Embed Size (px)
Citation preview

Boost.Spirit.QiとLLVM APIで遊ぼう NV(@nvsofts)

自己紹介
• HN:NV • Twitter:@nvsoftsでやっています(*´ω`*)
• Gentoo大大学院修士2年
• (株)ウサギィでC++とかDとかPythonとかを使ってバイトしています
• 昔にプログラミング言語KQなんてものを作りました

本日のテーマについて
• この2つを使ってプログラミング言語の処理系を作るときの話 • Boost.Spirit.Qi • LLVM API
(こう書くと多方面からフルボッコにされそうですが…)

こんな感じに
作成した処理系のソース
• 2つのライブラリを使って作成した処理系は、GitHubに公開しています(少し前に作ったものです)
https://github.com/nvsofts/GikoLLVM/
• コードをちらっと見ながらだと分かりやすいかも…? • 個人差があります

Boost.Spirit.Qiとはなんぞや • オープンソースライブラリであるBoost C++ Librariesに含まれている構文解析のためのライブラリ • Qiは「キー」って読むらしい(from:BoostConの動画)
• 演算子オーバーロードを巧みに使い、EBNFっぽいコードを書くだけで構文解析器ができあがる
• 構文規則に対するアクションは、Boost.Phoenixという無名関数記述ライブラリが使うことで楽に書ける

Boost.Sprit.Qiの使い方 • 基本的に文法を定義して、以下の関数を使って構文解析を行うことで使う • boost::spirit::qi::phrase_parse!
• 空白など、解析時に飛ばしたいもの(Skipper)があるときに使う • boost::spirit::qi::parse !
• 上のものとは違い、飛ばしたいものがないときに使う
• ここでは、空白を飛ばしたいのでphrase_parseを使う

Boost.Sprit.Qiの使い方 • phrase_parseのコード例
using namespace boost::spirit; !!std::string input; !std::vector<int> result; !auto it = input.begin(); !!bool success = qi::phrase_parse(it, input.end(), int_ % ',', ascii::space, result); !
• 解析が成功していればsuccessがtrueかつ、it == input.end()になっている

ルール
• 文法は1つ以上のルールで構成され、boost::spirit::qi::ruleのインスタンス
• セマンティックアクションと呼ばれる、そのルールが使われたときに呼ばれる関数を設定できる • 当然、渡すのは関数オブジェクトでもOK • しかし、C++11のラムダ式や関数オブジェクトでやるには少し面倒な要素が含まれているので、Boost.Phoenixを使った無名関数を使うのがおすすめ
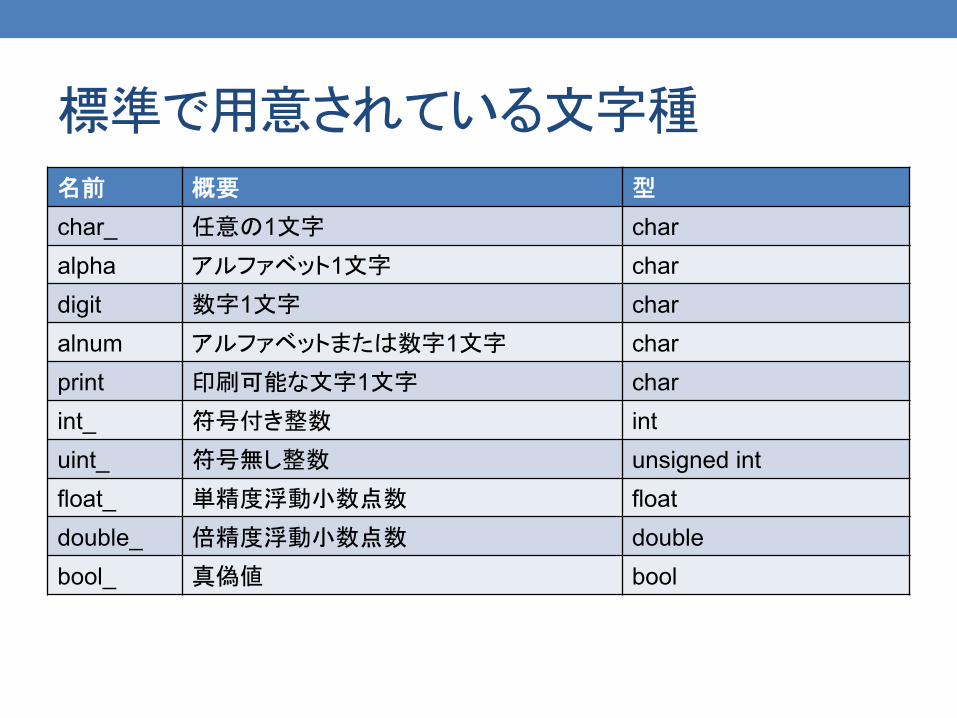
標準で用意されている文字種
名前 概要 型
char_ 任意の1文字 char alpha アルファベット1文字 char digit 数字1文字 char alnum アルファベットまたは数字1文字 char print 印刷可能な文字1文字 char int_ 符号付き整数 int uint_ 符号無し整数 unsigned int float_ 単精度浮動小数点数 float double_ 倍精度浮動小数点数 double bool_ 真偽値 bool

ルール同士の結合
• ルール同士の結合には、>>演算子を使う • 注意するべきことは、>>演算子が入るところにはSkipperのような無視するべき文字列が入ることがあること • これは、識別子のような途中にSkipperが入るとまずい場合に遭遇したときに対応しないといけない
• 途中でSkipperが入って欲しくない場合は、lexeme[〜]で囲えばOK

ルールの繰り返しと選択
• 標準の文字種はほとんど1文字のみ読むもので、複数文字読みたい場合は繰り返しルールを適用する必要がある • 0回以上の繰り返しにはルールの前に*演算子を付ける • 1回以上の繰り返しにはルールの前に+演算子を付ける
• また、複数のルールのうちどれかを選択するようなルールを記述する場合がある • ルールの選択には|(パイプ記号)演算子を使う

Boost.Phoenixの概要 • プレースホルダーと組み合わせると、演算子オーバーロードを駆使して目的の関数オブジェクトを作ってくれる
• プレースホルダーとして以下のものなどがある • _1, _2, …, _N !
• N番目の引数、Boost.Spirit.Qiではほとんど_1のみ使用 • _val!
• ルールや文法における、最終的に返す値 • _pass !
• falseを代入すると、強制的に構文解析を失敗させる

Boost.Phoenixの概要 • 基本的に、プレースホルダーを使ってやりたいことを書けばOK • 複数の処理を行いたい場合は、カンマで区切る
• しかし、一部の処理は記法が違うので注意 • 例:new演算子
• _new<T>(引数) !• 例:コンテナへのpush_back!
• push_back(対象, 値) !

Boost.Phoenixの概要 • 構造体やクラスへのアクセス
• phoenix::at_c<N>を使う • 例:返す構造体の0番目の要素に1番目の引数を代入する phoenix::at_c<0>(_val) = _1 !!
• 独自の構造体やクラスを使う場合は、BOOST_FUSION_ADAPT_STRUCTマクロでの登録が必要 !

複雑な文法を定義する
• 前の例では簡単な文法だったので引数に入れた • しかし、複雑なルールを含んだ文法になる場合は、別途構造体等を定義してそこに入れる方が良い場合もある
• 文法はboost::spirit::qi::grammarを継承して作る(テンプレート引数は最高で4つ) • Iterator:使用するイテレータの型 • A1:最終的に返す型、()を付ける • A2:飛ばすべきものを示した文法(Skipper)の型 • A3:文法内のローカル変数の型、通常は使わない

複雑な文法を定義する • カンマ区切りの整数を解析してstd::vector<int>として返すような文法の例
template <typename Iter, typename Skip> !struct grammar : qi::grammar<Iter, std::vector<int>(), Skip> !{ ! template <typename T> ! using rule = qi::rule<Iterator, T, Skipper>; ! ! rule<std::vector<int>()> int_rule; ! ! grammar() : grammar::base_type(int_rule) ! { ! int_rule = int_[push_back(_val, _1)] >> ',' >> *(int_[push_back(_val, _1)]); ! } !};

Boost.Spirit.Qiで抽象構文解析木(AST)を作る
• ルールを書き、それに対するセマンティックアクション内でルールに対応するASTのインスタンスを生成して返す • _newが必要なのはこのため
• 例 template <typename T> using rule = qi::rule<Iterator, T, Skipper>; rule<AssignAST *()> assign;!assign = id[_val = new_<AssignAST>(_1)] >> '=' >> expr[phoenix::at_c<1>(*_val) = _1]; !(ここで、idは識別子、exprは式を表すルールとする) !

ASTはできたが… • このASTをネイティブコードへ変換しないといけない
• ネイティブコードへの変換は気が遠くなるような作業
• LLVM APIなら、ネイティブコードへの変換を比較的容易に行える

LLVMとはなんぞや • 任意のプログラミング言語に対応可能なオープンソースのコンパイラ基盤 • Clangなどで使われている
• 仮想機械をターゲットとしたIRと呼ばれる中間コードを扱う
• IRはネイティブコードへ変換することができる • つまり、IRへの変換プログラムだけ書けばどんなプログラミング言語にも対応できる
• C++で記述されており、APIも豊富

LLVM IRを出力する • LLVM IRはC++においてはクラスのインスタンスで表現されるが、インスタンスを作る方法も物によってまちまち
• そこで、LLVM APIにあるIRBuilderを使うことで、簡単にLLVM IRのC++による表現を作ることができる
• IRBuilderに含まれる関数の一部 • CreateAdd(左辺値, 右辺値, 命令に付けるラベル)
• 加算命令を生成する • CreateCall(関数, 引数の配列)
• 関数の呼び出し命令を生成する

IRBuilderの実際の使用例 • 2項演算子の処理部分 • ASTの注目している葉に含まれている演算子の情報から対応する命令を生成する関数を呼んでいる
std::string &op = bin_expr->getOp(); if (op == "+") { return this->builder->CreateAdd(v_lhs, v_rhs, "add"); }else if (op == "-") { return this->builder->CreateSub(v_lhs, v_rhs, "sub"); }else if (op == "*") { return this->builder->CreateMul(v_lhs, v_rhs, "mul"); }else if (op == "/") { return this->builder->CreateSDiv(v_lhs, v_rhs, "div"); }else if (op == "%") { return this->builder->CreateSRem(v_lhs, v_rhs, "rem"); }

LLVM IRのファイルへの出力 • LLVM IRのC++による表現ができあがったら、ファイルへ出力する
• これにはraw_fd_ostreamとWriteBitcodeToFile関数を使う
using namespace llvm; Module *module; std::error_code error; raw_fd_ostream raw_stream("out.bc", error, sys::fs::OpenFlags::F_RW); WriteBitcodeToFile(module, raw_stream); raw_stream.close();

ネイティブコードへの変換
• ネイティブコードへの変換は、llvm-asコマンドを使う • $ llvm-as <*.bcへのパス> !
• これだけで、ネイティブなアセンブリ言語のコードを得られる • Clangが入っているのなら、clangコマンドに直接*.bcを投げ込んでも大丈夫
• ネイティブコードに変換したら、あとは用意した標準ライブラリとリンクして実行可能なファイルを得るだけ

全体の流れ
1. ソースコードを読み込む 2. Boost.Spirit.Qiによってソースコードの構文解析を行い、ASTを作成する
3. 作成されたASTをもとに、LLVM APIのIRBuilderでLLVM IRを作成する
4. 作成されたLLVM IRをファイルへ出力する 5. ファイルへ出力されたLLVM IRをネイティブコードへと変換し、実行可能な形式にする

参考になりそうなページや本
• Let’s BoostのBoost.Spiritの項目 • http://www.kmonos.net/alang/boost/classes/spirit.html
• きつねさんでもわかるLLVM • 少し現在のLLVMでは動かないコードがありますが、基本はおさえています
• ライブラリのドキュメントやDoxygen • http://www.boost.org/libs/spirit/ • http://llvm.org/docs/ • http://llvm.org/doxygen/

まとめ
• Boost.Spirit.QiとLLVM APIを組み合わせることで、プログラミング言語の処理系を生産性を確保して作成できる • これなら「ネタ言語って言ってもどうせBrainf*ck系でしょ?」って言われても切り返せるネタ言語が作れる
• LLVM IRの形にしてしまえば、LLVMに付属している最適化機構が使えるので本質のみに集中できる
• この組み合わせで実用的なネタ言語(?)を作ろう!





























