Embed Size (px)
Citation preview

2
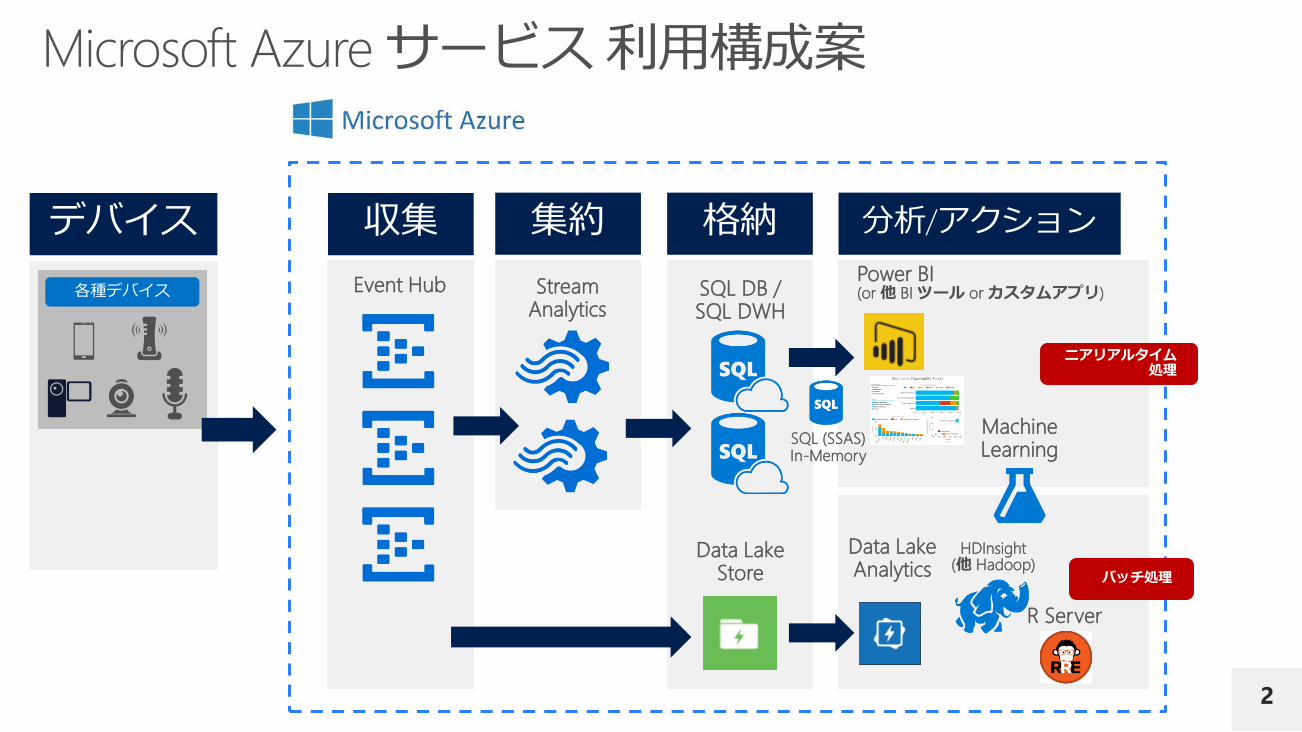
各種デバイス Event Hub Stream Analytics
SQL DB /SQL DWH
Data Lake Store
Power BI(or 他 BI ツール or カスタムアプリ)
SQL (SSAS)In-Memory
Data Lake Analytics
MachineLearning
R Server
HDInsight(他 Hadoop)
ニアリアルタイム処理
バッチ処理

3
入力データをその後の処理 (BI / データ分析) で必要な項目、件数に集約する。大規模な入力をより小規模な出力にする。例) デバイスからの 1 億件のデータを 1000 件程度に集約して保存
「どの項目」を「どの程度の間隔で集約して」後続工程 (BI / データ分析) で参照したいかを事前に設計する必要がある※トップダウンアプローチ
デバイスから受けとったデータを、そのまま or メタデータを追加して保存する。大規模な入力を大規模なまま出力する。例) デバイスからの入力 1 億件ごとにテキストファイルとして保存
保存したデータをどのように分析するかが明確でない場合、一定期間アーカイブしておく必要がある場合は、こちらを選択する※ボトムアップアプローチ

4
基本数秒程度の即時応答 (オンライン処理) を前提としたデータストアサービス。Table Storage は REST API、DocDB は REST API (JSON)HBase は SQL Like なクエリでアクセスを行う。一般的には SQL Database が使用される。大規模な環境では “Elastic Database pools” の使用を検討する。
基本バッチ処理を前提としたデータストアサービス。「数秒での応答」という要求にはそぐわない。
テーブル定義を決めて設計する「トップダウンアプローチ」なSQL DWH と、格納後に利用方法を検討する「ボトムアップアプローチ」な Data Lake Store を一般的には利用する。Hadoop の実装を管理したい場合は HDInsight を選択する。
Blob ストレージは、一般的には一方的な出力 (ログ出力、アーカイブ等) で利用する。

5
No. SQL or
NoSQL
オンライン処理 (基幹系、フロント系) 分析処理 (情報系)
1. NoSQL ・ドキュメントデータベース
(DocDB, MongoDB)
・KVS – Key Value Store
(Azure Table Storage, Riak)
・列指向ストア
(Apache HBase, Apache Cassandra)
・分散処理基盤
(Azure Data Lake Store, 各種 Hadoop ディストリビューション,
(HDInsight))
・分析用インタフェース、ライブラリ
(Azure Data Lake Analytics,
Apache Spark (Spark SQL, Pyspark))
2. SQL ・RDMBS
(Azure SQL Database, SQL Server on IaaS)
・MPP DWH
(Azure SQL DWH)
6
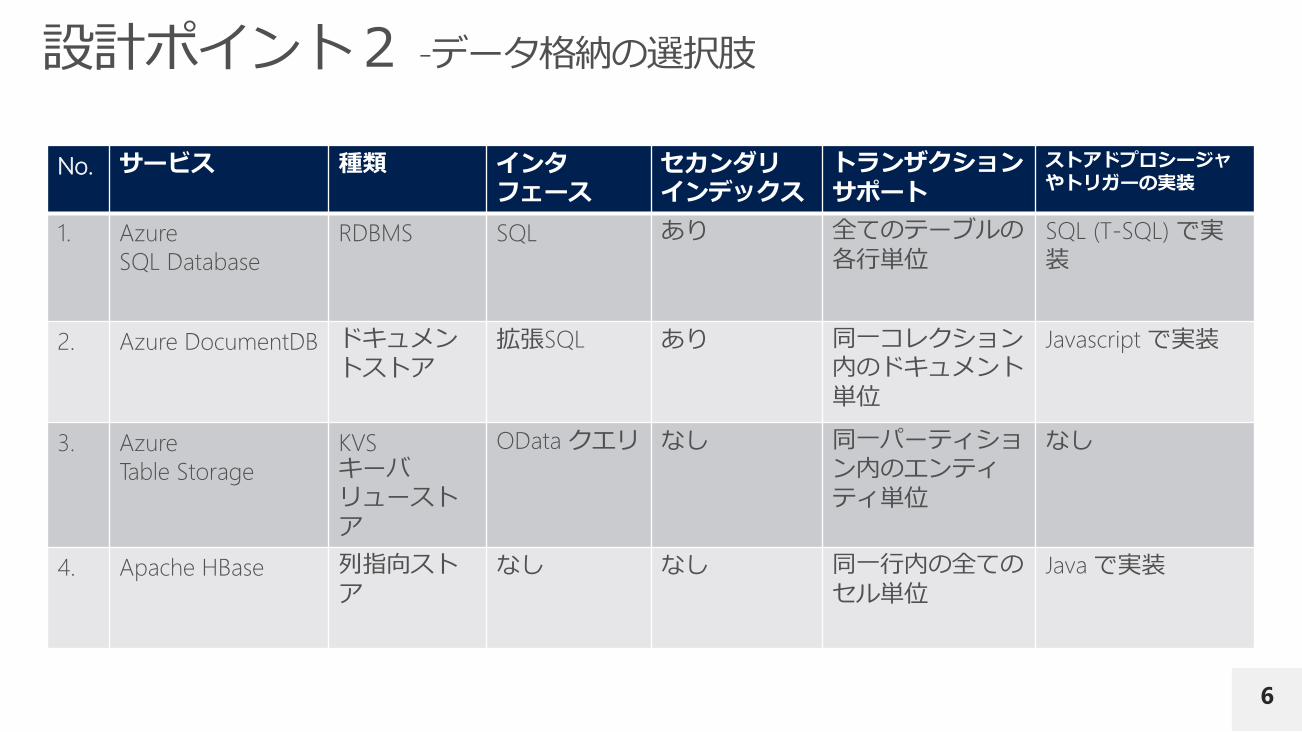
No. サービス 種類 インタフェース
セカンダリインデックス
トランザクションサポート
ストアドプロシージャやトリガーの実装
1. Azure
SQL Database
RDBMS SQL あり 全てのテーブルの各行単位
SQL (T-SQL) で実装
2. Azure DocumentDB ドキュメントストア
拡張SQL あり 同一コレクション内のドキュメント単位
Javascript で実装
3. Azure
Table Storage
KVS キーバリューストア
OData クエリ なし 同一パーティション内のエンティティ単位
なし
4. Apache HBase 列指向ストア
なし なし 同一行内の全てのセル単位
Java で実装

7
SQL DWH は Blob ストレージのファイルをテーブルに取込を行う機能を保持している (Polybase 機能)Blob ストレージの特定のコンテナ(フォルダパス) 配下のファイルを再帰的に読み込んで SQL DWH にロードできる。そのため、SQL DWH にデータ取込する時間間隔 (例: 1 時間) ごとにフォルダ名を定義することを検討する (例: 20151112_0900)
但し、全デバイス分格納してロードが間に合わない場合は、入力種別ごとなど (例: TV など) でフォルダを別にする (例: TV_20151112_0900)
Data Lake Store は管理された Web HDFS サービスであり、ディレクトリ構成を作ってファイル保存する但し、HDFS は大きなサイズのファイルでより効果を発揮するため、ファイル結合を考慮した方が良い(Data Lake Analytics を使えば、多数の小サイズファイルを1 つの大きなファイルにクエリ 1 つで結合でき、且つ分散処理として実行できる)

8
本書に記載した情報は、本書各項目に関する発行日現在の Microsoft の見解を表明するものです。Microsoftは絶えず変化する市場に対応しなければならないため、ここに記載した情報に対していかなる責務を負うものではなく、提示された情報の信憑性については保証できません。
本書は情報提供のみを目的としています。 Microsoft は、明示的または暗示的を問わず、本書にいかなる保証も与えるものではありません。
すべての当該著作権法を遵守することはお客様の責務です。Microsoftの書面による明確な許可なく、本書の如何なる部分についても、転載や検索システムへの格納または挿入を行うことは、どのような形式または手段(電子的、機械的、複写、レコーディング、その他)、および目的であっても禁じられています。これらは著作権保護された権利を制限するものではありません。
Microsoftは、本書の内容を保護する特許、特許出願書、商標、著作権、またはその他の知的財産権を保有する場合があります。Microsoftから書面によるライセンス契約が明確に供給される場合を除いて、本書の提供はこれらの特許、商標、著作権、またはその他の知的財産へのライセンスを与えるものではありません。
© 2015 Microsoft Corporation. All rights reserved.
Microsoft, Windows, その他本文中に登場した各製品名は、Microsoft Corporation の米国およびその他の国における登録商標または商標です。
その他、記載されている会社名および製品名は、一般に各社の商標です。