Embed Size (px)
Citation preview

O C T O B E R 1 3 - 1 6 , 2 0 1 6 • A U S T I N , T X

Developing a Big Data Search Engine 2.0 Where we have gone, where we are going.
Mark Miller Software Engineer, Cloudera

3
01Who am I?
I’m Mark Miller I’m a Lucene junkie (2006) I’m a Lucene committer (2008) And a Solr committer (2009) And a member of the ASF (2011) And a former Lucene PMC Chair (2014-2015) I co-created SolrCloud (????)
4
02A Quick Tour Through History
First there was Lucene. It took a little while, but soon it was “good enough” to replace most search engines. And faster. And more efficient. Lots of Search Engines built on Lucene (I made one!) Then there was Solr.
And then there were Others.
5
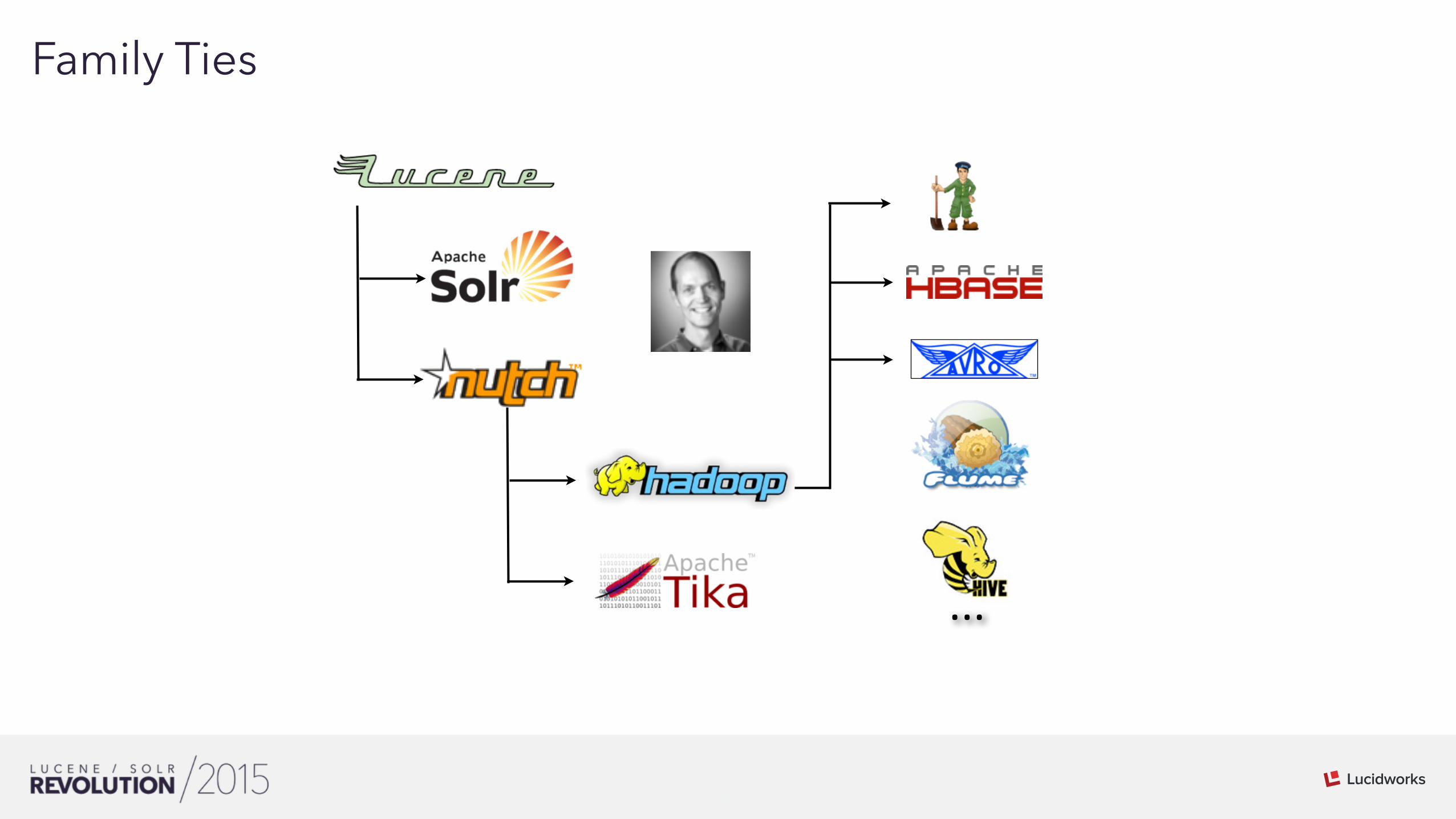
03Family Ties
...

6
01What Search Engines Matter?
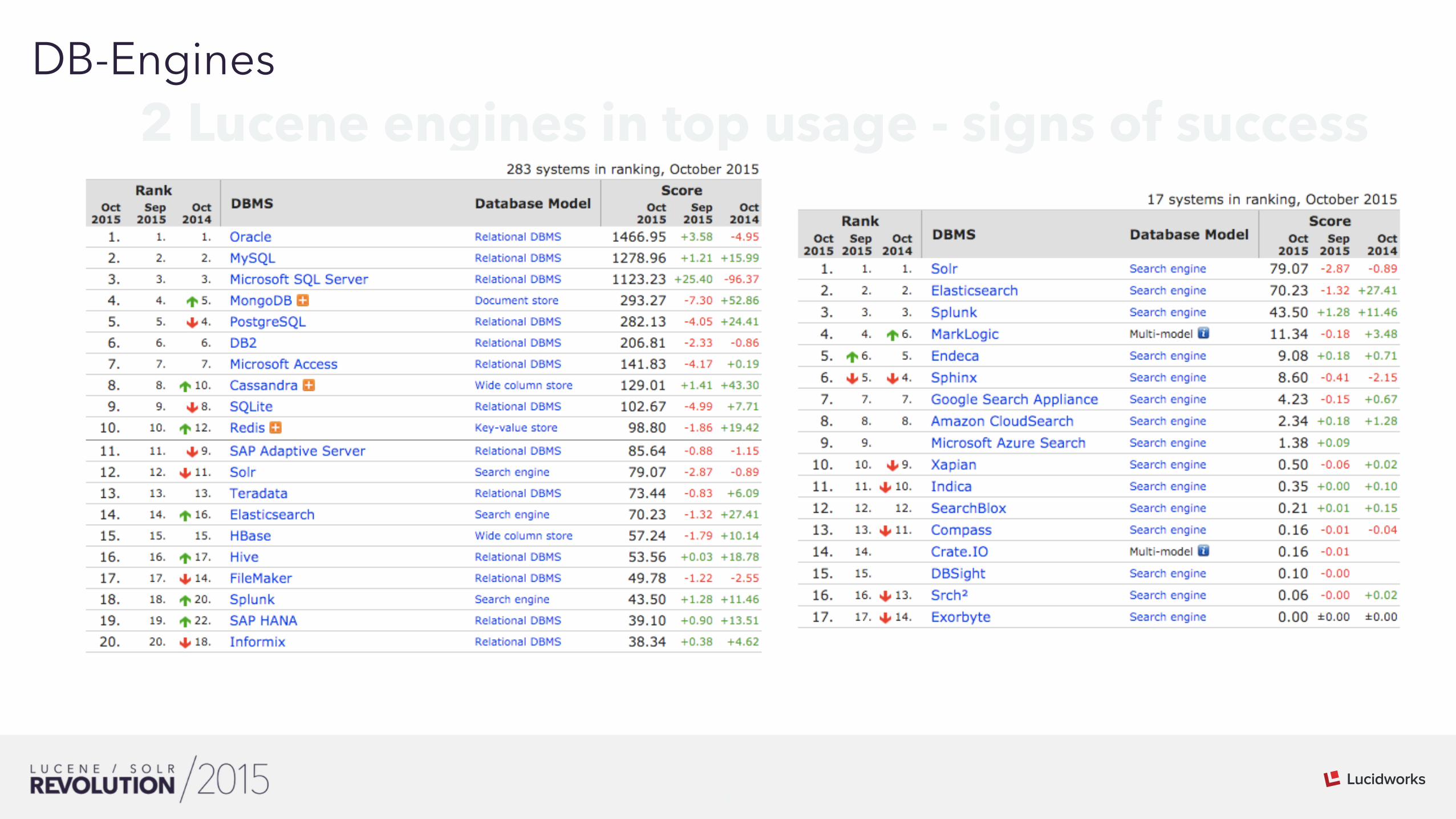
Lucene search engines lead the pack.
How can you tell?
I like to look at db-engines.org - these are the skills devs have, users are talking about and employers are hiring for.
Also, plenty of anecdotal evidence that others are using Lucene for the core. Classic Enterprise Search Engines matter a little bit.
7
01DB-Engines2 Lucene engines in top usage - signs of success

8
01Enterprise Search Engines
Oracle buys Endeca (2011 - $1.075B), Microsoft buys Fast (2008 - $1.2B), HP buys Autonomy (2011 - $10.3B)
World Happiness Decreases.
The old leaders.2006: Autonomy, FAST, Endeca tops in Gartner site search
study
2015 Leaders: Coveo, HP, Sinequa, Attivio, Lexmark
You can bet any large company using one of these also uses a Lucene based solution.
The new leaders.

9
But Search is a general tool and Open Source is the core of the Future and a virtuous cycle
Open source has become the default approach for software with more than 66 percent of respondents saying they consider OSS before other options. (2015 BlackDuck)
It’s an open-source world: 78 percent of companies run open-source software. (2015 BlackDuck)
Less than 3% DON’T USE OSS IN ANY WAY.

10
It’s the age of Lucene

11
“It is hopeless to talk to both of you, you don't understand virtual memory.”
Uwe Schindler @thetaph1 @uwesays

12
01What is the future of Search?
More NoSQL More SQL More Realtime Analytics More System of Record More Graph More Scale Search will eat away at the stack.
Search focuses on pre processing and efficient in memory data structures for fast responses.

13
01The Solr Beginnings - Single node, then DIY distributed
Solr started as a single node solution, followed by master/slave replication, followed by simple distributed search. This was ‘good enough’ for a long time. Classic ‘innovators dilemma’ problem.
Scaling out was super important, but not as soon as some thought and sooner than others thought. The challenge was, how do we evolve the system and can we move the Solr user base to this evolution without disrupting current users?
14
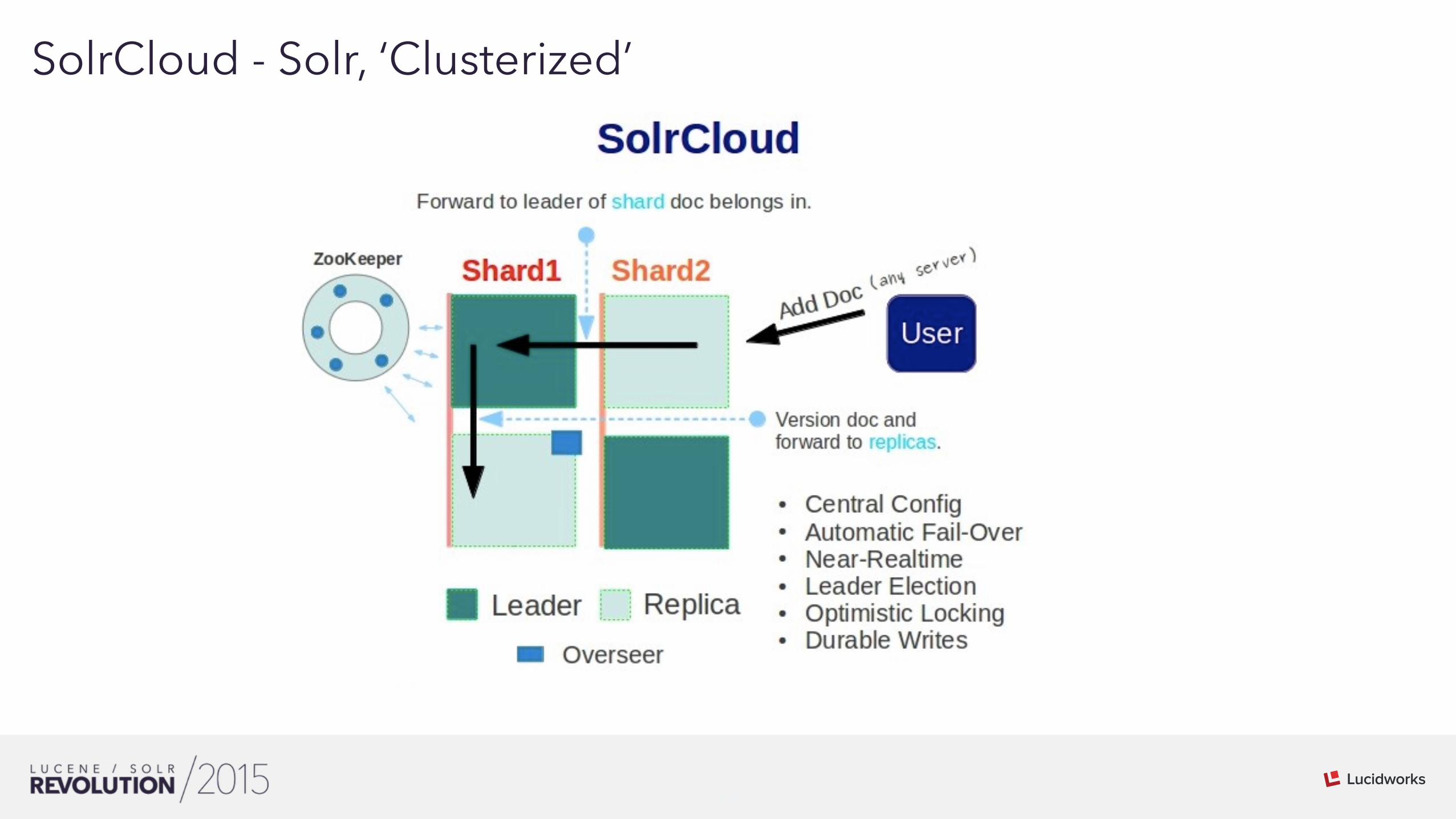
01SolrCloud - Solr, ‘Clusterized’

15
01Solr Meets Hadoop
First Class Solr Integrations HDFS MapReduce Spark Flume HBase Sentry Etc
SolrCloud was already built on ZooKeeper

16
01Now it’s all about scale and correctness.
The search features for the big data world are here and rapidly advancing.
The next step is being able to handle Hadoop scale in the ‘general’ case.
And to be able to handle that correctly ‘enough’ of the time.

17
“In my opinion the whole code is a bug by itself.”
Uwe Schindler @thetaph1 @uwesays
18
01The Call Me Maybe Tests
https://aphyr.com/tags/jepsen
Some basic testing around how systems live up to their CAP promises. Heavy focus on partitions.
Most systems fail pretty badly. ZooKeeper rocked it. SolrCloud did pretty darn well*.
Kyle Kingsbury
19
01Call Me … Maybe ??
Passing is actually like a very minimum bar. It doesn’t at all mean your system is correct.
Your system could be complete crap and still pass.
In fact, in the general case, all the current best search engines are still flakey at scale.

20
01Search at Scale is still Flakey?Yes, yes it is. Most systems at scale are still flakey. Most systems don’t deliver on their promises. It’s a matter of degree.
How does search in particular get away with it?
Users are already used to not considering it the system of record. Its easier to scale specialized than general - project has to scale general but massive users can scale specialized.
We want the project to easily scale generally - no expertise needed. You can already scale pretty large, but it takes a ‘vertical’ and expertise.

21
01Search in Particular is HARD
The search engine is a many faceted beast.
There is a lot of surface area.
You need many very different features to all integrate well together, usually in near realtime.
It sounds a lot easier than it is.

22
"Lucene is maybe the world's most tested open source project."
Uwe Schindler @thetaph1 #bbuzz 2014

23
01The Lucene Testing Framework
Lucene regularly finds bugs in new Java releases. Seriously. Regularly.
Many of those bugs are fixed and fixed quickly. Many are not.
Randomized testing, reproducible master seeds.
“Test Beasting” and seti@home type resource requirements.

24
01The Lucene Testing Framework
Code checkers and build enforcers galore, as well as test level checkers and enforcers.
Who is policing the policeman?
You need a vibrant community that gives a damn.

25
“The stack trace is only impossible if you look at the code.”
Uwe Schindler @thetaph1 @uwesays

26
01Testing is the Key and the Answer
Just because your tests don't normally fail doesn't mean they are great. You probably just don’t normally see the problems.
Our test framework exposes the problems - quickly.
This has pluses and minuses, but the pluses greatly outweigh the minuses!
27
01More on Testing
Integration and unit tests are equally important.
Integration tests are a little more important.
Testing, testing, and more testing is your best friend.
Communities grow, communities change, one or two can’t hold the code together.
28
01More on Testing
Distributed testing takes more. You want testing to the hardware level, not as just as part of a simple test framework. You want to test on large, expensive clusters. Debugging grows as an issue. Companies are taking on this work and the results are and will be funneled back into the project. Age is a virtue.

29
01Regular Large Scale Testing will be a challenge!
1000 nodes with
SolrCloud Radial View

30
01RAW
TBD: At Cloudera we are building htrace, chaos monkey w/ fault injection, etc - higher level is
important, beast test cluster

31
01The Race for Scalable search is on!
My approach will be to leverage Hadoop as much as possible!
Many companies are focused on Solr - there will be many approaches!
It’s still early in the game.

32
01Leverage Hadoop
A distributed filesystem is a beautiful crutch to lean on! Consider a single index shared by all replicas.
ETL at scale is not Solr’s strength. A marriage with Hadoop is natural and has been long
ongoing
Hadoop will push Solr to it’s limits and beyond.

33
"As a good policeman I have all open source ‘guns’ for code checking available."
Uwe Schindler @thetaph1 @uwesays
https://code.google.com/p/forbidden-apis/
http://labs.carrotsearch.com/randomizedtesting.html

34
01Thank You!
Mark Miller @heismark Software Engineer Cloudera



![Cloudera ODBC Driver for Apache Hive Installation and ... · separatedlistofZooKeeperservers.Usethefollowingformat,where[ZK_Host]isthe ... 6.IntheDataFileHDFSDirfield,typetheHDFSdirectorythatthedriverusestostorethe](https://img.pdfslide.net/doc/110x75/5b4908877f8b9a824f8cfafc/cloudera-odbc-driver-for-apache-hive-installation-and-separatedlistofzookeeperserversusethefollowingformatwherezkhostisthe.jpg)





![CENTERITY SERVICE PACK FOR CLOUDERA€¦ · OOZIE [roles status] • CLOUDERA ROLES SOLR [roles status] • CLOUDERA ROLES SPARK [roles status] • CLOUDERA ROLES SQOOP [roles status]](https://img.pdfslide.net/doc/110x75/5fc0df6d43307a59a12ae0a7/centerity-service-pack-for-cloudera-oozie-roles-status-a-cloudera-roles-solr.jpg)



















