Embed Size (px)
Citation preview

Bot Not?@erinshellman PyData Seattle, July 26, 2015
or End-to-end data analysis in Python

PySpark Workshop @Tune
August 27, 6-8pm
Starting a new career in software @Moz
October 22, 6-8pm

Q: Why?Bots are fun.
Q: How?Python.


In 2009, 24% of tweets were generated by bots.

Last year Twitter disclosed that 23 million of its active users were bots.


Hypothesis:
Bot behavior is differentiable from human behavior.

Experimental Design
• Ingest data
• Clean and process data
• Create a classifier

Experimental Design• Ingest data
• python-twitter
• Clean and process data
• Pandas, NLTK, Seaborn, iPython Notebooks
• Create a classifier
• Scikit-learn

Step 1: Get data.


lollollollol

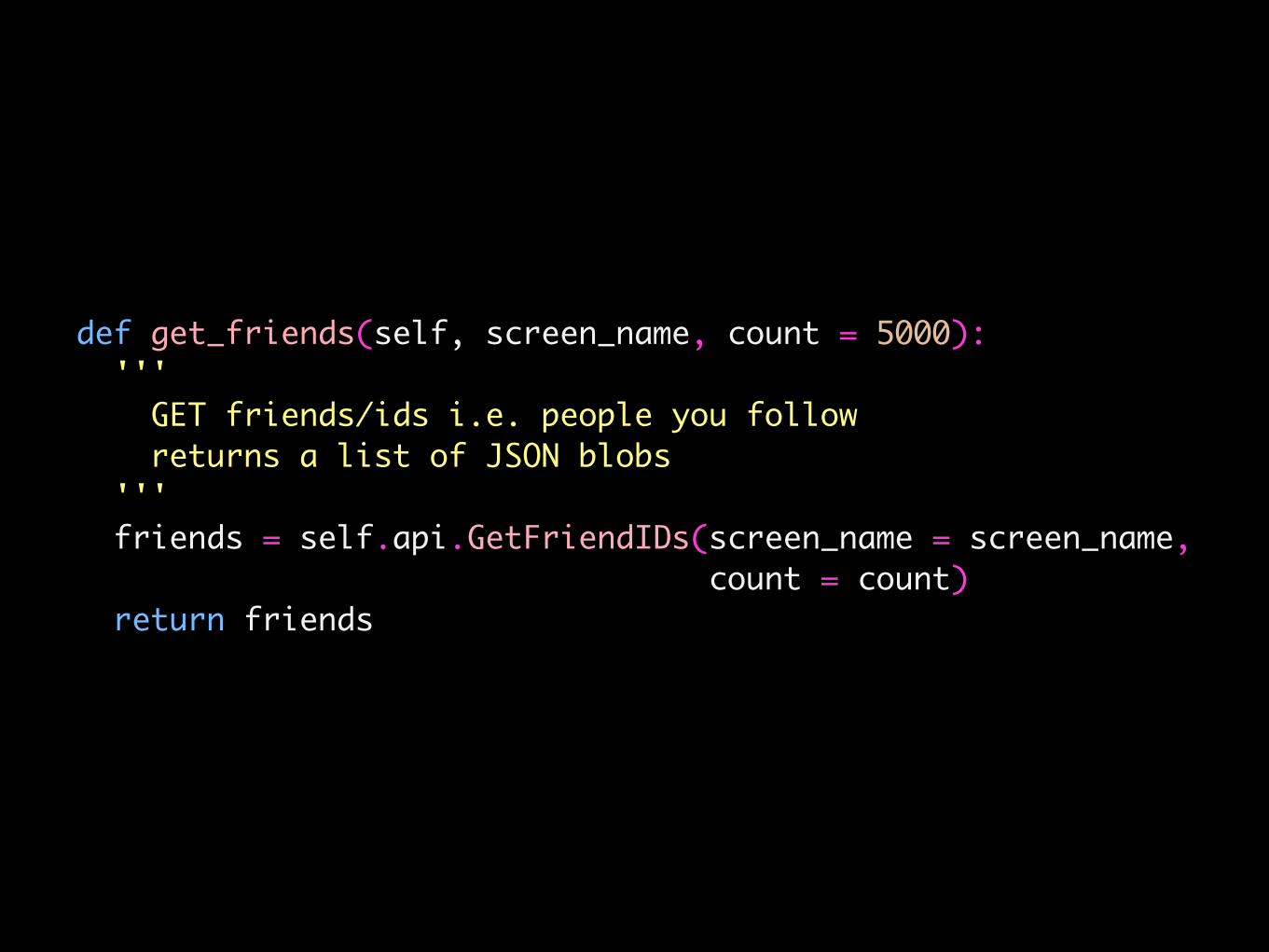
def get_friends(self, screen_name, count = 5000): ''' GET friends/ids i.e. people you follow returns a list of JSON blobs ''' friends = self.api.GetFriendIDs(screen_name = screen_name, count = count) return friends


# break query into bite-size chunks 🍔def blow_chunks(self, data, max_chunk_size): for i in range(0, len(data), max_chunk_size): yield data[i:i + max_chunk_size]

if len(user_ids) > max_query_size: chunks = self.blow_chunks(user_ids, max_chunk_size = max_query_size) while True: try: current_chunk = chunks.next() for user in current_chunk: try: user_data = self.api.GetUser(user_id = str(user)) results.append(user_data.AsDict()) except: print "got a twitter error! D:" pass print "nap time. ZzZzZzzzzz..." time.sleep(60 * 16) continue except StopIteration: break

if len(user_ids) > max_query_size: chunks = self.blow_chunks(user_ids, max_chunk_size = max_query_size) while True: try: current_chunk = chunks.next() for user in current_chunk: try: user_data = self.api.GetUser(user_id = str(user)) results.append(user_data.AsDict()) except: print "got a twitter error! D:" pass print "nap time. ZzZzZzzzzz..." time.sleep(60 * 16) continue except StopIteration: break
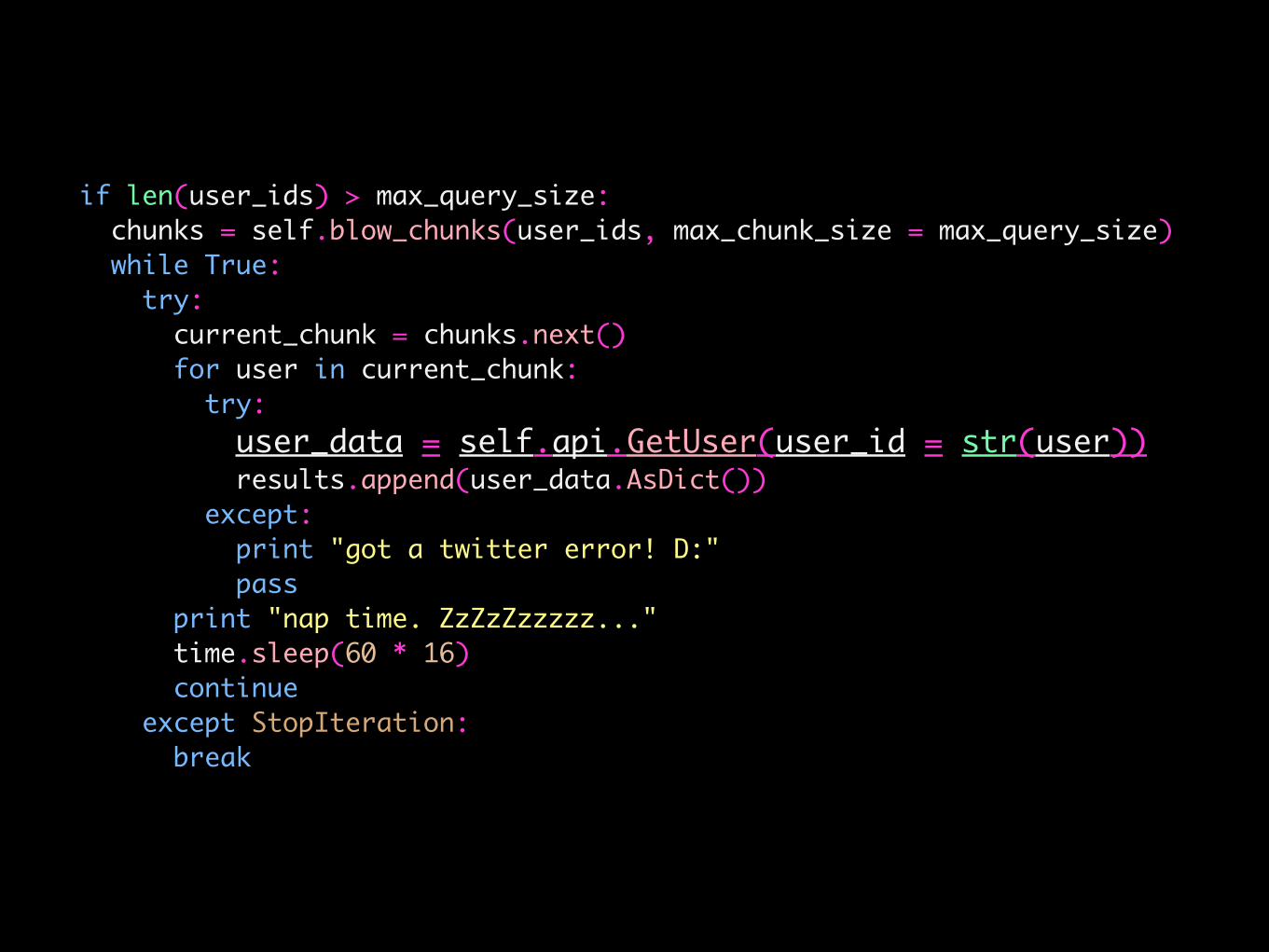
if len(user_ids) > max_query_size: chunks = self.blow_chunks(user_ids, max_chunk_size = max_query_size) while True: try: current_chunk = chunks.next() for user in current_chunk: try: user_data = self.api.GetUser(user_id = str(user)) results.append(user_data.AsDict()) except: print "got a twitter error! D:" pass print "nap time. ZzZzZzzzzz..." time.sleep(60 * 16) continue except StopIteration: break

if len(user_ids) > max_query_size: chunks = self.blow_chunks(user_ids, max_chunk_size = max_query_size) while True: try: current_chunk = chunks.next() for user in current_chunk: try: user_data = self.api.GetUser(user_id = str(user)) results.append(user_data.AsDict()) except: print "got a twitter error! D:" pass print "nap time. ZzZzZzzzzz..." time.sleep(60 * 16) continue except StopIteration: break
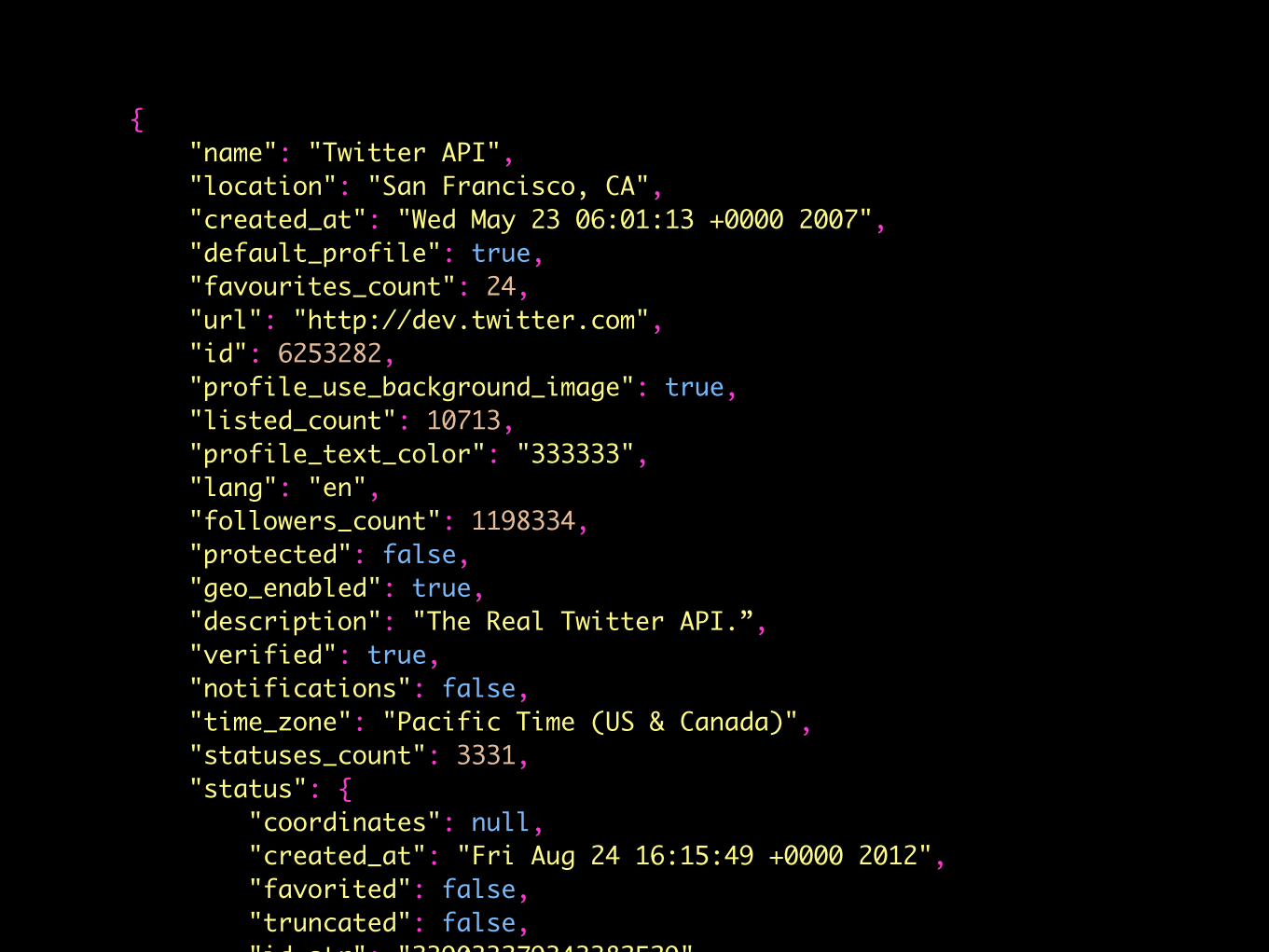
{ "name": "Twitter API", "location": "San Francisco, CA", "created_at": "Wed May 23 06:01:13 +0000 2007", "default_profile": true, "favourites_count": 24, "url": "http://dev.twitter.com", "id": 6253282, "profile_use_background_image": true, "listed_count": 10713, "profile_text_color": "333333", "lang": "en", "followers_count": 1198334, "protected": false, "geo_enabled": true, "description": "The Real Twitter API.”, "verified": true, "notifications": false, "time_zone": "Pacific Time (US & Canada)", "statuses_count": 3331, "status": { "coordinates": null, "created_at": "Fri Aug 24 16:15:49 +0000 2012", "favorited": false, "truncated": false, "id_str": "239033279343382529",
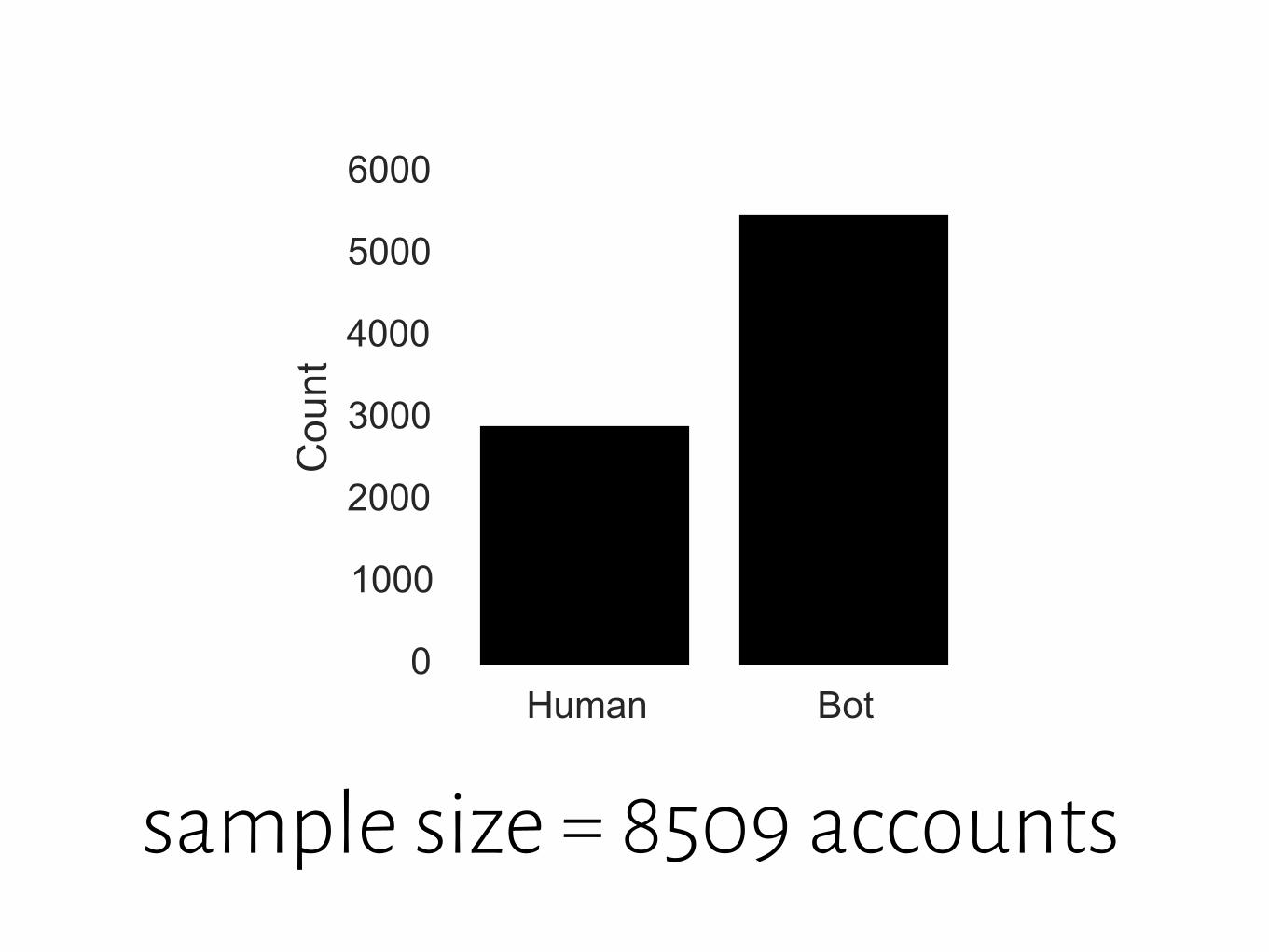
sample size = 8509 accounts

Step 2: preprocessing.

Who's ready1. “Flatten” the JSON into one
row per user.
2.Variable recodes. e.g. consistently denoting missing values, True/False into 1/0
3.Select only desired features for modeling.
to clean?
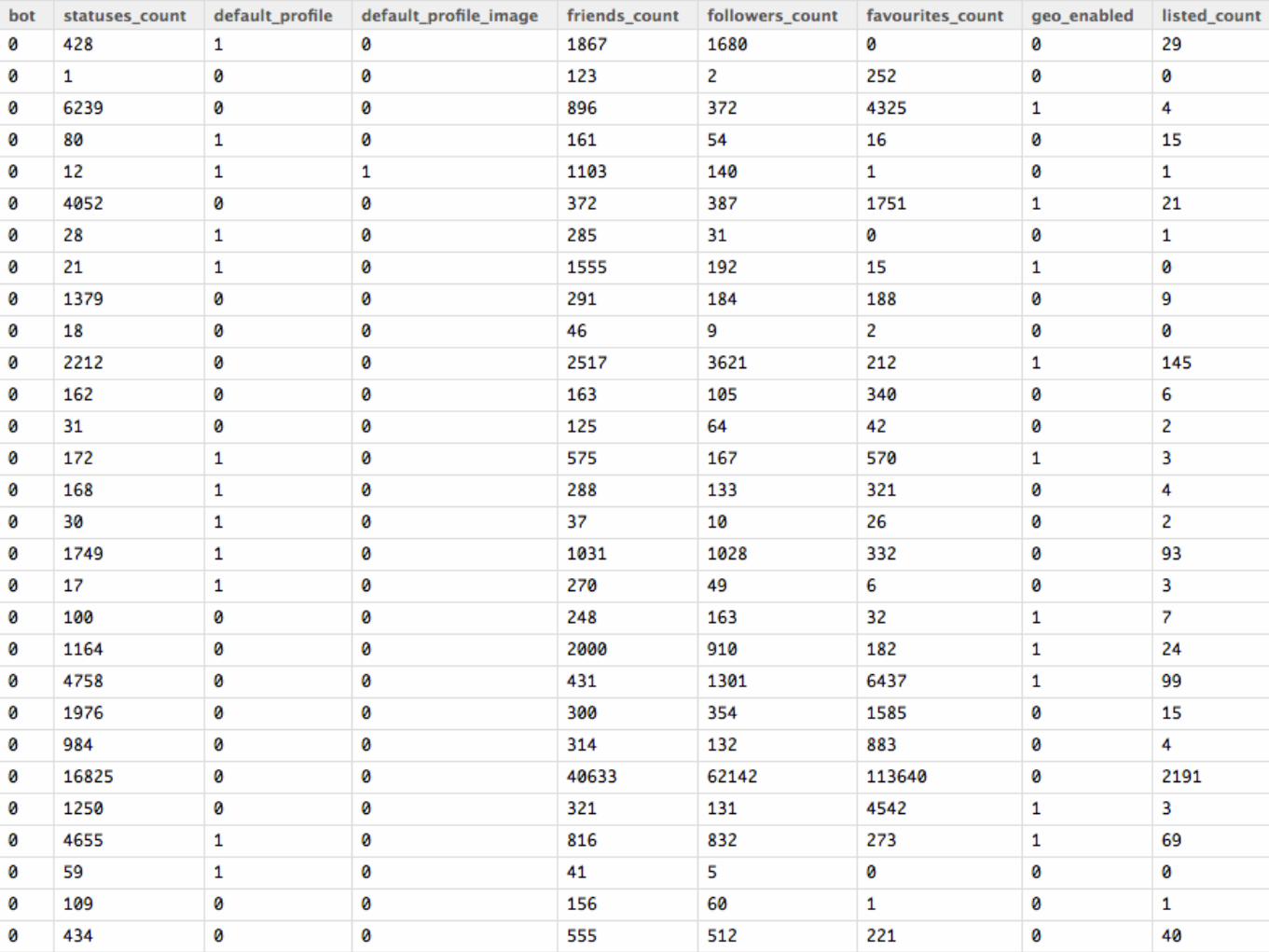



How to make data with this?


e.g. Lexical Diversity
• A token is a sequence of characters that we want to treat as a group.
• For instance, lol, #blessed, or 💉🔪💇
• Lexical diversity is the ratio of unique tokens to total tokens.
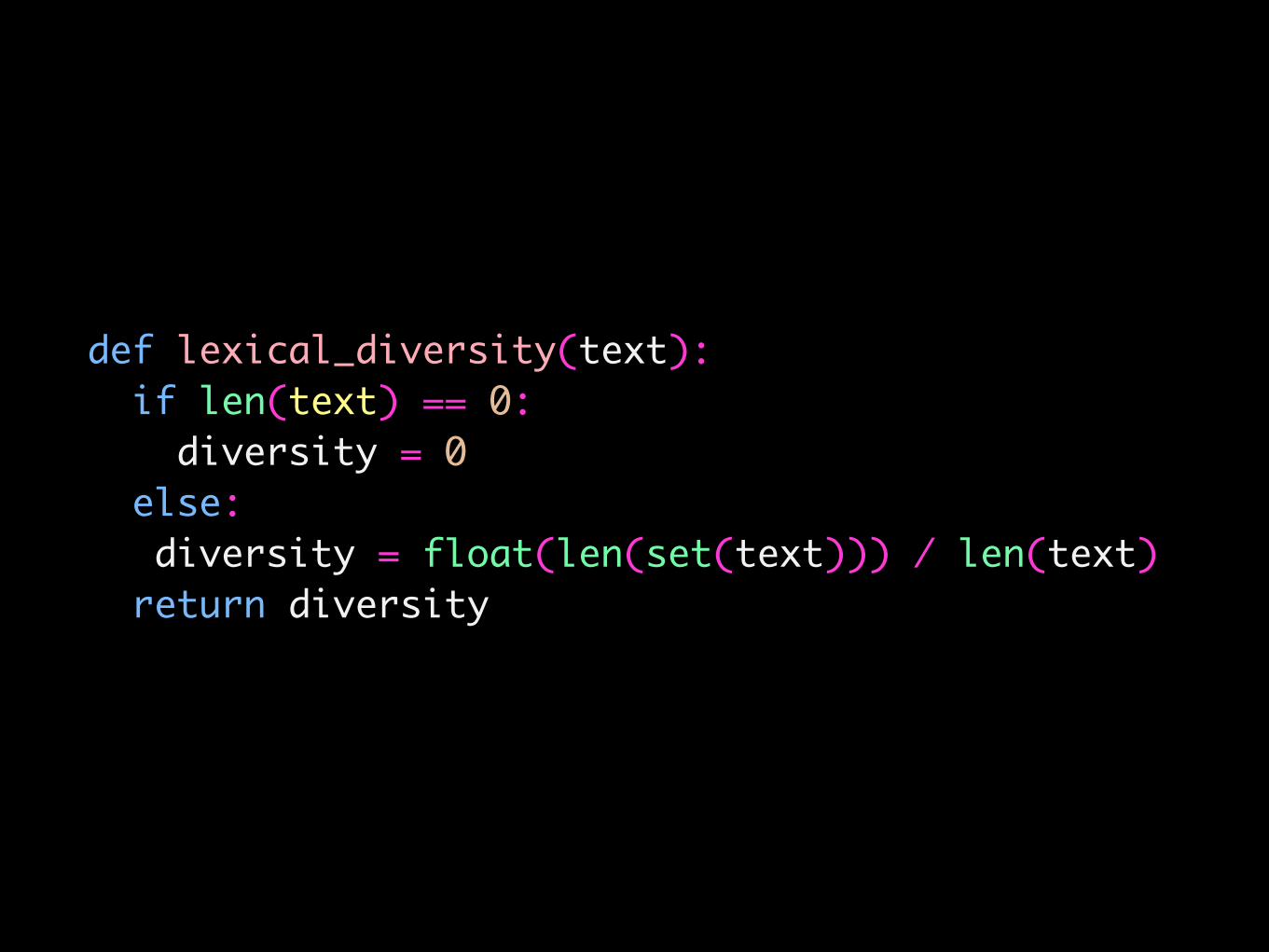
def lexical_diversity(text): if len(text) == 0: diversity = 0 else: diversity = float(len(set(text))) / len(text) return diversity
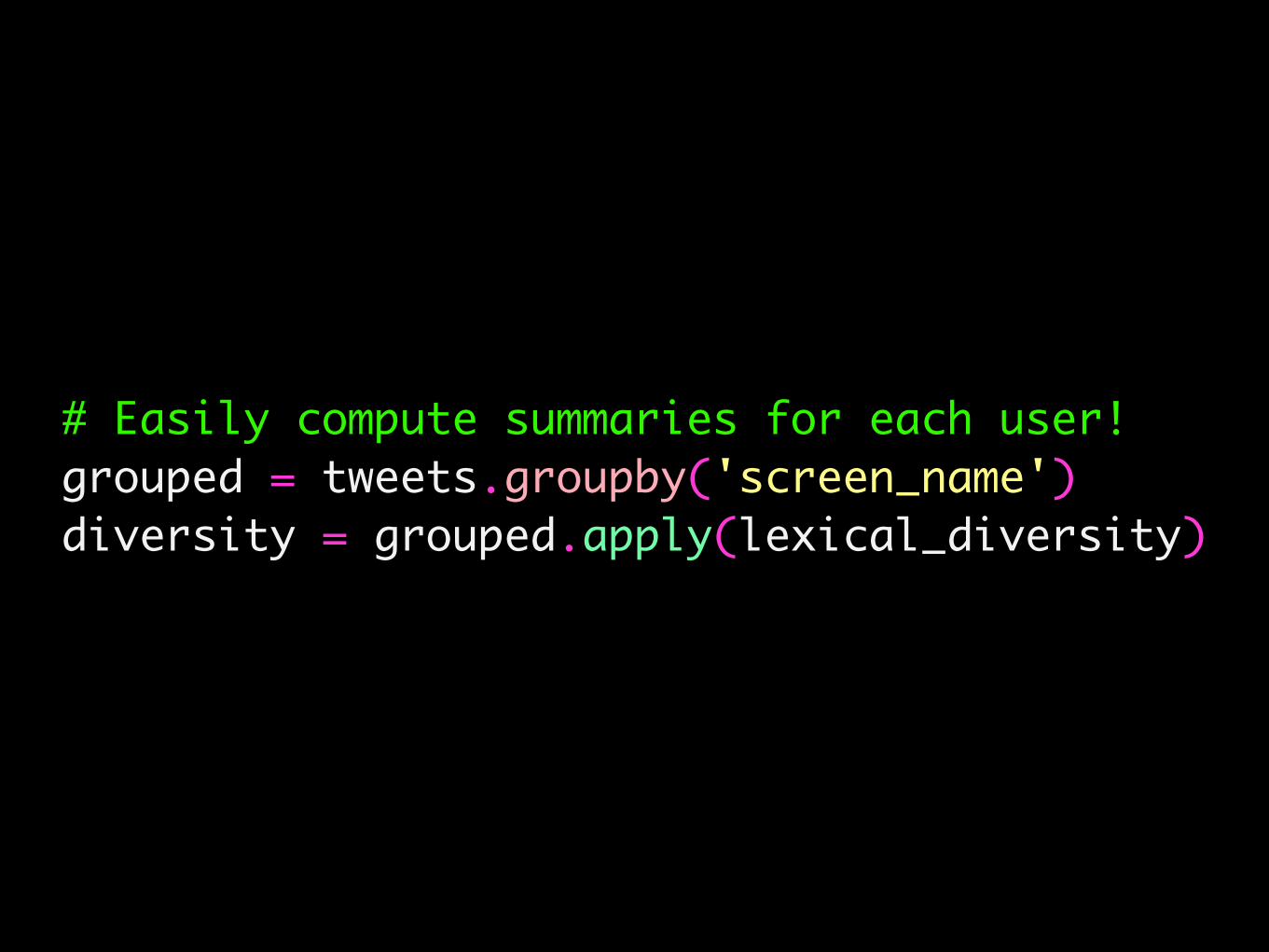
# Easily compute summaries for each user!grouped = tweets.groupby('screen_name')diversity = grouped.apply(lexical_diversity)


Step 3: Classification.

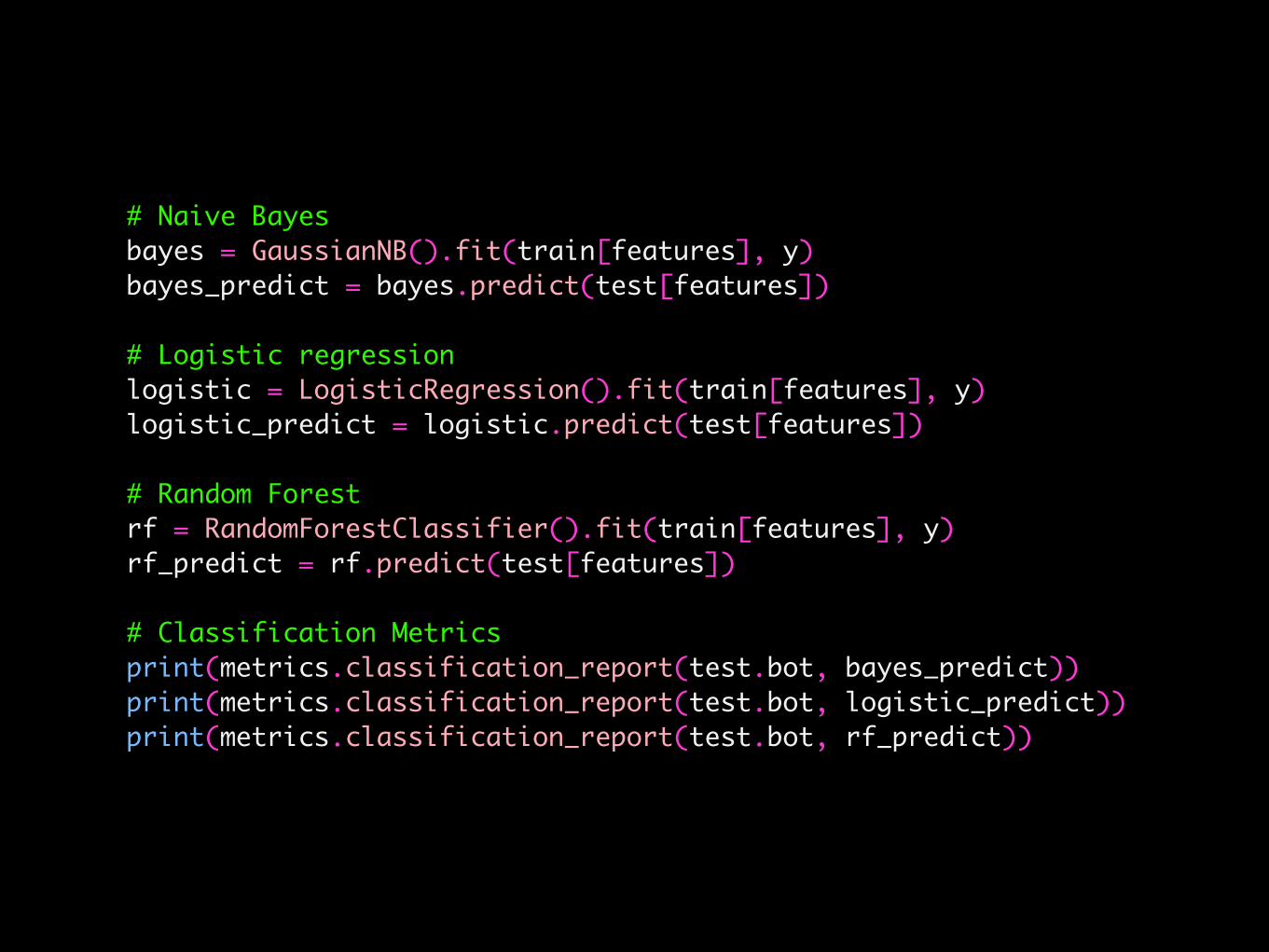
# Naive Bayesbayes = GaussianNB().fit(train[features], y)bayes_predict = bayes.predict(test[features])
# Logistic regressionlogistic = LogisticRegression().fit(train[features], y)logistic_predict = logistic.predict(test[features])
# Random Forestrf = RandomForestClassifier().fit(train[features], y)rf_predict = rf.predict(test[features])
# Classification Metricsprint(metrics.classification_report(test.bot, bayes_predict))print(metrics.classification_report(test.bot, logistic_predict))print(metrics.classification_report(test.bot, rf_predict))

precision recall f1-score 0.0 0.97 0.27 0.42 1.0 0.20 0.95 0.33
avg / total 0.84 0.38 0.41
precision recall f1-score 0.0 0.85 1.00 0.92 1.0 0.94 0.14 0.12
avg / total 0.87 0.85 0.79
precision recall f1-score 0.0 0.91 0.98 0.95 1.0 0.86 0.51 0.64
avg / total 0.90 0.91 0.90
Naive Bayes
Logistic Regression
Random Forest

# construct parameter gridparam_grid = {'max_depth': [1, 3, 6, 9, 12, 15, None], 'max_features': [1, 3, 6, 9, 12], 'min_samples_split': [1, 3, 6, 9, 12, 15], 'min_samples_leaf': [1, 3, 6, 9, 12, 15], 'bootstrap': [True, False], 'criterion': ['gini', 'entropy']}
# fit best classifiergrid_search = GridSearchCV(RandomForestClassifier(), param_grid = param_grid).fit(train[features], y)
# assess predictive accuracypredict = grid_search.predict(test[features])print(metrics.classification_report(test.bot, predict))

print(grid_search.best_params_)
{'bootstrap': True, 'min_samples_leaf': 15, 'min_samples_split': 9, 'criterion': 'entropy', 'max_features': 6, 'max_depth': 9}
Best parameter set for random forest

precision recall f1-score 0.0 0.93 0.99 0.96 1.0 0.89 0.59 0.71
avg / total 0.92 0.93 0.92
precision recall f1-score 0.0 0.91 0.98 0.95 1.0 0.86 0.51 0.64
avg / total 0.90 0.91 0.90
Default Random Forest
Tuned Random Forest
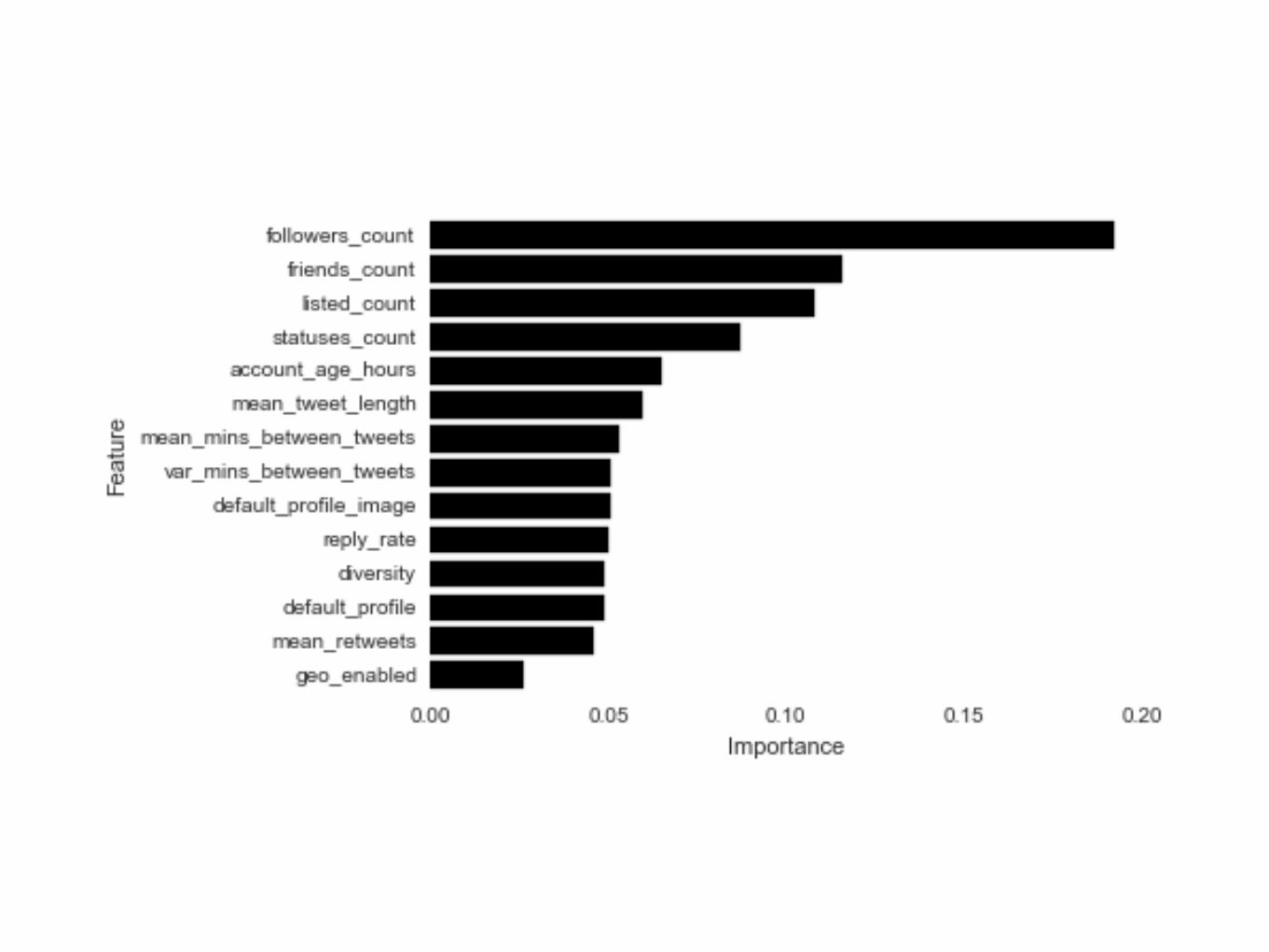

Iterative model development in Scikit-learn is laborious.

logistic_model = train(bot ~ statuses_count + friends_count + followers_count, data = train, method = 'glm', family = binomial, preProcess = c('center', 'scale'))

> confusionMatrix(logistic_predictions, test$bot)Confusion Matrix and Statistics
ReferencePrediction 0 1 0 394 22 1 144 70 Accuracy : 0.7365 95% CI : (0.7003, 0.7705) No Information Rate : 0.854 P-Value [Acc > NIR] : 1 Kappa : 0.3183 Mcnemars Test P-Value : <2e-16 Sensitivity : 0.7323 Specificity : 0.7609 Pos Pred Value : 0.9471 Neg Pred Value : 0.3271 Prevalence : 0.8540 Detection Rate : 0.6254 Detection Prevalence : 0.6603 Balanced Accuracy : 0.7466 'Positive' Class : 0
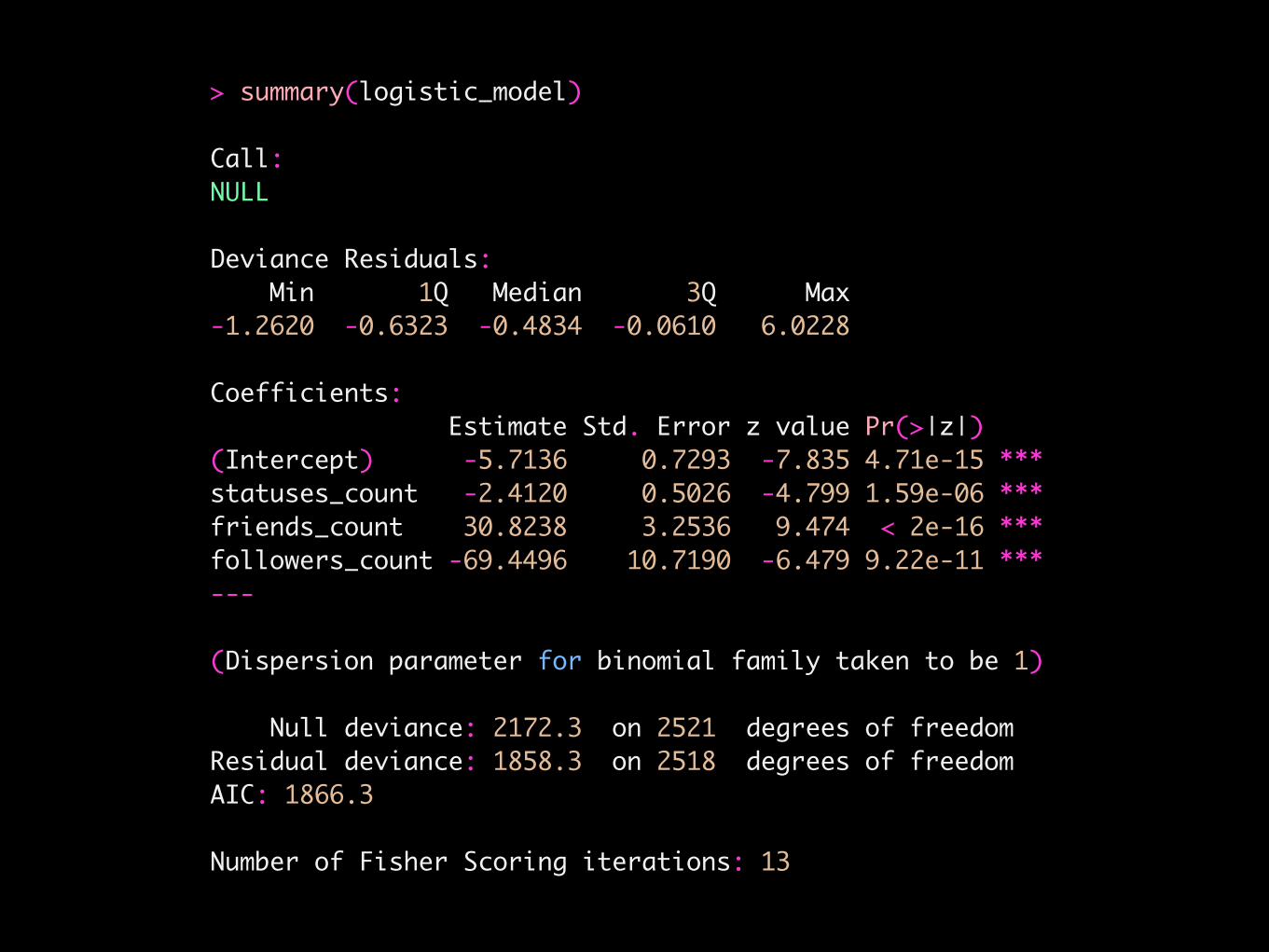
> summary(logistic_model)
Call:NULL
Deviance Residuals: Min 1Q Median 3Q Max -1.2620 -0.6323 -0.4834 -0.0610 6.0228
Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) -5.7136 0.7293 -7.835 4.71e-15 ***statuses_count -2.4120 0.5026 -4.799 1.59e-06 ***friends_count 30.8238 3.2536 9.474 < 2e-16 ***followers_count -69.4496 10.7190 -6.479 9.22e-11 ***---
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 2172.3 on 2521 degrees of freedomResidual deviance: 1858.3 on 2518 degrees of freedomAIC: 1866.3
Number of Fisher Scoring iterations: 13
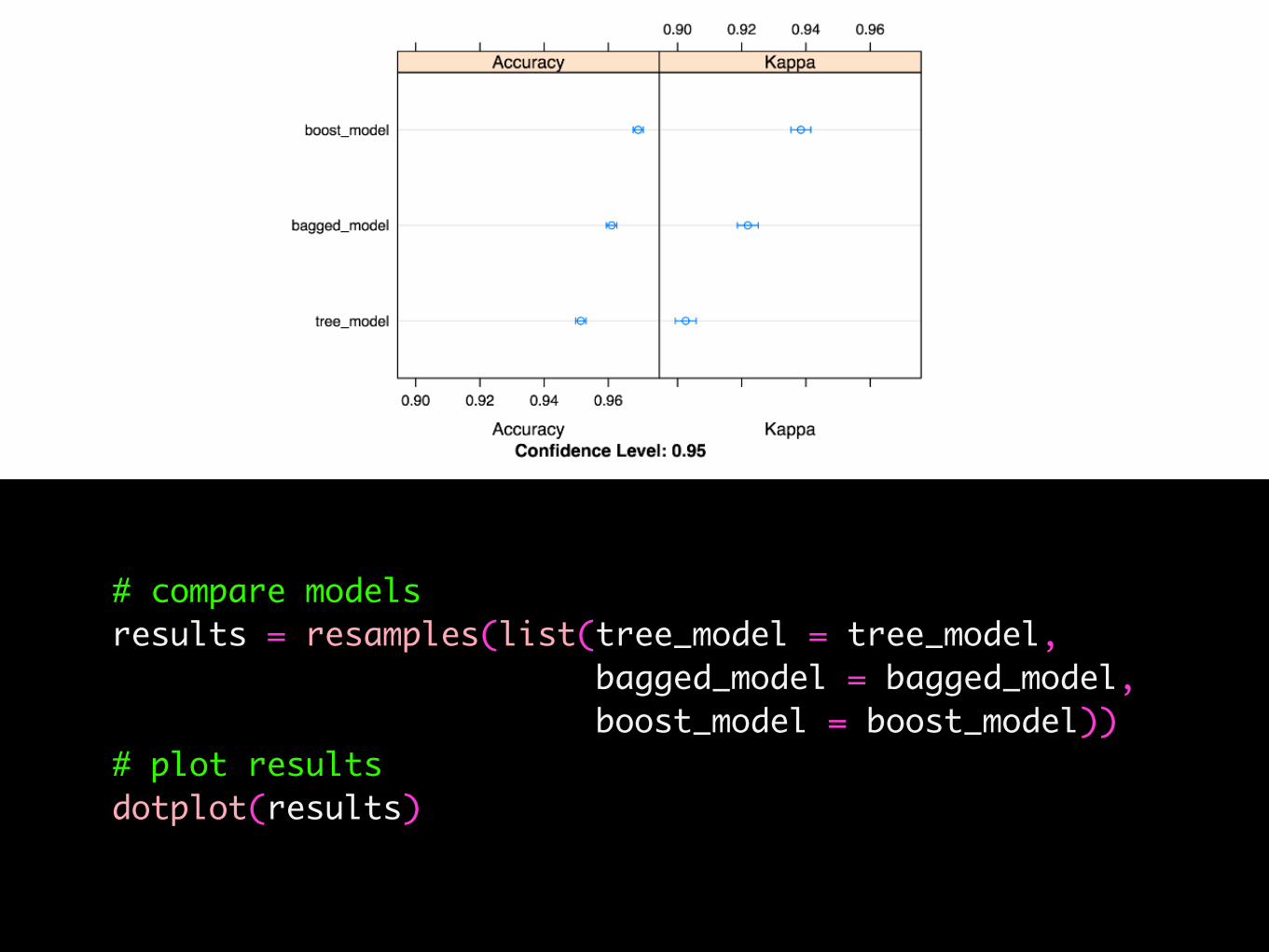
# compare modelsresults = resamples(list(tree_model = tree_model, bagged_model = bagged_model, boost_model = boost_model))# plot resultsdotplot(results)

Step 5: Pontificate.

Python rules!
• The Python language is an incredibly powerful tool for end-to-end data analysis.
• Even so, some tasks are more work than they should be.
Lame bots

And now…

the bots.






Clicks• Twitter Is Plagued With 23 Million Automated Accounts: http://valleywag.gawker.com/twitter-is-riddled-with-23-million-
bots-1620466086
• HOW TWITTER BOTS FOOL YOU INTO THINKING THEY ARE REAL PEOPLE: http://www.fastcompany.com/3031500/how-twitter-bots-fool-you-into-thinking-they-are-real-people
• Rise of the Twitter bots: Social network admits 23 MILLION of its users tweet automatically without human input: http://www.dailymail.co.uk/sciencetech/article-2722677/Rise-Twitter-bots-Social-network-admits-23-MILLION-users-tweet-automatically-without-human-input.html
• Twitter Zombies: 24% of Tweets Created by Bots: http://mashable.com/2009/08/06/twitter-bots/
• How bots are taking over the world: http://www.theguardian.com/commentisfree/2012/mar/30/how-bots-are-taking-over-the-world
• That Time 2 Bots Were Talking, and Bank of America Butted In: http://www.theatlantic.com/technology/archive/2014/07/that-time-2-bots-were-talking-and-bank-of-america-butted-in/374023/
• The Rise of Twitter Bots: http://www.newyorker.com/tech/elements/the-rise-of-twitter-bots
• OLIVIA TATERS, ROBOT TEENAGER: http://www.onthemedia.org/story/29-olivia-taters-robot-teenager/





























