Embed Size (px)
Citation preview

Click icon to add clip art
Full scan frenzy at AmadeusUnpredictable & interactive
analysis of terabytes of data
MongoDB World, June 1 2015
Laurent DolléAttila TozserNicolas Motte
265ced1609a17cf1a5979880a2ad364653895ae8

Amadeustoday
1
265ced1609a17cf1a5979880a2ad364653895ae8

AmadeusIn a few words
Amadeus is a technology company dedicated to the
global travel industry.
We are present in 195 countries with a worldwide team of more than 11,000 people.
Our solutions help improve the
business performance of travel agencies, corporations, airlines,
airports, hotels, railways and more.
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

ConnectingThe travel industry
Cruiselines
Hotels
Car rental
Ground handlers
Ferry operators
Ground transportation
Airports
Travel agencies
Insurance companies
Airlines
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

SupportingThe traveler life cycle
Post-trip
On trip
Pre-trip Buy/Purchase
Search
Inspire
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

RobustGlobal operations
We designed & own our Data Processing Centres_ Central DC @ Erding, Germany
_ Remote DCs all over the globe
_ Recovery DC on standby in case of natural disasters
1.6+billiontransactions processed per day
526+milliontravel agency bookingsprocessed in 2014
695+millionPassengers Boardedin 2014
95%of the world’s scheduled networkairline seats
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

CloseTo our customers
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Our commitmentTo innovation
_ Amadeus has invested €3.5bn in Research & Development since 2004.
_ Nominated within “top 3” software companies in 2014 European Union Industrial R&D Investment Scorecard.
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

AmadeusRevenue Accounting Search
2
265ced1609a17cf1a5979880a2ad364653895ae8

Revenue of a flight ticketis shared
_ Travel agent
_ Governments
_ Airlines: many can be involved
(marketing & operating)
What for?
Passenger Revenue Accounting
AmadeusRevenue Accountinghandles cash flowson behalf of airlines
_ Tracking
_ Error handling & optimisation_ Reporting: analysis & audit
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

One of our launch partners is a
large European airline
_ transporting 35m+ passengers a year
_ key player in therevenue accounting industry
Business needsGathered from a Revenue Accounting launch partner
They requested a user-friendly way to query any datain our main operational database
_ Unpredictable ad-hoc search
_ Many advanced reporting requirements
Migrating_ from their
in-house data warehouse
_ to ourcloud-based solution
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

_ Graphicaluser interface
_ based on the SQL paradigm_ to edit, import, save & share
queries
Revenue Accounting SearchThe main promises
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

_ Data warehousefed in real time4 years history (1.5bn documents, versioned)
_ Interactive response times
Revenue Accounting SearchThe main promises
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Expecting fast answerto unpredictable queries
No index, no hint (almost)
_ Fields to be scanned unknown_ In-memory full scans to decrease response time
Need to use all the available hardware power & scale out for sustainable performances
Support mainstream SQL DML statements_ Aggregation_ Cross-column comparison, Boolean logic_ Sort ©
20
15 A
mad
eu
s IT
Gro
up
SA

Technicalarchitecture
3
265ced1609a17cf1a5979880a2ad364653895ae8

6 physical data servers_ Server
HP ProLiant DL580 Gen84 sockets, x86, rack
_ 4x CPUIntel Xeon E7-4850 v22.30 GHz, 12 physical cores
_ RAM 512GB40GB/s scanning speed
_ 2x flash cardsFusion-io ioScale 3.2TB1.5GB/s read
3 virtual config servers_ RAM 8GB
Production cluster setupFacts & figures
Overall cluster
_ 288 cores, 3TB RAM, 38.4TB flash card storage
Currently 1 year of production data (4 expected)
_ 310m+ docs (1bn)
_ Data size 3,6TB (11TB)
_ Average object size 12,5KB
_ File size 4.8TB (16TB)
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

We have many cores, but only 6 boxes, if we would follow all the recommendations that would end up in:
Microsharding coming from Microservices?
Enforce parallel processing
A MongoDB daemon (mongod) processes
each incoming query on a single thread._ It is not recommended to:• Collocate many mongod processes on a single
box
Our online analytical processing use-case implies:
_ full scans (ad-hoc queries)
_ limited concurrency for queries (requests are from a queue)
SHARD1
Node 1 Node 2 Node 4 Node 5 Node 6Node 3
SecondaryPrimary Secondary Secondary SecondaryPrimary
SHARD2
_ 2 cores running 286 idling_ 2/3 of the memory idling_ 4 flash cards working at
around 6% each and 8 idling
We need to go against some of the recommendations!
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

_ Queries either CPU or memory scanning speed bound_ On a fix amount of shards, the speed scales linearly with the data size
Benchmarking
0 200 400 600 800 1000 12000
2
4
6
8
10
12
Full scan
data size
tim
e
0 200 400 600 800 1000 12000
100
200
300
400
500
Full scan with aggregation
data size
tim
e
Behaviour reproduced for 2 shard distributions24 & 48 shards on 6 physical servers, 100% in-memory
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Microsharding coming from Microservices?
Enforce parallel processing
Problem Reason Solution
2 cores running286 idling
2 primaries processing the requests
We need more primaries processing the requests(to use all the 288 CPUs)
2/3 of the memoryidling
Primaries only on 2 nodes We need to run primarieson all the available nodes
4 flash cards workingat around 6% eachand 8 idling
Only 2 threads used,on 2 nodes
We need many threads working on the cards (ideally 64 per box)
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Validation, from 6 to 48 shards on 6 physical serversfor 2 selected fairly complex queries
The behavior is logarithmic as the assigned proportion of the data per shard changes
0 10 20 30 40 50 600
50
100
150
200
250
300
350
400Full scan
shards
tim
e
0 10 20 30 40 50 600
200400600800
10001200140016001800
Full scan with aggregation
shardstim
e
MicroshardingMeasure the benefit
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

arb
Microsharding (how to align the services ?)
265ced1609a17cf1a5979880a2ad364653895ae8
Node 1
PrimarySecondaryArbiter
Shard, replicate & stripe
Node 2 Node 3 Node 4 Node 5 Node 6
1st 2nd
1st 2nd
1st 2nd
1st 2nd
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
1st
2nd
1st
1starb
arb
arb
arb
© 2
01
5 A
mad
eu
s IT
Gro
up
SA
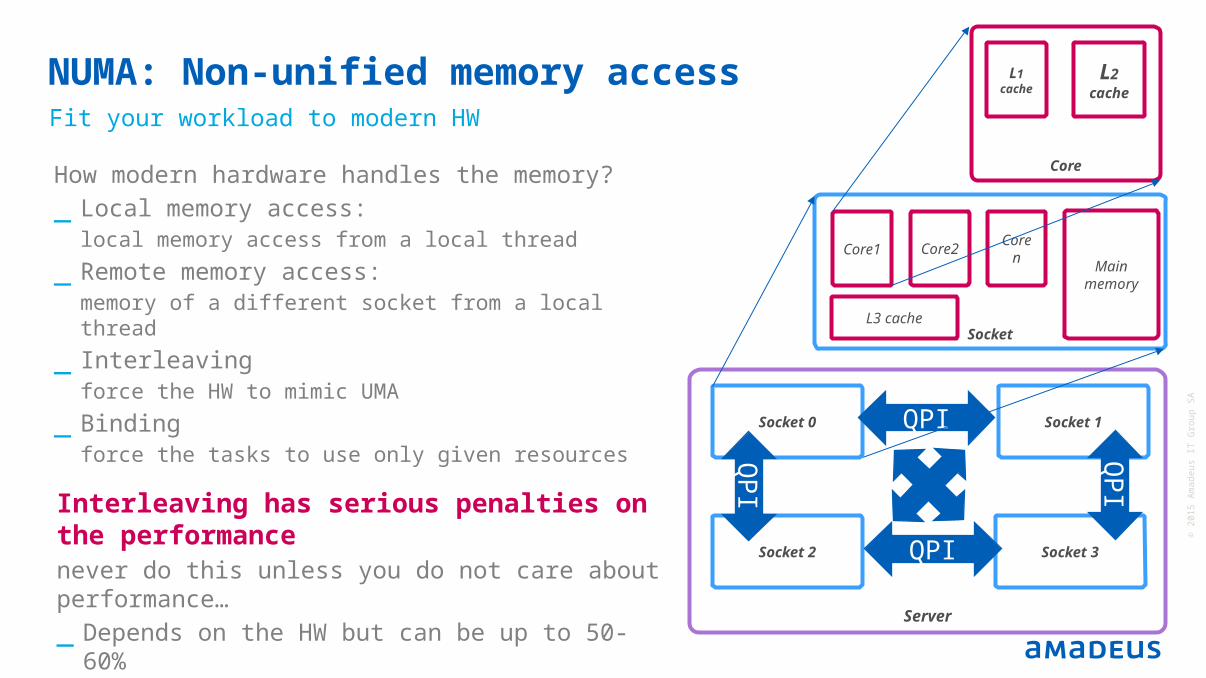
Interleaving has serious penalties on the performance never do this unless you do not care about performance…_ Depends on the HW but can be up to 50-60%
NUMA: Non-unified memory accessFit your workload to modern HW
How modern hardware handles the memory?_ Local memory access:
local memory access from a local thread
_ Remote memory access:memory of a different socket from a local thread
_ Interleaving force the HW to mimic UMA
_ Bindingforce the tasks to use only given resources
Socket
Server
Core
L1 cache
L2 cache
Core1
Core2
Coren
Main memory
L3 cache
Socket 2
Socket 1Socket 0
Socket 3
QPI
QPI
QPI
QPI
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

NUMA: Non-unified memory accessThe recommendation is to interleave, but:
Use node & memory binding!numactl --physcpubind xx --localalloc mongod –f …
0.00
049
0.00
293
0.00
781
0.02
344
0.06
25
0.18
75 0.5
1.5 4 12 32 96 25
61
10
100
1000
MEMORY LATENCY
Dataset Size / MB
Late
ncy
/ n
s
1 DIMM Per Channel
2 DIMM Per Channel
3 DIMM Per Channel
186,943
229,000
191,303
49,37861,919
43,124
Memory Bandwith (STREAM Triad)
NUMA UMA
Bandw
idth
MB
/s
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Tuning for better CPU utilization
Can be achieved with couple of small changes using sysctl:kernel.sched_min_granularity_ns set 2-10 times bigger kernel.sched_migration_cost set 2-10 times biggerTipp: Look for guidelines from your HW vendor, how to tune your BIOS settings for latency
Kernel tuningHow Linux schedules the CPU workload
IO-intensive workload scheduling_ Default in Linux_ Small slices on the cores_ Often migrations between cores
CPU-intensive workload scheduling (MongoDB)_ Needs tuning/experimenting_ Longer slices on the cores_ Rare migrations between cores
Use /proc/sched_debug or Intel PCM or any similar tool to find the optimal settings:
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

CgroupsLight weight resource management
Mongod processes running on the same hardware compete for resources_ Memory
One big pool competition for free pages
_ CPU• Aggregation is really CPU intensive in
our case• Often context switching
Above a certain size of memory we had serious issues
Resource management for the services_ Memory
Fine grained memory allocation limits
_ CPUsetCPU binding like in NUMA
_ CPUResource sharing between tasks (restrict some resources for the operation system)
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

CgroupsTiered storage concept with resource management
_ MongoDB uses mmap to cache data in memory (<3.0)• No good influence on the caching • Due to LRU works as a FIFO queue in
this case
_ Example:• 1., We have 200GB data and 100GB
memory• Or
• 2., 200GB data and 1GB memory• The scanning speed is the same
_ With cgroups the first case could be 40-50% faster.
Query 2 : progress at 70%
Query 2 : progress at 0%
Query 1 : progress at 100%
In cachePaging GAP
Query 1 : progress at 100%
Query 2 : progress at 20%
In cacheIn cache Paging GAP
Query 1 : progress at 100%
In cache
_ 50% memory 2 subsequent queries_ 100% paged in and out
1
2
3 © 2
01
5 A
mad
eu
s IT
Gro
up
SA

Q 1
_ Using many shards instead of one divides the work to smaller chunks
_ Define a high memory and a low memory cgroup and assign the shards to them
_ 40% served from memory 60% from disk_ The analogy can be applied for many
tiers• Memory -> SSD -> spinning disk
Query 1 : progress at 100%
Q 1 Q 1 Q 1 Q 1
Q 1
Query 1 : progress at 100%
Q 1 Q 1 Q 1 Q 1
In cache In cache
• High memory cgroupAll served from memory
• Low memory cgroupAll served from disk
CgroupsTiered storage concept with resource management
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Microsharding is a powerful way to increase response times, what else can bring value?
Database customizationAnd its results
NUMA
Kerneltuning
Stripedreplica set
Cgroups
CgroupsPrevent shards from competing for memory when data does not fit into RAM – especially with microsharding.Low-memory Cgroups may be compressed with zRAM/WiredTiger.
Kernel tuningOptimize Linux in case of CPU-bound effort (vs. IO-bound):small readahead, THP off, increase task scheduler.
NUMARestrict access to CPU & memory for secondary daemons.
Striped replica setSpan shards on all the available hardware, with secondary daemons replicated on different nodes for smooth failover.
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Productionbenchmarks
4
265ced1609a17cf1a5979880a2ad364653895ae8

Full scan aggregation is CPU-bound,with a fixed entry cost for unwinds._ no unwind 3s_ 1, 2 or 3 unwinds 70s_ additional cost if more unwinds
Interactive response times promise is complied with on basic use-cases.
In the absence of concurrency, response times are consistent across all tests.
Production response timesAnd their lessons learnt
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Operability & Monitoring Tools
5
265ced1609a17cf1a5979880a2ad364653895ae8

Operability & MonitoringTooling Architecture
Software Upgrade
Topology
Operability
Orchestrator
Alerting
Monitoring Data Store
Internal Tools
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

2.3 Puppet Setup
Orchestrator
1. Mount Servers
4. Install OS and NoSQL store
6. Ticket Tracker Setup
7. Tools Validation
8. Dev Validation
9. Handover to Ops
Only for Physical Node
Only for VM
Common for all Data Stores
2.2 Create VM2.1 Network Setup
3. Assign DNS names
System Setup
Application Setup
5. Monitoring Setup
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Monitoring
© 2
01
5 A
mad
eu
s IT
Gro
up
SA
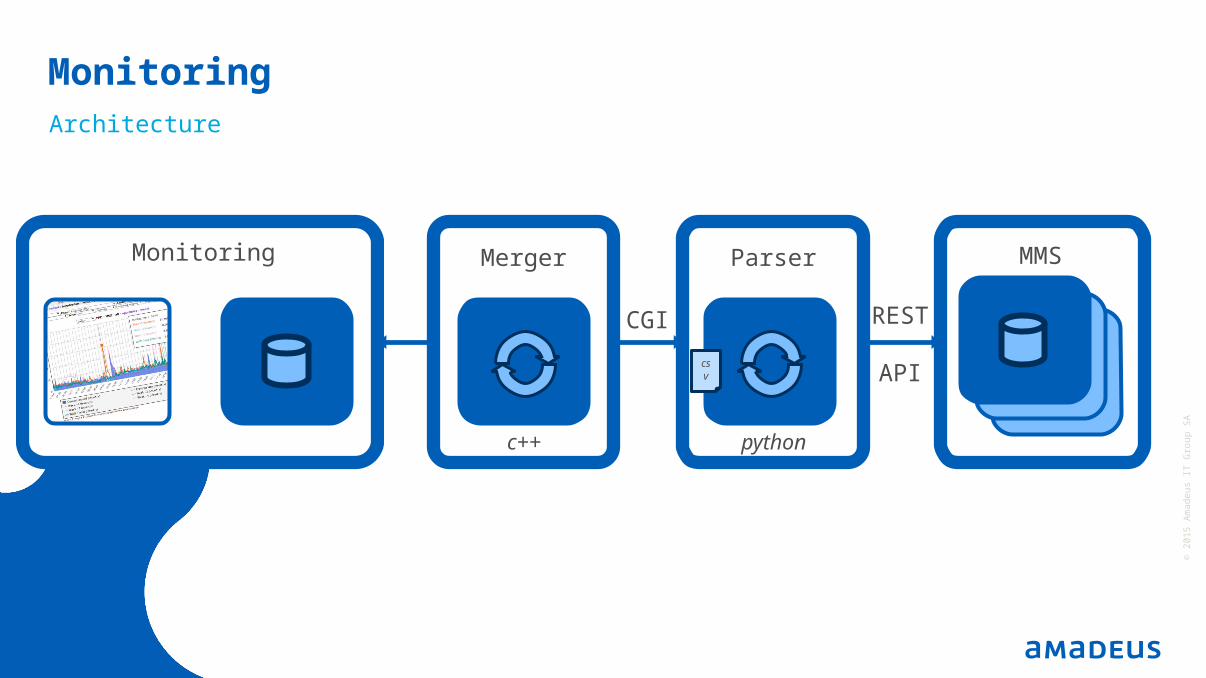
Merger
MMSMMS
MonitoringArchitecture
MMSParserMonitoring
REST
APIcsv
CGI
pythonc++
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

MonitoringDemo
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Alerting
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

AlertingArchitecture
MMSMMS
MMS
REST
API
AlertingTicket Pinger
Configuration
shell
TCP
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

Operability
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

MMS
Operability Server
MMSMMS
OperabilityArchitecture
MMS
Operability
Status
MCollective
ManualAction
MMSMMS
MongoDB
java
python
REST API
Active MQ
SSH SSH
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

OperabilityDemo
© 2
01
5 A
mad
eu
s IT
Gro
up
SA

You can follow us on:AmadeusITGroup
amadeus.com/blogamadeus.com
Thank you
265ced1609a17cf1a5979880a2ad364653895ae8





























