Embed Size (px)
Citation preview

Aerospike Migration
Aerospike Deep Dive 2015/06/24
CyberZ 上原 誠

2 株式会社サイバーエージェント
自己紹介
・ ~2012年2月 某SIerでインフラ周りに従事 ・ 2012年3月 サイバーエージェント入社
- Amebaスマフォプラットフォームの構築
- 統合ログ解析基盤やオンラインデータベースの
インフラミドルウェア部分を担当
- Hadoop、HBase、Flume
・ 上原 誠 (@pioho07)
【名前】
【経歴】

3 株式会社サイバーエージェント

4 株式会社サイバーエージェント
5 株式会社サイバーエージェント 株式会社サイバーエージェント

6 株式会社サイバーエージェント
本日の内容

7 株式会社サイバーエージェント
本日の内容
・Intro1. What’s a Migration
・Intro2. What’s a Partition
・Intro3. What’s Partition Map
・Case1. ノード追加 (スケールアウト)

8 株式会社サイバーエージェント
Intro1. What’s a Migration
9 株式会社サイバーエージェント
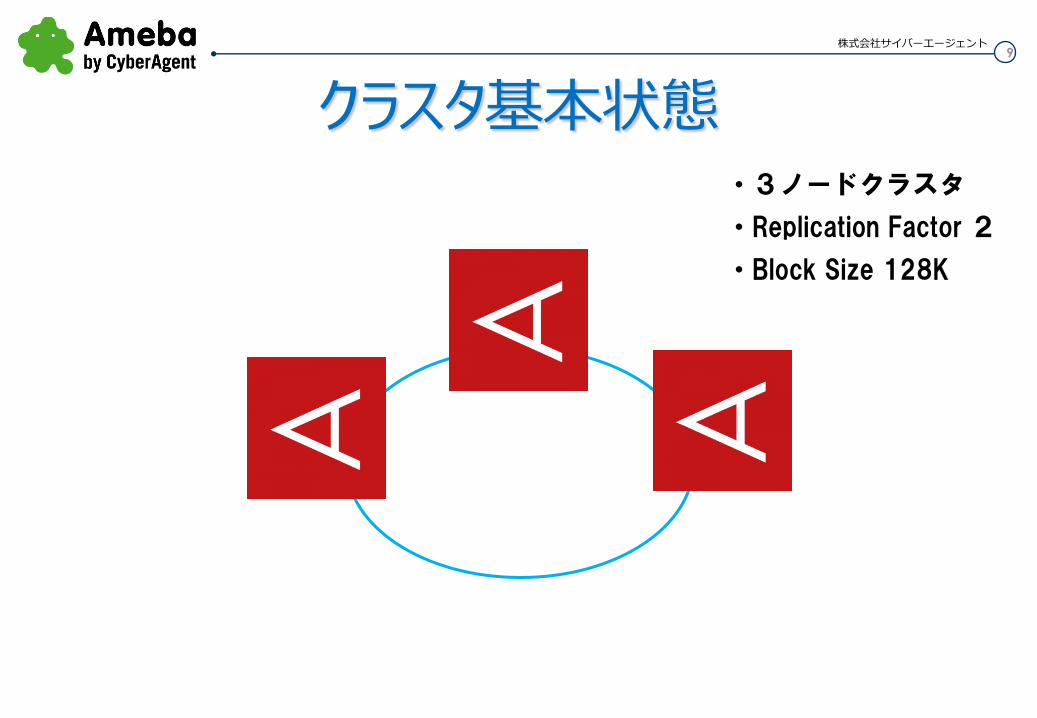
クラスタ基本状態 ・3ノードクラスタ
・Replication Factor 2
・Block Size 128K
10 株式会社サイバーエージェント
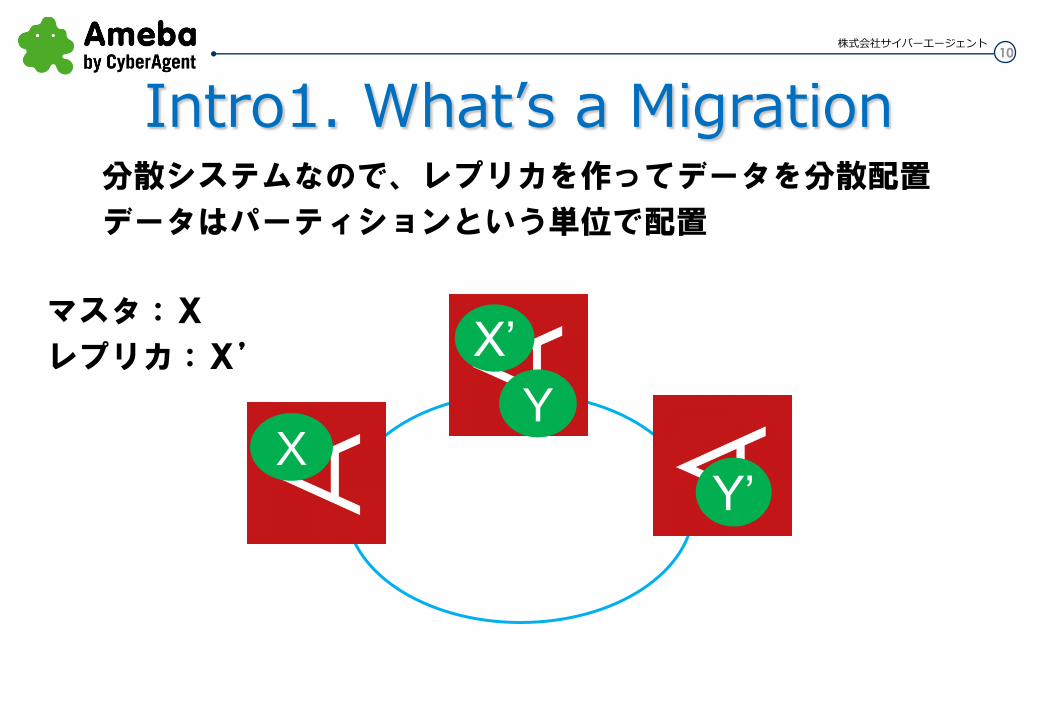
Intro1. What’s a Migration
X
分散システムなので、レプリカを作ってデータを分散配置
データはパーティションという単位で配置
X’
Y
Y’
マスタ:X
レプリカ:X’
11 株式会社サイバーエージェント

12 株式会社サイバーエージェント
すべて自動なので気にしなくていいです。

13 株式会社サイバーエージェント
Intro2. What’s a Partition

14
クラスタ
株式会社サイバーエージェント
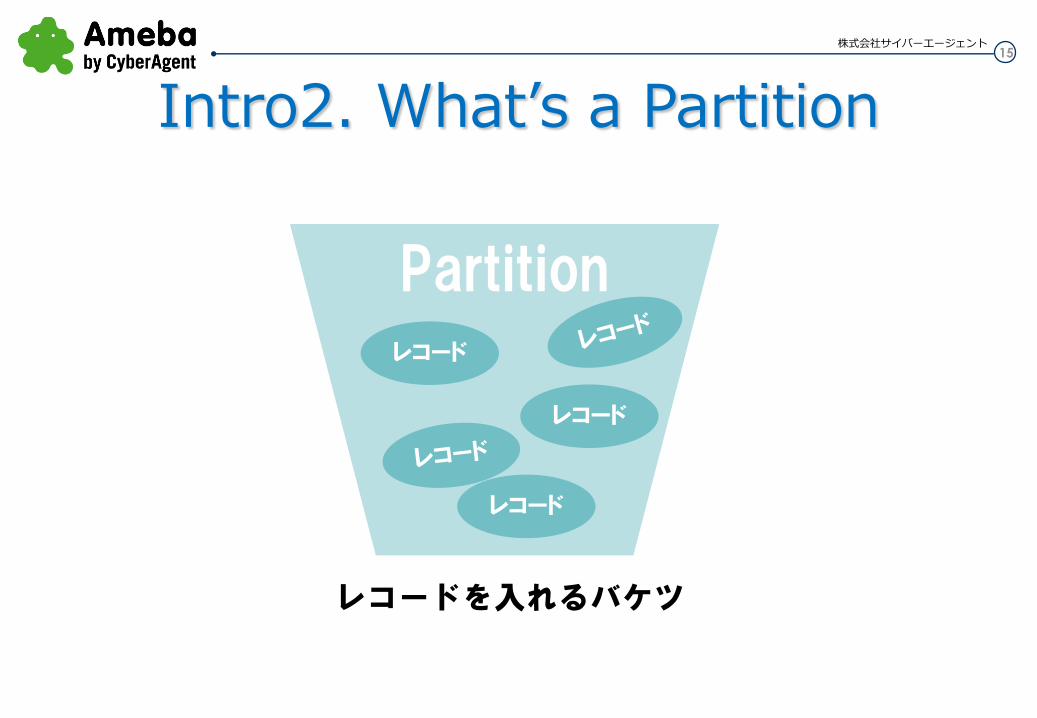
クラスタ内のデータを4096個に分割した単位
Intro2. What’s a Partition
・・・
15 株式会社サイバーエージェント
Partition レコード
レコード
レコード
レコードを入れるバケツ
Intro2. What’s a Partition

16 株式会社サイバーエージェント
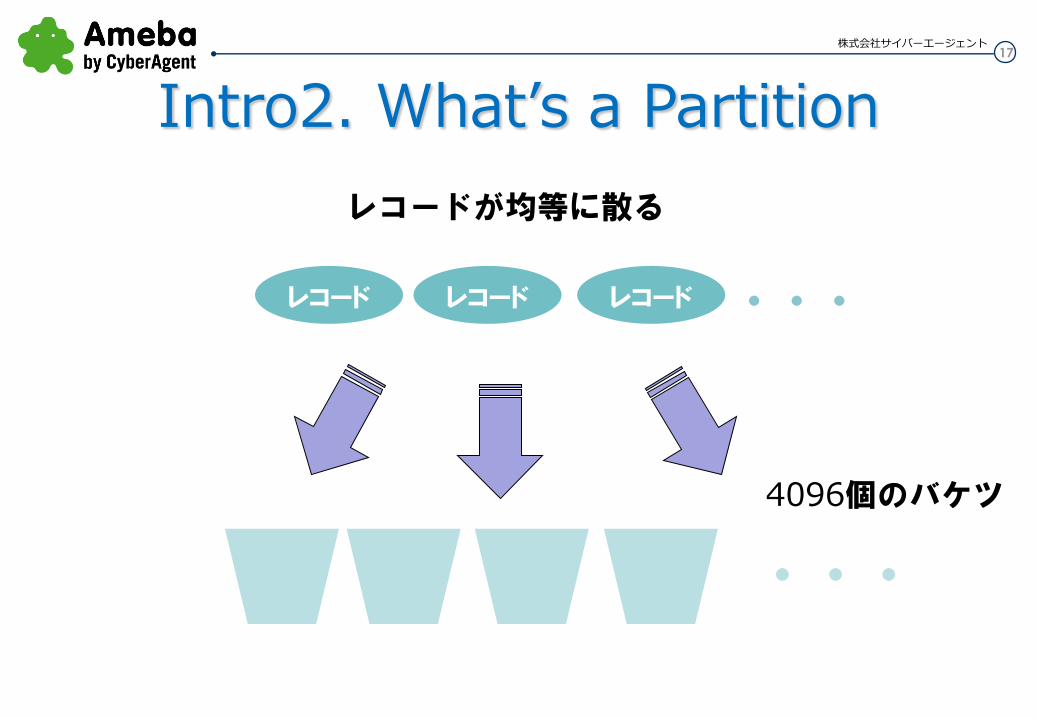
レコードを パーティションに均等に分散
Intro2. What’s a Partition
17 株式会社サイバーエージェント
・・・
レコード ・・・ レコード レコード
レコードが均等に散る
4096個のバケツ
Intro2. What’s a Partition

18 株式会社サイバーエージェント
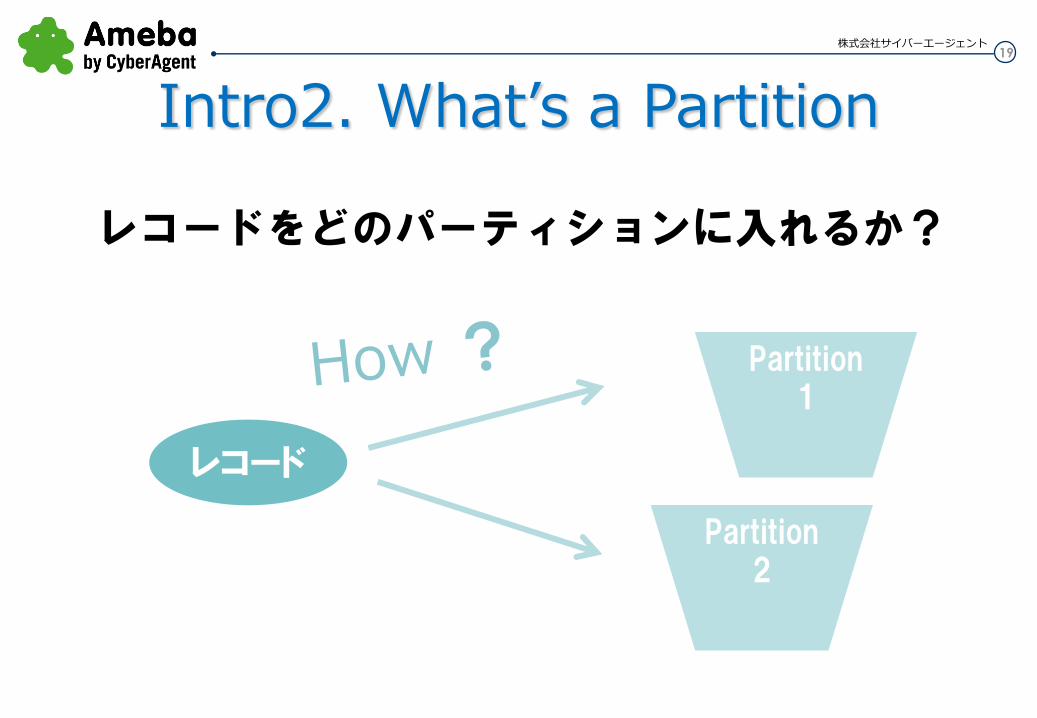
どう均等か?
Intro2. What’s a Partition
19 株式会社サイバーエージェント
レコードをどのパーティションに入れるか?
Partition1
レコード
Partition2
Intro2. What’s a Partition

20 株式会社サイバーエージェント
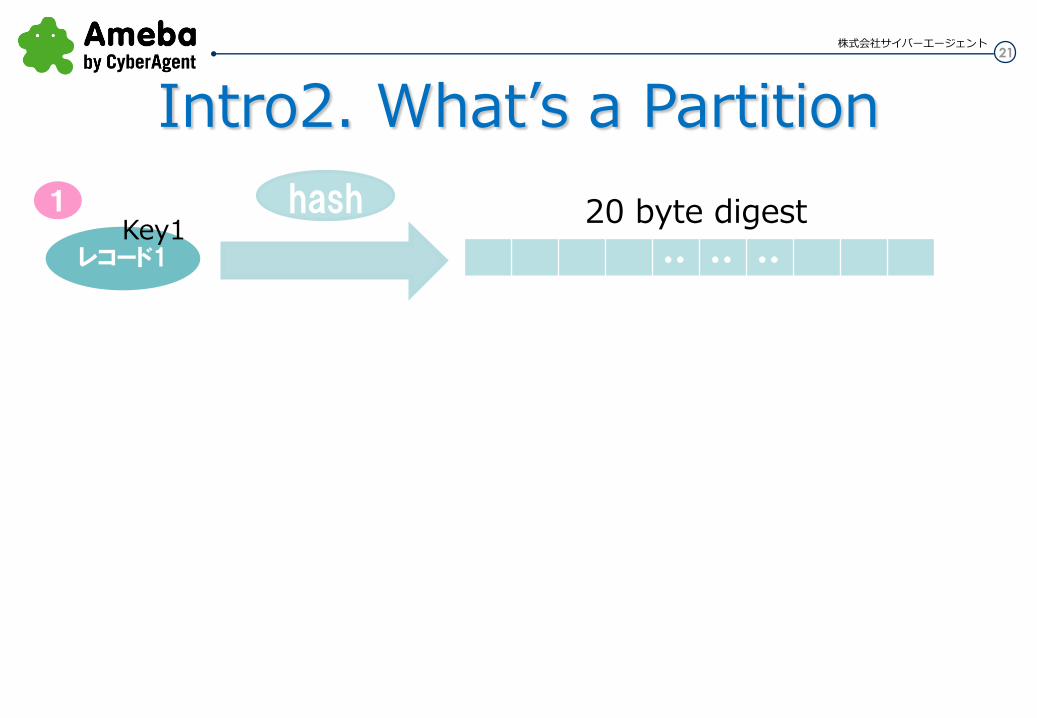
Every key is hashed into a 20 byte (fixed length) string using a hash function すべてのキーはハッシュ関数を使用して20バイト(固定長)の文字列にハッシュされる RIPEMD-160を使ってる。 128ビットだとセキュリティの問題があったとかで、256ビットだと計算重いので160ビットを使った感じ
1
パーティション ID の計算
Intro2. What’s a Partition
21
レコード1
株式会社サイバーエージェント
Key1 ・・ ・・ ・・
20 byte digest hash 1
Intro2. What’s a Partition

22 株式会社サイバーエージェント
12 bits of this hash are used to compute the partition id ハッシュ結果の先頭12ビットを、パーティションIDを計算するために使用する
2
パーティション ID の計算
Intro2. What’s a Partition
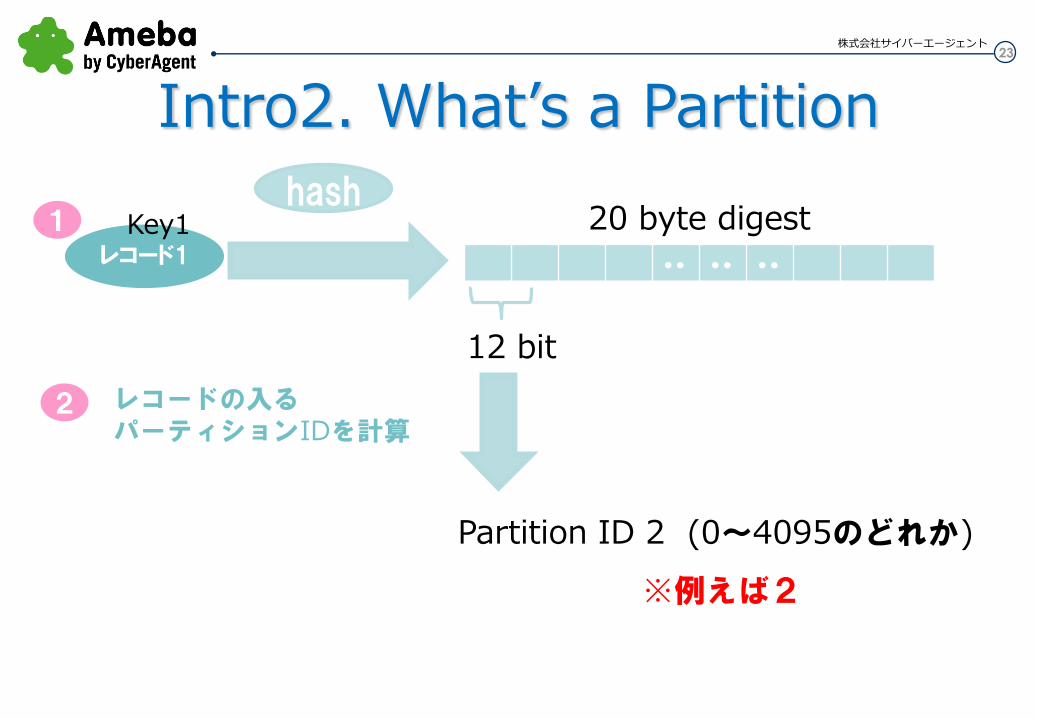
23
レコード1
株式会社サイバーエージェント
Key1
・・ ・・ ・・
20 byte digest
12 bit
Partition ID 2 (0~4095のどれか)
レコードの入る パーティションIDを計算
hash 1
2
Intro2. What’s a Partition
※例えば2
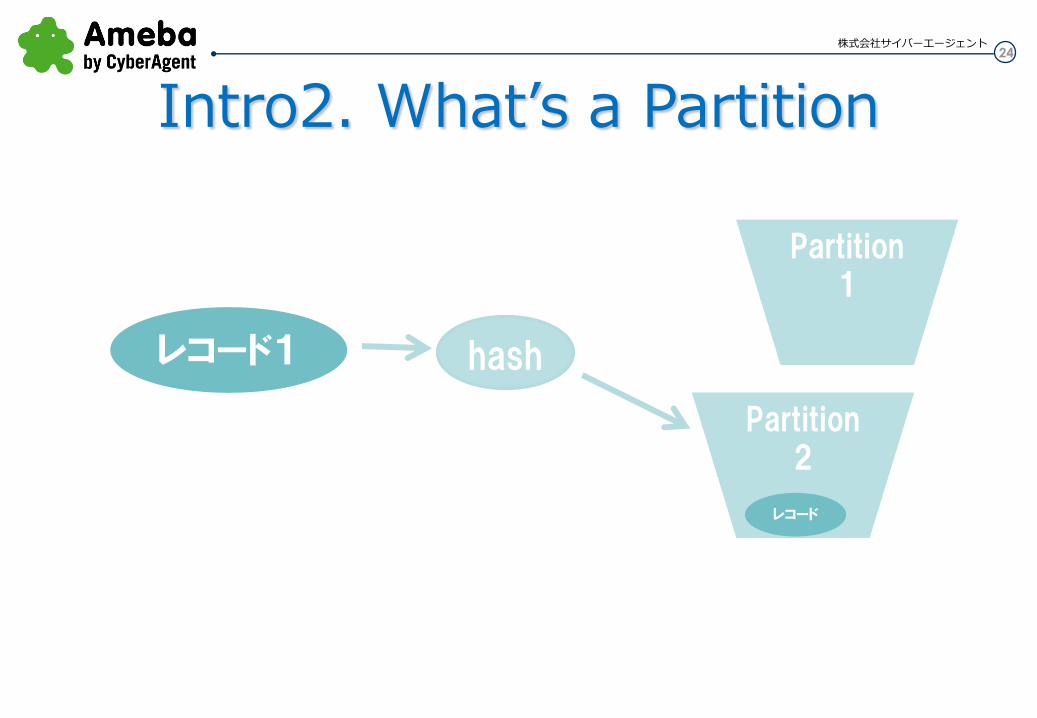
24 株式会社サイバーエージェント
Partition1
レコード1
Partition2
hash
レコード
Intro2. What’s a Partition

25 株式会社サイバーエージェント
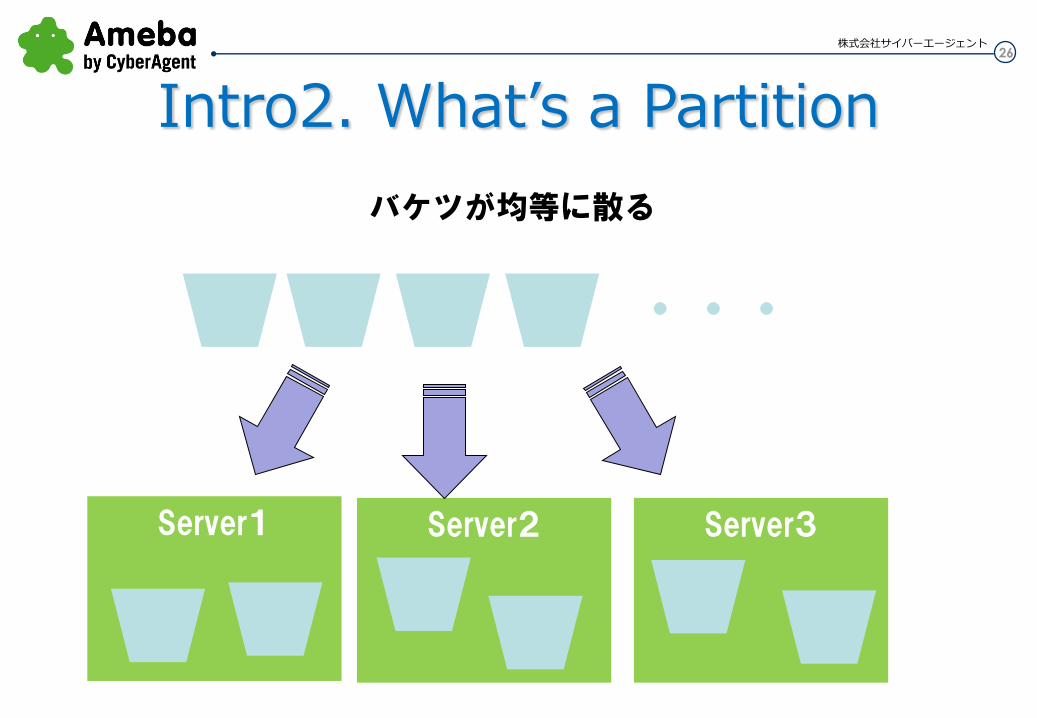
パーティションを サーバーに均等に分散する
Intro2. What’s a Partition
26 株式会社サイバーエージェント
Server1 Server2 Server3
・・・
バケツが均等に散る
Intro2. What’s a Partition
27 株式会社サイバーエージェント
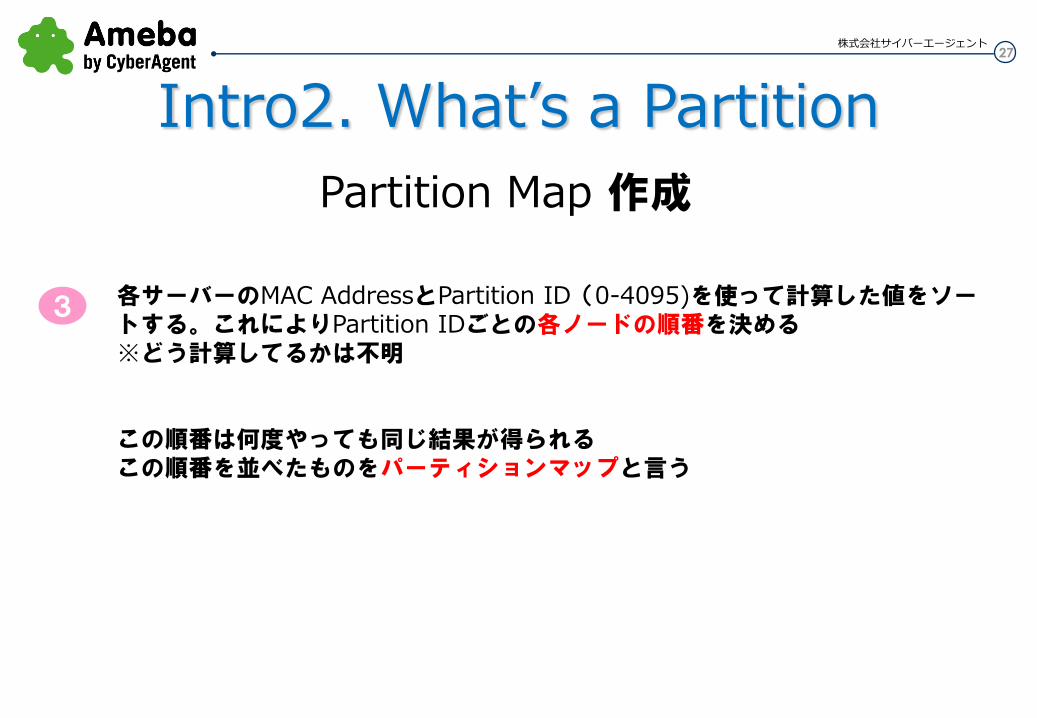
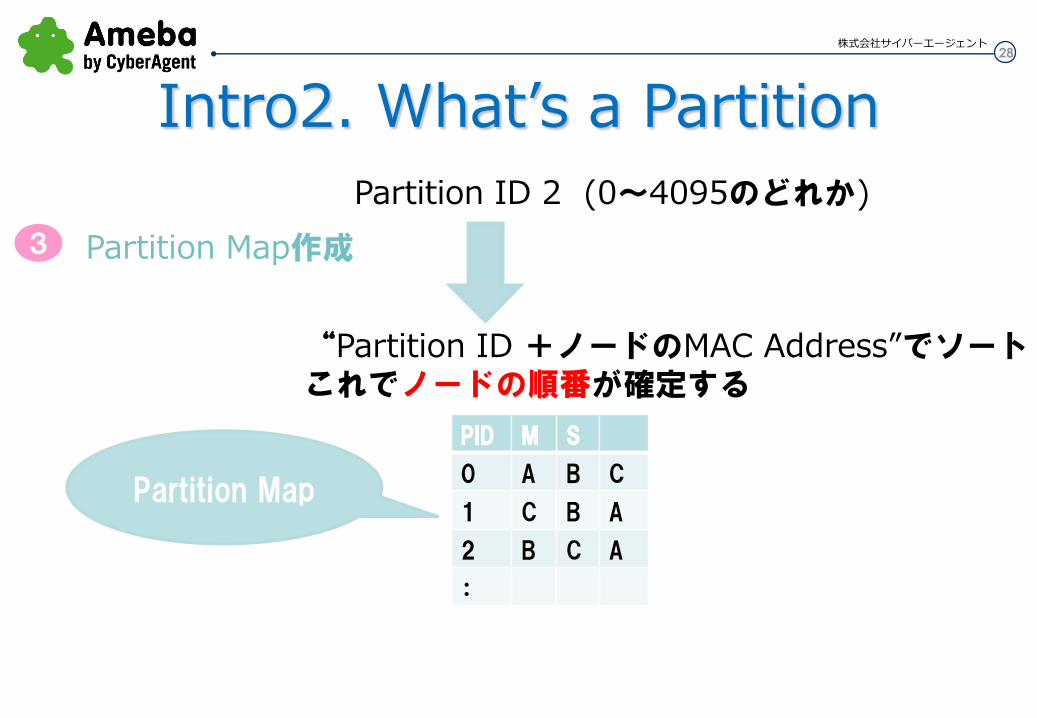
各サーバーのMAC AddressとPartition ID(0-4095)を使って計算した値をソートする。これによりPartition IDごとの各ノードの順番を決める ※どう計算してるかは不明 この順番は何度やっても同じ結果が得られる この順番を並べたものをパーティションマップと言う
3
Partition Map 作成
Intro2. What’s a Partition
28 株式会社サイバーエージェント
Partition ID 2 (0~4095のどれか)
Partition Map作成
“Partition ID +ノードのMAC Address”でソート これでノードの順番が確定する
PID M S
0 A B C
1 C B A
2 B C A
:
Partition Map
3
Intro2. What’s a Partition

29 株式会社サイバーエージェント
Intro3. What’s Partition Map
30 株式会社サイバーエージェント
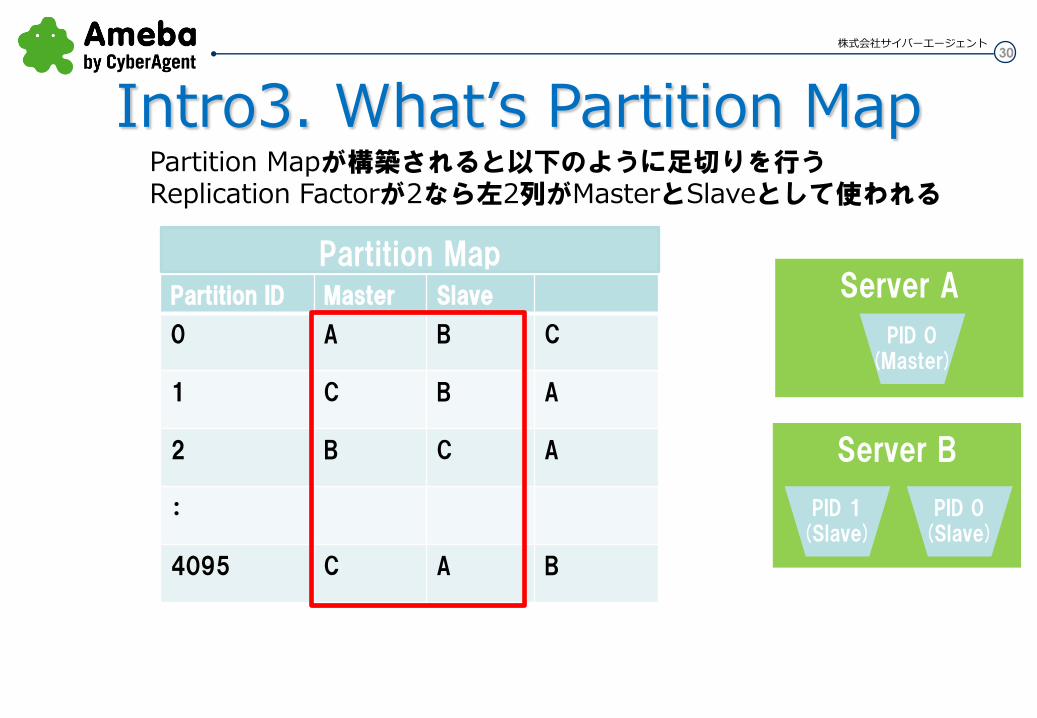
Partition ID Master Slave
0 A B C
1 C B A
2 B C A
:
4095 C A B
Partition Mapが構築されると以下のように足切りを行う Replication Factorが2なら左2列がMasterとSlaveとして使われる
Server B
Server A Partition Map
PID 0 (Master)
PID 0 (Slave)
PID 1 (Slave)
Intro3. What’s Partition Map
31
Client
株式会社サイバーエージェント
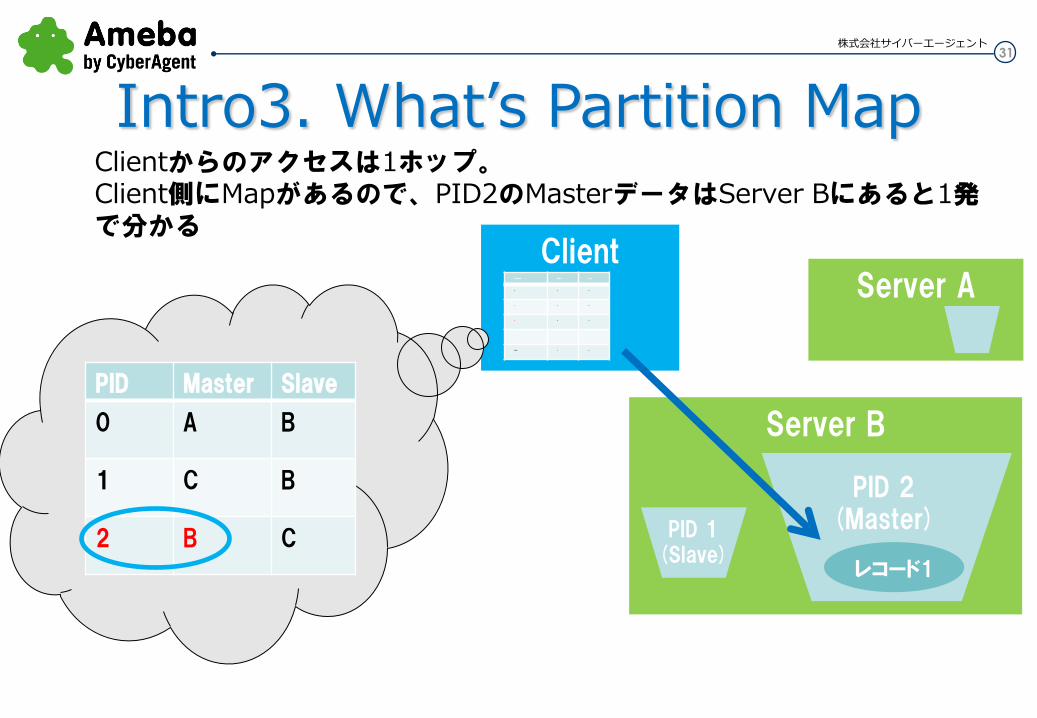
PID Master Slave
0 A B
1 C B
2 B C
Clientからのアクセスは1ホップ。 Client側にMapがあるので、PID2のMasterデータはServer Bにあると1発で分かる
Server B
Server A
PID 2 (Master) PID 1
(Slave) レコード1
Par t i tion ID Mas t er S l av e
0 A B
1 C B
2 B C
:
4095 C A
Intro3. What’s Partition Map

32
Server B
株式会社サイバーエージェント
・データのリバランスや配置はPartitionの単位で行われる 毎秒Clientからサーバーにアクセス、Partition MapのGenerationが新しければ自身のMapを更新 ・ハッシュ関数を使って均等に分散させる。 オフィシャルだと1~2%程度の誤差 ・手動シャーディング不要、パーティション分割は自動 オートシャーディング、オートバランシング
Aerospike Smart Partition Algorithm
Server A
P P Server C
P
P P P

33 株式会社サイバーエージェント
Case1. ノード追加 (スケールアウト)
34 株式会社サイバーエージェント
A
B
C
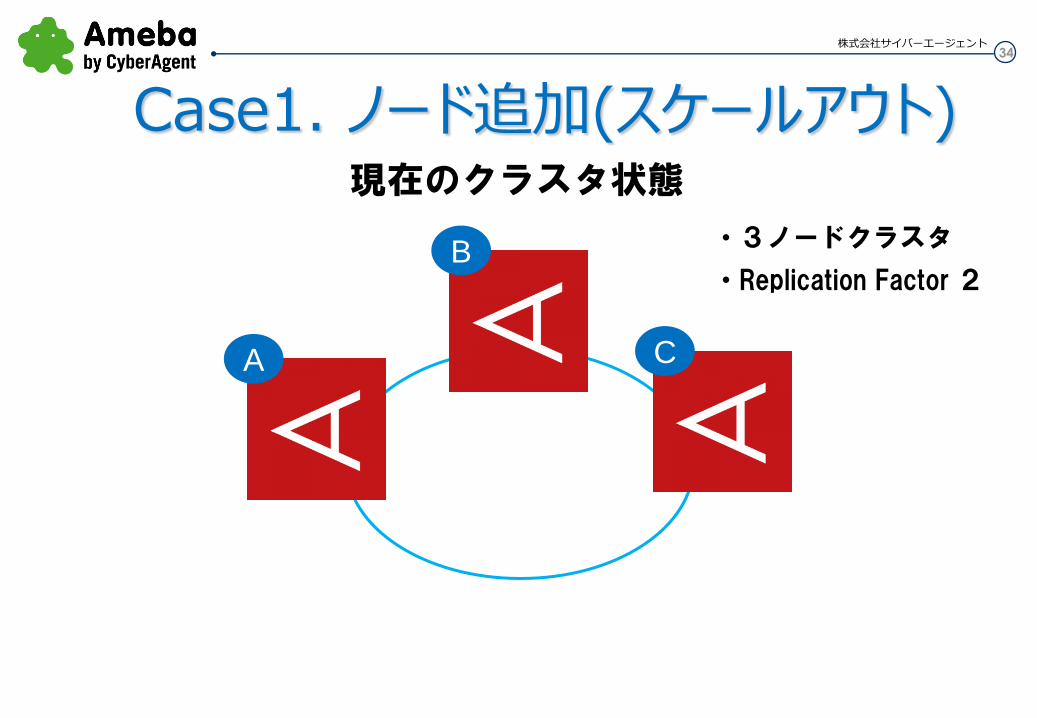
Case1. ノード追加(スケールアウト) 現在のクラスタ状態
・3ノードクラスタ
・Replication Factor 2

35 株式会社サイバーエージェント
PartitionID Master Slave
0 A B C
1 C B A
2 B C A
3 A C B
4 C A B
:
:
4095 C A B
Case1. ノード追加(スケールアウト) 現在のPartition Map
Partition Map
36 株式会社サイバーエージェント
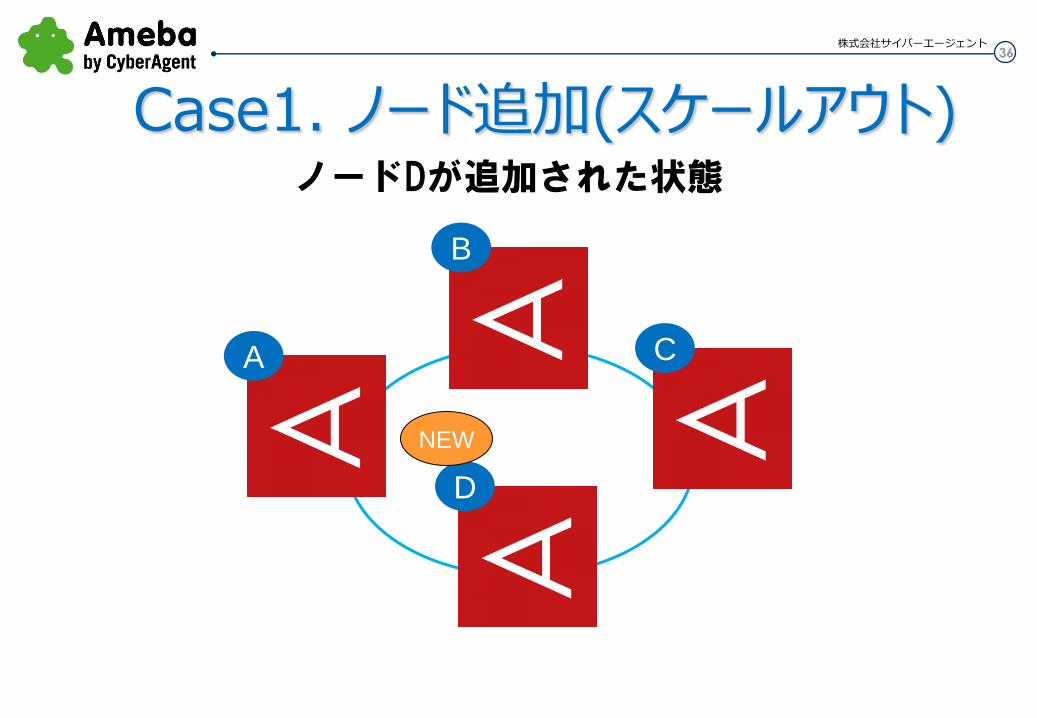
A
B
C
D
Case1. ノード追加(スケールアウト) ノードDが追加された状態
NEW
37 株式会社サイバーエージェント
A
B
C
D
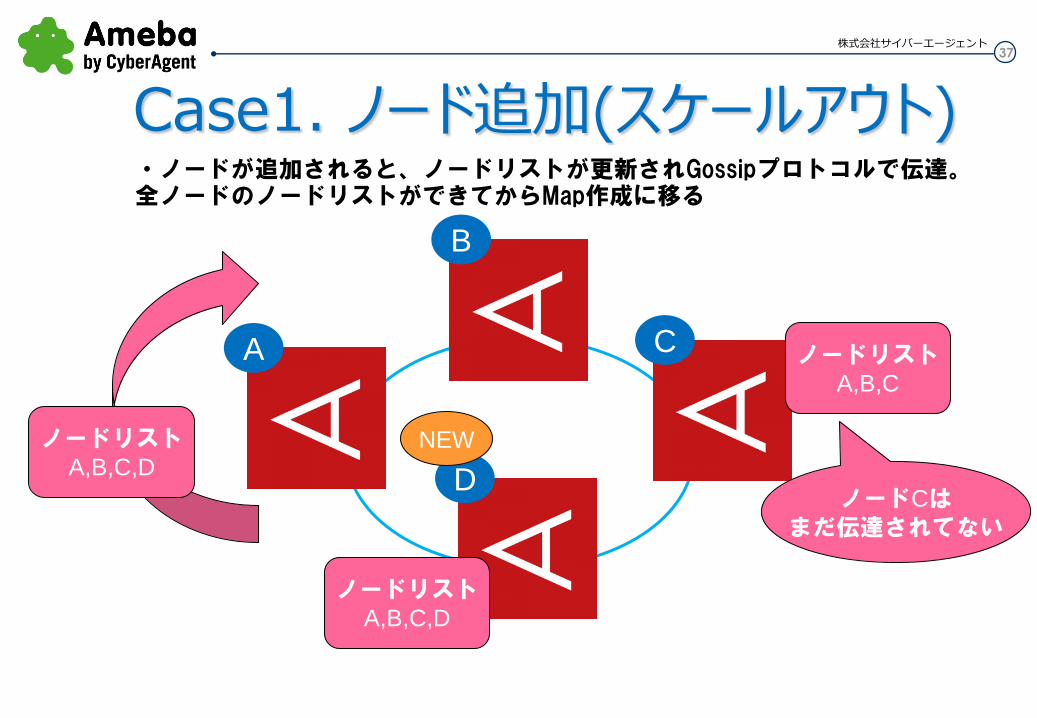
Case1. ノード追加(スケールアウト) ・ノードが追加されると、ノードリストが更新されGossipプロトコルで伝達。全ノードのノードリストができてからMap作成に移る
ノードリスト
A,B,C
ノードリスト
A,B,C,D
ノードCは
まだ伝達されてない
ノードリスト
A,B,C,D NEW

38 株式会社サイバーエージェント
PartitionID Master Slave
0 A D B C
1 C B D A
2 B D C A
3 A C B D
4 D C A B
:
:
4095 C A D B
Case1. ノード追加(スケールアウト) ノードDが追加された状態のPartition Map
・Introで行ったようにMapを作成する
順番はMACアドレスを付加した形でソートするので、PIDごとの既存ノードの順序は変わらない。
赤字のように新規ノードDがその間に入ってくる
39 株式会社サイバーエージェント
PartitionID Master Slave
0 A D B C
1 C B D A
2 B D C A
3 A C B D
4 D C A B
:
:
4095 C A D B
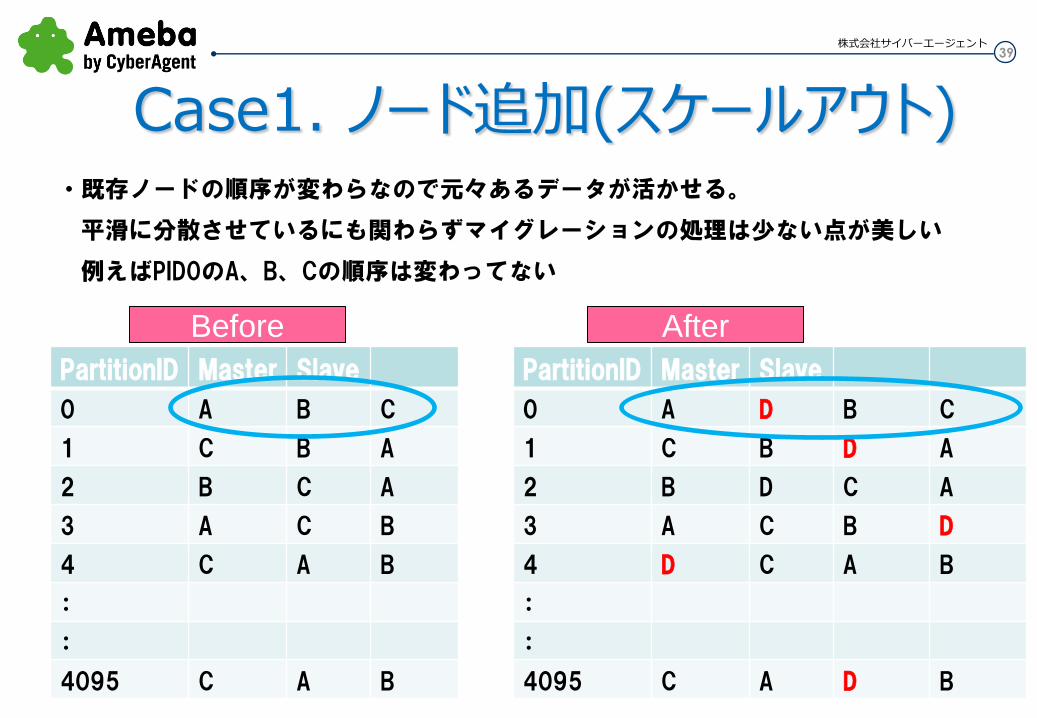
Case1. ノード追加(スケールアウト) ・既存ノードの順序が変わらなので元々あるデータが活かせる。
平滑に分散させているにも関わらずマイグレーションの処理は少ない点が美しい
例えばPID0のA、B、Cの順序は変わってない
PartitionID Master Slave
0 A B C
1 C B A
2 B C A
3 A C B
4 C A B
:
:
4095 C A B
Before After
40 株式会社サイバーエージェント
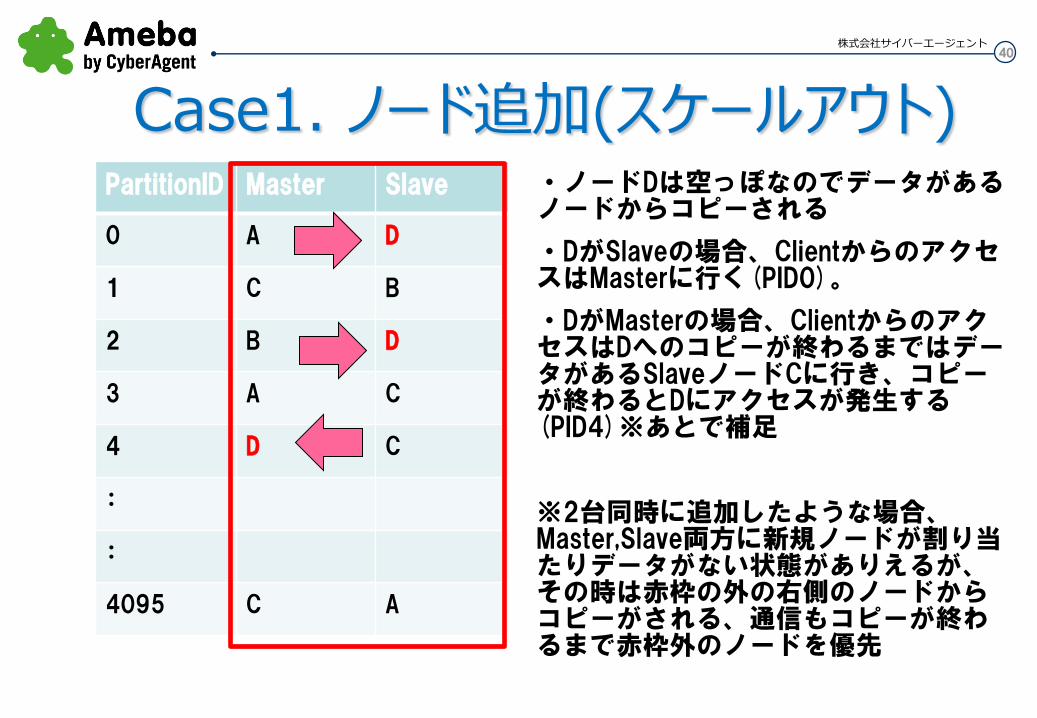
PartitionID Master Slave
0 A D
1 C B
2 B D
3 A C
4 D C
:
:
4095 C A
・ノードDは空っぽなのでデータがあるノードからコピーされる
・DがSlaveの場合、ClientからのアクセスはMasterに行く(PID0)。
・DがMasterの場合、ClientからのアクセスはDへのコピーが終わるまではデータがあるSlaveノードCに行き、コピーが終わるとDにアクセスが発生する(PID4)※あとで補足
※2台同時に追加したような場合、Master,Slave両方に新規ノードが割り当たりデータがない状態がありえるが、その時は赤枠の外の右側のノードからコピーがされる、通信もコピーが終わるまで赤枠外のノードを優先
Case1. ノード追加(スケールアウト)
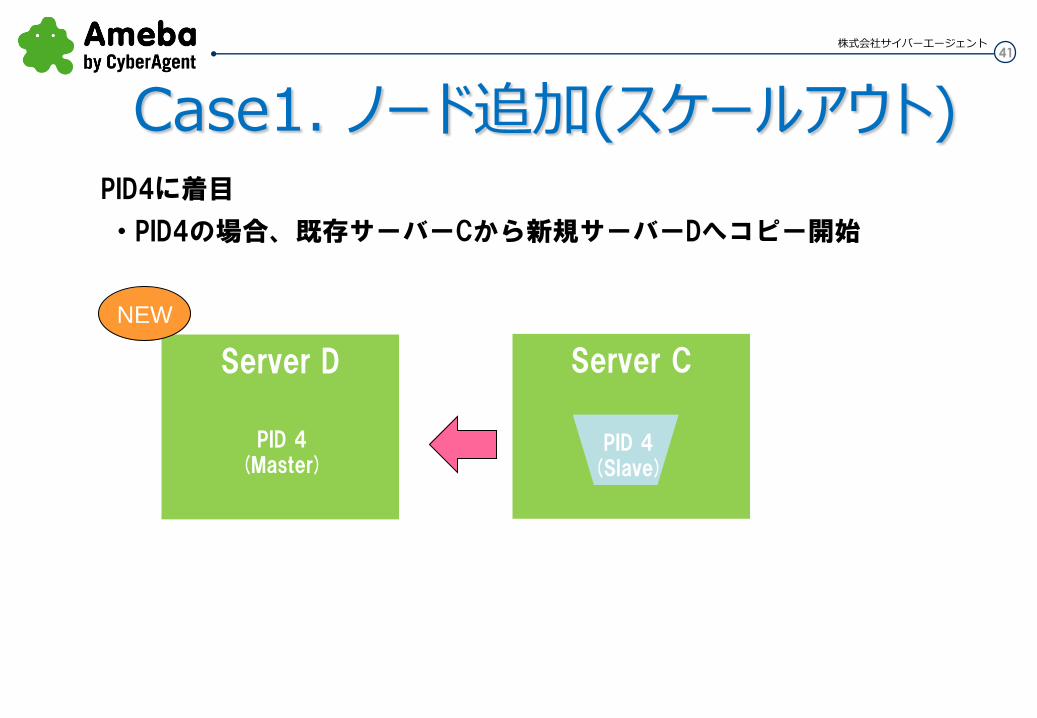
41 株式会社サイバーエージェント
・PID4の場合、既存サーバーCから新規サーバーDへコピー開始
Case1. ノード追加(スケールアウト)
Server C Server D
PID 4 (Slave)
PID4に着目
PID 4 (Master)
NEW
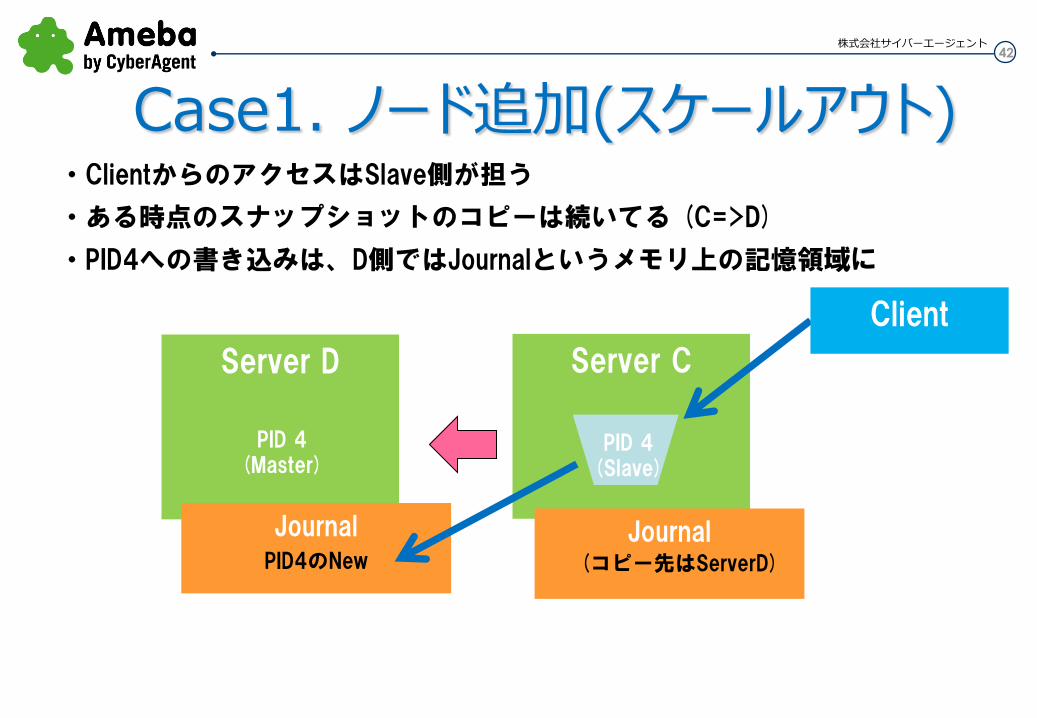
42 株式会社サイバーエージェント
・ClientからのアクセスはSlave側が担う
・ある時点のスナップショットのコピーは続いてる (C=>D)
・PID4への書き込みは、D側ではJournalというメモリ上の記憶領域に
Case1. ノード追加(スケールアウト)
Server C Server D
PID 4 (Slave)
PID 4 (Master)
Client
Journal (コピー先はServerD)
Journal PID4のNew
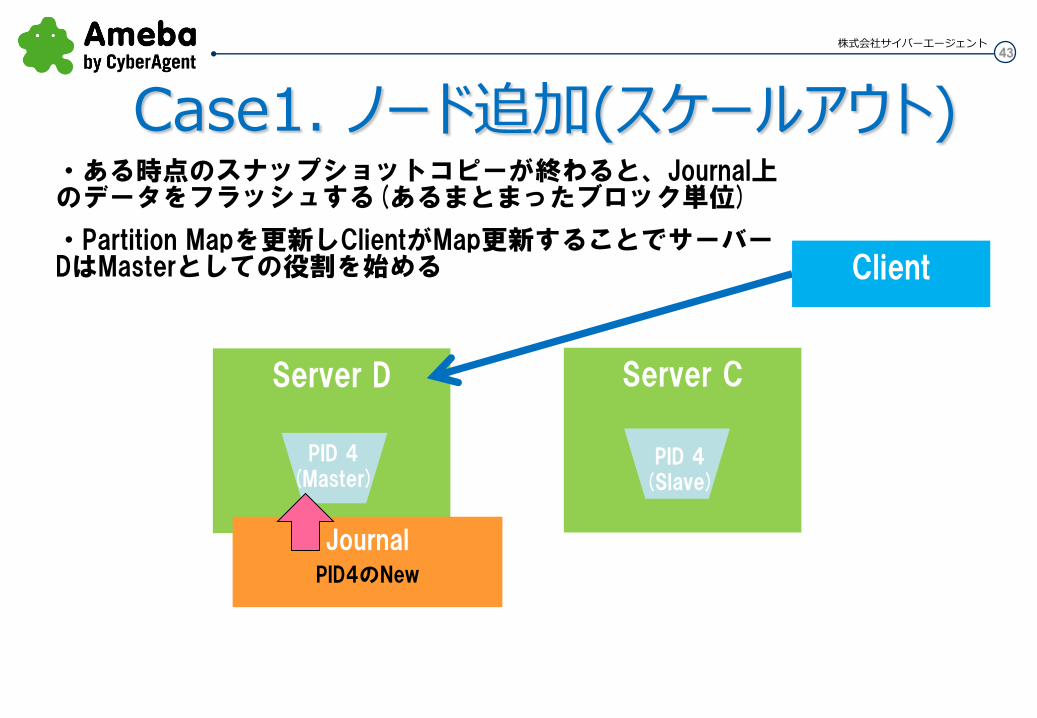
43 株式会社サイバーエージェント
・ある時点のスナップショットコピーが終わると、Journal上のデータをフラッシュする(あるまとまったブロック単位)
・Partition Mapを更新しClientがMap更新することでサーバーDはMasterとしての役割を始める
Case1. ノード追加(スケールアウト)
Server C Server D
PID 4 (Slave)
Client
Journal PID4のNew
PID 4 (Master)
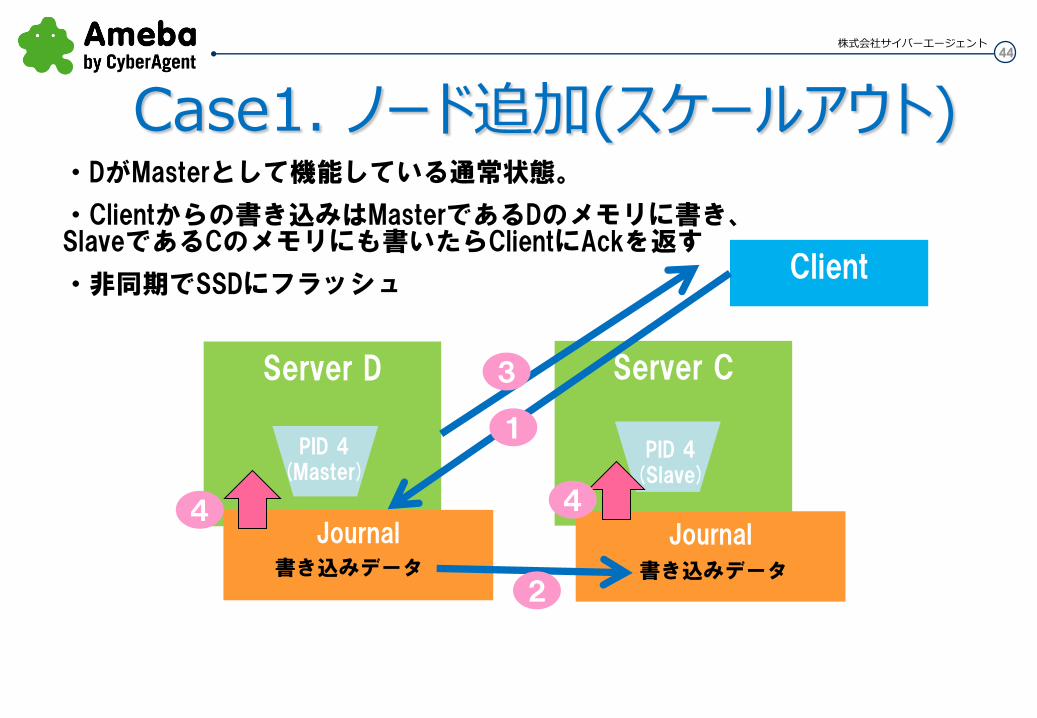
44 株式会社サイバーエージェント
・DがMasterとして機能している通常状態。
・Clientからの書き込みはMasterであるDのメモリに書き、SlaveであるCのメモリにも書いたらClientにAckを返す
・非同期でSSDにフラッシュ
Case1. ノード追加(スケールアウト)
Server C Server D
PID 4 (Slave)
Client
Journal 書き込みデータ
PID 4 (Master)
Journal
書き込みデータ
3
1
2
4 4
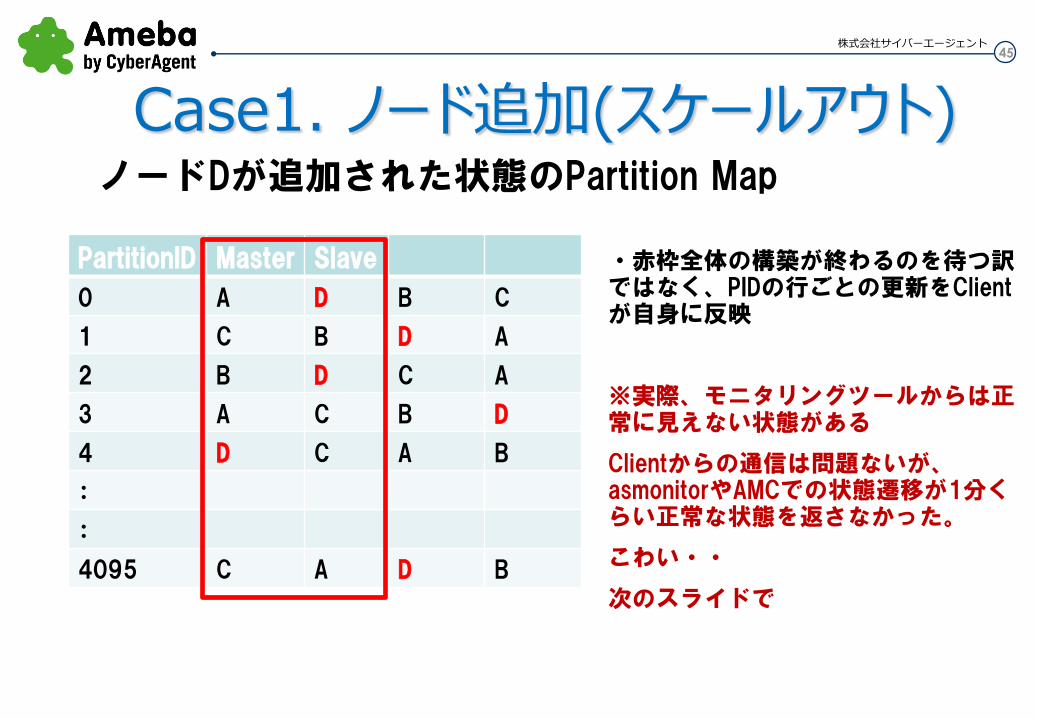
45 株式会社サイバーエージェント
PartitionID Master Slave
0 A D B C
1 C B D A
2 B D C A
3 A C B D
4 D C A B
:
:
4095 C A D B
Case1. ノード追加(スケールアウト)
・赤枠全体の構築が終わるのを待つ訳ではなく、PIDの行ごとの更新をClientが自身に反映
※実際、モニタリングツールからは正常に見えない状態がある
Clientからの通信は問題ないが、asmonitorやAMCでの状態遷移が1分くらい正常な状態を返さなかった。
こわい・・
次のスライドで
ノードDが追加された状態のPartition Map
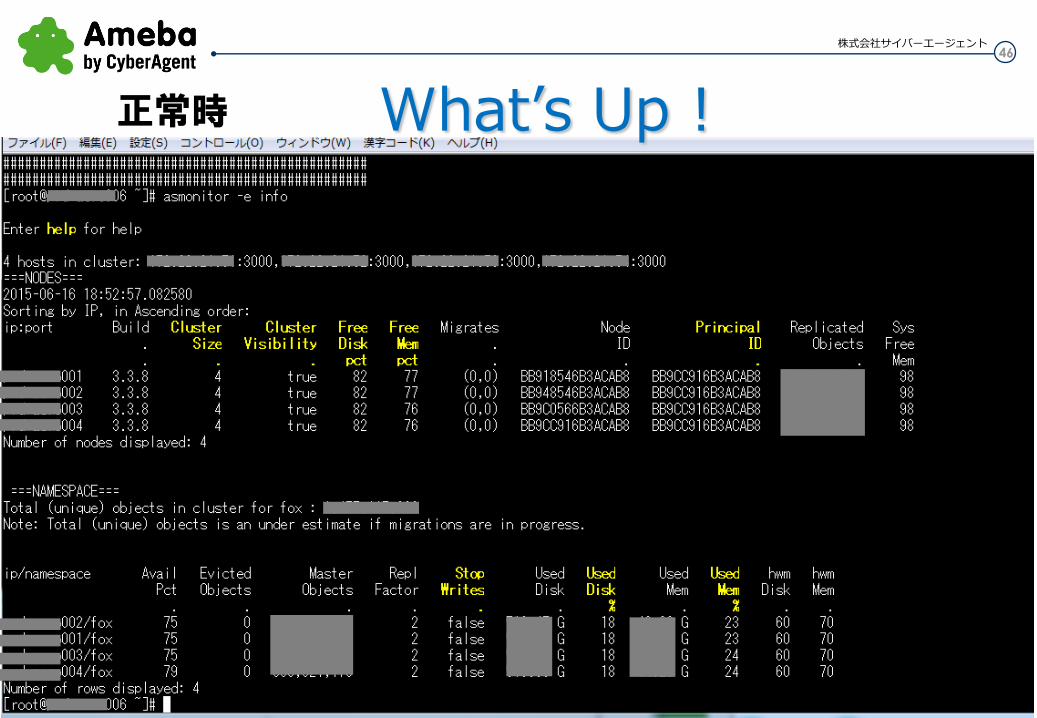
46 株式会社サイバーエージェント
正常時 What’s Up !

47 株式会社サイバーエージェント
・PIDごとの更新が終わるとクライアントのPartition Mapが更新される
赤枠全体の構築が終わるのを待つ訳ではなく、PIDの行ごとに更新をクライアントに反映
※実際、モニタリングツールからは正常に見えない状態があった。asmonitorやAMCでの状態遷移が1分くらい正常な状態を返さなかった。クライアントからの通信はほぼ問題なし。
こわい・・
ノード追加直後 What’s Up !
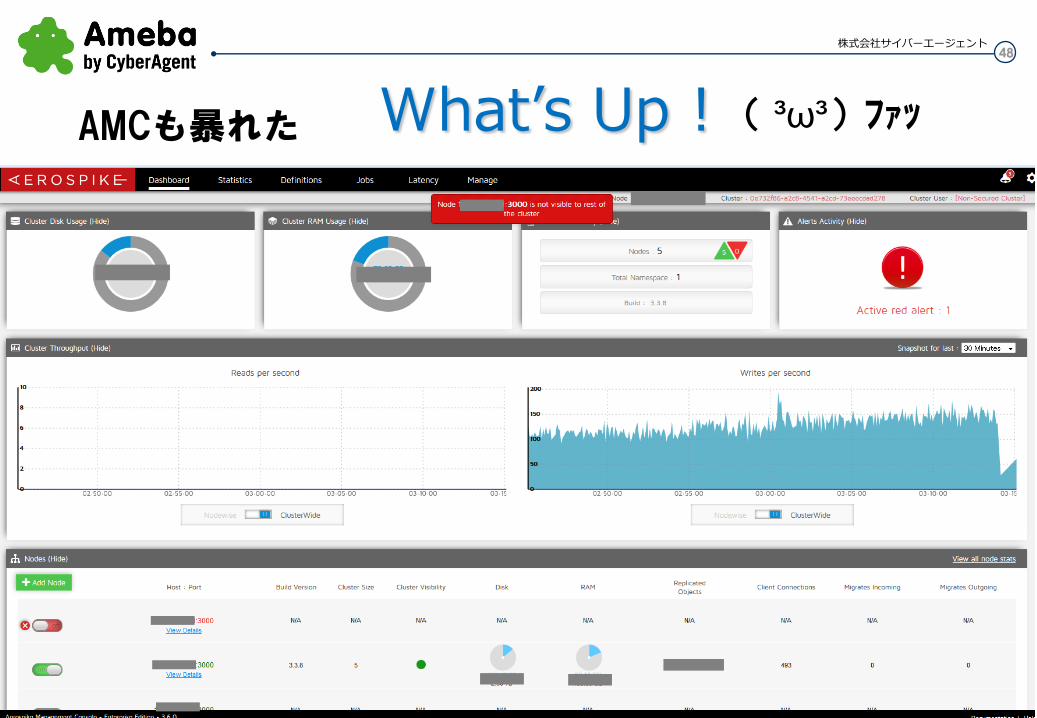
48 株式会社サイバーエージェント
What’s Up ! AMCも暴れた ( ³ω³)ファッ
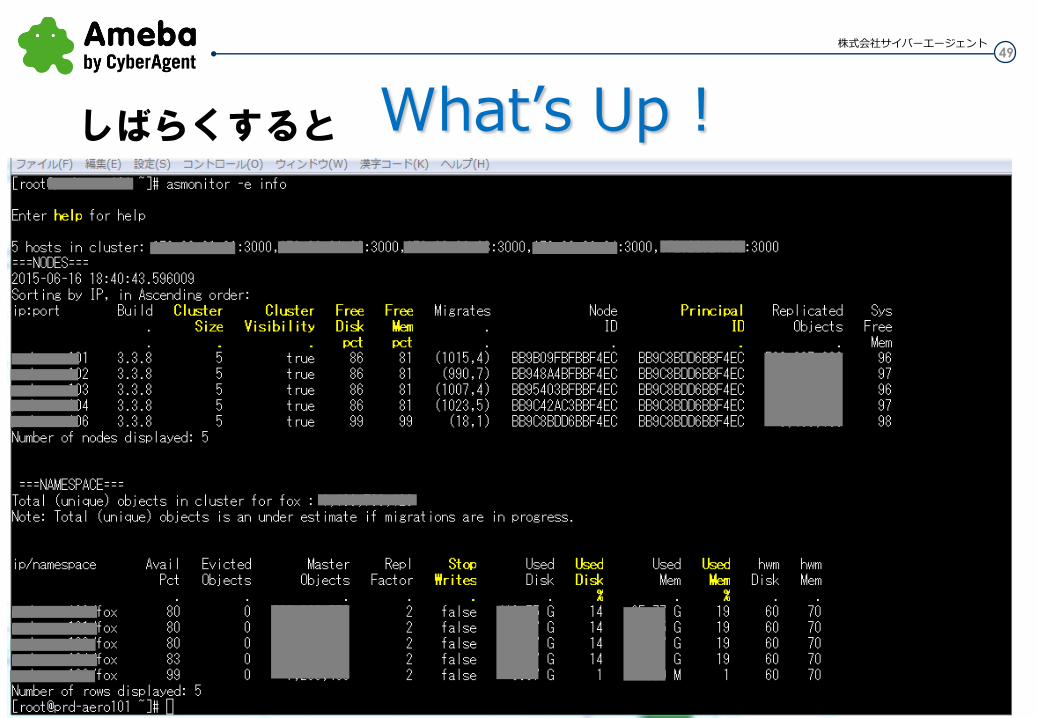
49 株式会社サイバーエージェント
What’s Up ! しばらくすると
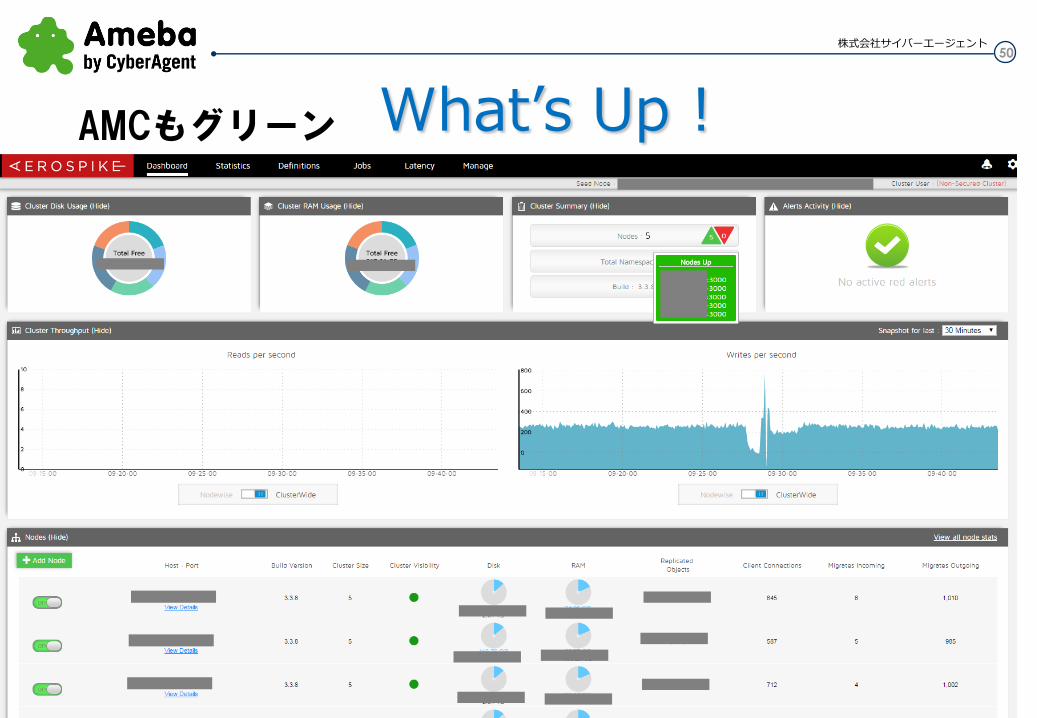
50 株式会社サイバーエージェント
What’s Up ! AMCもグリーン

51 株式会社サイバーエージェント
1分くらい 問題ないと言えば問題ない
なおしてほしいけど

52 株式会社サイバーエージェント
What’s Up !
それよりも マイグレーション中の注意点↓

53 株式会社サイバーエージェント
What’s Up ! ノード追加時の
Cacti
54 株式会社サイバーエージェント
PartitionID Master Slave
0 A D B C
1 C B D A
2 B D C A
3 A C B D
4 D C A B
:
:
4095 C A D B
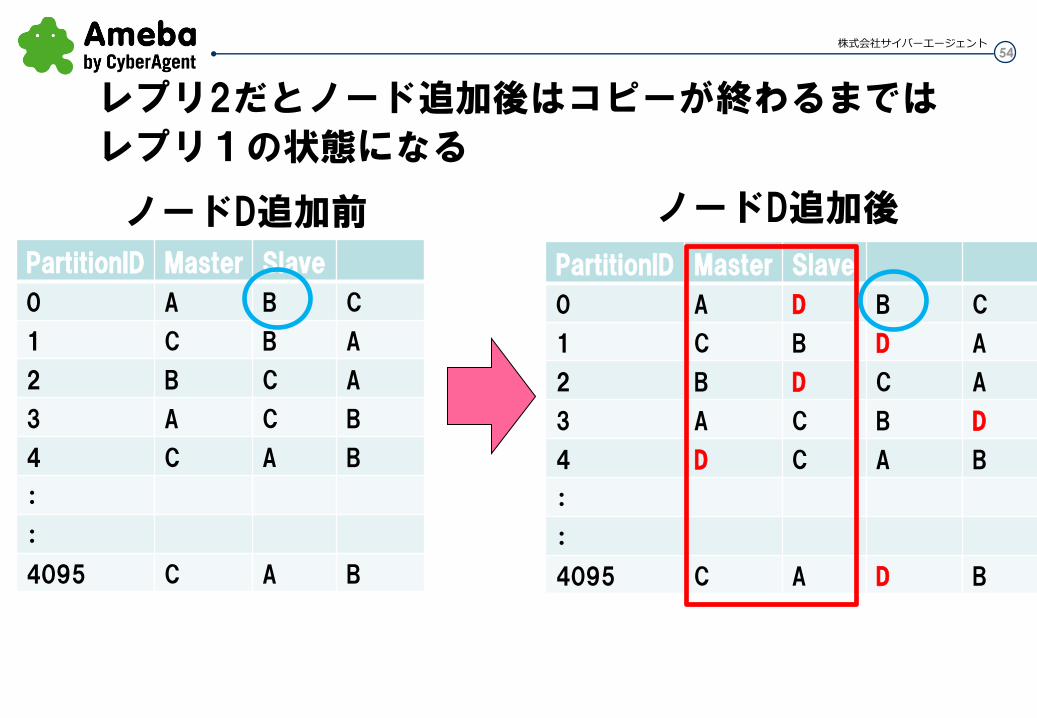
レプリ2だとノード追加後はコピーが終わるまでは
レプリ1の状態になる
PartitionID Master Slave
0 A B C
1 C B A
2 B C A
3 A C B
4 C A B
:
:
4095 C A B
ノードD追加前 ノードD追加後

55 株式会社サイバーエージェント
マイグレーション中はレプリ1になる

56 株式会社サイバーエージェント
Replication Factor は3にしよう
デフォは2

57 株式会社サイバーエージェント
実際マイグレーションは18時間くらい
マイグレ速度調整なし
クラスタ容量2TBくらい
3台=>4台 にした時
鎧なしはきつい><
issue上げました(ぼそ・・)

58 株式会社サイバーエージェント
ご清聴ありがとうございました!
俺

59 株式会社サイバーエージェント
参考資料
https://www.aerospike.com/docs/architecture/clustering.html
https://www.aerospike.com/docs/architecture/data-distribution.html
http://www.slideshare.net/PeterMilne1/principles-of-high-load-vilnius-january-2015





























