Embed Size (px)
Citation preview

BigQueryクエリの
処理の流れ
Jordan TiganiBigQuery Software Engineer
ゴール:BigQueryクエリの一連の処理手順を追う
注:ここに記されたアーキテクチャの内容や役割は、- すぐ古くなったり- 詳細は端折られてたり- いずれ変更されたり*します
*これがBigQueryの大きなメリットです。見えないところでつねに改善が続けられています

最近のアーキテクチャ改善の例
シャッフルのスループットが4倍にクラスタサイズが5倍にクラスタが追加ディスク保存のフォーマットを変更
(ColumnIOからの置き換え)ディスク保存のエンコード形式を変更
(耐久性の向上、サイズの縮小)
残念ながら、詳細は紹介できません
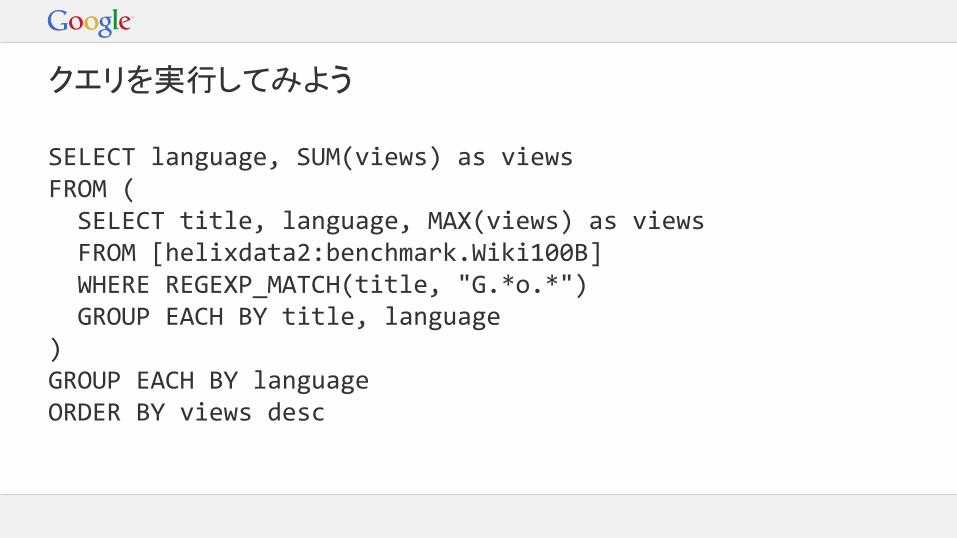
クエリを実行してみよう
SELECT language, SUM(views) as viewsFROM ( SELECT title, language, MAX(views) as views FROM [helixdata2:benchmark.Wiki100B] WHERE REGEXP_MATCH(title, "G.*o.*") GROUP EACH BY title, language)GROUP EACH BY languageORDER BY views desc
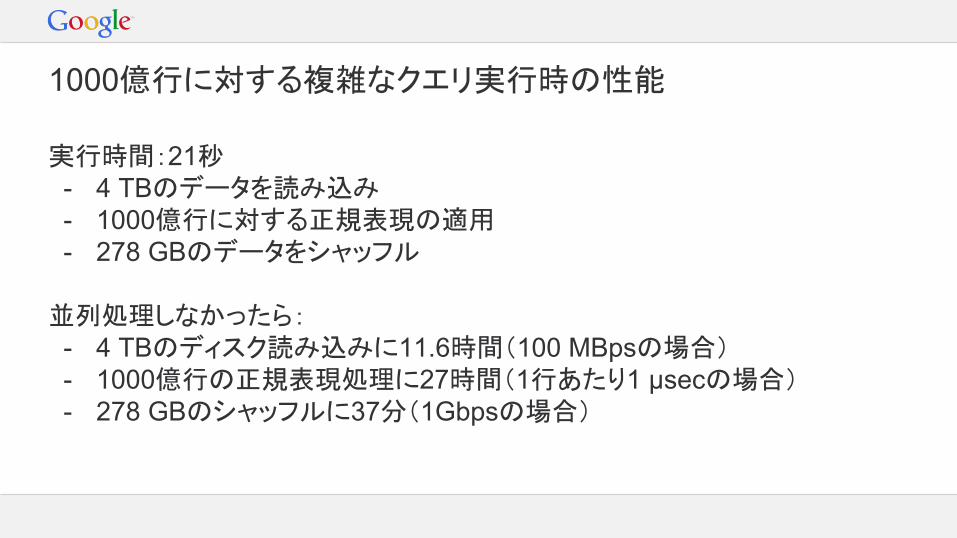
1000億行に対する複雑なクエリ実行時の性能
実行時間:21秒- 4 TBのデータを読み込み- 1000億行に対する正規表現の適用- 278 GBのデータをシャッフル
並列処理しなかったら:- 4 TBのディスク読み込みに11.6時間(100 MBpsの場合)- 1000億行の正規表現処理に27時間(1行あたり1 μsecの場合)- 278 GBのシャッフルに37分(1Gbpsの場合)

curlでクエリを実行する
curl -H "$(python auth.py)" \ -H "Content-Type: application/json" \ -X POST \ -d {'jobReference': { \ 'jobId': 'job_1429217599', \ 'projectId': 'bigquery-e2e'}, \ 'configuration': { \ 'query': { \ 'query': 'SELECT ...’}}} \ "https://www.googleapis.com/bigquery/v2/projects/bigquery-e2e/jobs"
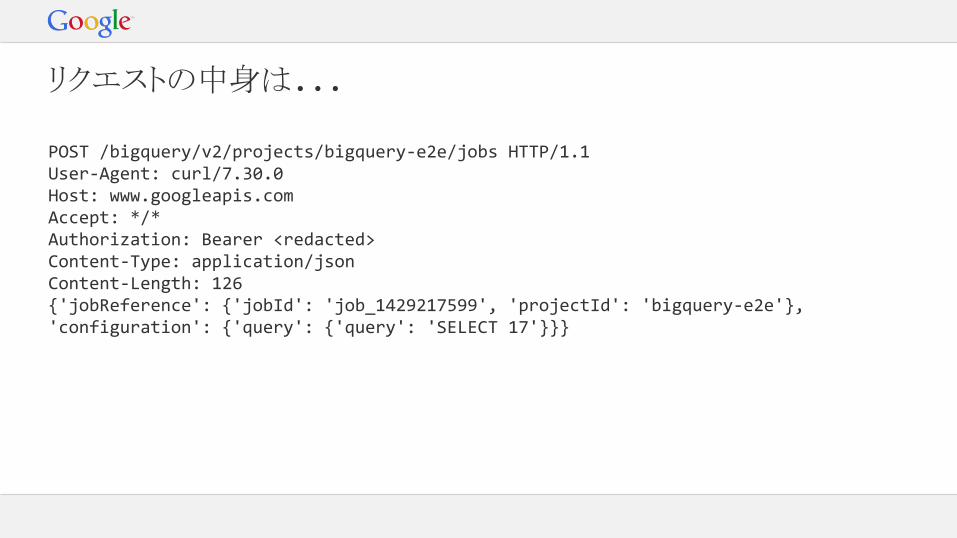
リクエストの中身は...
POST /bigquery/v2/projects/bigquery-e2e/jobs HTTP/1.1User-Agent: curl/7.30.0Host: www.googleapis.comAccept: */*Authorization: Bearer <redacted>Content-Type: application/jsonContent-Length: 126{'jobReference': {'jobId': 'job_1429217599', 'projectId': 'bigquery-e2e'}, 'configuration': {'query': {'query': 'SELECT 17'}}}
ClientHTTP POST
GFEJSON API frontendHTTP
JSONHTTP
BigQuery API Server
protobufgRPC
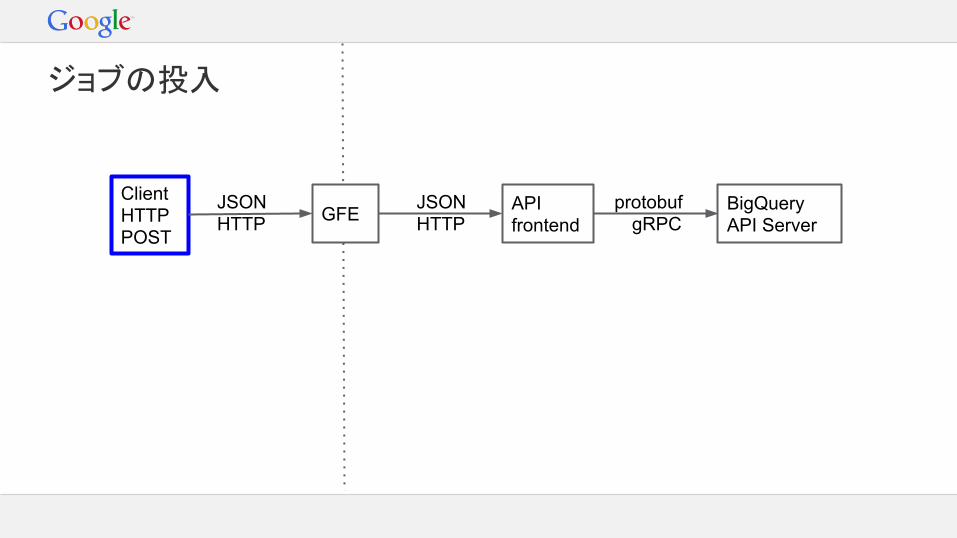
ジョブの投入

リクエストがBigQueryに届くまで...
GFE- GoogleネットワークへのHTTP接続を受け付け- DoS対策- 一般的なHTTPヘッダの処理
Google API Frontend- JSONとProtocol Buffer間の変換- HTTPとStubby/gRPC間の変換- リクエスト認証
HTTP POST
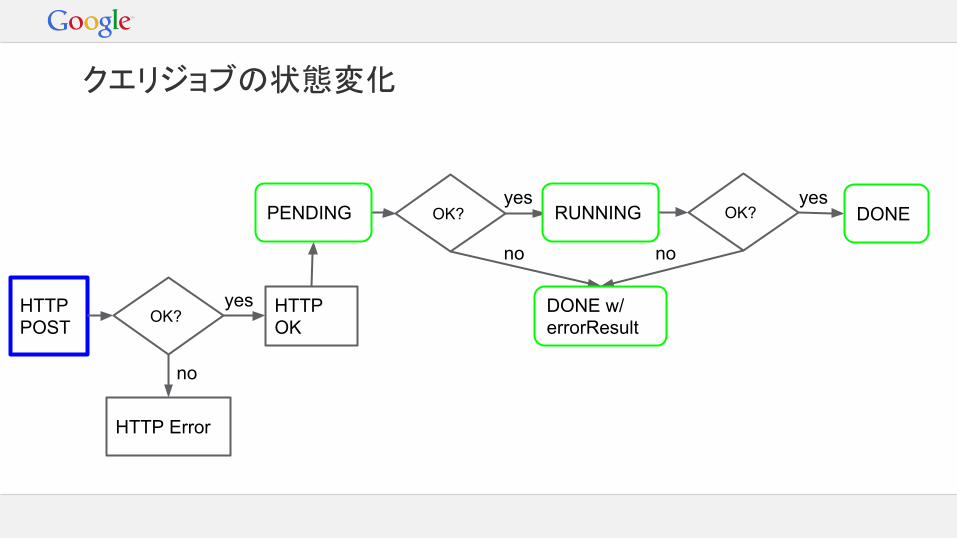
クエリジョブの状態変化
HTTP Error
HTTP OKOK?
OK?OK?PENDING RUNNING
DONE w/ errorResult
DONE
no
no
no
yes yes
yes
ClientHTTP POST
GFE200 OK API FrontendHTTP
200 OKHTTP
BigQuery API Server
protobufgRPC
Spanner
新規ジョブ Stubby
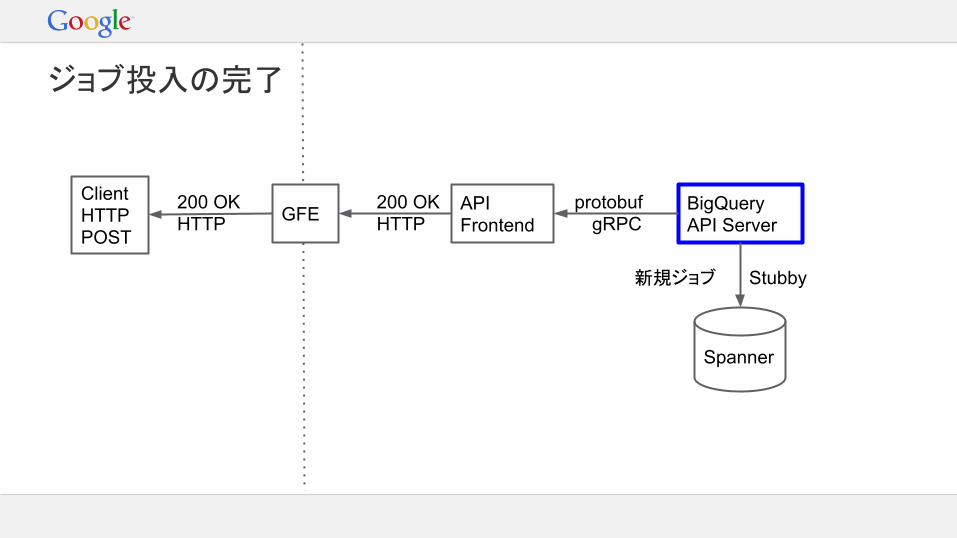
ジョブ投入の完了
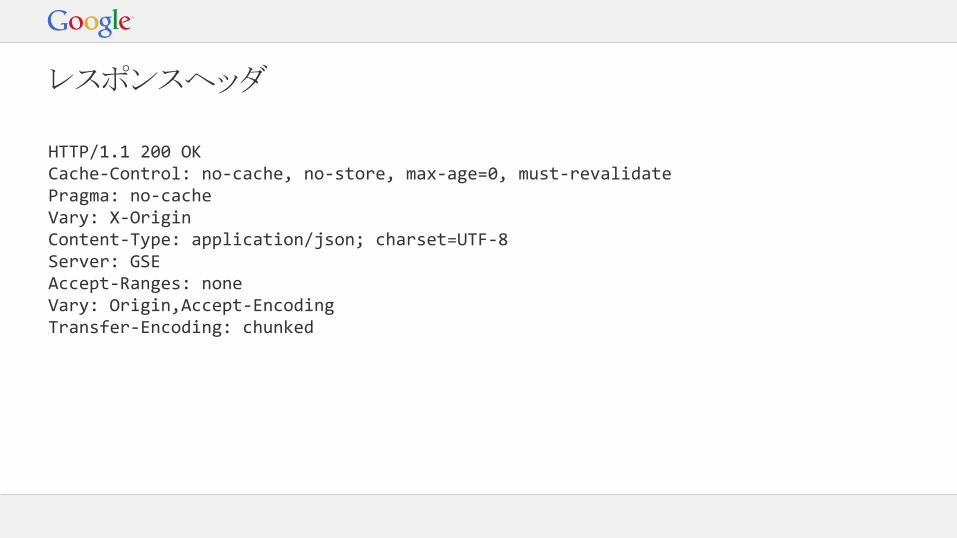
レスポンスヘッダ
HTTP/1.1 200 OKCache-Control: no-cache, no-store, max-age=0, must-revalidatePragma: no-cacheVary: X-OriginContent-Type: application/json; charset=UTF-8Server: GSEAccept-Ranges: noneVary: Origin,Accept-EncodingTransfer-Encoding: chunked
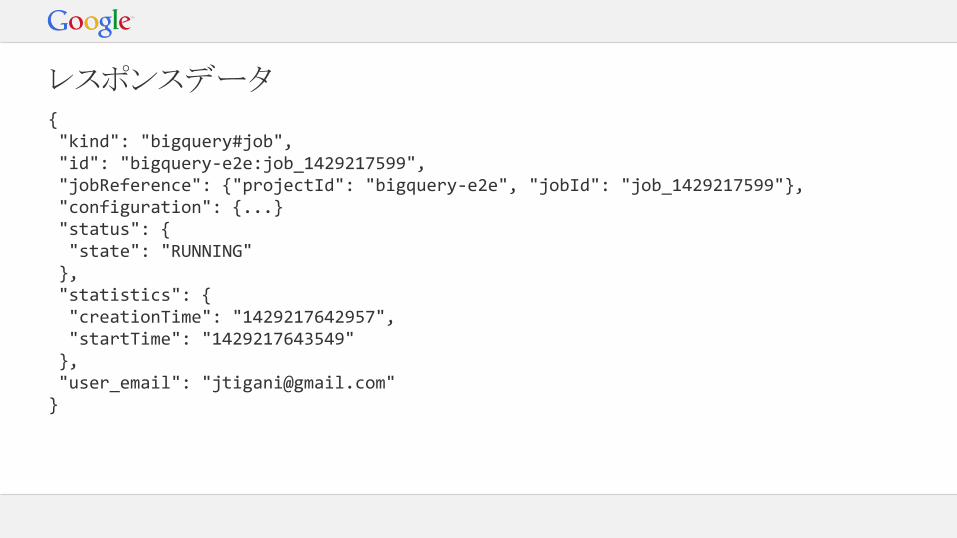
レスポンスデータ{ "kind": "bigquery#job", "id": "bigquery-e2e:job_1429217599", "jobReference": {"projectId": "bigquery-e2e", "jobId": "job_1429217599"}, "configuration": {...} "status": { "state": "RUNNING" }, "statistics": { "creationTime": "1429217642957", "startTime": "1429217643549" }, "user_email": "[email protected]"}
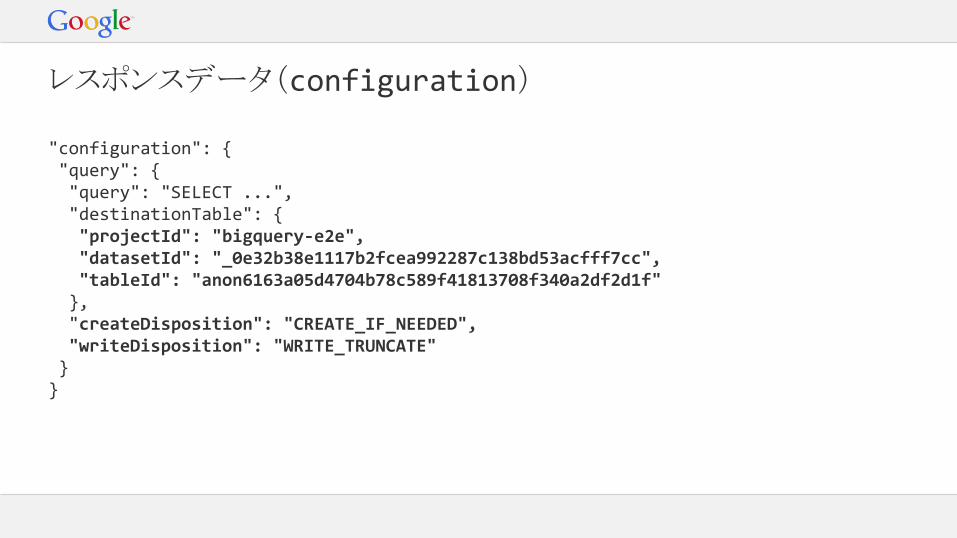
レスポンスデータ(configuration)
"configuration": { "query": { "query": "SELECT ...", "destinationTable": { "projectId": "bigquery-e2e", "datasetId": "_0e32b38e1117b2fcea992287c138bd53acfff7cc", "tableId": "anon6163a05d4704b78c589f41813708f340a2df2d1f" }, "createDisposition": "CREATE_IF_NEEDED", "writeDisposition": "WRITE_TRUNCATE" }}

新しいジョブの開始
1. 確認フェーズ:- 認証チェック- クオータのチェック- 入力内容の検証- キャッシュのチェック- 出力テーブルの用意
2. ジョブをメタデータストアに保存3. リクエスト元に正常開始を伝える

ところで:BigQueryのキャッシュの動き
以下のSHA-1ハッシュ値をとる:- データ更新時間- 参照テーブル以下の場合はキャッシュを使わない:- 値が変化する関数を使用(NOW()など)- 固定の出力テーブルを指定- 参照テーブルがストリーミングバッファを使用
SHA-1ハッシュ値が出力テーブル名となるユーザー単位でキャッシュされる
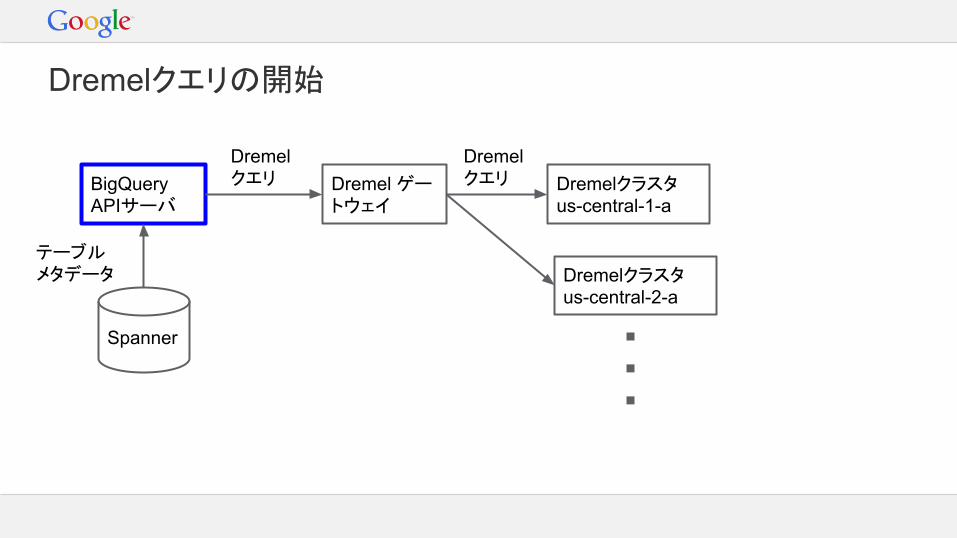
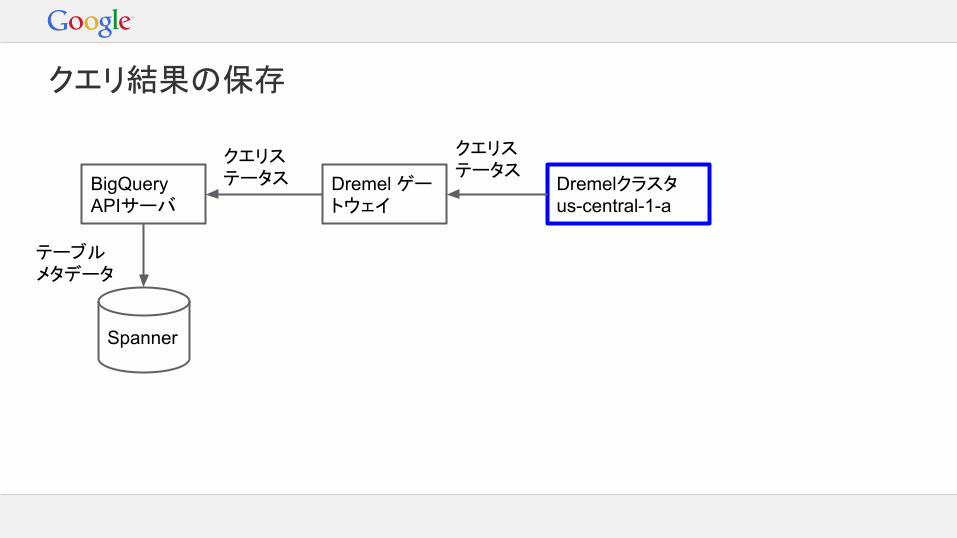
BigQuery APIサーバ
Spanner
テーブルメタデータ
Dremel ゲートウェイ
Dremel クエリ Dremelクラスタ
us-central-1-a
Dremelクラスタus-central-2-a
Dremel クエリ
Dremelクエリの開始

Dremelゲートウェイ
アクセス可能なレプリカを検索以下に基づき、クエリの実行に最適な場所を決定:- データからの距離- クラスタの負荷状況データは部分的にレプリケーションされる場合もある

ところで:BigQueryのレプリケーション
地理的に離れた複数のゾーン間でレプリケーション- 可用性の向上- ディザスタリカバリデータセンター内でのレプリケーション- 永続性の向上- リード性能の向上- リードソロモンに似たエンコーディングを使用小さなテーブルはメタデータ内に保存
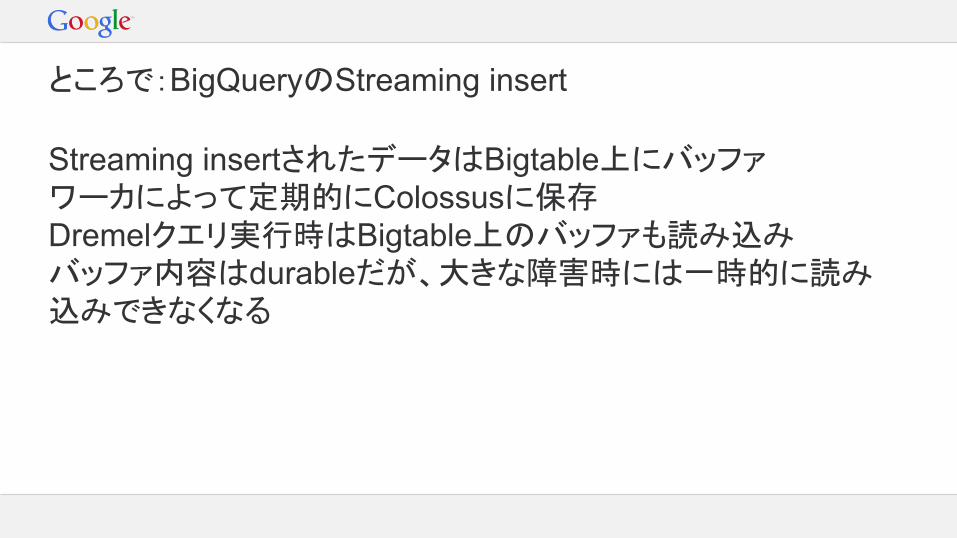
ところで:BigQueryのStreaming insert
Streaming insertされたデータはBigtable上にバッファワーカによって定期的にColossusに保存Dremelクエリ実行時はBigtable上のバッファも読み込みバッファ内容はdurableだが、大きな障害時には一時的に読み込みできなくなる
Dremel ゲートウェイ
Dremel Root Mixer
Dremel クエリ
Dremel Mixer-1
Dremel Mixer-1
Dremel Mixer-1
Dremel Shard
Dremel Shard
Dremel Shard
Dremel Shard
Dremel Shard
Dremel Shard
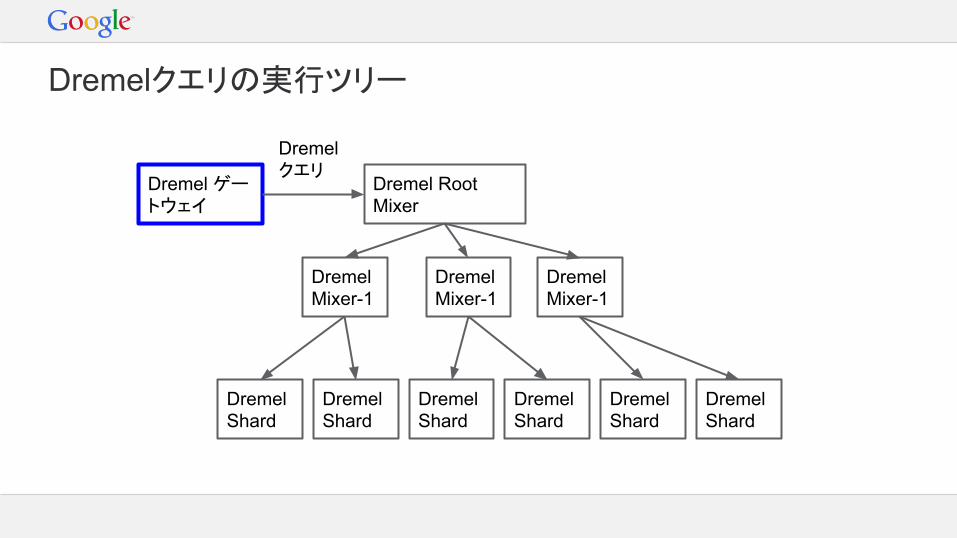
Dremelクエリの実行ツリー

Dremel Root Mixer
クエリプランの構築- クエリを複数のステージに分割- 処理内容を並列タスクに分割
クエリのスケジューリング- 利用可能なスロットを各ユーザーに分配- クエリの割り込み
クエリを下位のmixer/shardに転送

Dremel Shard
実行中のクエリの一部分を実行ソースからデータを読み込み
通常はColossusから(Streaming時の)Bigtable、またはCloud Storage
集約処理を部分的に実行
Dremel Shard
Dremel Shard
Dremel Shard
CFS CFS CFS CFS CFS CFS
分散メタデータ
分散ファイル
分散ストレージ
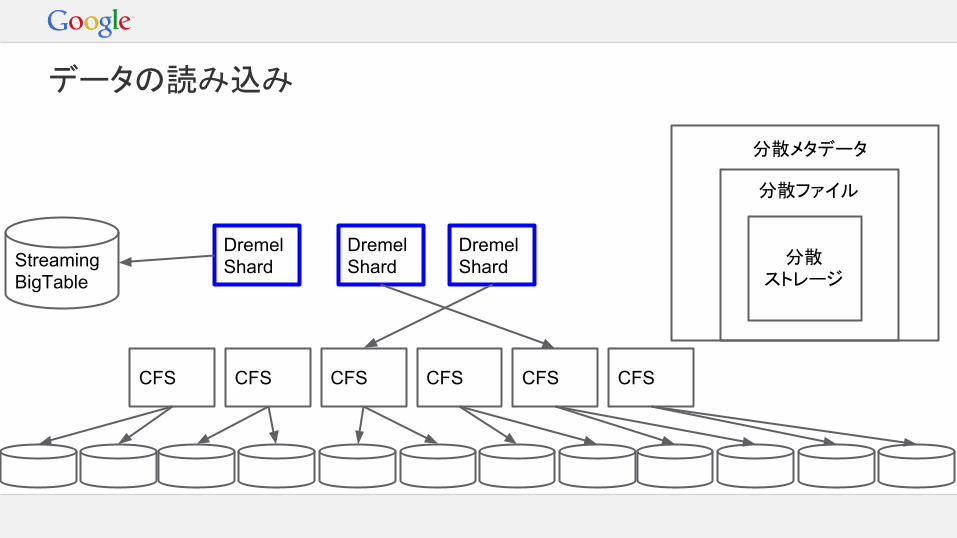
データの読み込み
StreamingBigTable

ストレージ階層
Colossusメタデータ- ディレクトリ構造- ACLs
Colossusファイル- ほとんどフラットな構造- 一部のACLs- 暗号化分散ストレージ- ディスクエンコード(RAID的なもの)- クラスタ内でレプリケーション
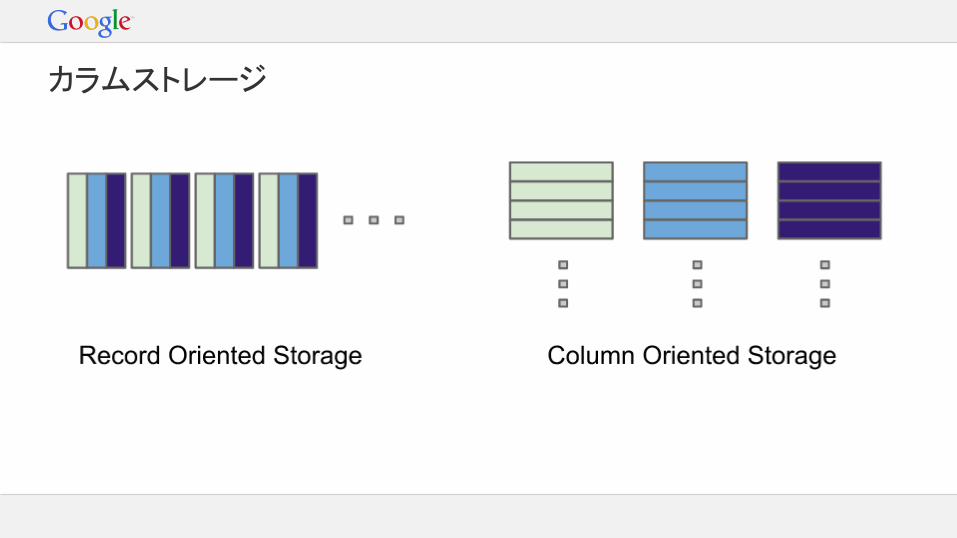
カラムストレージ

ColumnIO
データを行単位ではなくカラム単位で保存圧縮効率が向上分散ファイルシステムを利用- ローカルディスクではシークが多すぎる不要なカラムをスキップ- クエリの多くはテーブル内の一部のカラムのみ参照制約ヘッダ- 各カラムのレンジとカーディナリティを保持- ファイルのスキップが可能に
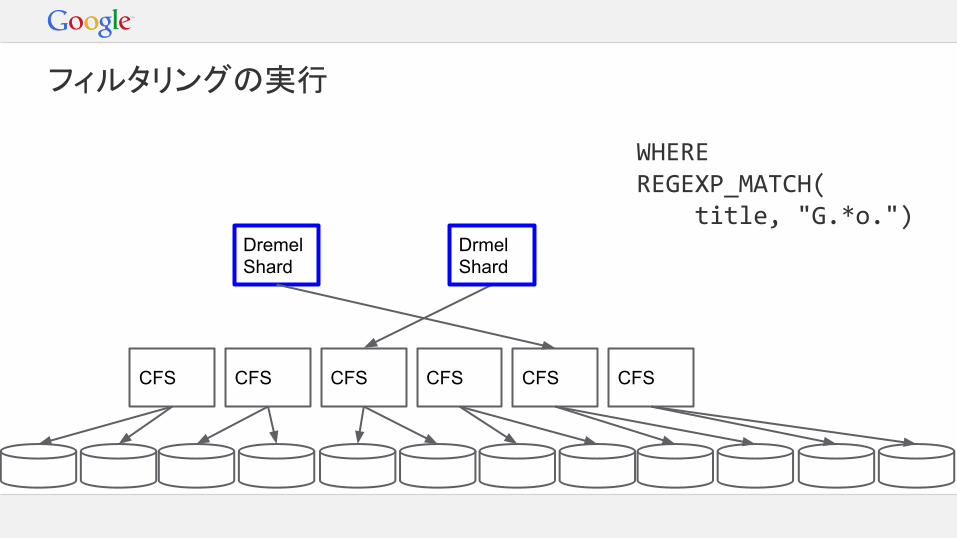
Dremel Shard
CFS CFS CFS CFS
WHERE REGEXP_MATCH( title, "G.*o.")
フィルタリングの実行
CFSCFS
Drmel Shard
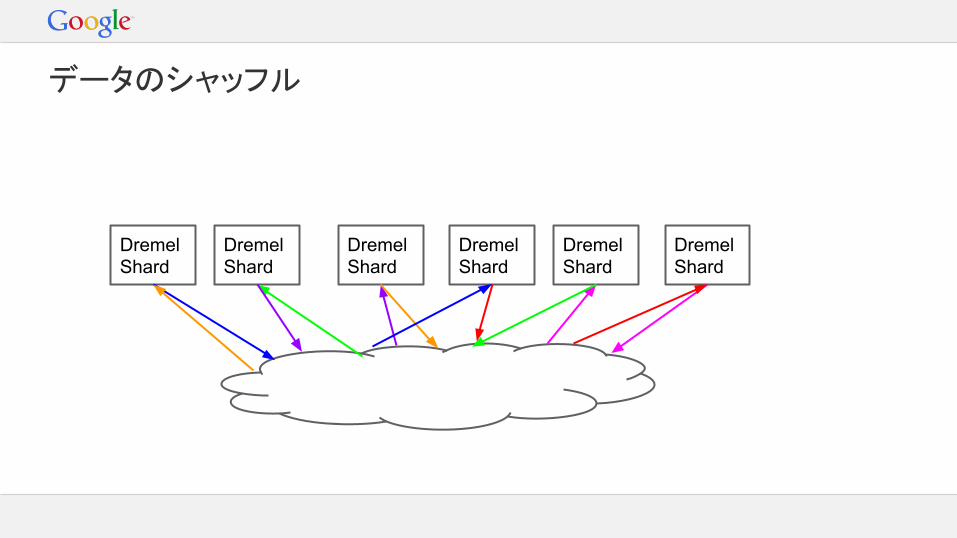
Dremel Shard
Dremel Shard
Dremel Shard
データのシャッフル
Dremel Shard
Dremel Shard
Dremel Shard

データのシャッフル
ハッシュ値でデータをパーティション分割- 個々のshardで集約が可能大きなパーティションはディスクにあふれるパーティションのばらつきも起こりうる- 例:3億のユニークユーザーIDのうち10%がユーザーID=0
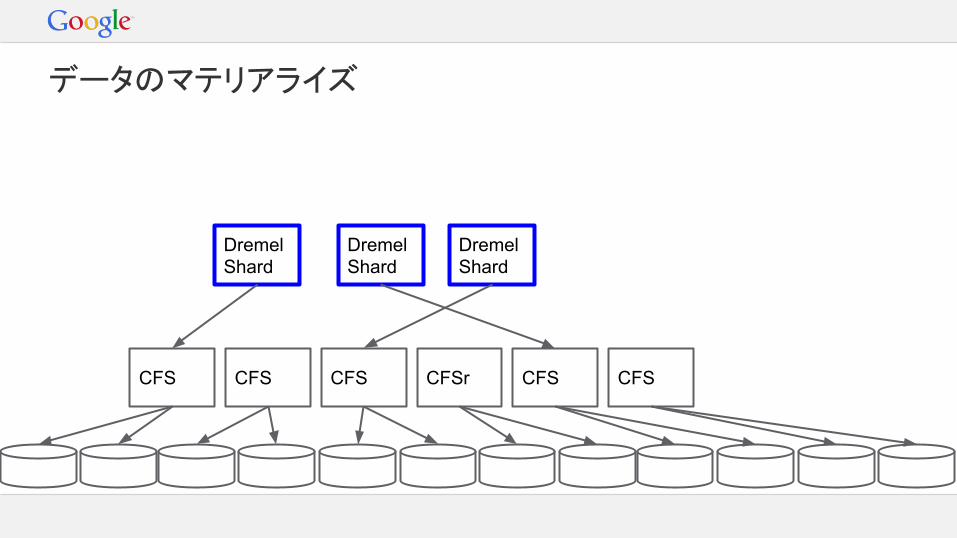
Dremel Shard
Dremel Shard
Dremel Shard
CFS CFS CFS CFSr CFS CFS
データのマテリアライズ
結果の出力
シャッフルした結果はshardに出力- shard内で集約されたデータ- 大規模な結果も出力可能シャッフル不要の結果はmixerに返す- mixerで集約を実行- 出力可能なサイズは128MBまで
BigQuery APIサーバ
Spanner
テーブルメタデータ
Dremel ゲートウェイ
クエリステータス Dremelクラスタ
us-central-1-a
クエリステータス
クエリ結果の保存

クエリ結果の保存
保存処理はACID特性を持つ- クエリ結果はすべてが返されるか、全く返されないか- クエリ結果は次のクエリですぐ利用できる小さなクエリ結果はメタデータ内部に保存される保存時に以下も可能:- CREATE_IF_NEEDED指定時のテーブル作成- WRITE_TRUNCATE指定時のテーブルまるめ- ジョブのステータスをDONEに
jobs.getQueryResults()
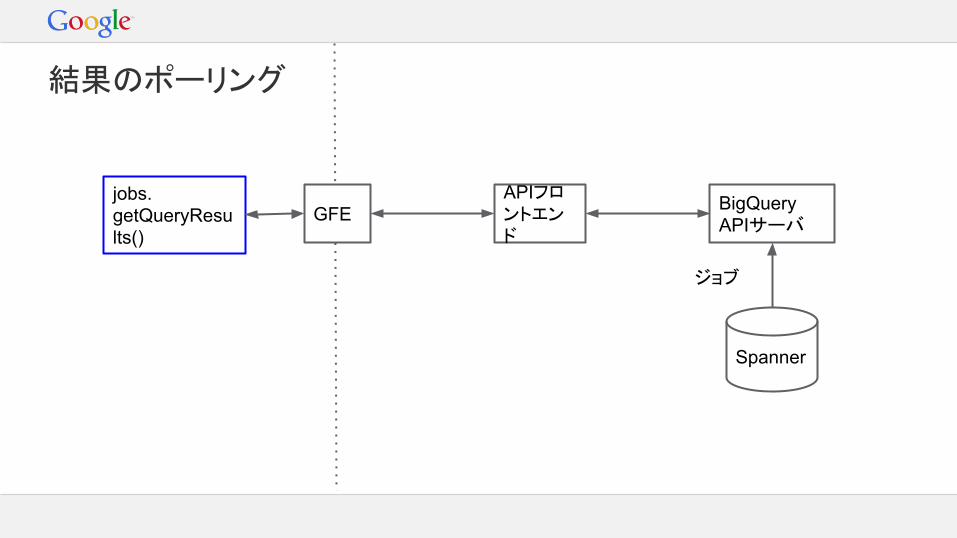
GFEAPIフロントエンド
BigQuery APIサーバ
Spanner
ジョブ
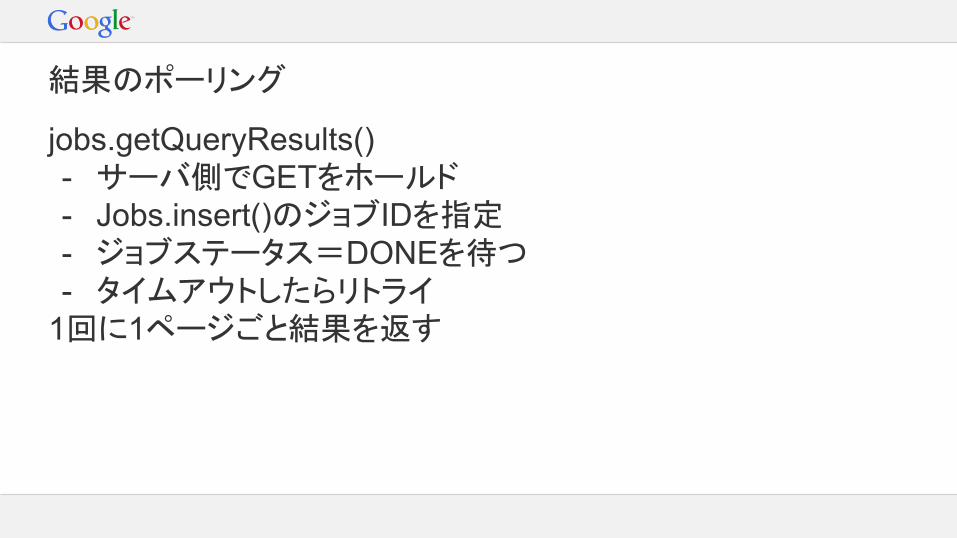
結果のポーリング
結果のポーリング
jobs.getQueryResults()- サーバ側でGETをホールド- Jobs.insert()のジョブIDを指定- ジョブステータス=DONEを待つ- タイムアウトしたらリトライ
1回に1ページごと結果を返す

curlでクエリ結果を取得
RESULTS_URL=${JOBS_URL}/${JOB_ID}/results
curl -H "$(python auth.py)" \ -H "Content-Type: application/json" \ -X GET \ "${RESULTS_URL}"