Embed Size (px)
Citation preview

Fast > Perfect
Practical real-time approximationsusing Spark Streaming
Kevin Schmidt@kevinschmidtbiz
Luis Vicente@lvicentesanchez

A Bit of Context: Mind Candy

A Bit of Context: Free To Play
Sum Arbitrary Values
Count Uniques It’s Complicated
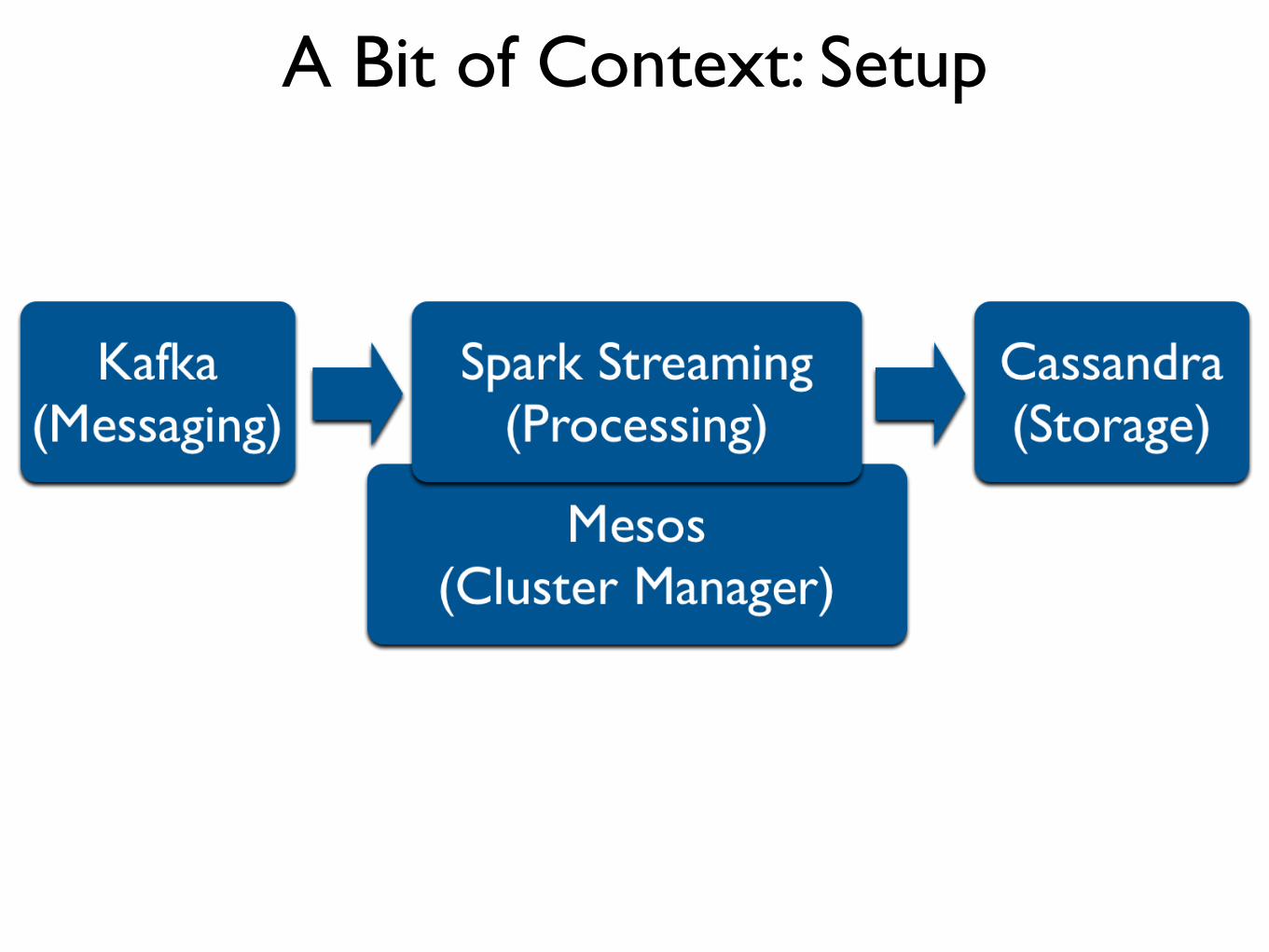
A Bit of Context: Setup

A Bit of Context: Requirements
• Constant storage space usage independent of number of users
• Handle delayed or duplicate data
• Error rate under 3%

Counting Users: Basics
How To Count IDs Uniquely

Counting Users: HyperLogLog
addIdentifier(value: String)
merge(other: HyperLogLog): HyperLogLog
zero(): HyperLogLog
countUniques(): Long
HyperLogLog
Error Rate = 1.6%Fixed Size = 4KB
14Bit Size:
12Bit Size:
Error Rate = 0.9%Fixed Size = 16KB

Counting Users: DStream
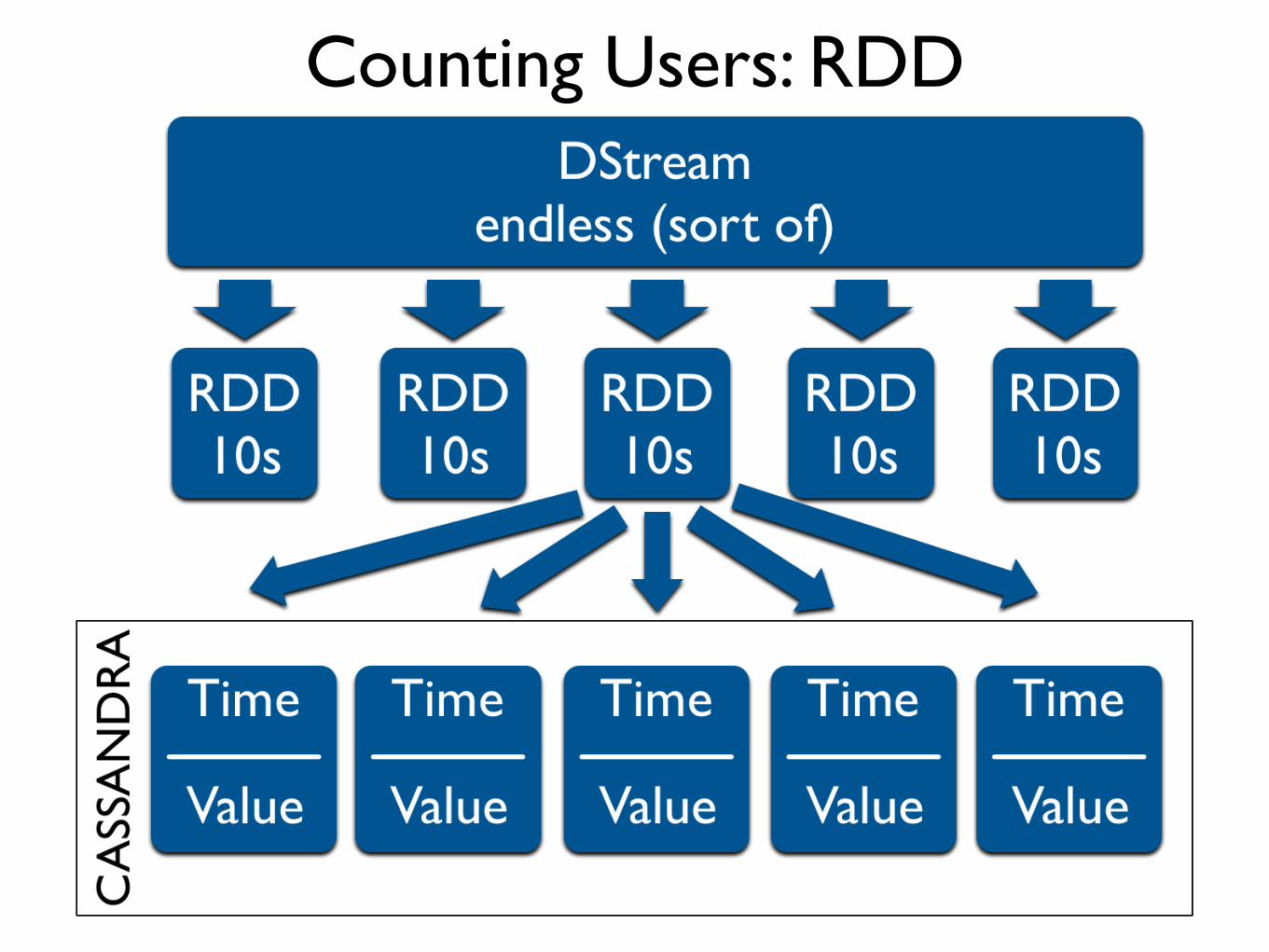
Counting Users: RDD
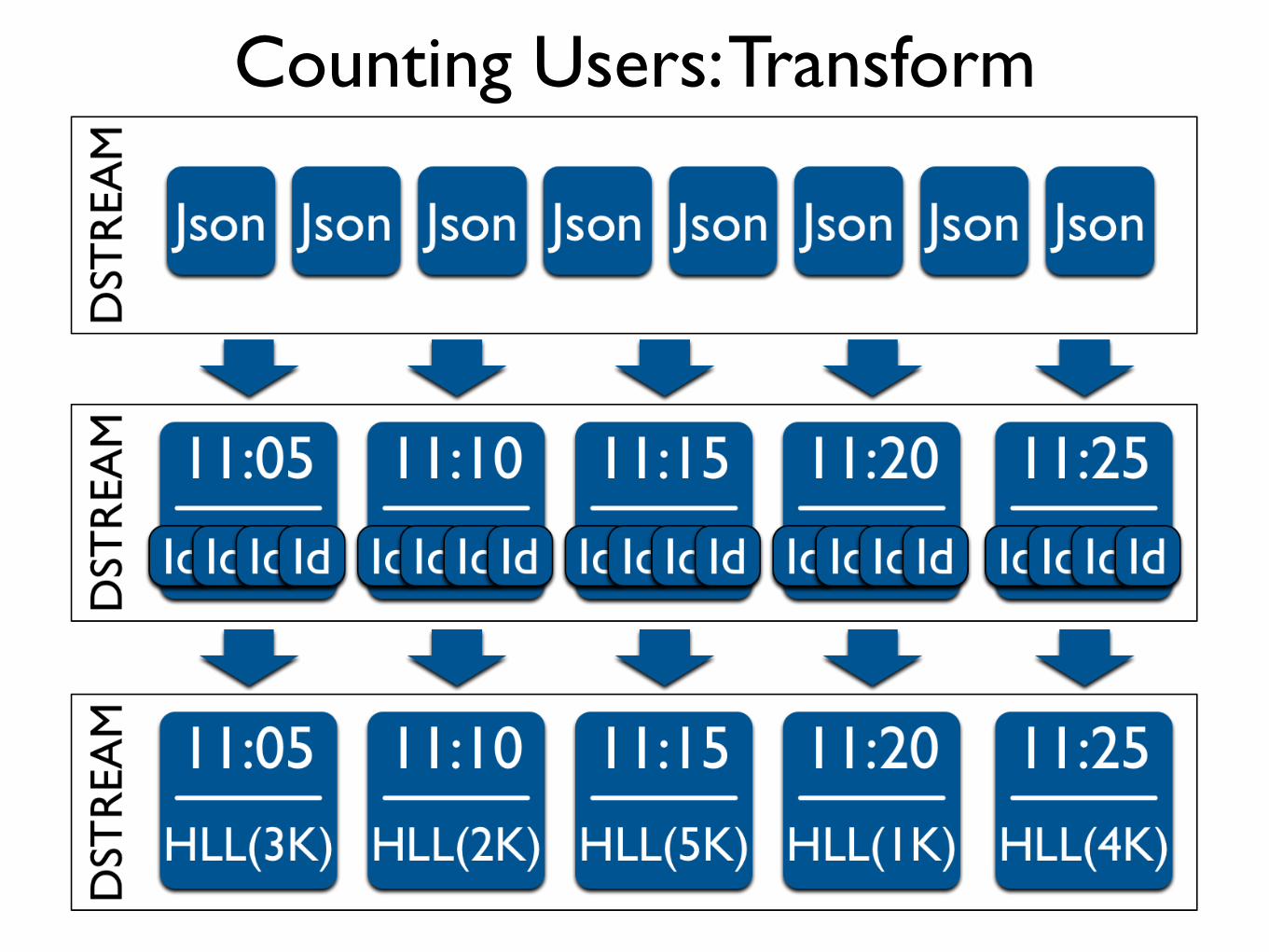
Counting Users: Transform

Counting Users: Storing

Counting Users: Some Scala
https://github.com/lvicentesanchez/fast-gt-perfect
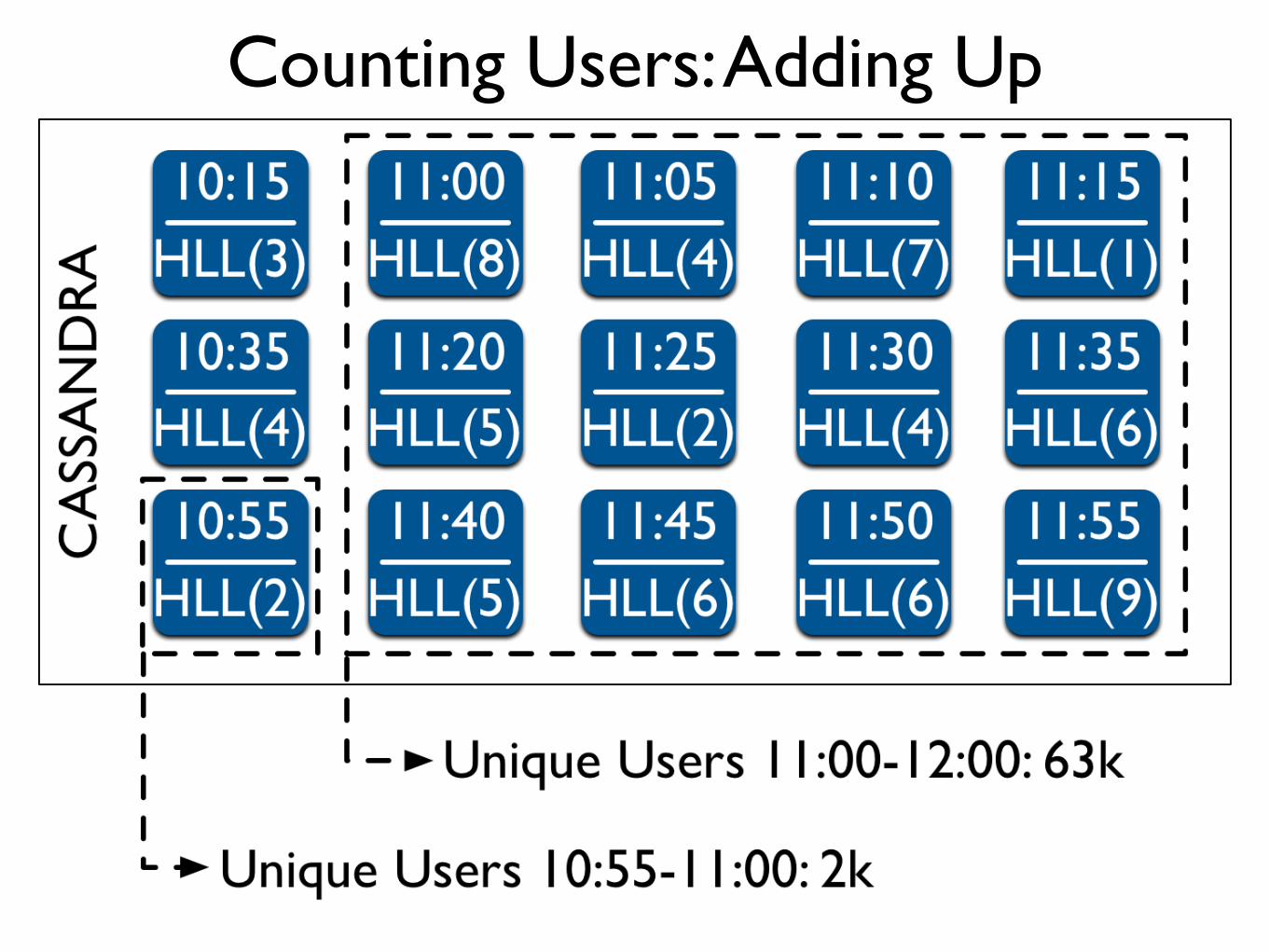
Counting Users: Adding Up
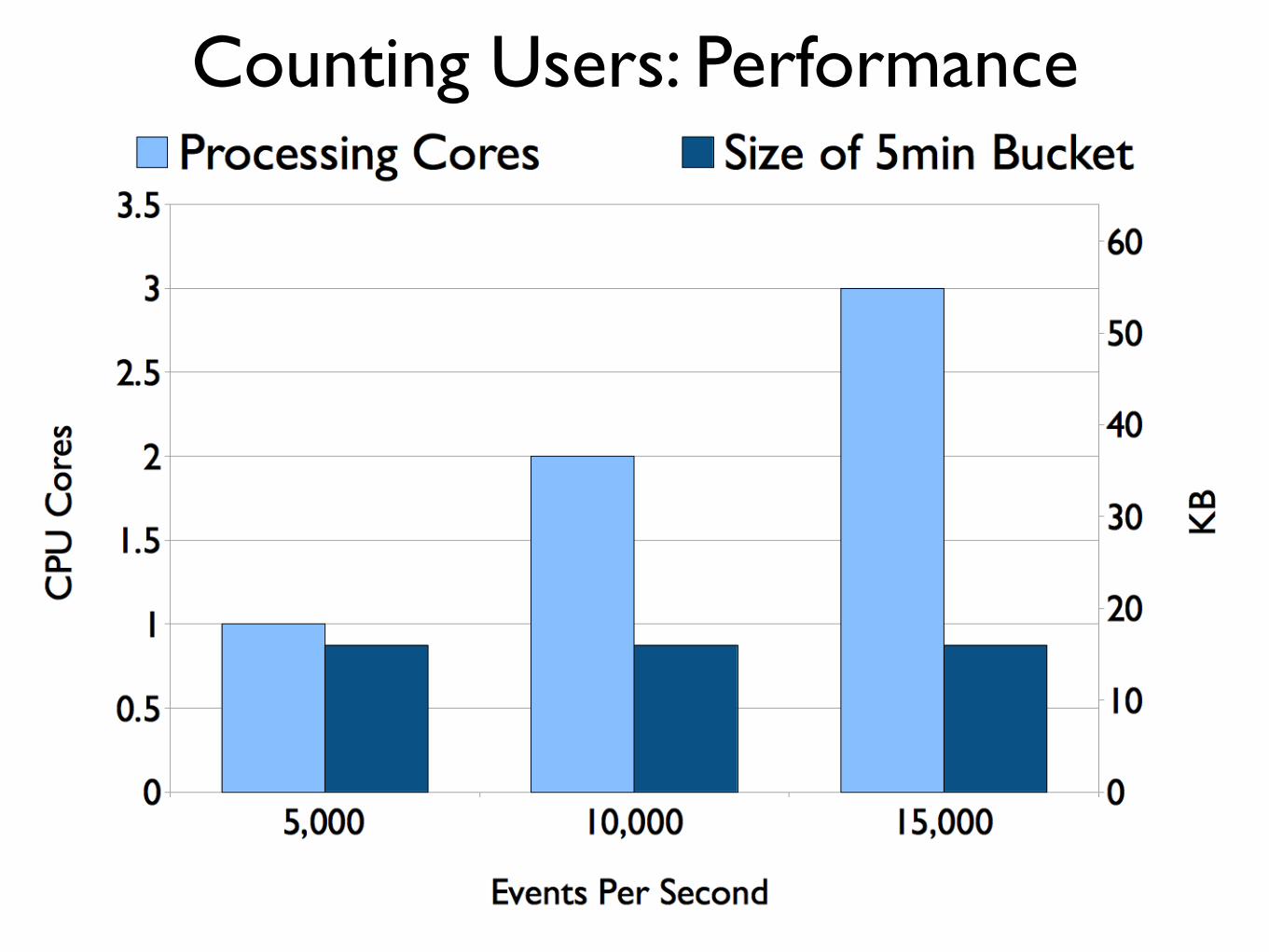
Counting Users: Performance

Counting Users: Result
• Constant storage size usage for one day of data using 14bit HyperLogLogs: 288 * 16KB = 4608KB
• HyperLogLogs count users only once even if data is duplicated or repeated
• Time bucketing ensures delayed data is counted correctly
• Difference of <1% between HyperLogLogs and real count

Counting Revenue: Basics
How To Sum Arbitrary Values

Counting Revenue: BloomFilter
BloomFilter
Capacity = 10kError Rate = 1%Size = 11.7KB
Configurable Size:
addIdentifier(value: String)
merge(other: BloomFilter): BloomFilter
zero(): BloomFilter
contains(): Boolean
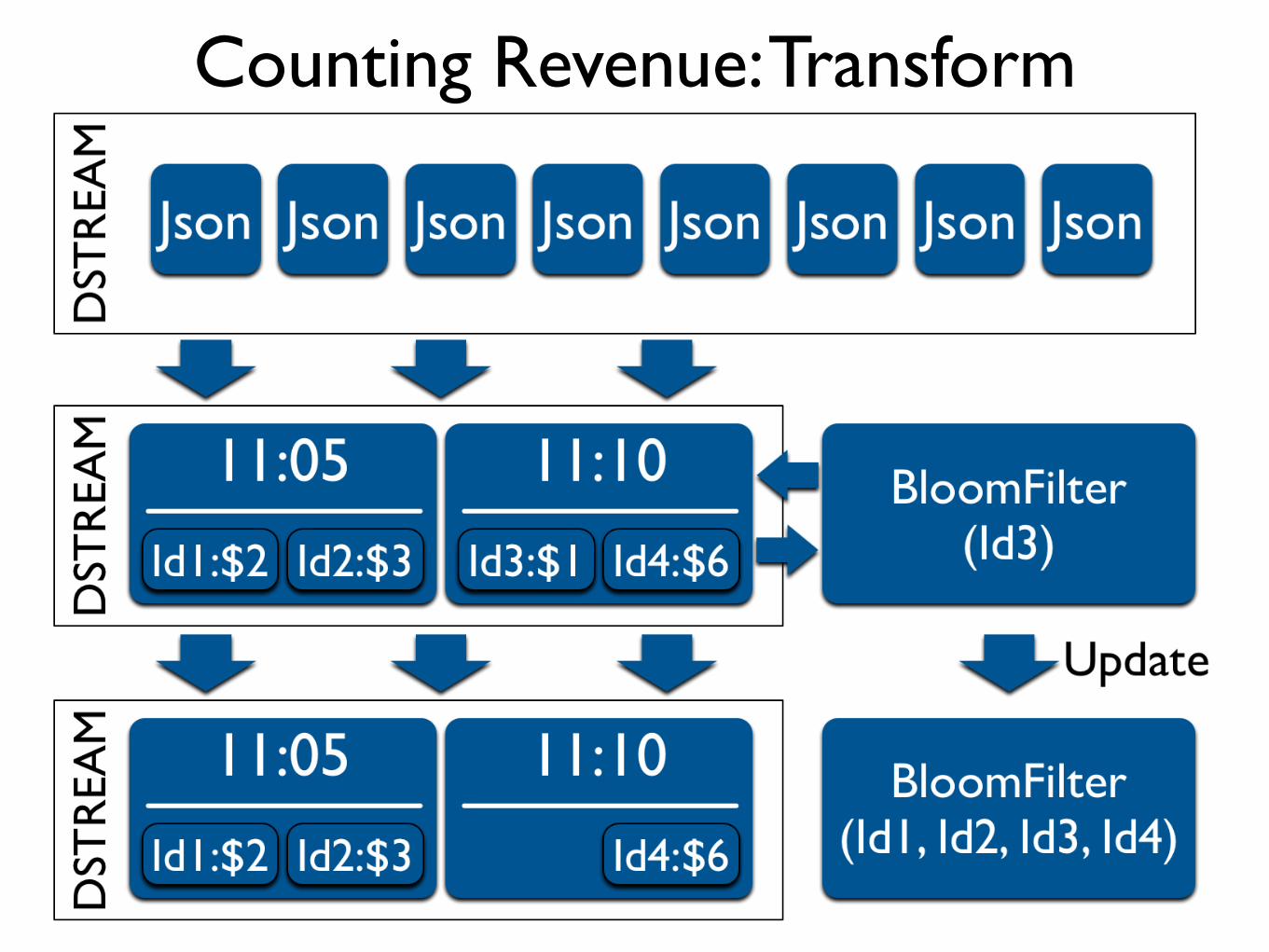
Counting Revenue: Transform
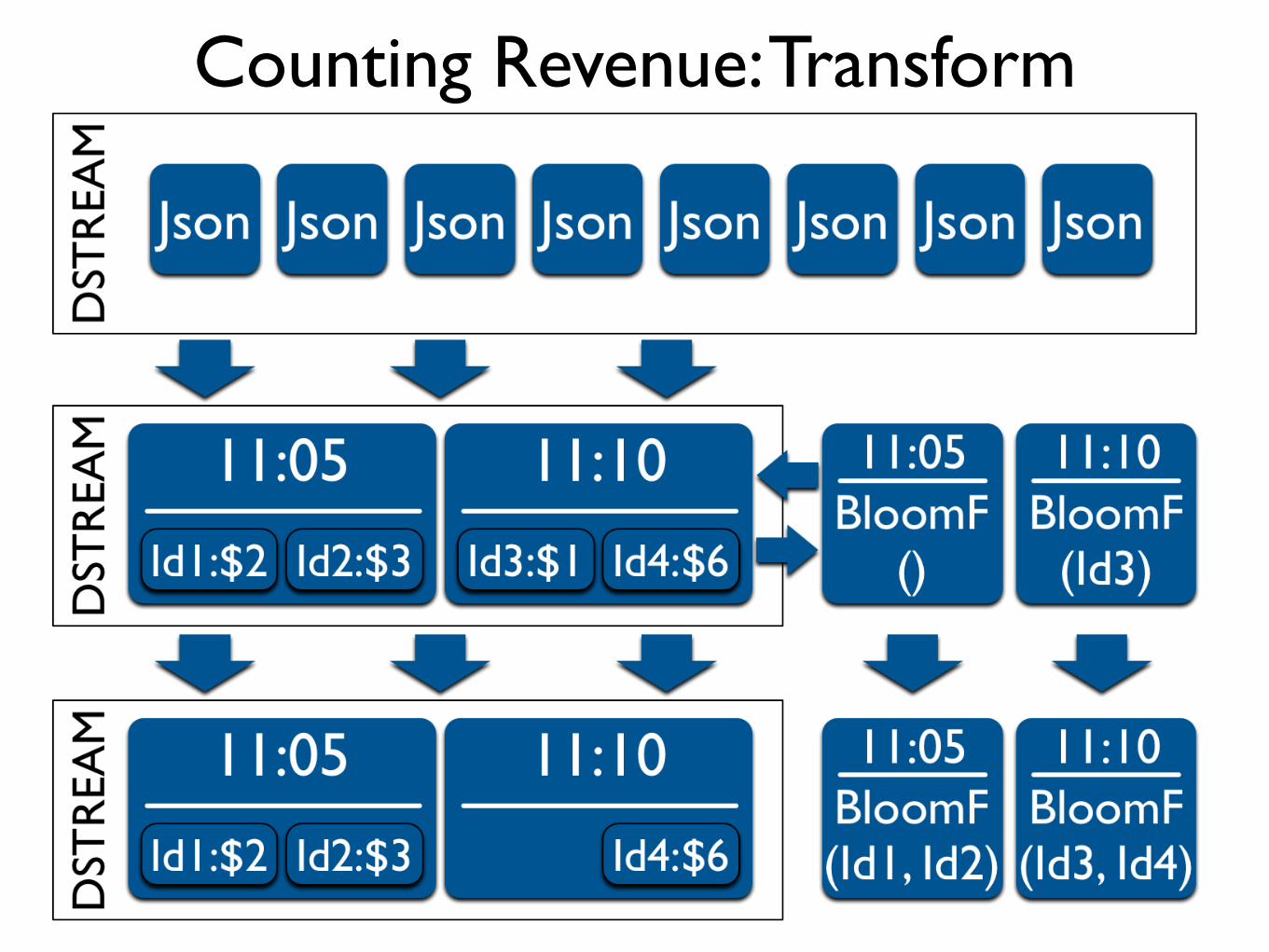
Counting Revenue: Transform
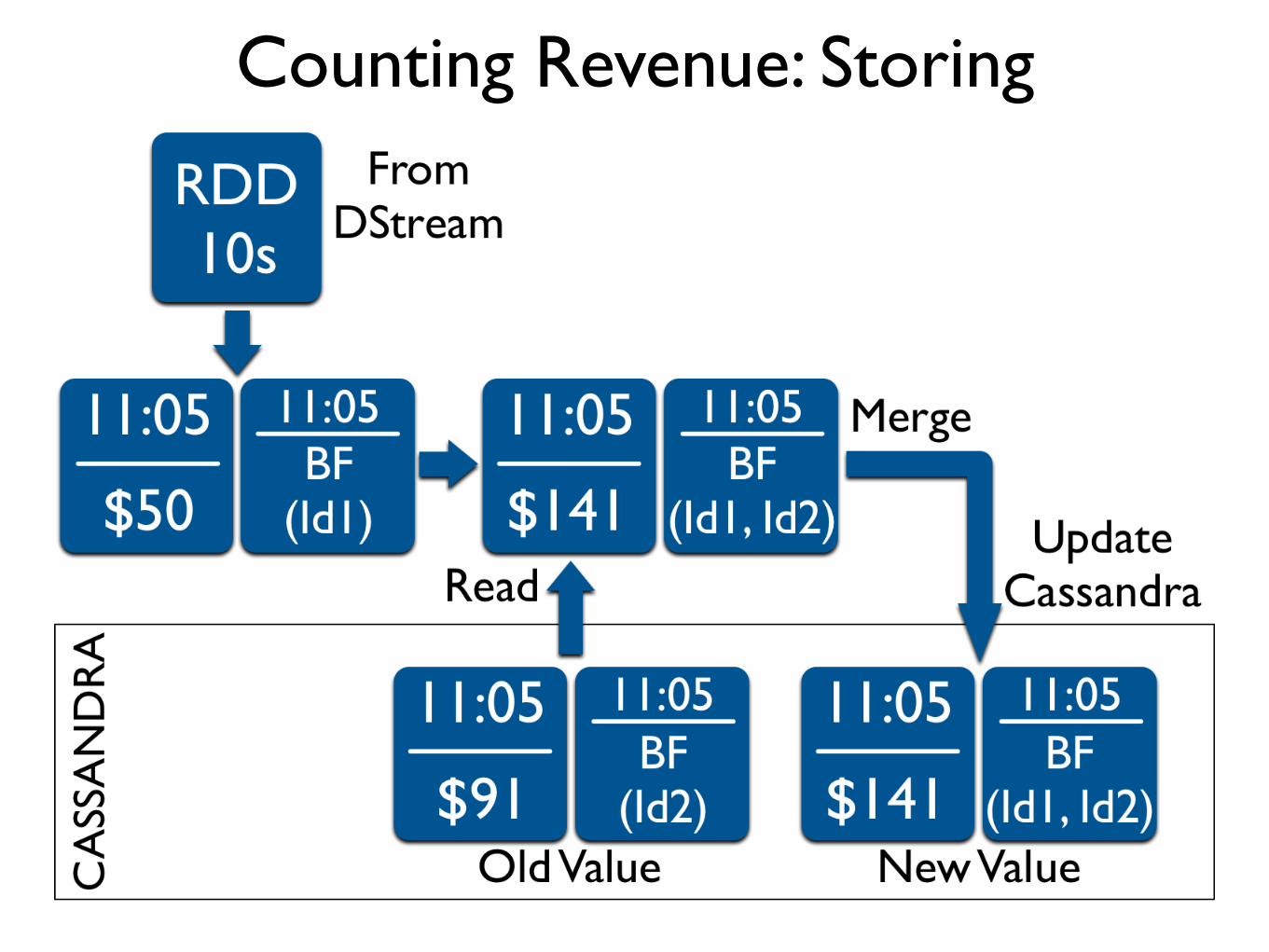
Counting Revenue: Storing

Counting Revenue: Some Scala
https://github.com/lvicentesanchez/fast-gt-perfect
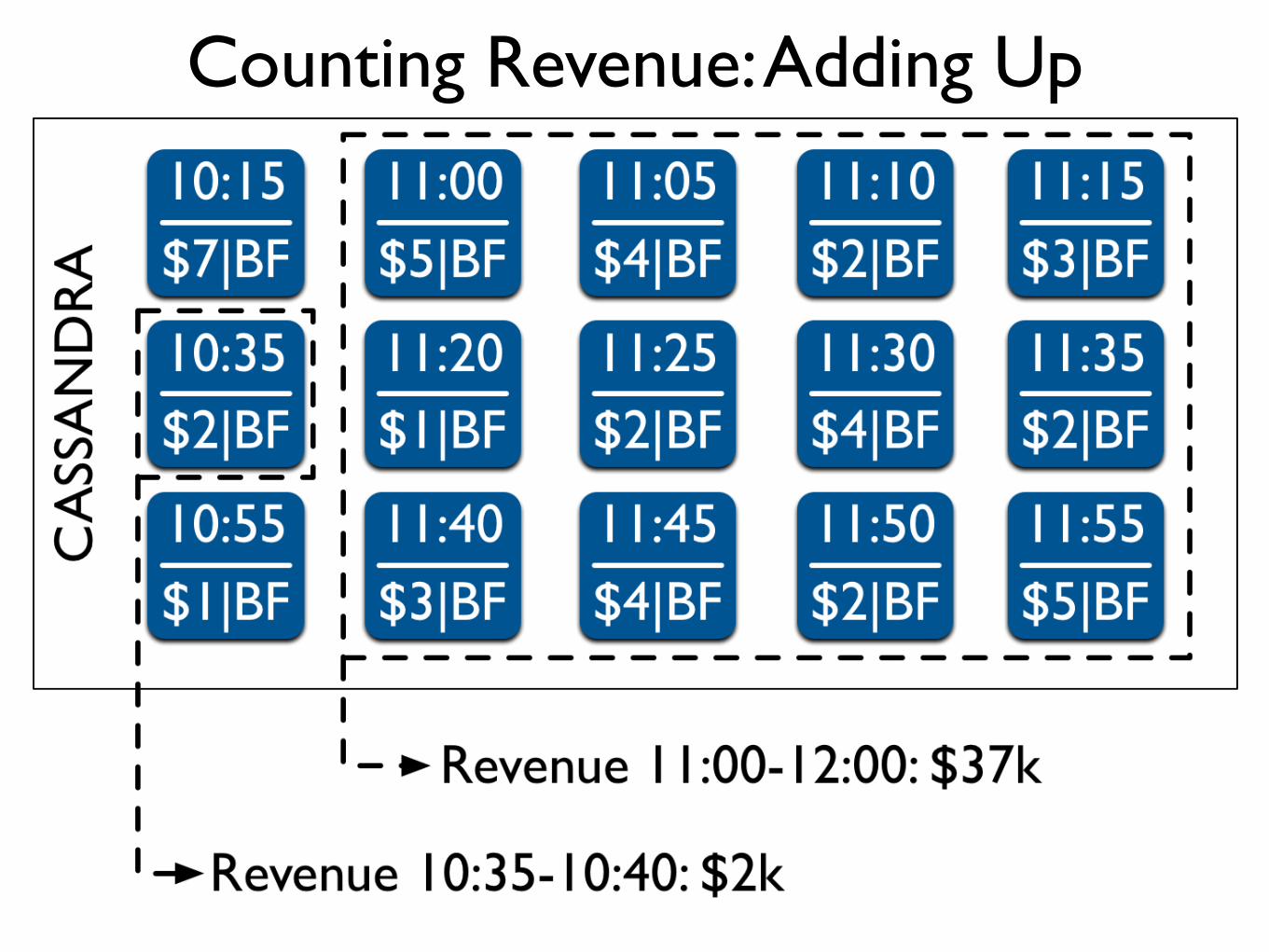
Counting Revenue: Adding Up

Counting Revenue: Result
• Constant storage size usage for one day of data using a 10k BloomFilter: 288 * 11.7KB = 3370KB
• BloomFilter eliminates sales already counted
• Time bucketing ensures delayed data is counted correctly and keeps BloomFilters small
• Difference of <1% between approximated and real revenue

Trending: Basics
How To Find the Top K

Trending: StreamSummary
StreamSummary
Configurable Size:
addIdentifier(value: String)
merge(other: SS): SS
topK(k: Int): Seq[(String, Long)]Capacity = 400Max Size = 21.9KB
Metwally, Agrawal & Abbadi: Efficient Computation of Frequent and Top-k Elements in Data Streams (2005)
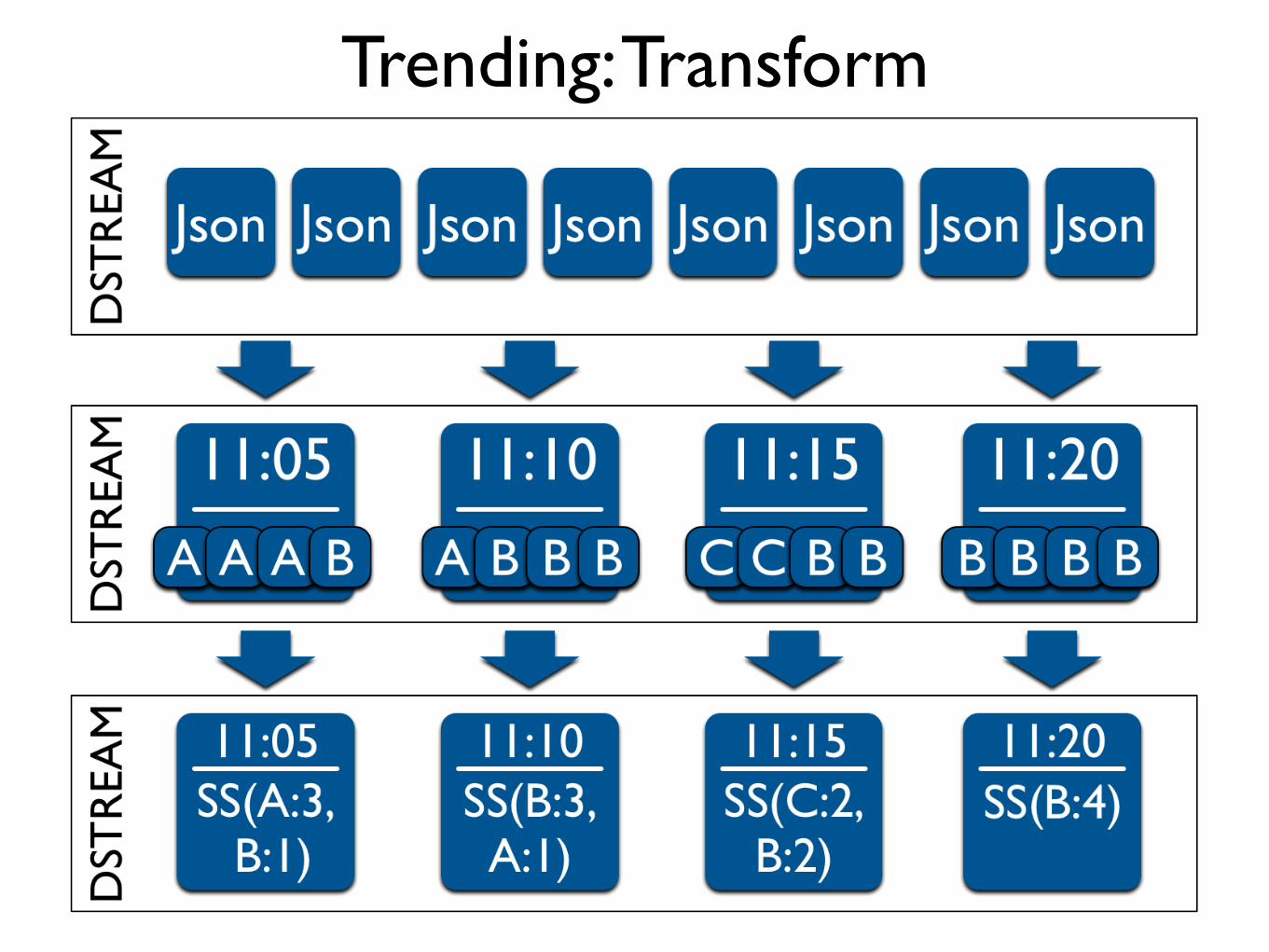
Trending: Transform

Trending: Storing

Trending: Adding Up

Trending: Result
• Constant storage size usage for one day of data using a Top400 StreamSummary: 288 * 21.9KB = 6307KB
• StreamSummary will not eliminate duplicates
• Time bucketing ensures delayed data is counted correctly
• Difference of <2% between StreamSummary trending items and the real trending items

Questions?
Kevin Schmidt@kevinschmidtbiz
Luis Vicente@lvicentesanchez
https://github.com/lvicentesanchez/fast-gt-perfect





![[Spark meetup] Spark Streaming Overview](https://img.pdfslide.net/doc/110x75/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)






















