graphics [10] LWA Live Website Annotate [See Section 4]](https://img.pdfslide.net/doc/110x75/5fdccc690a10ab2c1e74ae97/assisting-with-scalable-scalable-vector-graphics-and-svg-scalable-vector-graphics.jpg)


























