Embed Size (px)
Citation preview

Sistemas DistribuídosAlta Disponibilidade utilizando Pacemaker
Frederico MadeiraLPIC1, LPIC2, [email protected]

“Um sistema de alta disponibilidade é aquele que utiliza mecanismos de detecção, recuperação e mascaramento de falhas, visando manter o funcionamento dos serviços durante o máximo de tempo possível, inclusive no decurso de manutenções programadas”
Definição – Alta Disponibilidade

“Disponibilidade refere-se a capacidade de um usuário de determinado sistema acessar, incluir ou modificar os dados existentes em qualquer intervalo de tempo. Caso, por qualquer que seja o motivo, um usuário não tenha acesso, é dito então que ele está indisponível, sendo o tempo total de indisponibilidade conhecido pelo termo downtime.”
Definição – Disponibilidade
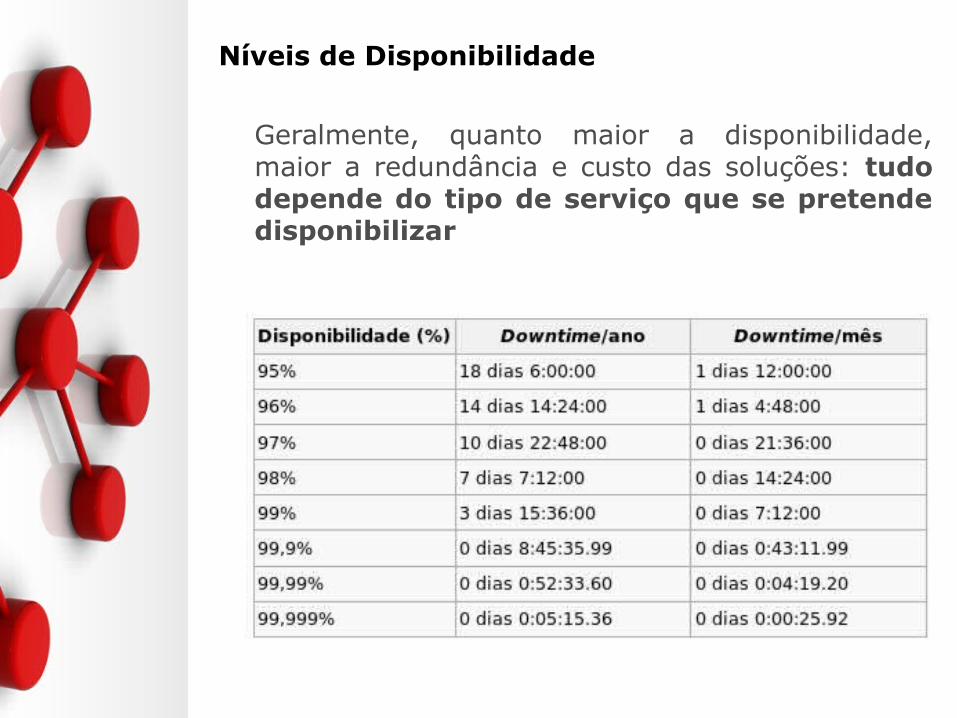
•Níveis de Disponibilidade
Geralmente, quanto maior a disponibilidade, maior a redundância e custo das soluções: tudo depende do tipo de serviço que se pretende disponibilizar

• Infraestrutura do Cluster (CMAN, DLM, Fencing)
– Provê as principais funções para que os nós trabalhem juntos como um cluster
– Gerenciamento dos arquivos de configuração, gerenciamento das associações (membership), lock management e fencing
• Gerenciamento de Serviços HA (rgmanager)– Provê failover dos serviços de um cluster para o outro
quando o nó fica inoperante
Principais Componentes

• Ferramentas de Administralçao do Cluster
(pacemaker, CCS, Conga)
– Ferramentas de configuração e gerenciamento para configurar e criar clusters
– Gerencia a alta disponibilidade para uso dos componentes do cluster, serviços e storage
Principais Componentes
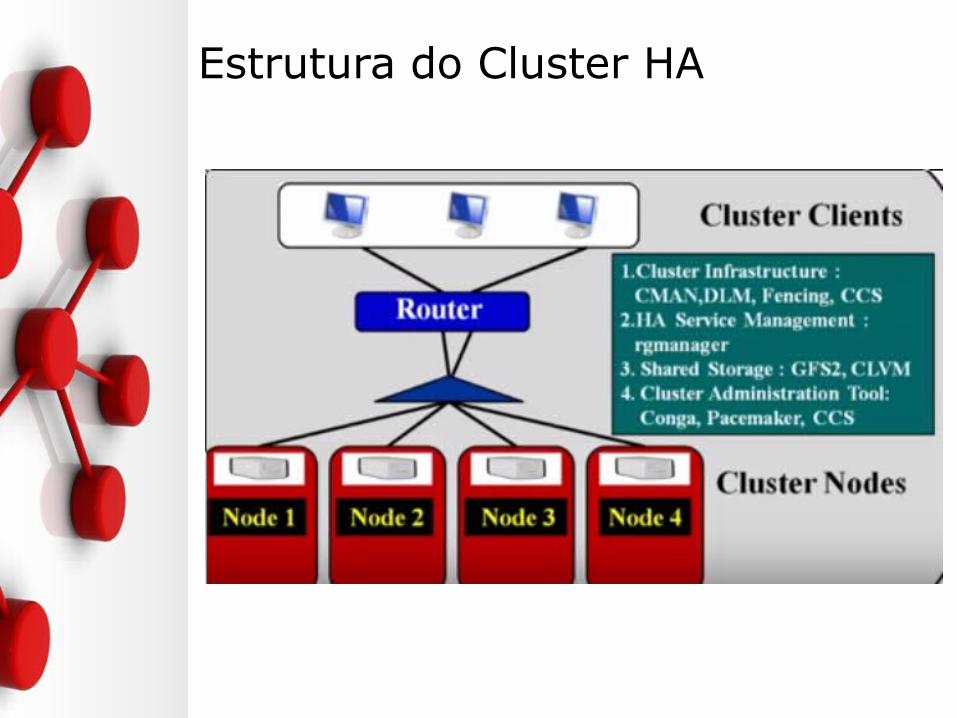
Estrutura do Cluster HA
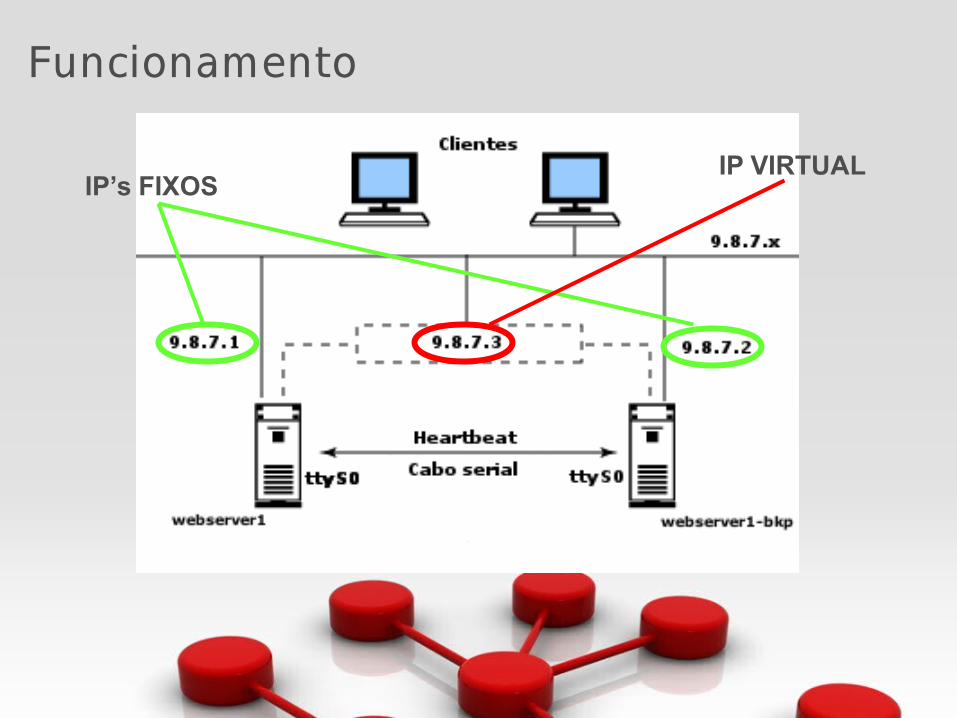
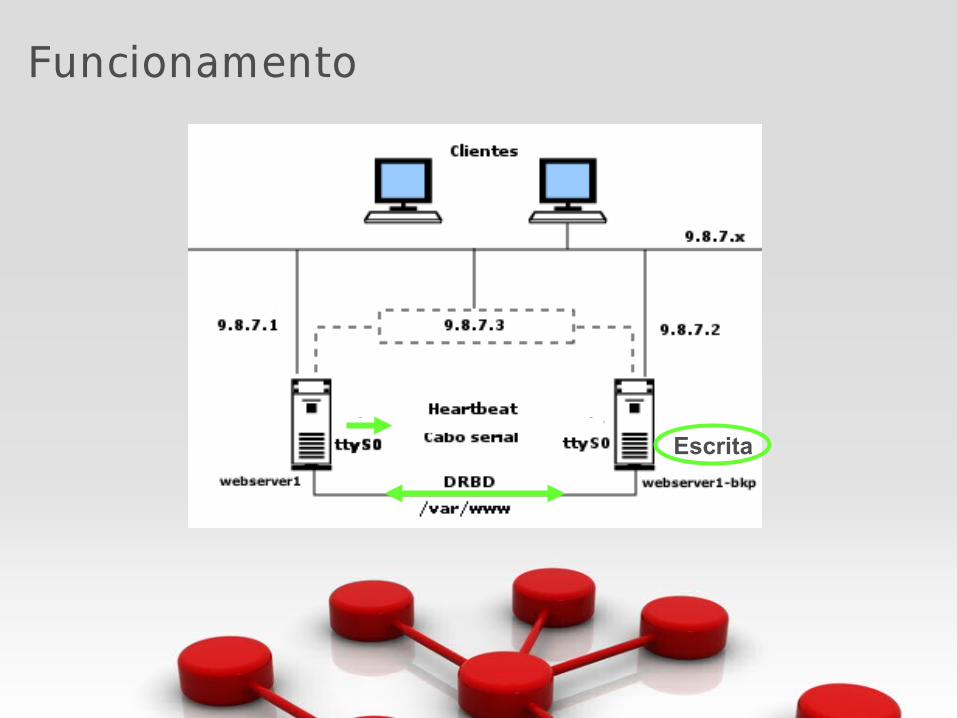
Funcionamento
IP VIRTUALIP’s FIXOS

Instalação Cluster Ativo/Passivo
➔ Instalação do Pacemaker stack e ferramenta pcs nos dois nós
yum install pacemaker pcs cman
➔ Inicialização do serviço e definição para iniciar no boot do servidor
Centos 7
systemctl enable pcsd.service
systemctl start pcsd.service
systemctl enable pacemaker.service
Centos 6
/etc/init.d/pcsd start
chkconfig pcsd on
chkconfig pacemaker on

Instalação
➔ Depois da instalação dos pacotes, um novo usuário chamado hacluster foi criado. Este usuário é usado para sincronização da configuração e gerenciamento dos serviços nos nós. É necessário definir a mesma senha em todos os servidores
[root@node1 ~]# passwd hacluster
➔ Desativando o Firewall (esta ação só deve ser feita no lab em sala, em implementações deve ser realizado os ajustes nas regras do firewall)
[root@node1 ~]# iptables -F
[root@node1 ~]# chkconfig iptables off
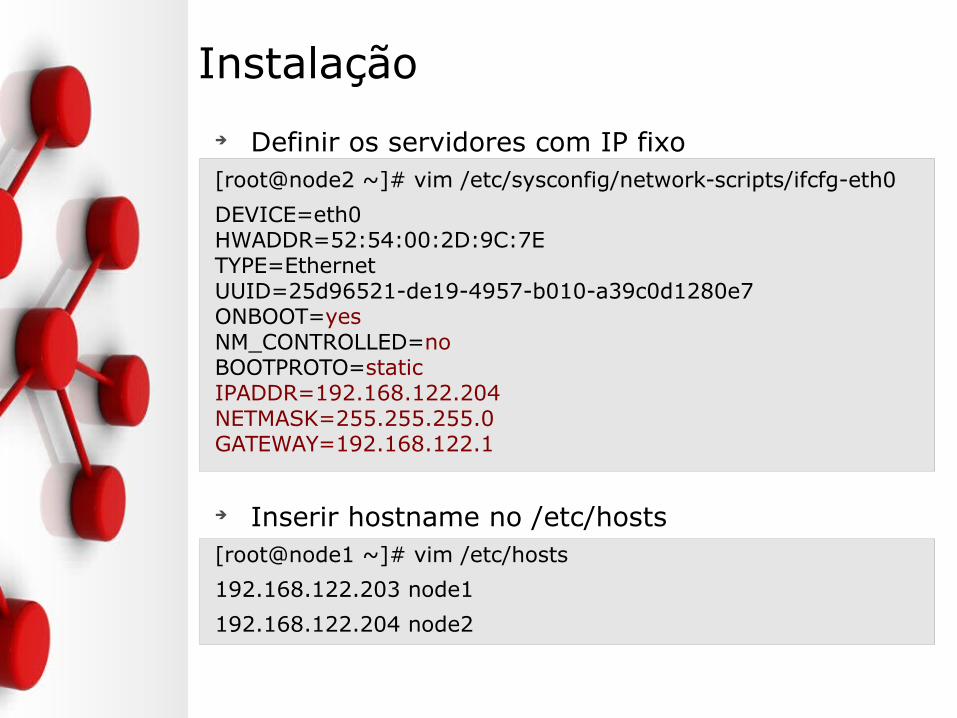
Instalação
➔ Definir os servidores com IP fixo[root@node2 ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0HWADDR=52:54:00:2D:9C:7ETYPE=EthernetUUID=25d96521-de19-4957-b010-a39c0d1280e7ONBOOT=yesNM_CONTROLLED=noBOOTPROTO=staticIPADDR=192.168.122.204NETMASK=255.255.255.0GATEWAY=192.168.122.1
➔ Inserir hostname no /etc/hosts[root@node1 ~]# vim /etc/hosts
192.168.122.203 node1
192.168.122.204 node2
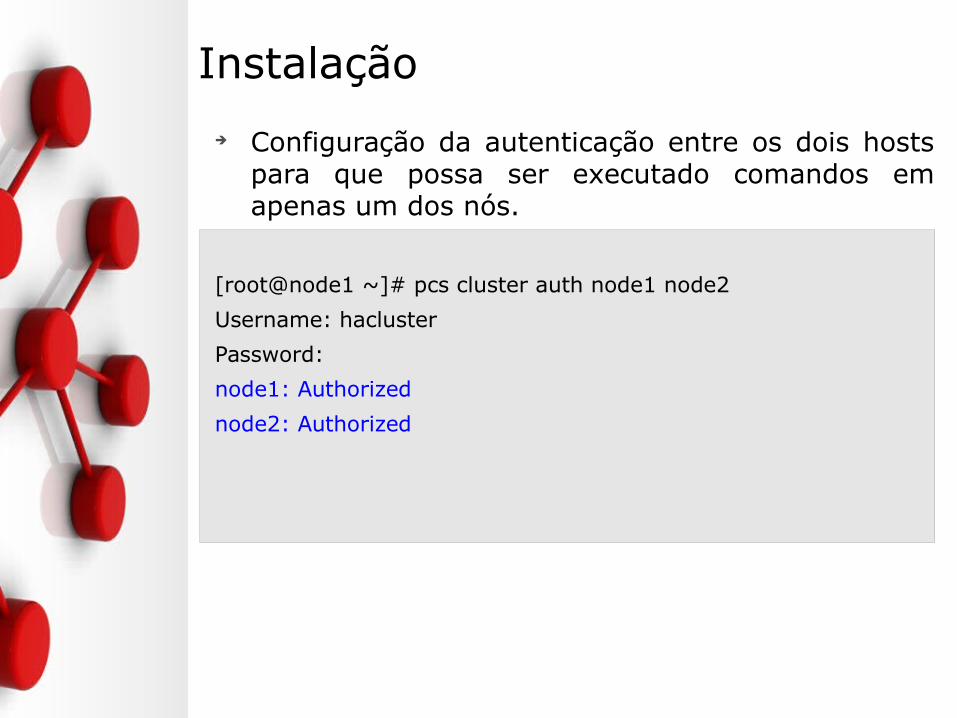
Instalação
➔ Configuração da autenticação entre os dois hosts para que possa ser executado comandos em apenas um dos nós.
[root@node1 ~]# pcs cluster auth node1 node2
Username: hacluster
Password:
node1: Authorized
node2: Authorized
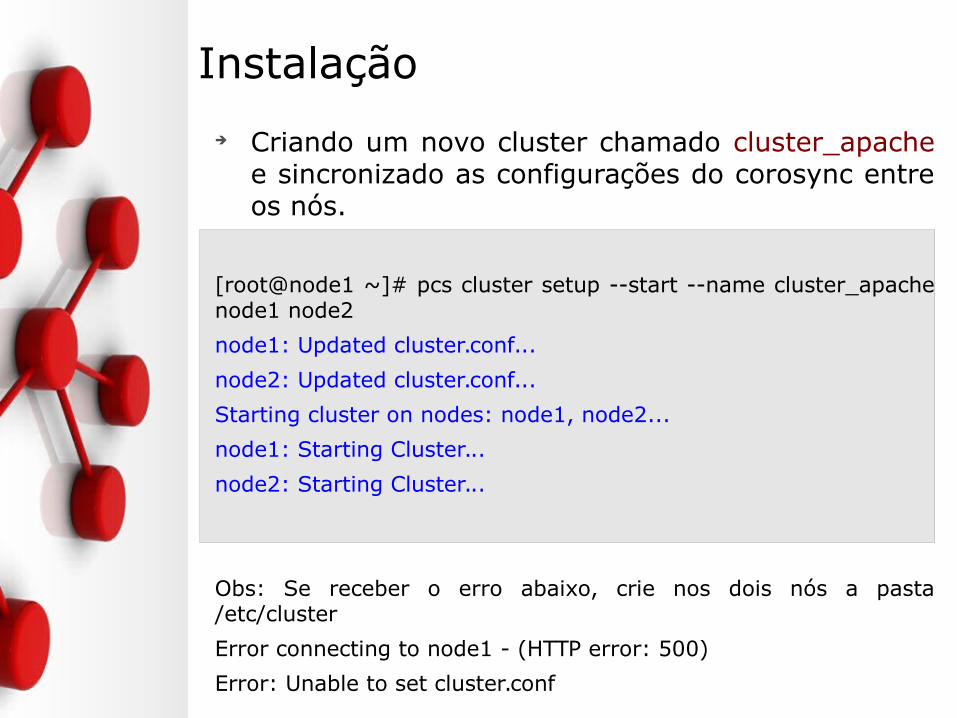
Instalação
➔ Criando um novo cluster chamado cluster_apache e sincronizado as configurações do corosync entre os nós.
[root@node1 ~]# pcs cluster setup --start --name cluster_apache node1 node2
node1: Updated cluster.conf...
node2: Updated cluster.conf...
Starting cluster on nodes: node1, node2...
node1: Starting Cluster...
node2: Starting Cluster...
Obs: Se receber o erro abaixo, crie nos dois nós a pasta /etc/cluster
Error connecting to node1 - (HTTP error: 500)
Error: Unable to set cluster.conf
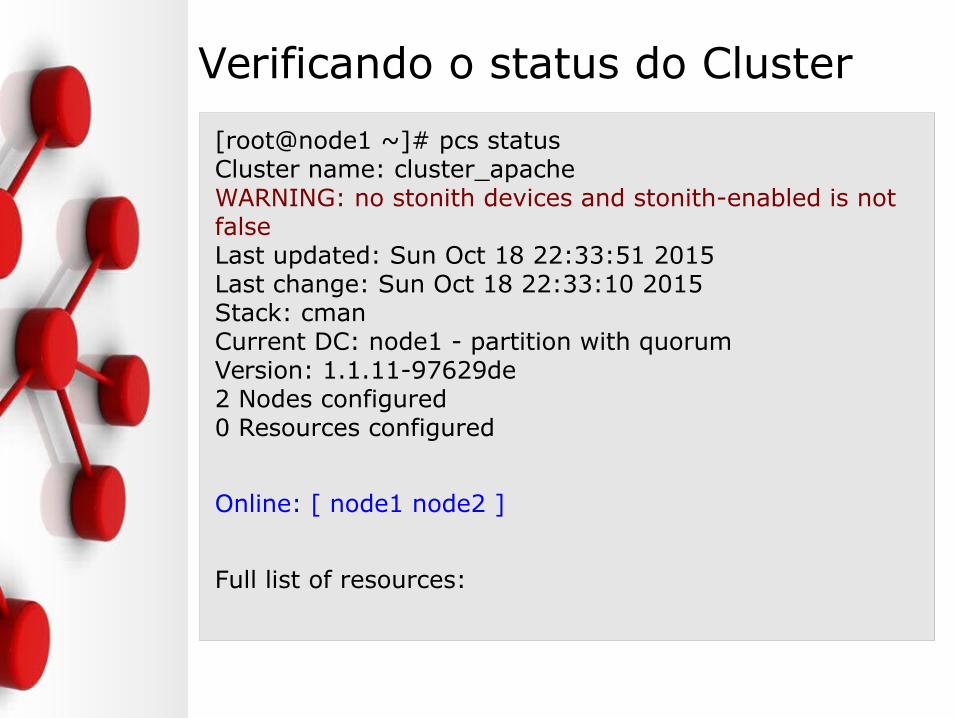
Verificando o status do Cluster
[root@node1 ~]# pcs statusCluster name: cluster_apacheWARNING: no stonith devices and stonith-enabled is not falseLast updated: Sun Oct 18 22:33:51 2015Last change: Sun Oct 18 22:33:10 2015Stack: cmanCurrent DC: node1 - partition with quorumVersion: 1.1.11-97629de2 Nodes configured0 Resources configured
Online: [ node1 node2 ]
Full list of resources:

Adicionando recursos: IP VIPSe o cluster estiver online, podemos inserir os recursos no mesmo.
Antes prescisaremos desativar o STONITH, pois em nossa configuração não temos nenhum dispositivo para fencing.
[root@node1 ~]# pcs property set stonith-enabled=false
Adicionando um IP Virtual para nosso cluster, esse recurso será chamado de VirtualIP
[root@node1 ~]# pcs resource create VirtualIP IPaddr2 ip=192.168.122.100 cidr_netmask=24
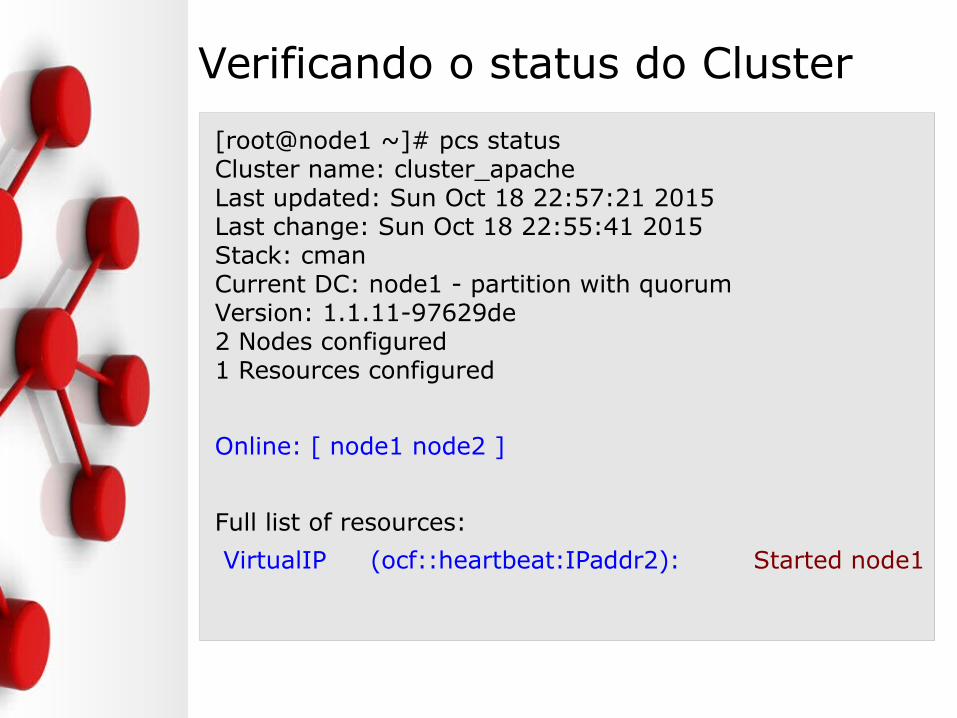
Verificando o status do Cluster
[root@node1 ~]# pcs statusCluster name: cluster_apacheLast updated: Sun Oct 18 22:57:21 2015Last change: Sun Oct 18 22:55:41 2015Stack: cmanCurrent DC: node1 - partition with quorumVersion: 1.1.11-97629de2 Nodes configured1 Resources configured
Online: [ node1 node2 ]
Full list of resources:
VirtualIP (ocf::heartbeat:IPaddr2): Started node1
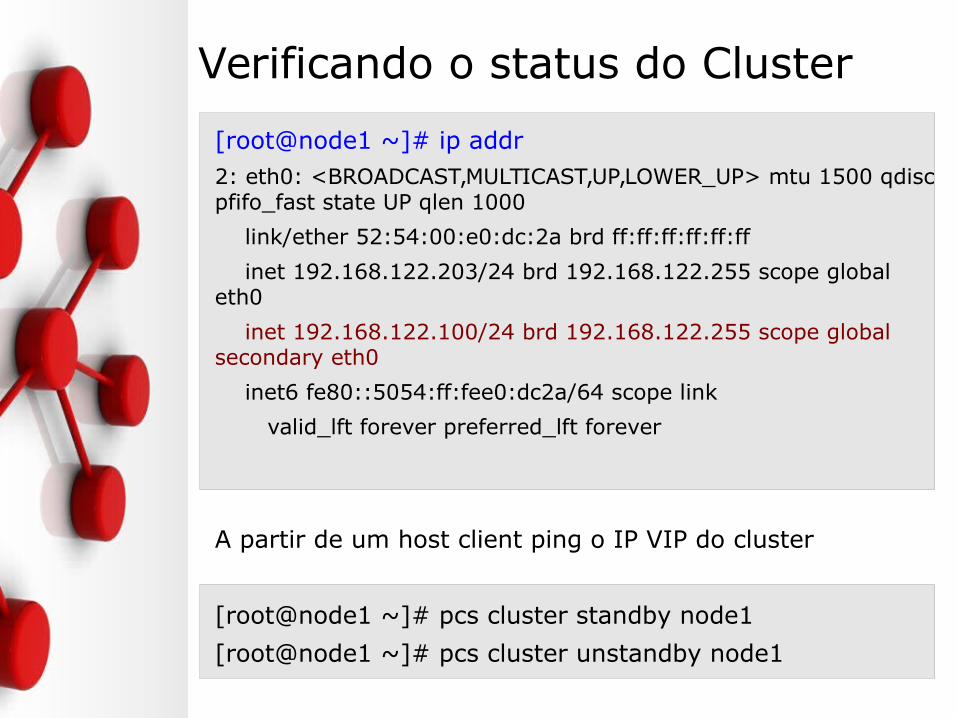
Verificando o status do Cluster
[root@node1 ~]# ip addr2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:e0:dc:2a brd ff:ff:ff:ff:ff:ff
inet 192.168.122.203/24 brd 192.168.122.255 scope global eth0
inet 192.168.122.100/24 brd 192.168.122.255 scope global secondary eth0
inet6 fe80::5054:ff:fee0:dc2a/64 scope link
valid_lft forever preferred_lft forever
A partir de um host client ping o IP VIP do cluster
[root@node1 ~]# pcs cluster standby node1
[root@node1 ~]# pcs cluster unstandby node1

Adicionando recursos: ApacheVamos inserir o apache para rodar em nosso cluster, faça os processos abaixo nos dois nós
[root@node1 ~]# yum install httpd
O Apache Resource Agent do pacemaker utiliza a página de status do apache para verificar a saúde do serviço. Para ativar a página de status, siga os paços abaixo:
[root@node1 ~]# vi /etc/httpd/conf.d/status.conf<Location /server-status> SetHandler server-status Order Deny,Allow Deny from all Allow from 127.0.0.1</Location>

Adicionando recursos: ApacheInserindo o recurso no cluster
[root@node1 ~]# pcs resource create httpd ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://127.0.0.1/server-status" op monitor interval=20s
Onde:
create httpd - é o nome do recurso
configfile=/etc/httpd/conf/httpd.conf – é o local do arquivo de configuração do apache
Statusurl="http://127.0.0.1/server-status" - Caminho usado para monitorar o status do servidor web
op monitor interval=20s – Monitora o serviço a cada 20s
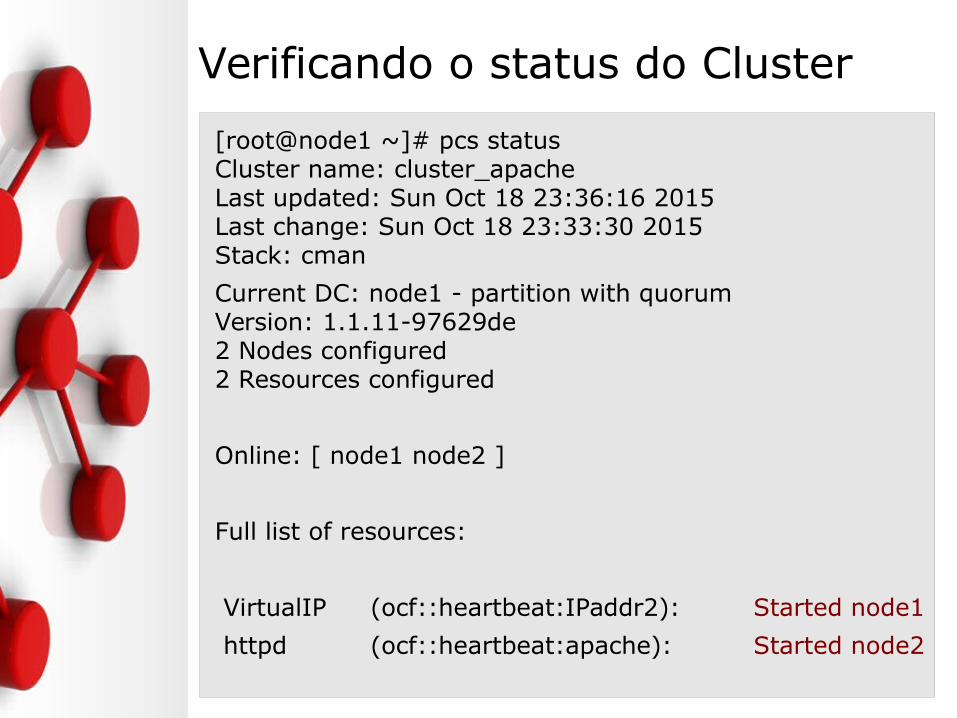
Verificando o status do Cluster
[root@node1 ~]# pcs statusCluster name: cluster_apacheLast updated: Sun Oct 18 23:36:16 2015Last change: Sun Oct 18 23:33:30 2015Stack: cman
Current DC: node1 - partition with quorumVersion: 1.1.11-97629de2 Nodes configured2 Resources configured
Online: [ node1 node2 ]
Full list of resources:
VirtualIP (ocf::heartbeat:IPaddr2): Started node1
httpd (ocf::heartbeat:apache): Started node2
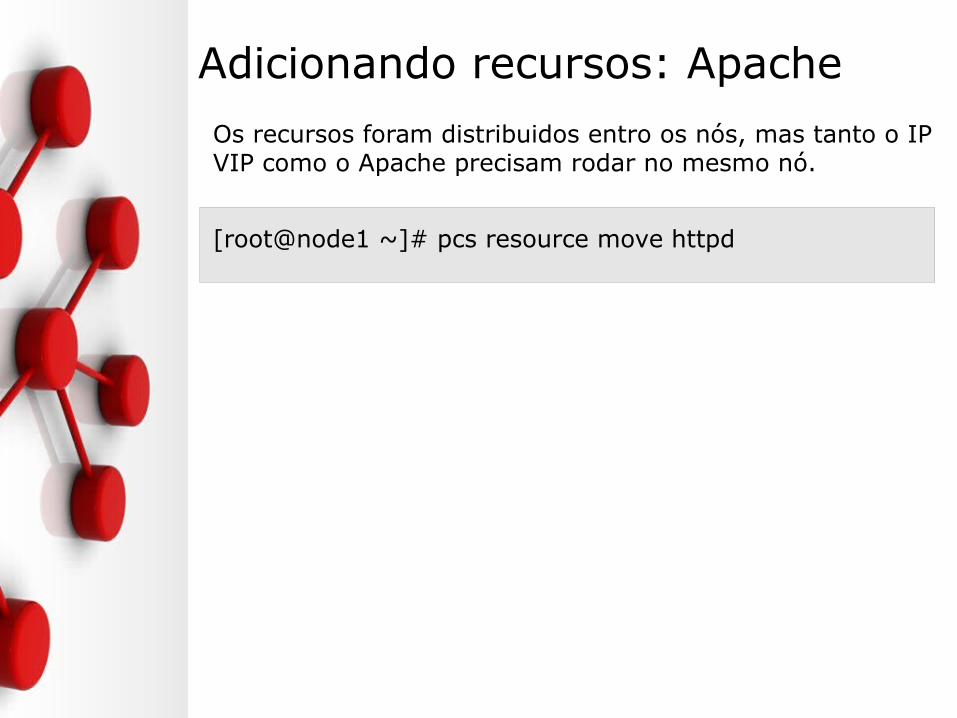
Adicionando recursos: Apache
Os recursos foram distribuidos entro os nós, mas tanto o IP VIP como o Apache precisam rodar no mesmo nó.
[root@node1 ~]# pcs resource move httpd

Constraint
Através das constraint é possível ordenar o startup dos serviços e definir quais recursos devem rodar juntos no mesmo nó.
[root@node1 ~]# pcs constraint colocation add VirtualIP httpd INFINITY
Mova apenas um recurso para o outro nó e você verá que ambos recursos serão movidos.
[root@node1 ~]# pcs resource move httpd nome_do_nó

O DRBD (Distributed Replicated Block Device) consiste em um módulo para o kernel Linux que faz o espelhamento dos dados de um dispositivo de bloco (partições de disco) entre diferentes servidores, interligados geralmente através de uma rede Ethernet.
DRBD = RAID 1 via Rede
Definição -DRBD

➔ Cada dispositivo de bloco envolvido na configuração do DRBD tem um estado, que pode ser primário ou secundário.
➔ Operações de escrita feitas no primário são replicadas para o secundário
➔ O protocolo padrão de replicação garante a sincronia e a integridade dos dados replicados.
➔ Operações de leitura, são sempre realizadas localmente.
Funcionamento

➔ O DRBD suporta três distintos modos de replicação, permitindo três graus de sincronnização da replicação. O
➔ Protocolo A é assíncrono. ➔ As operações de escrita no nodo primário são
consideradas completas quando a escrita no disco local termina e o pacote de replicação está no buffer TCP.
➔ Em casos de fail-over deve ocorrer perda de dados com este protocolo.
Funcionamento

➔ O Protocol B é um semi-síncrono protocolo de replicação.
➔ Operações locais são escritas no nodo primário e são consideradas completas quando estão escritas no diso local e a relpicação do pacote alcançou o outro nodo na rede.
➔ O Protocol C é sincrono por completo. ➔ Com este protocolo as operações no nodo primário são
consideradas completas quando ocorre a escrita no nodo primário e no secundário.
Funcionamento
Funcionamento
Escrita

DRBD - Instalação
Nos dois nós
[root@node1 ~]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
[root@node1 ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
[root@node1 ~]# yum install drbd84-utils kmod-drbd84
Adicione um disco de 1Gb na máquina virtual, no meu caso o novo dispositivo foi /dev/vdb em ambas as máquinas

DRBD - Configuração
Criar e configurar o arquivo de configuração abaixo nos dois nós:
[root@node1 ~]# vim /etc/drbd.d/drbd0.res
resource drbd0 {
disk /dev/vdb1;
device /dev/drbd0;
meta-disk internal;
Protocol C;
on node1 {
address 192.168.122.203:7789;
}
on node2 {
address 192.168.122.204:7789;
}
}

DRBD - Configuração
Inicializando o volume /dev/drbd0 nos dois nós:
[root@node1 ~]# drbdadm create-md drbd0
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created.
success
[root@node2 ~]# drbdadm create-md drbd0
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created.
success

DRBD - Configuração
Ativando o /dev/drbd0 nos dois nós:
[root@node1 ~]# drbdadm up drbd0
[root@node2 ~]# drbdadm up drbd0
[root@node1 ~]# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by phil@Build64R6, 2015-04-09 14:35:00
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:1048220
O DRBD marcou os dois recursos como inconsistentes pois ainda não foi marcado quem é o nó primário.

DRBD - Configuração
Marcando o volume do node1 como primário
[root@node1 ~]# drbdadm primary --force drbd0
[root@node2 ~]# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by phil@Build64R6, 2015-04-09 14:35:00
0: cs:SyncTarget ro:Secondary/Primary ds:Inconsistent/UpToDate C r-----
ns:0 nr:560232 dw:560232 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:487988
[=========>..........] sync'ed: 53.6% (487988/1048220)K
finish: 0:00:25 speed: 18,960 (13,664) want: 21,640 K/sec

DRBD - Configuração
Após o sincronismo dos dois volumes
[root@node1 ~]# cat /proc/drbd
version: 8.4.6 (api:1/proto:86-101)
GIT-hash: 833d830e0152d1e457fa7856e71e11248ccf3f70 build by phil@Build64R6, 2015-04-09 14:35:00
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:1048220 nr:0 dw:0 dr:1048884 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
Onde:
cs (connection state). Status da conexão de rede.
ro (roles). Se o nó é primeira ou secundário
ds (disk states). Status dos discos.O primeiro parâmetro representa o disco local e depois da barra representa o nó remoto.

DRBD – Criando um FS no recurso DRBDNo nó em que o DRBD estiver como primário, vamos criar o FS. Toda ação que for feita no volume /dev/drbd0 será replicada para o outro nó.
[root@node1 ~]# mkfs.ext3 /dev/drbd0mke2fs 1.41.12 (17-May-2010)Filesystem label=OS type: LinuxBlock size=4096 (log=2)Fragment size=4096 (log=2)Stride=0 blocks, Stripe width=0 blocks65536 inodes, 262055 blocks13102 blocks (5.00%) reserved for the super userFirst data block=0Maximum filesystem blocks=2684354568 block groups32768 blocks per group, 32768 fragments per group8192 inodes per groupSuperblock backups stored on blocks: 32768, 98304, 163840, 229376
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done

DRBD – Testando
Siga os passos abaixo a fim de testar a integridade do volume drbd nos dois nós.
#Montando o volume /dev/drbd0 e criando conteudo dentro dele
[root@node1 ~]# mkdir /media/teste_drbd
[root@node1 ~]# mount /dev/drbd0 /media/teste_drbd/
[root@node1 ~]# touch /media/teste_drbd/node1_teste.txt
[root@node1 ~]# umount /dev/drbd0
[root@node1 ~]# drbdadm secondary drbd0
[root@node1 ~]# drbd-overview
0:drbd0/0 Connected Secondary/Secondary UpToDate/UpToDate

DRBD – Testando
Montando o volume DRBD no nó 2 e verificando se o arquivo criado no nó 1 foi replicado.
[root@node2 ~]# mkdir /media/teste_drbd
[root@node2 ~]# mount /dev/drbd0 /media/teste_drbd/
mount: você precisa especificar o tipo do sistema de arquivos
O erro acima ocorreu pois o volume drbd não está como primário neste nó.
[root@node2 ~]# drbdadm primary drbd0
[root@node2 ~]# drbd-overview
0:drbd0/0 Connected Primary/Secondary UpToDate/UpToDate
[root@node2 ~]# mount /dev/drbd0 /media/teste_drbd/
[root@node2 ~]# ls /media/teste_drbd/
lost+found node1_teste.txt
Como o arquivo node1_teste.txt (criado no node1) apareceu, significa que ele foi replicado do node1 para o node2.

DRBD – Integrando o FS /dev/drbd0 ao Cluster
Nosso cluster está configurado com os seguintes recursos:– IP VIP– Servidor Web Apache
Necessário adicionar DRBD como recurso do cluster
Desativar o DRBD da inicialização do linux
[root@node1 ~]# chkconfig drbd off
Desmontar o volume DRBD onde ele estiver montado
[root@node1 ~]# umount /dev/drbd0
[root@node2 ~]# umount /dev/drbd0

DRBD – Integrando o FS /dev/drbd0 ao Cluster
O PCS tem a possibilidade de enfileirar diversos comandos para em seguida aplicá-los todos de uma vez só. Esse recurso é possível através da CIB (Cluster Information Base)
[root@node1 ~]# pcs cluster cib drbd_config
Através do pcs -f vamos inserir regras dentro do drbd_cofnig. Essas regras só serão inseridas após o push destas configurações.
[root@node1 ~]# pcs -f drbd_config resource create DrbdVol ocf:linbit:drbd drbd_resource=drbd0 op monitor interval=60s
[root@node1 ~]# pcs -f drbd_config resource master DrbdVolClone DrbdVol master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true

DRBD – Integrando o FS /dev/drbd0 ao Cluster
[root@node1 ~]# pcs -f drbd_config resource show
VirtualIP (ocf::heartbeat:IPaddr2): Started node1
httpd (ocf::heartbeat:apache): Started node1
Master/Slave Set: DrbdVolClone [DrbdVol]
Stopped: [ node1 node2 ]
Se as configurações estiverem corretas, podemos agora inserir as configurações no Cluster
[root@node1 ~]# pcs cluster cib-push drbd_config
CIB updated

DRBD – Integrando o FS /dev/drbd0 ao Cluster
[root@node1 ~]# pcs status
Cluster name: cluster_apache
Last updated: Sun Oct 25 16:21:57 2015
Last change: Sun Oct 25 16:20:40 2015
Stack: cman
Current DC: node1 - partition with quorum
Version: 1.1.11-97629de
2 Nodes configured
4 Resources configured
Online: [ node1 node2 ]
Full list of resources:
VirtualIP (ocf::heartbeat:IPaddr2): Started node1
httpd (ocf::heartbeat:apache): Started node1
Master/Slave Set: DrbdVolClone [DrbdVol]
Masters: [ node2 ]
Slaves: [ node1 ]

DRBD – Integrando o FS /dev/drbd0 ao Cluster
Uma vez que o DRBD já está inserido no Cluster, devemos agora inserir um filesystem para ser montado pelo nosso cluster e definir que ele só deve ser montado no nó primário
# Add FS
[root@node1 ~]# pcs cluster cib fs_config
[root@node1 ~]# pcs -f fs_config resource create DrbdFS Filesystem device="/dev/drbd0" directory="/var/www/html" fstype="ext3"
# Definindo a constraint
[root@node1 ~]# pcs -f fs_config constraint colocation add DrbdFS DrbdVolClone INFINITY with-rsc-role=Master
[root@node1 ~]# pcs -f fs_config constraint order promote DrbdVolClone then start DrbdFS
Adding DrbdVolClone DrbdFS (kind: Mandatory) (Options: first-action=promote then-action=start)

DRBD – Integrando o FS /dev/drbd0 ao Cluster
Precisamos definir que o Apache deve rodar no mesmo nó onde o FS estiver ativo e que o FS deve ser montado antes do inicio do apache
[root@node1 ~]# pcs -f fs_config constraint colocation add httpd DrbdFS INFINITY
[root@node1 ~]# pcs -f fs_config constraint order DrbdFS then httpd
Adding DrbdFS httpd (kind: Mandatory) (Options: first-action=start then-action=start)

DRBD – Integrando o FS /dev/drbd0 ao Cluster
Verificando os recursos e constraint da CIB fs_config
[root@node1 ~]# pcs -f fs_config constraint
Location Constraints:
Resource: httpd
Enabled on: node1 (score:INFINITY) (role: Started)
Ordering Constraints:
promote DrbdVolClone then start DrbdFS (kind:Mandatory)
start DrbdFS then start httpd (kind:Mandatory)
Colocation Constraints:
VirtualIP with httpd (score:INFINITY)
DrbdFS with DrbdVolClone (score:INFINITY) (with-rsc-role:Master)
httpd with DrbdFS (score:INFINITY)

DRBD – Integrando o FS /dev/drbd0 ao Cluster
Verificando os recursos e constraint da CIB fs_config
[root@node1 ~]# pcs -f fs_config resource show
VirtualIP (ocf::heartbeat:IPaddr2): Started node1
httpd (ocf::heartbeat:apache): Started node1
Master/Slave Set: DrbdVolClone [DrbdVol]
Masters: [ node2 ]
Slaves: [ node1 ]
DrbdFS (ocf::heartbeat:Filesystem): Stopped
Se tudo estiver certo, podemos fazer o push das configurações
[root@node1 ~]# pcs cluster cib-push fs_config
CIB updated
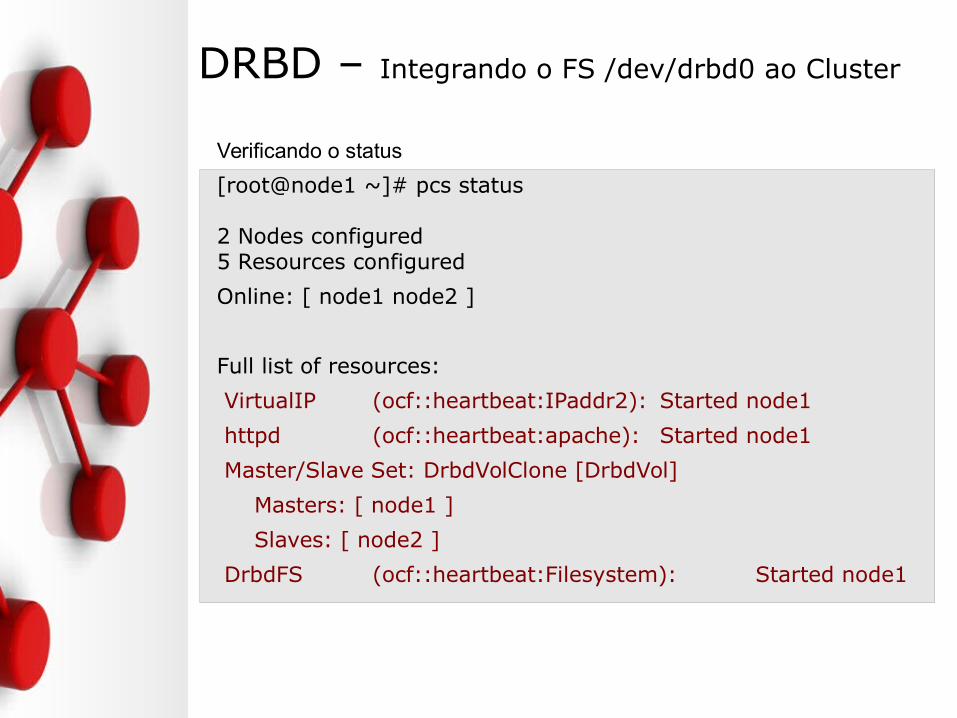
DRBD – Integrando o FS /dev/drbd0 ao Cluster
Verificando o status
[root@node1 ~]# pcs status
2 Nodes configured5 Resources configured
Online: [ node1 node2 ]
Full list of resources:
VirtualIP (ocf::heartbeat:IPaddr2): Started node1
httpd (ocf::heartbeat:apache): Started node1
Master/Slave Set: DrbdVolClone [DrbdVol]
Masters: [ node1 ]
Slaves: [ node2 ]
DrbdFS (ocf::heartbeat:Filesystem): Started node1

Testando
➔ Coloque o nó 1 em standby e observe que o a pasa /var/www/html está vazia. No nó 2 ela será montada com todo o conteúdo apresentado no nó 1 antes do standby.
[root@node1 ~]# pcs cluster standby node1
➔ Faça com que o nó 1 reassuma. Verifique o status do device /dev/drbd0 e dos dados na pasta /var/www/html
[root@node1 ~]# pcs cluster unstandby node1
Sistemas DistribuídosAlta Disponibilidade utilizando Heartbeat + drbd
Frederico MadeiraLPIC1, LPIC2, [email protected]




















![[SOLVED] Zimbra on DRBD - Zimbra __ Forums](https://img.pdfslide.net/doc/110x75/54f9cdde4a795956048b45f6/solved-zimbra-on-drbd-zimbra-forums.jpg)








