Embed Size (px)
Citation preview


The human intellect is like peacock feathers, just an extravagant display intended to attract a mate. Oh we think we are so great ..aha.. but a peacock can barely fly and eats insects.
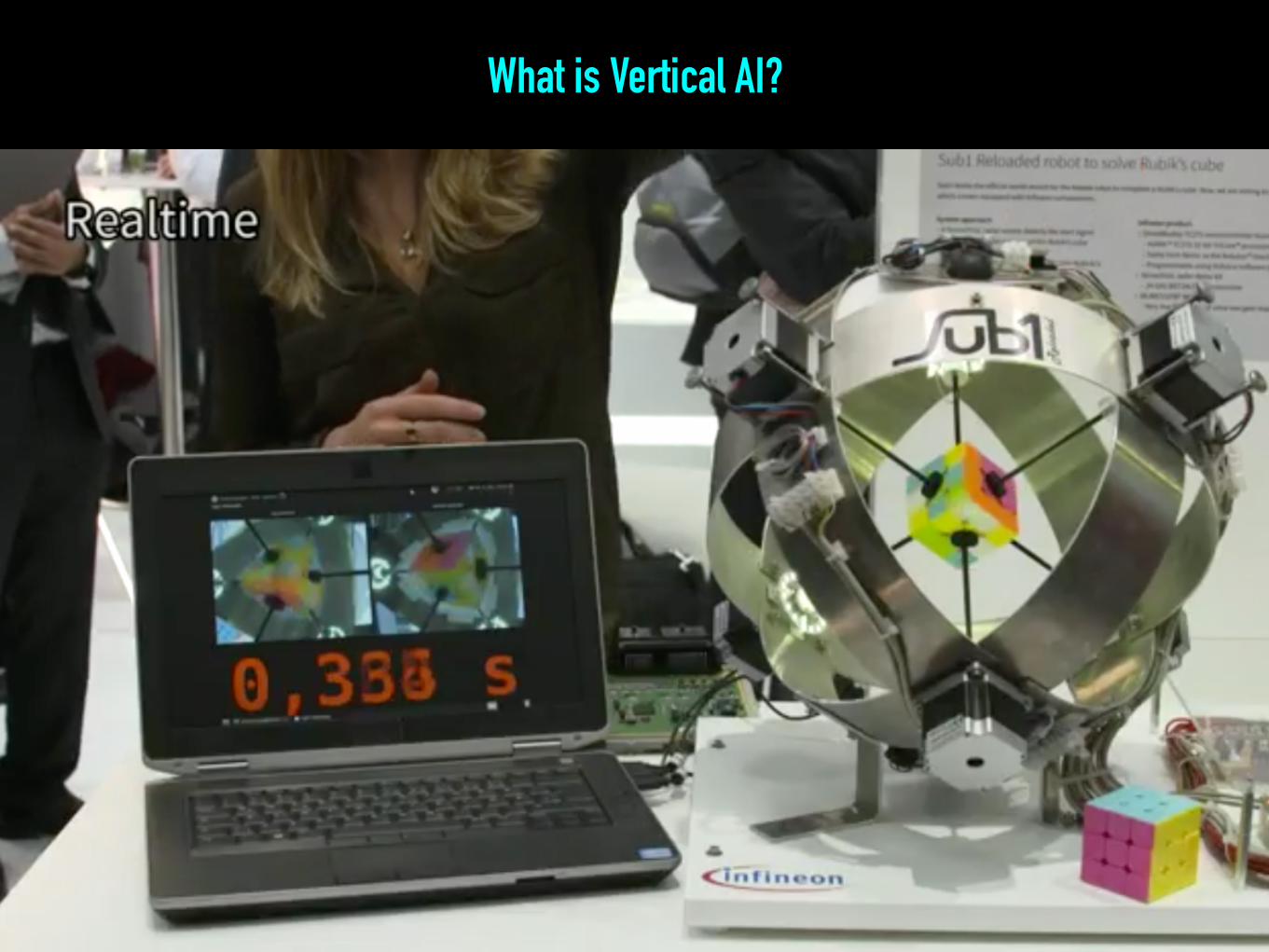
What is Vertical AI?



The Big Nine have open-sourced their toolkits for horizontal AI
Company Product
DLKIT
CNTK
DSSTNE


Citizen doctors

We now have supercomputers with thousands of cores (GPUs)3584*4=14,336 CUDA cores , $1/core


sentence = """This is what I have to you ..DL approach to NLP.""" tokens = nltk.word_tokenize(sentence)tagged = nltk.pos_tag(tokens)entities = nltk.chunk.ne_chunk(tagged)from nltk.corpus import treebank t = treebank.parsed_sents('wsj_0001.mrg')[0]t.draw()as alternative ... vocabulary_size = 8000 unknown_token = "UNKNOWN_TOKEN" sentence_start_token = "SENTENCE_START" sentence_end_token = "SENTENCE_END"# Read the data and append SENTENCE_START and SENTENCE_END tokensprint "Reading my CV file..."with open('CV-EN_v0.6.csv', 'rb') as f:reader = csv.reader(f, skipinitialspace=True)reader.next() # Split full comments into sentencessentences = itertools.chain(*[nltk.sent_tokenize(x[0].decode('utf-8').lower()) for x in reader])# Append SENTENCE_START and SENTENCE_ENDsentences = ["%s %s %s" % (sentence_start_token, x, sentence_end_token) for x in sentences] print "Parsed %d sentences." % (len(sentences)) # Tokenize the sentences into wordstokenized_sentences = [nltk.word_tokenize(sent) for sent in sentences]# Count the word frequenciesword_freq = nltk.FreqDist(itertools.chain(*tokenized_sentences))print "Found %d unique words tokens." % len(word_freq.items())# Get the most common words and build index_to_word and word_to_index vectorsvocab = word_freq.most_common(vocabulary_size-1)index_to_word = [x[0] for x in vocab]index_to_word.append(unknown_token) word_to_index = dict([(w,i) for i,w in enumerate(index_to_word)])print "Using vocabulary size %d." % vocabulary_sizeprint "The least frequent word in our vocabulary is '%s' and appeared %d times." % (vocab[-1][0], vocab[-1][1]) # Replace all words not in our vocabulary with the unknown tokenfor i, sent in enumerate(tokenized_sentences):tokenized_sentences[i] = [w if w in word_to_index else unknown_token for w in sent]print "\nExample sentence: '%s'" % sentences[0]print "\nExample sentence after Pre-processing: '%s'" % tokenized_sentences[0]# Create the training dataX_train = np.asarray([[word_to_index[w] for w in sent[:-1]] for sent in tokenized_sentences])y_train = np.asarray([[word_to_index[w] for w in sent[1:]] for sent in tokenized_sentences])
do i have your attention now?

We are DATAWE ARE CODE

Government is aligned
The Chinese Academy of Sciences has issued invitations to apply for
funding for PMI projects worth
$9.2 bn
NIH is funding PMI projects worth
$215 M
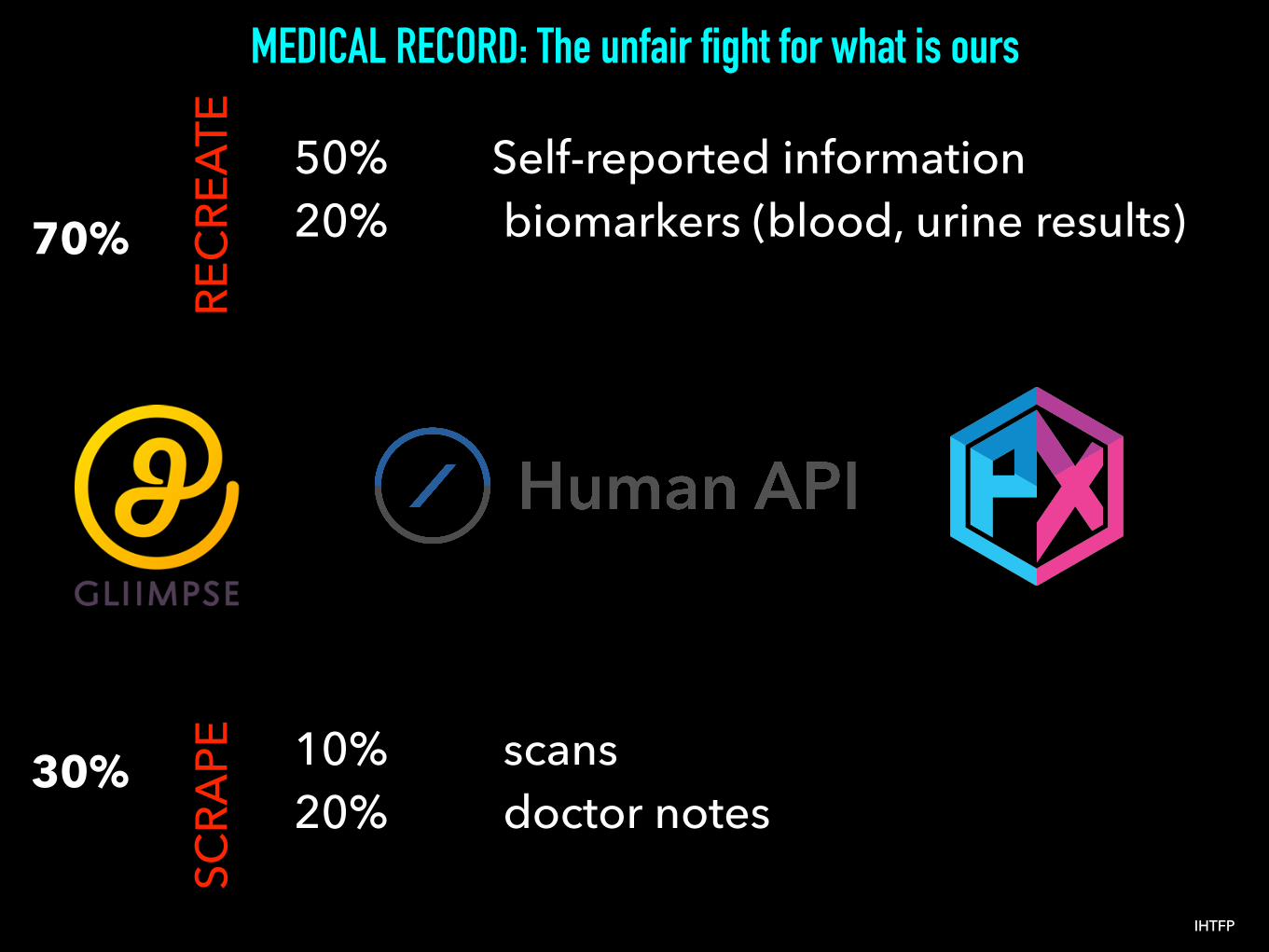
MEDICAL RECORD: The unfair fight for what is ours
IHTFPIHTFP
SCRA
PE50% Self-reported information20% biomarkers (blood, urine results)
10% scans20% doctor notes
REC
REAT
E70%
30%

Everything that does not learn will disappear

DIALOG SYSTEMS in a CLOSED DOMAIN
VA⊃BOT Supervised Learning
Discriminative Models: CRF, RF, NN, SVM SA, state tracker
Logistic regression for intentions (analysis) (CRF) labels + script answers (generation)
4.0 Artificial Intelligence(AI) her
Rule-based Pattern matching
PyAIML
• 3.0 Intelligent Agents (IA) doc
• 2.0 Virtual Assistant (VA) Amy, Clara, Melody
• 1.0 Chatbot (BOT) Mitsuku, Alice, Botlibre, Luka
AI⊇IA Zeno Behavior : 0.9999999..
IA⊇VA

Learning methodologies 1. Unsupervised (clustered patterns, machine generated) 2. Supervised (labels, classification) 3. RL (by experts, pre-release) 4. Memory-based (where concrete cases are used at runtime, so
learning is "just" remembering) 5. Semantic embedding: word2vec 6. “One-shot learning”

Algorithms
‣ clustering (k-NN) ‣ classification (discrete) ‣ regression (continuous) ‣ structural matching to match present circumstance in past
cases (CB) ‣ structural elaboration and substitution (use past examples for context-appropriate generation)

1. faceted (allowing users to explore a collection of information by applying multiple filters)
2. autocomplete 3. multimode 4. Speaker analysis 5. Goal-oriented dialogue 6. Longitudinal representation (Micro-Moments which are intensive-rich)
CONVERSATIONAL SEARCH

Linguistic Authority
1. NLU (bAbi, SemEval) or Winograd Schema = Google-proof PDP
2. MemNN 3. bidirectional CG (RRG, TAG, FCG, HPSG, CCG, DG,
LFG..) 4. OFSM (Optimizing Finite State Machines)

KR/Ontology ‣ LOINC (clinical values) ‣ ICD9, ICD10 (diagnoses) ‣ CPT (medical services) ‣ SNOMED (EHR terms) ‣ RXNORM (medications ‣ MeSH (how to combine structured vocabularies with data-driven
techniques)
Memory ‣ MemNN ‣ app ‣ FSM ‣ Pontifex Maximus
Association mining: Location-aware (Item-item CF recommender using DSSTNE)

IHTFP
RESUME
Name: doc Nationality: AI Age:1.577e+10ms Weight: 28.085(atomic 28.084–28.086) Address: Exxact Spectrum TXR410-0032R Family: NVIDIA DIGITS™ IQ: 14,336 CUDA cores Atomic number: 14 Gender: Si Student: big data medicine University: Enigma.ai Profession: rob0-medstudent Drivers license:4x NVIDIA GTX 1070/1080 Pascal GPUs Character: stochastic Language: python,C++, LUA, English, Mandarin Graduation: 2017 Ambition in life: helping my carbon-based medical colleagues with number crunching and their students (patients) with education Courses: crunching of genomes and phenomes Semantic neurons:LOINC, ICD9, ICD10, CPT, SNOMED, RXNORM Mission: Medical Access 4 all Thesis: n=1 Hobbies: TensorFlow, Torch
You are todayI am tomorrow
CORTEX
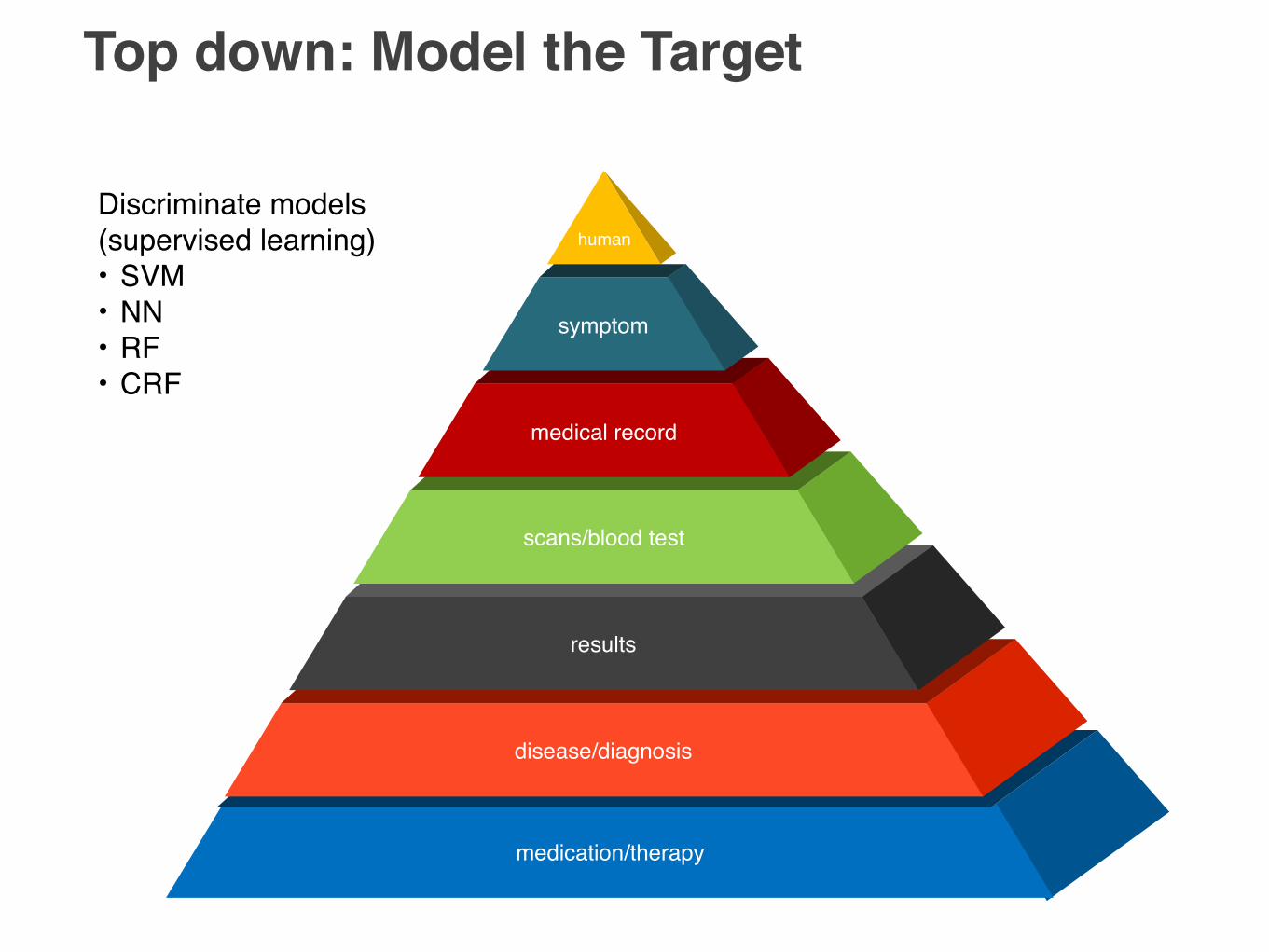
Top down: Model the Target
medication/therapy
disease/diagnosis
results
scans/blood test
human
medical record
symptom
Discriminate models(supervised learning)• SVM• NN• RF• CRF
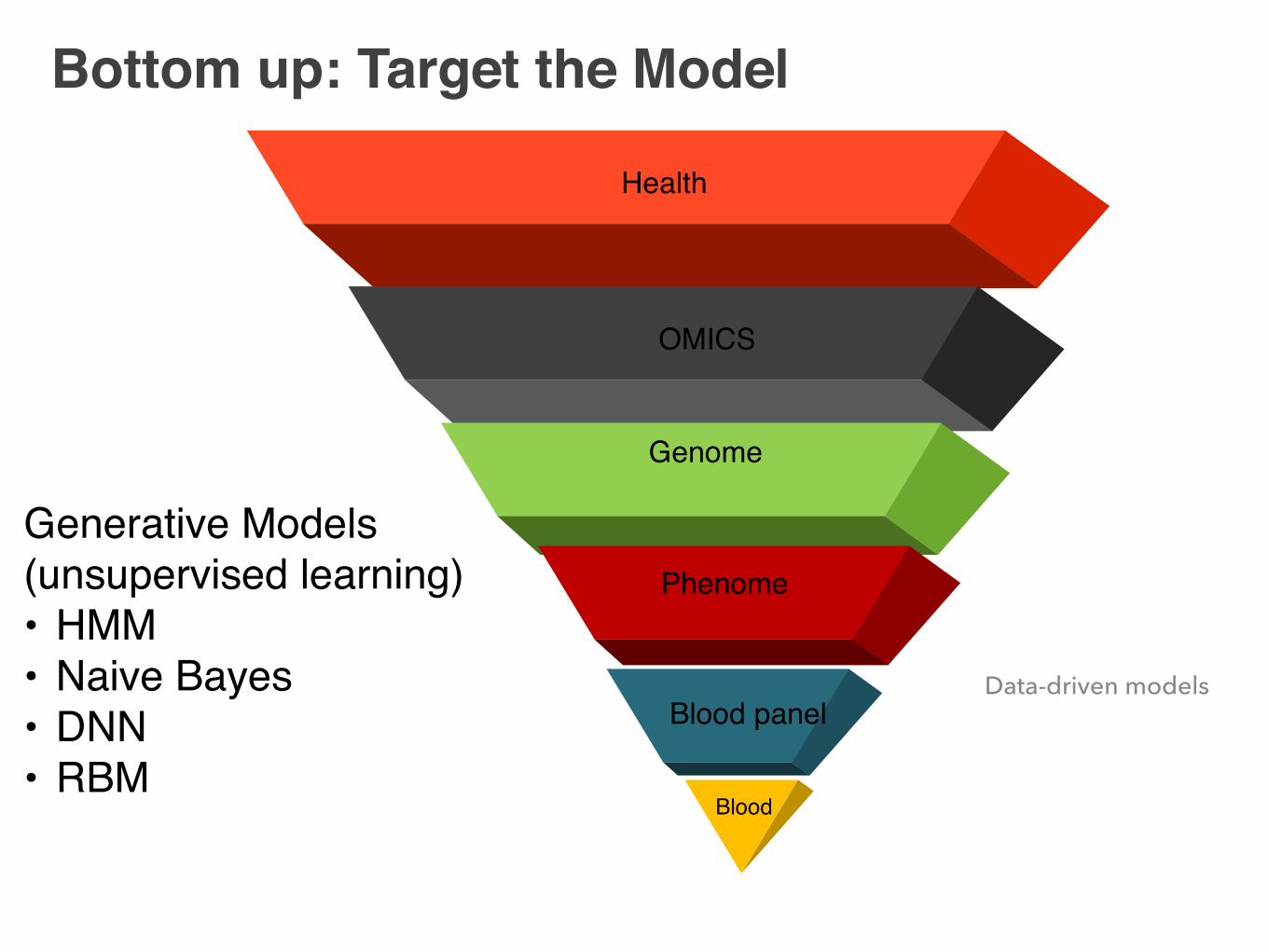
Bottom up: Target the Model
OMICS
Genome
Health
Blood panel
Phenome
Blood
Generative Models(unsupervised learning)• HMM• Naive Bayes• DNN• RBM
Data-driven models
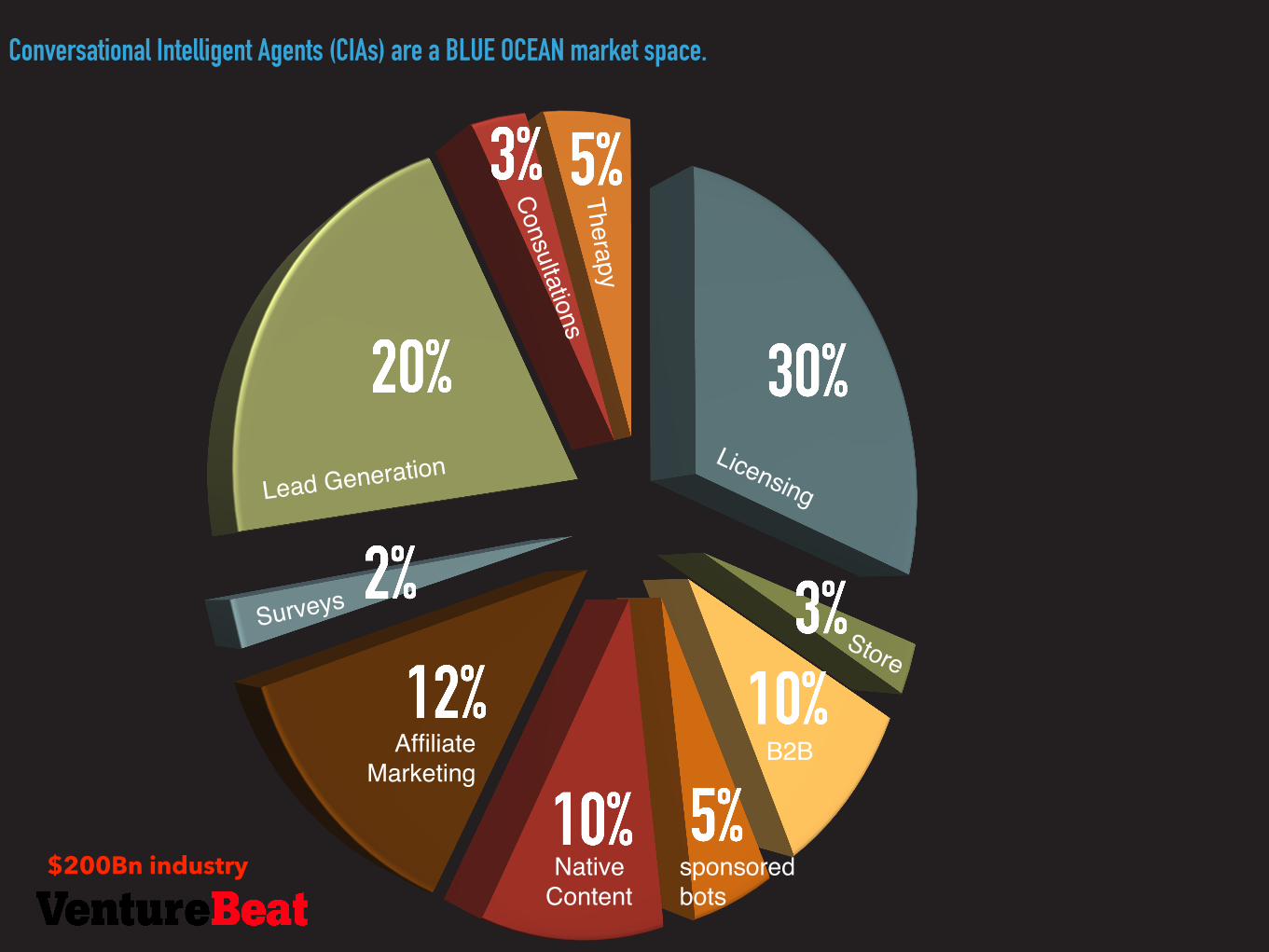
Conversational Intelligent Agents (CIAs) are a BLUE OCEAN market space.
LicensingLead Generation
Store
B2B
sponsored bots
Native Content
Affiliate Marketing
Surveys
ConsultationsTherapy
$200Bn industry
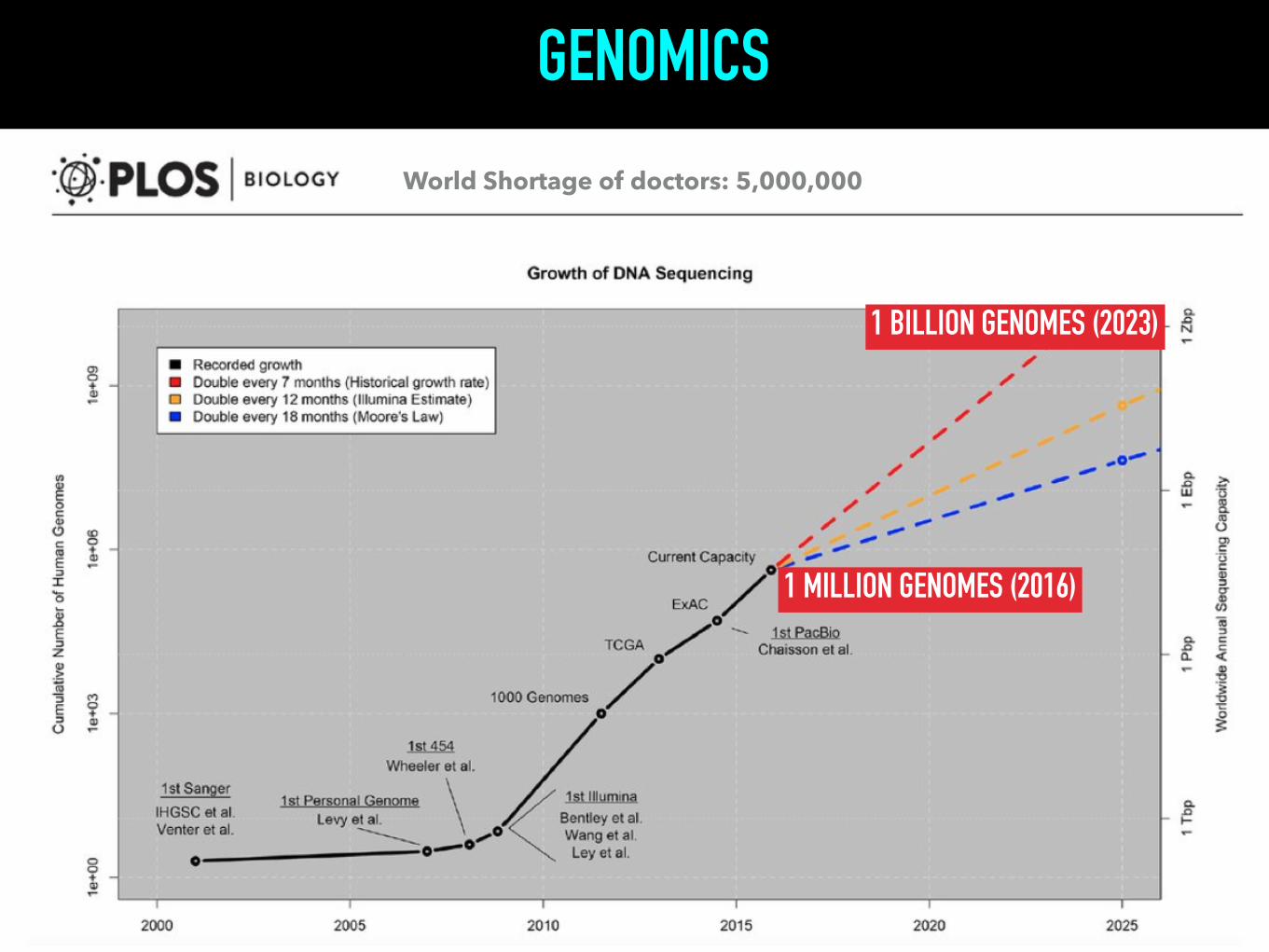
GENOMICS
1 MILLION GENOMES (2016)
1 BILLION GENOMES (2023)
World Shortage of doctors: 5,000,000

CRISPR will boost Personal Genomics

Data becomes a revenue stream
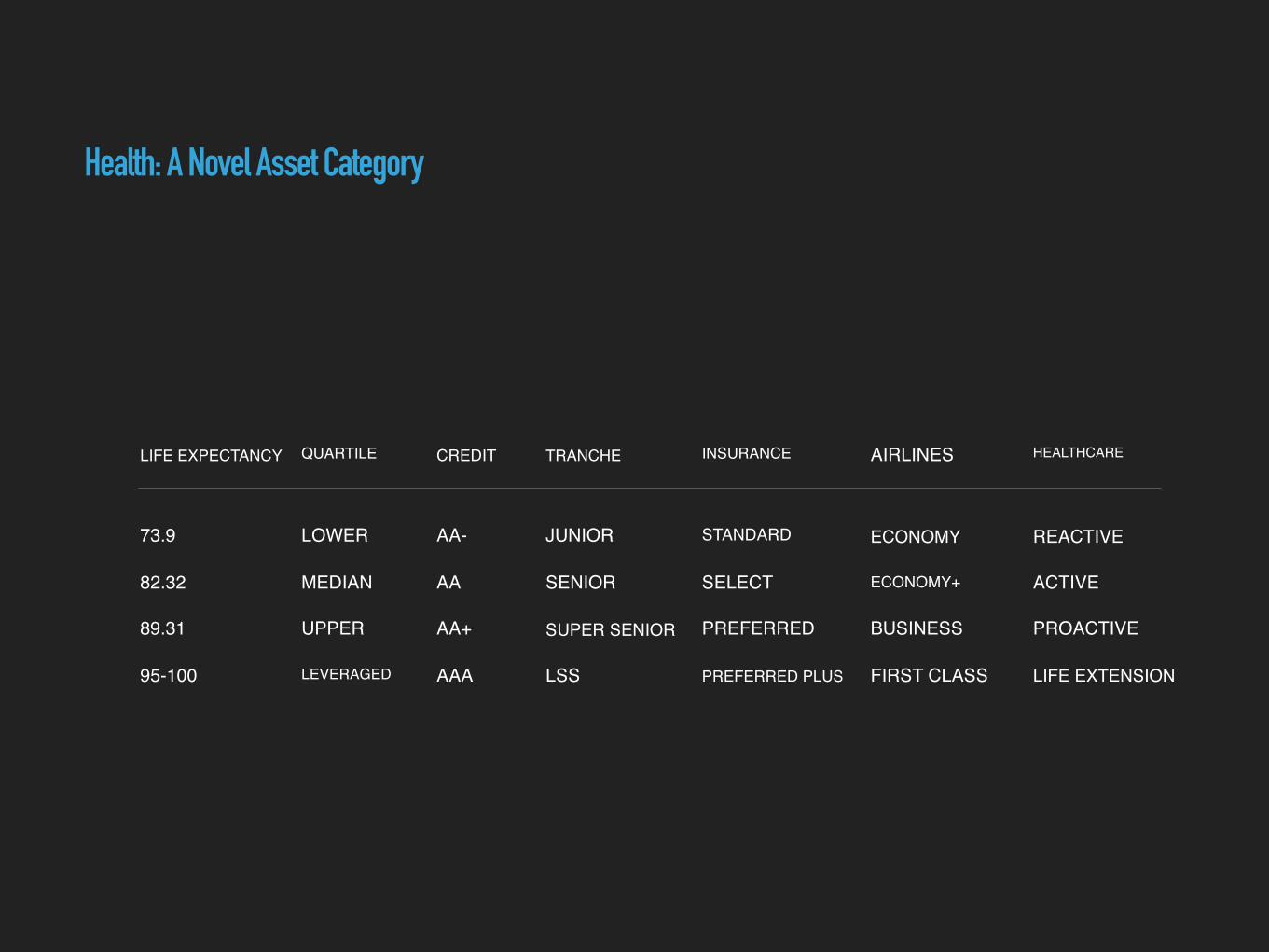
Health: A Novel Asset Category
LIFE EXPECTANCY QUARTILE CREDIT TRANCHE INSURANCE HEALTHCARE
73.9
82.32
89.31
95-100
LOWER
MEDIAN
UPPER
LEVERAGED
AA-
AA
AA+
AAA
JUNIOR
SENIOR
SUPER SENIOR
LSS
STANDARD
SELECT
PREFERRED
PREFERRED PLUS
REACTIVE
ACTIVE
PROACTIVE
LIFE EXTENSION
AIRLINES
ECONOMY
ECONOMY+
BUSINESS
FIRST CLASS
∆= 21st C20th
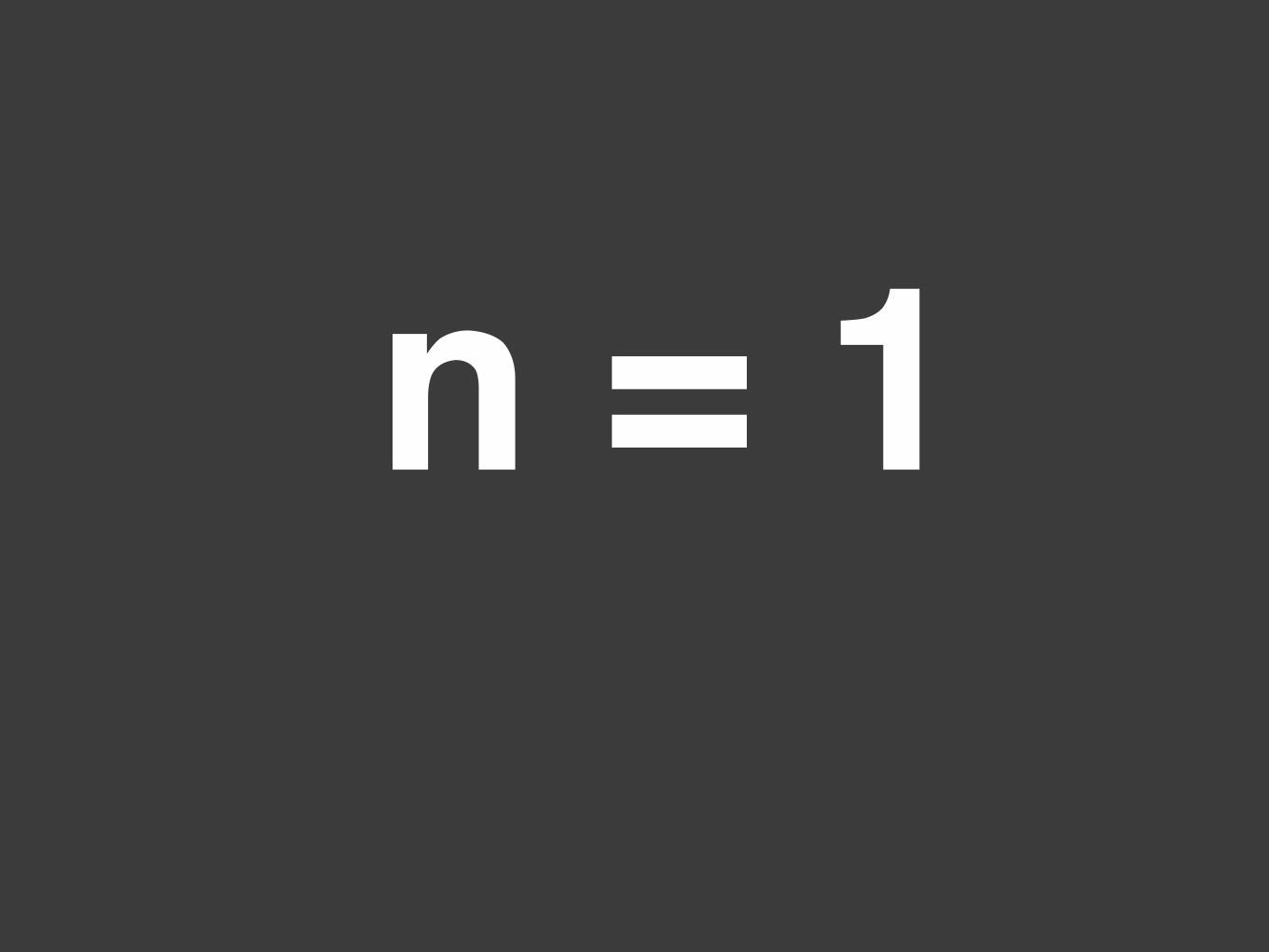
n = 1

21st C20th
N x*

Healthcare will become a continuous function
Discrete function
Continuous function

More is More
.56=0.015625
.512=0.000244140625

@walterdebrouwer
walterdebrouwer
www.doc.ai
walterdb
doc Incorporated 540 Bryant Street Palo Alto, CA 94301






























