Embed Size (px)
Citation preview

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Sony PlayStation: Breaking the Bandwidth Barrier using Soft
State and ELB Properties Sony Playstation
Dustin Pham and Alexander Filipchik
11/28/2016


Who is talkingAlexander Filipchik (PSN: LaserToy)Principal Software Engineer
at Sony Interactive Entertainment
Dustin Pham Principal Software Engineer
at Sony Interactive Entertainment

Agenda
• Quick PSN overview
• Standard Stateless architecture
• Soft State overview
• How we applied it

The Rise of PlayStation4PlayStation Network is big and growing.
– Over 65 million monthly active users– Hundreds of millions of users– More than 47M PS4s– A Lot of offerings

Social

Video

Commerce

It must be fast No matter what

Stateless Design
• The go to design
• Created a distinction between applicationsand scalable databases
• Pure Stateless systems are extremely rare, web calculator is a good example
• Sometimes design is taken to an extreme

Pros
• Easy to scale horizontally
• Easy to program
• Works in multiregional deployments
– As long as your underlying tech works
• 1 step to serverless

Cons• You rely on someone else's code to deal with
state• And hope it scales• Complex uses cases require a lot of network
communications (social networks)• Memory and disk are not utilized to their full
capacity• And…

A lot of times system look like
Scalable Black Magic
Your code
Your code
Your code
ClientYour code
Your code
The state

Any cool alternatives?
• Lambda architecture for services
• Soft state
– Accept the fact that state exists and use it to your advantage

Soft State
In computer science, soft state is state which is useful for efficiency, but not essential, as it can be regenerated or replaced if needed.

Highlights
• A simple state that is kept in memory for performance
• Harder to program, but can save a lot of money
• Some systems are not feasible without it

Why bother?
https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html

Or in English
• L1 cache reference: 1sec
• Branch mispredict: 3sec
• L2 cache reference: 4sec
• Main memory reference: 1.6min
• Send 2K bytes over network: 3min

Getting worse
• Read 1 MB sequentially from memory: 1.9hr
• SSD random read: 4.4hr
• Read 1 MB sequentially from SSD: 1.4d
• Round trip within same datacenter: 5.8d
• Disk seek: 1month
• Send packet CA->Netherlands->CA: 4.7 YEARS

Einstein said
Even servelessarchitectureis subject to the laws of physics

There is still a server somewhere

Friend Finder
Our Social Graph
100s millions of users
Growing number of connections
Rich networkingfeatures

New Feature/new Journey• We want users to be able to find other users on the platform• We should respect privacy settings• We want to recommend new friends to users (You May Know)• When user searches we want to display result in the following
order:– Direct friends– Friends of Friends 0_o– Everyone else
• Do it fast with a small team of ninjas (small means 2)
Here is the Problem

So, we figured out• We can use Solr to index everyone, so we can do
platform wide search• And try to use it for indexing relations between users,
so we can– Sort by distance (direct, friend of a friend)– Sort by other user related fields (who do I play with often,
Facebook friends, and so on)– You may know is another search: Give me 10
friend of friends sorted by number of common friends

But
• Data has both high and low cardinality properties
• We will need to somehow index relations between users. And it is not obvious.
• And it will not be very fast because Solr is optimized for a completely different use case

Options
• Tried graph databases and find a lot of reasons not to use them
• Dump everything into a scalable database in a denormalized format and see what happens– We can store friends graph there (the State) and
write stateless service to deal with requests
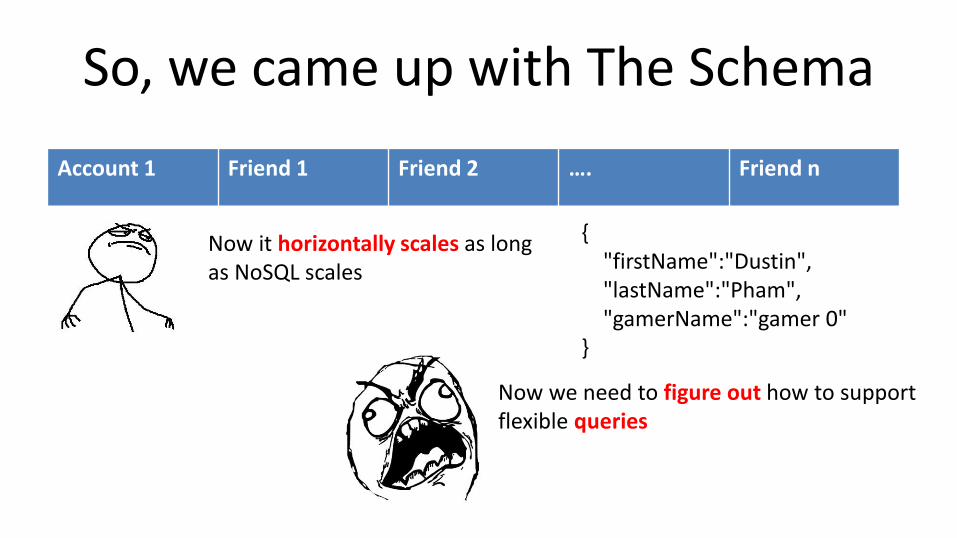
So, we came up with The Schema
Account 1 Friend 1 Friend 2 …. Friend n
Now it horizontally scales as long as NoSQL scales
Now we need to figure out how to support flexible queries
{ "firstName":"Dustin","lastName":"Pham","gamerName":"gamer 0"
}

Going deeper
• What does the client want:– Search, sort, filter
• What can we do:– Use some kind of NoSql secondary Index (Cassandra,
Couchbase, …) powered by magic
– Fetch everything in memory and process
– How about…

Apply CS 101
• We can index ourselves, and writing indexersounds like a lot of fun
• Wait, someone already had the fun and made:

Account 1 Friend 1 Friend 2 …. Friend n
Schema v2
Account 1 Friend Friend n Version
Now We can Search on anything inside the row that represents the userIndex is small and it is fast to pull it from NoSql
But we will be pulling all this bytes (indexes) all the time (stateless design again!!!)And what if 2 servers modify same row?

Distributed Cache?• It is nice to keep things as close to
our Microservice as possible
• So we can have a beefyMemcached/Redis/Aerospike/…
• And Still pay Network penalty and think about scaling them

Soft State?• Cache lives inside the MicroService, so no network penalty
• Requests for the same user are processed on the same instance, so we can save network roundtrip and also have some optimizations done (read/write lock, etc)
• Changes to State also are replicated to the storage and are identified with some version number
• We will need to check index version before doing search to make sure index is not stale

Or in Other WordsAccount 1
Version
Account 2
Version
Account 3
Version
Account 4
Version
Account 5
Version
Account 6
Version
Account1 jsons Version
Account2 jsons Version
Account3 jsons Version
Account4 jsons Version
Account5 jsons Version
…. … … …
Account n jsons Version
Instance 1
Instance 2
Instance 3
NoSql

Routing
• How to find where to route?– Lookup table
– Gossiping algorithm
– Routing master
• How to maintain?– Change in capacity
– New deployment

We followed KISS• We are on AWS so we just used ELB stickiness with a
twist• It works only with cookies so, you will need to
somehow store them• Client library is smart and writes accountId-
>AWSStickyCookie to a shared cache (or Dynamo)• Before sending request through ELB we pull sticky
cookie from the shared cache and attach it to the request
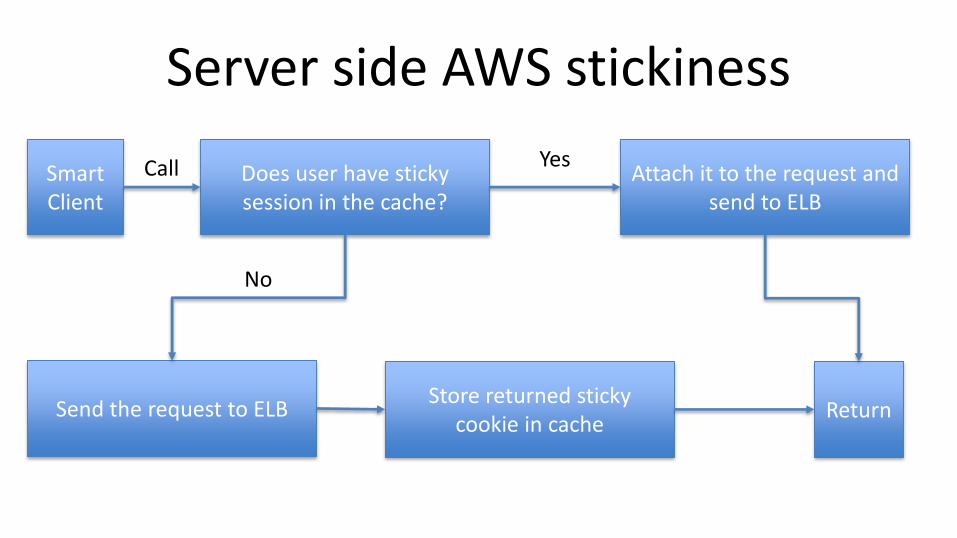
Server side AWS stickiness
Smart Client
Does user have sticky session in the cache?
Attach it to the request and send to ELB
Send the request to ELBStore returned sticky
cookie in cache
Call Yes
No
Return

The whole system looked like:
Solr Cloud
Social Network
Friends Finder
Cassandra
Queue
Personalized Search
Microservice
IndexerChange Change
New userPrivacy updateetc
Friendship changedName changeetc

How did it do?• Solr was fine• Personalized part not so fine• Each change in friendship required reindexing of a lot of
users• Same goes for privacy changes• Our NoSQL (Cassandra) uses SSTables, so space is not
released right after an update• Data size was growing much faster than
we expected


Taming the beast

Key insight
Users don’t search frequently, but when they do they spend some time doing it

Crazy idea
• What if we do ephemeral indexes?
• They can live in memory for the duration of the user’s search session and then get discarded
• We can use the same code, we just need to slightly change it

More boxes
Solr Cloud
Social Network
Friends Finder
Queue
Personalized Search
Microservice
IndexerChange
New userPrivacy updateetc
Get Friends Friendship Change, etc

Is it fixed yet?
• Not really
• Now we need to make indexing really fast
• And significant time and resources are spent on pulling user related data from Social network
• Wait, we’ve just talked about Soft State. What if?

Let’s do math
• Number of users: hundreds of millions, but number of active is less
• Each user has some searchable metadata; let’s say it is 200 bytes
• How much memory will we need to cache all the active ones?
• 100000000 * 200/ (1024 * 1024* 1024) = 18Gb

We can organize it likeApp Memory
Java Heap (8Gb)
Off Heap Ehcache (40 Gb)
Accounts info (20Gb) Lucene indexes (20Gb)
SSD if we need to spill over

Will it work?• On AWS we can have up to 256Gb of ram
(r3.8xlarge) and instances have SSDs which usually do nothing
• Actually, with new X1 family we can have up to 1.9 TB
• So, it sounds like it can work

Yes

Network

Indexing stats

With just stateless (rough)122 bytes per user
*
730,000 accounts per second
/
0.5 Index cache hit ratio
=
170Mb per sec vs 14Mb per sec

Learnings
• You can do wonders when you are desperate
• Stateless works but may result in tons of servers
• You can’t beat RAM

PlayStation is hiring in SF:
Find us at hackitects.com
Q & A

Thank you!

Remember to complete your evaluations!

Related Sessions















![[jaws days 2014]ELB/AutoScaling](https://img.pdfslide.net/doc/110x75/5595a4491a28ab357f8b4698/jaws-days-2014elbautoscaling.jpg)













