Embed Size (px)
Citation preview

CKylinCloud
Optimizations on Ceph Cache TieringCache Tiering
Li WangKylinCloud Team

Contents
01 社区介绍
Ceph社区参与02
2
社区介绍社区介绍
KylinCloudy

简介
基于O S 研发• 基于OpenStack研发
• 为用户提供IaaS、PaaS层次的云服务解决方案,可构建公有云和私有云服务公有云和私有云服务
• 提供虚拟化管理、项目管理、系统资源管理、资源状态监控 告警管理 计费管理 用户管理等功能控、告警管理、计费管理、用户管理等功能
K li Cl dKylinCloudBased on OpenStack
社区贡献
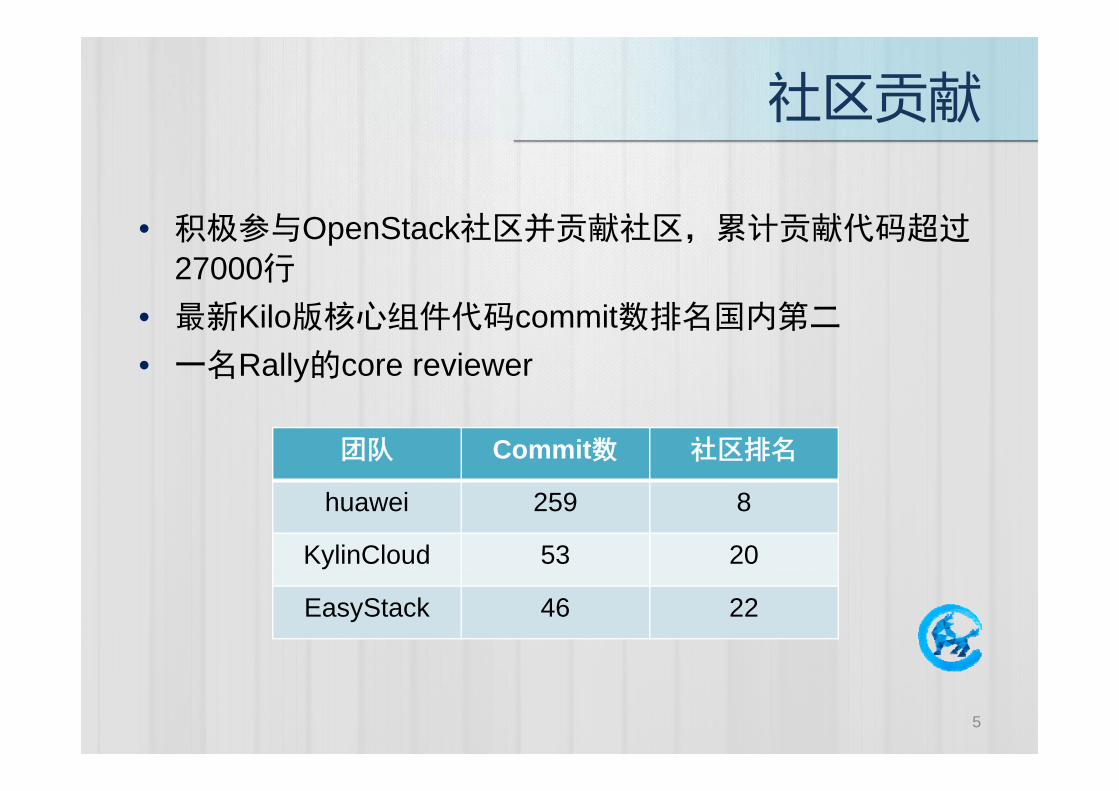
积极参与O S 社区并贡献社区 累计贡献代码超过• 积极参与OpenStack社区并贡献社区,累计贡献代码超过27000行最新Kil 版核心组件代码 it数排名国内第• 最新Kilo版核心组件代码commit数排名国内第二
• 一名Rally的core reviewer
团队 Commit数 社区排名
huawei 259 8
KylinCloud 53 20
EasyStack 46 22
5
社区贡献
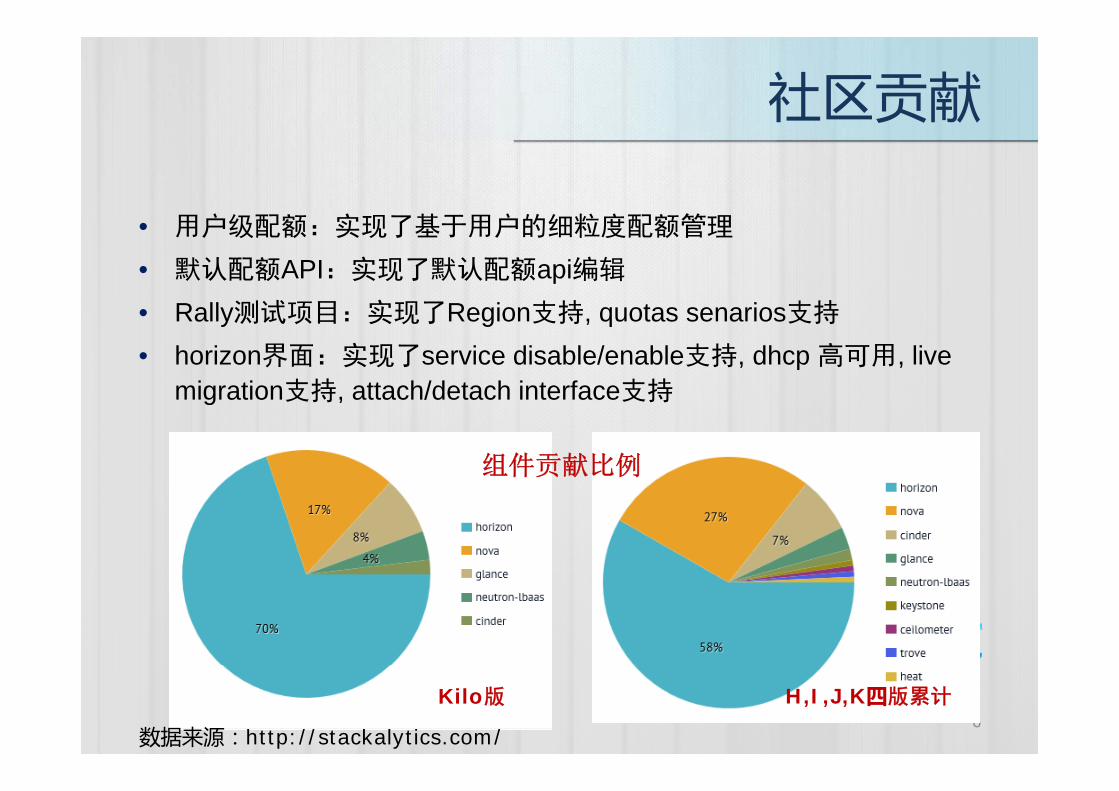
用户级配额 实现了基于用户的细粒度配额管理• 用户级配额:实现了基于用户的细粒度配额管理
• 默认配额API:实现了默认配额api编辑
R ll 测试项目 实现了R i 支持 t i 支持• Rally测试项目:实现了Region支持, quotas senarios支持
• horizon界面:实现了service disable/enable支持, dhcp 高可用, live migration支持 attach/detach interface支持migration支持, attach/detach interface支持
组件贡献比例
6数据来源:http://stackalytics.com/
Kilo版 H,I,J,K四版累计

应用平台• 天河二号超算平台
国家十二五863重大科技项目 广州科技 号工程– 国家十二五863重大科技项目,广州科技一号工程
– 峰值计算性能10亿亿次以上,连续四次位居国际Top500榜首
• 广州超算中心 目前系统20000个节点• 广州超算中心,目前系统20000个节点
– 双路12核E5-2692,64GB内存
定制的内部高速互联(224Gbps)– 定制的内部高速互联(224Gbps)– 总存储容量12.4PB

KylinCloud部署情况y
部署• 部署
– 当前部署约2000个节点
– 基于TH-NI高速网(224Gbps)– 基于Ceph构建分布式存储
• 性能
– 支持单节点同时运行10个以上虚拟机支持单节点同时运行10个以上虚拟机
– APIServer可每秒响应1100以上的虚拟机列表显示请求

应用情况
电子政务类应用• 电子政务类应用
– 广东省省级教育数据中心
– 广州市萝岗区电子政务
• 渲染类应用
– 华强文化科技集团
– 凡拓数码科技
广州市政府网站群 广州电子政务中心数据交换平台
凡拓数码科技
– 创意云
社区介绍社区介绍
UbuntuKyliny
10

简介
• 基于Ubuntu的开源操作系统 得到Ubuntu的官方认可和• 基于Ubuntu的开源操作系统,得到Ubuntu的官方认可和支持
• 目标是创建更适合中文用户的Linux发行版目标是创建更适合中文用户的Linux发行版
• 项目创建以来 已发布5个正式版本 最新版本• 项目创建以来,已发布5个正式版本,最新版本15.04(Vivid)– 官网下载点击量超过900万官网下载点击量超过900万– 15.04发布1周下载量超过25万
系统特性
系统中文支持增强• 系统中文支持增强
• 软件商店
• 优客系列系统工具:优客助手、优客天气、优客农历、优客企鹅、优客搜索
合作开发商业软件 迅雷快盘 金山WPS• 合作开发商业软件:迅雷快盘、金山WPS
社区建设
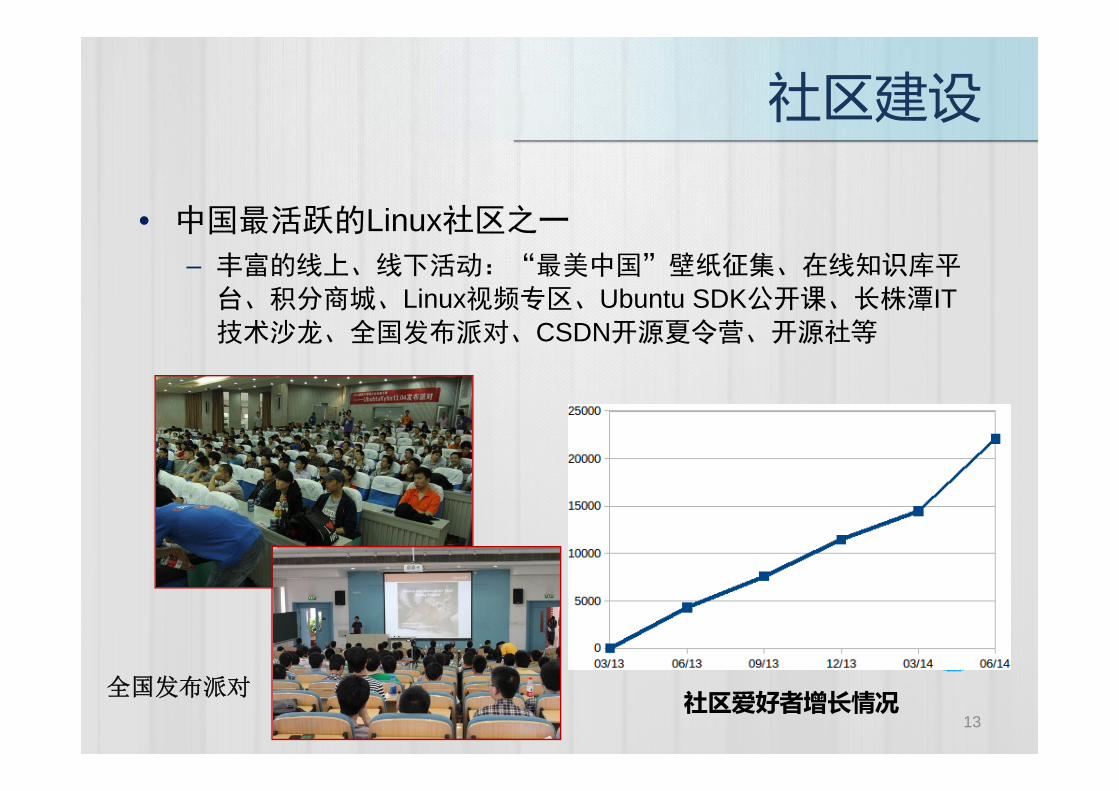
• 中国最活跃的Linux社区之• 中国最活跃的Linux社区之一
– 丰富的线上、线下活动:“最美中国”壁纸征集、在线知识库平台、积分商城、Linux视频专区、Ubuntu SDK公开课、长株潭IT台、积分商城、Linux视频专区、Ubuntu SDK公开课、长株潭IT技术沙龙、全国发布派对、CSDN开源夏令营、开源社等
13
全国发布派对 社区爱好者增长情况

应用情况
• 商务部援外系统• 商务部援外系统
– 商务部援外计算机唯一指定的预装操作系统
成功援助70多个国家和地区 累积60000余套– 成功援助70多个国家和地区,累积60000余套
• 国务院中央政府采购中心
用于政府采购的评标 招标业务– 用于政府采购的评标、招标业务
• 国家发改委
主要用于上网办公 目前完成试用和测试– 主要用于上网办公,目前完成试用和测试
• 与HP等品牌合作进行OEM预装
Ceph社区参与Ceph社区参与
社区参与社区参与
15

社区参与
• Ceph Develop Summit• Ceph Develop Summit– 讨论Ceph开发的核心会议
从第一届开始 每届CDS大会均参加– 从第一届开始,每届CDS大会均参加
– 每届至少提交2个以上的Blueprints– 每届均参与并主持Session讨论每届均参与并主持Session讨论
• 会议交流
– 参加北京第二届开源操作系统大会,并做《Ceph分布式对象存储系参加北京第二届开源操作系统大会,并做《Ceph分布式对象存储系统研究与优化》报告
– 参加China Linux Storage and File System 大会,并进行交流
16

Ceph社区参与Ceph社区参与
Merged FeaturesMerged Features

Merged�Featuresg
C hFS• CephFS– Inline data support
• 小文件的访问性能优化
• 优化后性能提升2倍
– quota support• 为CephFS实现了基于目录占用空间大小的,以及基于文件数量p的quota支持
– Punch hole support• 用于在虚拟机删除文件时回收主机存储空间
18

Merged�Featuresg
RBD• RBD– Rbd diff mergeRbd diff merge
• 将多个diff文件合并为单个diff文件,节省存储空间, 简化恢复过程简化恢复过程
– Copy on Read for RBD Clones• RBD Clone镜像访问性能优化
– Rbd offline recovery tooly• 离线恢复rbd image的工具

Ceph社区参与Ceph社区参与
Cache TieringCache Tiering
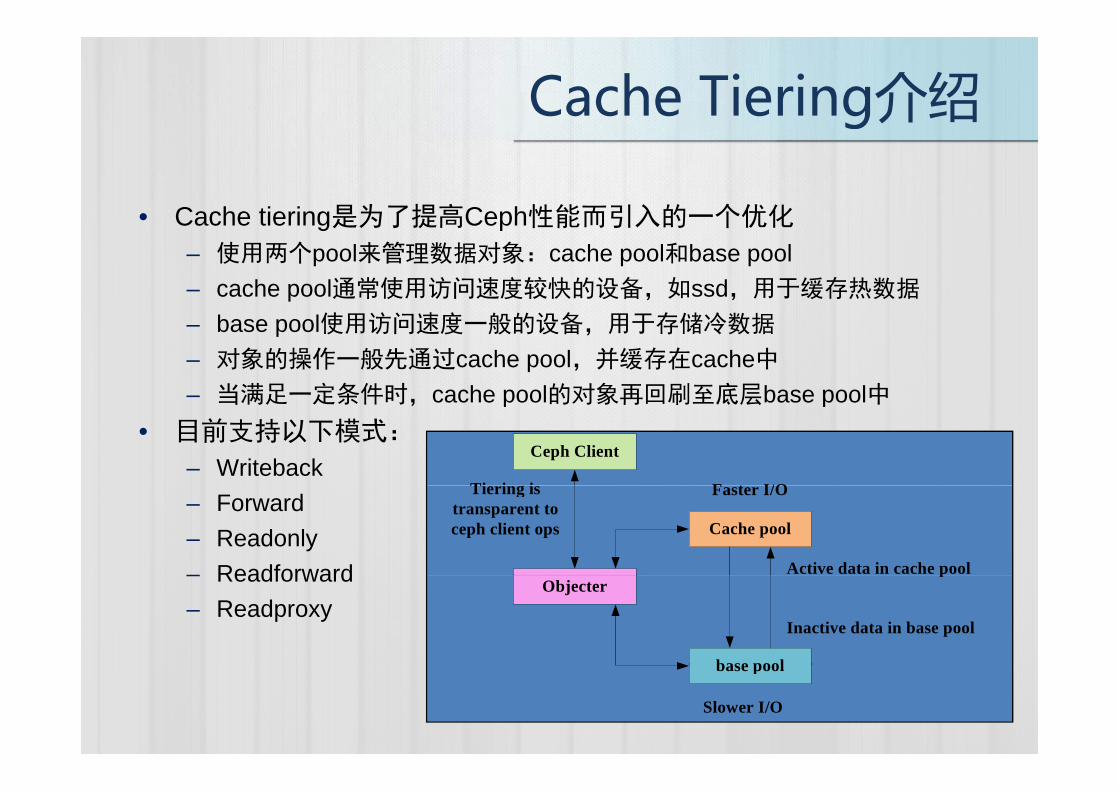
Cache�Tiering介绍g
• Cache tiering是为了提高Ceph性能而引入的一个优化• Cache tiering是为了提高Ceph性能而引入的一个优化
– 使用两个pool来管理数据对象:cache pool和base pool– cache pool通常使用访问速度较快的设备,如ssd,用于缓存热数据
– base pool使用访问速度一般的设备,用于存储冷数据
– 对象的操作一般先通过cache pool,并缓存在cache中– 当满足一定条件时 cache pool的对象再回刷至底层base pool中– 当满足 定条件时,cache pool的对象再回刷至底层base pool中
• 目前支持以下模式:
– WritebackCeph Client
F t I/OTi i i– Forward– Readonly– Readforward
Cache pool
Active data in cache pool
Faster I/OTiering is transparent to ceph client ops
– Readforward– Readproxy
Objecter
base pool
p
Inactive data in base pool
base pool
Slower I/O

Cache�Tiering优化g
T t b d h t• Temperature based cache management• IO hint for cache managementg• Write back throttling
M d l j l d• Metadata-only journal mode

Cache TieringCache Tiering
Temperature based cacheTemperature based cache management

动机与思路
动机• 动机
– 当前cache pool的淘汰算法是基于最近的访问时间,而没有考虑对象历史的访问频率
– 该算法倾向于将最近访问的对象保留在cache pool中,可能会将频繁访问但最近未访问的对象淘汰
• 思路
– 实现一种基于温度的对象淘汰算法,在原算法框架的基础上,同时根据对象的访问时间和访问频率来确定被淘汰的对象

动机与思路
假设对象访问序列如下• 假设对象访问序列如下:
0 1200 2400 3600 4800 对象A 为频繁访问对象
对象C 为临时一次性访问对象
对象B 为频繁访问对象
AAA BBB C
• 按照最近访问时间的淘汰算法:将会淘汰对象A,
AAA BBB C
而A为频繁访问对象,只是在最近一段时间没有被访问到
25

算法设计
• 算法设计– 定义Temperature = sum(f(atime))定义Temperature sum(f(atime))
– atime表示访问的时间,不同的访问时间对应不同的权重,访问时
间越近的权重越大间越近的权重越大
– f表示atime到权重的映射关系,把它定义为一个分段函数,允许用
户设定一个权重衰减率户设定 个权重衰减率
– 当缓存池被占满时,根据每个对象的访问时间和访问频率计算出
一个总的权重和个总的权重和
– 淘汰权重最小的缓存对象

算法设计
允许用户自定义权重表中的权重衰减率 算法中• 允许用户自定义权重表中的权重衰减率,算法中默认为20%
• 允许用户自定义hitset的数量,算法中默认为4• 允许用户自定义每个hitset区间的时间段,算法中允许用户自定义每个 区间的时间段,算法中为1200s

效果
避免某些临时性访问的对象污染 h• 避免某些临时性访问的对象污染cache• 同时考虑到访问时间与访问频率的分布,对于冷热数据的衡量更加准确
28
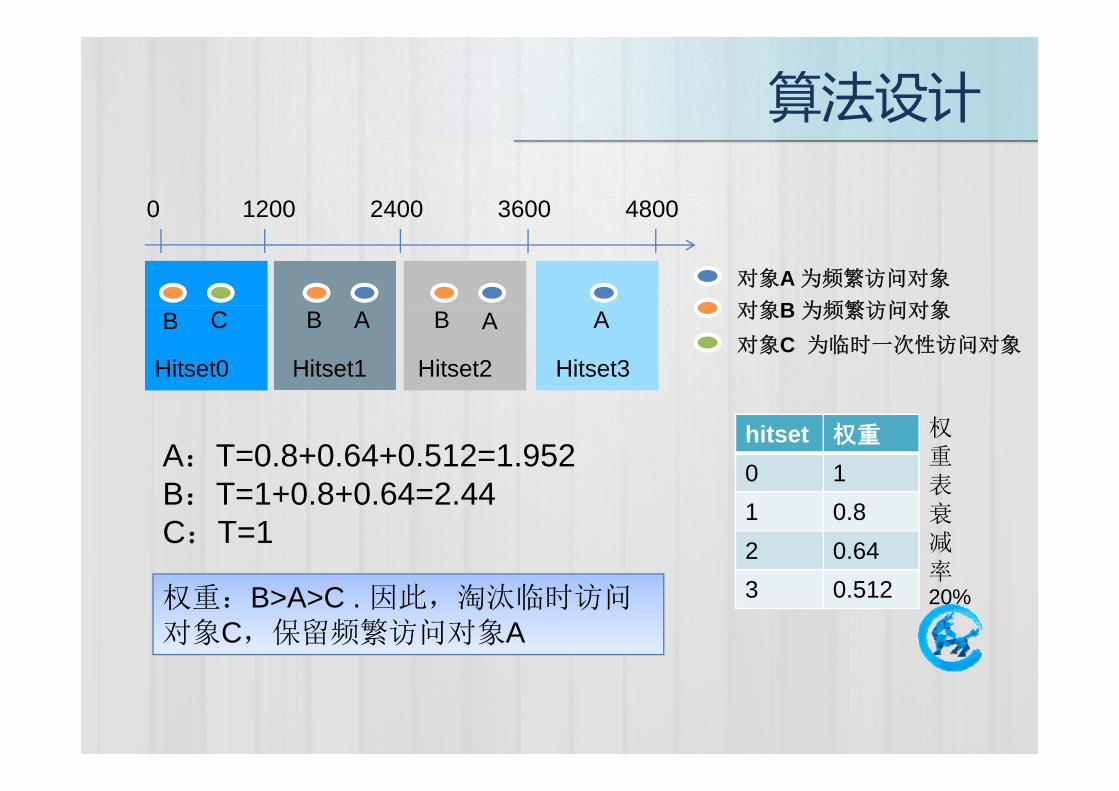
算法设计
0 1200 2400 3600 4800
对象A 为频繁访问对象
对象B 为频繁访问对象
0 1200 2400 3600 4800
Hitset0 Hitset1 Hitset2 Hitset3对象C 为临时一次性访问对象
对象B 为频繁访问对象AAA BBB C
hitset 权重
0 1A:T=0.8+0.64+0.512=1.952B T 1 0 8 0 64 2 44
权重表
1 0.82 0.64
B:T=1+0.8+0.64=2.44C:T=1
表衰减率
3 0.512权重:B>A>C . 因此,淘汰临时访问对象C,保留频繁访问对象A
率20%

Cache TieringCache Tiering
IO hint for cache managementIO hint for cache management

动机与思路
动机• 动机– 在writeback模式中,所有的读写操作都是先经过cache
pool再到base poolpool再到base pool– 如操作序列:写A->写B->读A,如果B在后续中不会被访
问到,那么B的写入会使得A被迫淘汰出缓存,导致cache问到,那么B的写入会使得A被迫淘汰出缓存,导致cache污染,再读A时,将无法命中缓存
• 思路思路– 客户端发起对象读写操作时,通过IO hint,显式的提示该
对象的读写操作直接在base pool中进行,不缓存在cache pool中
– 以op为粒度设置cache mode而非pool粒度

应用场景
适用于对象的 次读/写 后期较少访问的• 适用于对象的一次读/写,后期较少访问的场景:
– rbd image export:rbd image备份
– rbd image import:rbd image恢复– rbd image import:rbd image恢复
32
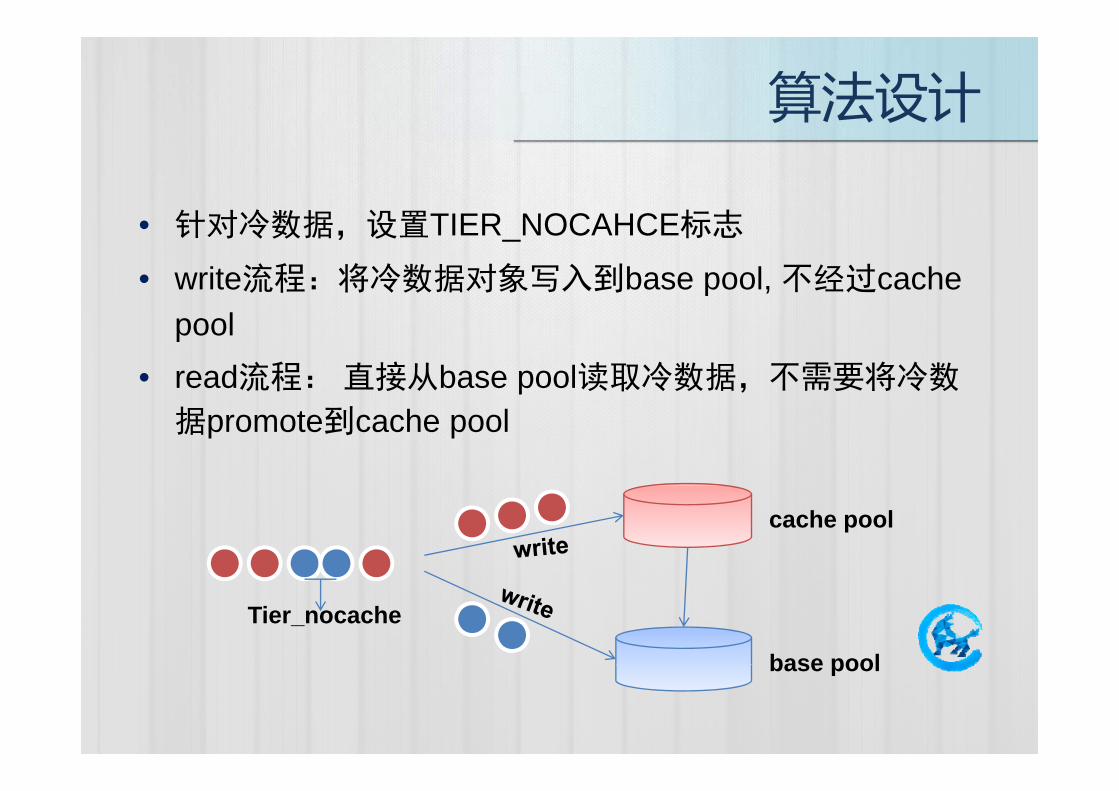
算法设计
针对冷数据 设置TIER NOCAHCE标志• 针对冷数据,设置TIER_NOCAHCE标志
• write流程:将冷数据对象写入到base pool, 不经过cache pool
• read流程: 直接从base pool读取冷数据,不需要将冷数
据promote到cache pool
cache pool
Tier_nocache
base poolbase pool

Cache TieringCache Tiering
Write back throttlingWrite back throttling

动机与思路
动机• 动机
– 当前cache flush机制是当pg中脏数据达到了设定的阈值以后 立即将该 中所有脏数据回刷后,立即将该pg中所有脏数据回刷
– 对于突发性IO,大量回刷会对性能造成影响
• 思路– 设定高、低两个阈值,在低阈值时限速回刷,当达到高阈设定高、低两个阈值,在低阈值时限速回刷,当达到高阈
值再高速回刷
– 通过限制回刷并发数的方式限制回刷的速度通过限制 刷并发数的方式限制 刷的速度
– 低速回刷时的最大并行数是高速回刷时的一半

算法设计
设定cache target dirty high ratio(默认0 6)为• 设定cache_target_dirty_high_ratio(默认0.6)为高速回刷的阈值
设定 h t t di t ti (默认0 4)为低速• 设定cache_target_dirty_ratio(默认0.4)为低速回刷的阈值
脏数据比例 0 4 空闲模式 不回刷数据• 脏数据比例<0.4,空闲模式,不回刷数据
• 0.4<脏数据比例<0.6,低速回刷
• 脏数据比例>0.6,高速回刷

效果
允许自定义高低阈值• 允许自定义高低阈值
• 允许设定回刷的并行数
• 通过设定高低阈值,能够利用两段突发性IO的间隔时间将cache回刷至低阈值以下,为下次突发时间将 刷 低阈值以 ,为 次突发性IO留出更多的cache空间
37

Cache TieringCache Tiering
Metadata only journal modeMetadata-only journal mode

动机与思路
动机• 动机
– 当前OSD的filestore实现的写逻辑是先写到journal,再写到磁盘写到磁盘
– 数据的双份写造成写性能较低
思路• 思路
– 实现一个新的journal模式,即metadata-only journal d 类似于 t4中的d t d d 模式mode,类似于ext4中的data=ordered 模式
– 在这种模式下,对象数据直接写入到磁盘,然后元数据写入到journal 最后写操作返回据写入到journal,最后写操作返回
39

应用场景
适用于有机制来保证数据 致性的场景 如• 适用于有机制来保证数据一致性的场景,如:
– rbd作为虚拟机的存储设备,在其上创建文件系统,充当磁盘使用
• 磁盘控制器不提供事务机制来保证写操作的原子性磁盘控制器不提供事务机制来保证写操作的原子性
• 由管理磁盘的文件系统来保证一致性,如日志模式
– Cache pool已经提供了一致性保证 因此 当– Cache pool已经提供了 致性保证,因此,当脏数据回刷时,可以不通过journal
40

算法设计
为对象增加 t bl / t bl 的状态标志• 为对象增加stable/unstable的状态标志
– stable表示对象是有效的
– unstable表示对象正在进行数据修改操作

算法设计
流程• 流程– client向osd发ops(ops中设有是否启用no journal的标志)
osd处理ops 生成transaction– osd处理ops,生成transaction– filestore分析transaction,如果满足使用no journal的条件,
则将其分为直接写入object的data和需要写入journal的j jmetadata
– 将unstable标记记录到journal中将 直接 入到 中– 将data直接写入到object中
– 将metadata及stable的标记记录到journal中返回ack– 返回ack
• 如果transaction中包含某些特殊的操作,如clone,则禁用no journal 按原流程执行禁用no journal,按原流程执行
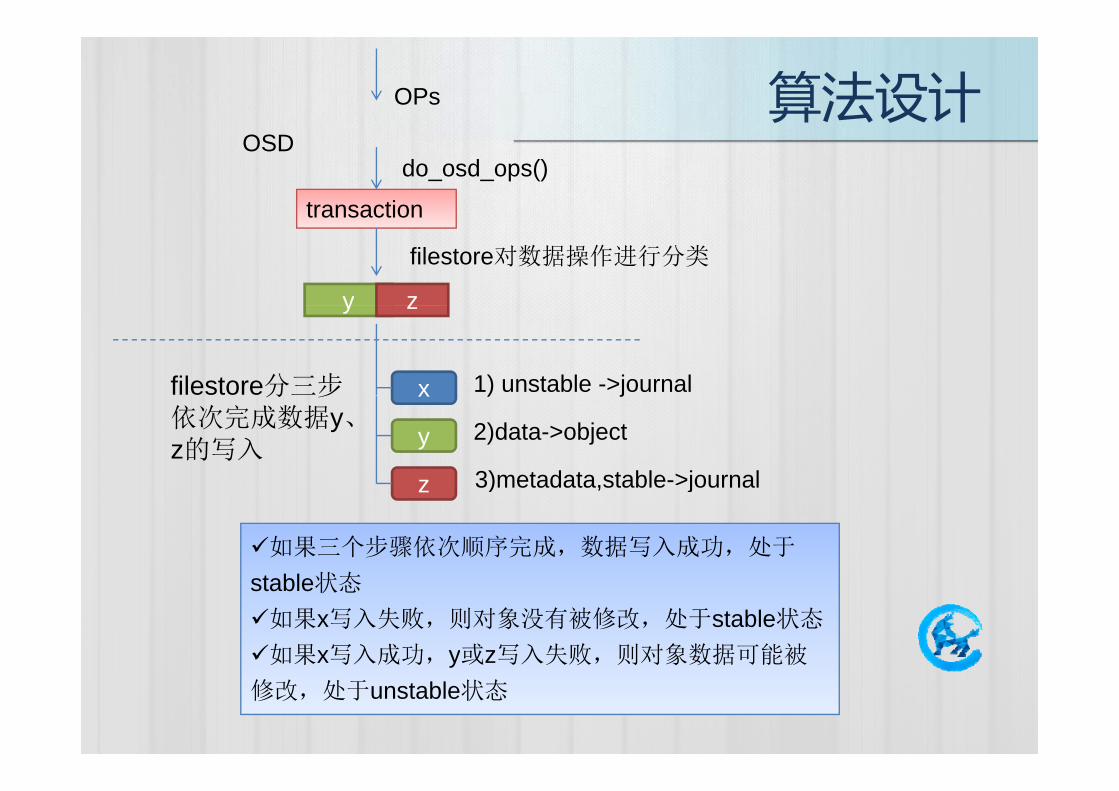
算法设计OPs
transaction
OSDdo_osd_ops()
transaction
y z
filestore对数据操作进行分类
1) unstable ->journalxfilestore分三步
y z
) j
2)data->object
3)metadata,stable->journal
x
y
z
分 步依次完成数据y、z的写入
3)metadata,stable journalz
如果三个步骤依次顺序完成,数据写入成功,处于
t bl 状态stable状态
如果x写入失败,则对象没有被修改,处于stable状态
如果x写入成功,y或z写入失败,则对象数据可能被如果 成功 y或 失败 则对象数据 能被
修改,处于unstable状态

一致性
保证元数据的 致性• 保证元数据的一致性
• CREATE和APPEND是保证一致性的
• OVERWRITE的一致性,取决于调用者
44

待讨论的问题
Recovery• Recovery–将unstable的对象各副本数据同步到一致状态 标记为 t bl状态,标记为stable

Welcome to Join UsTHANK YOUTHANK YOU