Embed Size (px)
Citation preview

Journey Through the Cloud
[email protected]@IanMmmm
Ian Massingham — Technical Evangelist
Data Analysis

Journey Through the Cloud
Learn from the journeys taken by other AWS customers
Discover best practices that you can use to bootstrap your projects
Common use cases and adoption models for the AWS Cloud123

Data Analysis
Collect and store Big Data in the AWS CloudMeet the challenge of the increasing volume, variety, and velocity of dataReduce costs, scale to meet demand & increase the speed of innovation
Make use of solutions for every stage of the big data lifecycle

Agenda
Why Build Big Data Applications on AWS? Collecting Big Data in the AWS Cloud
Real-time Streaming and AnalysisBig Data Cloud Storage Solutions
AWS Database Services Analytics with Hadoop with Amazon EMR
Case Studies & Useful Resources

WHY BUILD BIG DATA APPLICATIONS ON AWS?

It’s Never Been Easier And Less Expensive To Collect, Store, Analyze & Share Data

We are constantly producing more data

From all types of industries

From a diverse range of sources

Sources of Truth Analysis PlatformsHigh Performance Databases
AWS Services For Big Data Workloads
Amazon S3 Amazon EFS
Amazon Redshift
Amazon DynamoDB Amazon Aurora
Amazon EMR
Real time
Amazon Kinesis

Broad Analytics Usage In The AWS Cloud
Discovery Development Delivery
Risk Marketing Reporting Trade
Sales

WHEN OUR ANALYSTS FIRST STARTED TO DO
QUERIES ON AMAZON REDSHIFT, THEY THOUGHT
IT WAS BROKEN BECAUSE IT WAS WORKING SO FAST.
John O’Donovan CTO Financial Times
• Needed a way to increase speed, performance and flexibility of data analysis at a low cost
• Using AWS enabled FT to run queries 98% faster than previously—helping FT make business decisions quickly
• Easier to track and analyze trends
• Reduced infrastructure costs by 80% over traditional data center model
Financial Times Uses AWS to Reduce Infrastructure Costs by 80%
Find out more here: aws.amazon.com/solutions/case-studies/financial-times/

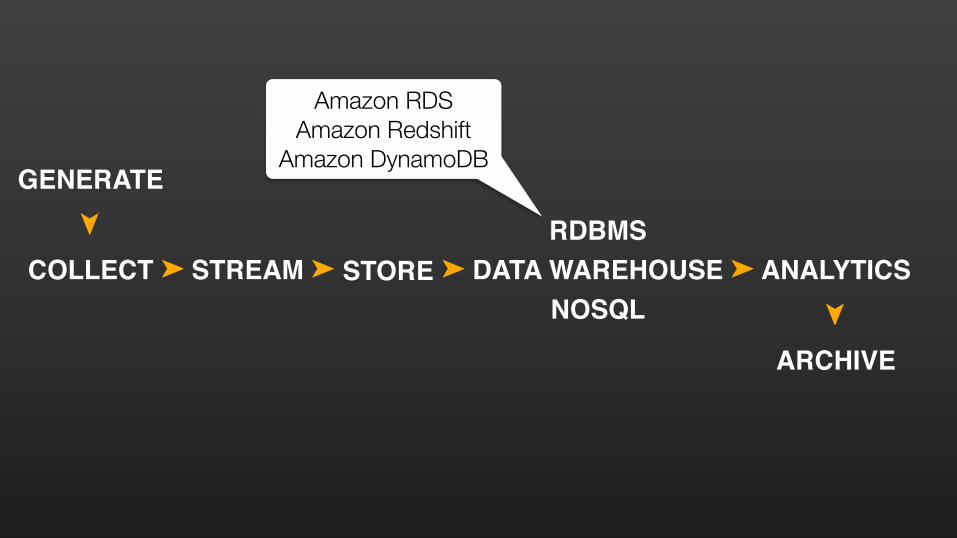
COLLECT STREAM STORERDBMS
DATA WAREHOUSENOSQL
ANALYTICS➤ ➤ ➤ ➤
GENERATE
➤
➤
ARCHIVE

COLLECTING BIG DATA IN THE AWS CLOUD

COLLECT STREAM STORERDBMS
DATA WAREHOUSENOSQL
ANALYTICS➤ ➤ ➤ ➤
GENERATE
➤
➤
ARCHIVE
Amazon S3 Multipart upload AWS Import/Export AWS Direct Connect
AWS Storage Gateway

Amazon S3
Secure, durable, highly-scalable object storageAccessible via a simple web services interface
Store & retrieve any amount of data Use alone or together with other AWS services
Amazon S3 Masterclass webinar: https://youtu.be/VC0k-noNwOU
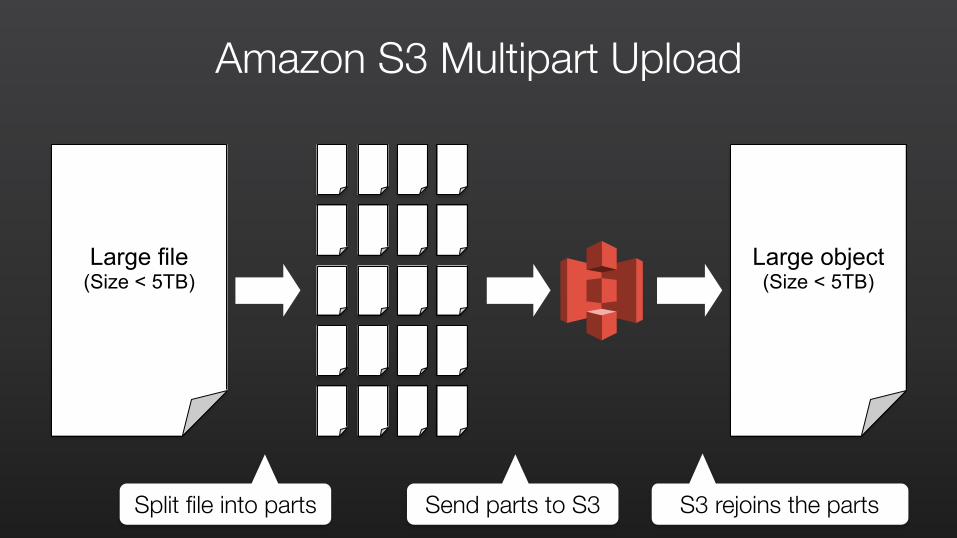
Amazon S3 Multipart Upload
Large file (Size < 5TB)
Large object (Size < 5TB)
Split file into parts Send parts to S3 S3 rejoins the parts

AWS Import/Export
Move large amounts of data into and out of the AWS cloud using portable storage devices Transfer your data directly onto and off of storage devices using Amazon’s high-speed internal network For significant data sets, AWS Import/Export is often faster than Internet transfer and more cost effective than upgrading your connectivity Supports upload & download from S3 & upload to Amazon EBS snapshots & Amazon Glacier Vaults
aws.amazon.com/importexport/

AWS Direct Connect
Makes it easy to establish a dedicated network connection from your premises to AWS Establish private connectivity between AWS & your datacenter, office, or colocation environment Reduce your network costs, increase bandwidth throughput, and provide a more consistent network experience The dedicated connection can be partitioned into multiple virtual interfaces using 802.1q VLANs
aws.amazon.com/directconnect

AWS Direct Connect Locations & Partners
aws.amazon.com/directconnect/partners/
1GB and 10GB ports are available from AWS
50Mbps, 100Mbps, 200Mbps, 300Mbps, 400Mbps, and
500Mbps can be ordered from any APN partners supporting
AWS Direct Connect

AWS Storage Gateway
An on-premises software appliance connecting with cloud-based storage Supports industry-standard storage protocols that work with your existing applications and workflows Provides low-latency performance by maintaining frequently accessed data on-premises while securely storing all of your data encrypted in Amazon S3 or Amazon Glacier
aws.amazon.com/storagegateway/

AWS Storage Gateway
Designed for user with other AWS Services Enables you to easily mirror data from your on premises environment for access within the AWS Cloud Easy to integrate into existing ETL workflows
aws.amazon.com/storagegateway/

REAL-TIME STREAMINGAND ANALYSIS

COLLECT STREAM STORERDBMS
DATA WAREHOUSENOSQL
ANALYTICS➤ ➤ ➤ ➤
GENERATE
➤
➤
ARCHIVE
Amazon Kinesis

Amazon Kinesis
A fully managed, cloud-based service for real-time data processing over large, distributed data streams Continuously capture and store terabytes of data per hour from hundreds of thousands of sources Emit data to other AWS services such as Amazon S3, Amazon Redshift, Amazon Elastic Map Reduce (Amazon EMR)
aws.amazon.com/kinesis

As a startup, using AWS has allowed us to scale nicely
and use resources without spending a lot of capital.
Brian Langel CTO Dash
• Needed scale IT resources to create an app that would offer real-time information to drivers
• Developed and deployed the Dash application on the AWS Cloud
• Streams more than 1 TB of real-time data per day using Amazon Kinesis and processes billions of entries using Amazon DynamoDB
• Scaled up to support large traffic spikes–several thousand updates per second–in app usage
• Reduced operating costs by $200,000 per year
Using AWS, Dash Streams More Than 1 TB of Real-Time Data Per Day
Find out more here: aws.amazon.com/solutions/case-studies/dash/

Millions of sources producing 100s of
TB per hour
Front End
AuthenticationAuthorization
AZAZAZ
Durable, consistent replicas across three AWS Availability Zones
Amazon Web Services RegionInexpensive: $0.0165 per million PUT Payload Units
(in EU Ireland)
Aggregate and archive to S3
Real-time dashboards and
alarms
Machine learning algorithms
Aggregate analysis in Hadoop or a data
warehouse
Ordered stream of events supporting multiple readers
Amazon Kinesis Architecture
New

BIG DATA CLOUDSTORAGE SOLUTIONS

COLLECT STREAM STORERDBMS
DATA WAREHOUSENOSQL
ANALYTICS➤ ➤ ➤ ➤
GENERATE
➤
➤
ARCHIVE
Amazon S3 Amazon GlacierAmazon EBS

Amazon S3
Secure, durable, highly-scalable object storageAccessible via a simple web services interface
Store & retrieve any amount of data Use alone or together with other AWS services
Amazon S3 Masterclass webinar: https://youtu.be/VC0k-noNwOU

Amazon S3
Allows you to decouple compute from storage for analytics workloads
Amazon S3 Masterclass webinar: https://youtu.be/VC0k-noNwOU
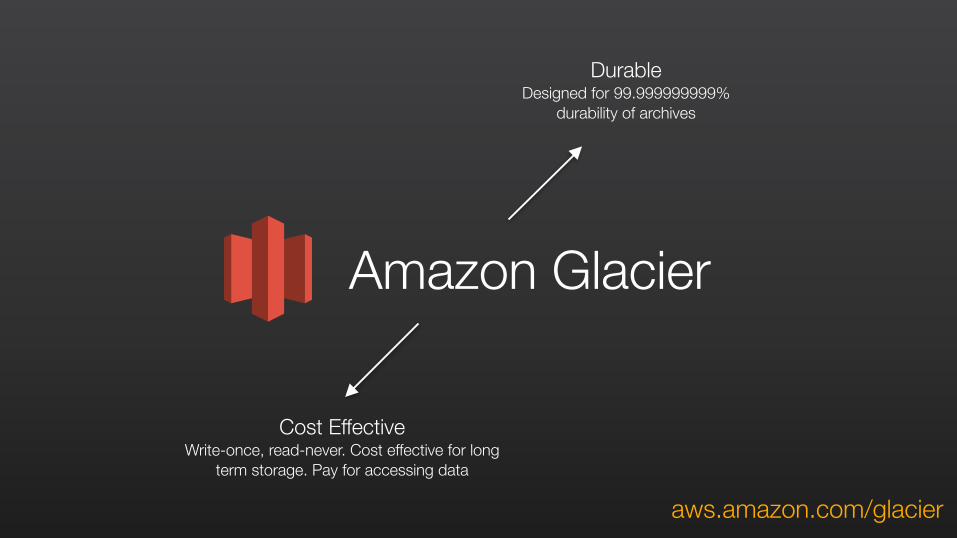
Amazon Glacier
Durable Designed for 99.999999999%
durability of archives
Cost Effective Write-once, read-never. Cost effective for long
term storage. Pay for accessing data
aws.amazon.com/glacier

Amazon Elastic Block Store (EBS)
Persistent block level storage volumes For use with Amazon EC2 instances
Automatically replicated within Availability Zones Offer consistent and low-latency performance
EBS Snapshot (stored on S3)
EBS Volume
EC2 Instance
aws.amazon.com/ebs

EC2Instance
Very Fast Block devices to attach
to EC2 Instances
Fast API Accessible Object Storage
3-5 hour access latency Intended for write once, read never use-cases
Elastic Block Store Amazon EBS
Simple Storage Service Amazon S3 Amazon Glacier
1GB to 16TB Volumes up to 20,000 IOPS per
volume with EBS PIOPS
Highly Scalable Object Store Objects from 1 byte to 5TB 99.99999999% durability
Long term archive storage Extremely low cost per GB 99.99999999% durability

AWS DATABASE SERVICES
COLLECT STREAM STORERDBMS
DATA WAREHOUSENOSQL
ANALYTICS➤ ➤ ➤ ➤
GENERATE
➤
➤
ARCHIVE
Amazon RDS Amazon Redshift
Amazon DynamoDB

Amazon Relational Database Service (RDS)
Easy to set up, operate, and scale a relational database Provides cost-efficient and resizable capacity
Manages time-consuming database management tasks
aws.amazon.com/rds/

Amazon Redshift
A fast, fully managed, petabyte-scale data warehouse Cost-effectively & efficiently analyze all your data
Use existing Business Intelligence tools Fast query performance using columnar storage technology
aws.amazon.com/redshift/

Getting Started with Amazon Redshift
aws.amazon.com/redshift/getting-started/
2 Month Free Trial 6 Step Getting Started Tutorial Best Practices Guides — loading data, table design & performance tuning
Cluster Management Guide

BI & ETL Tools for Amazon Redshift
aws.amazon.com/redshift/partners/

Amazon DynamoDB
A fast and flexible NoSQL database service Consistent, single-digit millisecond latency at any scale
A fully managed cloud database Supports both document and key-value store models
Flexible data model and reliable performance
aws.amazon.com/dynamodb/

ANALYTICS WITH HADOOP & AMAZON EMR

COLLECT STREAM STORERDBMS
DATA WAREHOUSENOSQL
ANALYTICS➤ ➤ ➤ ➤
GENERATE
➤
➤
ARCHIVE
Amazon EMR

AMAZON ELASTIC MAPREDUCE
A MANAGED HADOOP FRAMEWORK

HADOOPDISTRIBUTED FILESYSTEM
(HDFS) +
DISTRIBUTED PROCESSING ENGINE(MAPREDUCE)

Amazon Elastic MapReduce (EMR)
A managed Hadoop framework Quickly & cost-effectively process vast amounts of data
Dynamically scale across fleets of Amazon EC2 instances Run other popular distributed frameworks such as Spark
aws.amazon.com/emr/

Amazon Elastic MapReduce (EMR)
Splits data in pieces using the HDFS filesystem Manages distributed access to data and task execution Gathers the results and deposits these in S3 for access

Very large clickstream logging data
(e.g TBs)

Lots of actions by John Smith
Very large clickstream logging data
(e.g TBs)
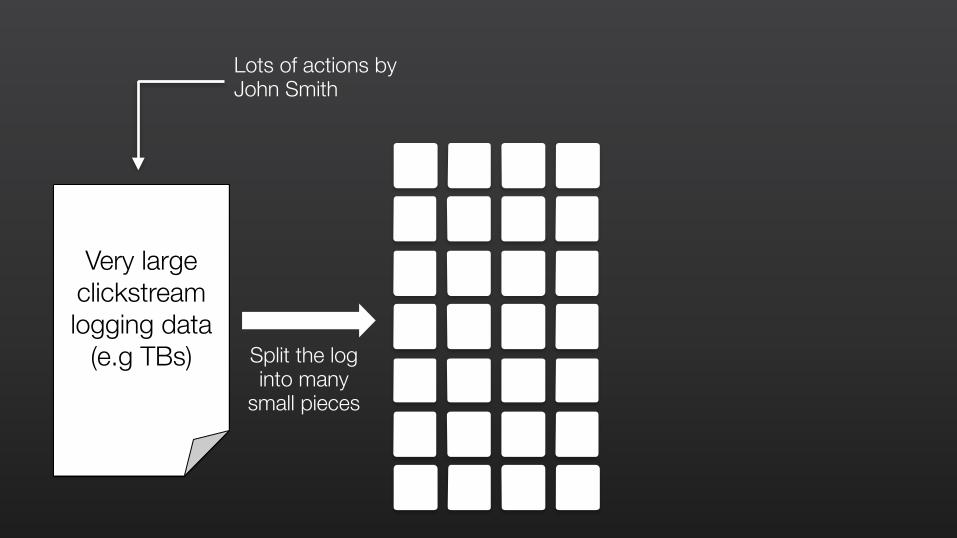
Lots of actions by John Smith
Split the log into many
small pieces
Very large clickstream logging data
(e.g TBs)

Lots of actions by John Smith
Split the log into many
small pieces
Process in an EMR cluster
Very large clickstream logging data
(e.g TBs)

Lots of actions by John Smith
Split the log into many
small pieces
Process in an EMR cluster
Aggregate the results from all
the nodes
Very large clickstream logging data
(e.g TBs)

Lots of actions by John Smith
Split the log into many
small pieces
Process in an EMR cluster
Aggregate the results from all
the nodes
Very large clickstream logging data
(e.g TBs)
What John Smith did

Insight in a fraction of the time
Very large clickstream logging data
(e.g TBs)
What John Smith did

Analytics languages/enginesData management
Amazon Redshift
AWS Data Pipeline
Amazon Kinesis
Amazon S3
Amazon DynamoDB
Amazon RDSAmazon EMR
Data Sources

DEMO:ANALYZING AMAZON S3 ACCESS
LOGS WITH EMR AND HUE

PREDICTIVE ANALYTICS WITHAMAZON MACHINE LEARNING

Email targeting Recommendations Social news
Digital health Language processing Auto-scaling
More & More Customers Are Using Prediction Technologies

Large opportunity to apply ML
Low barrier to entry

Easily create machine learning models
Visualize and optimize models
Put models into production in seconds
Battle-hardened technology
NewIntroducing Amazon Machine Learning
aws.amazon.com/ml/

Train and optimize models on GBs of data
Batch process predictions
Real-time prediction API in one-click
No servers to provision or manage
Easy to Use, High Performance

3 Make predictions
Asynchronous predictions with trained model
Batch predictions
Synchronous, low latency, high throughput
Mount API end-point with a single click
Real-time predictions1 Build model
2 Validate & optimize

RESOURCES YOU CAN USETO LEARN MORE

aws.amazon.com/big-data/

aws.amazon.com/importexport
aws.amazon.com/directconnect
aws.amazon.com/kinesis
aws.amazon.com/rds
aws.amazon.com/redshift
aws.amazon.com/elasticmapreduce

Big Data Analytics Options on AWS
Erik Swensson
December 2014
Amazon Web Services – Big Data Analytics Options on AWS December 2014
Page 2 of 29
Contents Contents 2
Abstract 3
Introduction 3
The AWS Advantage in Big Data Analytics 3
Amazon Redshift 4
Amazon Kinesis 7
Amazon Elastic MapReduce 10
Amazon DynamoDB 14
Application on Amazon EC2 17
Solving Big Data Problems 19
Example 1: Enterprise Data Warehouse 21
Example 2: Capturing and Analyzing Sensor Data 23
Conclusion 27
Further Reading 27
Amazon Web Services – Big Data Analytics Options on AWS December 2014
Page 3 of 29
Abstract Amazon Web Services (AWS) is a flexible, cost-effective, easy-to-use cloud computing platform. The AWS Cloud delivers a comprehensive portfolio of secure and scalable cloud computing services in a self-service, pay-as-you-go model, with zero capital expense needed to handle your big data analytics workloads, such as real-time streaming analytics, data warehousing, NoSQL and relational databases, object storage, analytics tools, and data workflow services. This whitepaper provides an overview of the different big data options available in the AWS Cloud for architects, data scientists, and developers. For each of the big data analytics options, this paper describes the following:
x Ideal usage patterns x Performance x Durability and availability x Cost model x Scalability x Elasticity x Interfaces x Anti-patterns
This paper describes two scenarios showcasing the analytics options in use and provides additional resources to get started with big data analytics on AWS.
Introduction As we become a more digital society the amount of data being created and collected is accelerating significantly. The analysis of this ever-growing data set becomes a challenge using traditional analytical tools. Innovation is required to bridge the gap between the amount of data that is being generated and the amount of data that can be analyzed effectively. Big data tools and technologies offer ways to efficiently analyze data to better understand customer preferences, to gain a competitive advantage in the marketplace, and to use as a lever to grow your business. The AWS ecosystem of analytical solutions is specifically designed to handle this growing amount of data and provide insight into ways your business can collect and analyze it.
The AWS Advantage in Big Data Analytics Analyzing large data sets requires significant compute capacity that can vary in size based on the amount of input data and the analysis required. This characteristic of big data workloads is ideally suited to the pay-as-you-go cloud computing model, where applications can easily scale up and down based on demand. As requirements change you can easily resize your environment (horizontally or vertically) on AWS to meet your
Amazon Web Services – Big Data Analytics Options on AWS December 2014
Page 4 of 29
needs without having to wait for additional hardware, or being required to over-invest to provision enough capacity. For mission-critical applications on a more traditional infrastructure, system designers have no choice but to over-provision, because a surge in additional data due to an increase in business need must be something the system can handle. By contrast, on AWS you can provision more capacity and compute in a matter of minutes, meaning that your big data applications grow and shrink as demand dictates, and your system runs as close to optimal efficiency as possible. In addition, you get flexible computing on a world-class infrastructure with access to the many different geographic regions that AWS offers1, along with the ability to utilize other scalable services that Amazon offers such as Amazon Simple Storage Service (S3)2 and AWS Data Pipeline.3 These capabilities of the AWS platform make it an extremely good fit for solving big data problems. You can read about many customers that have implemented successful big data analytics workloads on AWS on the AWS case studies web page. 4
Amazon Redshift Amazon Redshift is a fast, fully-managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence tools.5 It is optimized for datasets ranging from a few hundred gigabytes to a petabyte or more, and is designed to cost less than a tenth of the cost of most traditional data warehousing solutions. Amazon Redshift delivers fast query and I/O performance for virtually any size dataset by using columnar storage technology while parallelizing and distributing queries across multiple nodes. As a managed service, automation is provided for most of the common administrative tasks associated with provisioning, configuring, monitoring, backing up, and securing a data warehouse, making it very easy and inexpensive to manage and maintain. This automation allows you to build a petabyte-scale data warehouse in minutes, a task that has traditionally taken weeks, or months, to complete in an on-premises implementation.
Ideal Usage Pattern Amazon Redshift is ideal for online analytical processing (OLAP) using your existing business intelligence tools. Organizations are using Amazon Redshift to do the following:
x Analyze global sales data for multiple products x Store historical stock trade data x Analyze ad impressions and clicks x Aggregate gaming data x Analyze social trends
1 http://aws.amazon.com/about-aws/globalinfrastructure/ 2 http://aws.amazon.com/s3/ 3 http://aws.amazon.com/datapipeline/ 4 http://aws.amazon.com/solutions/case-studies/big-data/ 5 http://aws.amazon.com/redshift/
AWS White Paper - Big Data Analytics Options on AWS

aws.amazon.com/solutions/case-studies/analytics/

aws.amazon.com/solutions/case-studies/big-data/

aws.amazon.com/architecture/

Certification
aws.amazon.com/certification
Self-Paced Labs
aws.amazon.com/training/self-paced-labs
Try products, gain new skills, and get hands-on practice working
with AWS technologies
aws.amazon.com/training
Training
Validate your proven skills and expertise with the AWS platform
Build technical expertise to design and operate scalable, efficient applications on AWS
AWS Training & Certification

Follow us fo
r more
events
& webina
rs
@AWScloud for Global AWS News & Announcements
@AWS_UKI for local AWS events & news
@IanMmmmIan Massingham — Technical Evangelist
































