Embed Size (px)
Citation preview

CAT @ ScaleDeploying cache isolation in a mixed-workload environment
Rohit Jnagal jnagal@googleDavid Lo davidlo@google

David
Rohit
Borg : Google cluster manager
● Admits, schedules, starts, restarts, and monitors the full range of applications that Google runs.
● Mixed workload system - two tiered: latency sensitive ( front-end tasks): latency tolerant (batch tasks)
● Uses containers/cgroups to isolate applications.

Borg: Efficiency with multiple tiers
Large Scale Cluster Management at Google with Borg

Isolation in Borg

Borg: CPU isolation for latency-sensitive (LS) tasks
● Linux Completely Fair Scheduling (CFS) is a throughput-oriented scheduler; no support for differentiated latency
● Google-specific extensions for low-latency scheduling response● Enforce strict priority for LS tasks over batch workloads
○ LS tasks always preempt batch tasks○ Batch never preempts latency-sensitive on wakeup○ Bounded execution time for batch tasks
● Batch tasks treated as minimum weight entities○ Further tuning to ensure aggressive distribution of batch tasks over available cores

Borg : NUMA Locality
Good NUMA locality can have a significant performance impact (10-20%)*
Borg isolates LS tasks to a single socket, when possible
Batch tasks are allowed to run on all sockets for better throughput
* The NUMA experience

Borg : Enforcing locality for performance
Borg isolates LS tasks to a single socket, when possible
Batch tasks are allowed to run on all sockets for better throughput
LS1
LS2
LS3
Batch
Affinity masks for tasks on a machine
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
Socket 0 Socket 1
8 9 10 11 12 13 14 15

Borg : Dealing with LS-LS interferenceUse reserved CPU sets to limit interference for highly sensitive jobs
○ Better wakeup latencies○ Still allows batch workloads as they have minimum weight and always yield
Socket 0
Affinity masks for tasks on a machine
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
Socket 1
LS1
LS2 (reserved)
LS3
Batch
8 9 10 11 12 13 14 15LS4

Borg : Micro-architectural interference
● Use exclusive CPU sets to limit microarchitectural interference○ Disallow batch tasks from running on cores of an LS task
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
8 9 10 11 12 13 14 150 1 2 3 4 5 6 7
Socket 0 Socket 1
LS1
LS2 (reserved)
LS3 (exclusive)
LS4
Batch
Affinity masks for tasks on a machine
8 9 10 11 12 13 14 15

Borg : Isolation for highly sensitive tasks
● CFS offers low scheduling latency● NUMA locality provides local memory and cache● Reserved cores keep LS tasks with comparable weights from
interfering● Exclusive cores keep cache-heavy batch tasks away from L1, L2
caches
This should be as good as running on a non-shared infrastructure!
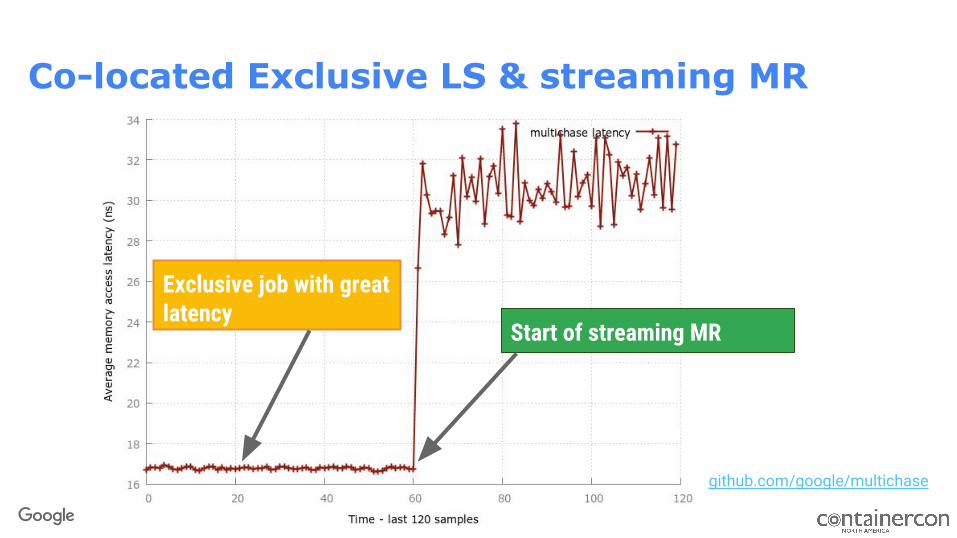
Co-located Exclusive LS & streaming MR
Start of streaming MR
github.com/google/multichase
Exclusive job with great latency

Performance for latency sensitive tasks
At lower utilization, latency sensitive tasks need more cache protection.
Interference can degrade performance up to 300% even when all other resources are well isolated.
Mo Cores, Mo Problems
*Heracles

CAT

Resource Director Technology (RDT)
● Monitoring:○ Cache Monitoring Technology (CMT)○ Memory Bandwidth Monitoring (MBM)
● Allocation:○ Cache Allocation Technology (CAT)
■ L2 and L3 Caches○ Code and Data Prioritization (CDP)
Actively allocate resources to achieve better QoS and performance
Allows general grouping to enable monitoring/allocation for VMs, containers, and arbitrary threads and processes
Introduction to CAT

Cache Allocation Technology (CAT)
● Provides software control to isolate last-level cache access between applications.
● CLOS: Class of service corresponding to a cache allocation setting
● CBM: Cache Capacity Bitmasks to map a CLOS id to an allocation mask
Introduction to CAT

Setting up CAT
Introduction to CAT

Let’s add CAT to our service ...

Add CAT to the mix
Start of streaming MR
Restricting MR cache use to 50%

CAT Deployment: Batch Jails
Data for batch jobs Data for latency sensitive jobs
Batch jail(shared between all tasks, including LS)
Dedicated for latency sensitive(only LS can use)

CAT Deployment: Cache cgroup
Cache
T1 T2
CPU
T1 T2
Memory
T1 T2
Cgroup Root
● Every app gets its own cgroup
● Set CBM for all batch tasks to same mask
● Easy to inspect, recover
● Easy to integrate into existing container mechanisms
○ Docker○ Kubernetes

CAT experiments with YouTube transcoder

CAT experiments with YouTube
CPI as a good measure for cache interference
lower is better
Ant
agon
ist c
ache
occ
upan
cy (%
of L
3)
CP
I
0%
25%
50%
75%
100%

Production rollout

Impact of batch jails
Higher gains for smaller jail
+0%
lower is better
LS tasks avg CPI comparison

LS tasks CPI percentile comparisonComparison of LS tasks CPI PDF
Batch jails deployment
Batch jailing shifts CPI lower
Higher benefits of CAT for tail tasks
+0%

Batch jails deployment
Smaller jails lead to higher impact on batch jobs
lower is better
Batch tasks avg CPI comparison
+0%

The Downside: Increased memory pressure
BW spike!
BW hungry Batch job starts
BW hungry Batch job stops
Jailing LLC increases DRAM BW pressure for Batch
System Memory BW

Controlling memory bandwidth impact
Intel RDT: CMT (Cache Monitoring Technology) - Monitor and profile cache usage pattern for all applications
Intel RDT: MBM (Memory Bandwidth Monitoring)- Monitor memory bandwidth usage per application
Controls:- CPU throttling- Scheduling- Newer platforms will provide control for memory bandwidth per
application

Controlling infrastructure processes
Many system daemons tend to periodically thrash caches
- None of them are latency sensitive- Stable behavior, easy to identify
Jailing for daemons!
- Requires ability to restrict kernel threads to a mask

What about the noisy neighbors?
Noisy neighbors hurting performance (Intel RDT)
● Use CMT to detect; CAT to control
● Integrated into CPI2 signals○ CPI2 built for noisy neighbor
detection○ Dynamically throttle noisy tasks○ Possibly tag for scheduling hints
Observer
Master
Nodes
CPISamples
CPISpec

CMT issues with cgroups
● Usage model: many many cgroups, but can’t run perf on all of them all the time
○ Run perf periodically on a sample of cgroups○ Use same RMID for a bunch of cgroups○ Rotate cgroups out every sampling period
● HW counts cache allocations - deallocations, not occupancy:○ Cache lines allocated before perf runs are not accounted○ Can get non-sensical results, even zero cache occupancy○ Work-around requires to run perf for life-time of monitored cgroup○ Unacceptable context switch overhead
● David Carrillo-Cisneros & Stephane Eranian working on a newer version for CMT support with perf

CAT implementation

Cache Cgroup
Cache
T1 T2
CPU
T1 T2
Memory
T1 T2
Cgroup Root
● Every app gets its own cgroup● Set CBM for all batch tasks to
same mask● Easy to inspect, recover● Easy to integrate into existing
container mechanisms○ Docker○ Kubernetes
● Issues with the patch:○ Per-socket masks○ Not a good fit?○ Thread-based isolation
vs cgroup v2

New patch: rscctrl interface
● Patches by Intel from Fenghua Yu○ Mounted under /sys/fs/rscctrl○ Currently used for L2 and L3 cache masks○ Create new grouping with mkdir /sys/fs/rscctrl/LS1○ Files under /sys/fs/rscctrl/LS1:
■ tasks: threads in the group■ cpus: cpus to control with the setting in this group■ schemas: write L2 and L3 CBMs to this file
● Aligns better with the h/w capabilities provided● Gives finer control without worrying about cgroup restrictions● Gives control over kernel threads as well as user threads● Allows resource allocation policies to be tied to certain cpus across all
contexts

Current Kernel patch progress
David Carrillo-Cisneros, Fenghua Yu, Vikas Shivappa, and others at Intel working on improving CMT and MBM support for cgroups
Changes to support cgroup monitoring as opposed to attach to process forever model
Challenges that are being faced:
● Sampled collections● Not enough RMIDs to go around
○ Use per-package allocation of RMIDs○ Reserved RMIDs (do not rotate)

Takeaways
● With larger machines, isolation between workloads is more important than ever.
● RDT extensions work really great at scale:○ Easy to set up static policies.○ Lot of flexibility.
● CAT is only one of the first isolation/monitoring features.
○ Avoid ad-hoc solutions ● At Google, we cgroups and containers:
○ Rolled out cgroup based CAT support to the fleet.● Let’s get the right abstractions in place.
If you are interested,
talk to us here or find us online:
jnagal
davidlo
davidcc
eranian
Thanks!

● Friday 8am - 1pm @ Google's Toronto office● Hear real life experiences of two companies using GKE● Share war stories with your peers● Learn about future plans for microservice management
from Google● Help shape our roadmap
g.co/microservicesroundtable† Must be able to sign digital NDA
Join our Microservices Customer Roundtable





























