Embed Size (px)
DESCRIPTION
this presentation covers the following: * Data warehouse-design strategies * Data warehouse-modeling techniques * the points of attention when building ETL-procedures for one of these Data warehouse-modeling techniques
Citation preview

And its relation to the four dominant scientific
DWH-modeling concepts
Data warehousing in practice
Drs. S.F.J Otten
13-05-2014

Topics About me…
Business Intelligence
What is a Data warehouse (DWH)
DWH – Design strategies
Data-modeling Brief history in data modeling Star-schematic Snowflake-schematic Datavault Anchormodeling
Pratical examples
Summary

About me… Education
Highschool (MAVO)
College (MBO ICT lvl.4)
Univeristy of Applied sciences (Avans Hogeschool, Business Informatics; BSc)
Utrecht University (MBI; MSc)
Utrecht University (Dissertation on BI,DM,PPM; PhD)
Carreer till now..
CSB-System BV/GmbH (privatly held, 500-1000 employees globally) (2010-present) BI-consultant/architect
(Microsoft BI stack)
SQL-Programmer
Expert-role at programmingdepartment for BI-development at HQ
Semantic development
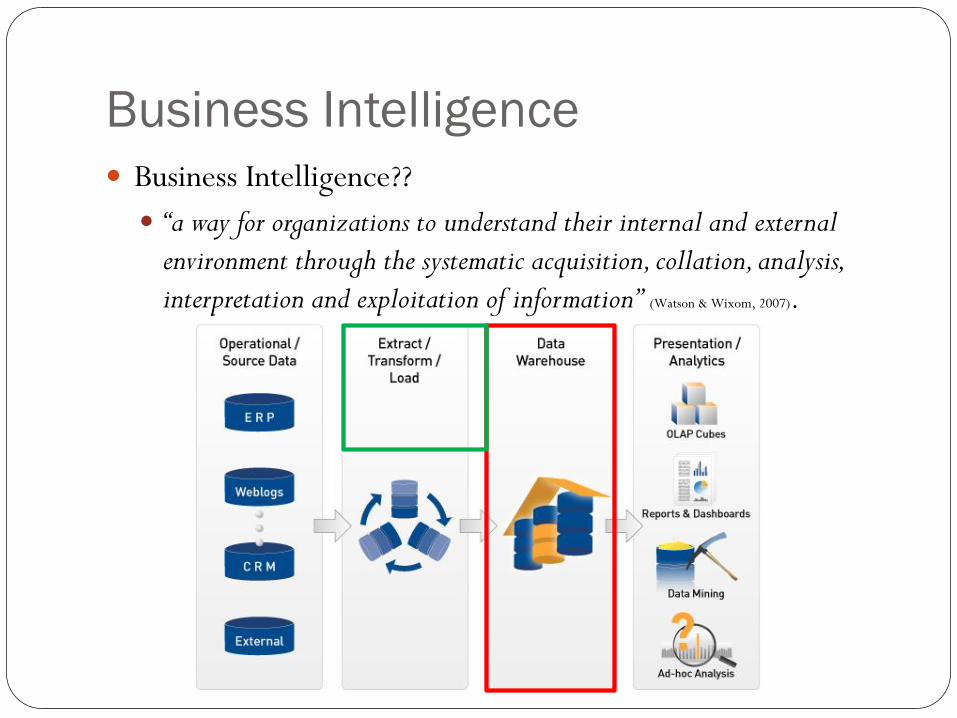
Business Intelligence
Business Intelligence??
“a way for organizations to understand their internal and external
environment through the systematic acquisition, collation, analysis,
interpretation and exploitation of information” (Watson & Wixom, 2007).

What is a Data warehouse (1) Data warehouse?? (DWH)
“a repository where all data relevant to the management of an organization is stored and from which knowledge emerges.” (March & Hevner,
2007)
“A data warehouse is a subject-oriented, integrated, time-variant, nonvolatile collection of data in support of management’s decision-making process.” (Inmon, 1992)
Different definitions same goal;
provide data in such a way that it has meaning and can be used in all levels of an organization as input for a decision-making-process

DWH – design strategies (1)
Enterprise wide DWH-design (Imnon, 2002)
DWH is designed by using a normalized enterprise data model
From the EDWH data marts for specific business domains are
derived
Data mart design (Kimball, 2002)
Hybrid strategy (top-down & bottom-up) for DWH-design
Create datamarts in a bottom-up fasion
Datamart-design conforms to a top-down
skeleton/framwork-design which is called the “data
warehouse bus”
The EDW = the union of the conformed datamarts
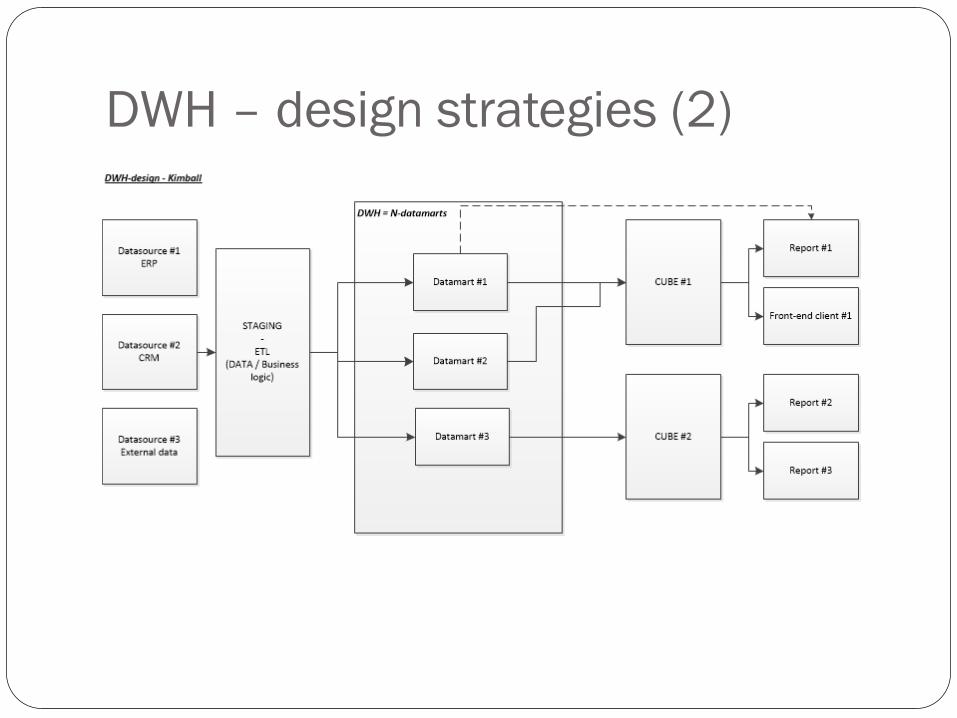
DWH – design strategies (2)

DWH – design strategies (3)

DWH – design strategies (3)
Inmon Kimball
Subject-oriented
Integrated
Non-volatile
Time-variant
Top-Down
Integration via assumed Enterprise data model (EDM / 3NF)
Datamarts are derived from EDW
Business-process-oriented
Bottom-up /evolutionary
Dimensional modeling (star-schematic)
Integration via conformed dimensions
Star-schematic enforces query semantics
The sum of the datamarts = the EDW

Data-modeling history
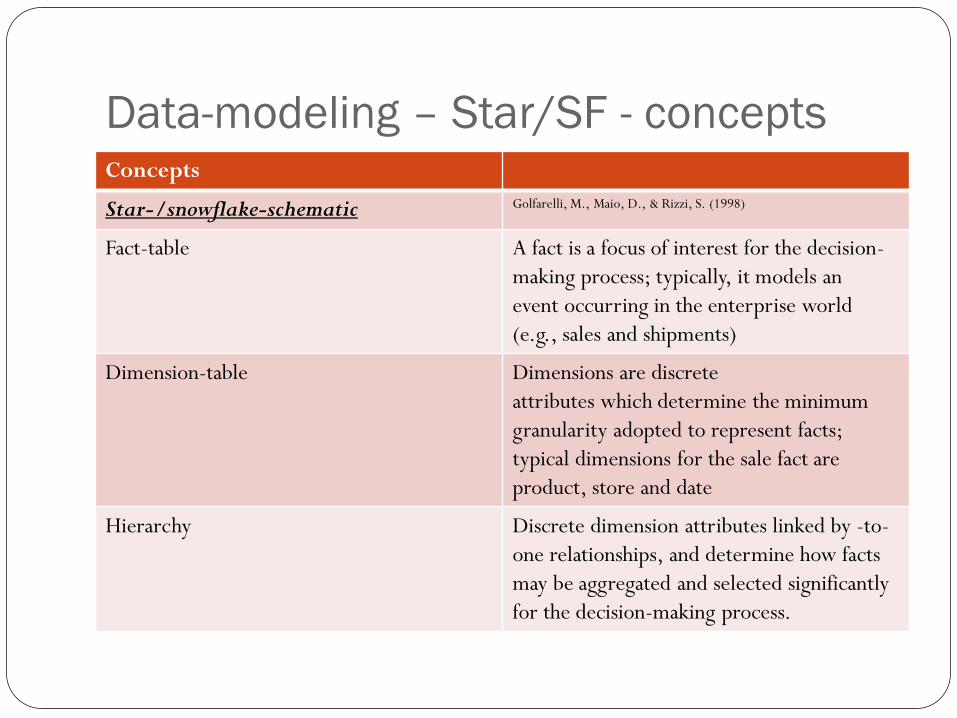
Data-modeling – Star/SF - concepts Concepts
Star-/snowflake-schematic Golfarelli, M., Maio, D., & Rizzi, S. (1998)
Fact-table A fact is a focus of interest for the decision-
making process; typically, it models an
event occurring in the enterprise world
(e.g., sales and shipments)
Dimension-table Dimensions are discrete
attributes which determine the minimum
granularity adopted to represent facts;
typical dimensions for the sale fact are
product, store and date
Hierarchy Discrete dimension attributes linked by -to-
one relationships, and determine how facts
may be aggregated and selected significantly
for the decision-making process.
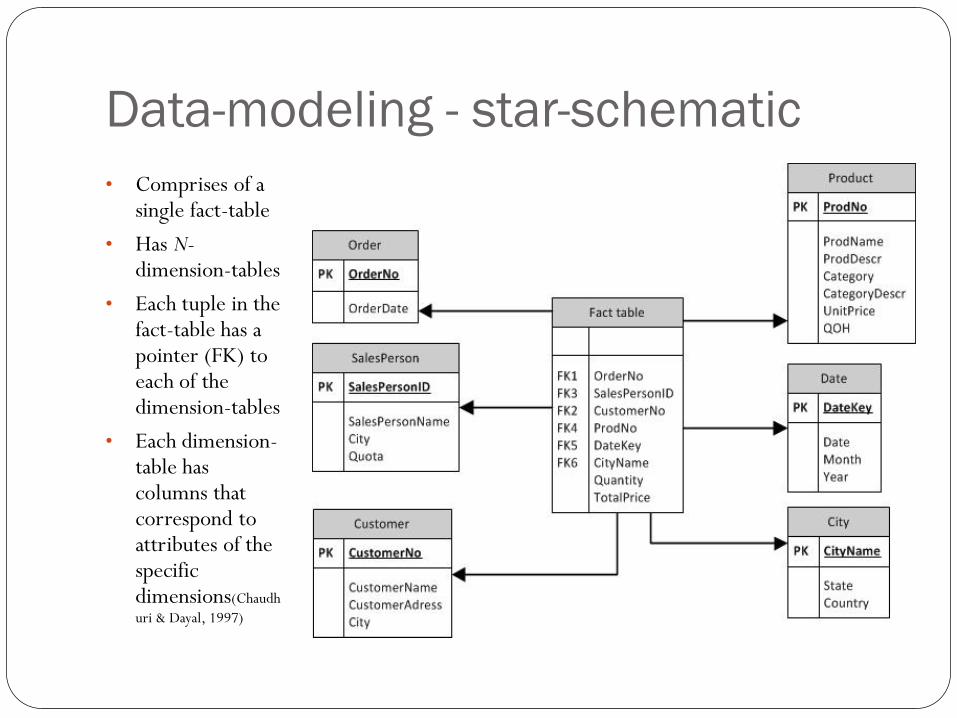
Data-modeling - star-schematic
• Comprises of a single fact-table
• Has N-dimension-tables
• Each tuple in the fact-table has a pointer (FK) to each of the dimension-tables
• Each dimension-table has columns that correspond to attributes of the specific dimensions(Chaudh
uri & Dayal, 1997)
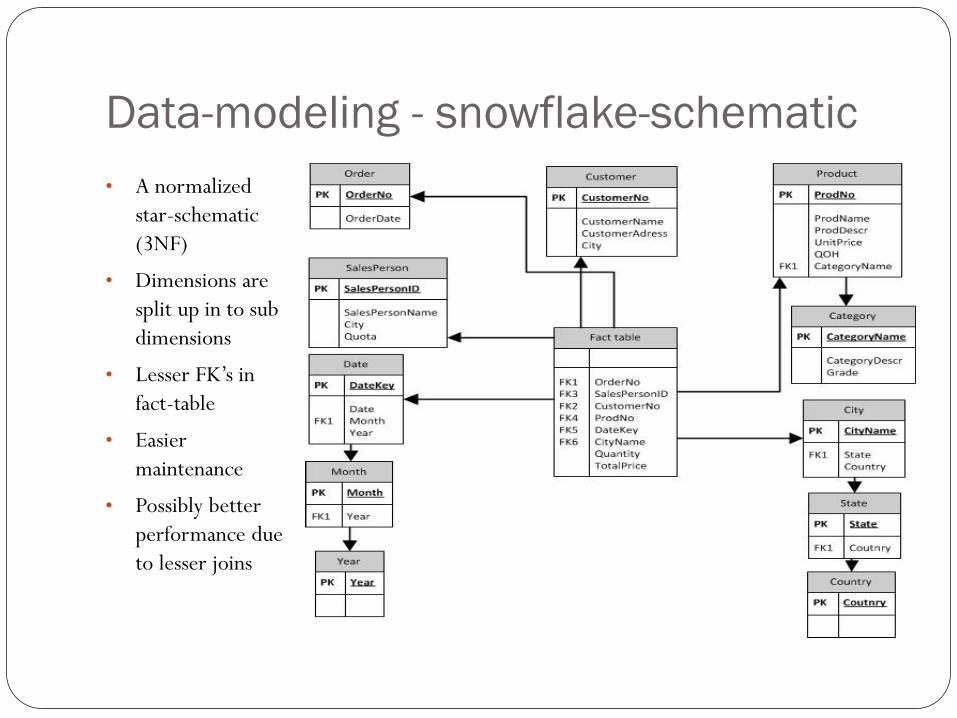
Data-modeling - snowflake-schematic
• A normalized
star-schematic
(3NF)
• Dimensions are
split up in to sub
dimensions
• Lesser FK’s in
fact-table
• Easier
maintenance
• Possibly better
performance due
to lesser joins
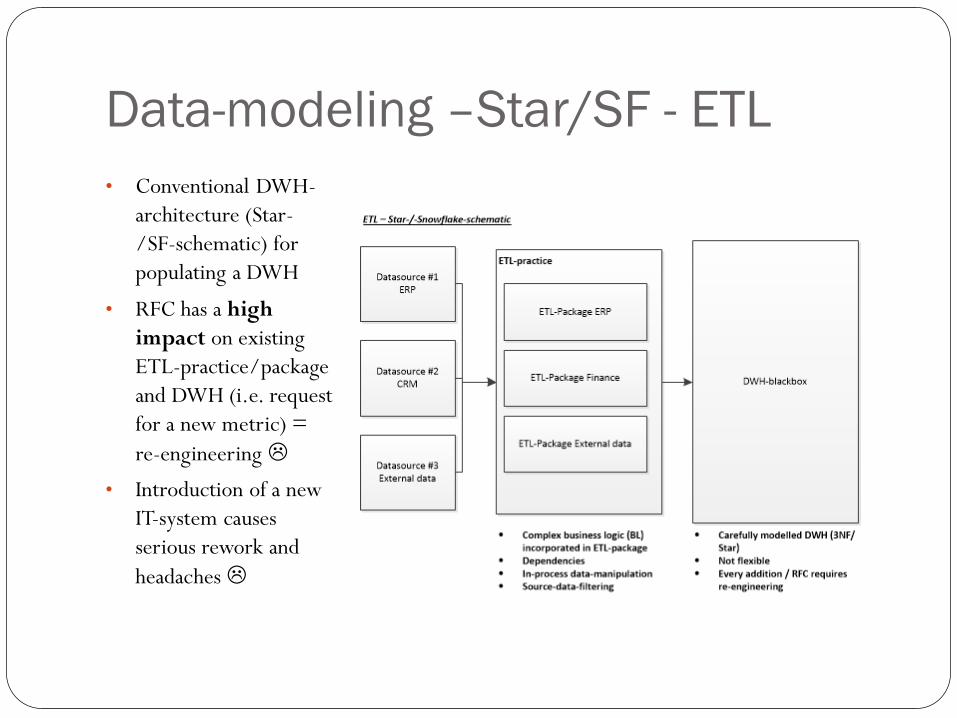
Data-modeling –Star/SF - ETL
• Conventional DWH-
architecture (Star-
/SF-schematic) for
populating a DWH
• RFC has a high
impact on existing
ETL-practice/package
and DWH (i.e. request
for a new metric) =
re-engineering
• Introduction of a new
IT-system causes
serious rework and
headaches

Data-modeling – Star/SF – ETL - P.O.A
Two types of ETL:
FULL ETL
Complete transfer of all data in source-systems via ETL-packages
Incremental ETL
After FULL ETL , incremental ETL determines the delta and loads it into
the DWH. The loading can be :
INSERT records that are not present in the DWH
UPDATE records that have changed values in certain columns
o Requires UPDATE-statements need to take into account the keys
(primary and foreign) that uniquely identify a record in a table and
execute the UPDATE-statement); risky if not entirely clear
what the unique identifier is.

Data-modeling – Star/SF – Case (1)
DWH = Snowflake-architecture (3NF)
Dimension-tables (DimItem,DimInvoice)
Fact-table (FactSalesStatistics)
ETL comprises a FULL and INCREMENTAL-load
Client A sends an RFC for an addition in the sales-overview.
Addition = metric “NetValue” per item per invoice
Additional req= metric “NetValue” is present for future data and also for data allready residing in the sales-overview
How would you guys, as future Business-/Technical-consultants / researches approach this case??

Data-modeling – Star/SF – Case (2) Solution
Identify column containing metric “NetValue” in the source-system (requires in-depth analysis of transactional system)
Add column to fact table “FactSalesStatistics” ([NetValue] [decimal] (x,y) NULL)
Revert to appropriate ETL-package; Adjust the source-query / source-columns to include the identified column
(metric)
Adjust the function that determines the Delta (add identified column)
Adjust the INSERT-command to write the value from the identified source-column metric “NetValue” in fact-table “FactSalesStatistics”
Adjust the UPDATE-command to update the metric “NetValue” with the value from the identified source-column for the existing data in table “FactSalesStatistics”
VALIDATE…VALIDATE…VALIDATE…the ERP-data and DWH-data (especially in the beginning)

Data-modeling – Star/SF – Case (3)
Introduce the new metric in your Sales-cube
Refresh the data source / data source view to get the metric
“NetValue” in the cube-server-environment
Add measure simply by adding the metric in a measuregroup in
the sales-cube
Process the cube and the metric should be available for all end-
users

Data-modeling – Datavault - Concepts Concepts
Data vault (DV) Lindstedt, D., & Graziano, K. (2011)
Data vault The Data Vault is a detail oriented, historical
tracking and uniquely linked set of
normalized tables that support one or more
functional areas of business. It is scalable and
flexible
Hub The Hub is intended to represent major
identifiable concepts-entities of interest from
the real world. It is required that every Hub
entity can be denoted by a unique identifier
Link The Link represents relationship among
Concepts. Both, Hubs and Links may be
involved in such relationships
Satellite The Satellite is used to associate a Hub
(or a Link) with (a data model) attribute
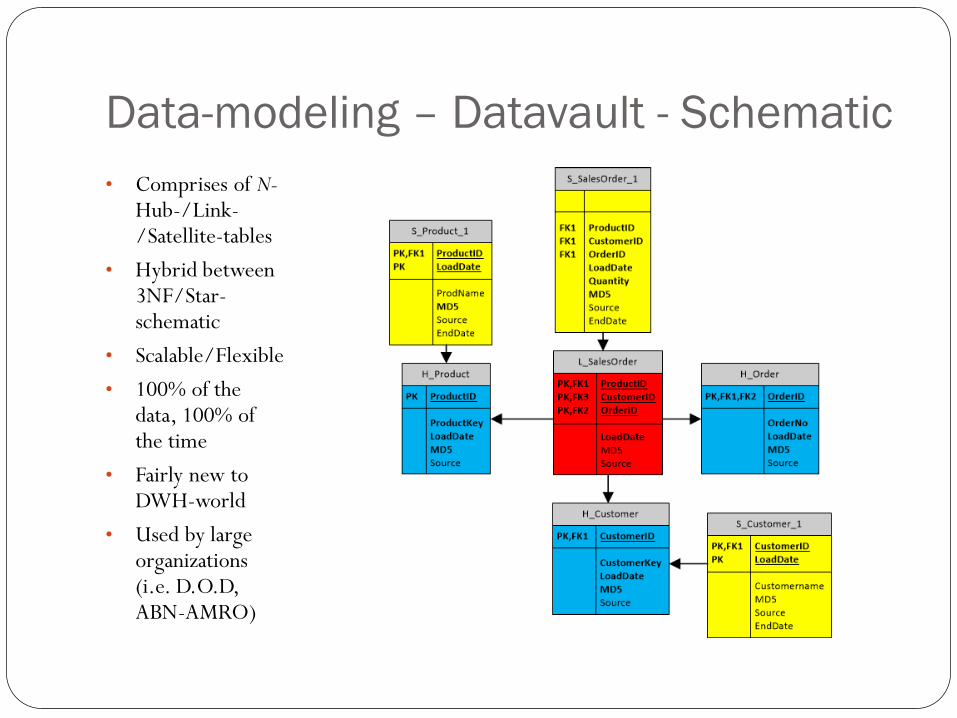
Data-modeling – Datavault - Schematic
• Comprises of N-Hub-/Link-/Satellite-tables
• Hybrid between 3NF/Star-schematic
• Scalable/Flexible
• 100% of the data, 100% of the time
• Fairly new to DWH-world
• Used by large organizations (i.e. D.O.D, ABN-AMRO)
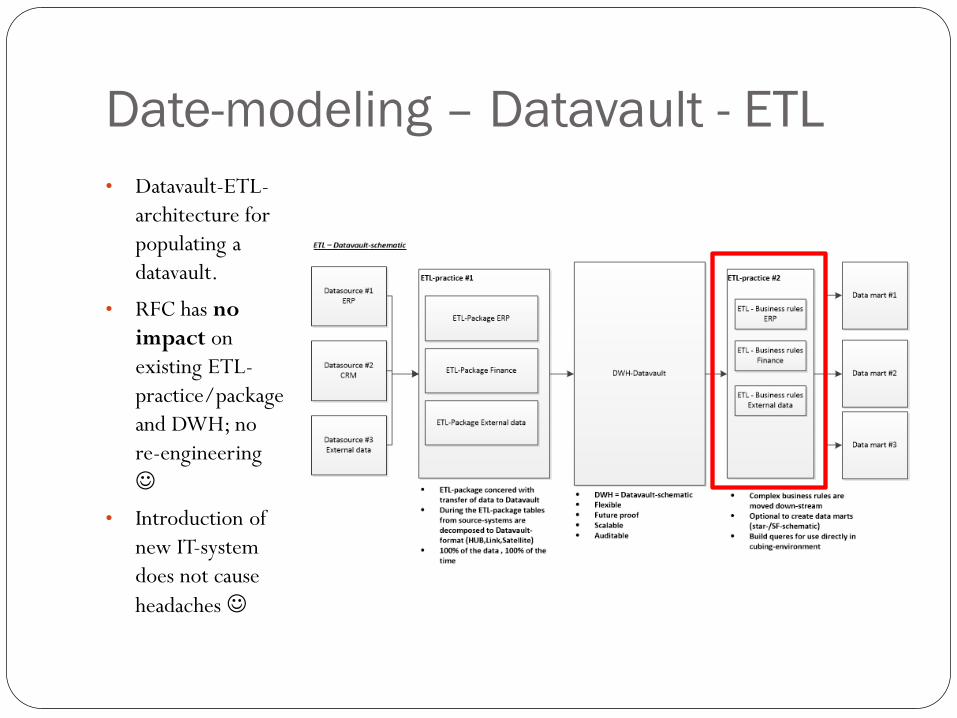
Date-modeling – Datavault - ETL
• Datavault-ETL-
architecture for
populating a
datavault.
• RFC has no
impact on
existing ETL-
practice/package
and DWH; no
re-engineering
• Introduction of
new IT-system
does not cause
headaches

Data-modeling – Datavault – ETL –
P.O.A
Two types of ETL:
FULL ETL
Complete transfer of all data in source-systems via ETL-packages
Decomposition of existing tables in to Hubs, Links, and Satellites
Incremental ETL
After FULL ETL , incremental ETL determines the delta and loads it into
the DWH. The loading can be :
INSERT records that are not present in the DWH
END-DATING records that are not valid anymore
There is no UPDATING of metric columns in Datavault. Only
an End-date update is required

Data-modeling – Datavault – Case (1) DWH = Datavault-architecture
Hub-tables (H_Product,H_Customer,H_Order)
Link-tables (L_SalesOrder)
Satellite-tables (S_Product_1,S_SalesOrder_1,S_Customer_1)
ETL comprises a FULL and INCREMENTAL-load
Client A sends an RFC for an addition in the sales-overview.
Addition = metric “NetValue” per item per order
Additional req= metric “NetValue is present for future data and also for data allready residing in the sales-overview
How would you guys, as future Business-/Technical-consultants / researches approach this case??

Data-modeling – Datavault – Case (2) Solution
Identify column containing metric “NetValue” in the source-system (requires in-depth analysis of transactional system)
Create a new table in the DWH called S_SalesOrder_2 (ProductID,CustomerID,OrderID,LoadDate,NetValue,MD5,Source,EndDate)
Create a new ETL-package
Provide the source-query/ source-columns including the new metric “NetValue”
Create the function that determines the Delta (Keyfields &identified column)
Create the INSERT-command to write the value from the identified source-column metric “NetValue” in satellite S_SalesOrder_2 with additional values for “ProductID,CustomerID,OrderID,LoadDate,MD5,Source)
Optional: Create EndDate-function (with the help of staging-tables)
VALIDATE…VALIDATE…VALIDATE…the ERP-data and DWH-data (especially in the beginning)
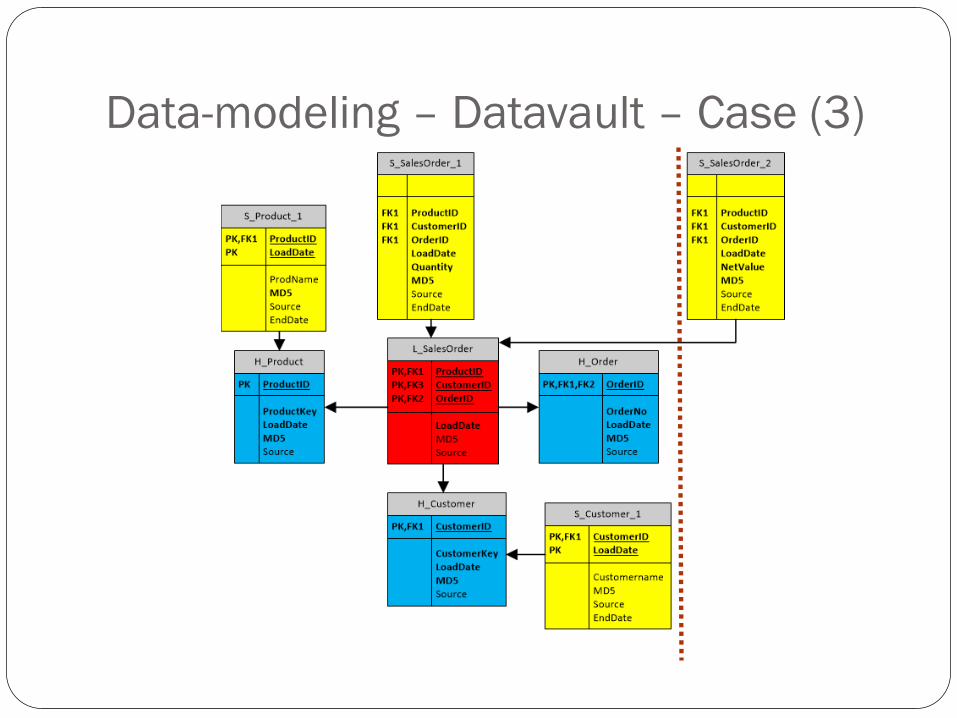
Data-modeling – Datavault – Case (3)
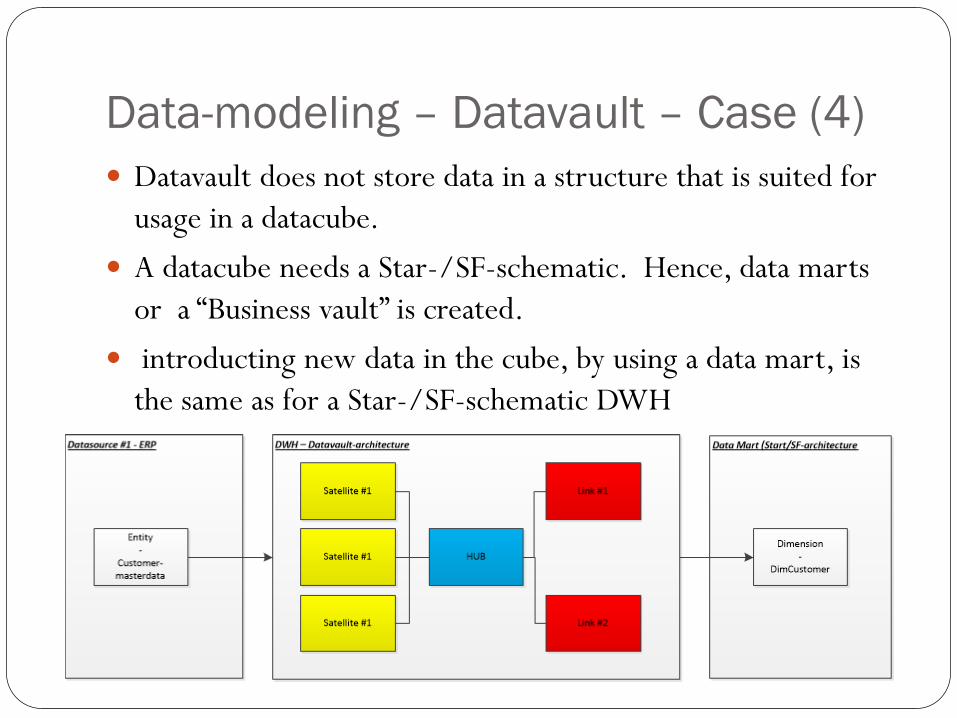
Data-modeling – Datavault – Case (4)
Datavault does not store data in a structure that is suited for
usage in a datacube.
A datacube needs a Star-/SF-schematic. Hence, data marts
or a “Business vault” is created.
introducting new data in the cube, by using a data mart, is
the same as for a Star-/SF-schematic DWH
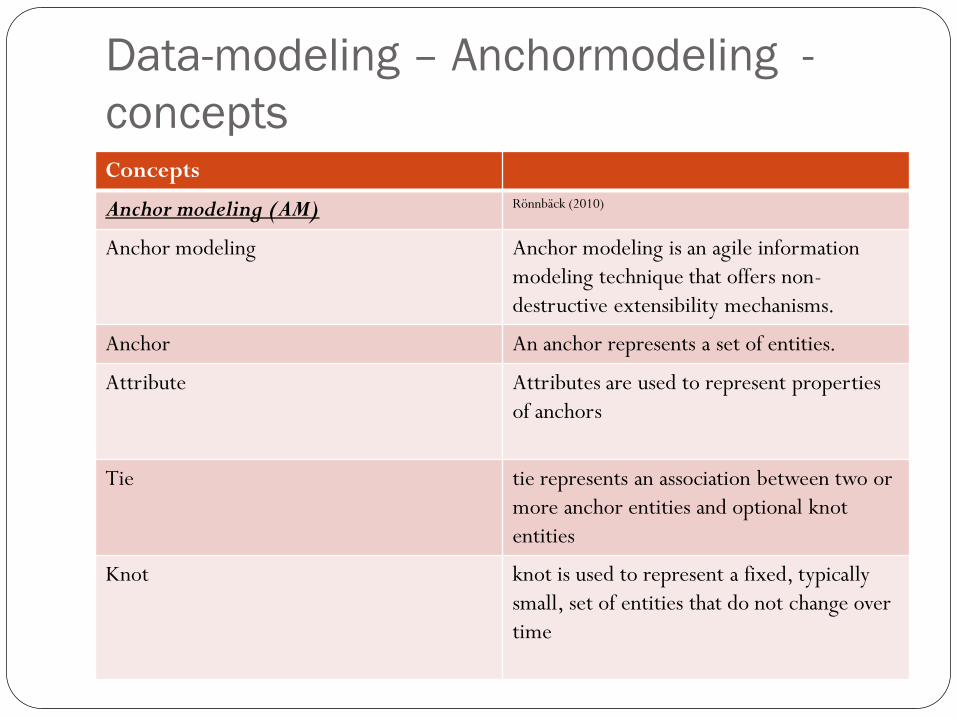
Data-modeling – Anchormodeling -
concepts Concepts
Anchor modeling (AM) Rönnbäck (2010)
Anchor modeling Anchor modeling is an agile information
modeling technique that offers non-
destructive extensibility mechanisms.
Anchor An anchor represents a set of entities.
Attribute Attributes are used to represent properties
of anchors
Tie tie represents an association between two or
more anchor entities and optional knot
entities
Knot knot is used to represent a fixed, typically
small, set of entities that do not change over
time
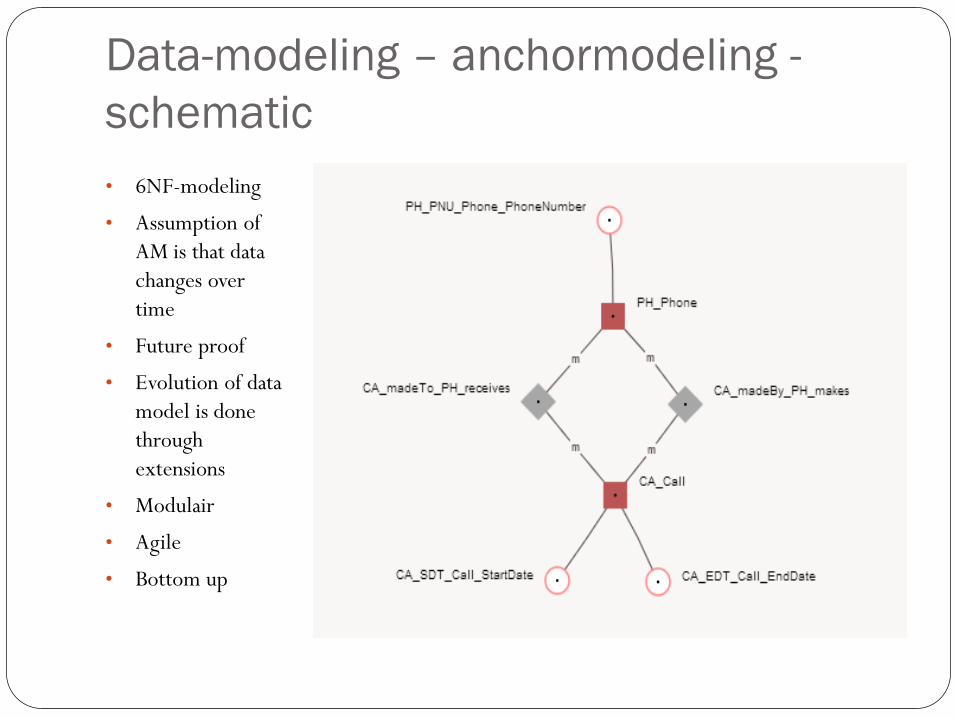
Data-modeling – anchormodeling -
schematic
• 6NF-modeling
• Assumption of
AM is that data
changes over
time
• Future proof
• Evolution of data
model is done
through
extensions
• Modulair
• Agile
• Bottom up

Data-modeling – anchormodeling - ETL
ETL-procedure has many similarities with DV-ETL-ing
In DV first the HUBS are filled, followed by the LINKS and to finish it of the SATELLITES are filled.
With AM at first the ANCHORS are populated, followed by the TIES and ATTRIBUTES
In addition a metadata-repository is filled with each ETL-run
Like DV, there are only INSERT-statements and END-DATING-procedures.
NO UPDATE-statement
DELETE-statement is only performed when errornous data is loaded for a given batch

Data-modeling – anchormodeling –
ETL – P.O.A
In an ANCHOR only the surrogate key is stored. While with DV in a HUB the surrogate key and businesskey are stored together
How is this resolved in an ETL-environment?
Well, when implementing an AM in a database, views are created for each anchor (comprising the anchor and attributes) with an insert-trigger We can simply populate the anchor and attributes through the view
created by the online modeler.
Additional attributes can be loaded in parallel like in DV. For each of those attributes the surrogatekey is resolved by referencing the businesskey-attribute.

BREAK

Practical examples
Star /SF-schematic
ETL
DWH
Datavault
ETL
DWH
Anchor Modeling
ETL
DWH

Summary (1)
Two main DWH-design-strategies
Enterprise wide DWH-design
DWH is designed by using a normalized enterprise data model
From the EDWH data marts for specific business domains are derived
Data mart Design
Create datamarts in a bottom-up fasion
Datamart-design conforms to a top-down skeleton/framwork-design
which is called the “data warehouse bus”
The EDW = the union of the conformed datamarts

Summary (2) Four main Data-modeling-techniques
Star-/Snowflake were introduced in the 80’s Star-/Snowflake requires re-engineering when introducing new metrics
or systems at the source (ETL/DWH). High impact
Not Agile, specs are determined beforehand, traditional way of system development deliver results slow hard to expand existing
Datavault / anchor-modeling introduced in early/mid 00’s Flexible, Scalable data-model, requires no re-engineering when
introducing new metrics or systems at the source (ETL/DWH), simply extend/expand. Little to no impact
Agile fast developemt track due to iterative development start small deliver results fast Expand Scale without effort

Summary (3)
So, which data-modeling technique comes out as the
winner…
Well, None, they can co-exist and you should choose the one
that is suited for your needs,demands, skillset etc.
It is merely a tool for acieving your goal













![[Itpub.net]Oracle Database 11g BI and Data Warehousing D52358](https://img.pdfslide.net/doc/110x75/55cf9baa550346d033a6ec88/itpubnetoracle-database-11g-bi-and-data-warehousing-d52358.jpg)















