Embed Size (px)
Citation preview

Chord RecognitionAka. Chord detection, audio chord estimation
Mu-Heng Yang – RA at CITI, Academia Sinica

TODO
If no chord -> N

C C Em Em | C C Em Em
Purpose
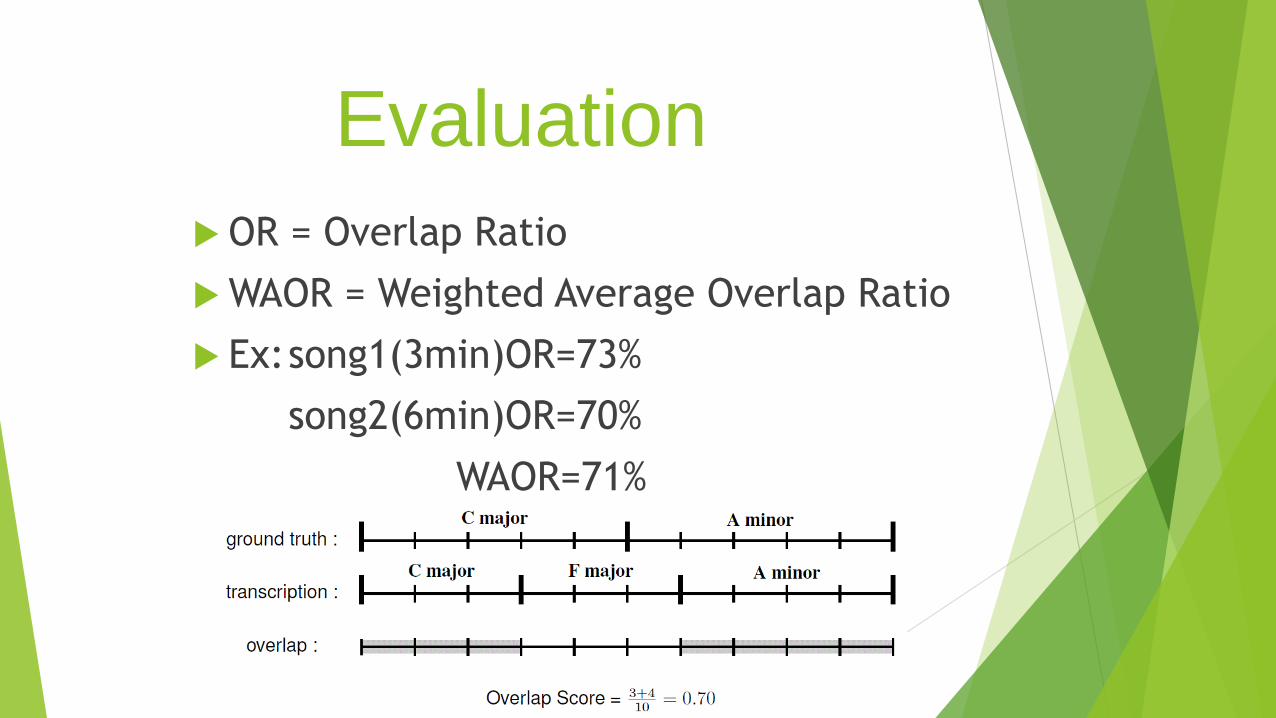
Evaluation
OR = Overlap Ratio
WAOR = Weighted Average Overlap Ratio
Ex:song1(3min)OR=73%
song2(6min)OR=70%
WAOR=71%

Evaluation
CSR = Chord Symbol Recall
WCSR = Weighted Chord Symbol Recall
Because ground truth is almost continuous
Discretize the ground truth will cause small error

Chord
<Root>:<Type>/<Inversion>
Root: C, C#, D, … , A, A#, B
Type: maj, min, 7, maj7, min7
Inversion: 3 or 5 or 7
Other: aug, dim, sus, 1, 4, 5, 6, 9, 11, 13

MIREX
Chord root note only
Major and minor
Seventh chords
Major and minor with inversions
Seventh chords with inversions

Data
hard to get audio files due to copyrights.
Remastering results in different audio files
180 songs from the Beatles dataset
100 songs from the RWC Pop dataset
18 songs from the Zweieck dataset
19 songs from the Queen dataset
198 songs from the Billboard dataset

Ambiguity
Fade out
Staccato
Many chords at the same time
Overlapped due to reverb
Different chord mapping

Basic Model
Chroma
Median filter
HMM/GMM
Viterbi

Outline
Feature Extraction
Pre-processing
Learning
Post-filtering

Outline
Feature Extraction
Pre-processing
Learning
Post-filtering

HPSS
Harmonic Percussive Sound Separation
Percussion Suppressed 50.9%→74.2%
No harmonic structure
Smooth frequency envelope
Concentrated in a short time
Demo
2010 Ueda et. al. [1]

Tuning
Standard frequency of A4 is 440 Hz.
Sometime tuning is deviated. (415~445 Hz)
One song’s WCSR increase from 14.5% to 73.9%
However, it’s very hard to get perfect tuning

Chroma
A.k.a Pitch Class Profile
Sum energies of frequencies within each bin
Use log/power function to compress energy
Sum up respective bins to get chroma vector
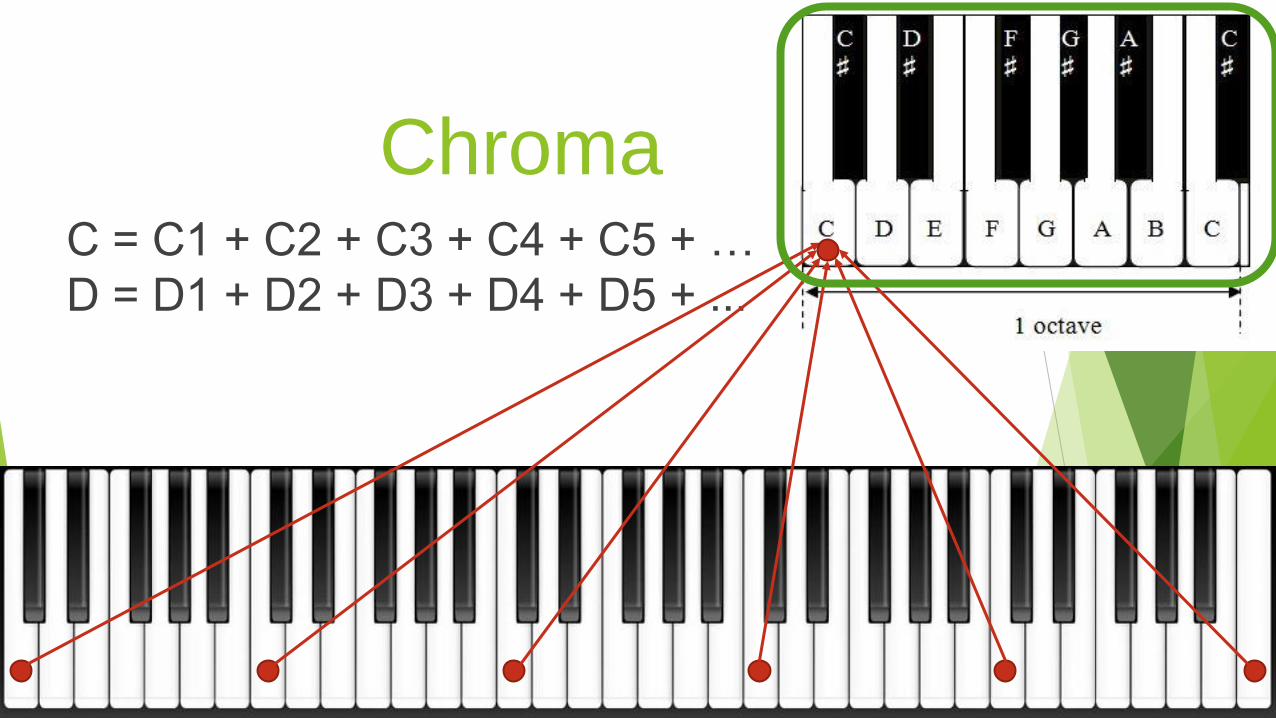
C = C1 + C2 + C3 + C4 + C5 + …
D = D1 + D2 + D3 + D4 + D5 + ...
Chroma

DNN features
DNN likes lower-level features
DNN likes lots of information
Unfold each octave
2~3 bins per semitone
Some even directly use FFT

Outline
Feature Extraction
Pre-processing
Learning
Post-filtering

Beat Synchronize
Assume there’s only one chord in a beat
Average all frames within each beat
It can smooth the noise and percussion
But most NN-based models don’t use it
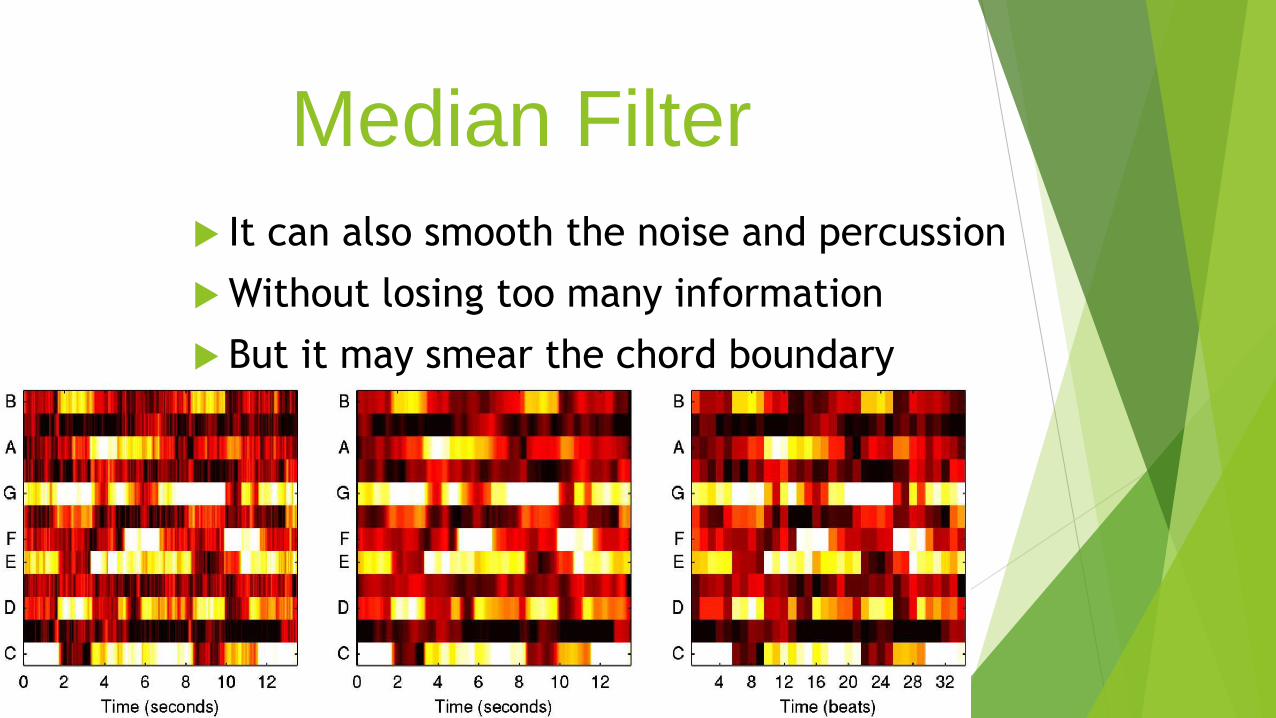
Median Filter
It can also smooth the noise and percussion
Without losing too many information
But it may smear the chord boundary

Time-Splicing
Include frames before and after the current one.
If it’s the 7th frame, then concatenate the 6th & 8th
Of course you can include more frames(3~11)
It depends on the capability of your DNN model

Spliced Filter
Inspired by CNN(convolution neural network)
Use filters to include past and future frames
Use max pooling to reduce feature dimension
WCSR increases from 75.5% to 91.9% !
2015 Xinquan Zhou et. al. [2]

Outline
Feature Extraction
Pre-processing
Learning
Post-filtering

Learning
Unsupervised Learning (pre-train)
Unlabeled Data
Supervised Learning (fine-tune)
Labeled Data
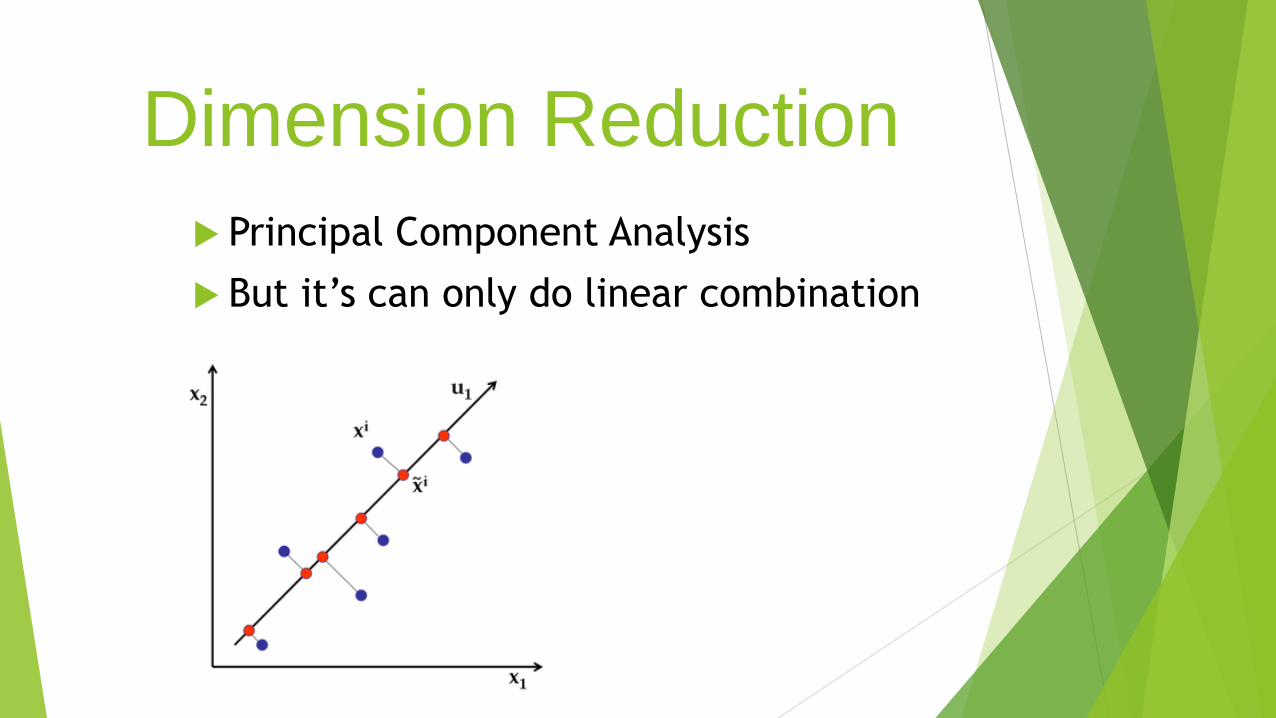
Dimension Reduction
Principal Component Analysis
But it’s can only do linear combination
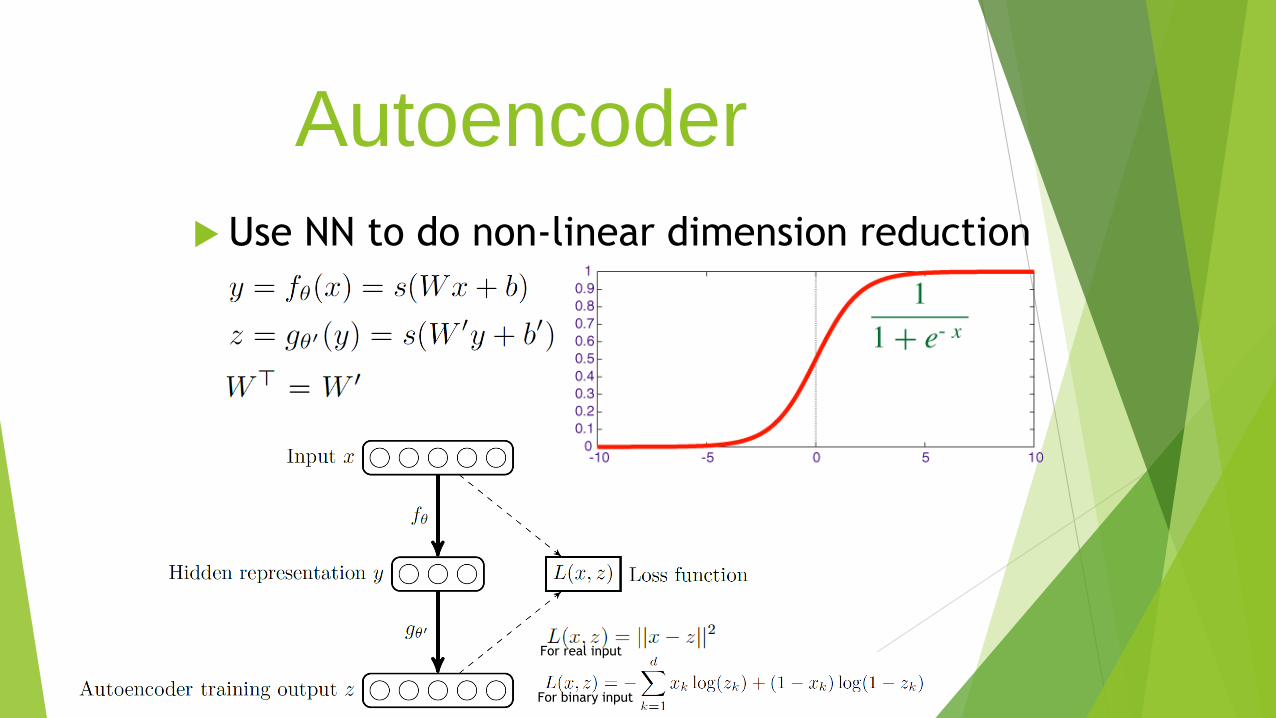
Autoencoder
Use NN to do non-linear dimension reduction
For binary input
For real input
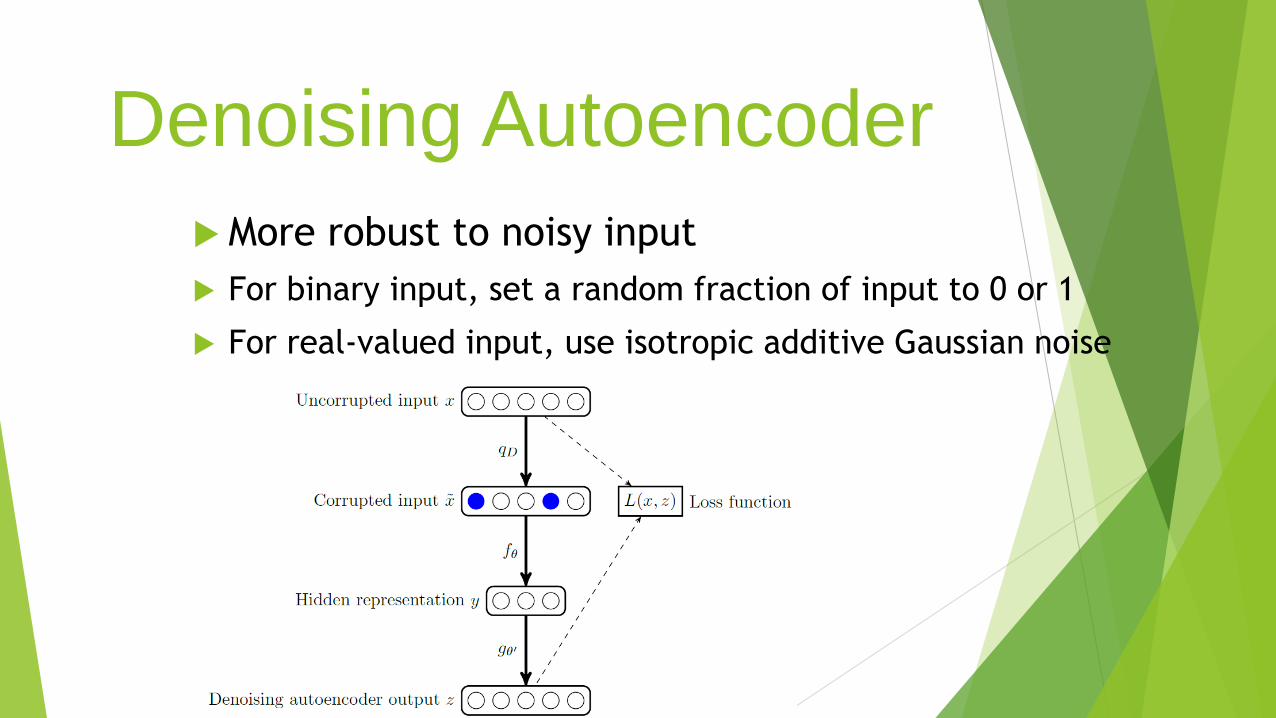
Denoising Autoencoder
More robust to noisy input
For binary input, set a random fraction of input to 0 or 1
For real-valued input, use isotropic additive Gaussian noise
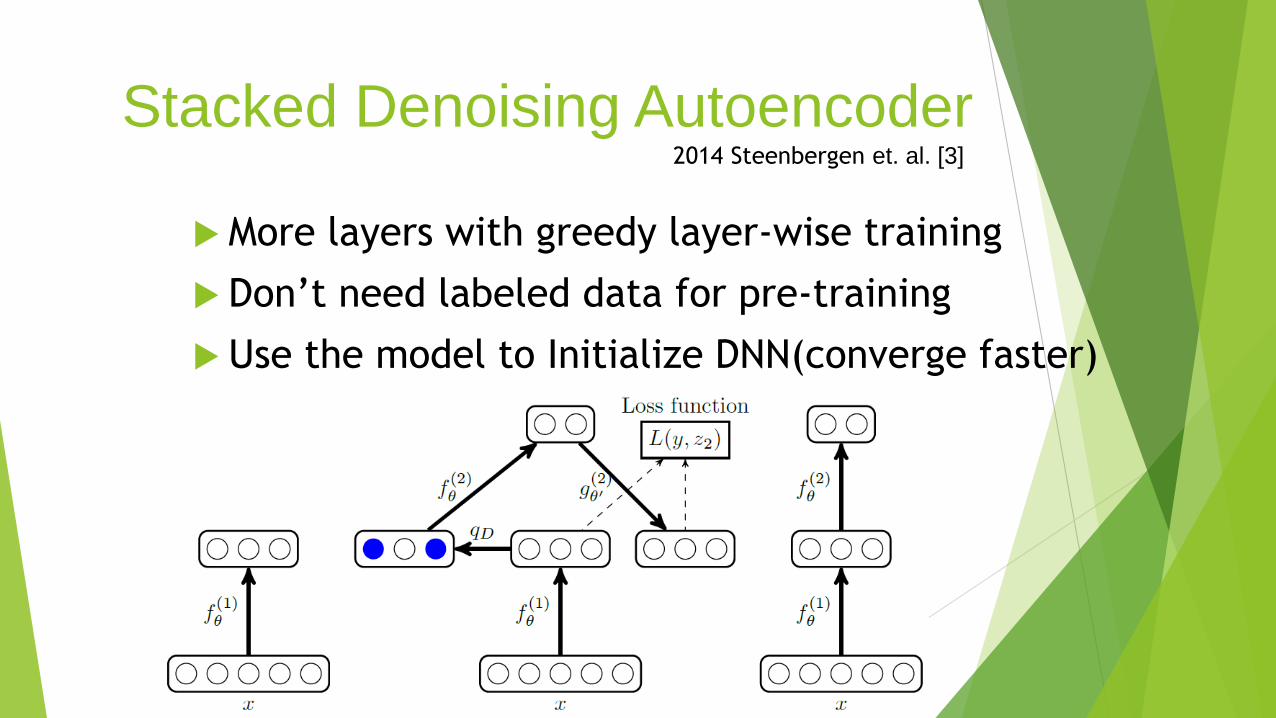
Stacked Denoising Autoencoder
More layers with greedy layer-wise training
Don’t need labeled data for pre-training
Use the model to Initialize DNN(converge faster)
2014 Steenbergen et. al. [3]

Supervised-Learning
Fine-tune by back-propagation after pre-training
Predict the emission probability for each chord
Softmax output layer at the end of DNN
Emis Frame1 Frame2 Frame3 Frame4 Frame5 Frame6
Cmaj 80% 70% 45% 40% 80% 85%
Fmaj 5% 5% 10% 5% 10% 5%
Gmaj 10% 15% 35% 50% 5% 5%
Amin 5% 10% 10% 5% 5% 5%

Prevent Overfitting
Happen when models are too powerful
Song-based Cross Validation
Early-Stopping (20 iter)
Dropout & DropConnect
Weight Penalty, Weight Constraint
Bottleneck Architecture
2010 Hinton et. al. [4] https://www.coursera.org/course/neuralnets
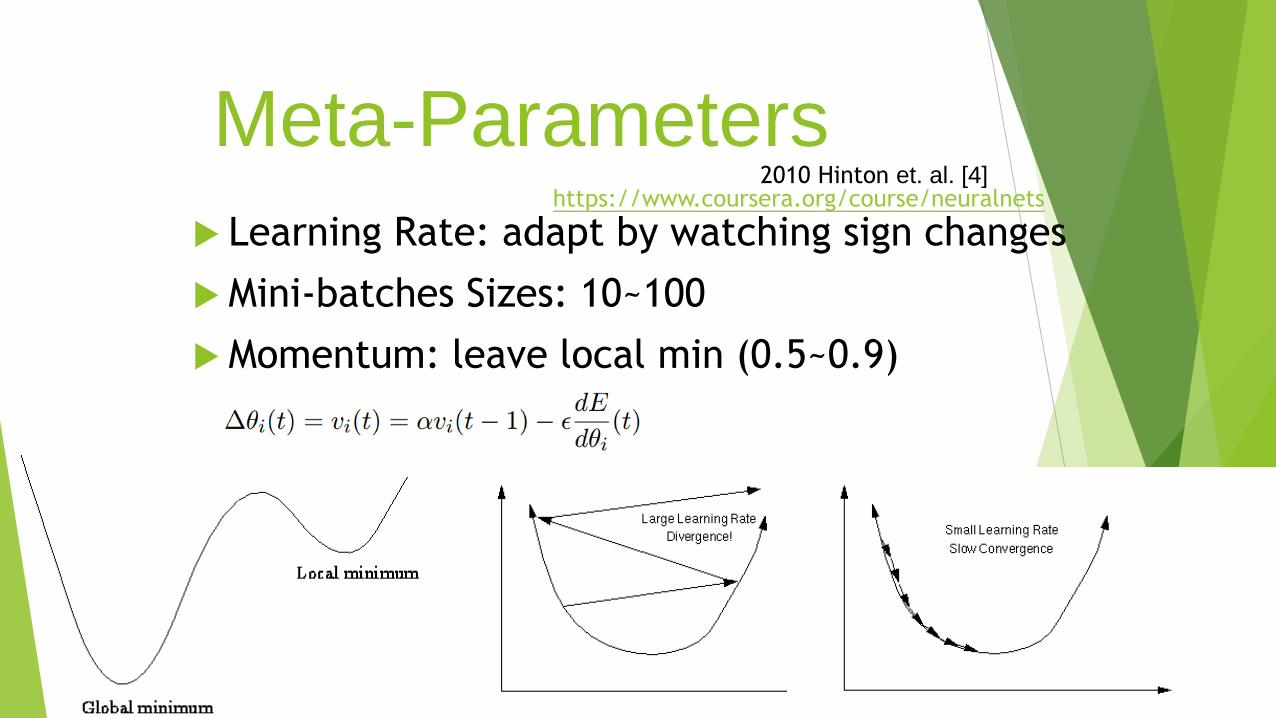
Meta-Parameters
Learning Rate: adapt by watching sign changes
Mini-batches Sizes: 10~100
Momentum: leave local min (0.5~0.9)
2010 Hinton et. al. [4] https://www.coursera.org/course/neuralnets

Outline
Feature Extraction
Pre-processing
Learning
Post-filtering

Viterbi-decoding
Get Transition Probability by counting
Remember the best path to current node
Tran Cmaj Fmaj Gmaj Amin
Cmaj 80% 5% 10% 5%
Fmaj 20% 70% 5% 5%
Gmaj 10% 10% 70% 10%
Amin 10% 20% 60% 10%
Emis T1 T2 T3 T4 T5 T6
Cmaj 80% 70% 45% 40% 80% 85%
Fmaj 5% 5% 10% 5% 10% 5%
Gmaj 10% 15% 35% 50% 5% 5%
Amin 5% 10% 10% 5% 5% 5%
http://www.hooktheory.com/trends
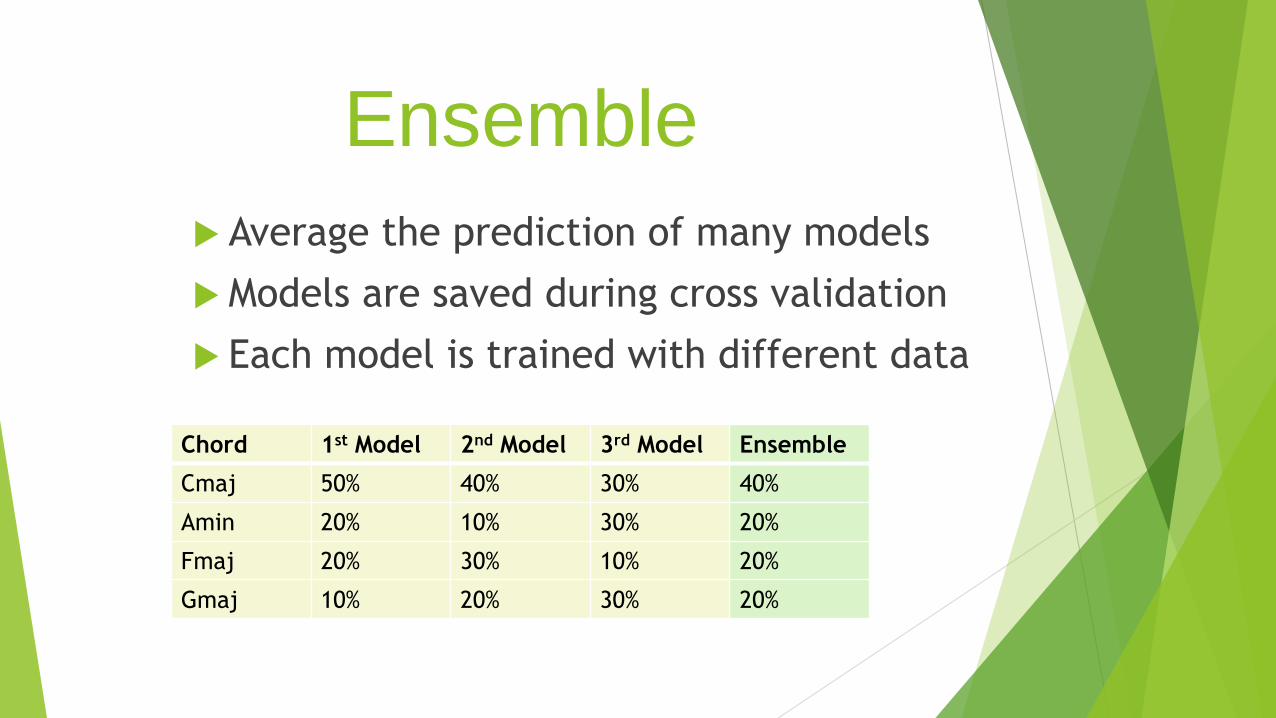
Ensemble
Average the prediction of many models
Models are saved during cross validation
Each model is trained with different data
Chord 1st Model 2nd Model 3rd Model Ensemble
Cmaj 50% 40% 30% 40%
Amin 20% 10% 30% 20%
Fmaj 20% 30% 10% 20%
Gmaj 10% 20% 30% 20%

RNN
Recurrent Neural Network
Combine acoustic model and language model
Result in 80.6% WAOR
2015 Nicolas et. al. [5] [6]
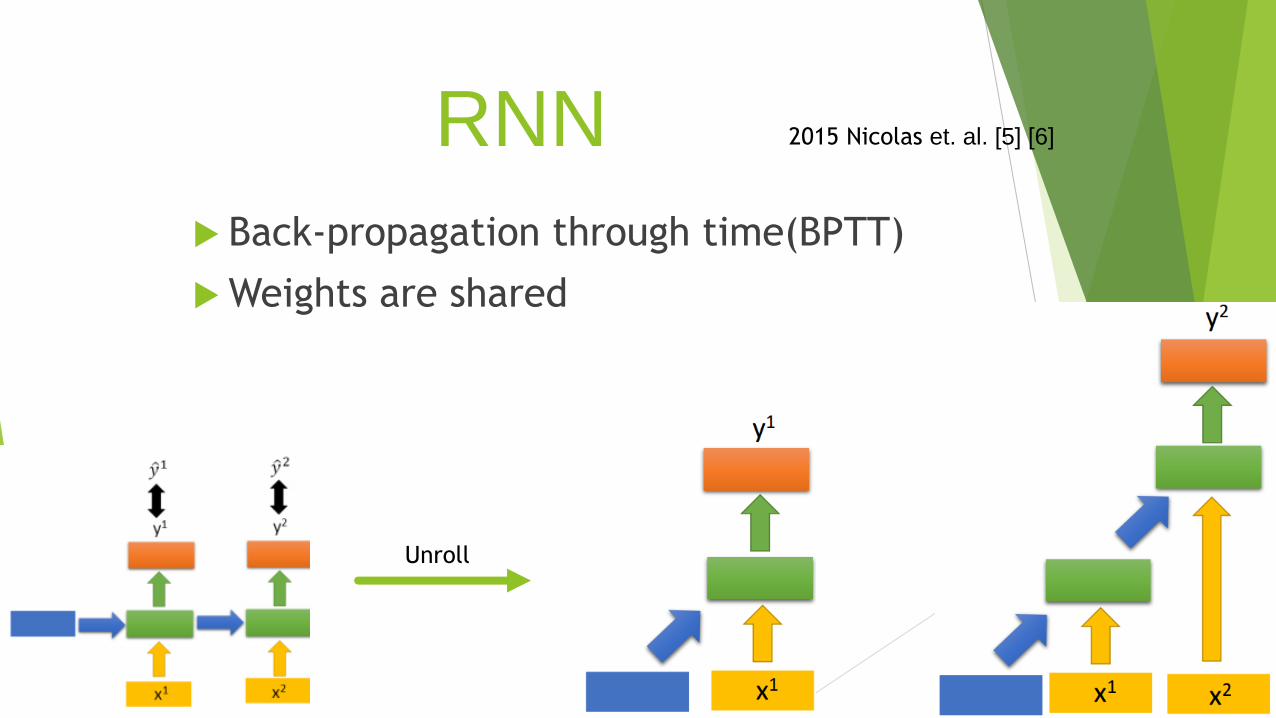
RNN
Back-propagation through time(BPTT)
Weights are shared
2015 Nicolas et. al. [5] [6]
Unroll

DBN with Musical Context
Dynamic Bayesian Network
Depend on other information
Map back to Cmaj key
Chord Progession: I V vi IV
Average chorus1~3
2010 Mauch et. al. [7] [8]

Reference [1] HMM-based Approach for Automatic Chord Detection Using Refined Acoustic Features
[2] Chord Detection Using Deep Learning
[3] Chord Recognition with Stacked Denoising Autoencoders
[4] A Practical Guide to Training Restricted Boltzmann Machines
[5] Audio Chord Recognition with Recurrent Neural Network
[6] Audio Chord Recognition with a Hybrid Recurrent Neural Network
[7] Simultaneous Estimation of Chords and Musical Context From Audio
[8] Using Musical Structure to Enhance Automatic Chord Transcription

Q&A
Thanks for listening.





























